我们为什么讨论DTO和VO?

在开始之前
DTO(Data Transfer Object)与VO(Value Object)的区别并不仅仅是编码规范的问题。
这更像是软件架构范式如何演变的活化石。
追溯这一争论的历史,就如同理解从“分布式对象”时代到“领域驱动设计(DDD)”时代,再到最终受“函数式编程(FP)”影响的现代技术思想流动一样。
尽管两者都是以“值(Value)”为中心的对象,但它们根据设计目的和设计方式而有所不同。
通常,DTO是为了数据的形式,而VO则是为了数据的意义。那么,让我们来探讨一下DTO和VO到底是什么。
在此之前,我会先附上一些必要的基础知识。
为了方便读者理解,我会先解释一下领域模型和业务逻辑,如下所示:
所需的前提知识:
1.领域模型(Domain Model)
领域模型是表示特定问题领域(领域)的一组对象
将现实世界中的概念抽象化并用代码实现
例如,在音乐流媒体服务中,“专辑”、“艺术家”、“曲目”等概念可以包含在领域模型中。
领域模型的特征
面向对象:由类和对象组成。
例如:Album、Artist、Track 类
关系中心:领域对象之间存在相互关系。
例如:一张专辑(Album)可以包含多首曲目(Track),每首曲目可以与多位艺术家(Artist)相关联。
反映业务规则:领域模型反映了该领域的核心规则和约束条件。
例如:“专辑必须至少包含一首曲目。”
2.业务逻辑(Business Logic)
业务逻辑 是为了解决软件要处理的问题所需的规则和流程
它在领域模型之上运行,并实现实际的业务需求
例如,“创建专辑时必须包含艺术家信息”的规则就属于业务逻辑。
业务逻辑的特征
基于领域模型:业务逻辑利用领域模型来实现
核心功能:定义应用程序的核心操作
例如:“创建专辑、添加曲目、关联艺术家。”
灵活性:如果业务需求发生变化,业务逻辑也必须进行修改。
领域模型是将现实世界中的概念用对象表示,而业务逻辑是在领域模型之上处理实际业务需求的规则。
领域模型涉及数据和状态等更广泛的高层概念,而业务逻辑则是利用数据执行任务的具体实现。
3.实体(Entity)
实体是在特定领域内拥有唯一标识符并在时间流逝中保持一致性的对象 对现实世界的实体进行建模,以存储和管理数据及状态 举例来说,“用户(User)”或“产品(Product)”可以用实体来表示。
实体的核心特征
唯一标识符(ID): 每个实体都有一个唯一标识符,用于区分其他对象 例如:User 类的 userId、Product 类的 productId。
持久性(Persistence): 实体存储在数据库或文件系统中,即使应用程序关闭也能保持其状态。
同一性(Identity): 两个实体如果具有相同的 ID,即使数据不同,也被视为同一个对象。 例如:User 对象 A 和 B 拥有相同的 userId,则 A 和 B 表示同一个用户。
状态变化(State Change): 实体的状态可能会随着时间的推移而改变,但其标识符不会改变 例如:即使用户的名称发生更改,userId 仍然保持不变。
两位巨人的诞生(2002~2003)
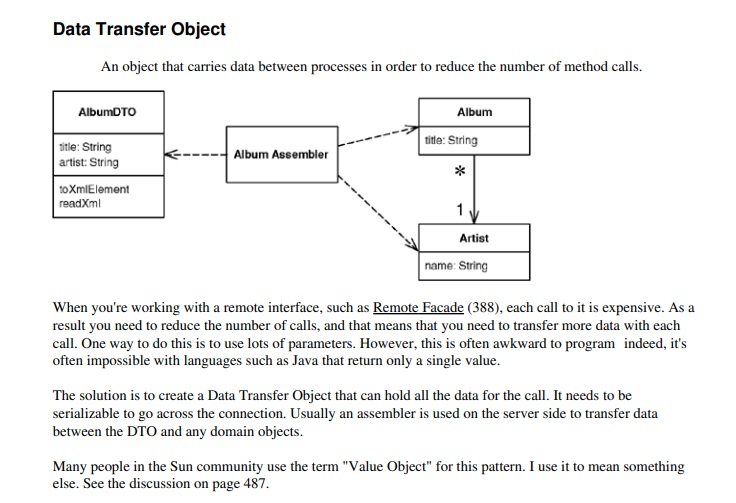
数据传输对象(DTO)
用于在进程之间传递数据的对象,旨在减少方法调用的次数。
当与远程接口(例如 Remote Facade (388))一起工作时,每次调用的成本都很高。因此,需要减少调用次数,这意味着每次调用需要传输更多数据。实现这一目标的一种方法是使用大量参数。然而,这通常会使编程变得困难,尤其是在像 Java 这样的语言中,只能返回单个值,有时甚至无法实现。解决方案是创建一个可以包含所有数据的数据传输对象(DTO) 。为了通过连接进行传输,该对象必须是可序列化的。通常,在服务器端会使用一个组装器(assembler)在 DTO 和领域对象之间传输数据。
在 Sun 社区中,许多人将这种模式称为“Value Object(值对象)”。但我用它来表示不同的含义。参见第 487 页的讨论。
DTO(Data Transfer Object)的诞生
DTO(数据传输对象)的概念源于Martin Fowler的《企业应用架构模式》(Patterns of Enterprise Application Architecture),并因此广为人知。
核心讨论如下:
“为了最小化远程调用,将多次调用获取的数据全部放入一个‘傻瓜式’(Dumb)对象中,通过一次调用完成传输。”
此时的DTO是一个可变(mutable)对象,通常将DTO描述为可变对象,而VO(值对象)描述为不可变对象的说法也由此而来。
那么,为什么会进行这样的讨论呢?
在2000年代初期,EJB(Enterprise JavaBeans)等分布式组件技术是主流。那个时代最主要的技术限制是什么?
答案是网络调用的成本问题。当时服务器与客户端之间、服务器与服务器之间的远程调用成本非常高,远远高于现在。
什么是分布式组件系统?
分布式组件系统是一种架构,其中多台计算机作为节点存在,独立的组件分布在不同的节点上运行,但整体上表现为一个集成的系统。
为了获取远程对象的信息(当时是分布式组件系统,所以通过远程接口获取),需要支付高昂的调用成本。
这种成本非常高昂,而用来减少这种成本的对象就是DTO。
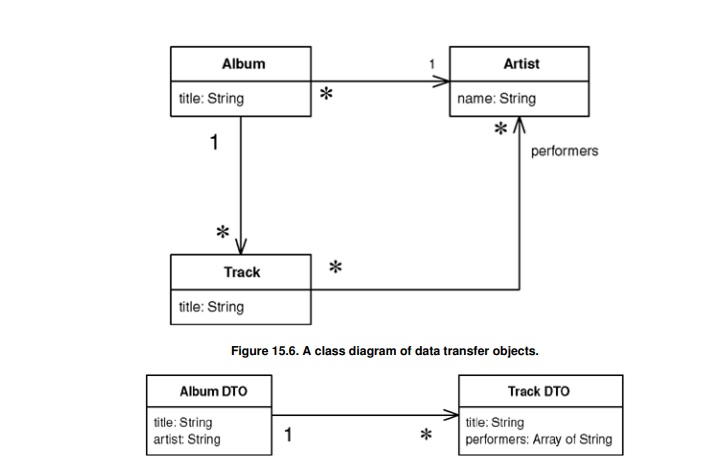
此时的DTO仅仅用于数据传输。实际上,Martin Fowler提供的示例如下,稍后我们将详细说明。
首先,代码的目的如下:
从领域模型(Domain Model)中提取所需数据,将其转换为简单的结构,并将其序列化(Serialization)为适合远程调用的格式。
然后,展示如何将从客户端接收到的数据再次转换为领域模型的示例。
领域模型(Domain Model):领域模型是表示应用程序核心业务逻辑和数据的对象(例如:Album、Track、Artist类)。这些类具有复杂的关系和方法,不适合远程调用。
数据传输对象(DTO)[Data Transfer Object]:领域模型数据的简化形式,并转换为可序列化的格式(例如:AlbumDTO、TrackDTO)。
组装器(Assembler):组装器负责领域模型与DTO之间的转换(例如:AlbumAssembler类)。这个类可以将领域对象转换为DTO,或将DTO转换回领域对象。在现代架构中,组装器已经很少使用,通常被Mapper取代,这部分内容我们将在以后有时间时再详细探讨。
虽然这样解释可能有些难以理解,但在Martin Fowler的《企业应用架构模式》(P of EAA)中,他通过示例解释了领域模型的概念。
现在我们已经掌握了核心概念,来看下面的代码块。
(1) DTO 编写 (Domain → DTO)
class AlbumAssembler {
public AlbumDTO writeDTO(Album subject) {
AlbumDTO result = new AlbumDTO();
result.setTitle(subject.getTitle());
result.setArtist(subject.getArtist().getName());
writeTracks(result, subject);
return result;
}
private void writeTracks(AlbumDTO result, Album subject) {
List newTracks = new ArrayList();
Iterator it = subject.getTracks().iterator();
while (it.hasNext()) {
TrackDTO newDTO = new TrackDTO();
Track thisTrack = (Track) it.next();
newDTO.setTitle(thisTrack.getTitle());
writePerformers(newDTO, thisTrack);
newTracks.add(newDTO);
}
result.setTracks((TrackDTO[]) newTracks.toArray(new TrackDTO[0]));
}
private void writePerformers(TrackDTO dto, Track subject) {
List result = new ArrayList();
Iterator it = subject.getPerformers().iterator();
while (it.hasNext()) {
Artist each = (Artist) it.next();
result.add(each.getName());
}
dto.setPerformers((String[]) result.toArray(new String[0]));
}
}代码解读如下:
writeDTO:将Album对象转换为AlbumDTO
- 设置专辑标题(title)和艺术家名称(artist)到DTO中
- 调用writeTracks方法处理曲目信息
writeTracks:将专辑中包含的曲目转换为TrackDTO数组
- 提取每个曲目的标题和表演者信息,并存储到DTO中
writePerformers:将曲目的表演者名称转换为字符串数组
(2) 使用 DTO 创建领域对象 (DTO → Domain)
class AlbumAssembler {
public void createAlbum(String id, AlbumDTO source) {
Artist artist = Registry.findArtistNamed(source.getArtist());
if (artist == null)
throw new RuntimeException("没有名为 " + source.getArtist() + " 的艺术家");
Album album = new Album(source.getTitle(), artist);
createTracks(source.getTracks(), album);
Registry.addAlbum(id, album);
}
private void createTracks(TrackDTO[] tracks, Album album) {
for (int i = 0; i < tracks.length; i++) {
Track newTrack = new Track(tracks[i].getTitle());
album.addTrack(newTrack);
createPerformers(newTrack, tracks[i].getPerformers());
}
}
private void createPerformers(Track newTrack, String[] performerArray) {
for (int i = 0; i < performerArray.length; i++) {
Artist performer = Registry.findArtistNamed(performerArray[i]);
if (performer == null)
throw new RuntimeException("没有名为 " + performerArray[i] + " 的艺术家");
newTrack.addPerformer(performer);
}
}
}解释:
- createAlbum : 基于 DTO 创建新的专辑对象。
- 从注册表(Registry)中查找艺术家和曲目信息并进行关联。
- createTracks : 根据 DTO 中的曲目信息创建新的曲目对象。
- createPerformers : 基于曲目中的表演者信息,将艺术家对象与曲目关联。
(3) 使用 DTO 更新领域对象
class AlbumAssembler {
public void updateAlbum(String id, AlbumDTO source) {
Album current = Registry.findAlbum(id);
if (current == null)
throw new RuntimeException("专辑不存在: " + source.getTitle());
if (!source.getTitle().equals(current.getTitle()))
current.setTitle(source.getTitle());
if (!source.getArtist().equals(current.getArtist().getName())) {
Artist artist = Registry.findArtistNamed(source.getArtist());
if (artist == null)
throw new RuntimeException("没有名为 " + source.getArtist() + " 的艺术家");
current.setArtist(artist);
}
updateTracks(source, current);
}
private void updateTracks(AlbumDTO source, Album current) {
for (int i = 0; i < source.getTracks().length; i++) {
current.getTrack(i).setTitle(source.getTrackDTO(i).getTitle());
current.getTrack(i).clearPerformers();
createPerformers(current.getTrack(i), source.getTrackDTO(i).getPerformers());
}
}
}解释:
- updateAlbum : 使用 DTO 的信息更新现有的专辑对象。
- 比较标题、艺术家和曲目信息并反映更改。
- updateTracks : 更新曲目信息或添加新曲目。
值对象(Value Objects)的诞生 - Eric Evans 的《领域驱动设计》(2003)

值对象 (VALUE OBJECTS)
许多对象并没有概念上的标识性(conceptual identity)。这些对象描述了某些事物的特征。
假设一个孩子正在画画,他可能会关注所选马克笔的颜色,也许还会在意笔尖的锐利程度。但如果他面前有两支颜色和形状完全相同的马克笔,他通常不会在意使用哪一支。即使他丢失了一支马克笔,并用另一支从新包装中取出的相同颜色的马克笔替换,他也不会在意,而是会继续他的创作。
如果问这个孩子冰箱上贴着的几幅画是谁画的,他会很快区分出哪些是他画的,哪些是他妹妹画的。孩子和他的妹妹都有有用的标识性,他们完成的画作同样如此。但试想一下,如果需要追踪每一幅画中的每一条线是由哪支马克笔画的,那将变得多么复杂。绘画或许就不再是孩子的简单游戏了。
在模型中,最显眼的对象通常是实体(ENTITIES),它们的标识性非常重要,因此很自然地会开始思考是否要为所有领域对象赋予标识性。有时甚至会创建为每个对象分配唯一ID的框架,为了在整个分布式系统和数据库存储中完美追踪对象,可能还需要额外的分析工作。
这种做法不仅会让系统承担巨大的追踪开销,还可能导致许多潜在的性能优化被排除在外,从而对系统性能产生高昂的成本。更重要的是,这种做法把所有对象都强行归入同一个框架,给模型强加了容易引起误解的人为标识性,导致模型变得混乱。
虽然追踪实体的标识性是必要的,但为其他对象赋予标识性可能会损害系统性能、增加分析负担,并使所有对象看起来千篇一律,从而使模型更加混乱。软件设计是一场与复杂性不断斗争的过程,我们需要通过区分来确保特殊处理仅应用于真正需要的地方。
然而,如果我们仅仅把这些对象归类为“没有标识性”的对象,我们的工具箱和词汇表就会显得非常单薄。事实上,这些对象有着自己的独特特性和在模型中的重要性。它们是用来描述事物本质的对象。
我们将那些表示领域中描述性方面且没有概念标识性的对象称为值对象(VALUE OBJECT) 。值对象是为了表示设计中的那些我们只关心“是什么”而不关心“是谁”的元素而实例化的。

随着编程变得越来越复杂,
业务逻辑也随之变得更加复杂。在这个过程中,为了“优雅地”表达业务逻辑,诞生了一个概念——值对象(Value Object, VO)。
而这个VO的概念是在一本经典著作《领域驱动设计》(Domain-Driven Design, DDD)中被介绍并广泛传播的,它定义为:
“将值及其相关的业务逻辑封装到一个对象中,该对象不依赖ID进行标识,而是通过其拥有的值(Value)来判断相等性,并且一旦创建就不可更改,即必须是不可变(Immutable)的对象。”
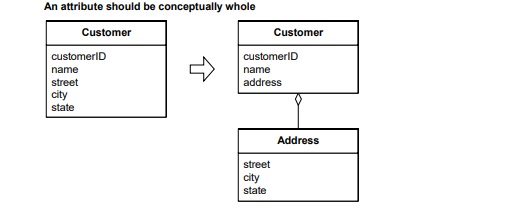
(DDD Book Value Object Example)
(1) Address 值对象
public class Address {
private final String street;
private final String city;
private final String state;
// 构造函数
public Address(String street, String city, String state) {
this.street = street;
this.city = city;
this.state = state;
}
// Getter 方法
public String getStreet() {
return street;
}
public String getCity() {
return city;
}
public String getState() {
return state;
}
// 重写 equals 和 hashCode 方法(基于值比较)
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Address address = (Address) o;
return Objects.equals(street, address.street) &&
Objects.equals(city, address.city) &&
Objects.equals(state, address.state);
}
@Override
public int hashCode() {
return Objects.hash(street, city, state);
}
@Override
public String toString() {
return "Address{" +
"street='" + street + '\'' +
", city='" + city + '\'' +
", state='" + state + '\'' +
'}';
}
}(这是在Java 14之前实现VO的代码。虽然从Java 14开始推荐使用record来实现VO,但本文旨在展示随时代变化的不同实现方式。)
Address 是一个值对象(Value Object),包含 street、city、state 等属性。
值对象通常是不可变对象,具有相同的值时被视为同一个对象。
最初,这两个概念的角色是非常明确的。
过去
| DTO | VO | |
|---|---|---|
|
目的 |
用于网络传输 |
表示领域模型 |
|
结构 |
可变对象(get; set;) |
不可变对象(final, val, readonly) |
|
逻辑 |
无 |
存在有效性验证和相等性逻辑 |
|
位置 |
API 边界 |
领域层 |
补充说明:
- DTO 强调序列化的便利性 :DTO 是一个装有所有远程通信所需数据的盒子。
- VO 注重意义的表达 :VO 是设计领域模型时带有意义的值。
DTO 是一个装有所有远程通信所需数据的盒子,
VO 则是设计领域模型时带有意义的值。
然而,随着硬件性能的提升,这两者的界限逐渐模糊了。
为什么我们开始讨论 DTO 与 VO?

经过分布式系统和EJB时代的发展,强大的Spring框架诞生了。
过去分布式系统和EJB时代与Spring框架时代的差异有很多例子可以列举,几乎是无穷无尽的。但为了简单说明,我将用一个比喻来解释。
过去的房子设施简陋,家里甚至没有厨房(EJB时代)。
卧室在房子里,
而厨房和卫生间则位于外部(独立的服务器)。
所以当你早上起床想去厨房吃早餐时,你必须出门才行。
同样,去卫生间也需要通过网络调用(外部调用),
并且为了在厨房和卫生间之间自由移动,你不得不随身携带所有必需的工具(如厕纸、餐具刀具等)。
然而,随着像Spring这样强大Web框架的出现,分布式系统的界限逐渐消失,在单个应用程序内部的层间数据传递(Controller ↔ Service ↔ Repository)成为主要关注点。
也就是说,当所有房间都集中在一个屋檐下时,昂贵的网络调用成本消失了。
因此,DTO从远程传输对象的角色逐渐转变为用于层间数据传递的对象,并且开始被使用。
“既然都在同一个屋檐下,为什么还要随身携带所有工具(DTO)呢?为什么不根据需要取出相应的物品(VO)呢?”
因此,DTO作为传输对象和VO作为领域建模对象之间的区别变得模糊了,“为什么一定要使用DTO”的问题也开始具有说服力。
DTO真的不需要了吗?

(《Clean Code》第8章 边界)
结论是,DTO的作用以某种不同的方式开始发生变化。
正如Uncle Bob在其著作《Clean Code》中提到的,“系统应与外部代码设置明确的边界”。
在此背景下,DTO开始作为与外部代码交互的边界对象使用。
DTO用于外部边界,API、数据库、消息队列、文件等场景中使用;
而VO则用于内部模型。
也就是说,DTO开始作为封装外部API的边界适配器(Boundary Adapter)发挥作用。
换句话说,DTO的作用是作为与外部通信的翻译工具,
而VO成为了内部领域中的语言本身。
此外,随着多线程编程成为主流,DTO也经历了新的变化。

(《Effective Java》第17章 最小化可变性)
在2010年代初期,多线程编程再次成为热门话题,函数式编程的优点——不可变性被引入其中。
此时,DTO也顺应潮流,从可变(Mutable)对象逐渐演变为不可变对象(Immutable),并引入了诸如record关键字等特性。
(之后,Robert Martin在《Clean Architecture》中通过Use Case Output DTO的概念强调,DTO应该被定义为外部世界与Use Case层之间的单向接口。也就是说,DTO应始终存在于“边界之外”,而领域模型应仅存在于边界之内。不过这些内容会破坏本文结构,因此只需理解有这样的概念即可。)
随着这一趋势的发展,DTO和VO都逐渐具备了“不可变性”作为默认属性,两者的差异变得更加微妙。
当前的争论已经转变为:没有领域逻辑的不可变对象(DTO)VS 有领域逻辑的不可变对象(VO)。
现在
| DTO | VO | |
|---|---|---|
|
不可变性 |
推荐(近乎强制) |
强制 |
|
是否包含领域逻辑 |
无(仅作为容器) |
有(如相等性、验证等逻辑) |
|
基于意义的相等性 |
ID或键值为基础,或无关 |
equals,基于值的身份识别,强制 |
|
位置 |
API/输入输出层 |
领域层 |
|
依赖性 |
基于框架(如 Jackson, gRPC 等) |
独立,以意义为中心 |
当然,DTO 并不一定完全没有逻辑。
在某些情况下,DTO 也可能包含数据验证逻辑。这里所说的“无逻辑”通常是指“不包含领域逻辑”的概念,应以此理解。
结语...

(Martin Fowler)
The fundamental horror of this anti-pattern is that it's so contrary to the basic idea of object-oriented design
- 这种贫血领域模型的反模式违背了面向对象设计的核心思想。
虽然两者之间的差异逐渐缩小,但我们为什么仍然要区分它们?难道只用 DTO 不可以吗?
这是因为这不仅仅是一个技术上的差异,更是为了在代码层面清晰地表达设计意图(Design Intent)。
使用 DTO:意味着“这个对象仅仅负责将数据从 A 层传递到 B 层,对数据的意义或业务规则一无所知。”这是一种责任边界的声明。
使用 VO:意味着“这个对象通过‘值’本身具有完整的意义,并且我直接负责与我的值相关的有效性验证和相关行为。”这是领域知识封装的声明。
Martin Fowler 是推广 DTO 概念的人,但他同时反对像 J2EE 模型中那样,仅有数据的 DTO 被用于领域逻辑核心部分的情形。
仅使用 DTO 是一种反模式,VO 不仅仅是存储值的容器,它还封装了与值相关的行为,因此不能仅依赖 DTO 存在。
但如果只存在 VO 会怎样?复杂的业务逻辑将直接暴露给外部,换句话说,层级间的边界被破坏,外部请求可能侵入和改变领域层级。这意味着领域对象不得不承担序列化和 API 契约的责任,从而导致领域设计受到污染。
最终,没有任何一种方法是绝对正确的。
因此,我们依然在 DTO 和 VO 之间权衡,不断在这两者之间思考设计的选择。
![]()

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 31
31 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)