Java AI 之 DJL 实战(第 2 篇):NDArray(张量)
NDArray(张量)
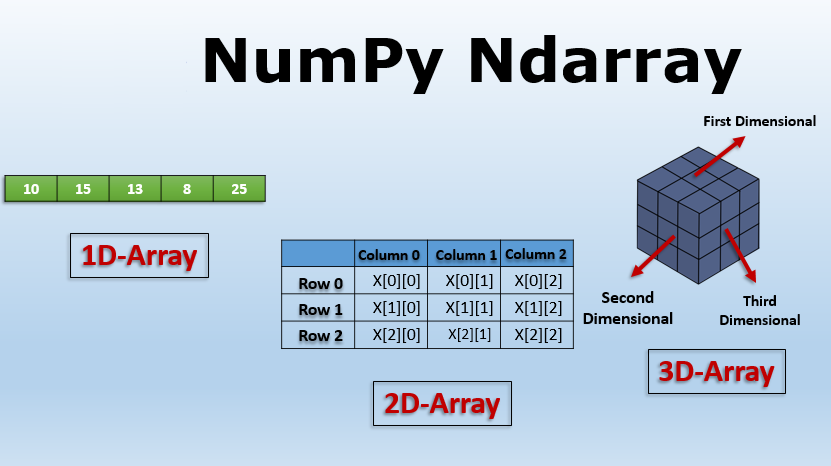
在Java生态系统中,DJL是一个强大的深度学习库,它提供了丰富的工具和数据结构来支持深度学习模型的构建和训练。其中,NDArray是DJL中的核心数据结构之一,用于表示多维数组,类似于Python中NumPy的ndarray,如下图所示:
接下来将系统化地介绍DJL中NDArray数据结构的使用,包括相关的Maven依赖引入、关键概念、附带代码示例以及详细的注释。
什么是NDArray?
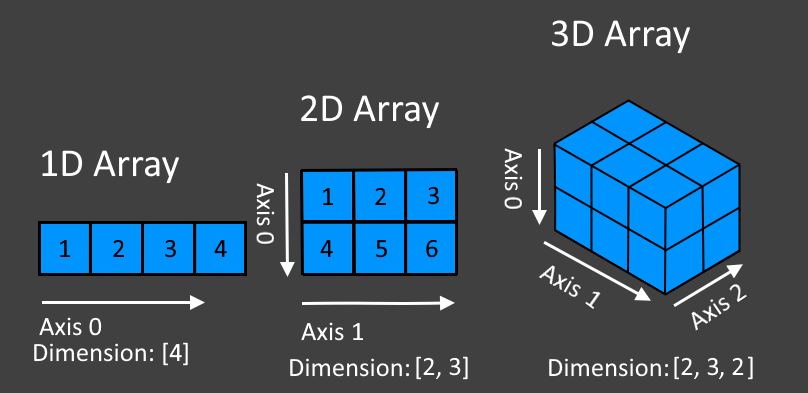
NDArray顾名思义,表示任意维度的数组。NDArray是DJL中的多维数组数据结构,用于存储和操作多维数据。它是DL4J中所有计算的核心,类似于NumPy中的ndarray。NDArray支持各种数学运算、广播操作、切片、索引等功能,是构建和训练深度学习模型的基础。
NDArray 的设计初衷就是为了能够处理各种不同维度的数据。它可以是一维的向量,比如存储一组特征值;也可以是二维的矩阵,常见于图像数据(其中行可以表示图像的像素行,列可以表示不同的颜色通道或特征);甚至可以是更高维度的张量,用于处理复杂的深度学习任务,如卷积神经网络中多通道的图像数据和多个滤波器的组合。
NDArray的重要性
在深度学习中,理解NDArray是非常重要的。它是数据预处理、模型构建、训练和评估的基础。通过掌握NDArray,可以更高效地进行数据操作和模型开发,从而提升深度学习项目的开发效率和质量。
学习NDArray 创建,核心价值在于掌握深度学习框架中最基础、最核心的张量操作能力,NDArray(张量)是所有深度学习任务的 “数据载体”,无论是做模型训练、推理、数据预处理还是自定义算法,都绕不开它。
之前的所有 DJL 示例(MNIST 分类、SSD 目标检测),底层都是先把原始数据转成 NDArray,再输入模型 ;不使用 NDArray ,就没法把 “业务数据” 和 “DJL 模型” 连接起来。

核心特性:
- 跨引擎兼容:无论底层是PyTorch还是TensorFlow,API完全一致
- 自动内存管理:基于NDManager的层级内存管理,自动释放native内存
- 懒评估优化:支持操作融合和延迟执行
- 丰富的操作集:600+个数学、统计、线性代数操作
NDArray的基本操作
创建NDArray
NDArray可以通过多种方式创建,包括从数组、列表、随机数生成等。
以下是一些常见的创建方法:
import ai.djl.ndarray.NDArray;
import ai.djl.ndarray.NDManager;
import ai.djl.ndarray.types.Shape;
public class NDArrayCreationExample {
public static void main(String[] args) {
// 创建NDManager(DJL中管理NDArray生命周期的核心类)
try (NDManager manager = NDManager.newBaseManager()) {
// 1. 创建一个全零的NDArray,形状为(3, 3)
NDArray zeros = manager.zeros(new Shape(3, 3));
System.out.println("Zeros:\n" + zeros);
// 2. 创建一个全一的NDArray,形状为(2, 2)
NDArray ones = manager.ones(new Shape(2, 2));
System.out.println("Ones:\n" + ones);
// 3. 创建一个随机NDArray(0-1均匀分布),形状为(3, 3)
NDArray random = manager.randomUniform(0f, 1f, new Shape(3, 3));
System.out.println("Random:\n" + random);
// 4. 从Java数组创建NDArray
double[][] data = {{1, 2, 3}, {4, 5, 6}};
NDArray fromArray = manager.create(data);
System.out.println("From Array:\n" + fromArray);
} // NDManager会自动关闭,释放资源
}
}
执行结果
Zeros:
ND: (3, 3) cpu() float32
[[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.],
]
Ones:
ND: (2, 2) cpu() float32
[[1., 1.],
[1., 1.],
]
Random:
ND: (3, 3) cpu() float32
[[0.5488, 0.5928, 0.7152],
[0.8443, 0.6028, 0.8579],
[0.5449, 0.8473, 0.4237],
]
From Array:
ND: (2, 3) cpu() float64
[[1., 2., 3.],
[4., 5., 6.],
]
NDArray的形状和维度
NDArray的形状(shape)表示数组的维度信息。例如,一个形状为(3, 3)的NDArray表示一个3x3的二维数组。
import ai.djl.ndarray.NDArray;
import ai.djl.ndarray.NDManager;
import java.util.Arrays;
public class NDArrayShapeExample {
public static void main(String[] args) {
// 创建NDManager管理NDArray生命周期(DJL核心规范)
try (NDManager manager = NDManager.newBaseManager()) {
// 1. 创建二维NDArray
NDArray array = manager.create(new double[][]{{1, 2, 3}, {4, 5, 6}});
// 2. 获取NDArray的形状
long[] shape = array.getShape().getShape();
System.out.println("Shape: " + Arrays.toString(shape));
// 3. 获取NDArray的维度
int rank = array.getShape().dimension();
System.out.println("Rank: " + rank);
// 拓展:DJL中常用的形状操作
// 获取某一维度的大小(比如第0维)
long dim0Size = array.getShape().get(0);
System.out.println("Dimension 0 size: " + dim0Size);
// 获取总元素个数
long totalElements = array.size();
System.out.println("Total elements: " + totalElements);
} // 自动关闭NDManager,释放内存
}
}
结果
Shape: [2, 3]
Rank: 2
Dimension 0 size: 2
Total elements: 6
获取 NDArray 的形状(Shape)和维度(Dimension/Rank)是深度学习开发中最基础也最核心的操作,几乎所有模型训练、数据预处理、推理部署的环节都离不开它,本质是为了保证 “数据维度” 和 “模型要求” 匹配,同时高效管理 / 操作张量数据。
NDArray的索引和切片
NDArray支持类似于NumPy的索引和切片操作,可以方便地访问和修改数组中的元素。
import ai.djl.ndarray.NDArray;
import ai.djl.ndarray.NDManager;
import ai.djl.ndarray.index.NDIndex;
public class NDArrayIndexingExample {
public static void main(String[] args) {
// 创建NDManager管理张量生命周期(
try (NDManager manager = NDManager.newBaseManager()) {
// 1. 创建3×3二维张量
NDArray array = manager.create(new double[][]{{1, 2, 3}, {4, 5, 6}, {7, 8, 9}});
System.out.println("原始数组" + array);
// 2. 获取单个元素
double element = array.getDouble(1L, 2L); // 第二行第三列(索引0开始)
System.out.println("(1, 2) 位置的元素:" + element);
// 3. 获取子数组(切片), 第二行所有元素
// NDIndex("1, :") 等价于“第1行 + 所有列”
NDIndex row1Index = new NDIndex("1, :");
NDArray slice = array.get(row1Index);
System.out.println("切片(第二行):" + slice);
// 4. 修改单个元素
NDIndex pos00Index = new NDIndex(0L, 0L); // 第一行第一列
array.set(pos00Index, manager.create(10.0)); // 改为10.0
System.out.println("修改(0,0)后的数组:" + array);
// 切片前两行、后两列
NDIndex first2RowsLast2Cols = new NDIndex(":2, 1:"); // 合并为单个字符串索引,更规范
NDArray slice2 = array.get(first2RowsLast2Cols);
System.out.println("切片(前2行,后2列):" + slice2);
// 批量修改第三列
NDIndex thirdColIndex = new NDIndex(": , 2"); // 所有行、第三列
array.set(thirdColIndex, manager.create(99.0));
System.out.println("修改第三列后:" + array);
} catch (Exception e) {
e.printStackTrace();
}
}
}
结果
原始数组ND: (3, 3) cpu() float64
[[1., 2., 3.],
[4., 5., 6.],
[7., 8., 9.],
]
(1, 2) 位置的元素:6.0
切片(第二行):ND: (3) cpu() float64
[4., 5., 6.]
修改(0,0)后的数组:ND: (3, 3) cpu() float64
[[10., 2., 3.],
[ 4., 5., 6.],
[ 7., 8., 9.],
]
切片(前2行,后2列):ND: (2, 2) cpu() float64
[[2., 3.],
[5., 6.],
]
修改第三列后:ND: (3, 3) cpu() float64
[[10., 2., 99.],
[ 4., 5., 99.],
[ 7., 8., 99.],
]
在 DJL(以及所有深度学习框架)中,张量切片(Tensor Slicing) 是操作多维数据的核心能力,其本质是从高维张量中精准提取 / 筛选所需的子数据, 就像从一本厚书中只撕下某几页、某几行,或从 Excel 表里只选某几列 / 某几行。
切片就是从一大份数据里,只挑你想要的那一小部分,就像你吃蛋糕只切一块、翻书只看某几页,不用把整个蛋糕吃了、整本书翻完。
举几个生活例子对应代码里的切片:
- 切蛋糕(对应二维数组切片)
比如有个 3×3 的方形蛋糕(就像代码里的 3 行 3 列数组):
- 只想吃 “第二行” 的所有奶油(对应代码
array.get(new NDIndex("1, :"))):就沿着第二行的边,把这一行完整切下来,其他行不动; - 只想吃 “前两行、后两列” 的水果(对应
":2, 1:"):就切左上角 2 行 ×2 列的小块,只拿这部分。
- 翻笔记本(对应序列数据切片)
有个写满 100 行的笔记本(对应代码里 100 长度的序列张量):
- 老师只让看前 20 行(对应
":20"):就只翻到 20 行,后面的不看; - 只想看第 50 到 80 行(对应
"50:80"):就只翻这 30 行,其他行跳过。
- 分水果篮(对应批量数据切片)
有个装了 100 个苹果的篮子(对应 100 条训练数据):
- 想拿前 80 个做 “训练用”(对应
":80, :"):就先数出 80 个装小篮子,剩下 20 个留着 “验证用”(对应"80:, :"); - 一次拿不动 100 个,分 10 次拿、每次拿 10 个(对应分块切片):每次只抓 10 个,拿完再拿下 10 个,不累还不浪费。
为啥非要用切片?
- 省事儿:不用处理没用的数据。比如只想算第二行的和,直接切出第二行算就行,不用把整个 3×3 数组都算一遍;
- 适配需求:模型 “吃不下” 大份数据。比如模型只能处理 128 个字符的句子,你有 200 个字符,就切前 128 个,不然模型会 “噎住”(报错);
- 不浪费资源:手机 / 电脑内存有限。比如有个 10G 的大文件,直接打开会卡死,切片成 10 个 1G 的小块,每次只处理 1 块,用完就扔,不占内存;
- 精准拿想要的:比如模型输出 10 个类别的概率,你只想看 “猫” 这个类别的概率(对应某一列),直接切这一列就行,不用看其他 9 个。
切片就是 “按需取数” : 想要哪部分数据,就用切片 “框” 出来,只处理这部分。不用像 “笨办法” 那样,把所有数据都加载、都计算,既省时间、又省内存,还能精准满足模型 / 业务的要求。
NDArray的数学运算
NDArray支持各种数学运算,包括加法、减法、乘法、除法、矩阵乘法等。
import ai.djl.ndarray.NDArray;
import ai.djl.ndarray.NDManager;
import ai.djl.ndarray.types.DataType;
import java.nio.charset.StandardCharsets;
public class NDArrayMathExample {
public static void main(String[] args) {
// 创建NDManager管理张量生命周期
try (NDManager manager = NDManager.newBaseManager()) {
// 1. 创建两个2×2张量
NDArray a = manager.create(new double[][]{{1, 2}, {3, 4}});
NDArray b = manager.create(new double[][]{{5, 6}, {7, 8}});
System.out.println("原始张量a:" + a);
System.out.println("原始张量b:" + b);
// 2. 对应元素加法
NDArray sum = a.add(b);
System.out.println("对应元素相加:" + sum);
// 3. 对应元素减法
NDArray difference = a.sub(b);
System.out.println("对应元素相减:" + difference);
// 4. 对应元素乘法(
NDArray product = a.mul(b);
System.out.println("对应元素相乘:" + product);
// 5. 矩阵乘法
NDArray matmul = a.matMul(b);
System.out.println("矩阵乘法:" + matmul);
} catch (Exception e) {
e.printStackTrace();
}
}
}
结果
原始张量a:ND: (2, 2) cpu() float64
[[1., 2.],
[3., 4.],
]
原始张量b:ND: (2, 2) cpu() float64
[[5., 6.],
[7., 8.],
]
对应元素相加:ND: (2, 2) cpu() float64
[[ 6., 8.],
[10., 12.],
]
对应元素相减:ND: (2, 2) cpu() float64
[[-4., -4.],
[-4., -4.],
]
对应元素相乘:ND: (2, 2) cpu() float64
[[ 5., 12.],
[21., 32.],
]
矩阵乘法:ND: (2, 2) cpu() float64
[[19., 22.],
[43., 50.],
]
矩阵与矩阵相乘遵循特定的数学规则。为了相乘,第一个矩阵的列数必须等于第二个矩阵的行数。矩阵乘法的结果是一个新矩阵,其行数等于第一个矩阵的行数,列数等于第二个矩阵的列数。矩阵乘法不满足交换律,即 AB≠BA。
原理示例:
假设我们有两个矩阵 A 和 B,其中:
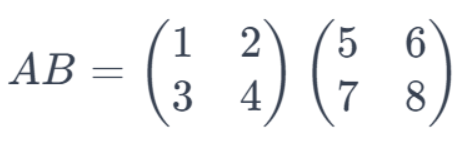
在这个例子中,矩阵 A 和 B 都是 2x2 矩阵。我们可以将它们相乘,得到一个新的 2x2 矩阵。
进行矩阵乘法的计算如下:
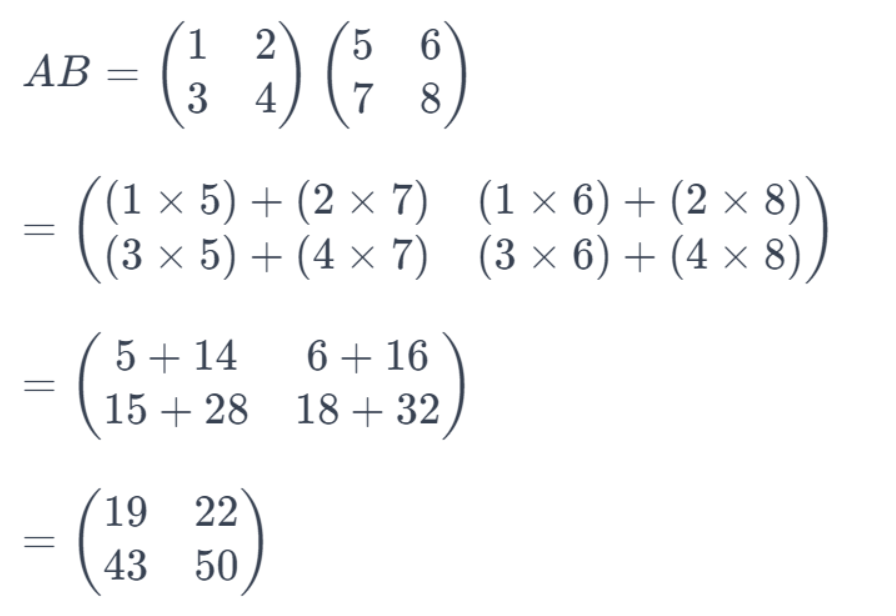
应用示例1:
假设你开一家小餐厅,卖两种套餐:
套餐 A:需要 2 个鸡蛋 + 1 杯牛奶
套餐 B:需要 3 个鸡蛋 + 2 杯牛奶
我们可以写成一个 “配方矩阵”(每一行代表一种套餐,每一列代表一种原料):
| 鸡蛋 | 牛奶 | |
|---|---|---|
| 套餐 A | 2 | 1 |
| 套餐 B | 3 | 2 |
某天订单如下:
星期一订单:
- 要 3 份 套餐 A
- 要 5 份 套餐 B
把订单写成一个 订单矩阵(每一行代表一种套餐,每一列代表一天):
| 星期一 | |
|---|---|
| 套餐 A | 3 |
| 套餐 B | 5 |
现在算星期一需要多少鸡蛋、多少牛奶?
手工算法:
- 鸡蛋总数 = (套餐A的鸡蛋数 × 份数) + (套餐B的鸡蛋数 × 份数)
= (2×3) + (3×5) = 6 + 15 = 21 个鸡蛋 - 牛奶总数 = (套餐A的牛奶数 × 份数) + (套餐B的牛奶数 × 份数)
= (1×3) + (2×5) = 3 + 10 = 13 杯牛奶
原料消耗矩阵(每一行是原料,每一列是套餐)
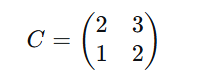
第一行(鸡蛋):套餐A需要2个,套餐B需要3个
第二行(牛奶):套餐A需要1杯,套餐B需要2杯
订单矩阵(每一行是套餐,每一列是天数):
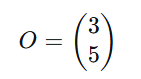
表示星期一:套餐A订单3,套餐B订单5。
现在 CC 是 2×2(原料×套餐),OO 是 2×1(套餐×天),可以相乘:
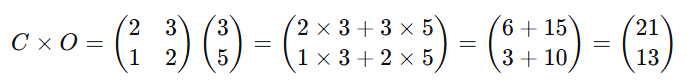
结果矩阵是 2行1列,第一行是鸡蛋总数 21,第二行是牛奶总数 13。
应用示例2
假设学生期末成绩由:
平时成绩占 30%,期中考试占 30%,期末考试占 40%。
有两个学生,成绩如下(行是学生,列是考试类型):
成绩表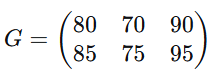
(学生1:平时80,期中70,期末90;学生2:平时85,期中75,期末95)
权重向量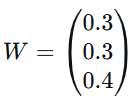
总评成绩 = G×W
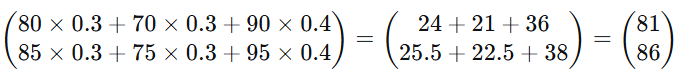
学生1总评 81 分,学生2总评 86 分。
矩阵乘法就是把多个线性配方关系与多组数据一次性结合起来,算出最终各类别总量的高效方法。它在生活中无处不在:食品配方计算、成本核算、成绩汇总、图形变换(比如旋转图片)、推荐系统(用户喜好矩阵 × 商品属性矩阵)等等。
NDArray的广播
广播(Broadcasting)是NDArray中的一个重要概念,允许不同形状的数组进行算术运算。
示例1:
import ai.djl.ndarray.NDArray;
import ai.djl.ndarray.NDManager;
import ai.djl.ndarray.types.Shape;
public class NDArrayBroadcastingExample {
public static void main(String[] args) {
// 创建NDManager管理张量生命周期(DJL核心规范)
try (NDManager manager = NDManager.newBaseManager()) {
// 1. 创建2×2的二维张量a
NDArray a = manager.create(new double[][]{{1, 2}, {3, 4}});
// 2. 创建1维张量b
NDArray b = manager.create(new double[]{10, 20});
System.out.println("原始张量a(2×2):\n" + a);
System.out.println("原始张量b(1×2):\n" + b);
// 3. 广播加法
NDArray broadcastSum = a.add(b);
System.out.println("\n广播相加结果:\n" + broadcastSum);
// 4. 模拟广播:先把b从(2,)扩展为(1,2),再广播扩展为(2,2),再相加
NDArray bBroadcast = b.reshape(new Shape(1, 2)).broadcast(new Shape(2, 2));
System.out.println("\n手动广播后的b:\n" + bBroadcast);
NDArray manualSum = a.add(bBroadcast);
System.out.println("\n手动广播相加结果:\n" + manualSum);
} catch (Exception e) {
e.printStackTrace();
}
}
}
结果
原始张量a(2×2):
ND: (2, 2) cpu() float64
[[1., 2.],
[3., 4.],
]
原始张量b(1×2):
ND: (2) cpu() float64
[10., 20.]
广播相加结果:
ND: (2, 2) cpu() float64
[[11., 22.],
[13., 24.],
]
手动广播后的b:
ND: (2, 2) cpu() float64
[[10., 20.],
[10., 20.],
]
手动广播相加结果:
ND: (2, 2) cpu() float64
[[11., 22.],
[13., 24.],
]
为什么b是(2,)而不是(1,2)呢
(2,)→ 就像 一排书放在桌子上(只有长度,没有明确的“行”概念)(1,2)→ 就像 一个书架的第一层放了2本书(明确有1行2列)
代码示例
// (2,)
NDArray b = manager.create(new double[]{10, 20});
// 这是创建一维数组,不是二维数组!
// 如果要创建 (1,2),应该写:
NDArray b2 = manager.create(new double[][]{{10, 20}});
// 注意:这里有两层大括号!
为什么设计成这样
(2,)→ 表示"我就是一组数据",不关心行列结构(1,2)→ 明确表示"我是1行2列的表格"
示例2:
你是食堂大厨,面前有三口大锅(代表3个菜):
锅A:青椒肉丝
锅B:西红柿鸡蛋
锅C:麻婆豆腐
每个菜都要放三种调料(盐、糖、醋),但每道菜需要的量不同。
| 菜品 | 盐(克) | 糖(克) | 醋(克) |
|---|---|---|---|
| 青椒肉丝 | 10 | 5 | 3 |
| 西红柿鸡蛋 | 8 | 12 | 1 |
| 麻婆豆腐 | 15 | 4 | 6 |
现在,老板说:“今天所有菜都统一少放1克盐,因为客人反映偏咸”。
import ai.djl.ndarray.NDArray;
import ai.djl.ndarray.NDManager;
public class CookingBroadcastFull {
public static void main(String[] args) {
try (NDManager manager = NDManager.newBaseManager()) {
// 1. 三锅菜的完整配方表(盐、糖、醋)
// 形状:3锅 × 3种调料
NDArray recipe = manager.create(new double[][]{
{10, 5, 3}, // 青椒肉丝:盐10g, 糖5g, 醋3g
{8, 12, 1}, // 西红柿鸡蛋
{15, 4, 6} // 麻婆豆腐
});
System.out.println("原始配方表(行=菜,列=调料[盐,糖,醋]):");
System.out.println(recipe.toDebugString());
// 2. 场景1:统一减少盐量(所有菜盐减1克)
System.out.println("\n--- 场景1:统一减盐 ---");
NDArray saltReduction = manager.create(new double[]{1, 0, 0}); // 只减盐,糖醋不变
NDArray recipe1 = recipe.sub(saltReduction);
System.out.println("减盐后的配方:\n" + recipe1.toDebugString());
// 3. 场景2:厨师手抖,每锅菜的每种调料都多加了一点
System.out.println("\n--- 场景2:所有调料都多加一点 ---");
NDArray extra = manager.create(new double[]{0.5, 0.3, 0.2}); // 盐+0.5, 糖+0.3, 醋+0.2
NDArray recipe2 = recipe.add(extra);
System.out.println("加量后的配方:\n" + recipe2.toDebugString());
// 4. 场景3:调整口味(每锅菜独立调整)
System.out.println("\n--- 场景3:个性化调整 ---");
// 青椒肉丝:盐+2, 西红柿鸡蛋:不变, 麻婆豆腐:醋+3
NDArray adjustments = manager.create(new double[][]{
{2, 0, 0}, // 第一锅调整
{0, 0, 0}, // 第二锅不变
{0, 0, 3} // 第三锅调整
});
NDArray recipe3 = recipe.add(adjustments);
System.out.println("个性化调整后:\n" + recipe3.toDebugString());
} catch (Exception e) {
e.printStackTrace();
}
}
}
高级功能
NDArray的转置
转置(Transpose)是将数组的行和列进行交换的操作,把行转为列,把列转为行
假设餐厅有这样一份竖版菜单:
| 菜品 | 价格 | 辣度 |
|---|---|---|
| 麻婆豆腐 | 38 | 5 |
| 宫保鸡丁 | 45 | 3 |
| 鱼香肉丝 | 42 | 2 |
这其实是一个 3行×3列 的矩阵
转置后的菜单(矩阵 Aᵀ):
现在把菜单横过来,变成横版菜单:
| 麻婆豆腐 | 宫保鸡丁 | 鱼香肉丝 | |
|---|---|---|---|
| 菜品 | 麻婆豆腐 | 宫保鸡丁 | 鱼香肉丝 |
| 价格 | 38 | 45 | 42 |
| 辣度 | 5 | 3 | 2 |
转置到底做了什么?
把原来的第 i 行第 j 列的元素,放到新矩阵的第 j 行第 i 列
用大白话说就是:行变列,列变行
import ai.djl.ndarray.NDArray;
import ai.djl.ndarray.NDManager;
import ai.djl.ndarray.types.DataType;
import java.nio.charset.StandardCharsets;
public class NDArrayTransposeExample {
public static void main(String[] args) {
// 创建NDManager管理张量生命周期(DJL核心规范)
try (NDManager manager = NDManager.newBaseManager()) {
// 1. 创建2×3的二维张量
NDArray array = manager.create(new double[][]{{1, 2, 3}, {4, 5, 6}});
System.out.println("原始张量(2行3列):\n" + array);
// 2. 张量转置(等价ND4J的transpose(),DJL 0.34.0 用transpose()方法)
NDArray transposed = array.transpose();
System.out.println("\n转置后张量(3行2列):\n" + transposed);
// 拓展:指定维度转置
// 二维张量转置等价于指定维度(1,0),和transpose()效果一致
NDArray transposedByDim = array.transpose(1, 0);
System.out.println("\n指定维度(1,0)转置结果:\n" + transposedByDim);
} catch (Exception e) {
e.printStackTrace();
}
}
}
结果
原始张量(2行3列):
ND: (2, 3) cpu() float64
[[1., 2., 3.],
[4., 5., 6.],
]
转置后张量(3行2列):
ND: (3, 2) cpu() float64
[[1., 4.],
[2., 5.],
[3., 6.],
]
指定维度(1,0)转置结果:
ND: (3, 2) cpu() float64
[[1., 4.],
[2., 5.],
[3., 6.],
]
NDArray的拼接
拼接(Concatenation)是将多个数组沿指定轴连接在一起的操作。把两个同样大小的矩阵,像拼图一样粘在一起,可以上下拼,也可以左右拼。
import ai.djl.ndarray.NDArray;
import ai.djl.ndarray.NDManager;
public class NDArrayConcatenationExample {
public static void main(String[] args) {
// 创建NDManager管理张量生命周期
try (NDManager manager = NDManager.newBaseManager()) {
// 1. 创建两个2×2的二维张量
NDArray a = manager.create(new double[][]{{1, 2}, {3, 4}});
NDArray b = manager.create(new double[][]{{5, 6}, {7, 8}});
System.out.println("原始张量a(2×2):\n" + a);
System.out.println("原始张量b(2×2):\n" + b);
// 2. 沿行拼接 上下拼
NDArray concatenatedRows = a.concat(b, 0);
System.out.println("\n沿行拼接结果(4×2):\n" + concatenatedRows);
// 3. 沿列拼接 左右拼
NDArray concatenatedCols = a.concat(b, 1);
System.out.println("\n沿列拼接结果(2×4):\n" + concatenatedCols);
} catch (Exception e) {
e.printStackTrace();
}
}
}
结果
原始张量a(2×2):
ND: (2, 2) cpu() float64
[[1., 2.],
[3., 4.],
]
原始张量b(2×2):
ND: (2, 2) cpu() float64
[[5., 6.],
[7., 8.],
]
沿行拼接结果(4×2):
ND: (4, 2) cpu() float64
[[1., 2.],
[3., 4.],
[5., 6.],
[7., 8.],
]
沿列拼接结果(2×4):
ND: (2, 4) cpu() float64
[[1., 2., 5., 6.],
[3., 4., 7., 8.],
]
NDArray的归约操作
归约操作(Reduction Operations)是对数组进行聚合操作,如求和、求平均值、求最大值等。
- 学生1:数学1分,语文2分,英语3分
- 学生2:数学4分,语文5分,英语6分
import ai.djl.ndarray.NDArray;
import ai.djl.ndarray.NDManager;
import ai.djl.ndarray.types.DataType;
import java.nio.charset.StandardCharsets;
public class NDArrayReductionExample {
public static void main(String[] args) {
// 创建NDManager管理张量生命周期(严格遵循源码newBaseManager())
try (NDManager manager = NDManager.newBaseManager()) {
// 1. 创建2×3的二维张量
NDArray array = manager.create(new double[][]{{1, 2, 3}, {4, 5, 6}});
System.out.println("原始张量(2×3):\n" + array);
// 2. 求和
double sum = array.sum().getDouble();
System.out.println("\n所有元素求和:" + sum);
// 3. 求平均值
double mean = array.mean().getDouble();
System.out.println("\n所有元素平均值:" + mean);
// 4. 求最大值
double max = array.max().getDouble();
System.out.println("\n所有元素最大值:" + max);
// 拓展:按维度归约(可选,帮助理解维度级运算)
// 按行求和(dim=1):每行的和
NDArray sumByRow = array.sum(new int[]{1});
System.out.println("\n按行求和:\n" + sumByRow);
// 按列求均值(dim=0):每列的均值
NDArray meanByCol = array.mean(new int[]{0});
System.out.println("\n按列求均值:\n" + meanByCol);
} catch (Exception e) {
e.printStackTrace();
}
}
}
结果
原始张量(2×3):
ND: (2, 3) cpu() float64
[[1., 2., 3.],
[4., 5., 6.],
]
所有元素求和:21.0
所有元素平均值:3.5
所有元素最大值:6.0
按行求和:
ND: (2) cpu() float64
[ 6., 15.]
按列求均值:
ND: (3) cpu() float64
[2.5, 3.5, 4.5]
应用场景
-
电商数据分析
-
神经网络损失计算
-
图像处理

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 10
10 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)