MIA虚拟染色新作: 面向虚拟免疫组化染色的病理感知薛定谔桥
PASB:面向虚拟免疫组化染色的病理感知薛定谔桥
摘要
虚拟免疫组化(IHC)染色利用深度生成模型将苏木精-伊红(H&E)图像自动转换为 IHC 图像,从而实现 IHC 染色流程的自动化。弱监督虚拟 IHC 染色方法利用相邻组织切片提供的引导信号,无需精确配准,已成为该领域的主流范式之一。然而,这类方法仍面临两个主要挑战:(i)往往难以提取具有临床意义的病理语义,依赖低层特征,无法保证病理一致性;(ii)现有生成框架难以刻画组织病理数据复杂且异质的分布特性,从而导致模式崩塌以及关键诊断结构的丢失。为解决这些问题,我们提出一种新的弱监督方法,称为 Pathology-Aware Schrödinger Bridge(PASB)。具体而言,我们采用薛定谔桥作为生成骨干,在避免固定先验假设的同时保留生成多样性并减轻模式崩塌。此外,我们引入约束驱动对齐学习(CDAL)模块,以提供高层语义监督,并设计基于相似性的动态路径细化(SDPR)模块,以增强生成过程中的病理一致性。大量实验表明,所提出的 PASB 在生成质量和病理一致性方面均优于现有方法,生成的 IHC 图像在下游诊断任务中展现出可与真实 IHC 相媲美的临床潜力。
关键词:虚拟染色,薛定谔桥,组织病理图像,免疫组化
1. 引言
免疫组化(IHC)染色通过定位蛋白表达,为肿瘤精准分型和治疗决策提供关键信息(Hua et al., 2024)。然而,在临床实践中,传统手工染色常常受限于繁琐的操作流程、较长的时间消耗以及较高的试剂成本(Cimino-Mathews, 2021)。为解决这一问题,虚拟免疫组化染色利用深度生成模型,将易于获得的苏木精-伊红(H&E)图像自动转换为对应的 IHC 图像(Bai et al., 2023; Latonen et al., 2024; Kataria et al., 2024)。虚拟 IHC 染色的核心挑战不仅在于染色风格迁移,还在于确保图像到图像转换过程中的病理保真性。这要求机器学习模型学习到语义准确的生物标志物映射关系,因为错误映射可能导致严重的临床误判。
现有虚拟 IHC 染色技术大体可分为三类:监督方法、无监督方法和弱监督方法。为了实现较高的病理保真性,监督方法试图利用完美对齐的 H&E-IHC 图像对学习像素到像素的映射,但由于组织处理过程的限制,这类完美对齐图像往往难以获得(Peng et al., 2024; Dubey et al., 2025)。无监督方法则绕开了对齐数据的需求,具有更高的灵活性,但由于缺乏显式监督,其生物学合理性往往难以保证(Zhu et al., 2017; Park et al., 2020; Li et al., 2024a)。相比之下,弱监督方法利用粗对齐的相邻连续切片提供引导信号,在避免监督方法严格配准要求的同时,保留了无监督方法所缺乏的重要病理信息(Huang et al., 2022; Chen et al., 2024; Wang et al., 2025)。例如,Li et al. (2023b) 首先计算生成 IHC 图像与相邻切片参考图像之间的余弦相似度,并将其作为优化信号以强化病理一致性。Wang et al. (2025) 则采用正交解耦对齐策略,对生成 IHC 图像与相邻切片之间与染色相关的特征进行对齐,从而提升病理一致性与真实性。
尽管虚拟 IHC 染色具有广泛的临床应用前景,现有弱监督方法在语义引导和生成建模两方面仍存在根本性局限。首先,这些方法通常难以提取具有临床意义的病理语义。尽管相邻连续切片能够提供有价值的监督信息,许多方法仍仅使用低层相似性信号,如余弦距离(Li et al., 2023b)和 patch 级对比学习目标(Wang et al., 2024a),作为病理对齐的替代指标。这种病理对齐方式仍然容易受到空间错位和临床语义鸿沟的影响。其次,现有虚拟 IHC 染色生成框架难以刻画组织病理数据复杂且异质的分布特征。例如,生成对抗网络(GAN)常常遭受模式崩塌,无法充分表示病理特征的多样性;同时,其训练不稳定性还会引入具有误导性的临床伪影(Goodfellow et al., 2020; Shen and Ke, 2023)。扩散模型被视为 GAN 的一种替代方案,但其高斯先验使其难以准确建模非完美配对的 H&E 与 IHC 图像之间的转换,从而导致关键诊断结构的丢失(Ho et al., 2020; Song et al., 2020; He et al., 2024)。这些问题共同限制了虚拟 IHC 染色的保真度与临床可靠性。
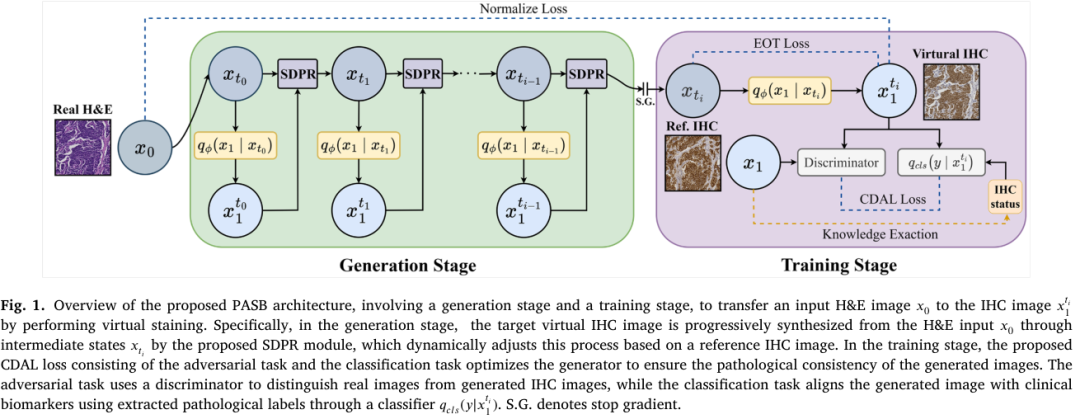
Fig
为了解决上述问题,我们提出一种新的弱监督方法,即病理感知薛定谔桥(PASB),如图 1 所示。首先,我们将薛定谔桥(Kim et al., 2024b)作为虚拟 IHC 染色的原理性骨干,用于直接刻画组织病理数据复杂且异质的本质。与假设固定高斯先验的扩散模型不同,薛定谔桥将图像翻译建模为两个边缘分布之间的随机输运过程。该灵活框架更适用于组织病理数据异质、非高斯的特性,并允许在输运路径中注入噪声,从而保留生成多样性并减轻模式崩塌(Shen and Ke, 2023)。其次,我们设计约束驱动对齐学习(CDAL)模块,将生成过程引导至具有临床意义的语义空间。具体来说,CDAL 首先从相邻 IHC 图像(即参考图像)中抽取高层免疫相关语义,并将其作为薛定谔桥端点处的软约束。这保证了生成的虚拟 IHC 图像能够体现超越表面相似性的诊断线索。此外,我们引入基于相似性的动态路径细化(SDPR)机制,以增强轨迹一致性。即,SDPR 利用生成 IHC 图像与参考图像之间的相似性,动态调整输运路径上的中间状态。因此,CDAL 与 SDPR 的结合使 PASB 能够生成高质量且具有病理一致性的虚拟 IHC 图像。本文的主要贡献如下:
-
1. 我们提出 PASB 框架,在弱监督条件下有效注入高层病理语义,并在不依赖固定先验假设的情况下建模 H&E 域与 IHC 域之间的转换,同时保留生成多样性,从而缓解训练中的模式崩塌问题。
-
2. 我们设计 CDAL,从相邻 IHC 图像中提供高层语义监督,并设计 SDPR 以增强输运过程中的病理一致性。二者协同作用,使 PASB 能够生成具有病理意义且结构保真的 IHC 预测结果。
-
3. 大量实验表明,我们的方法在生成质量和病理一致性方面均优于基线模型,生成的虚拟 IHC 图像在下游诊断任务中可与真实 IHC 图像相媲美,展现出较强的临床应用潜力。
2. 相关工作
2.1. 虚拟免疫组化染色
现有虚拟 IHC 方法通常可分为三类:监督方法、无监督方法和弱监督方法。这些方法在 H&E 与 IHC 图像对之间的对齐程度上有所不同。监督方法旨在通过完美对齐的 H&E-IHC 图像对学习像素级映射,以实现较高的病理保真性。然而,由于组织处理过程的限制,获取此类对齐图像往往十分困难。在同一组织切片上进行多次染色通常不可行;即使采用相邻连续切片,固有的形变和生物学差异也会使像素级配准变得十分困难(Huang et al., 2022; Peng et al., 2024)。例如 PyramidP2P(Liu et al., 2022a)这类方法依赖复杂的预处理流程,包括弹性配准和重采样,这可能引入配准误差并限制其泛化能力。类似地,使用荧光成像辅助对齐的方法需要昂贵的多模态成像系统,增加了技术和经济成本(de Haan et al., 2021)。
相比之下,无监督方法通过绕开精确对齐图像对的需求,具有更高的灵活性。诸如 CycleGAN 和 CUT(Li et al., 2023b; Bai et al., 2023; Li et al., 2024b)等方法使用风格迁移来生成 IHC 图像,而不依赖严格对齐。然而,这类方法通常难以保证生物学合理性,因为它们缺乏对生物标志物表达的显式监督,因而生成图像可能无法准确反映组织病理空间模式。近期一些方法尝试通过引入辅助监督策略来改进这一问题,例如潜在特征提取(Boyd et al., 2022)和预训练细胞分类器(Pati et al., 2024),但其性能仍高度依赖这些辅助网络的准确性,以及病理专家的大量人工参与。
为克服监督方法与无监督方法的局限,弱监督方法利用粗对齐相邻组织切片提供的引导信号。这种方法在无需严格配准的同时,仍然能够利用无监督方法所缺乏的重要病理信息。这种生物学一致性使得研究者可以使用区域级约束的粗对齐 H&E-IHC 图像对,在放宽严格对齐要求的同时保留关键生物标志物模式(Li et al., 2023b; Chen et al., 2024; Wang et al., 2024b)。与其他方法相比,这一策略避免了复杂的像素级配准,也降低了对专家标注的依赖。我们提出的方法正是建立在这一范式之上,利用相邻切片对提取组织病理引导信息,以构建无需像素级精确对齐的薛定谔桥。
2.2. 薛定谔桥的应用
薛定谔桥(SB)问题因其在随机过程控制中的独特优势而受到广泛关注(Shi et al., 2022; Tong et al., 2023)。从数学上看,SB 的目标是在给定参考测度约束下,寻找一个连接两个给定概率分布的随机过程。从算法角度看,De Bortoli et al. (2021) 将迭代比例拟合算法与基于 score 的扩散模型统一起来;Vargas et al. (2021) 则提出了一种基于高斯过程的近似解法。Pavon and Trigila (2021) 进一步推进了该领域的发展,他们用约束最大似然估计替代非线性边界耦合,并通过重要性采样求解薛定谔系统。
在图像翻译领域,Liu et al. (2023) 通过 I2SB 模型展示了 SB 的实际有效性,该模型能够利用配对数据成功处理多模态视觉任务。Shi et al. (2022) 将 Markov 投影和 Markov 测度理论引入 SB,拓展了其适用范围,克服了配对数据集的限制。尤其是,Kim et al. (2024a) 首次提出了一种基于对抗学习的 SB 问题分解方法,使得高分辨率图像翻译成为可能。受这些工作的启发,我们探索基于 SB 模型在虚拟染色任务中的潜力,从而拓展生成模型在生物医学图像处理中的应用边界。
3. 方法
3.1. 动机
由于临床实践中相邻组织切片数据较为容易获得,利用相邻切片的弱监督学习范式已成为虚拟 IHC 染色的主流方法。然而,现有方法在捕获具有临床意义的病理语义方面仍存在困难。基于配准的像素级监督会因切片间固有的组织差异而引入误差(Liu et al., 2022a; Huang et al., 2022);而基础相似性度量则常常难以充分保留准确虚拟染色所需的复杂病理一致性(Liu et al., 2021; Li et al., 2023b; Ma et al., 2024)。这些引导策略通常缺乏与临床诊断标准的直接联系,从而削弱了生成图像的临床保真性和可解释性。

Fig
此外,在生成模型的选择上,现有方法仍难以刻画组织病理数据复杂且高度异质的特性。GAN 类方法容易发生模式崩塌、训练不稳定以及伪影生成(Goodfellow et al., 2020; Shen and Ke, 2023),如图 2(a) 所示。在复杂的病理图像生成任务中,这往往会导致模型只学习到有限的染色风格,丢失多样而真实的生物标志物表达模式,甚至生成具有误导性的伪影。为此,许多虚拟染色研究转向去噪扩散概率模型(DDPM)(Ho et al., 2020; Song et al., 2020; He et al., 2024)。然而,其标准高斯先验假设与病理图像高度异质且未严格对齐的数据分布并不匹配,往往导致关键结构信息的丢失。Shen and Ke (2023)、He et al. (2024) 采用双扩散链(图 2(b))来缓解这些问题,但其计算复杂度限制了临床应用。
基于上述分析,我们提出的 PASB 框架(如图 1 所示)旨在系统性地解决这两大挑战。首先,我们引入神经薛定谔桥(SB)(图 2©)作为稳定且灵活的生成骨干(第 3.2 节)。在此基础上,我们设计了一个双组件系统:约束驱动对齐学习(第 3.3 节)提供高层病理引导以确保临床保真性,而基于相似性的动态路径细化(第 3.4 节)则通过动态细化输运路径来增强结构一致性。
3.2. 薛定谔桥
如前所述,GAN 的训练不稳定性以及 DDPM 的分布假设不匹配,使其难以胜任高保真病理图像生成任务。因此,理想的虚拟染色框架需要一种既训练稳定、又能灵活建模复杂数据分布的生成模型。为此,我们将神经薛定谔桥(SB)引入为 PASB 的生成骨干。基本定义:SB 问题旨在寻找最可能的随机过程 ,使其将初始概率分布 转换为终止概率分布 。形式上,在路径空间 上,该问题即寻找一个概率测度 ,使其在满足端点边缘约束的条件下,相对于参考 Wiener 测度 的 Kullback-Leibler(KL)散度最小:
解 表示:为满足边界条件而对参考过程施加的最小扰动。静态形式与自相似性:直接在路径测度上优化是十分困难的。幸运的是,SB 问题具有静态形式,并与熵正则化最优传输(EOT)紧密相关,同时还具备关键的自相似性质。对于任意子区间 ,边缘分布 与 之间的 SB 耦合 可以表示为如下 EOT 问题的解(Kim et al., 2024a):
其中,第一项是二次型最优传输的标准目标;第二项表示熵正则项。因子 反映了随时间变化的方差,而系数 2 则来源于参考过程高斯核的标准推导结果。此外,对于任意中间时刻 ,中间状态 在给定端点条件下服从条件高斯分布:
其中 , 为温度参数。该性质为从 SB 路径中采样提供了有效方法。优化目标:为了使 SB 问题在训练中可处理,一个主流思路是将其重构为一系列对抗学习任务(Kim et al., 2024a)。我们参数化一个时间条件生成器 ,用于逼近真实转移核 。对于给定时刻 ,学习过程被表述为最小化如下 SB 代价的优化问题:
关键在于,该优化必须受到约束,以保证生成样本的终止分布与目标分布 一致。这一边界约束通过最小化 KL 散度实现,实际中则通过对抗损失近似实现:
其中, 为生成的边缘分布。KL 散度通过判别器构成的对抗学习框架进行估计。与传统 GAN 中对抗目标作为唯一训练驱动力不同,在这里它仅作为辅助约束,用于保证主 EOT 目标满足边界条件,从而维持整体训练稳定性。
由于真实的中间分布 未知,我们通过递归模拟来对其进行近似。从 出发,中间状态通过迭代方式生成,其中从 到 的转移定义为:
这一期望可通过如下方式计算:首先根据当前状态 预测目标 ,再根据式(3)采样得到 。
3.3. 约束驱动对齐学习
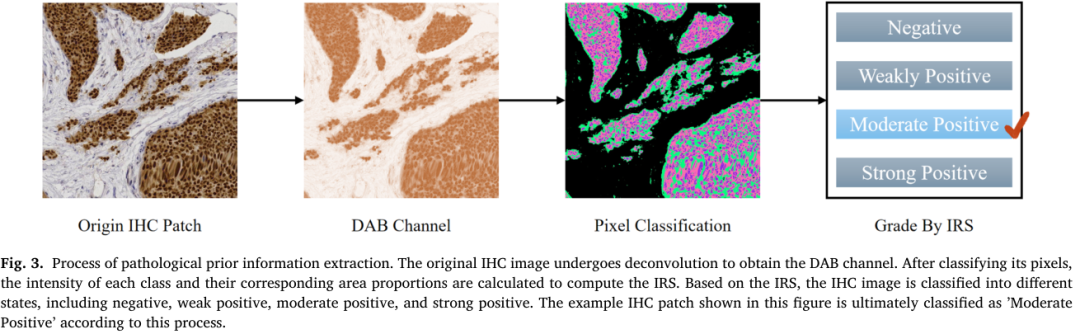
Fig
现有引导策略,如像素级监督或简单相似性约束,缺乏高层语义信息,因此难以保证生成图像在临床解释层面上的一致性。为实现更高维度、也更接近临床诊断层面的引导,我们设计了约束驱动对齐学习(CDAL)模块。CDAL 的核心思想并非直接约束像素,而是约束生成图像中所蕴含的临床病理解读信息。病理先验提取:为实现这一思想,我们利用 IHC 临床评估中广泛使用的免疫反应评分(IRS)体系(Specht et al., 2015),如图 3 所示。对于每幅 H&E 图像,其对应的相邻 IHC 切片作为参考图像。为了从该参考图像中提取高层病理先验,我们首先利用 QuPath 软件(Bankhead et al., 2017)进行颜色去卷积,分离出 DAB 通道。随后,我们使用 Otsu 方法基于每幅图像的直方图自动确定阳性区域阈值,以区分染色和未染色像素。在此基础上,我们计算面积占比和强度等级,并赋予对应的 IRS 分数。由于 H&E 与 IHC 图像对大体对齐,我们采用基于分类的引导策略,而非对 IRS 分数进行直接回归(Fedchenko and Reifenrath, 2014)。依据临床标准,训练样本根据 IRS 分数被划分为四类表达水平:阴性、弱阳性、中阳性和强阳性。与精确回归值相比,这种较粗粒度的病理类别划分提供了更加稳定的语义约束,并天然具有对轻微染色差异的鲁棒性。损失函数:在虚拟免疫组化染色任务中,我们将 H&E 图像 到 IHC 图像 的转换建模为一个条件 SB 问题。二者共享病理先验信息 ,该先验通过 IRS 系统提取,用于编码抗原表达水平。因此,核心目标是学习一条与共享上下文 保持一致的最优输运路径。受近期条件 SB 理论进展的启发(Shi et al., 2022; Garg et al., 2024),我们通过显式将先验 引入学习过程,构造出刻画图像及其病理标签联合分布的复合目标函数:
其中, 表示真实标签分布,表示预测标签分布。该目标施加了两个约束:(1)生成分布匹配,即通过式(5)中的对抗学习使逼近真实 IHC 分布;(2)标签对齐,即约束预测分布与真实病理评分保持一致。为实现这一点,我们首先在真实数据上训练一个分类器以逼近。对于生成样本,我们计算预测标签分布,并通过交叉熵近似 KL 散度:
该项保证生成图像的 DAB 染色强度分布与病理先验 一致,从而提升病理可解释性。最终的训练目标综合了 CDAL 损失、熵正则化最优传输损失以及正则项损失(Kim et al., 2024a):
其中, 和 用于平衡各损失项。
3.4. 基于相似性的动态路径细化
通过以动态方法替代静态形式,我们的模型能够更好地利用最优传输理论来适应数据中的病理差异和实验差异。这一修改使 SB 框架完全依赖于底层数据分布来生成更加真实的结果。然而,即使进行了这种改进,生成的 IHC 图像仍可能因切片间轻微对位偏差而与 H&E 图像产生生物学不一致。为此,我们提出一种动态路径校正方法。该方法在提升生成质量的同时,确保 H&E 与 IHC 图像之间的生物语义得到更好的对齐。用于路径校正的相似性度量定义如下:
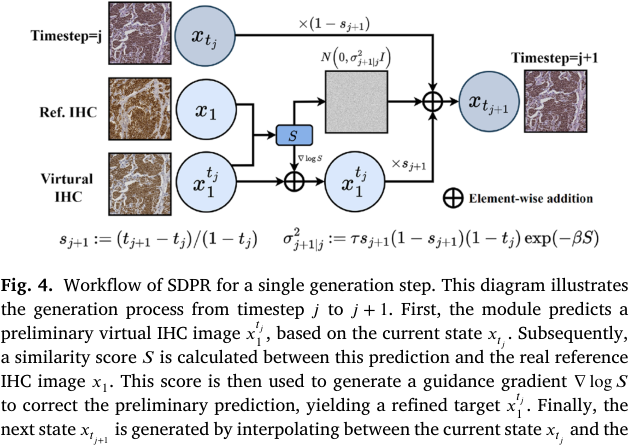
Fig
结合上述思想,我们将 SDPR 的单步更新表述为一个统一、受控的离散化随机微分方程(SDE)步骤,如图 4 所示。假设当前时刻为 ,状态为 ,目标是生成 。我们首先利用生成网络根据当前状态 预测一个初始目标图像:
随后,计算生成图像 与参考图像 之间的相似性:
其中, 表示 范数, 与 分别表示均值和方差。在 SB 框架中,路径值依据如下方程计算,我们在其中引入扰动幅度控制项。
接着,根据该相似性计算引导修正项:
其中, 控制修正强度。该修正项可以理解为对预测目标 的调整,以获得结构上一致性更高的修正目标 。随后,我们使用高斯桥插值公式,将原始预测替换为修正后的目标 ,并注入自适应噪声以生成下一状态 :
其中,, 为噪声调制的缩放因子。
该更新步骤的具体设计包含两个关键机制,以避免模型过拟合参考图像。首先,式(12)中的梯度引导属于软约束,因为其来源于基于统计矩(均值和方差)的相似性度量,而非直接的像素级比较。其次,式(14)中的自适应噪声充当动态正则项,其方差与相似性分数成反比调制,用于在路径探索与结构保真性之间取得平衡。二者共同保证 SDPR 在提供稳健引导的同时,仍能保持生成多样性。
3.5. 训练与推理

Algorithm 1 Generation stage with SDPR
训练:在 PASB 的训练过程中,我们首先随机选取一个时间步 进行优化。为了计算复合损失,我们采样一个中间状态、一个参考 IHC 图像以及其对应的病理先验。的生成过程将在下文详细说明。采样得到的状态随后输入生成器,得到虚拟 IHC 预测结果。该预测结果将被用于计算损失函数的三个组成部分。EOT 损失由样本对计算得到。对于对抗损失,参考图像与生成图像分别作为判别器的“真实”输入和“伪造”输入。对于 CDAL 损失,分类器会对进行评估,以约束其与病理先验保持一致。生成与采样:下面我们介绍中间状态的采样过程。如算法 1 所示,我们从源 H&E 图像出发,模拟一个 Markov 链。对于任意状态(其中),我们首先利用预测一个初始目标图像。随后,利用参考 IHC 图像所导出的引导梯度,使用 SDPR 对该目标进行细化。然后,我们通过在当前状态与细化目标之间进行插值并加入自适应噪声,采样得到下一状态。重复上述过程次,即可获得所需的中间状态。这一过程也体现在模型结构中的生成阶段。
4. 实验与结果
我们对提出的 PASB 框架进行了全面评估。首先,我们在 BCI 数据集上通过比较实验和消融实验,对其核心性能及关键组成模块进行了分析。随后,我们在 MIST 数据集上评估了该方法在多种染色模态下的泛化能力,以及其扩展到整张全视野切片图像(WSI)的能力。最后,我们在 SLN 数据集上的下游肿瘤分类任务中验证了其临床实用性,并借助 HyReCo 数据集对评估指标进行了进一步分析。
4.1. 实验设置
4.1.1. 数据集
BCI(Liu et al., 2022a):包含 4870 对 H&E-HER2 图像 patch,来自 51 张 WSI,扫描分辨率为 0.46 𝜇m/pixel。该数据集支持乳腺癌诊断和图像翻译研究。此外,我们还对 BCI 数据集中的图像进行了亮度归一化。MIST(Li et al., 2023b):包括 4642 对 H&E-HER2、4361 对 H&E-Ki67、4153 对 H&E-ER 和 4139 对 H&E-PR 图像 patch,每种染色类型均有 1000 对样本用于测试。所有图像均来自 20× 放大倍率(0.4661 𝜇m/pixel)的 WSI,尺寸为 1024×1024 像素。HyReCo(van der Laak et al., 2021):该数据集由 Radboud University Medical Center 收集,包括九组连续切片,染色类型包括 H&E、CD8、CD45 和 Ki67。此外,PHH3 切片是通过对原始 H&E 切片进行脱色后重新染色得到的。ANHIR(Borovec et al., 2020):包含来自相邻组织切片的高分辨率乳腺组织 WSI(最高 40×),染色类型为 H&E 与 IHC(ER、PR、Her2)。图像以 10× 放大倍率(2.294 𝜇m/pixel)扫描。SLN(Campanella et al., 2019):包含来自 78 名患者的 130 张腋窝淋巴结 H&E 染色 WSI,其中 36 张切片显示乳腺癌转移。所有切片均以 20× 放大倍率(0.5 𝜇m/pixel)扫描,并依据病理报告进行了标注。
4.1.2. 评估指标
鉴于虚拟免疫组化染色同时要求跨模态纹理映射与病理特征保留,本文构建了一个包含三个维度的综合评估框架:图像质量、形态一致性以及临床相关性。生成图像质量:我们采用 Fréchet Inception Distance(FID)与 Kernel Inception Distance(KID)评估生成 IHC 图像与真实 IHC 图像之间的分布相似性。这两个指标都衡量特征空间中的对齐程度,数值越低表示匹配越好(Jayasumana et al., 2024)。为便于阅读,我们在表格中将所有 KID 数值统一乘以 100。
形态一致性:尽管相邻切片之间的空间错位可能导致像素级偏差,我们仍参考主流方法的评估流程(Zhang et al., 2022; Li et al., 2023b; Pati et al., 2024),引入结构相似性指数(SSIM)与直方图相关性(HC)作为辅助评估指标。SSIM 用于度量亮度、对比度和结构相似性;HC 用于衡量颜色匹配程度,数值越高表示一致性越好。临床诊断相关性:为了补充现有评估指标,我们进一步引入两个病理导向指标:H-Score(HS)(Debaugnies et al., 2016),其综合考虑染色强度和阳性细胞比例;以及积分光密度(IOD)(Rizzatti et al., 2013),其表示染色区域的光密度积分。我们并不直接报告这些原始分数,而是用它们衡量生成 IHC 图像与真实参考图像之间的误差。具体而言,HS 指标定义为二者 H-Score 之间的绝对差值;IOD 指标定义为二者自然对数值之间的绝对差值。对于这两个指标,差值越小表示对生物标志物表达的重现越准确,也意味着更高的病理保真性。
4.1.3. 实现细节
我们的模型在 512×512 像素 patch 上进行训练,不同数据集采用不同的预处理方式。对于 BCI 和 MIST 这类 patch 级数据集,我们从更大尺寸的图像对中随机裁剪 512×512 的 patch 对,以保证覆盖范围的多样性。对于 WSI 级数据集,我们采用了不同策略。对于 HyReCo 数据集,我们首先进行图像配准,并从组织区域中为每种染色类型提取 10,000∼12,000 对无重叠的 512×512 patch。对于 10× 放大倍率的 ANHIR 数据集,我们采用 25% 重叠的裁剪策略以生成足够的数据量,最终得到 3,228 对 512×512 patch。我们设置 batchsize = 1,并使用初始学习率为 0.0001 的 Adam 优化器进行训练。时间域离散步数设置为 ,。对于 SDPR,我们将式(12)中的梯度修正强度系数 设为 0.1,将式(14)中的初始噪声衰减系数 设为 1。式(9)中的 与 均设为 1。所有实验均基于 PyTorch 框架,在 NVIDIA A100 GPU 上完成。
4.2. BCI 数据集上的结果
4.2.1. 染色性能比较
我们在 BCI 提供的 ROI 测试集上进行了定量比较。需要指出的是,尽管我们出于完整性报告了像素级指标,但真实图像来自相邻切片。在病理染色迁移任务中,核心目标是在病理特征和结构细节层面保证生成图像与真实 IHC 图像的高度一致性。为评估 PASB 的性能,我们在 BCI 数据集上将其与多种最先进的图像翻译方法进行了系统比较。这些方法包括 CycleGAN(Zhu et al., 2017)、PyramidPix2Pix(Liu et al., 2022a)、CUT(Park et al., 2020)、EnCo(Lippe et al., 2021)、ASP(Li et al., 2023b)、BBDM(Li et al., 2023a)、PSPStain(Chen et al., 2024)以及 UNSB(Kim et al., 2024a)。其中,CycleGAN、CUT 和 EnCo 属于无监督方法;PyramidPix2Pix 和 BBDM 需要配对数据训练;ASP 和 PSPStain 使用相邻切片数据训练;UNSB 则作为对比基线。
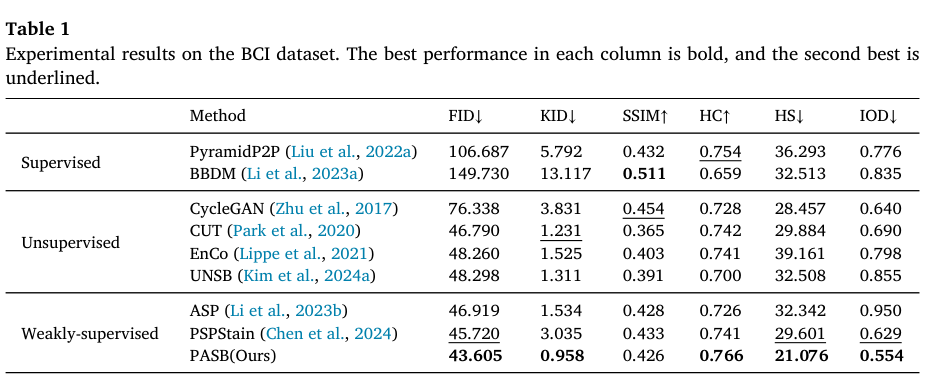
Table 1
如表 1 所示,PASB 在生成图像质量方面表现最优,在所有比较方法中取得了最佳的 FID(43.605)和 KID(0.958)分数。这种视觉保真度的提升源于 PASB 的动态路径优化,它通过引入生物相似性函数来校正路径偏移。在形态一致性方面,PASB 在 SSIM 上略低于 PSPStain 与 ASP,但在 HC 上优于二者。这揭示了像素级对齐与染色准确性之间的权衡:PSPStain 与 ASP 更偏重像素级结构对齐,但会以牺牲 DAB 染色特性为代价;而 PASB 借助最优传输与标签分布对齐(式(7)),在无需严格结构对齐的情况下获得更好的综合一致性。在临床诊断相关性方面,PASB 以 HS = 21.076 和 IOD = 0.554 取得最佳结果。该优势归因于其标签分布对齐机制,它能够保证生成图像的病理分布与真实 IRS 评分体系一致。特别是,尽管 UNSB 在 FID 上具有竞争力,但由于缺乏病理先验约束,其在 HS 和 IOD 上表现较差。
Fig
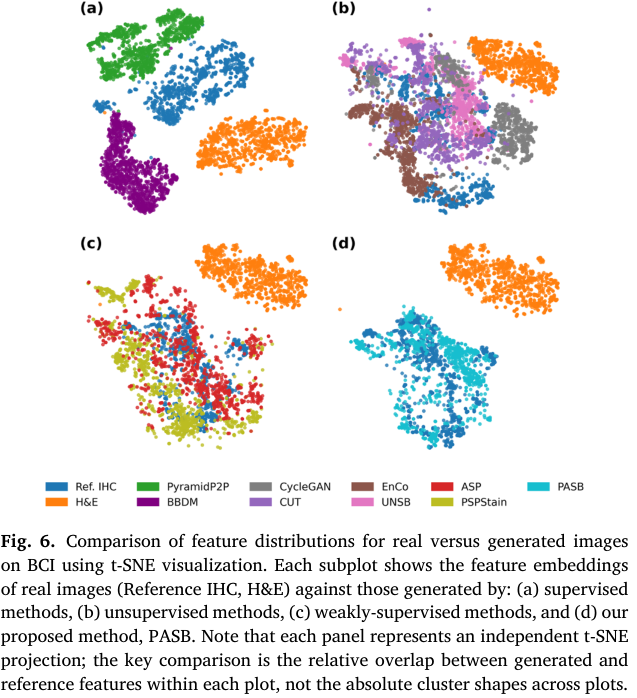
此外,我们对不同学习范式下训练得到的模型特征分布进行了 t-SNE 可视化,如图 6 所示。监督方法(图 6(a))由于受到切片间空间错位带来的错误监督影响,其特征分布与真实 IHC 图像偏差较大。无监督方法(图 6(b))完全由数据驱动,虽有部分重叠,但整体上仍与参考分布较为分散。利用相邻切片的弱监督 GAN 方法(图 6©)虽然表现出更好的重叠程度,但与真实分布的对齐程度仍不及 PASB,这进一步说明了我们基于 SB 的建模方式的优势。
4.2.2. HER2 分级与模型复杂度
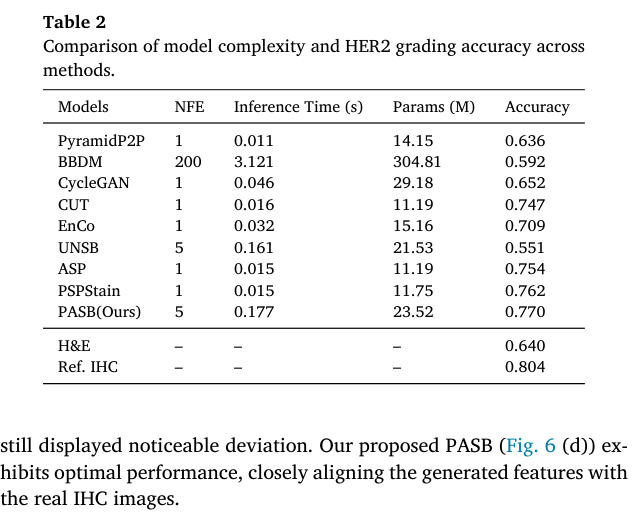
Table 2 Comparison of model complexity and HER2 grading accuracy across methods
我们通过比较计算开销(FLOPs 和参数量)评估模型复杂度,并在 BCI 数据集上设计了 HER2 分级任务,以评估模型的临床实用性。在该实验中,我们使用不同方法生成的 IHC 图像,对预训练于 ImageNet-1k 的 ConvNeXt-T 模型(Liu et al., 2022b)进行微调。评估的关键标准是:生成图像是否保留了对应目标图像的 HER2 分级。如表 2 所示,PASB 在效率与准确率之间取得了良好平衡。其迭代特性需要 5 次函数评估(NFE),从而带来中等计算代价,但仍能提供较高的分级准确率。
4.2.3. 消融实验

Table 3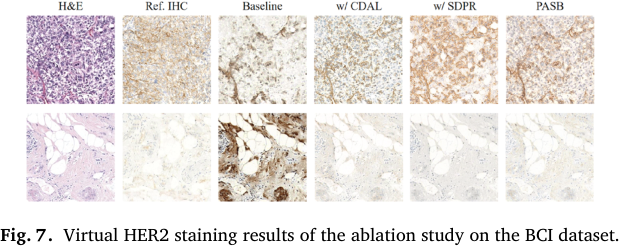
Fig
表 3 和图 7 系统评估了 PASB 关键组件的作用。基线模型在各项指标上表现较差。引入 CDAL 模块后,基于分布的指标(FID/KID)获得显著提升,这表明其通过病理约束提供的全局引导有效增强了生成分布的真实性。相比之下,SDPR 模块主要提升单幅图像层面的病理导向指标(HS/IOD),因为它提供了局部、实例级的结构引导,能够直接细化每一幅图像的生物标志物表达。完整 PASB 框架取得的最优性能说明,CDAL 与 SDPR 发挥了互补作用:CDAL 保证全局分布真实性,SDPR 保证局部实例保真性,从而使 PASB 能够同时维持结构保真和染色准确性。
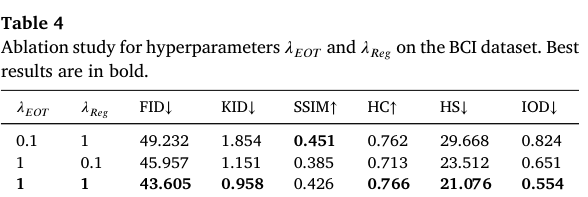
Table 4
为了研究式(9)中超参数 与 对模型性能的影响,我们评估了三组关键权重设置。
4.2.4. 最优 NFE 讨论
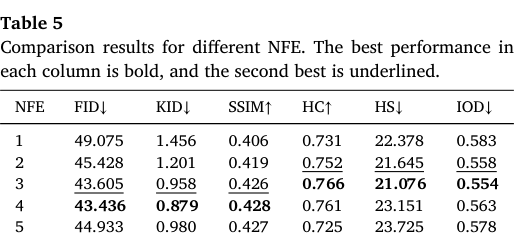
Table 5
我们系统评估了不同函数评估次数(NFE)设置下的虚拟染色性能。表 5 表明,NFE = 3 在图像质量和生物保真性之间取得了最佳平衡。该设置下,FID(43.605)与 KID(0.958)显著低于其他设置,说明其与真实 IHC 图像的对齐程度更高。尽管当 NFE = 4 时 FID 和 KID 还会进一步改善,但 HS 与 IOD 指标反而变差,说明关键生物标志物细节出现损失。这些结果表明,NFE = 3 在图像质量、结构保真性与生物学相关性之间实现了最佳折中,避免了过拟合导致的病理特征丢失。
4.3. MIST 数据集上的结果
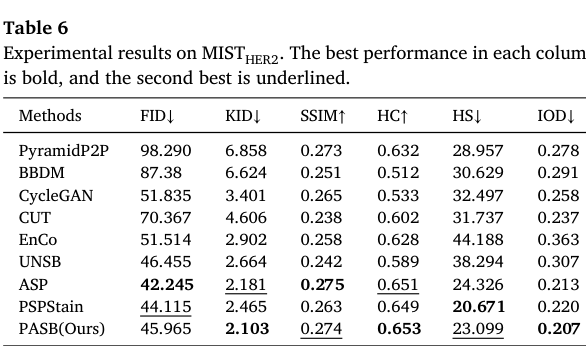
Table 6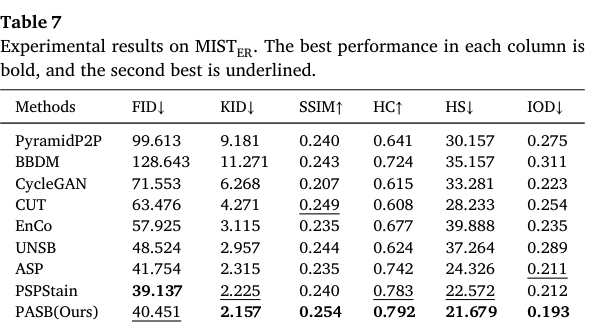
Table 7 Experimental results on MISTER
为了验证模型的泛化能力,我们将 PASB 应用于 MIST 的不同子集。表 6 给出了在 MISTHER2 子集上的结果,PASB 通过取得最佳 KID(2.103)和最佳 IOD(0.207),展现出很强的竞争力。尽管其 FID 不是绝对最低,但整体结果表明其与真实图像具有较强的一致性。进一步在 MISTER 子集上的验证结果表明,PASB 能够处理不同染色模态,如表 7 所示。即使在染色类型发生变化的情况下,PASB 在 KID、SSIM、HC、HS 和 IOD 等指标上仍取得最佳表现,说明其在跨模态染色迁移中的适应性很强。这些结果共同验证了 PASB 的鲁棒性与泛化能力,使其成为面向多种数据集和染色类型的有效虚拟染色方案,并具有潜在的临床应用价值。
4.4. 从 patch 到 WSI
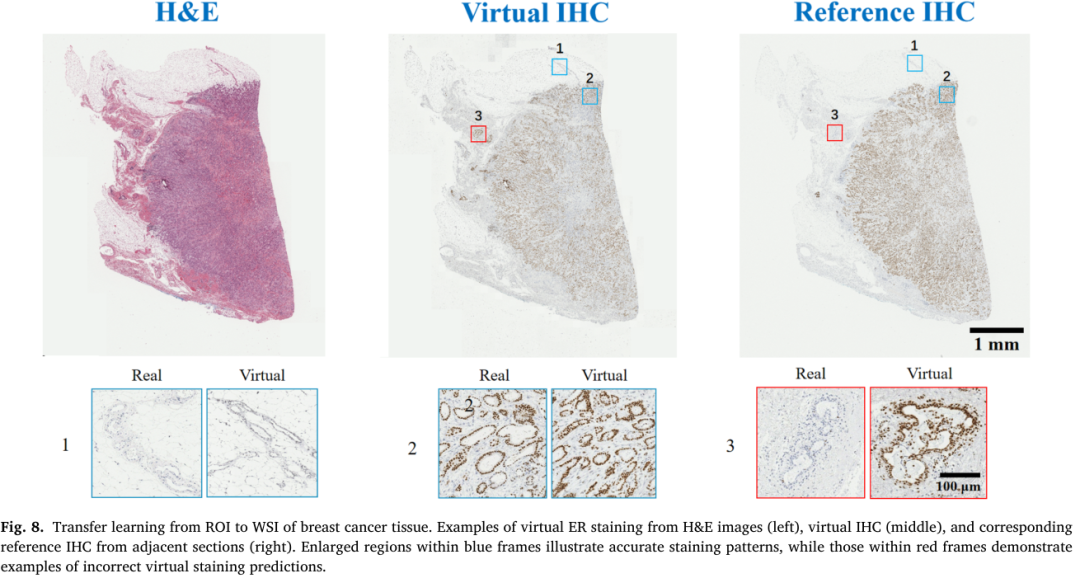
Fig
鉴于全视野切片图像(WSI)已成为数字病理实践中的标准数据形式,我们在 ANHIR 乳腺组织数据集上重新训练 PASB,以实现从 H&E 到 ER 染色的系统级可视化转换。完整 WSI 通过 patch 生成与后续拼接获得,如图 8 所示。在图 8 的示例 1 中,PASB 在非目标区域(如血管和间质)呈现出干净的背景信号,与真实 IHC 染色一致。在示例 2 中,虚拟染色能够准确勾勒肿瘤细胞边界,并保留弱 ER 阳性信号而不过度染色,与真实染色表现一致。在示例 3 中,尽管在低信号区域(如血管周围区域)存在轻微强度变化,但关键的 ER 染色模式总体上仍被较好保留。总体而言,PASB 能够较好捕捉 ER 染色模式,并与真实 IHC 染色保持较高一致性。虽然某些区域仍存在轻微强度差异,但这可能与训练数据集和模型的学习策略有关。总体来看,虚拟染色在高倍视野下呈现出准确的染色模式,展现出临床应用潜力。
4.5. 下游分析
Fig
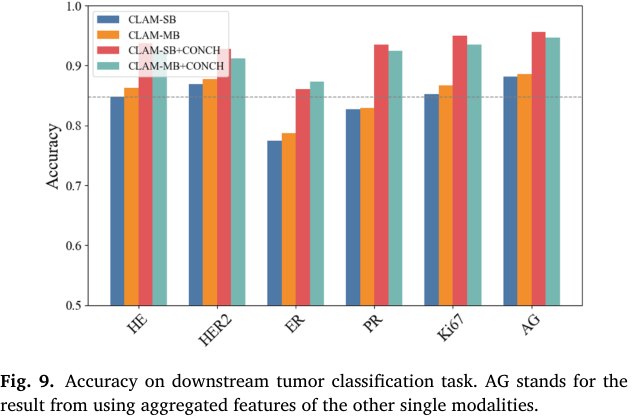
我们使用 SLN 数据集进一步评估了模型的临床性能。具体而言,我们将基于 MIST 数据集训练得到的虚拟 IHC 染色模型直接应用于 SLN 数据集中的 H&E 染色 WSI。随后,我们在生成的虚拟 IHC 图像上使用 CLAM(Lu et al., 2021)的两种弱监督架构进行肿瘤分类:单分支 SB 和多分支 MB。在这一框架中,首先利用在 ImageNet 上预训练的 ResNet-50 编码器提取 tile 级特征,然后通过 CLAM-SB 和 CLAM-MB 得到切片级预测。如图 9 所示,ER 和 PR 的分类准确率略低于原始 H&E 图像结果,这可能源于这些特定标志物较难从 H&E 图像中直接捕捉。相比之下,Ki67 和 HER2 在 H&E 图像中具有更显著的形态学特征(如细胞核密度、有丝分裂象和膜增强),因此具有更好的迁移效果和更高的分类准确率。
随后,我们将 H&E 切片及四张虚拟 IHC 切片的 WSI 级特征嵌入进行拼接,构成一个聚合特征向量(AG)。具体来说,该 AG 特征由 H&E 切片和四张虚拟 IHC 切片的 patch 级特征拼接而成,再输入 CLAM-SB 或 CLAM-MB 进行切片级聚合。为了验证其相对于仅使用 H&E 基线的效果,我们在 10 折交叉验证的准确率结果上进行了配对 t 检验。结果表明,AG 特征在所有测试分类器架构上均呈现出一致的正向提升趋势。具体而言,CLAM-MB 模型的准确率提升达到统计显著()。另外两个模型 CLAM-SB 与 CLAM-MB+CONCH 的提升也接近统计显著();最后一个模型 CLAM-SB+CONCH 虽未达到统计显著(),但同样表现出正向趋势。我们认为,这一整体结果模式充分说明,聚合虚拟 IHC 特征能够带来切实收益。
除了验证其在特征聚合中的作用外,我们还进一步检验了虚拟 IHC 图像与预训练视觉模型(如 CONCH,Lu et al., 2024)的兼容性。我们将默认的 ResNet-50 tile 级编码器替换为 CONCH,同时保留 CLAM-SB 和 CLAM-MB 作为切片级聚合架构。与不使用 CONCH 的基线方法相比,引入 CONCH 后的方案在所有模态上均显著提升了准确率。如图 9 所示,CLAM-SB 在 H&E 图像上的准确率为 0.937,而在 AG 模式下甚至达到 0.956。这些结果表明,尽管虚拟 IHC 图像是通过计算生成的,但它们仍可以被面向真实病理图像预训练的模型有效处理,从而进一步证明其临床相关性。
4.6. 评估指标讨论
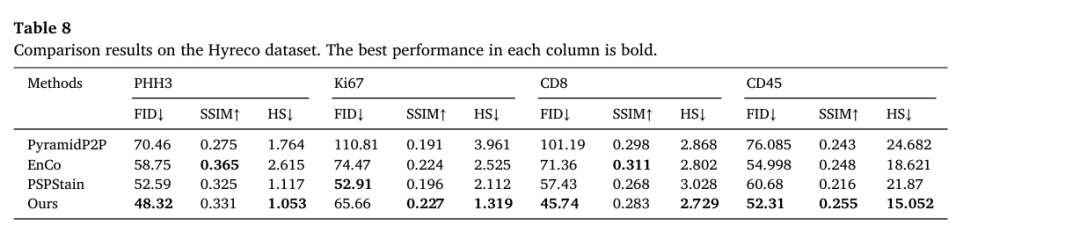
Table 8
为了进一步评估本文提出的评估体系,我们在 HyReCo 数据集上进行了实验。该数据集同时提供了完美配对数据(由重染切片得到的 H&E-PHH3)和连续切片数据。我们从每种学习范式中各选择一个模型,并分别用每个评估维度中的代表性指标进行评价:FID、SSIM 和 HS。如表 8 所示,我们的方法在 FID 和 HS 上表现优异,而在 SSIM 上表现中等,这一对比凸显了理解不同指标作用差异的重要性。
每个指标都从不同角度反映模型性能。较优的 FID 分数说明整体生成分布具有较高质量和真实性,但并不能直接说明单幅图像在病理层面的正确性。
Fig
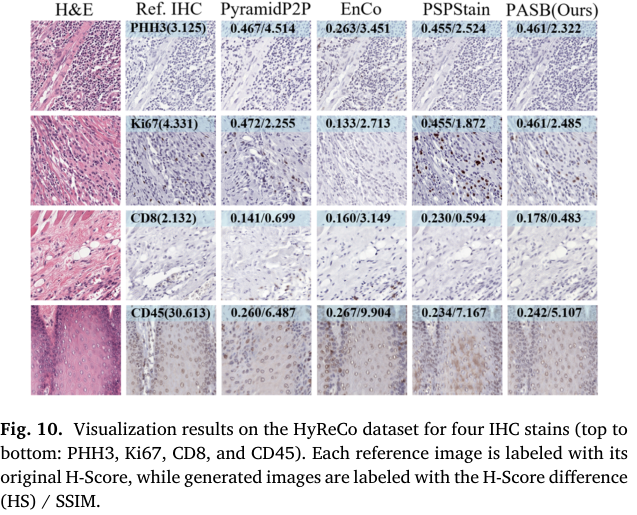
像素级的 SSIM 指标并不可靠,因为它会受到轻微但临床上并不重要的空间偏移的严重惩罚,这一点甚至在完美配对的 PHH3 数据上也得到了验证,如图 10 所示。相比之下,面向病理的 H-Score 对这些偏移更具鲁棒性,能够更准确地反映底层生物学特征。因此,我们认为,在评估虚拟染色的关键诊断效用时,像 HS 这样的临床指标比 SSIM 这类像素级指标更可靠、更重要。这也提示该领域需要进行评价范式的转变:应优先关注临床诊断等价性,而非像素级完美重建,才能真正验证虚拟染色工具的实用价值。
5. 讨论
5.1. PASB 的有效性与可靠性
我们选择薛定谔桥作为 PASB 的生成骨干,是出于对传统虚拟染色模型固有限制的考虑,而这一选择也得到了大量实验结果的验证。
Fig
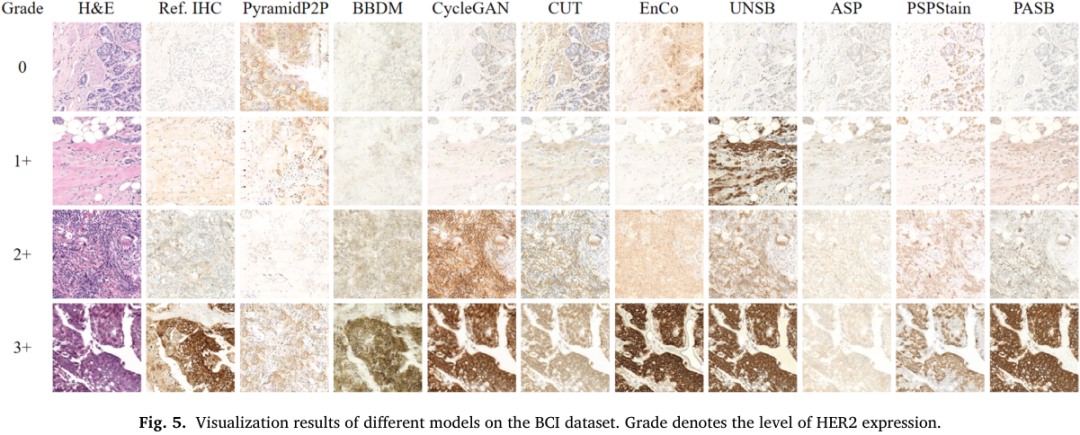
与 GAN 相比,PASB 框架在实际应用中展现出更优的稳定性与多样性。这一优势源于二者在训练目标上的根本差异:GAN 依赖于竞争性的 min-max 博弈,众所周知其平衡十分困难;而我们的 SB 框架则被表述为一个良定义的最优传输问题,因此能够获得更稳定的收敛行为。GAN 不稳定性的实际后果在实验中表现得非常明显:诸如 CycleGAN 和 CUT 等 GAN 方法容易生成同质化的染色风格,这正是模式崩塌的典型表现(见图 5)。相比之下,PASB 能够稳定生成多样且真实的染色模式。图 6 中的 t-SNE 可视化进一步说明,PASB 的特征分布与真实 IHC 图像更加接近,明显优于基于 GAN 的范式。
与扩散模型相比,PASB 更适合刻画组织病理数据的异质性。关键差异在于,SB 具有更加灵活、数据驱动的建模方式,更适合病理图像复杂且非高斯的本质;而扩散模型依赖限制更强的固定高斯先验。这种灵活性使 PASB 更能保留关键诊断特征,这一点也通过其在病理导向指标 HS 与 IOD 上优于扩散模型 BBDM(见表 1)得到验证。保持病理语义对于临床应用至关重要。
此外,PASB 还表现出突出的泛化能力和临床适用性。它在 MIST 数据集的不同染色模态(HER2、ER)上保持了较强性能(表 6 和表 7),并能够以较少伪影顺利扩展到 WSI 级别(图 8)。不过需要指出的是,这种优异表现依赖于特定领域内的训练,因为模型对染色流程和放大倍率变化较为敏感。本文的方法设置也体现了这一点:对于 20× 放大倍率数据集(BCI、MIST)与 10× 放大倍率数据集(ANHIR),我们分别训练不同模型。这一常规实践能够最大程度保证病理保真性,也说明虽然部署到新环境时仍需进行领域适配,但 PASB 架构本身在目标领域内的虚拟染色任务中具有很高的有效性。
5.2. 局限性与未来工作
尽管本文工作取得了一定成果,仍存在一些需要承认的局限。首先,虽然 PASB 在整体上表现良好,但在低信号强度区域(如血管周围区域)中的准确性可能下降,导致虚拟染色结果与真实 IHC 图像之间存在轻微偏差(图 8)。这可能源于训练数据中的样本分布不平衡。未来可以通过增加低信号样本或设计专门损失函数来进一步改善这一问题。其次,PASB 的优异性能是以计算复杂度为代价换来的。其动态路径优化的迭代特性会增加推理时间,尤其在较高 NFE(表 2)下更为明显,这可能限制其在时间敏感型临床流程中的实际部署。未来工作可以探索模型压缩技术(如知识蒸馏)或设计更高效的采样策略,以提升其临床可用性。
最后,要将该研究真正转化为临床工具,还面临更广泛的挑战,这些也是未来的重要研究方向。为了实现临床整合,需要开展大规模、多中心验证,以建立模型的鲁棒性和泛化能力。为确保可重复性,我们承诺公开代码和模型。最后,提高模型可解释性对于获得临床医生信任和满足监管审批要求至关重要,这也对应着深度学习固有的“黑箱”问题。
6. 结论
总之,我们成功提出了 PASB,一种新的虚拟染色框架,它利用薛定谔桥理论在弱监督条件下实现从 H&E 到 IHC 图像的高保真转换。该方法的核心,即 SB 骨干,将染色转换建模为最优传输问题,从而有效缓解了传统生成网络中常见的模式崩塌问题。为保证临床保真性,我们进一步引入两项关键创新:CDAL 利用高层病理语义引导生成过程,而 SDPR 则通过动态优化输运路径来维持病理一致性。基于多个公开数据集的大量实验验证表明,PASB 显著优于现有最先进方法,能够生成在诊断质量上可与真实 IHC 相媲美的虚拟 IHC 图像。该工作不仅展示了薛定谔桥理论在组织病理图像分析中的强大潜力,也为构建更具生物学约束的数字病理 AI 系统建立了新的范式。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)