水泥水化热也能用AI预测?三种主流模型效果对比,干货来了!

水泥水化热是影响混凝土早期开裂和长期耐久性的关键因素,尤其在掺入粉煤灰、矿渣等低碳材料后,水化过程变得更加复杂。传统实验方法耗时长、成本高,难以满足快速配比优化的需求。
这篇发表在 Materials 期刊上的研究,系统比较了 CatBoost、ExtraTrees、XGBoost 三种机器学习模型在预测水泥基材料水化热方面的表现,结论非常实用。
01 研究背景:水泥也“发烧”
水泥与水反应会释放大量热量,这一过程称为水化热。在大体积混凝土中,水化热散不出去,容易导致温度裂缝,影响结构安全。
为了降低碳排放,现代水泥中常掺入粉煤灰、矿渣等辅助胶凝材料(SCMs)。这些材料会改变水化热的释放速度和总量,使得传统经验公式难以准确预测。
传统测量方法(如等温量热法)虽然精确,但:
-
实验周期长(可达7天以上)
-
操作复杂,对人员要求高
-
不适合快速筛选大量配比
因此,研究者开始尝试用机器学习来建立预测模型,用数据代替部分实验。
02 研究目的:找出一款最适合预测水化热的AI模型
研究目标很明确:
对比三种主流机器学习模型(CatBoost、ExtraTrees、XGBoost),找出哪一个在预测水化热方面最准确、最稳定。
具体包括:
-
预测不同时间点(12h、72h、168h)的累积水化热
-
预测最大放热速率
-
评估模型的泛化能力(是否能预测未见过的配比)
03 研究方法:51组实验数据 + 三种模型 + 严格验证
数据集构成
|
类型 |
数量 |
说明 |
|---|---|---|
|
训练集 |
45组 |
用于训练模型 |
|
测试集 |
6组 |
用于最终评估 |
|
输入变量 |
5个 |
OPC含量、矿渣含量、粉煤灰含量、水胶比、温度 |
|
输出变量 |
4个 |
12h/72h/168h水化热 + 最大放热速率 |
三种模型简介
|
模型 |
特点 |
|---|---|
| CatBoost |
擅长处理非线性关系,对类别特征友好 |
| ExtraTrees |
随机性更强,抗过拟合能力强 |
| XGBoost |
经典梯度提升树,精度高,支持正则化 |
验证策略
-
使用留一法交叉验证(LOOCV),充分利用有限数据
-
最后用6组独立测试集评估泛化能力
评价指标:MAE、RMSE、MAPE、R²,并辅以残差分析和正态性检验。
04 研究过程与重难点
重点步骤
-
数据预处理:检查缺失值、分布特征、相关性分析
-
模型训练:每种模型都经过网格搜索调参
-
交叉验证:LOOCV,防止信息泄露
-
残差诊断:Q-Q图、残差-预测值图、正态性检验
-
测试集验证:最终评估模型泛化能力
研究重难点
|
难点 |
应对策略 |
|---|---|
|
样本量小(仅51组) |
采用LOOCV,充分利用每一组数据 |
|
输出变量之间高度相关 |
分别建模,避免多重共线性影响 |
|
长期预测误差大 |
使用多种指标综合评估,不只看R² |
|
残差不完全正态 |
补充非参数检验和可视化诊断 |
05 关键结果与图表解读
图1:变量相关性热图(原文 Figure 1)
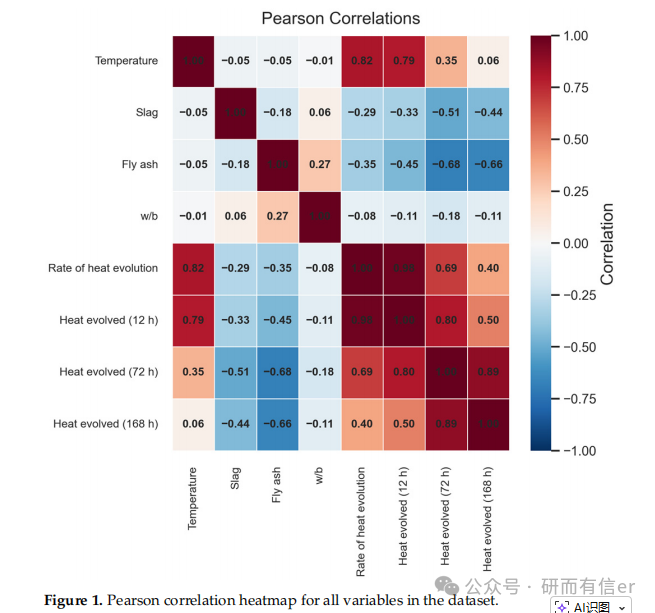
解读:
-
温度与所有输出变量呈强正相关(r ≈ 0.8),说明温度是影响水化热的关键因素
-
粉煤灰和矿渣与输出变量呈中等负相关,说明SCMs会延缓或降低水化热
-
输出变量之间相关性极高(r ≈ 0.98),说明它们来自同一物理过程
图4-7:CatBoost模型的残差诊断图(原文 Figures 4–7)
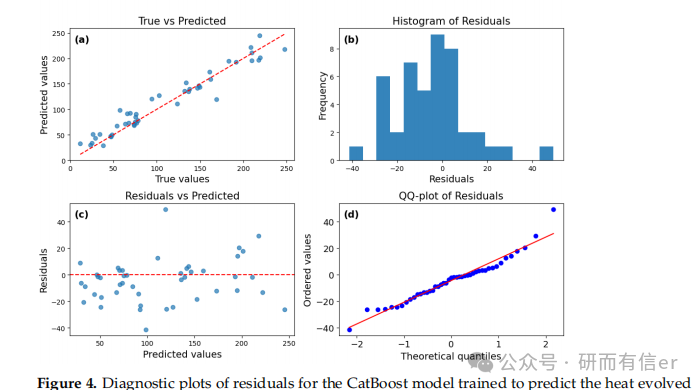
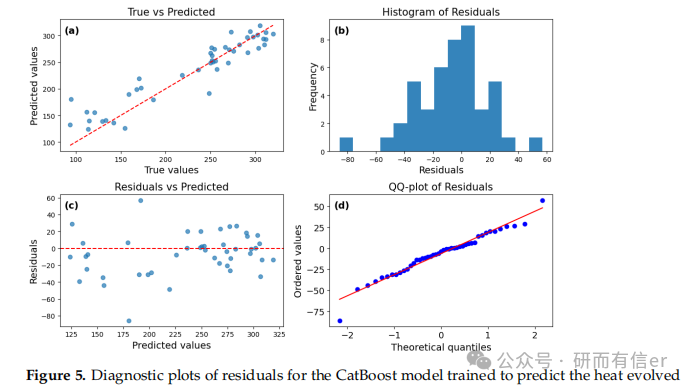
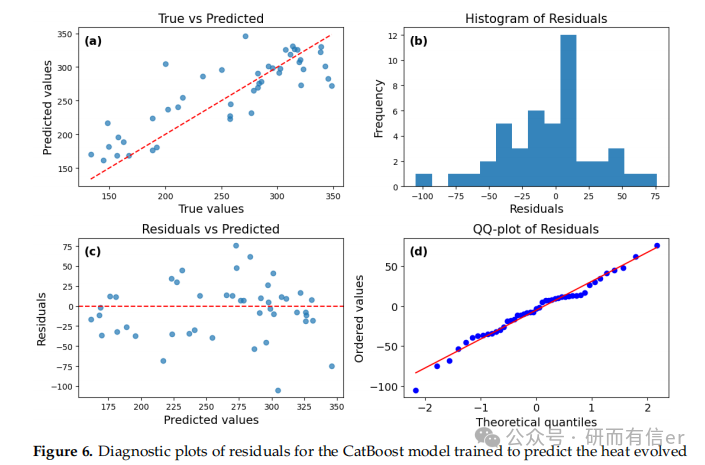
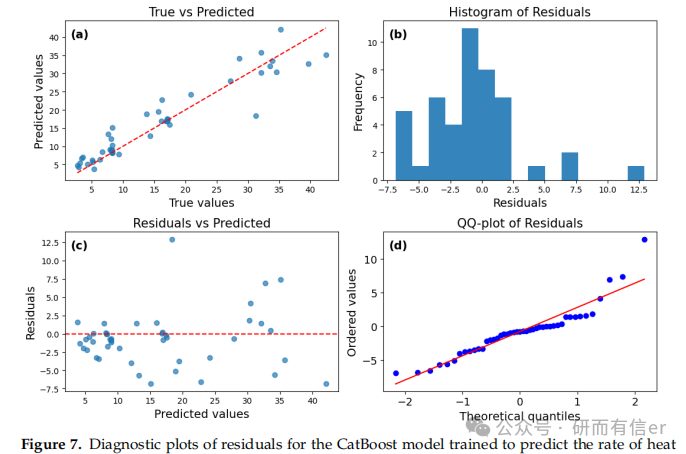
解读:
-
True vs Predicted图:点越靠近对角线,预测越准
-
Residuals vs Predicted图:残差应随机分布在零线两侧,无明显趋势
-
Q-Q图:点越靠近直线,残差越接近正态分布
结论:CatBoost在短期预测中表现良好,但残差存在一定偏斜。
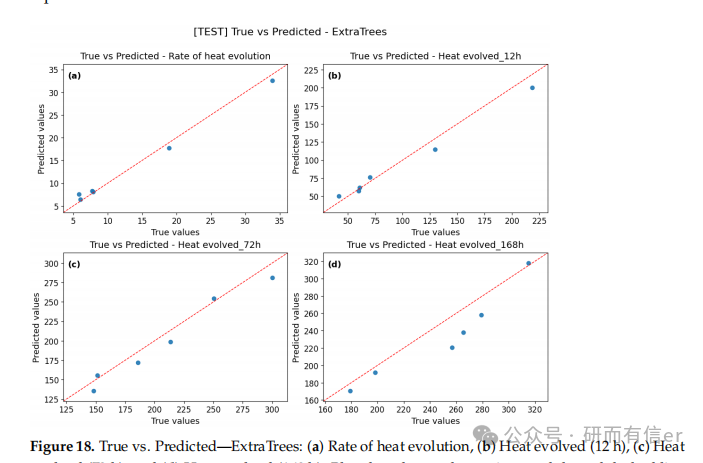
图8-11:ExtraTrees模型的残差诊断图(原文 Figures 8–11)
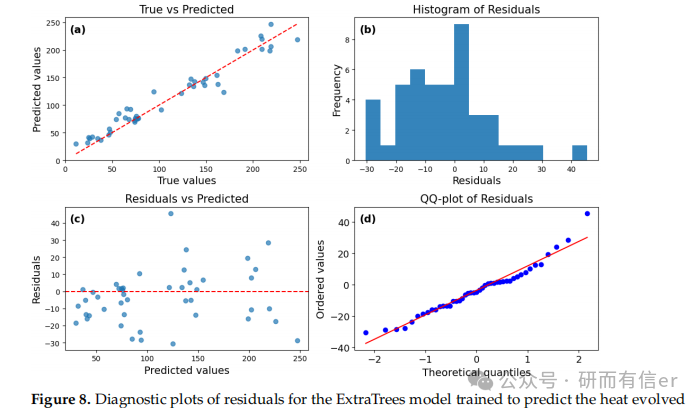
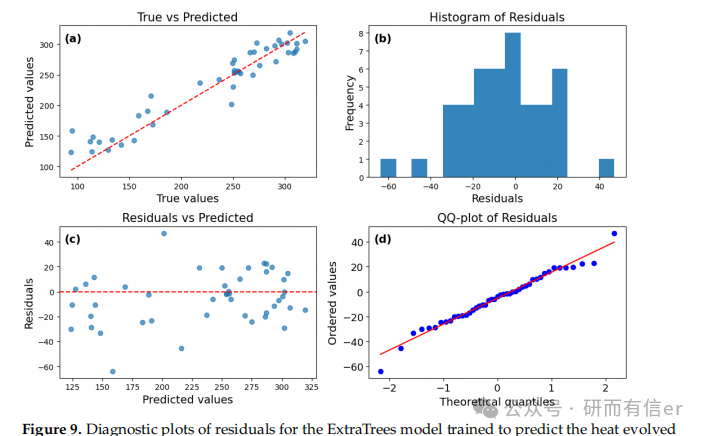
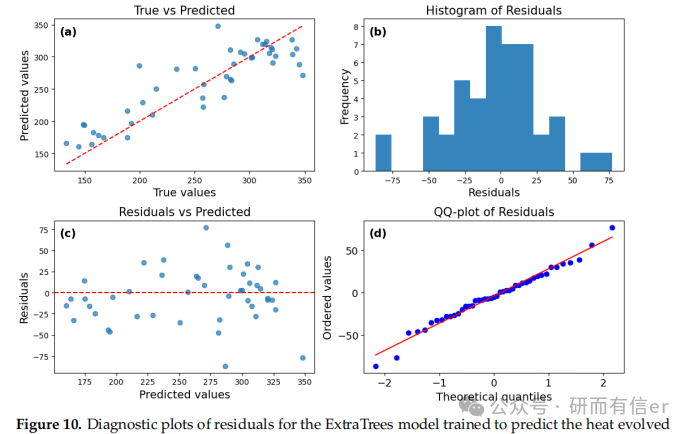
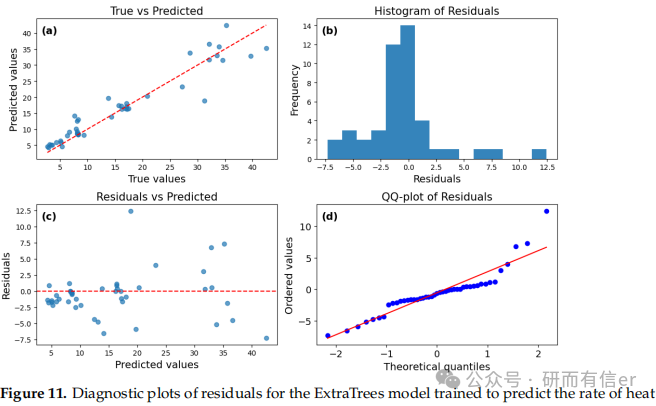
解读:
-
残差分布更对称,Q-Q图尾部偏差较小
-
ExtraTrees在长期预测(168h)中表现最稳定
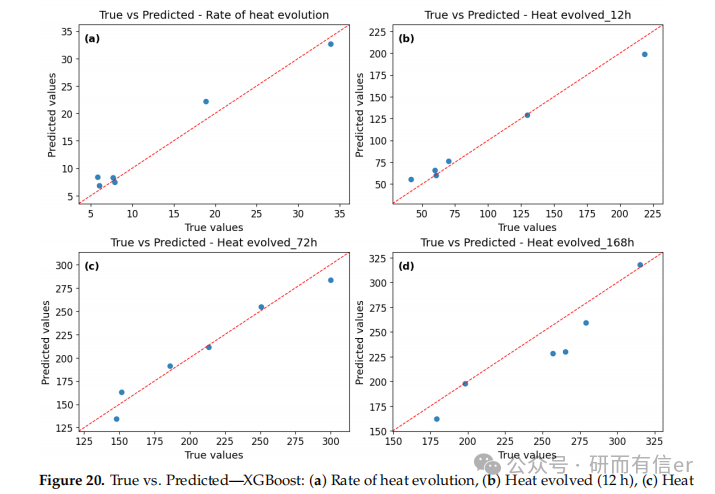
图12-15:XGBoost模型的残差诊断图(原文 Figures 12–15)
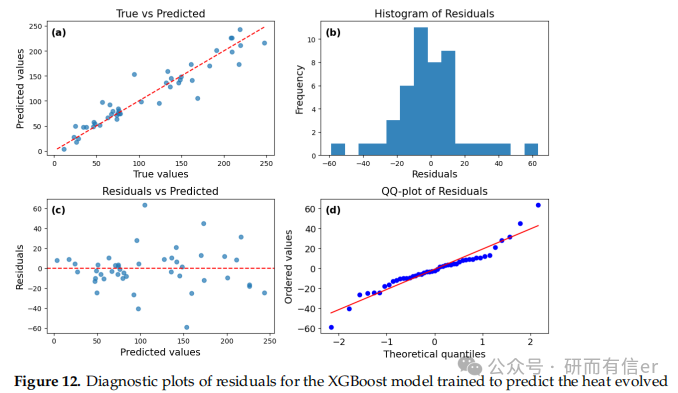
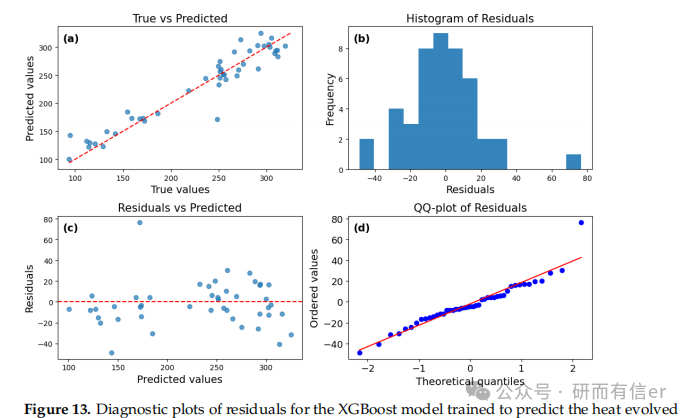
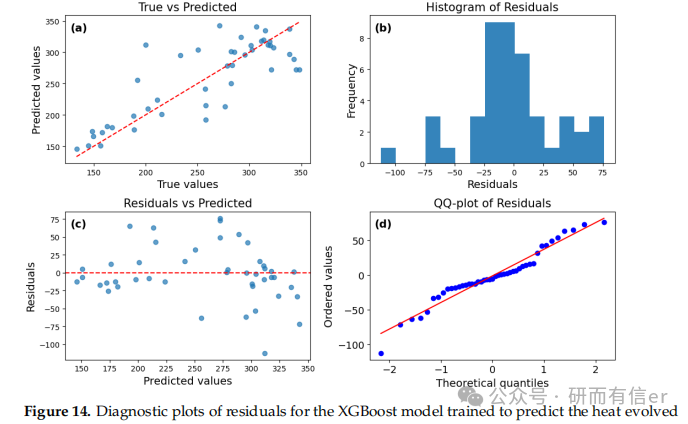
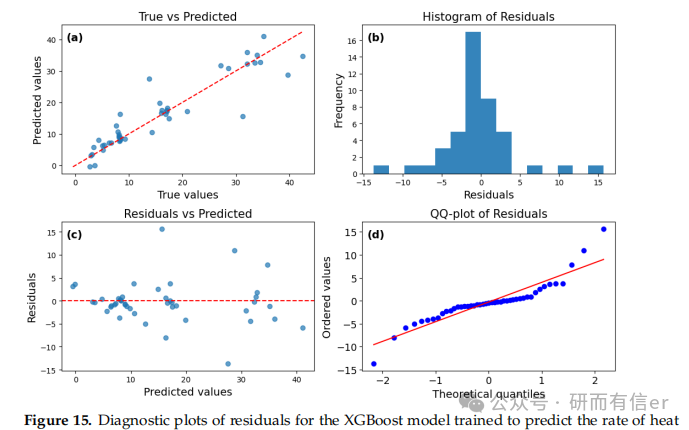
解读:
-
短期预测(12h、72h)中残差最小
-
长期预测残差增大,说明模型稳定性随时间下降
图16-21:测试集上的逐样本残差图(原文 Figures 16–21)
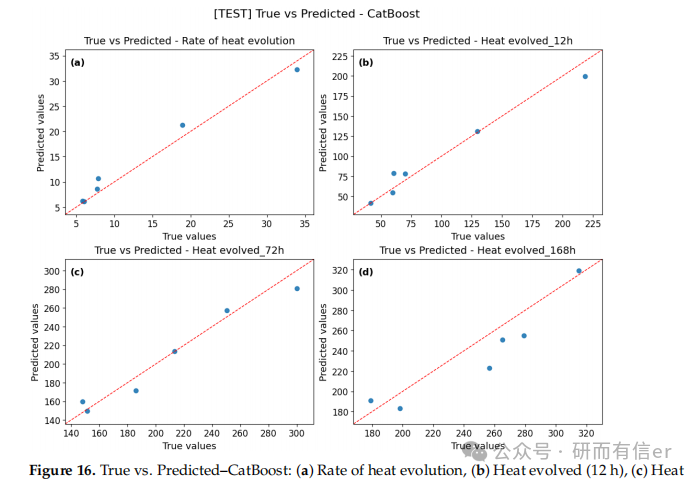
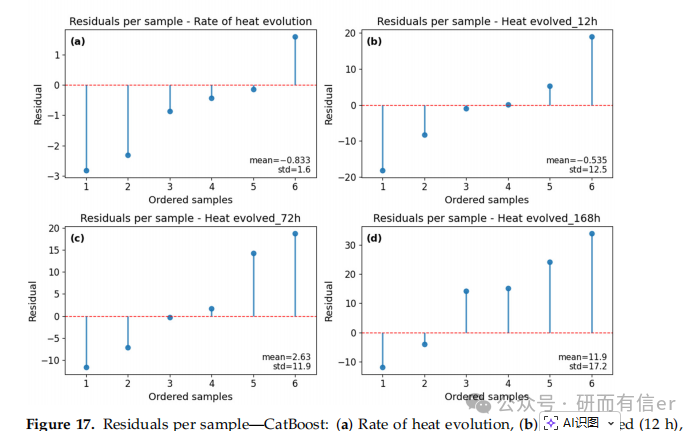
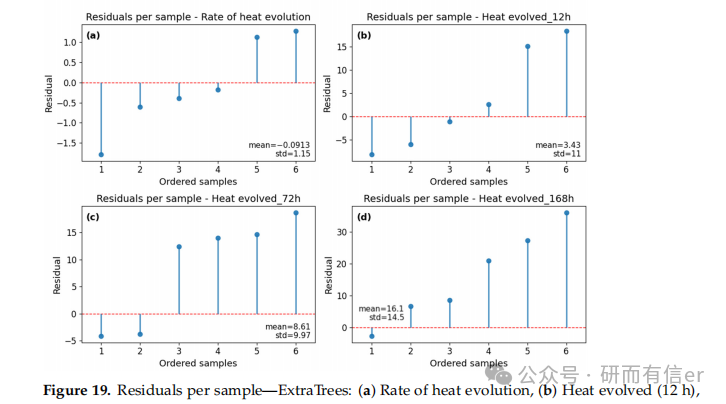
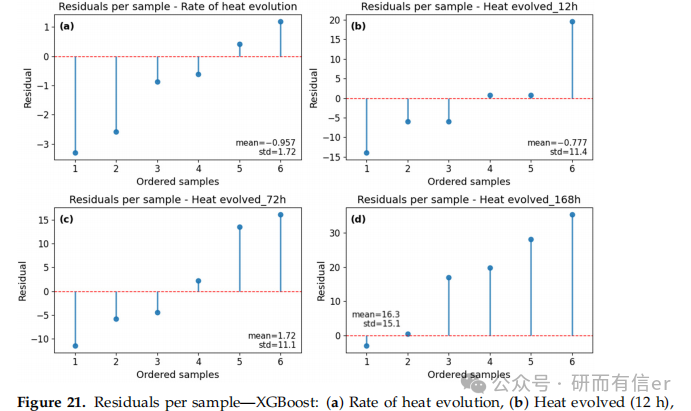
解读:
-
大多数样本残差在零线附近
-
长期预测(168h)出现个别较大偏差,说明模型仍有改进空间
06 研究结论:三款模型各有千秋
|
模型 |
优势 |
适用场景 |
|---|---|---|
| ExtraTrees |
最稳定,长期预测(168h)误差最小 |
需要稳定、泛化能力强的场景 |
| XGBoost |
短期预测(12h、72h)精度最高 |
关注早期水化行为的场景 |
| CatBoost |
表现中等,但无显著短板 |
通用场景,尤其是类别特征较多的数据 |
关键数据速览(测试集R²):
|
模型 |
12h |
72h |
168h |
放热速率 |
|---|---|---|---|---|
|
CatBoost |
0.965 |
0.957 |
0.822 |
0.973 |
|
ExtraTrees |
0.970 |
0.946 |
0.800 |
0.989 |
|
XGBoost |
0.971 | 0.964 |
0.790 |
0.967 |
07 未来展望
作者指出几个值得深入的方向:
-
扩大数据集:当前仅51组,更多数据可提升模型泛化能力
-
超参数自动优化:使用贝叶斯优化等更先进的方法
-
混合模型:如CatBoost + XGBoost,结合两者优势
-
模型可解释性:引入SHAP值,解释哪些输入变量最影响预测结果
-
工程落地:开发简单易用的预测工具,供混凝土配比设计使用
写在最后
这项研究告诉我们:机器学习不是要完全取代实验,而是让实验做得更聪明。
在低碳水泥材料快速发展的今天,能够快速、低成本地预测水化热,对于配比优化、裂缝控制和碳排放评估都具有重要价值。
如果你也在从事水泥、混凝土或建筑材料相关的工作,不妨关注一下这三种模型——ExtraTrees稳,XGBoost准,CatBoost通用,总有一款适合你。
注:更多关于机器学习水泥基的前沿知识小编之前有推荐,可以详查置顶文章:ai-MOFs预测筛选技术与机器学习水泥基复合材料应用综述
如果您觉得文章不错,欢迎点赞、关注、收藏及转发~

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 12
12 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)