【优化求解】基于带惯性项的自适应交替方向乘子法iADMMn求解带正则化的逻辑回归矩阵分解问题,对比ADMM和梯度下降法GD算法附Matlab代码
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、建模仿真、程序设计、完整代码获取、论文复现及科研仿真。
👇 关注我领取海量matlab电子书和数学建模资料
🍊个人信条:格物致知,完整Matlab代码获取及仿真咨询内容私信。
![]()
🔥 内容介绍

![]()
一、联邦学习概述
-
概念:联邦学习是一种分布式机器学习框架,旨在在多个参与方(如多个设备、机构或组织)之间协同训练模型,同时保护各方的数据隐私。在联邦学习中,各参与方在本地存储和处理数据,无需将数据上传至中央服务器,而是通过与中央服务器交换模型参数或梯度信息来共同构建一个全局模型。
-
应用场景与需求:联邦学习在诸多领域有广泛应用,例如在医疗领域,不同医院可以在不共享患者敏感数据的前提下,共同训练一个用于疾病诊断的模型;在金融领域,多家银行可联合训练信用评估模型,而不泄露各自客户的财务信息。然而,联邦学习面临着通信成本高、数据异构性强以及模型收敛速度慢等挑战。因此,需要高效的优化算法来提升联邦学习的性能。
二、交替方向乘子法(ADMM)

优势:ADMM 结合了对偶上升法和乘子法的优点,具有收敛速度快、可并行计算以及对大规模分布式问题适应性强等特点。它能够有效处理约束条件,并且在每次迭代中,子问题的求解相对简单,通常可以得到闭式解或通过高效的迭代算法求解。

![]()
⛳️ 运行结果

![]()
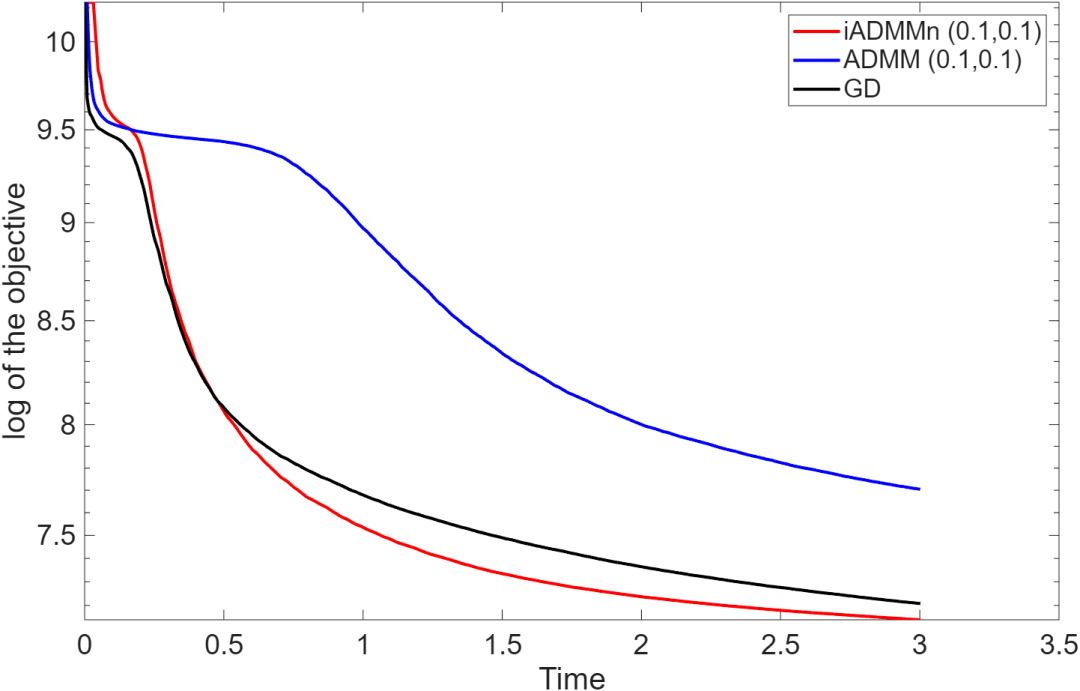
![]()
📣 部分代码

![]()
function [obj_save,U,V,time_save] = GD(Y,c,lambda_d,lambda_t,options)
% GD (alternating gradient descent) algorithm for solving
% (*) \min_{U,V} \sum_{i=1}^m \sum_{j=1}^n (1+c y_{ij}-y_{ij}) \log (1+\exp(u_i v_j^\top))
% -c y_{ij}u_i v_j^\top + \frac{\lambda_d}{2} \|U\|_F^2
% + \frac{\lambda_t}{2}\|V\|_F^2
% note that y_{ij} \in [0,1]
%
% written by LTK. Hien
% lastest version Oct 2023
%
%
% input: 0<=Y<=1, c, lambda_d, lambda_t
% options.beta : penalty parameter of iADMMn
% options.max_time : max time of running the algorithm
% options.max_iter : max number of iterations to run the algorithm
% options.U0, options.V0: initial points of iADMMn
%
% output: obj_save: sequence of the objective of problem (*),
% U,V : solution
% time_save: sequence of running time
%
cputime0 = tic;
max_time=options.max_time;
max_iter=options.max_iter;
% initial point
U=options.U0;
V=options.V0;
%start
i=1;
time_i=toc(cputime0);
time_save=time_i;
UV=U*V;
yy=1+(c-1)*Y;
LG=1/4*max(yy(:));
GW=yy.*logexp(UV);
YUV=Y.*UV;
obj=sum(GW(:))-c*sum(YUV(:))+lambda_d*norm(U,'fro')^2/2+lambda_t/2*norm(V,'fro')^2;
obj_save=obj;
while i<=max_iter && time_i<=max_time
% update U
W=U*V;
P=expX(W);
gradU=P*V'+(c-1)*(Y.*P)*V'-c*Y*V'+lambda_d*U;
stepsize=1/(LG*norm(V)^2+lambda_d);
U=U-stepsize*gradU;
%update V
P=expX(U*V);
gradV=U'*P+(c-1)*U'*((Y).*(P))-c*U'*Y+lambda_t*V;
stepsize=1/(LG*norm(U)^2+lambda_t);
V=V-stepsize*gradV;
UV=U*V;
yy=1+(c-1)*Y;
GW=yy.*logexp(UV);
YUV=Y.*UV;
obj=sum(GW(:))-c*sum(YUV(:))+lambda_d*norm(U,'fro')^2/2+lambda_t/2*norm(V,'fro')^2;
obj_save=[obj_save,obj];
time_i=toc(cputime0);
time_save=[time_save,time_i];
if mod(i,2)==0
fprintf('GD: iteration %4d fitting error: %1.2e \n',i,obj);
end
i=i+1;
end
end
function e=expX(X)
%compute e^x/(1+e^x)
e=exp(-max(-X,0))./(1+exp(-abs(X)));
end
function e=logexp(X)
%compute log(1+e^x)
e=log(1+exp(-abs(X)))+max(0,X);
end
![]()
🔗 参考文献

![]()
![]()
🌿 往期回顾可以关注主页,点击搜索


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 0
0 0
0- 0



 已为社区贡献110条内容
已为社区贡献110条内容

所有评论(0)