Gemma-4-31B-it 在 DGX Spark 上的性能测试结果
以下是 Gemma-4-31B-IT 在 DGX Spark 上的性能测试结果,数据来自 2026 年 4 月 2 日(模型发布当天)NVIDIA 开发者论坛发布的初步基准测试。
🖥️ 测试硬件环境
| 规格 | 数值 |
|---|---|
| 架构 | Grace Blackwell Superchip(GB10) |
| 统一内存 | 122 GB LPDDR5X |
| 内存带宽 | ~273 GB/s |
| 平台 | Ubuntu 24.04, aarch64 |
| CUDA | 13.0(驱动 580.142) |
部署使用官方 Docker 镜像 vllm/vllm-openai:gemma4-cu130,上下文窗口配置为 256K tokens(262144),KV cache 类型为 fp8。
📊 测试模型对比
| 模型 | 量化方式 | 磁盘大小 |
|---|---|---|
| gemma-4-31B-it | bf16 | ~62 GB |
| gemma-4-31B-it-AWQ-8bit | int8 | ~33 GB |
| gemma-4-31B-it-AWQ-4bit | int4 | ~20 GB |
| gemma-4-26B-A4B-it(MoE) | bf16 | ~49 GB |
⚡ Prompt 处理吞吐量(t/s,越高越好)
| 模型 | pp128 | pp512 | pp2048 |
|---|---|---|---|
| 31B bf16 | 244 ± 46 | 757 ± 67 | 1066 ± 48 |
| 31B AWQ int8 | 267 ± 26 | 399 ± 33 | 430 ± 0 |
| 31B AWQ int4 | 545 ± 104 | 778 ± 39 | 810 ± 2 |
| 26B-A4B MoE | 429 ± 165 | 1299 ± 441 | 3105 ± 372 |
🔤 Token 生成(解码)吞吐量(t/s,越高越好)
| 模型 | tg128 | 峰值 |
|---|---|---|
| 31B bf16 | 3.7 ± 0.1 | 4.0 |
| 31B AWQ int8 | 6.5 ± 0.1 | 7.0 |
| 31B AWQ int4 | 10.6 ± 0.0 | 11.0 |
| 26B-A4B MoE | 23.7 ± 0.0 | 24.0 |
⏱️ 首次响应时间(ms,越低越好)
| 模型 | TTFR pp128 | TTFR pp512 | TTFR pp2048 |
|---|---|---|---|
| 31B bf16 | 547 ± 91 | 686 ± 64 | 1929 ± 89 |
| 31B AWQ int8 | 490 ± 51 | 1297 ± 108 | 4761 ± 2 |
| 31B AWQ int4 | 247 ± 46 | 664 ± 33 | 2533 ± 8 |
| 26B-A4B MoE | 371 ± 176 | 464 ± 197 | 672 ± 82 |
本地实测:
部署参数:4并发,70%显存占用
| 参数 | 含义 |
|---|---|
--model /home/admin/models/modelscope/gemma-4-31B-it |
模型路径,指定 Gemma 4 31B 指令微调版的位置 |
--served-model-name gemma-4-31b |
对外暴露的模型名称,API 调用时使用的标识名 |
--enable-auto-tool-choice |
启用自动工具选择,让模型自动决定是否调用工具 |
--tool-call-parser pythonic |
工具调用解析器格式,使用 Python 风格的工具调用格式 |
--reasoning-parser gemma4 |
推理解析器,专门用于解析 Gemma 4 模型的推理输出格式 |
--gpu-memory-utilization 0.70 |
GPU 内存使用率上限,限制使用 70% 的显存,预留空间给其他进程 |
--host 0.0.0.0 |
监听地址,绑定到所有网络接口,允许外部访问 |
--port 30000 |
服务端口,容器内部监听端口(与 Docker 映射的 30000 对应) |
--kv-cache-dtype fp8 |
KV 缓存数据类型,使用 8 位浮点量化,减少显存占用 |
--load-format safetensors |
模型加载格式,使用 SafeTensors 格式(更安全、加载更快) |
--enable-prefix-caching |
启用前缀缓存,对相同前缀的输入复用 KV 缓存,加速推理 |
--enable-chunked-prefill |
启用分块预填充,将长输入分块处理,减少显存峰值占用 |
--max-model-len 262144 |
最大上下文长度,支持 262,144 tokens(约 20 万字) |
--max-num-seqs 4 |
最大并发序列数,同时处理 4 个请求序列 |
--max-num-batched-tokens 8192 |
最大批处理 token 数,每个批次最多处理 8192 个 token |
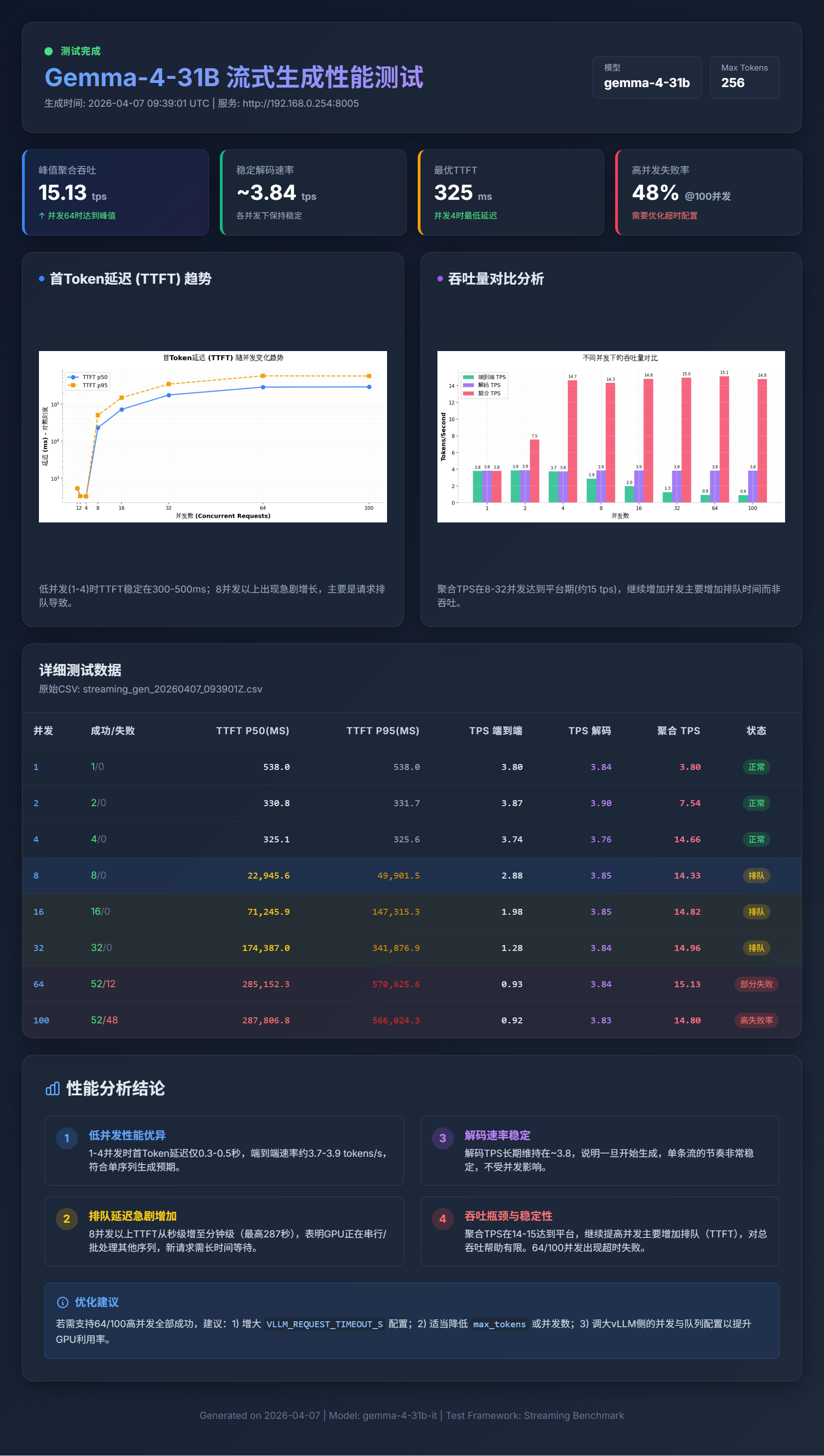
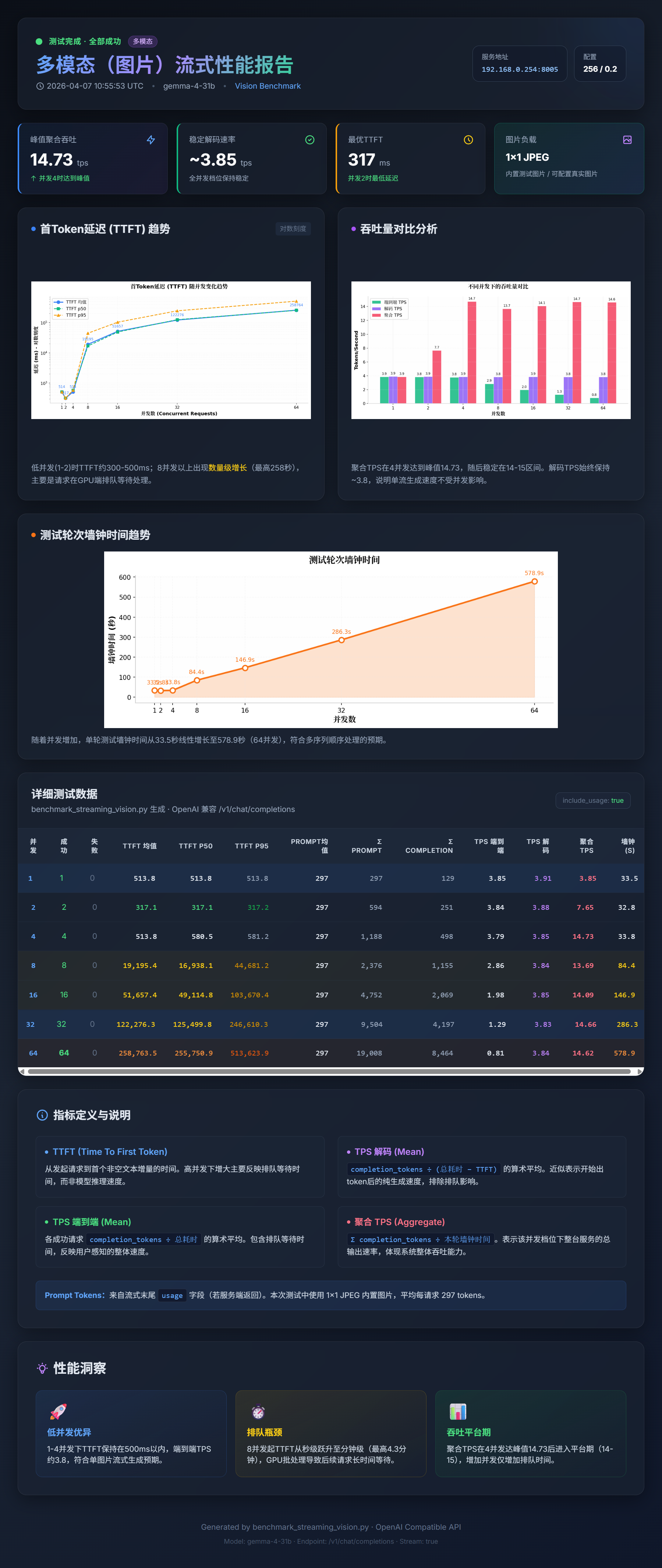
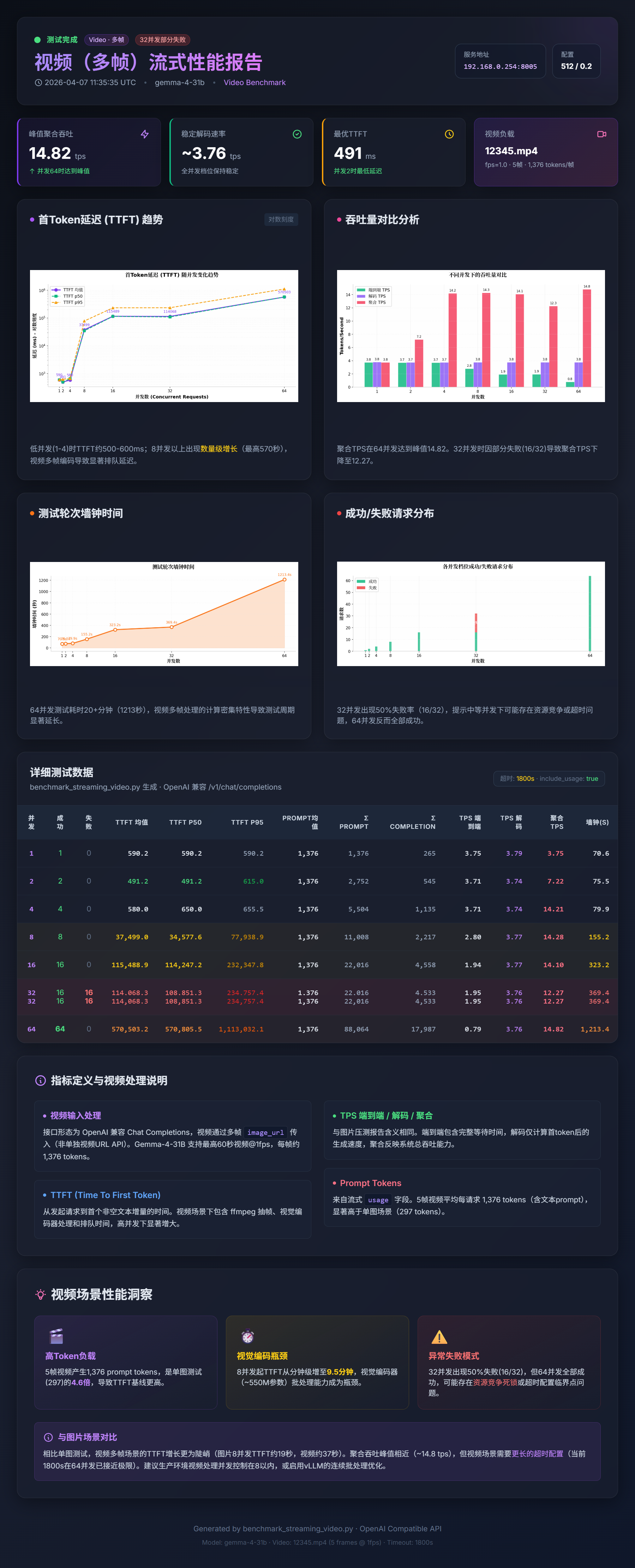
🧠 关键分析
31B是稠密模型
| 属性 | E2B | E4B | 31B 稠密 |
|---|---|---|---|
| 总参数量 | 2.3B 有效参数(含嵌入层共 5.1B) | 4.5B 有效参数(含嵌入层共 8B) | 30.7B |
| 层数 | 35 | 42 | 60 |
| 滑动窗口大小 | 512 个 token | 512 个 token | 1024 个 token |
| 上下文长度 | 128K 个 token | 128K 个 token | 256K 个 token |
| 词表大小 | 262K | 262K | 262K |
| 支持的模态 | 文本、图像、音频 | 文本、图像、音频 | 文本、图像 |
| 视觉编码器参数量 | ~1.5 亿 | ~1.5 亿 | ~5.5 亿 |
| 音频编码器参数量 | ~3 亿 | ~3 亿 | 不支持音频 |
解码受限于内存带宽: 在 DGX Spark 上,单用户 Token 生成受限于内存带宽。理论值与实测值对比如下:
- 31B bf16:273 GB/s ÷ 62 GB ≈ 4.4 t/s,实测 3.7 t/s(效率 84%)
- 31B int8:≈ 8.8 t/s,实测 6.5 t/s(效率 74%)
- 31B int4:≈ 17.0 t/s,实测 10.6 t/s(效率 62%)
- 26B-A4B MoE:≈ 34.0 t/s,实测 23.7 t/s(效率 70%)
MoE 的结构性优势: MoE 模型解码优势来自其架构特性:尽管 49 GB 的专家权重全部驻留在显存中,每个 Token 生成时只需读取 4B 激活参数,解码吞吐量比 dense bf16 基准高 6.4 倍,比 AWQ int4 高 2.2 倍。
31B AWQ int4 是 dense 模型的最佳选择: 对于需要完整 31B dense 模型质量的场景,AWQ int4 是最优选择:解码速度 10.6 t/s(约为 bf16 基准的 3 倍),短提示首次响应时间最低(247 ms),且仅占用 20 GB 磁盘,为 256K 上下文留出充裕的 KV 缓存空间。
📝 总结建议
对于交互式和 Agentic 工作负载,26B-A4B MoE 是 DGX Spark 上的明确赢家:最快解码速度(23.7 t/s)、长上下文下最佳 Prompt 处理速度(pp2048 达 3105 t/s)、首次响应时间也具有竞争力。LPDDR5X 统一内存架构在限制 dense 模型的同时,反而有利于 MoE 设计——每个 Token 只需流式读取 4B 激活参数。
⚠️ 注意:这是 2026 年 4 月 2 日模型发布当天的初步快照,随着 vLLM 内核成熟、量化方案优化和服务参数调整,数字会持续改善。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 11
11 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)