强化学习3.2:表格求解法——蒙特卡罗方法
定义
直接从与环境的完整交互经验中学习价值函数和最优策略的重要方法
核心思想
通过完整回合采样的平均回报来估计状态 / 动作价值函数,进而优化策略
-
构造随机过程:将实际问题转化为某种随机分布的参数(如均值、概率)
-
大量采样:通过计算机生成成千上万个符合要求的随机样本
-
统计推断:对样本结果求平均值或频率,作为问题的近似解
核心公式
- 状态价值函数估计:
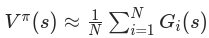 ,其中Gi(s)是第 i 个 episode 中状态 s 后的回报,N 是包含 s 的 episode 数量
,其中Gi(s)是第 i 个 episode 中状态 s 后的回报,N 是包含 s 的 episode 数量 - 回报 :
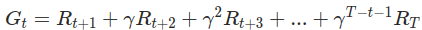 ,
,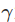 为折扣因子 (0≤
为折扣因子 (0≤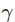 ≤1)
≤1)
核心特点
- 无模型学习:无需环境模型 (P 和 R),直接从经验中学习
- 完整轨迹依赖:必须等待整个episode结束才能计算回报并更新价值
- 采样平均估计:价值函数是真实回报的无偏估计,方差随样本数量增加而减小
- 通用性强:适用于任意马尔可夫决策过程 (MDP),无需马尔可夫性假设
蒙特卡罗策略评估
在给定策略π下,准确估计其状态价值函数![]() 或动作价值函数
或动作价值函数![]()
| 方法 | 定义 | 特点 | 收敛性 |
|
首次访问 |
仅在每个 episode 中首次访问状态 s 时,用该 episode 回报更新Vπ(s) |
无偏估计,方差较小 |
当访问次数→∞时,收敛到Vπ(s) |
|
每次访问 |
在每个 episode 中每次访问状态 s 时,都用该 episode 回报更新Vπ(s) |
无偏估计,方差较大 |
同样收敛到Vπ(s),但收敛速度可能不同 |
首次访问 MC 策略评估伪代码:
# 初始化
V = {s: 0 for s in 所有状态} # 状态价值函数
Returns = {s: [] for s in 所有状态} # 存储每个状态的回报列表
# 循环直至收敛
for 每个episode in 足够多的episodes:
生成遵循策略π的完整轨迹: S₀,A₀,R₁,S₁,A₁,R₂,...,S_T(终止状态)
计算每个时间步t的回报G_t
对于轨迹中每个状态S_t:
if S_t 未在当前episode的更早时间步出现:
将G_t添加到Returns[S_t]
V[S_t] = Returns[S_t]的平均值 # 或增量更新: V[S_t] += (G_t - V[S_t])/len(Returns[S_t])
算法流程
1.输入:待评估的策略 π
2.初始化:
- 初始化价值函数
或
(通常为0)
- 初始化每一个状态的累计回报列表
,用于存放状态s的所有历史回报值
3.循环(生成大量回合):
-
使用策略π与环境交互,生成一个完整的回合轨迹:
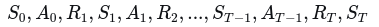
-
初始化回报 G=0
-
从回合的最后一步向前遍历,计算每个时刻的折扣回报
:
-
如果St 是首次出现在本回合中:
-
在一次轨迹中,只在第一次经过状态
时记录并计算
中
-
更新价值函数:
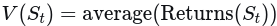
-
- 每次访问:只要状态
蒙特卡罗策略改进
目标:找到最优策略 π∗。
广义策略迭代框架:评估当前策略→改进策略→重复直至收敛
-
策略评估:使用蒙特卡罗方法评估当前策略 π下的
-
策略改进:根据
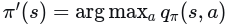
1.蒙特卡罗探索开始 (MC ES)
强制每个回合从随机的状态-动作对开始,并保证每个状态-动作对都有非零概率被访问到
MC ES 伪代码:
# 初始化
Q = {(s,a): 0 for s in 所有状态 for a in 所有动作} # 动作价值函数
Returns = {(s,a): [] for s in 所有状态 for a in 所有动作} # 状态-动作对回报列表
π = {s: 随机选择动作 for s in 所有状态} # 初始随机策略
# 循环直至收敛
for 每个episode in 足够多的episodes:
随机选择起始状态-动作对(S₀,A₀),保证所有(s,a)有非零概率被选中
生成完整轨迹: S₀,A₀,R₁,S₁,A₁,R₂,...,S_T
计算每个时间步t的回报G_t
对于轨迹中每个(S_t,A_t):
if (S_t,A_t)未在当前episode更早时间步出现:
将G_t添加到Returns[(S_t,A_t)]
Q[(S_t,A_t)] = Returns[(S_t,A_t)]的平均值
# 策略改进:对当前Q值贪心
π[S_t] = argmax_a Q[(S_t,a)]
2.无探索开始的MC控制
如果智能体总是遵循当前最优的策略(纯贪心),那么它可能永远不会尝试那些看起来“暂时不好”但实际上“潜力巨大”的动作
- 同轨 (on-policy) 控制:学习和执行同一个策略(如ε- 贪心策略)
- 离轨 (off-policy) 控制:学习目标策略(如贪心策略),同时执行行为策略(如 ε- 贪心策略) 进行探索,需使用 “重要性采样 “校正偏差
-贪心策略
我们不强制要求从每个状态动作对开始,而是要求策略在任何时候都以的概率进行“随机探索”
- 以
的概率选择当前
- 以
的概率在所有动作中随机选择(包括那个最大的)
ε- 贪心同轨 MC 控制伪代码:
# 初始化
Q = {(s,a): 0 for s,a in 所有状态-动作对}
Returns = {(s,a): [] for s,a in 所有状态-动作对}
π = ε-贪心策略初始化(基于Q)
for 每个episode:
生成遵循π的完整轨迹: S₀,A₀,R₁,S₁,A₁,...,S_T
计算G_t
对于每个(S_t,A_t):
if (S_t,A_t)首次出现:
添加G_t到Returns[(S_t,A_t)]
Q[(S_t,A_t)] = 平均值
# 更新ε-贪心策略
π[S_t] = 以1-ε概率选择argmax_a Q(S_t,a),以ε概率随机选择动作
行为策略 (Behavior Policy, ):用来产生数据的策略。它必须是具备探索性的(如完全随机或
-贪心)
目标策略 (Target Policy, ):我们要学习的最优策略。它可以是纯贪心的。
算法流程对比
| 特性 | 探索性初始化 (ES) | 同策略 (ϵ-greedy) | 离策略 (Off-policy) |
| 对起始要求 | 覆盖所有 |
无要求 | 无要求 |
| 策略类型 | 学习确定性策略 | 学习“软”策略 | 学习确定性策略 |
| 采样策略 | 当前策略 |
当前策略 |
独立的探索策略 |
| 收敛目标 | 最优策略 |
近似最优的软策略 | 最优策略 |

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 13
13 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)