CUDA核心:SIMT并行模型
SIMT (Single Instruction, Multiple Threads) 是 NVIDIA CUDA 架构的核心执行模型。
即: 多个线程在同一时间执行相同的指令,但处理不同的数据。
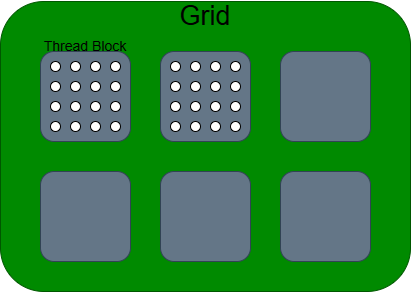
线程层次结构
多个线程组成线程块,多个线程块组成网格,它们可以是1维、2维、3维的。可以使用不同的内置变量查询。
| 网格维度 | gridDim.[x|y|z] | 表示网格在 x、y、z 维度上的大小 |
| 线程块维度 | blockDim.[x|y|z] | 表示线程块在 x、y、z 维度上的大小 |
| 线程块索引 | blockIdx.[x|y|z] | 表示线程块在网格中的索引 |
| 线程索引 | threadIdx.[x|y|z] | 表示线程在线程块中的索引 |
在网格中,threadIdx.y 的步长为 blockDim.x
全局内存
全局内存(设备内存)是内核中所有线程都可以访问的主要数据存储空间,运行在 GPU 上的内核可以直接访问全局内存。全局内存是一直存在的,在全局内存中进行的分配以及存储在其中的数据会一直保留,直到分配的内存被释放或应用程序终止。
#include <cuda_runtime.h>
int main() {
int h_data = 100, h_res = 0;
int *d_data;
// 1. 分配:在 GPU 开辟空间
cudaMalloc(&d_data, sizeof(int));
// 2. 复制:CPU -> GPU
cudaMemcpy(d_data, &h_data, sizeof(int), cudaMemcpyHostToDevice);
// 2. 复制:GPU -> CPU
cudaMemcpy(&h_res, d_data, sizeof(int), cudaMemcpyDeviceToHost);
// 3. 释放:回收这块内存
cudaFree(d_data);
// 4. 重置:清空当前线程所有 CUDA 资源
cudaDeviceReset();
return 0;
}| 操作 | 目标对象 | 典型位置 | 影响 |
| cudaMalloc | 显存空间 | 初始化阶段 | 增加显存占用 |
| cudaMemcpy | 内存数据 | 计算前/后 | 引起 CPU-GPU 同步阻塞 |
| cudaFree | 特定指针 | 任务结束时 | 释放显存,不影响 Context |
| cudaDeviceReset | 整个 Context | 程序退出时 | 抹除所有 CUDA 痕迹 |
共享内存
共享内存是线程块内所有线程都可以访问的内存空间。因为线程块内所有线程都可以访问,所以需要使用__syncthreads()函数实现线程块所有线程的同步,它会阻塞所有线程,直到线程块内所有线程执行完毕。
声明静态分配的共享内存
共享内存的静态分配需使用声明符__shared__,以这种方式声明的共享内存的大小需在编译时指定。在内核内部,使用extern __shared__声明符来声明一个在内核启动时动态分配的变量。
__shared__ float sharedArray[512];声明动态分配的共享内存
在内核中使用 extern __shared__ 声明符可以动态分配共享内存。例如:
extern __shared__ float sharedArray[];
这种声明方式允许在启动内核时通过第三个执行配置参数指定共享内存的大小。
多个动态分配的共享内存分区
如果需要多个动态分配的共享内存区域,必须通过指针手动分区,且指针需要与它们指向的类型对齐。例如:
extern __shared__ float array[];
short* array0 = (short*)array;
float* array1 = (float*)&array0[128];
int* array2 = (int*)&array1[64];这种方式确保所有共享内存从同一块动态分配的内存中划分,避免重复分配。
内核启动时指定共享内存大小
启动内核时,共享内存的大小通过执行配置的第三个参数指定:
kernel<<<gridSize, blockSize, sharedMemorySize>>>(...);
sharedMemorySize 是以字节为单位的总共享内存大小,需覆盖所有分区需求。
注意事项
动态共享内存的声明必须是未指定大小的数组形式,如 extern __shared__ T name[]。静态共享内存(固定大小)的声明方式为 __shared__ T name[size],无需 extern 关键字。
动态分配的共享内存生命周期仅限于内核执行期间,无法在设备代码中重新分配或释放。
寄存器
寄存器的物理位置在流式多处理器(SM)上,其作用域仅限于单个线程。编译器负责管理寄存器的分配和使用,在内核执行期间,寄存器作为线程的局部存储空间。每个 SM 的寄存器总数和每个线程块可用的寄存器数量由 GPU 的硬件规格决定,具体参数为 regsPerMultiprocessor。
寄存器数量的优化
NVCC 编译器提供了 -maxrregcount 选项,允许开发者指定单个内核可使用的最大寄存器数量。通过调整此参数,可以控制寄存器的使用情况。减少内核可用的寄存器数量可能导致以下效果:
- 更多线程块可以同时调度到同一个 SM 上,从而提高并行度。
- 寄存器使用量减少可能导致更多的寄存器溢出(register spilling),即部分数据被迫存储到全局内存中,从而可能降低性能。
寄存器溢出的影响
寄存器溢出是指当寄存器资源不足时,编译器将部分变量存储到全局内存或本地内存中。这会增加内存访问延迟,从而对内核性能产生负面影响。优化寄存器使用需要在提高并行度和减少溢出之间找到平衡。
性能调优建议
通过实验性地调整 -maxrregcount 参数,可以观察内核性能的变化。建议结合性能分析工具(如 NVIDIA Nsight)监控寄存器的使用情况和溢出次数,以确定最优的寄存器分配策略。同时,可以通过重构内核代码减少寄存器依赖,例如合并变量或减少临时变量的使用。
CUDA 常量内存
常量内存是 GPU 中一种受限但极高性能的只读存储路径。它物理驻留在显存中,但通过硬件级别的专用常量缓存(Constant Cache)实现近乎寄存器级的访问速度。
1. 内存布局与物理驻留
常量内存在软件层面具有严格的定义约束,而在硬件层面则享有特殊的缓存通道:
-
声明位置: 必须在全局作用域(Global Scope,即所有函数之外)使用
__constant__修饰。 -
物理位置: 数据驻留在 显存(Device Memory) 中。
-
缓存位置: 数据在运行时会被加载到每个 SM 内部的常量缓存(Constant Cache)中。
-
生命周期: 随应用程序启动而创建,直到进程结束。
2. 核心特性:广播机制与容量限制
常量内存的设计初衷是“单次读取,全体广播”。
-
广播机制(Broadcasting): 当一个线程束(Warp)内的 32 个线程同时请求同一个常量内存地址时,硬件仅需执行一次读取操作,随后将数据广播给所有线程。
-
容量上限: NVIDIA 架构通常固定为 64 KB。
-
低延迟: 缓存命中时,延迟极低;但若 Warp 内线程访问不同地址(发散访问),请求将被串行化,性能会大幅下降。
3. 代码实现与主机端交互
常量内存的操作不使用常规的 cudaMalloc 或 cudaMemcpy,而是基于符号(Symbol)进行编址。
设备端定义与使用
// 1. 在全局作用域声明
__constant__ float d_filter_coeffs[256];
__global__ void applyFilter(float* data) {
// 2. 直接通过符号名访问,无需传递指针
int tid = blockIdx.x * blockDim.x + threadIdx.x;
data[tid] *= d_filter_coeffs[tid % 256];
}
主机端管理 API
由于常量内存空间在编译期已分配,主机端需使用专用 API 寻找符号并同步数据:
| 常用 API | 功能描述 |
cudaMemcpyToSymbol |
最常用。将主机数据拷贝至常量区符号。 |
cudaMemcpyFromSymbol |
将常量区数据回传至主机(调试用)。 |
cudaGetSymbolAddress |
获取常量符号在设备端的运行时偏移地址。 |
cudaGetSymbolSize |
运行时查询该常量符号占用的字节数。 |
4. 性能优化与架构建议
要发挥常量内存的最佳性能,应遵循以下准则:
-
最佳场景: 存储核函数中所有线程都会用到的只读参数(如:卷积核、变换矩阵、物理常数)。
-
规避发散: 尽量确保 Warp 内的所有线程在同一时刻访问同一个常量地址,以利用广播机制。
-
避免频繁修改: 修改常量内存需要重新启动内核并调用
cudaMemcpyToSymbol,这会带来额外的主机同步开销。
分布式共享内存 (DSM)
1. 概念
-
概念: 在计算能力 9.0 中,通过引入“线程块集群”(Thread Block Clusters),集群内的多个线程块现在可以互相访问彼此的共享内存。
-
寻址空间: 所有参与集群的线程块的共享内存拼接在一起,形成了一个全新的地址空间,称为“分布式共享内存地址空间”。
-
操作权限: 集群内的任意线程,都可以对这个地址空间内的任意位置(无论是自己 Block 的,还是其他 Block 的)执行读取、写入或原子操作(Atomics)。
2. 内存容量与分配
-
按块分配机制不变: 无论你是否使用 DSM,共享内存的代码申请方式(静态
__shared__或动态extern __shared__)依然是基于单个线程块的。 -
总容量计算: 分布式共享内存的总大小 = (每个线程块申请的共享内存大小) × (集群中的线程块总数)。
3. 同步与生命周期管理
-
启动同步: 要想访问其他线程块的共享内存,前提是该共享内存必须“存在”。必须使用协作组 API
cluster.sync()来确保集群内所有的线程块都已经成功启动。 -
退出同步: 这是极其容易出错的一点。 线程块一旦执行完毕退出,它的共享内存就会被回收。因此,程序必须严格保证:当 Block B 正在读取 Block A 的共享内存时,Block A 绝对不能提前结束运行。这就要求在内核结束前再次进行集群级别的同步。
#include <cooperative_groups.h>
#include <cooperative_groups/reduce.h>
namespace cg = cooperative_groups;
// 定义内核,指定集群大小为 2 (要求 CUDA 12.0+ 及 Compute Capability 9.0+)
__global__ void __cluster_dims__(2, 1, 1) dsm_example_kernel(int* output) {
// 1. 常规分配共享内存
__shared__ int local_smem[1];
// 获取当前线程所在的集群组
cg::cluster_group cluster = cg::this_cluster();
int cluster_rank = cluster.block_rank(); // 当前 Block 在集群中的编号 (0 或 1)
// 2. 同步:确保所有的 Block 都已经启动并分配了共享内存
cluster.sync();
// ---------------- 操作阶段 ----------------
// 让 Block 0 初始化自己的共享内存
if (cluster_rank == 0 && threadIdx.x == 0) {
local_smem[0] = 42; // Block 0 写入数据
}
// 确保 Block 0 的写入操作已经完成,再让其他 Block 读取
cluster.sync();
// 让 Block 1 读取 Block 0 的共享内存
if (cluster_rank == 1 && threadIdx.x == 0) {
// 参数 1: 共享内存变量指针
// 参数 2: 目标 Block 在集群中的 Rank (这里是 0)
int* remote_smem_ptr = cluster.map_shared_rank(local_smem, 0);
// 跨 Block 读取数据并写入全局内存
output[0] = remote_smem_ptr[0];
}
// 3. 退出同步
cluster.sync();
}
AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)