基于核密度估计的CNN-LSTM-Attention-KDE多输入单输出回归模型【MATLAB】
基于核密度估计的CNN-LSTM-Attention-KDE多输入单输出回归模型
在深度学习时间序列预测与回归分析中,传统的模型往往只能给出一个确定的“点预测”结果(例如:预测明天的温度是25度)。然而,在许多高风险的工程和金融场景中,我们不仅需要知道预测值是多少,还需要知道这个预测值的可靠程度(例如:明天温度在23度到27度之间的概率是90%)。
为了解决这一问题,本文将为大家分享一种结合了卷积神经网络 (CNN)、长短期记忆网络 (LSTM)、注意力机制 (Attention) 以及 核密度估计 (Kernel Density Estimation, KDE) 的复合预测框架。该模型不仅具有强大的非线性特征提取能力,还能提供科学的概率区间预测。
一、 核心技术与模型架构解析
本模型的架构可以分为两个主要的阶段:深度特征提取与点预测,以及基于KDE的误差分布建模与区间估计。
1. CNN-LSTM-Attention 深度提取模块
- 空间特征提取 (CNN):通过引入二维卷积层(
convolution2dLayer),模型能够有效地捕捉多输入特征在特定时间步内的局部关联信息。 - 注意力机制 (Attention):代码中构建了一个类似Squeeze-and-Excitation (SE)模块的通道注意力机制。利用全局平均池化(GAP)聚合全局空间信息,通过全连接层与Sigmoid激活函数计算各个特征通道的权重,最后通过
multiplicationLayer对原始特征进行加权。这使得模型能够动态聚焦于对输出最具影响力的特征。 - 时序建模 (LSTM):加权后的特征序列被展平并输入到具有6个隐藏单元的
lstmLayer中,用于捕捉数据中潜藏的长期时序依赖关系。
2. 核密度估计 (KDE) 区间预测模块
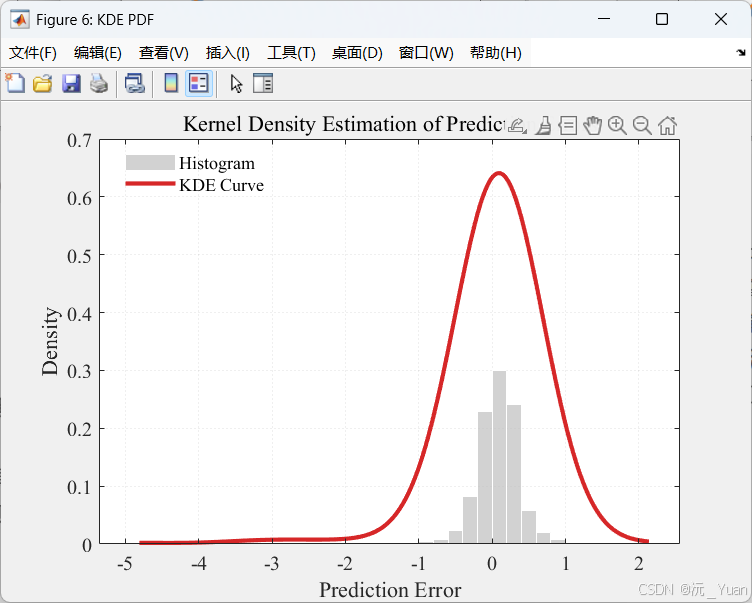
传统的置信区间估计往往假设误差服从正态分布,但这在实际工程数据中很少成立。KDE是一种非参数检验方法,它不需要提前假设数据服从何种分布。
- 模型首先收集训练集上的预测误差(真实值 - 预测值)。
- 利用高斯核函数(Normal Kernel)拟合误差的真实概率密度函数(PDF),并计算累积分布函数(CDF)。
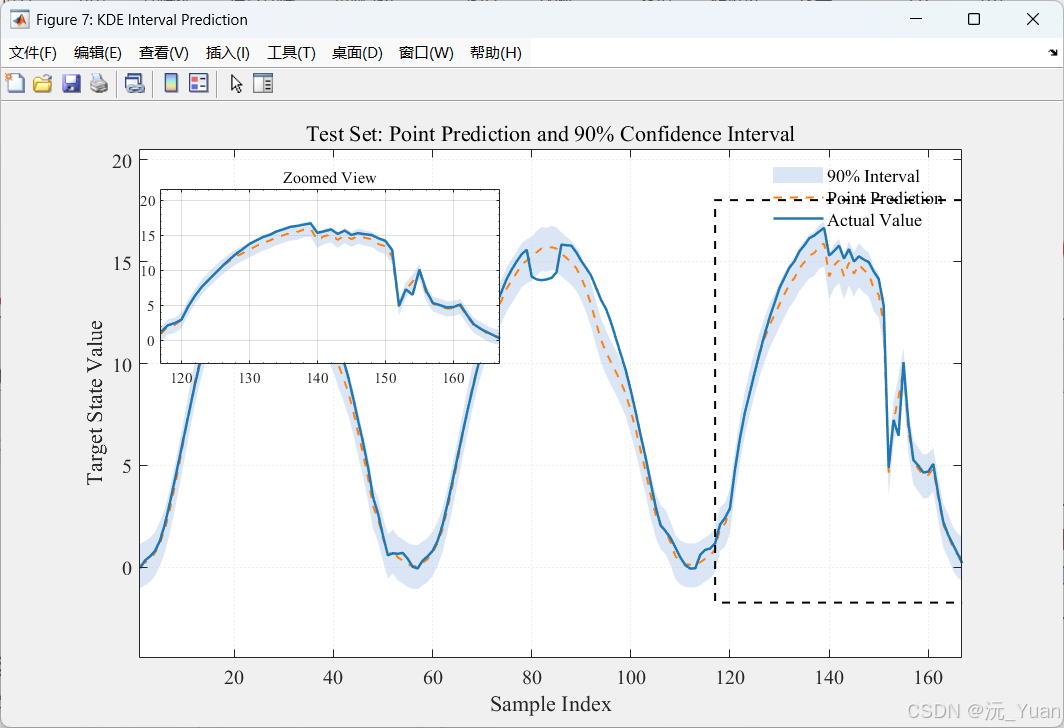
- 在测试集上,根据拟合出的CDF,反求出指定置信水平(如90%)对应的误差上下分位数,从而构建出预测的上下界。
二、 MATLAB 部分源码实现
以下是包含数据预处理、网络构建、模型训练、KDE区间估计及多维可视化图表的完整MATLAB代码。请准备好您的 data.xlsx 数据文件(最后一列为输出目标变量),即可直接运行。
warning off % 关闭报警信息
close all % 关闭开启的图窗
clear % 清空变量
clc % 清空命令行
tic
rng('default')
%% ==================== 1. 数据导入与预处理 ====================
res = xlsread('data.xlsx');
num_size = 0.7; % 训练集占数据集比例
outdim = 1; % 最后一列为输出
num_samples = size(res, 1); % 样本个数
% res = res(randperm(num_samples), :); % 打乱数据集(不希望打乱时,注释该行)
num_train_s = ceil(num_size * num_samples)+1; % 训练集样本个数
f_ = size(res, 2) - outdim; % 输入特征维度
% 划分训练集和测试集
P_train = res(1: num_train_s, 1: f_)';
T_train = res(1: num_train_s, f_ + 1: end)';
M = size(P_train, 2);
P_test = res(num_train_s + 1: end, 1: f_)';
T_test = res(num_train_s + 1: end, f_ + 1: end)';
N = size(P_test, 2);
% 数据归一化
[p_train, ps_input] = mapminmax(P_train, 0, 1);
p_test = mapminmax('apply', P_test, ps_input);
[t_train, ps_output] = mapminmax(T_train, 0, 1);
t_test = mapminmax('apply', T_test, ps_output);
% 数据平铺与格式转换
p_train = double(reshape(p_train, f_, 1, 1, M));
p_test = double(reshape(p_test , f_, 1, 1, N));
t_train = double(t_train)';
t_test = double(t_test )';
for i = 1 : M
Lp_train{i, 1} = p_train(:, :, 1, i);
end
for i = 1 : N
Lp_test{i, 1} = p_test( :, :, 1, i);
end
三、 评估指标解读
本框架综合输出了点预测与区间预测两套独立的评估体系:
1. 点预测常规指标
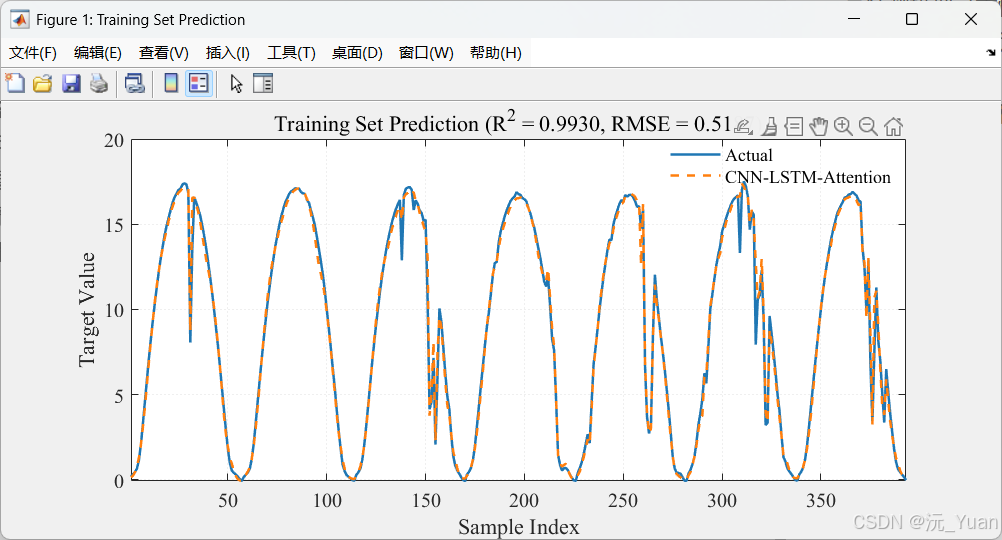
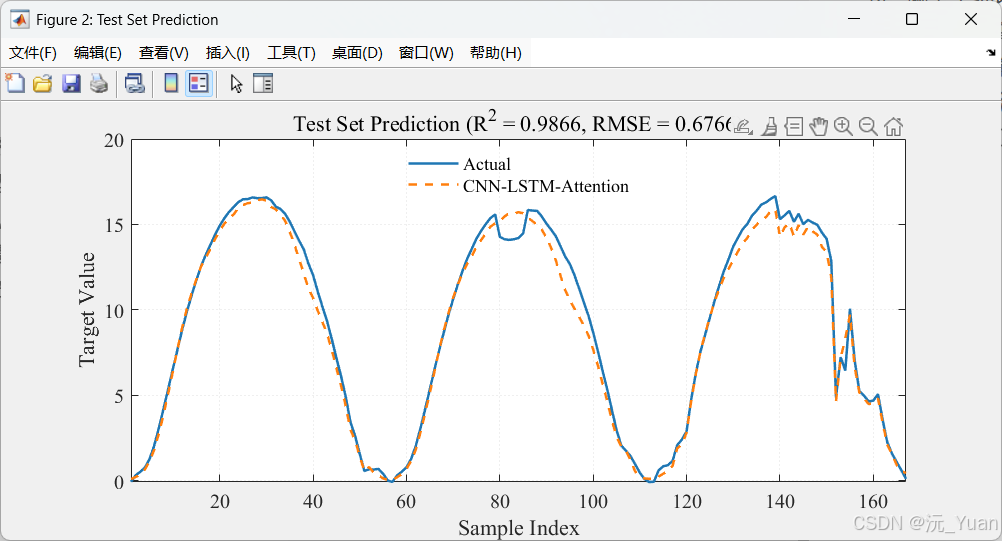
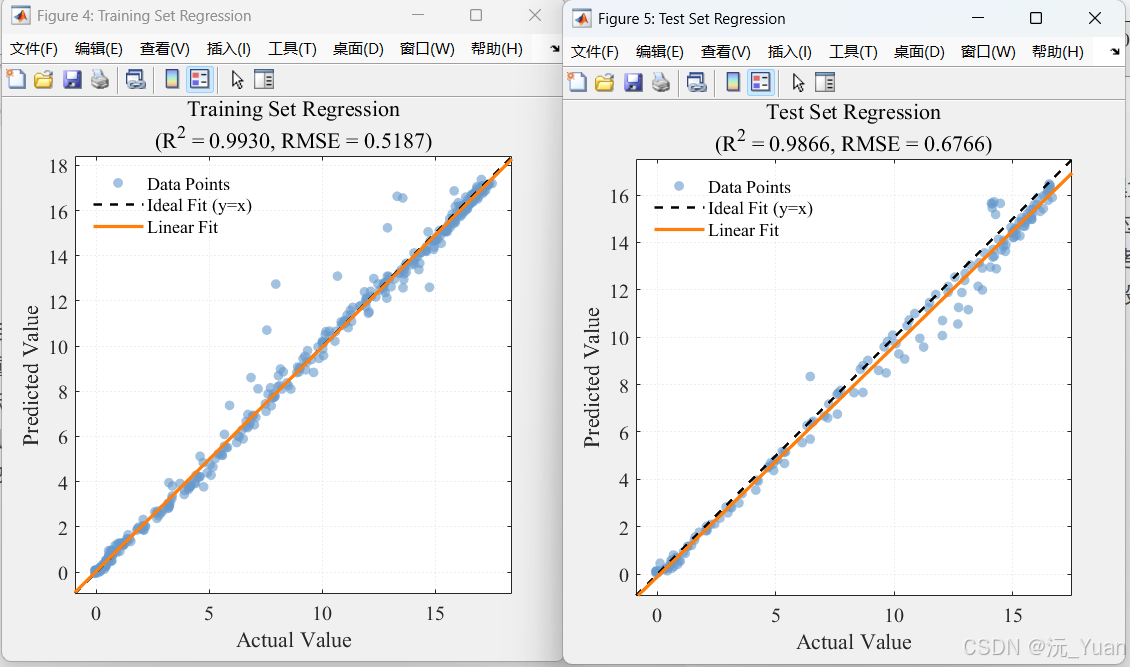
- 决定系数 (R2R^2R2):越接近1,说明CNN-LSTM-Attention主干网络的拟合性能越好。
- 均方根误差 (RMSE) & 平均绝对误差 (MAE):反映了预测值偏离真实值的绝对尺度。
2. 区间预测专属指标 (基于 KDE)
- 区间覆盖率 (PICP - Prediction Interval Coverage Probability):表示实际真实值落入预测区间内的样本比例。对于设置的90%置信区间,若 PICP 值接近 0.90 甚至大于 0.90,说明我们的区间预测非常可靠。
- 区间平均宽度 (PINAW - Prediction Interval Normalized Average Width):表示构建的置信区间的平均宽度(并经极差归一化)。PINAW越小,说明预测区间越窄,模型预测的不确定性越低。
- 博弈关系:PICP 和 PINAW 往往相互制约。一个优秀的模型不仅要确保高覆盖率(大的PICP),同时还要尽可能保持较窄的区间跨度(小的PINAW),这正是深度网络提取高精度特征后,配合KDE准确量化分布边界的优势所在。
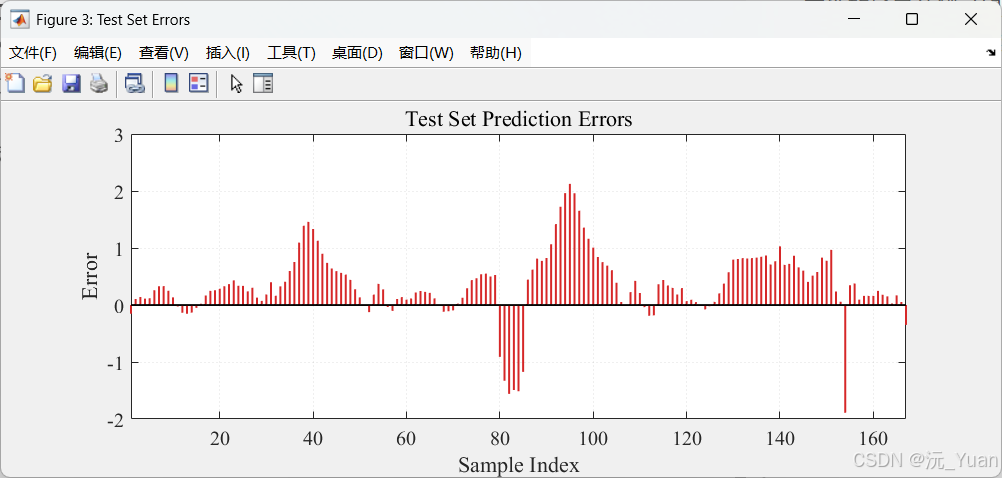
四、运行结果展示
五、 总结
将**概率学统计方法(KDE)与深度学习黑盒模型(CNN-LSTM-Attention)**相结合,是当前学术界提高预测模型可靠性的重要研究分支。通过本文提供的框架,开发者不仅可以获得极高精度的时序回归结果,更能为实际业务提供极具参考价值的容错区间。这套代码极其适合用于具有高度不确定性的场景预测(如风速发电量预测、股市时间序列、设备剩余寿命预测等)。希望这篇文章能为您的科研和工程落地带来启发!
六、 代码下载
https://mbd.pub/o/bread/YZWclphvag==

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 1
1 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)