基于上一篇对 Vibe Coding 使用技巧的具体实战流程
在上一篇文案中,我写了一些关于 Vibe Coding 的使用技巧,但是光凭理论是不行的。所以我写了这一篇文章,如何全程利用 Cursor 写一个多平台视频下载工具。这篇文章同时是对上一篇文章的一个实践演示。接下来进入正题。
规划部分
首先我们第一步就是让自己变成“系统架构者”,我们应该明确目标:“我想要制作通过输入视频链接然后可以把视频保存到本地的工具”,怀着这个想法我们可以去询问 AI (当然你也可以自己进行规划),这个项目不算复杂,我们可以很快的列出它的核心功能:
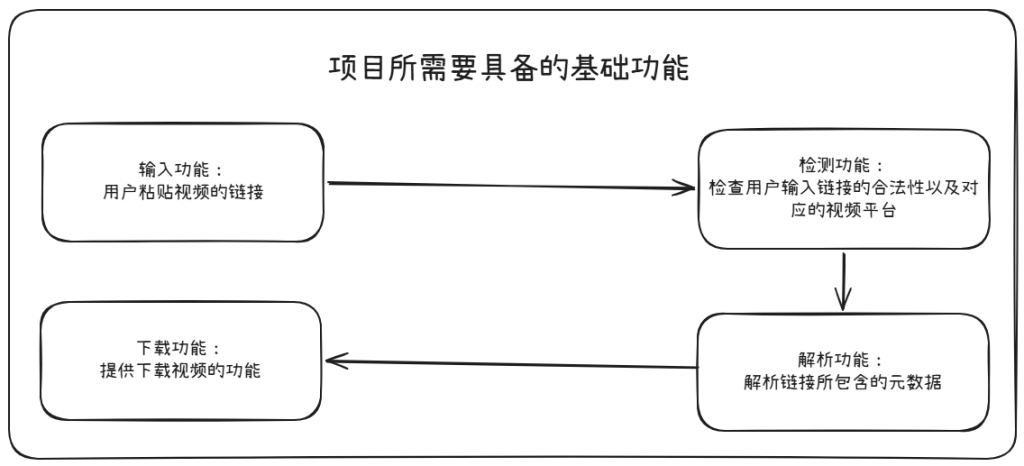
这里我们会用到的工具如下:
- Streamlit :傻瓜式构建可视化 web 的 Python 神器(前端UI部分)
- yt-dlp :一个基于 youtube-dl 的命令行音视频下载工具(解析下载部分)
- ffmpeg :用于处理音视频等多媒体资源的工具(合并下载出来的音乐和视频文件
到目前为止规划已经很明显了我们最终要求为:
- 一个干净、现代、响应式的 Streamlit Web 应用
- 粘贴任意视频链接→ 自动识别平台 → 显示视频信息 → 用户勾选清晰度 → 一键下载(使用 ffmpeg 合并音视频)→ 下载完成后显示本地路径
- 使用 Python + Streamlit + yt-dlp + FFmpeg 进行开发
开发部分
接下来就是正式开发部分了,在进入我们的编译工具(我使用的是 Cursor )在侧边栏输入我们的提示词,如果觉得自己写的提示词不好或者不想麻烦的话可以把我们上面的规划内容发送给 AI 让它给我们生成一个提示词,我的提示词如下:
“你是一位精通 Python、Streamlit、yt-dlp 和 FFmpeg 的高级全栈工程师。项目最终要求:干净、现代、响应式的 Streamlit Web 应用;支持用户粘贴任意视频链接→ 自动识别平台 → 显示视频标题、封面、时长、所有可用清晰度 → 用户选择清晰度 → 一键下载(自动用 ffmpeg 合并音视频)→ 显示本地路径;未来可扩展新功能。请先创建目录结构,生成对应的requirements.txt填写所需依赖,生成 config.py 文件填写用户默认保存路径和FFmpeg 路径自动检测(如果系统有就用系统路径,没有就提示用户安装),生成 memory-bank/project-memory.md 填写上项目当前阶段和已完成功能以及未完成功能。具体代码暂时不用生成“(以上由 Gork 生成)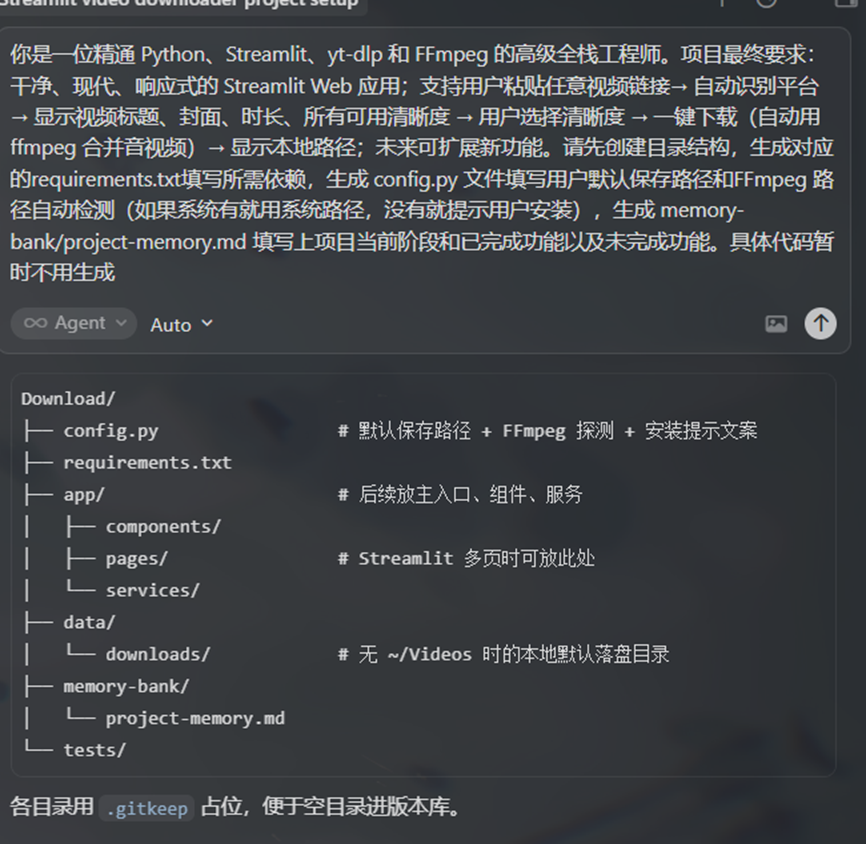
我们可以看到,文件的框架十分清晰,下一步就是在框架之下填充对应代码了
按照我们的规划,首先应该实现输入功能,不过流程是死的但人是活的,这里我们可以进行一些调整,比如将输入链接和解析链接合并为一个整体,在这个整体上预留出解析功能的下载功能的接口。那么将输入和解析合并在一起有什么好处呢?其实本质上就是把“收数据”和“验数据”这两个紧密相关的动作放在一起处理,做到一种“输入即校验”的作用。在用户输入链接后系统可以立即告知链接是否有效、格式是否正确或是否为支持的平台。同时也提高了内聚性,因为输入和检测本质上都是对“原始数据”的处理。
基于这种因素,我们选择将输入和解析合并成一个总体,因为我们计划采用 yt-dlp 来实现解析链接的功能,所以在提示词中我们要明确的表述出来,让 AI 在代码之中按照 yt-dlp 的规范进行生成,提示词如下:
“请生成输入功能和检测功能的对应代码,这两个功能实现在同一个代码文件中。其中要求如下:用户输入网页链接后使用 yt-dlp 解析链接所对应的视频平台并显示当前视频的信息(如标题,封面图片URL,视频时长,平台名称等可用内容),接着按照清晰度从高到底排序。并且做好错误处理当链接无效、平台不支持、网络错误时,抛出错误异常。预留调用解析代码的接口。如果生成过程中需要参考 yt-dlp 最佳实践,请自行回忆或使用标准方式。”在有了初步的提示词后,我们可以使用 AI 进行迭代优化。
优化后的提示词:
你现在是一位精通 Python、Streamlit、yt-dlp 的高级全栈工程师。我们正在使用 Vibe Coding 的模块化渐进法开发多平台视频下载器。
当前阶段:已完成项目初始化,正在开发输入功能 + 平台检测功能,并要求这两个功能合并在同一个代码文件中。
请生成 components/input_section.py 文件(将输入功能和检测平台功能完全实现在这一个文件中,不要拆分)。
具体要求如下:
1. 实现一个 Streamlit 组件:
- 使用 st.text_input 让用户粘贴视频链接(默认提示文字为“粘贴视频链接(支持 YouTube、Bilibili、Twitter 等)”)
- 添加一个“解析视频”按钮
- 点击后使用 st.spinner 显示“正在解析...”
- 成功后以现代卡片式布局显示视频信息:标题、平台名称、封面图片(使用 st.image)、时长(秒转 mm:ss)、其他可用元数据
2. 核心解析逻辑使用 yt-dlp 最佳实践:
- 导入:from yt_dlp import YoutubeDL
- from yt_dlp.utils import DownloadError, ExtractorError
- 使用以下 ydl_opts:
{
'quiet': True,
'no_warnings': True,
'extract_flat': False,
'ignoreerrors': False
}
- 调用 ydl.extract_info(url, download=False) 获取完整元数据
- 自动检测平台名称:info.get('extractor_key') 或 info.get('ie_key')
- 提取字段:title、thumbnail、duration、webpage_url、uploader 等
3. 清晰度处理:
- 从 info['formats'] 中过滤有效视频格式(vcodec != 'none' 且有 height)
- 按清晰度从高到低排序(优先 height,其次 fps)
- 生成适合前端显示的列表:[{"id": format_id, "label": "1080p 60fps MP4 (约 XXX MB)", "format": ...}]
4. 错误处理:
- 链接无效、平台不支持、网络错误时,必须抛出自定义异常(带中文提示,例如 raise ValueError("❌ 链接无效或平台不支持,请检查后重试"))
- 在 Streamlit 组件中捕获异常并使用 st.error 友好显示
5. 预留接口(重要):
- 提供一个纯后端可复用函数:
def extract_video_metadata(url: str) -> dict:
# 返回结构化字典:{"title": , "thumbnail": , "duration": , "extractor": , "formats": sorted_list, "error": None 或错误信息}
- 这个函数可以被 future 的 downloader.py 直接 import 调用
6. 代码风格:
- 简洁、可读、添加详细中文注释
- 使用类型提示
- 现代 UI:使用 st.columns、st.expander、卡片布局
- 整个文件自包含(不需要 import 其他 core 文件的 detector)
请先生成完整的 components/input_section.py 代码。
生成完成后:
- 告诉我“✅ 已生成 components/input_section.py”
- 简要说明如何在 main.py 中调用这个组件
- 自动将本次进展更新到 memory-bank/project-memory.md(当前阶段:输入+检测合并模块已生成,下一步计划:downloader.py)
随后我们如愿以偿的完成了第一步,接着就是解析+下载功能了,在这一步我们依旧先列出我们需要完成的目标:
- 用户选择清晰度(从 input_section.py 传来的格式列表)
- 使用 yt-dlp 下载(支持视频+音频分离格式)
- 自动调用 FFmpeg 合并音视频为单个 MP4 文件
- 显示实时下载进度条(Streamlit 兼容)
- 下载完成后显示本地保存路径 + 打开文件夹按钮
- 友好错误处理 + 中文提示
- 预留未来扩展接口(历史记录、单独下载封面/字幕等)
具体操作方法同上,我们首先跟据目标生成提示词然后反复进行迭代优化后让 AI 生成相对应的代码。两个核心功能(输入/检测功能和解析/下载功能)就像是两块独立的拼图一样,接下来我们需要一个接口把两个功能链接在一起。一个主文件入口 main.py 由此出现,它的作用就是将 input_section.py和downloader.py组合起来。在总体代码完成之后我们就可以进入到了调试部分
调试部分
首先输入 “pip install -r requirements.txt“ 安装运行所需的依赖,接着 ”streamlit run main.py“ 运行程序,注意由于我们使用是 FFmpeg 所以需要先配置好系统变量,这样我们的程序才可以直接调用 FFmpeg 。同时因为我的前端使用的是 Streamlit 框架所以在第一次运行时会有这样一个弹窗:
回车略过即可,随后编译器自动给我们打开了一个网页,整体界面如下:
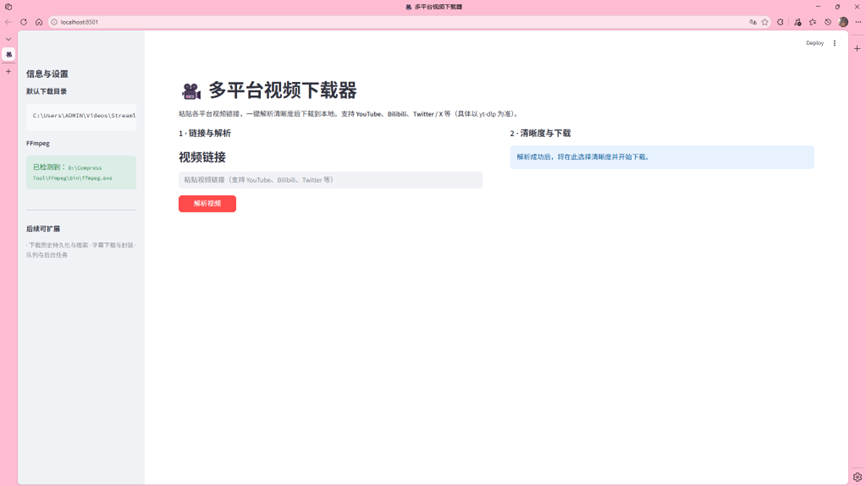
看上去很完美,接下来我们复制一个视频链接输入进去,实际测试一下...不过好像出了一点问题,在询问 AI 之后我们得到了原因:

我们需要新鲜的曲奇才能进行解析,那么如何获得曲奇呢?(当然是去蛋糕店买一点了)
我们在浏览器上安装拓展:
![]()
接着在对应的视频平台下使用这个拓展工具下载导出我们的 cookies.txt 文件,将文件贴在项目根目录然后再让 AI 进行优化生成读取 cookies.txt 的代码。随后我们再次进行测试。效果如下:
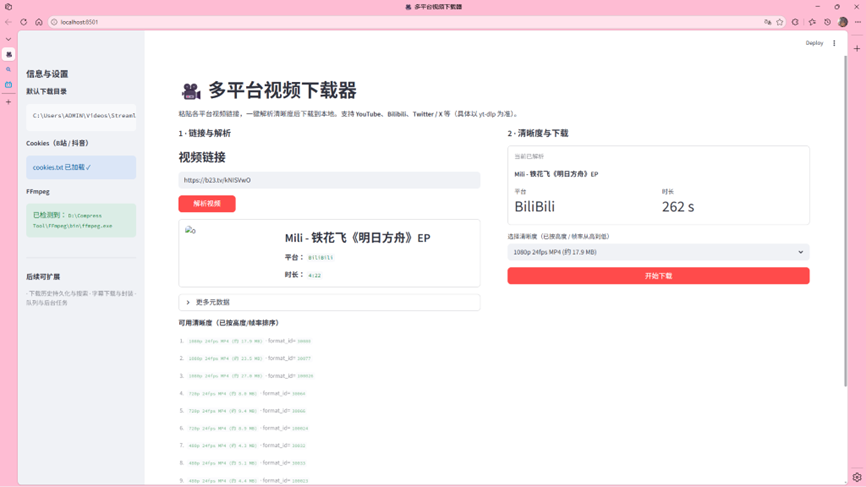
这次没有问题了,我们点击 ”开始下载“ 接着出现进度条,然后下载完毕之后自动调用 FFmpeg 把下载的音频和视频合并,点开默认下载目录后我们就看到了最终成品
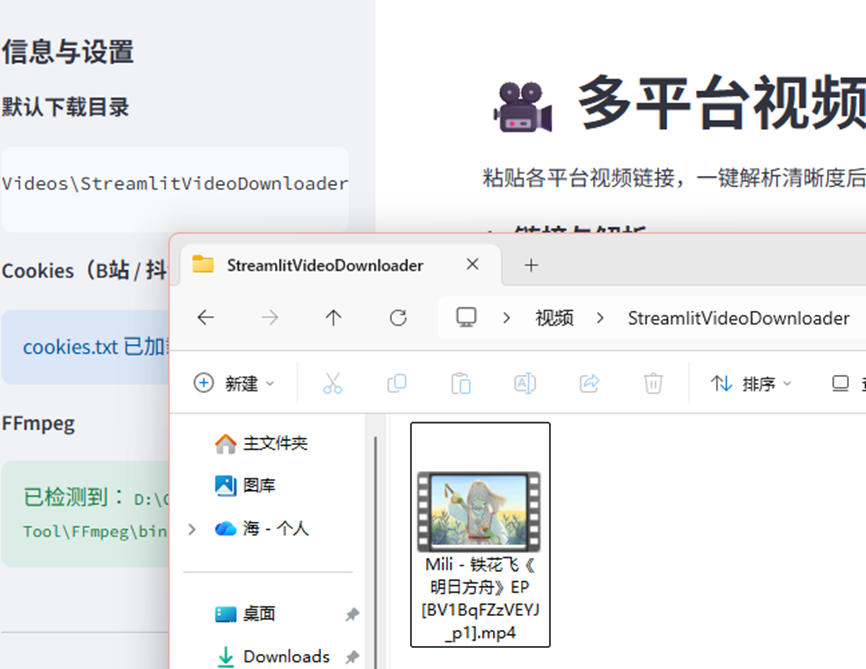
恭喜!!!我们的项目成功完成了。
现在我们进行一下总结:
第一步:明确项目内容和目的,划分出粗略的功能模块
第二步:进入开发流程,按照功能模块依靠 AI 不断优化提示词生成可运行代码
第三步:实际运行代码,检查是否存在漏洞。如果存在漏洞则重新回到第二步进行调试
第四步:运行后未发现问题可以将其作为测试版发布到开源社区或者其他服务上运行,在实际运行中继续发现新问题进行优化
注意:本教程所演示的内容仅供参考和学习,不涉及任何商业元素
项目仓库:https://github.com/asJEI/Multi-platform-video-downloader

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 13
13 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)