意图识别与实体抽取:基于 BERT + UIE 的多模型协同设计实战
一、 业务背景:为什么需要多模型协同
在电商智能客服场景中,用户输入往往具有高度的随机性和碎片化特征。例如,“我想看3000元左右的华为手机”与“帮我查一下这款华为手机的屏幕尺寸”,虽然都提到了“华为手机”,但其背后的业务逻辑完全不同。
单一的模型难以兼顾全局语义分类与局部特征提取。如果仅使用意图识别,系统无法获取具体的参数(如价格区间、机身内存);如果仅使用实体抽取,系统无法判断用户是在执行“查询”还是“对比”操作。因此,意图识别 + 实体抽取的多模型协同设计成为主流:
- 意图识别:确定用户“想干什么”,通过预定义的分类标签(如:查询价格、查询配置、查找同类品)引导后续逻辑。
- 实体抽取:识别文本中的关键参数(槽位),为业务接口(如 Cypher 查询)提供输入变量。
二、 意图识别:基于 BERT 的分类模型
该方案采用 BERT(Bidirectional Encoder Representations from Transformers)作为底座。其核心原理是利用预训练的中文权重获取句子的上下文表示,并通过 [CLS] 位的向量进行多分类。
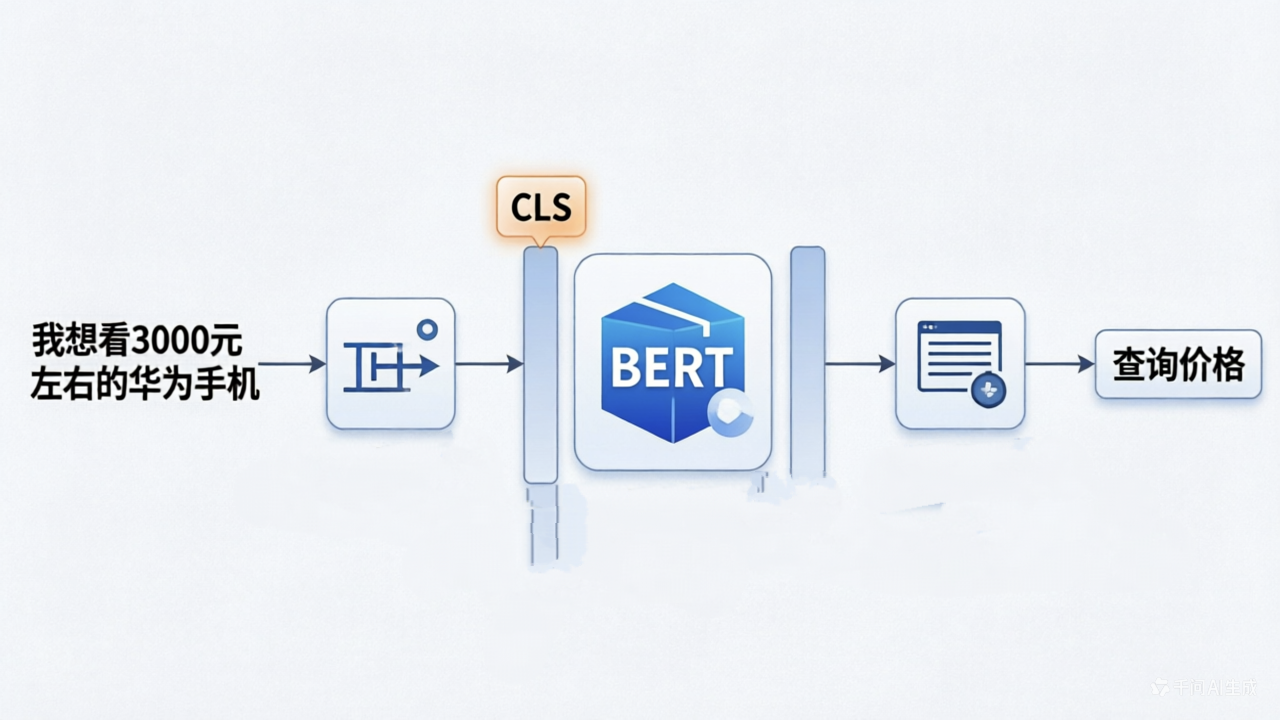
1. 模型架构设计
意图识别被建模为一个单标签多分类问题。该模型由 BERT 编码器和线性分类头组成,提取 [CLS] token 的输出作为句子的整体语义表示。
2. 代码实现
以下为基于 PyTorch 封装的意图分类模型:
# src/models_def/intent_classify.py
import torch
import torch.nn as nn
from transformers import AutoTokenizer, BertModel
class IntentClassifyModel(nn.Module):
"""意图分类模型定义"""
def __init__(self, model_name: str, intent_list: list):
super().__init__()
self.intent_list = intent_list
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.model = BertModel.from_pretrained(model_name)
# 线性分类头:映射至意图数量空间
hidden_size = self.model.config.hidden_size
self.classifier = nn.Linear(hidden_size, len(self.intent_list))
self.loss_fn = nn.CrossEntropyLoss()
def forward(self, input_ids, attention_mask=None, labels=None):
outputs = self.model(input_ids, attention_mask)
# 取 [CLS] token 的向量 (batch_size, hidden_size)
cls_output = outputs.last_hidden_state[:, 0, :]
logits = self.classifier(cls_output)
loss = 0.0
if labels is not None:
loss = self.loss_fn(logits, labels)
return {"logits": logits, "loss": loss}
@torch.inference_mode()
def predict(self, text: str, device=torch.device("cpu")):
"""单条文本预测逻辑"""
self.eval()
self.to(device)
inputs = self.tokenizer(
text,
max_length=256,
truncation=True,
padding=True,
return_tensors="pt"
).to(device)
outputs = self.forward(inputs["input_ids"], inputs["attention_mask"])
pred_idx = torch.argmax(outputs["logits"], dim=1).item()
return self.intent_list[pred_idx]
三、 实体抽取:基于 UIE 的动态抽取
对于电商中的属性(如“机身内存”、“颜色”、“分辨率”),实体类型繁杂且变化快。UIE (Universal Information Extraction) 通过 Prompt 机制将抽取任务转化为“文本到结构”的生成过程,具备极强的零样本或小样本迁移能力。
1. UIE 工作原理
UIE 模型不依赖固定的实体标签,而是根据传入的 schema(提示词)动态寻找边界。例如输入 schema 为 ["颜色", "价格"],模型会在文本中定位对应的 span 并返回概率得分。
2. 代码封装
该方案将 UIE 包装为实体抽取服务,支持批量处理:
# src/entity_extractor_model_base.py
import sys
from uie_predictor import UIEPredictor # 假设已安装 uie-pytorch 依赖
class EntityExtractorModelBase:
"""基于 UIE 的实体抽取服务"""
def __init__(self, model_path, device="cpu"):
# 初始化预测器
self.uie = UIEPredictor(
model="uie-base",
task_path=model_path,
schema=[], # 初始 schema 为空
engine="pytorch",
device=device
)
def __call__(self, text, schema):
"""执行动态抽取"""
self.uie.set_schema(schema)
# 模型返回包含 start/end 位置及 text 的字典列表
batch_res = self.uie([text] if isinstance(text, str) else text)
results = []
for one_res in batch_res:
processed = {}
for label, spans in one_res.items():
processed[label] = list({s["text"] for s in spans}) # 去重提取
results.append(processed)
return results if isinstance(text, str) else results
四、 协同设计:多模型流水线架构
多模型协同的核心在于:根据意图识别的结果,动态决定实体抽取的 Schema。这种设计避免了全量扫描所有可能实体的计算浪费,并降低了噪声干扰。
1. 协同逻辑流程
- 输入清洗:对原始文本进行拼写纠错(如将“Nkie”纠正为“Nike”),确保模型输入质量。
- 意图锁定:BERT 模型输出分类结果。
- 策略映射:系统根据意图类型,从配置中调取对应的实体槽位需求(Schema)。
- 精准抽取:UIE 模型针对性提取相关实体。
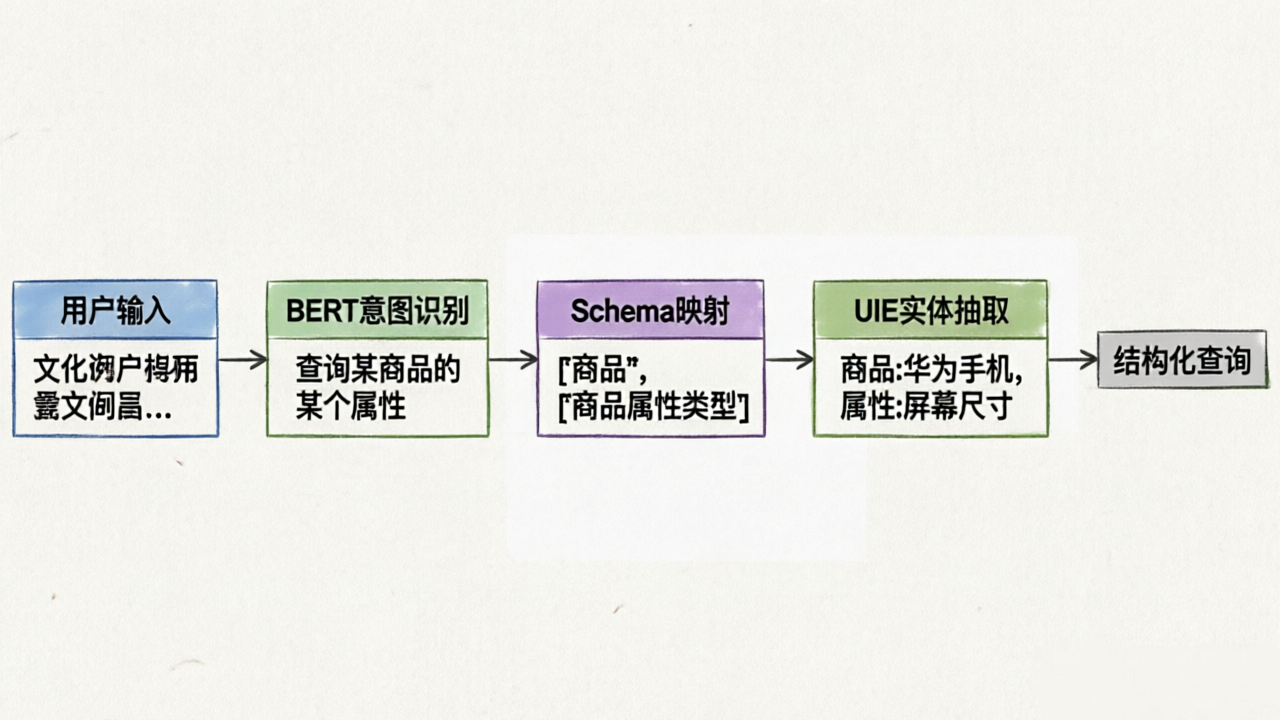
2. 结果融合实现
以下是对话处理流程的完整封装,展示了意图与实体的整合:
# src/dialog_process.py
class DialogProcess:
def __init__(self, intent_model, uie_model, device):
self.intent_model = intent_model
self.uie_model = uie_model
self.device = device
# 预定义意图与实体 Schema 的映射关系
self.intent_to_schema = {
"查询某商品的某个属性的属性值": ["商品", "商品属性类型"],
"查询某品类某价格区间的单品": ["品类", "价格"],
"查询某品类具有某些属性值的单品": ["品类", "属性"],
"查询某品牌所有品类": ["品牌"]
}
def process(self, user_text):
# 1. 意图识别
intent = self.intent_model.predict(user_text, self.device)
# 2. 获取该意图对应的抽取模式
schema = self.intent_to_schema.get(intent, [])
# 3. 执行实体抽取
slots = {}
if schema:
slots = self.uie_model(user_text, schema)
# 4. 结果融合:构建结构化输出
return {
"intent": intent,
"slots": slots,
"structured_query": self._build_query(intent, slots)
}
def _build_query(self, intent, slots):
# 示例:将结果映射为 Cypher 查询参数
return f"Logic for {intent} with params {slots}"
五、 踩坑经验分享
在多模型协同部署过程中,以下两点实践经验对于系统稳定性至关重要:
1. 拼写纠错的必要性
现象:模型无法识别“三星s24 Ultra”中的品牌,原因是用户误输入为“三生s24”。 对策:在 NLU 模块之前必须前置一个拼写纠错模型。基于 BERT 的掩码预测(Masked LM)能力,可以有效纠正同音字和形近字错误。纠错后的文本再流转至意图与实体模块,可显著降低漏抽率。
2. UIE 负例构造与过拟合预防
现象:UIE 模型在推理时,容易将不相关的词强行归类到 schema 中的标签下。 对策:在 UIE 微调阶段,必须加入负例数据。即构造一部分 Prompt 与文本完全不匹配的数据,并令其结果列表为空。这能让模型学会“预测空集合”,从而在处理真实复杂对话时表现更稳健。
3. 结果序列化问题
现象:从意图模型输出的类别索引是 torch.Tensor 类型,直接接入后端会引发 JSON 序列化失败。 对策:在模型 predict 方法中,务必显式调用 .item() 将单值 Tensor 转换为 Python 原生类型,或通过索引映射为字符串标签。
六、 总结与展望
通过 BERT 锁定用户意图,配合 UIE 动态捕捉属性槽位,该方案构建了一个具备高度灵活性和可解释性的 NLP 解析引擎。相较于单模型,多模型协同架构在逻辑解耦和复杂业务适配上具有明显优势。
未来的演进方向将聚焦于 RAG(检索增强生成) 与知识图谱的深度融合。通过 LLM 对解析出的结构化三元组进行二次推理,可以进一步提升系统在模糊查询与长尾知识覆盖上的表现。
如果觉得有帮助,点个赞支持一下! 欢迎留言交流你的多模型设计经验!
收藏备用,总有一天用得上!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)