番外(开源心电图数据库处理)-续
·
前文提到了数据清洗,经过操作发现这里面细节还真多,现在来分享一下心路历程。
我的思路是根据标签进行清洗,所以第一步就是先搞清有什么标签:
%% ====================== 批量统计所有注释(时间分布) ======================
% 基于 128 Hz 采样率,将样本位置转换为时间(秒)
% 输出每个记录的前 10 个注释作为示例,并保存完整结果
clear; clc;
%% 参数设置
dataFolder = 'D:\ECG-Tran\mit-bih-normal-sinus-rhythm-database';
recordNames = {
'16265', '16272', '16273', '16420', '16483', '16539', ...
'16773', '16786', '16795', '17052', '17453', '18177', ...
'18184', '19088', '19090', '19093', '19140', '19830'
};
nRecords = length(recordNames);
Fs = 128; % 固定采样率(已知该数据库为 128 Hz)
% 用于保存所有记录的注释统计结果
all_stats = cell(nRecords, 1);
fprintf('开始批量统计 %d 个记录的注释...\n\n', nRecords);
%% 主循环:依次处理每个记录
for i = 1:nRecords
recName = recordNames{i};
fprintf('========== 记录 %d/%d : %s ==========\n', i, nRecords, recName);
% 切换到数据文件夹
oldFolder = cd(dataFolder);
% 读取注释(样本位置 ann 和类型代码 atype)
try
[ann, atype] = rdann(recName, 'atr');
catch ME
fprintf('错误:无法读取注释文件 %s.atr\n', recName);
cd(oldFolder);
continue;
end
% 切回原目录
cd(oldFolder);
nAnnot = length(ann);
fprintf('注释总数: %d\n', nAnnot);
% 统计各类型代码的出现次数
unique_types = unique(atype);
fprintf('类型代码统计 (代码 : 次数):\n');
for j = 1:length(unique_types)
code = unique_types(j);
count = sum(atype == code);
fprintf(' %d : %d\n', code, count);
end
% 将样本位置转换为时间(秒): 假设 ann 为 1-based
time_sec = (ann - 1) / Fs;
end
fprintf('\n批量统计完成。\n');经过统计发现共有70、78、83、86、124、126六种,对应的ASCII为:F、N、S、V、|、~。依次是心室律与正常心律的融合、正常节拍、室上性早搏、室性早搏、孤立的QRS状伪影、信号质量的变化[1]。
表1 注释统计结果
| 编号 | 注释总数 | 70 | 74 | 78 | 83 | 86 | 124 | 126 |
| 16265 | 100955 | 6 | 0 | 100216 | 5 | 16 | 259 | 453 |
| 16272 | 97146 | 0 | 0 | 87757 | 1 | 0 | 7265 | 2123 |
| 16273 | 90097 | 0 | 0 | 89840 | 5 | 0 | 52 | 200 |
| 16420 | 102436 | 0 | 0 | 102061 | 4 | 2 | 73 | 296 |
| 16483 | 104561 | 0 | 0 | 104330 | 4 | 0 | 96 | 131 |
| 16539 | 108674 | 0 | 0 | 108265 | 17 | 0 | 47 | 345 |
| 16773 | 112897 | 0 | 0 | 81962 | 27 | 0 | 30782 | 126 |
| 16786 | 101739 | 2 | 0 | 101605 | 5 | 3 | 40 | 84 |
| 16795 | 87678 | 0 | 0 | 86872 | 0 | 0 | 686 | 120 |
| 17052 | 88002 | 0 | 0 | 87354 | 2 | 0 | 296 | 350 |
| 17453 | 101173 | 0 | 0 | 100655 | 3 | 0 | 108 | 407 |
| 18177 | 117004 | 0 | 0 | 115908 | 3 | 0 | 826 | 267 |
| 18184 | 102672 | 0 | 0 | 102313 | 0 | 0 | 173 | 186 |
| 19088 | 117880 | 0 | 0 | 97957 | 2 | 2 | 19186 | 733 |
| 19090 | 81953 | 0 | 2 | 81382 | 7 | 0 | 281 | 281 |
| 19093 | 83670 | 0 | 0 | 75100 | 3 | 3 | 8424 | 140 |
| 19140 | 96992 | 0 | 0 | 96596 | 0 | 0 | 244 | 152 |
| 19830 | 111263 | 0 | 0 | 109329 | 3 | 0 | 1230 | 701 |
| 总计 | 1806792 | 8 | 2 | 1729502 | 91 | 26 | 70068 | 7095 |
非正常的可视化:
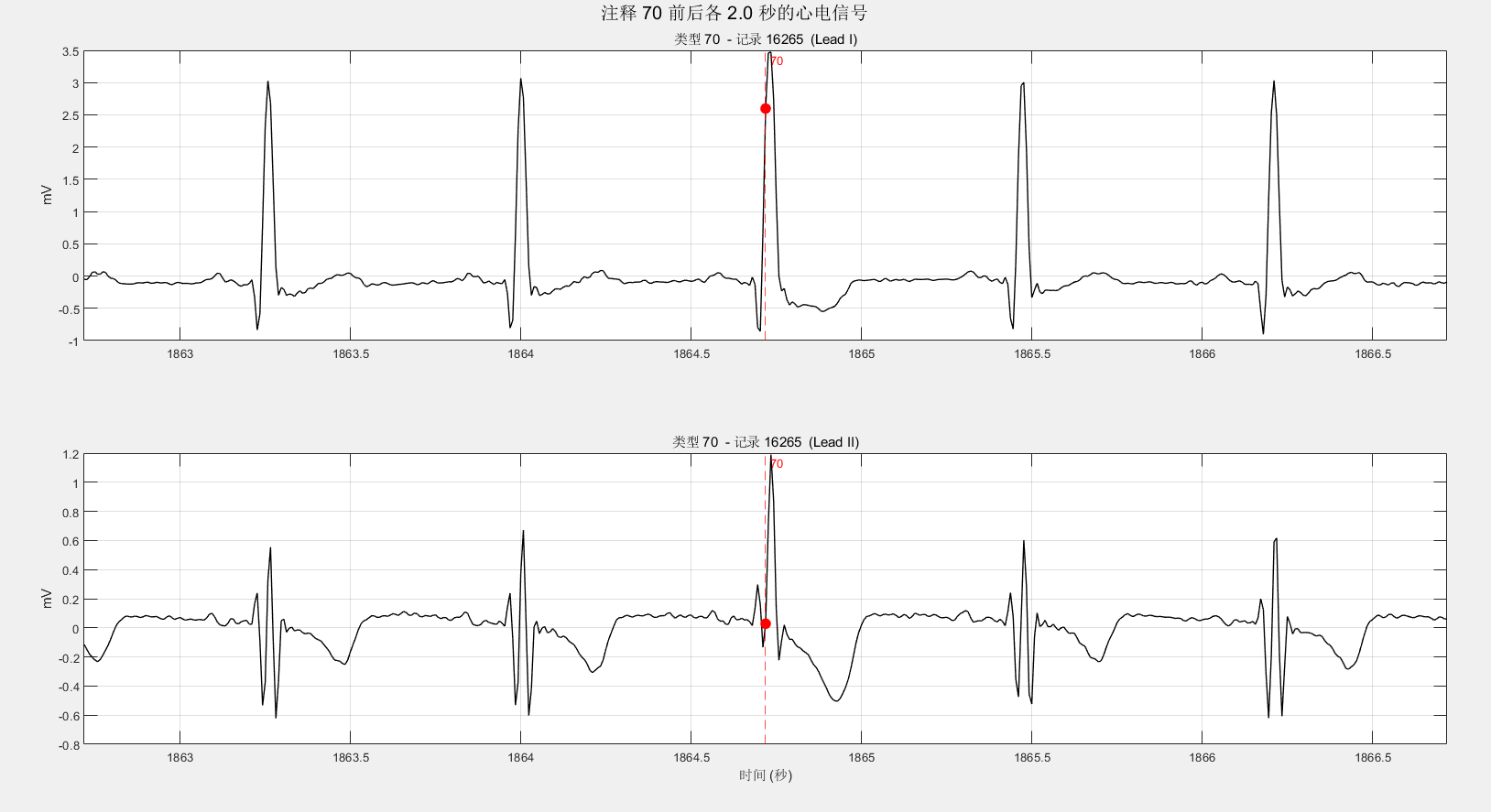
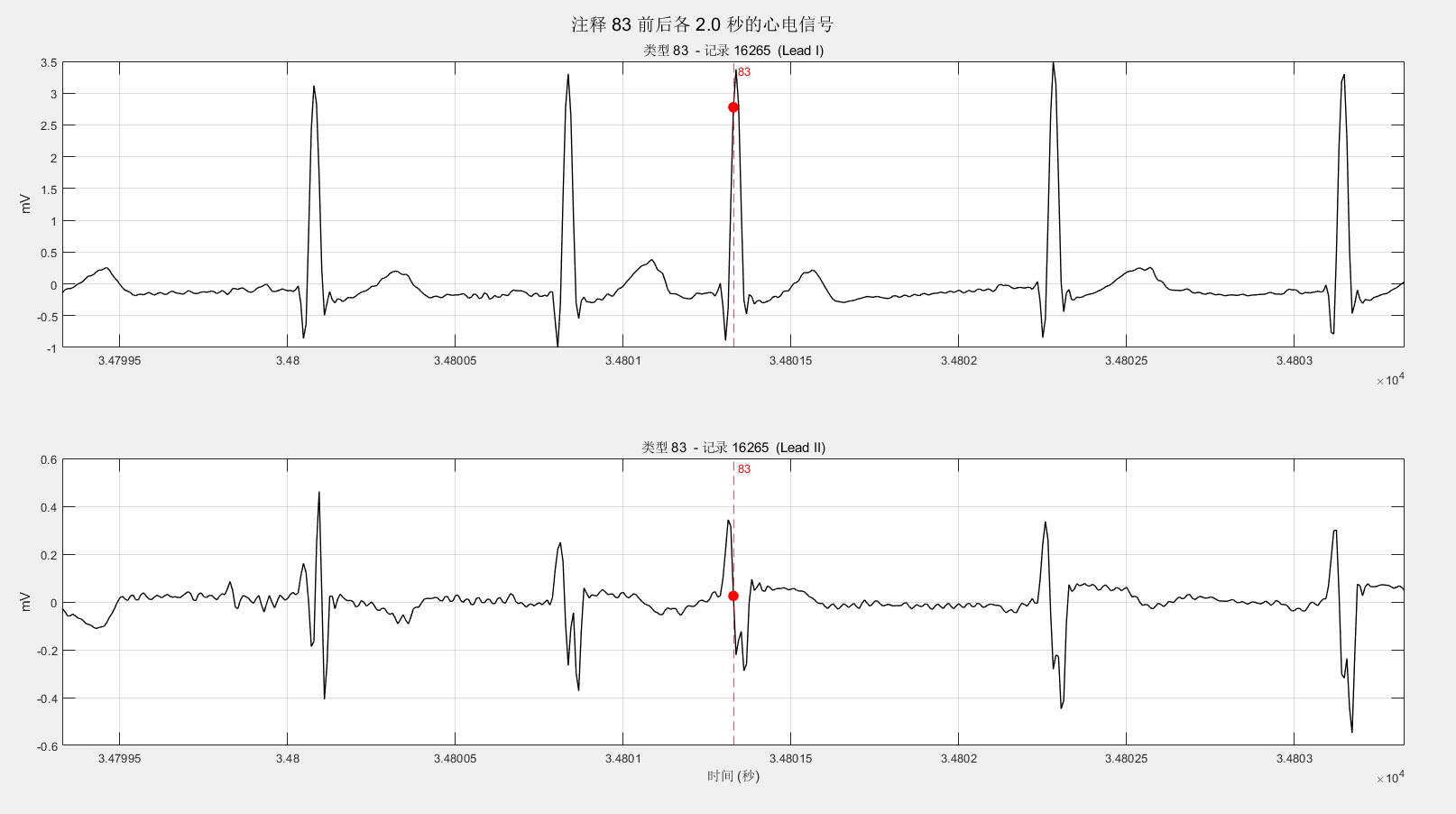
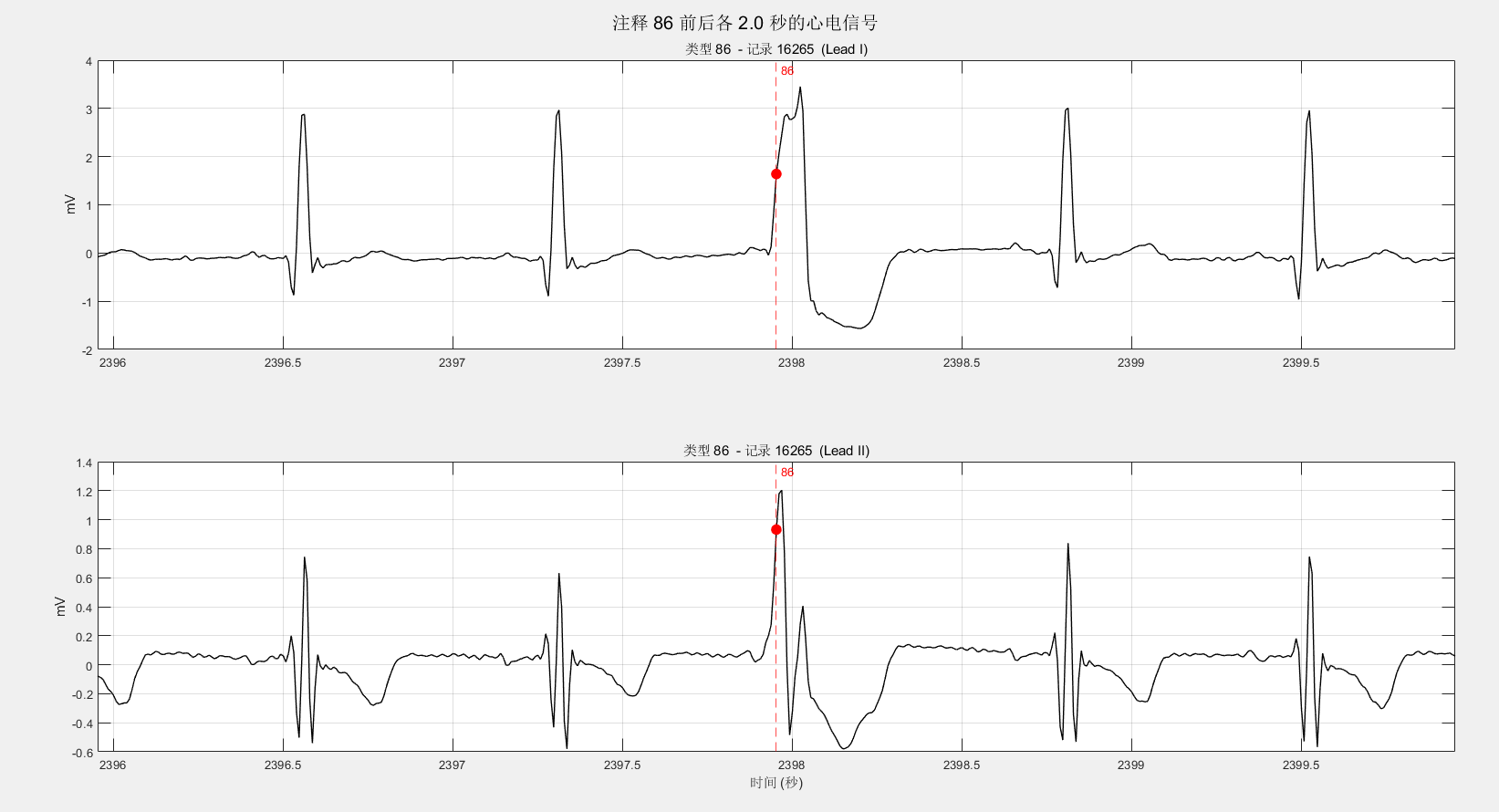
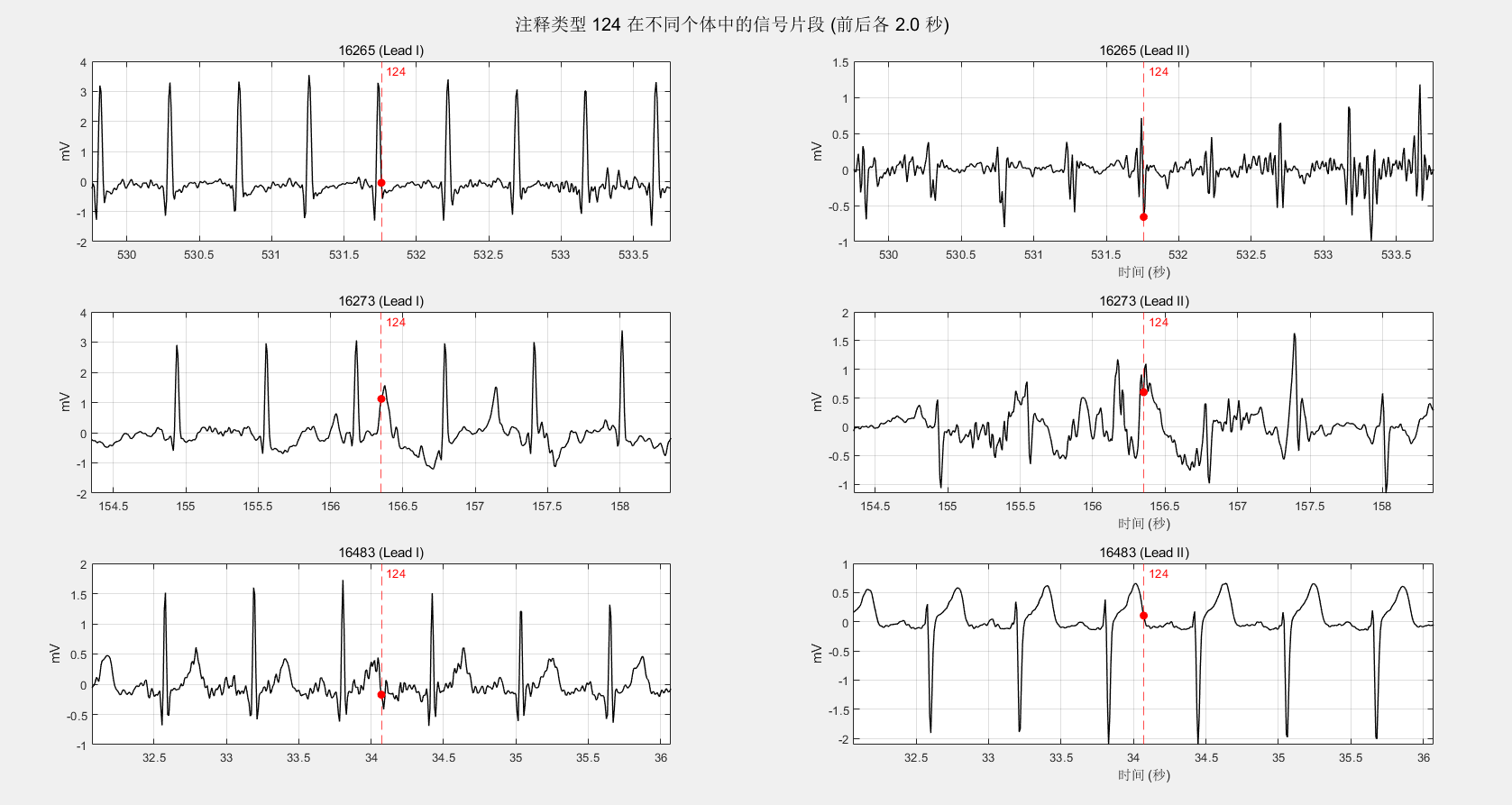
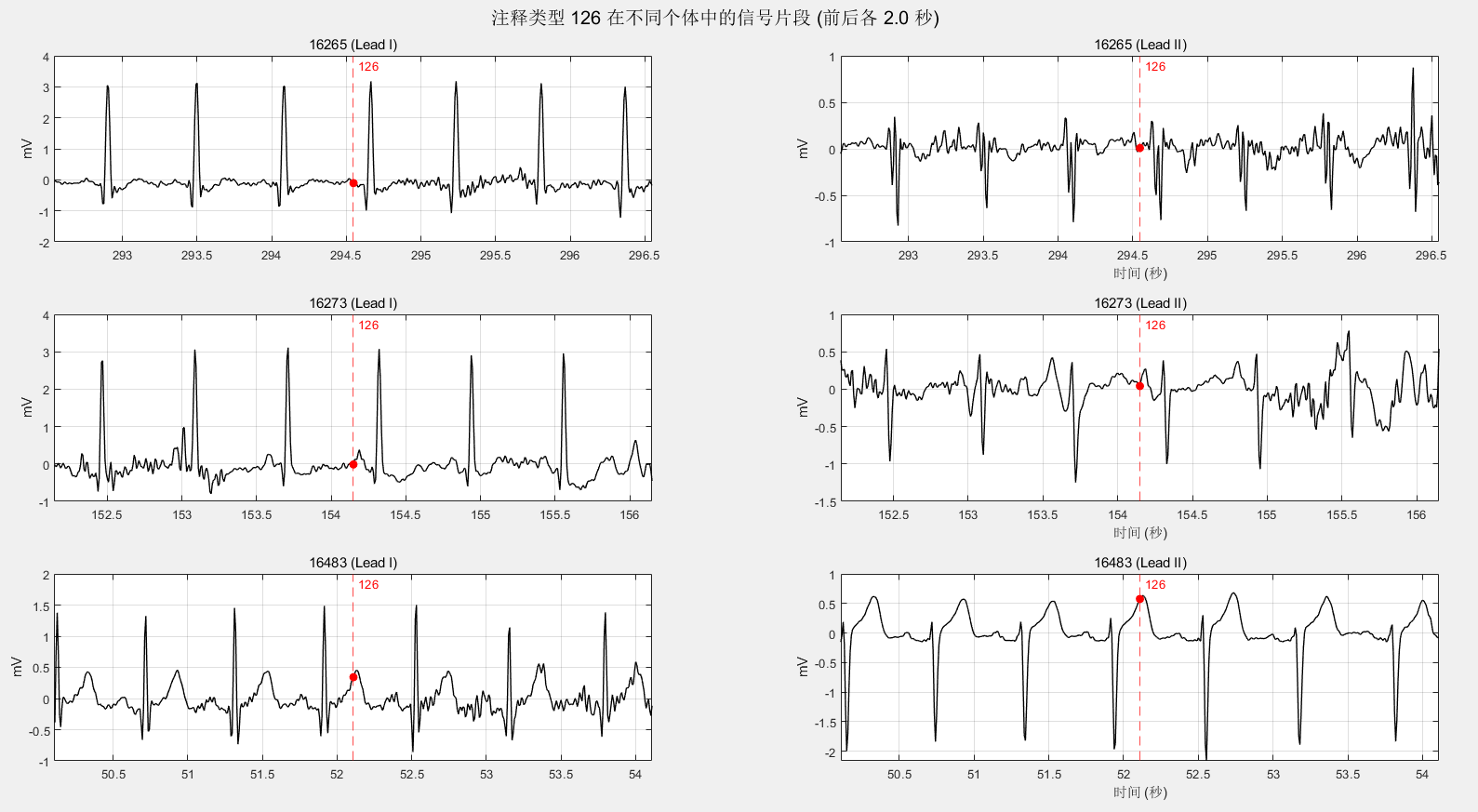 126是信号质量变化,是我关注的一点,我对比发现:并不一定是两条导联均出现质量变化。
126是信号质量变化,是我关注的一点,我对比发现:并不一定是两条导联均出现质量变化。
还有就是,它在“反复横跳”,如第一个,它的变化标签相对于正常心拍是很少的。
在124比较多的16773上,他甚至在一个时间戳上同时出现:

可视化一下前5s和前20s:
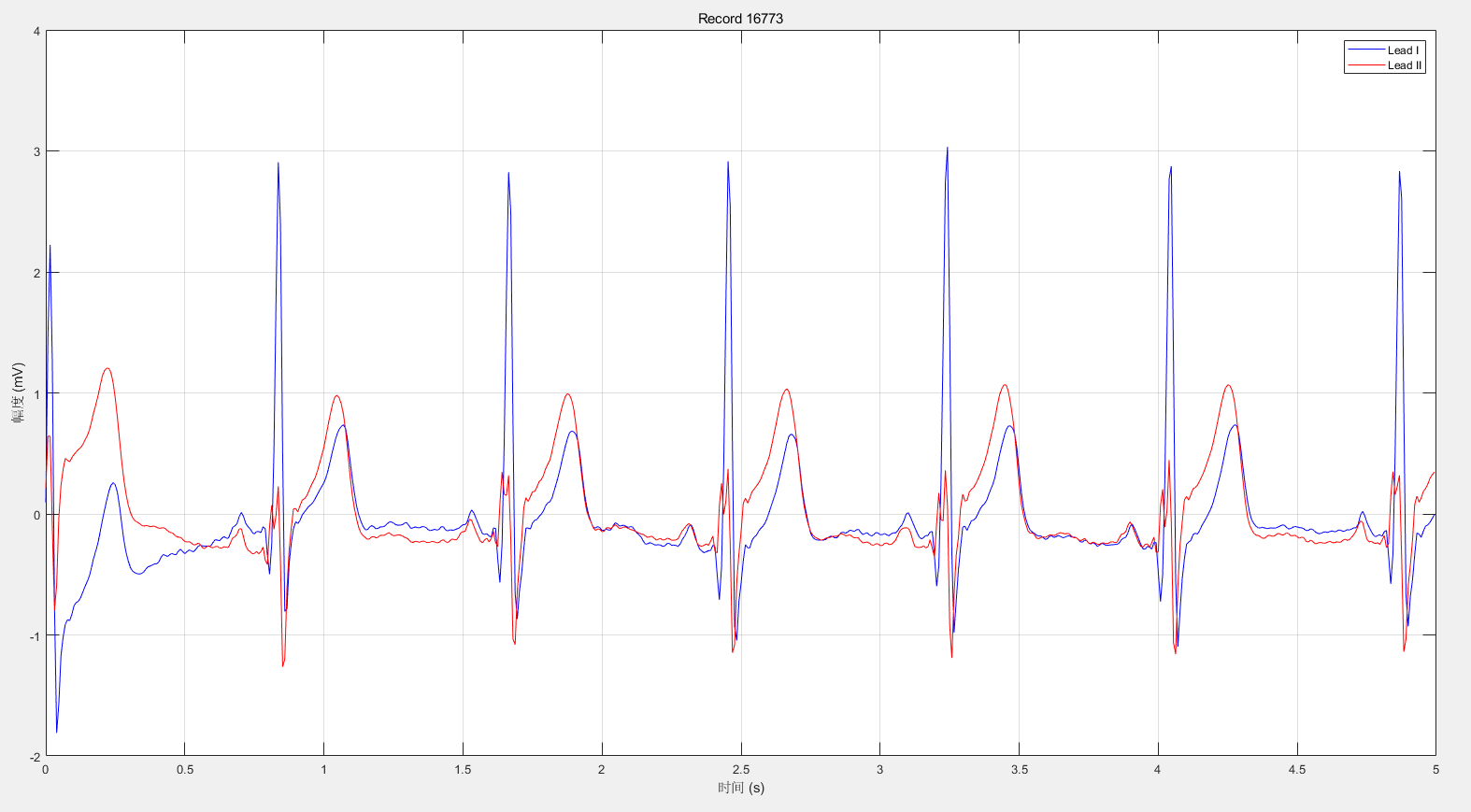
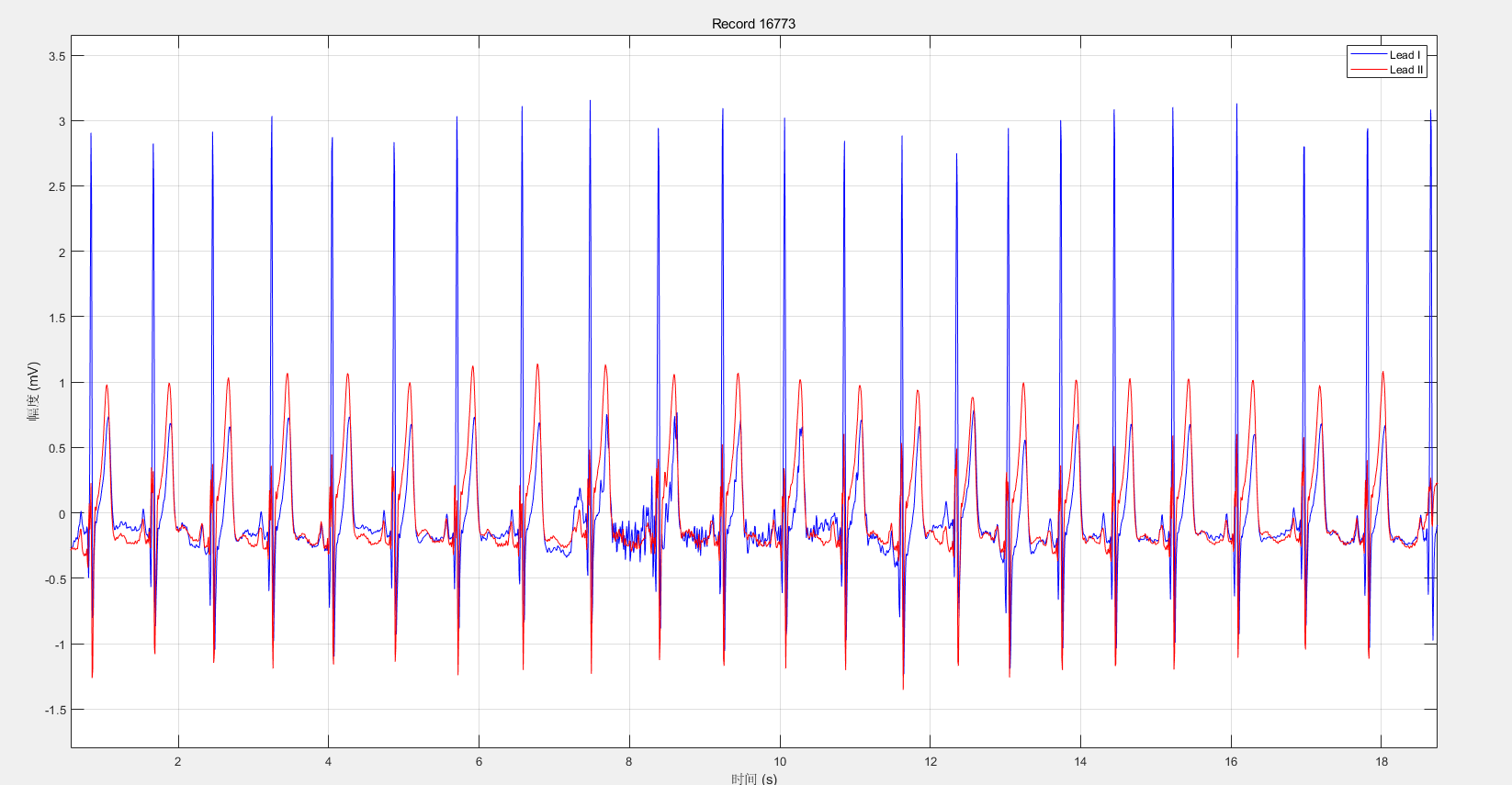
直观感觉,我并未发现有什么问题,当然我并不具备专业的医学背景,无法看懂心电图的细节问题。
同时查阅了一下相关的文献,没看到有研究对其进行清洗,大家普遍认为该数据集质量很高,是一个有效的参考数据集。所以我暂时也不大量清洗了,只针对上次发现的开头的问题进行了处理:
function [sig, Fs, tm] = readdata(recordName, dataFolder)
% 读取心电图信号,根据注释自动裁切,并进行去趋势和带通滤波
% 输入:
% recordName - 记录名称 (如 '16265')
% dataFolder - 数据文件夹路径
% 输出:
% sig - 处理后的双导联信号 [nSamples × 2]
% Fs - 采样率 (Hz)
oldFolder = cd(dataFolder);
cleanup = onCleanup(@() cd(oldFolder));
% 读取完整信号和注释
[sig_full, Fs, tm] = rdsamp(recordName);
[ann, atype] = rdann(recordName, 'atr');
% 找到所有类型78的注释位置(样本索引)
idx78 = find(atype == 78);
if length(idx78) < 2
error('记录 %s 中类型78的注释不足2个,无法裁切', recordName);
end
% 统计从开始到第二个78之间出现的124数量
second78_pos = ann(idx78(2));
idx124 = find(atype == 124);
count124_before_second = sum(ann(idx124) < second78_pos);
% 决定取第几个78
if count124_before_second >= 5 && length(idx78) >= 10
start_idx = 12; % 取第10个78
fprintf('记录 %s:前段出现 %d 个124,从第%d个78开始裁切\n', recordName, count124_before_second,start_idx);
else
start_idx = 6; % 取第5个78
fprintf('记录 %s:前段出现 %d 个124,从第%d个78开始裁切\n', recordName, count124_before_second,start_idx);
end
startSample = ann(idx78(start_idx));
if startSample > size(sig_full, 1)
error('起始样本 %d 超出信号长度 %d', startSample, size(sig_full,1));
end
% 裁切信号
sig_cropped = sig_full(startSample:end, :);
fprintf('裁切后剩余 %d 个样本\n', size(sig_cropped,1));
% ---- 去趋势和带通滤波 ----
% 对每个导联独立处理
sig = zeros(size(sig_cropped));
for lead = 1:2
% 去线性趋势
signal_detrend = detrend(sig_cropped(:, lead));
% 带通滤波器设计 (0.5 - 40 Hz)
nyquist = Fs / 2;
[b, a] = butter(4, [0.5/nyquist, 40/nyquist], 'bandpass');
% 零相位滤波
sig(:, lead) = filtfilt(b, a, signal_detrend);
end
fprintf('已完成去趋势和带通滤波 (0.5-40 Hz)\n');
end******END******

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)