智能体 JSON 处理防护与优化方案(实战版)
·
在基于大模型的智能体系统中,JSON 是最常见的数据交换格式。但在实际落地中,常见问题包括:
- JSON 格式错误(多余逗号、缺括号、单双引号混用)
- 字段缺失或多余
- 类型错误(字符串/数字混乱)
- 枚举值不符合规范
- 输出夹杂解释性文本
这些问题如果不做防护,会直接影响系统稳定性。
本文给出一套简洁可落地的 JSON 防护方案,核心思路是:
“约束生成 → 严格校验 → 有限修复 → 可控重试”
一、总体架构
推荐的处理链路如下:
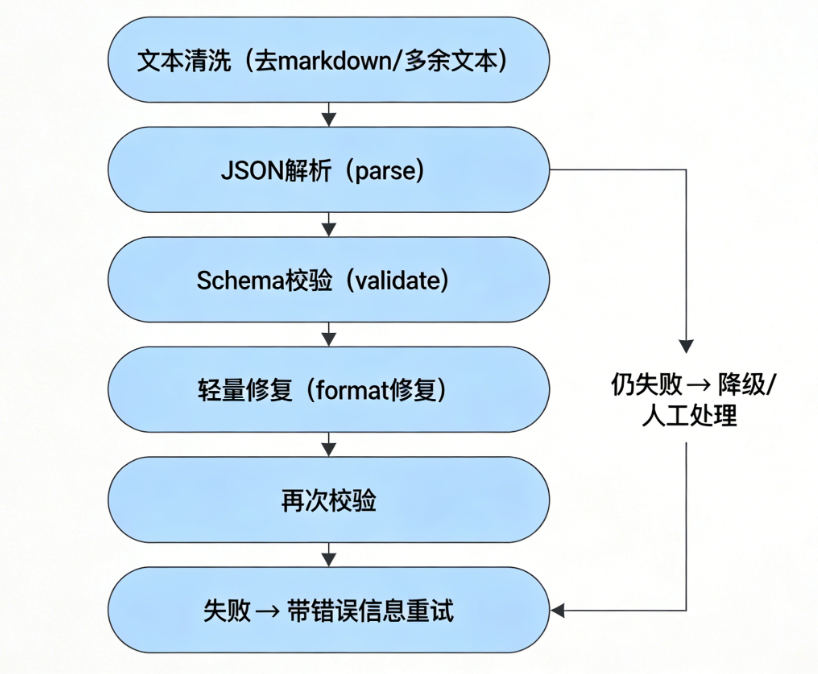
二、生成阶段:减少错误的关键
1. 使用 Schema 强约束
为所有 JSON 定义结构:
{
"type": "object",
"properties": {
"task": { "type": "string" },
"priority": {
"type": "string",
"enum": ["low", "medium", "high"]
},
"deadline": {
"type": "string",
"format": "date"
}
},
"required": ["task", "priority"],
"additionalProperties": false
}
关键点:
- 必填字段(required)
- 类型约束
- 枚举限制(enum)
- 禁止额外字段(additionalProperties: false)
2. Prompt 强约束输出
请严格输出合法 JSON:
1. 仅输出一个 JSON 对象
2. 不要使用 ```json
3. 不要添加任何解释或注释
4. 所有字段必须符合 schema
3. 提供标准示例
正确示例:
{
"task": "整理日报",
"priority": "high",
"deadline": "2026-04-10"
}
错误示例:
下面是结果:
{
"task": "整理日报",
"priority": "urgent"
}
三、解析与校验阶段(必须做)
1. 解析 + 校验,而不是只解析
data = json.loads(text)
validate(data, schema)
说明:
能解析≠合法- 必须做 schema 校验
2. 标准错误结构
{
"error": "SCHEMA_VALIDATION_FAILED",
"details": [
{
"field": "priority",
"message": "must be one of [low, medium, high]"
}
]
}
四、自动修复(有限度)
1. 可自动修复的问题
- 单引号 → 双引号
- 去除尾随逗号
- 去掉 markdown ```json
- 剥离前后解释文本
- Python 值转 JSON(True → true)
2. 不要修复语义错误
❌ 错误示例:
"priority": "urgent"
不要自动改为:
"priority": "high"
原因:这是业务语义,不是格式问题。
五、重试机制(关键稳定器)
1. 带错误信息重试
你的 JSON 不合法,问题如下:
1. priority 不在枚举范围
2. deadline 格式错误
请修复并重新输出完整 JSON。
2. 控制重试次数
建议策略:
- 自动修复:1 次
- 带反馈重试:1~2 次
- 超过次数 → 降级处理
六、字段设计优化(减少模型出错)
1. 简化字段名
推荐:
{
"task": "xxx",
"priority": "high"
}
避免:
{
"taskPriorityLevel": "high"
}
2. 使用枚举替代自由文本
"priority": ["low", "medium", "high"]
3. 统一数据格式
| 类型 | 规范 |
|---|---|
| 日期 | YYYY-MM-DD |
| 时间 | ISO 8601 |
| 布尔 | true / false |
| 金额 | 数字,不带单位 |
| 空值 | null |
七、复杂 JSON 的处理策略
1. 两阶段生成
- 第一步:生成内容(自然语言/结构草稿)
- 第二步:转换为 JSON
2. 拆分大对象
不要一次生成超大 JSON:
- 基础信息
- 配置
- 元数据
最后由程序合并。
优先使用结构化输出能力
如:
- function calling
- JSON mode
- response schema
比纯 prompt 更稳定。
八、参考实现
raw = llm_output()
cleaned = clean_text(raw)
try:
data = json.loads(cleaned)
except:
cleaned = repair_json(cleaned)
data = json.loads(cleaned)
errors = validate(data, schema)
if errors:
retry_prompt = build_retry_prompt(errors)
raw2 = llm_output(retry_prompt)
cleaned2 = clean_text(raw2)
data2 = json.loads(cleaned2)
errors2 = validate(data2, schema)
if errors2:
raise Exception("final validation failed")
return data2 if errors else data
总结
让智能体稳定处理 JSON 的关键不是“让模型一次就对”,而是构建一个可靠的数据处理链路:
✅ 前端约束生成
✅ 中间严格校验
✅ 后端有限修复
✅ 异常可控重试
最终目标是:
即使模型不完美,系统仍然稳定

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)