收藏!小白程序员轻松入门大模型:RAG技术实践指南,助你90%准确率!
引言:RAG - LLM 应用落地的关键技术
在 LLM 浪潮爆发之后,RAG (检索增强生成) 技术因其清晰的技术路径和相对可控的实施成本,成为企业快速落地 AI 应用的重要突破口。本文将分享我们在构建企业知识库智能问答系统过程中的实践历程:如何通过系统化的优化方法,将准确率从初期的 30% 提升到 90% 的实用水平。
这不仅是一个追踪 RAG 技术演进的历程,更是一个将 LLM 技术落地为实用产品的实践案例。本文将介绍如何通过优化召回策略、选择生成模型、设计产品策略,构建一个准确性高、成本可控的 RAG 知识库问答系统,无需复杂的模型精调工作。
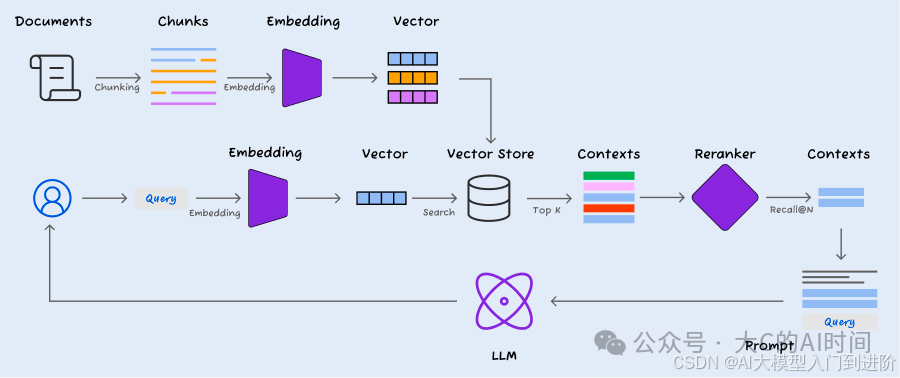
RAG流程示意图
初期探索:从简单实现到系统思考
V1 版本:基础 RAG 实践
在 2023 年下半年,我们完成了第一版基于 RAG 的知识库问答系统的上线。这个版本采用了相对简单且主流的技术方案:
- 文档预处理:采用基于三级标题的分割策略,将文档切分为 500~1000 tokens 的片段,并保留 Markdown 格式的富文本内容
- 向量化处理:使用当时表现较好的 bge-large-zh-v1.5 模型进行文本向量化
- 检索策略:结合向量搜索和基于 Elastic Search 的关键词混合检索方案,通过 RRF(Reciprocal Rank Fusion)算法融合排序
- 问答生成:选用 ChatGLM3-6B 作为基础模型,提供问题总结服务
然而,这个版本在实际运营中的表现并不理想。系统性评测结果显示,真实用户提问的回答正确率仅有约 30%。而更令人沮丧的是,在相当长的一段时间内,我们难以找到明确的优化方案。
RAG 技术远比想象中更难以提升效果。
大模型业界发展:新模型带来的转机
2023 年底至 2024 年初,大模型业界依然在狂飙突进。几个关键的技术进展为我们带来了新的思路:
- 更强大的基础模型:阿里巴巴 Qwen 系列模型的快速迭代(从 qwen1.5到 qwen2),在中文理解、指令遵循等方面都展现出显著优势,尤其是其 32k 的上下文支持能力
- 更优秀的向量模型:北京智源研究院发布的 reranker 重排序模型和bge-m3 embedding 模型,为检索优化提供了新的可能性
- 技术思路的突破:twitter 社区上出现关于 Long Context 与 RAG 技术优劣的大讨论,启发我们重新思考系统架构
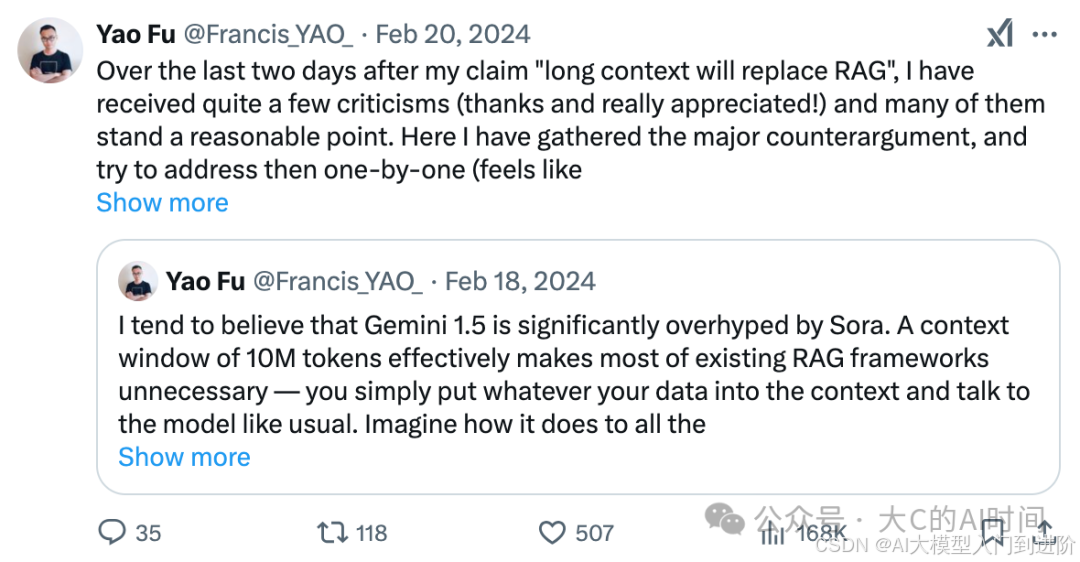
2024年初 X 上 Long Context replace RAG的讨论
通过初步测试,我们发现更长的上下文长度支持下(32k),能成倍的增加召回文档的数目,从而显著的提升问答的准确性。然而,这种提升伴随着明显的成本增长:响应时间的增加,以及 GPU 显存消耗增加。
这时就需要评估,如何平衡问答准确性与计算成本和延时?
方法论:构建系统化的评测方案
为了找到这个平衡点,我们设计了一套系统化的评测方案:
1. RAG 流程的漏斗模型
我们将 RAG 流程解构为两个关键阶段:
- 召回阶段:从知识库中检索相关文档
- 生成阶段:基于检索结果生成答案
这种分解让我们能够分别优化和评估各个环节的性能,更精确地定位瓶颈所在。
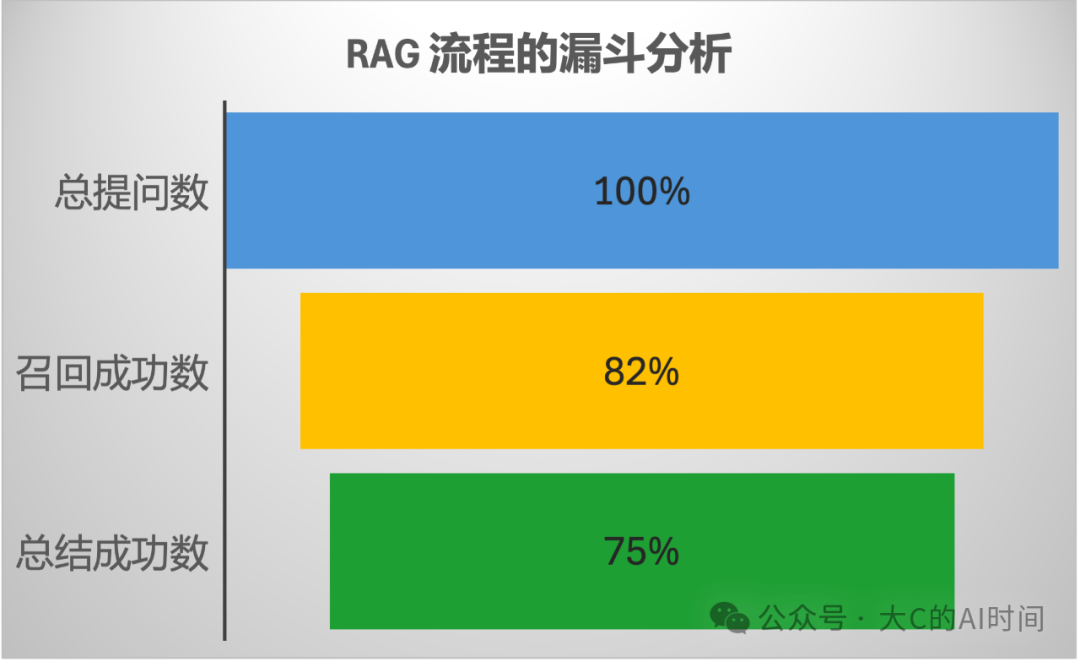
RAG流程的漏斗模型
2. 标准化评测集
我们建立了包含200个标准问题的评测集,每个问题都包括了:
- 相关文档链接
- 标准参考答案
这个评测集覆盖了不同类型和难度的问题,能够较好地模拟真实场景下的用户提问。评测的目的是评估不同 RAG 策略的相对优劣,并不等于线上真实运营的结果。
3. 量化的优化策略
基于这个评测体系,我们展开了系统性的优化工作:
召回阶段
召回阶段的目标是选择最优的文档召回策略。通过深入分析不同策略组合的特点,我们得到这些结论:
- Vector Search:速度快,适合作为粗排阶段,快速召回 Top K (20/50/100) 的文档
- **Rerank:**准确率高,但耗时较大,适合作为精排阶段,对粗排结果进一步提升正确文档的排名。实验表明,对于相同的 N 值,Rerank 比 Vector Search 的准确率普遍提升约 10%
- Recall@N:N 值越大,召回文档越多,准确率越高,但同时也增加了输送给 LLM 的 Context Length,对模型的要求也更高
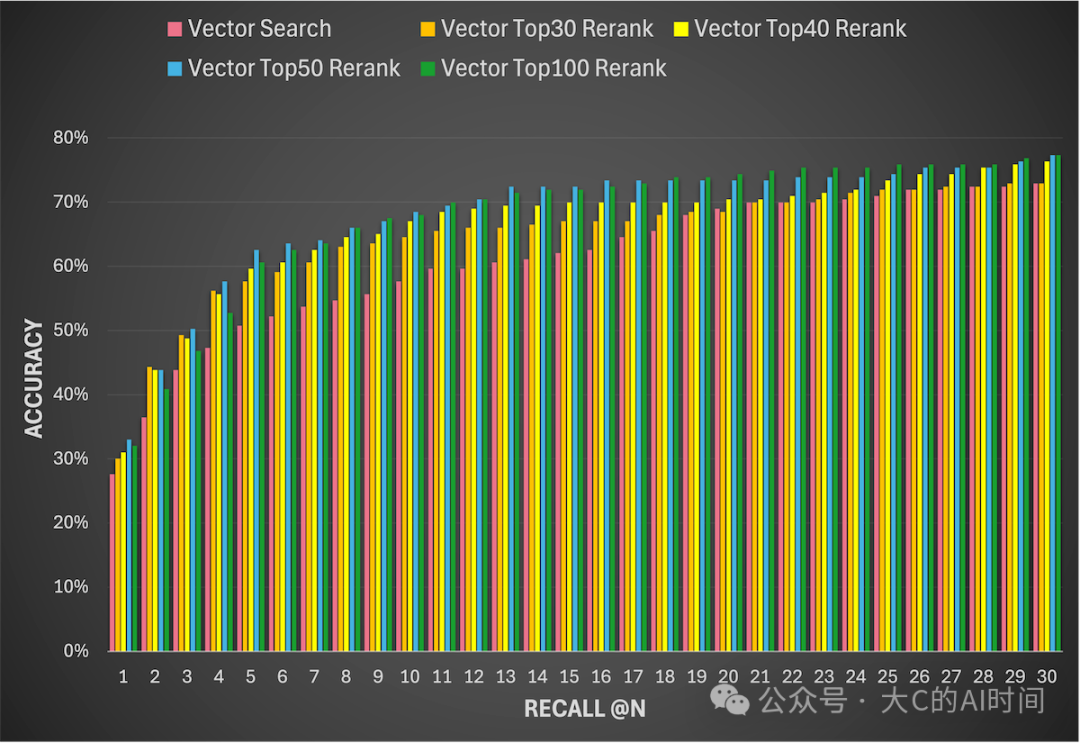
向量搜索、Rerank及TopN的评测实验
召回阶段的优化策略
- Vector Search 作为粗排,召回 Top 100 的文档
- Rerank 作为精排,从中选取 Top 15 的最相关文档
- 最终实现了约 85% 的 Recall@15 准确率
生成阶段
模型生成阶段的目标是选择性能和性价比俱佳的模型。经过多次实验和对比,我们发现 Qwen2.5-7B 模型在 10k Context Length 下,依然能保持 90% 左右的正确率,且明显优于之前使用的 ChatGLM3-6B。虽然 Qwen2.5-72B 参数更大,准确率方面有略微提升,但其对显存要求极高,并不具备经济性。
生成阶段的优化策略
- 选定 Qwen2.5-7B 作为生成模型
- 将上下文长度限制在 10k tokens,在保证性能的同时控制资源消耗
- 最终模型达到了约 90% 的生成准确率
产品化思考:技术之上的产品优化
我们逐渐意识到,仅依靠模型技术的优化是不够的。要建设一个真正好用的知识库问答系统,需要从产品和用户体验的角度进行全方位提升:
1. 文档体系建设
大模型素有 “garbage in, garbage out” 的说法。这强调了文档质量的重要性。不但要写好文档,更需要 “面向LLM” 写文档。因此在文档建设方面:
- 补充高频文档:针对性补充常见问题的标准答案,效果立竿见影
- 面向 LLM 写文档:确保文档背景知识完整、语义清晰、对模型友好
2. 用户交互优化
我们观察到用户在不同场景下的提问有差异性,并且用户可能无法准确描述问题。因此在产品设计方面:
- 设计场景化的问题推荐,引导用户更准确地表达问题
- 提供答案反馈机制,持续收集用户反馈进行优化
成果与思考
通过上述系统性优化,我们最终实现了:
- 召回阶段:正确文档召回率达到 95%
- 生成阶段:生成答案准确率达到 90%
这个结果意味着可以投入生产运营中,我们的系统已经为大多数用户提供切实有效的帮助。
整个优化过程也让我们获得了一些重要经验:
1. 系统化方法的重要性:通过建立标准评测体系和量化指标,我们能够更客观地评估不同优化策略的效果
2. 平衡性能与成本:不必一味追求最大参数的 LLM,优秀的 7B 级别的小模型已经足以解决好 RAG 场景
3. 产品设计的必要性:技术优化需要与产品设计优化相结合,才能扬长避短的落地 LLM 应用
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】
大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:
04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)
05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!
06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 19
19 0
0- 0



 已为社区贡献70条内容
已为社区贡献70条内容

所有评论(0)