解读AI大模型,从了解token开始
什么是token?最小的语义单元
你可能好奇:大规模语言模型究竟是如何工作的?它们如何从海量数据中习得语言规律?又如何依据输入生成合乎逻辑、语义连贯的文本续写?要回答这些问题,我们需从最基础的概念出发——token(词元)。 在自然语言处理(NLP)中,token 是文本中最小的、具有独立语义或功能的单元。例如,句子“I love you”可被切分为三个 token:“I”“love”“you”。这种切分使文本更易于建模、计算与分析。 但并非所有语言都像英文那样依赖空格分词。中文、日语等语言缺乏显式词边界,因此需借助更精细的分词策略:如基于规则、统计模型或预训练分词器,识别出语义合理的字串组合。以“我爱你”为例,常见切分结果为“我”和“爱你”;不过此类方法仍存在歧义与误差,并非绝对可靠。 此外,标点符号、数字、表情符号等也常被视作 token——它们虽非词汇,却承载重要语气、情感或结构信息。例如,“I love you!” 与 “I love you?” 在语义和语用层面明显区别于中性表达“I love you”,正源于感叹号与问号所传递的不同态度。 简言之,token 是文本中最小的有意义单位,是模型理解与生成语言的基本粒度。不同语言特性与任务需求,往往对应差异化的 tokenization 策略。那么,GPT 系列模型究竟采用何种 token 类型?我们接下来将深入探讨。
GPT系列采用了什么样的token类型?
GPT系列是一系列基于Transformer架构的生成式预训练语言模型,可广泛用于各类文本生成任务。目前已有GPT-2、GPT-3和GPT-4等多个版本,主要差异体现在模型参数量、训练数据规模与质量,以及文本生成能力的强弱上。 GPT系列均采用**子词(subword)分词法**。
子词是介于字符与单词之间的语言单元,其划分依据语料中词汇的频次与共现模式自动学习得出。例如,单词“transformer”可被切分为“trans”+“former”,也可细分为“t”+“rans”+“former”,甚至进一步拆为“t”+“r”+“ans”+“former”等。不同切分策略会生成数量与长度各异的子词:子词越细碎、数量越多,语言覆盖越广,但计算开销相应增大;反之,子词越粗粒、数量越少,虽降低计算负担,却可能损失部分语言细节。 GPT系列具体采用**字节对编码(Byte Pair Encoding, BPE)**作为子词划分算法。BPE源于数据压缩思想,通过迭代合并语料中高频出现的相邻字节对来构建新符号。例如,若“ns”是当前最高频字节对,则将其统一替换为新符号“Z”,从而压缩序列长度。该过程持续进行,直至达到预设的词表大小或无可合并的字节对为止——最终将原始字节流转化为由紧凑子词构成的序列。
例如,“obsessiveness”这个单词可以被BPE转换成以下子词序列:
• 原始字节序列:o b s e s s i v e n e s s
• 第一次合并:o b s e Z i v e n e Z (假设Z代表ss)
• 第二次合并:o b s E i v e n E (假设E代表e Z)
最终子词序列:o b s E i v e n E(如果没达到预设的字节要求,可合并只出现一次的子词)
当然,这只是一个简单的例子,实际上BPE会根据大规模的语料库来生成更多更复杂的子词。GPT系列使用了不同大小的BPE词典来存储所有可能出现的子词。
比如,GPT-3使用了50,257个子词。 总之,GPT系列采用了基于BPE算法的子词作为token类型, 主要目的是以无损的方式压缩文本的内容,从而以保证语言覆盖度和计算效率之间达到一个平衡 。接下来,我们要看看如何用子词来表示和生成文本?
如何用子词来表示和生成文本?
我们已知GPT系列采用子词(subword)作为基本token单位,并通过前述的BPE等算法,将原始文本切分为由子词构成的序列——这一过程即术语中所称的“分词”。 那么,得到子词序列后,是否就能直接用其表示或生成文本了呢?答案是否定的。因为语言模型基于神经网络构建,而神经网络仅能处理数值型数据,无法直接操作文本。因此,还需完成第二步:将子词序列映射为数值向量。 这里需引入两个关键概念:编码(encoding)与解码(decoding)。
编码和解码
将子词序列转换为数值向量的过程称为编码(Encoding),是语言模型处理流程中的第二步。其核心目标是将离散、无序的token映射至连续、有序的向量空间,以便模型高效地进行计算与学习。
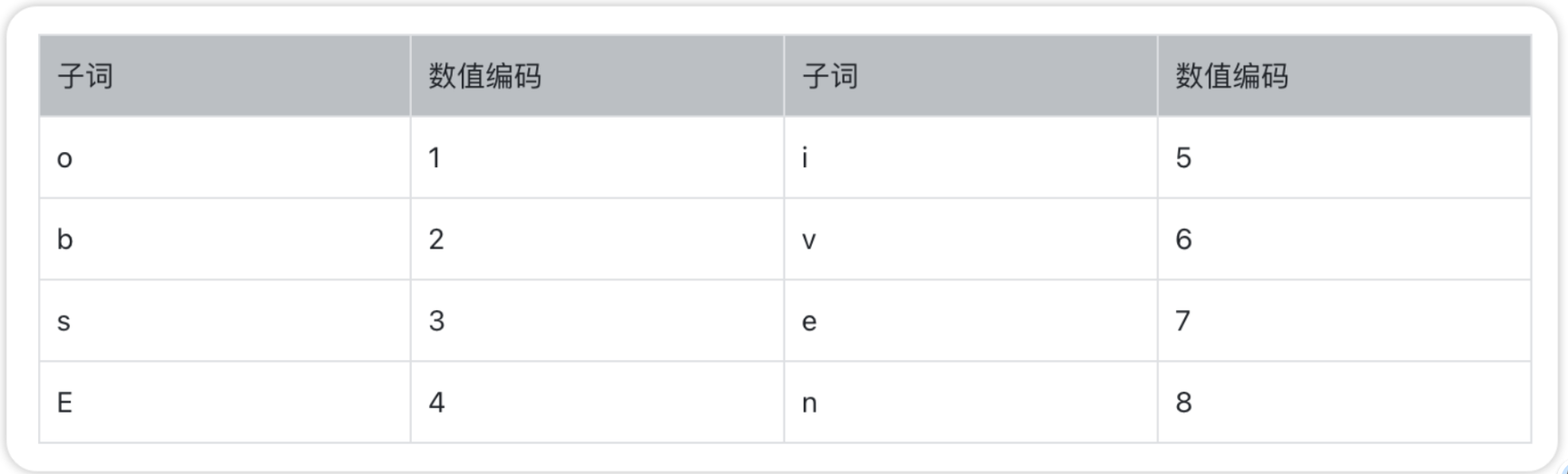
比如,我们可以用以下的BPE词典来表示上面的例子:
BPE(字节对编码)算法的编码和解码规则如下:
编码:先用 BPE 算法把文本拆成最长的匹配子词,再对照 BPE 词典,把每个子词换成对应的数字,最终得到一串数字向量。举个例子,单词obsessiveness就可以被编码成[1, 2, 3, 4, 5, 6, 7, 8, 4]这样的数字序列。
解码:反过来,先对照 BPE 词典把数字还原成对应的子词,再用 BPE 算法把相邻的子词合并成最长的完整单词,最终还原成原始文本。比如刚才那串数字,就能解码回obsessiveness这个单词。
编码和解码实现了文本和子词数字向量的互相转换,但这只是第一步。要让 GPT 这类大模型真正理解、生成文本,还需要两个关键步骤:嵌入(Embedding)和预测(Prediction)
嵌入和预测
我们已知,子词分词与编解码可将文本转化为数字序列,正如我们用数字表示电话号码一样。但这类数字仅是一种符号映射,并不蕴含子词间的语义关联。例如,我们如何判断“猫”与“狗”同属动物类别,而“猫”与“桌子”则在语义上截然不同? 为使GPT系列模型真正理解子词之间的关系,需引入嵌入(embedding)——即为每个子词分配一个稠密的特征向量。该向量能综合反映其语义、语法、语境乃至情感等多维信息。 尽管特征向量的具体计算涉及复杂算法,其核心思想却相对直观:GPT依托海量互联网文本,统计词语在相邻位置、同一句子或篇章中共现的频次与上下文权重,进而量化词语间的语义亲密度,并以此构建表征向量。例如,“猫”常与“动物”“毛发”“鱼”“喵喵声”等词共现,其嵌入向量便自然编码了这些语义线索。 借助嵌入,每个子词被映射为高维空间中的一个点;点与点之间的距离与方向,便直观体现了语义的相似性与差异性——如“猫”与“狗”的向量距离较近(同为常见宠物),而“猫”与“牛”的距离则相对更远。 完成嵌入后,模型即可执行**预测(prediction)**:基于已有文本,估算下一个最可能出现的子词及其概率分布。例如,输入“我家有一只”,模型会赋予“猫”“狗”较高概率,而“桌子”“电视”等则概率极低——这一判断正依赖于嵌入向量间的相似性计算。 嵌入与预测共同实现了文本与数字表征的双向转换。但这仍非终点:要让GPT真正具备创造性,还需最后一步——生成(generation)。
生成与自回归
生成是指根据给定文本生成新文本的过程。生成主要分为两类模式:自回归(autoregressive)和自编码(autoencoding),其中GPT系列模型主要采用自回归模式。
那么,什么是自回归?
可作如下类比: 想象一位画家在创作连环画——每一帧画面都需承接前一帧(甚至前几帧)的情节与构图,才能合理延续故事。同理,自回归模型在每个时间步的输出,都依赖于此前一个或多个时间步的输出结果。这种逐词/逐帧递进、环环相扣的生成方式,使各时间步之间形成强序列依赖,因而特别适用于时间序列预测等任务。
例如,“I love you”这个句子可以被GPT系列生成为以下的文本: • I love you more than anything in the world. • I love you and I miss you so much. • I love you, but I can't be with you. 总之,GPT系列使用了子词、数值向量、实数向量和Transformer模型来表示和生成文本。通过编码、解码、嵌入、预测和生成等步骤,它可以实现从文本到文本的转换

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)