人体姿态识别
人体姿态识别(Human Pose Estimation, HPE)是计算机视觉领域的重要研究方向,旨在通过图像或视频数据检测人体的关键点(关节位置)并重建人体骨架结构,从而理解人体的姿态和动作状态。这一技术可用于动作分析、行为识别、增强现实(AR/VR)、人机交互、运动健康评估等多个场景。简单来说就是:
👉 从图像或视频中识别人体关键点(关节),并理解人的姿态结构。
人体姿态识别的核心任务是:
- 关键点检测:识别人体的各个关节(如肩、肘、膝、脚踝等)在图像中的二维或三维坐标。
- 骨架重建:将关键点按人体拓扑结构连接,形成完整骨架模型。
- 姿态理解(可选):基于骨架模型进行动作分类或行为分析。
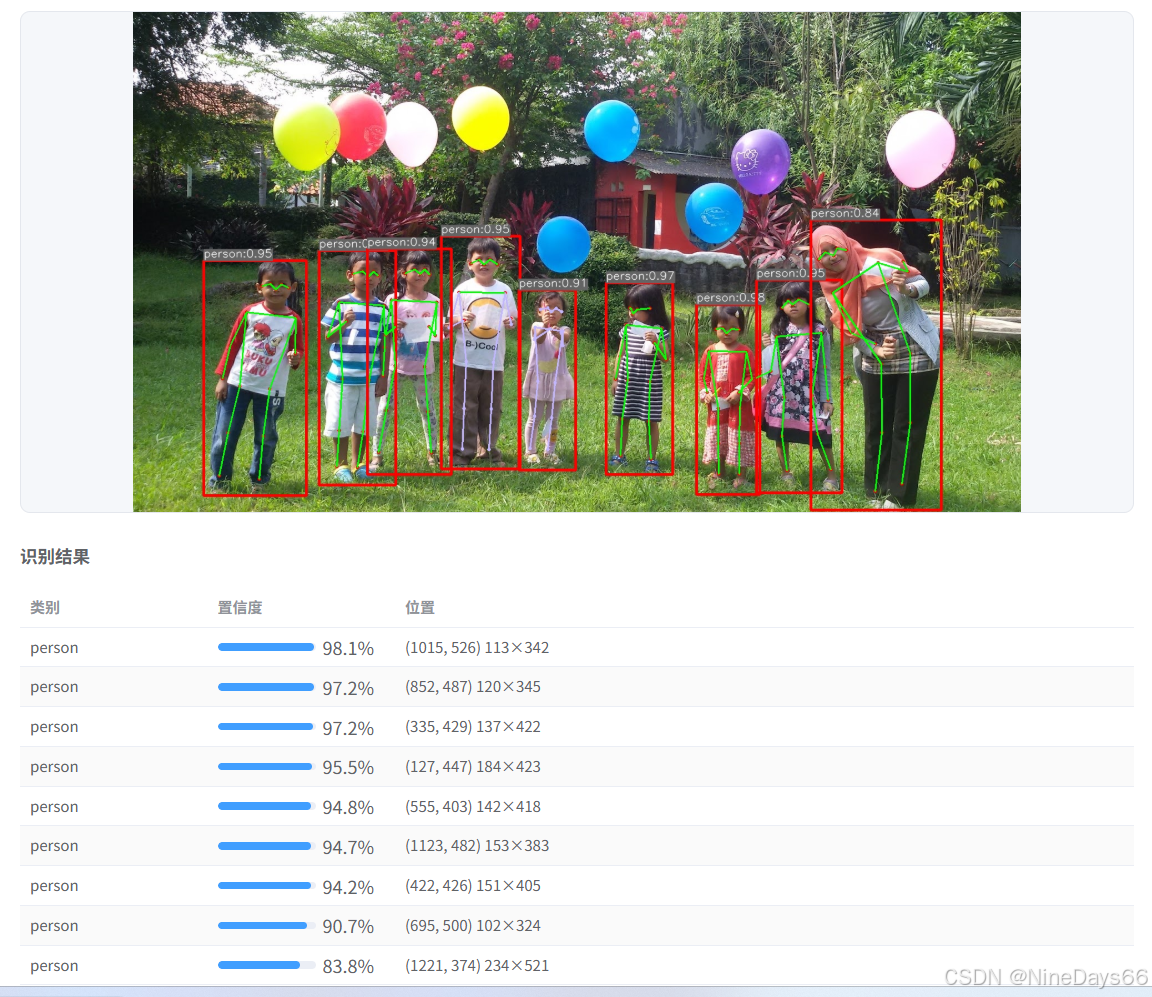
算法效果展示:
技术感兴趣联系:547691062@qq.com
端到端模型策略
我们采用 端到端人体姿态识别策略,直接将图像输入映射为人体关键点预测,无需额外的检测或分割模块。这种方法大幅简化了模型结构,提高了推理效率,使模型在实时视频流和边缘设备部署场景下都能保持高性能。
多数据集混合训练
在训练阶段,我们将来自 COCO、MPII 、 CrowdPose 、AIC、OChuman、 Joints 、自采数据 等多数据集的样本进行混合训练,充分利用不同数据集的多样性,包括多姿态、多人场景、遮挡和复杂光照条件。这种方法显著增强了模型的 泛化能力和鲁棒性,使其能够在未知场景下准确预测人体关键点。
精度与性能指标
通过端到端策略和多数据集混合训练,我们的模型在标准测试集上取得了显著提升:
- COCO 骨架 mAP:约 76.5%
- MPII PCKh@0.5:约 91.2%
- 推理速度:在 1080p 视频输入下可达 30 FPS(单人场景),在多人场景下保持 20 FPS 以上
- 模型大小:轻量化设计约 5MB,适合移动端或边缘设备部署
技术优化手段
为了进一步提升关键点定位精度,我们还引入了 热图优化、偏移微调和数据增强 等技术手段,使关键点预测更加稳定可靠。在真实场景中,无论是单人运动还是多人复杂交互,模型都能保持高精度和低抖动表现,为视频分析、动作识别及智能交互提供坚实的技术保障。
🧠 一、核心目标
输入:
- 单张图片 / 视频帧
输出:
- 人体关键点坐标(2D 或 3D)
- 可选:骨架连接关系
例如:
鼻子:(x1, y1) 左肩:(x2, y2) 右膝:(x3, y3) ...
常见关键点数量:
- 17点(COCO标准)
- 21点(手部)
- 33点(全身+细节)
🧩 二、技术分类(重点)
1️⃣ Top-Down(先检测人,再识别姿态)
流程:先使用人体检测器获取每个人的 bounding box,再对每个目标单独进行关键点检测。
特点:
- 精度高,单人姿态识别效果优秀;
- 依赖人体检测结果,多人场景计算量大。
代表方法:
- OpenPose(早期经典)
- HRNet
- AlphaPose
2️⃣ Bottom-Up(先找关键点,再组人)
流程:先在整张图上检测所有人体关键点,再通过连接算法将关键点组合成对应人体。
特点:
- 多人场景效率高;
- 对遮挡和关键点关联要求高,精度略低。
代表方法:
- OpenPose(Paf 连接)
- HigherHRNet
3️⃣ One-Stage(端到端)
流程:直接输入图像,输出人体关键点,无需先检测人体。
特点:
- 部署简单,实时性强;
- 精度介于 Top-Down 与 Bottom-Up 之间。
代表方法:
- YOLOv7-Pose
- RTMPose
🧪 三、关键技术细节(核心)
- Heatmap 表示
- 模型输出每个关键点的概率热图(heatmap)。
- 热图中最大值位置对应关键点坐标。
- 优点:精度高、鲁棒性好;缺点:受分辨率影响大。
- 直接回归
- 模型直接回归关键点坐标 (x, y)。
- 优点:速度快,轻量化;
- 缺点:精度略低,容易受遮挡影响。
- 时序建模
- 在视频中加入时间信息,用 EMA、Kalman 或 Transformer 平滑关键点位置。
- 解决抖动问题,适合视频动作分析。
- 后处理
- 对关键点位置进行微调,修正量化误差。
- 对多人场景进行关键点关联。
📊 四、评估指标
最常用:
- OKS(Object Keypoint Similarity):用于衡量预测关键点与真实关键点的接近程度。
- mAP(mean Average Precision):COCO 数据集标准,用于评价整体识别性能。
本质:
👉 看关键点预测是否接近 GT
⚙️ 五、工程落地(结合你方向)
👉 轻量模型 + 边缘设备(ncnn / RKNN)
重点建议:
🔹1. 模型选择
优先:
- RTMPose
- YOLOv7-Pose
原因:
- 结构简单
- 易转 ncnn
🚀 六、应用场景
- 动作识别(健身、安防)
- 手势识别
- AR/VR
- 人脸辅助(头部姿态)
- 自动驾驶(行人行为)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)