【开源】DINOv3 特征可视化与 Few-shot 分割 GUI 工具:DINO-Lens
序言:大模型的“黑盒”焦虑
Meta AI 的 DINOv3 发布后,大家都被它 70 亿参数、1.7 亿张图片预训练的规模所震撼 。但对于大多数开发者来说,模型依然是一个冰冷的权重文件。我们读了论文,看了 Benchmark,却很难直观地感受到:它到底在想什么?它的特征到底强在哪里?
为了回答这个问题,我写了一个轻量级的交互工具:DINO-Lens。它的逻辑很简单:不改动模型,只是给 DINOv3 装上一个“镜头”,让我们能通过鼠标点击,实时看见特征空间的奥秘。
交互背后的“暴力美学”
在开发过程中,最让我惊讶的不是 GUI 本身,而是 DINOv3 特征表现出的“线性可分性”。
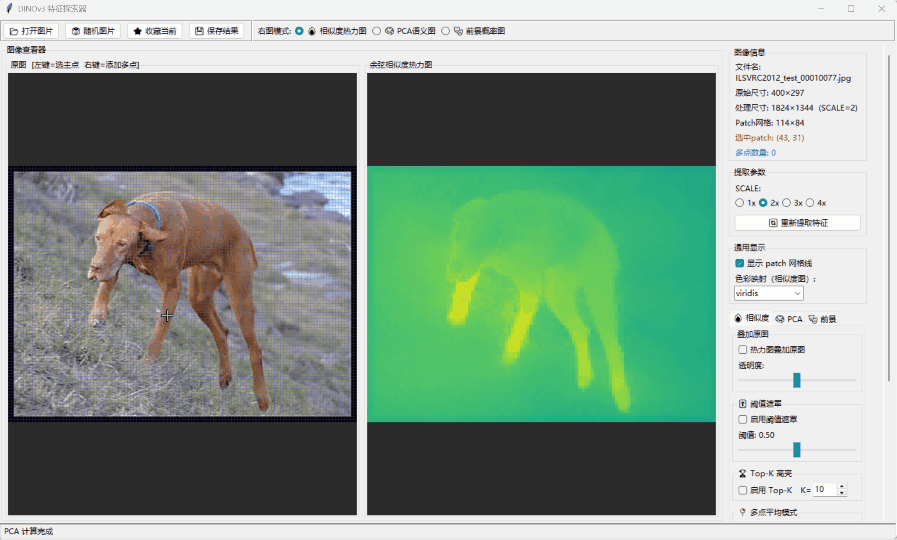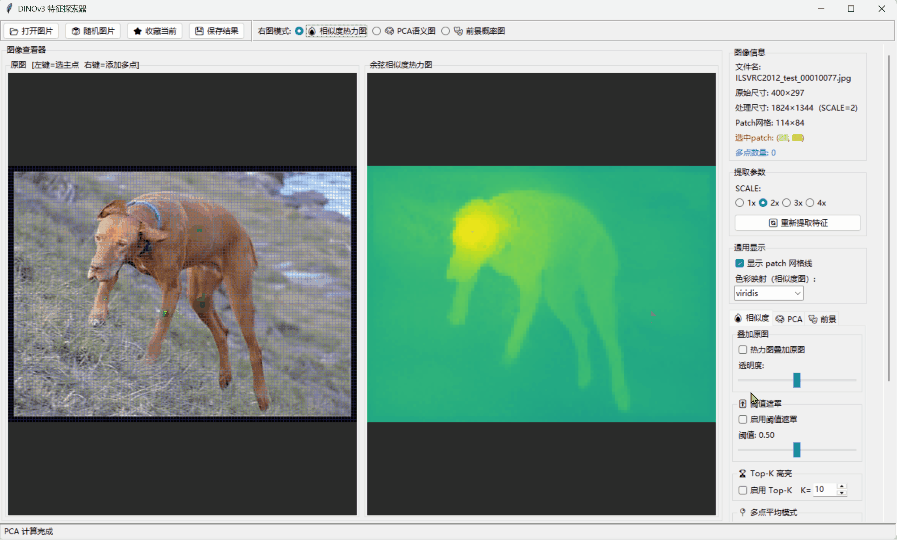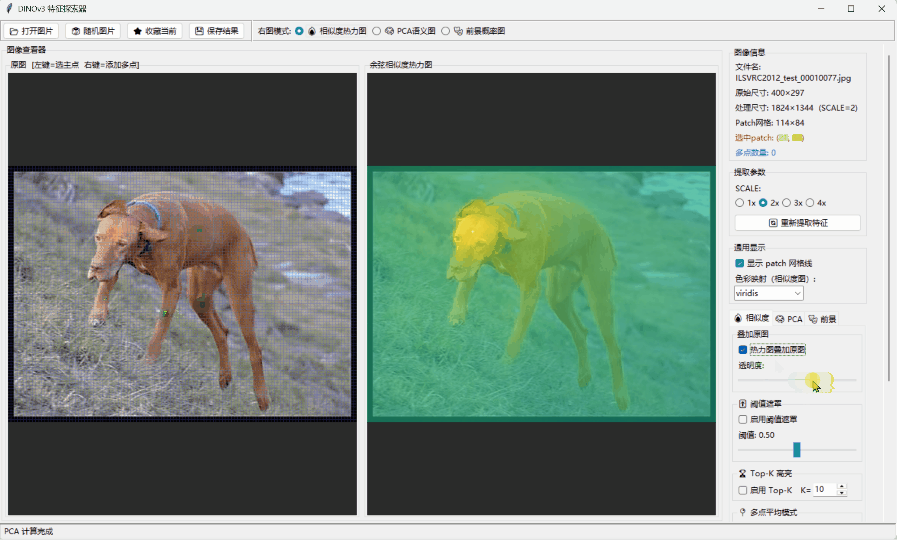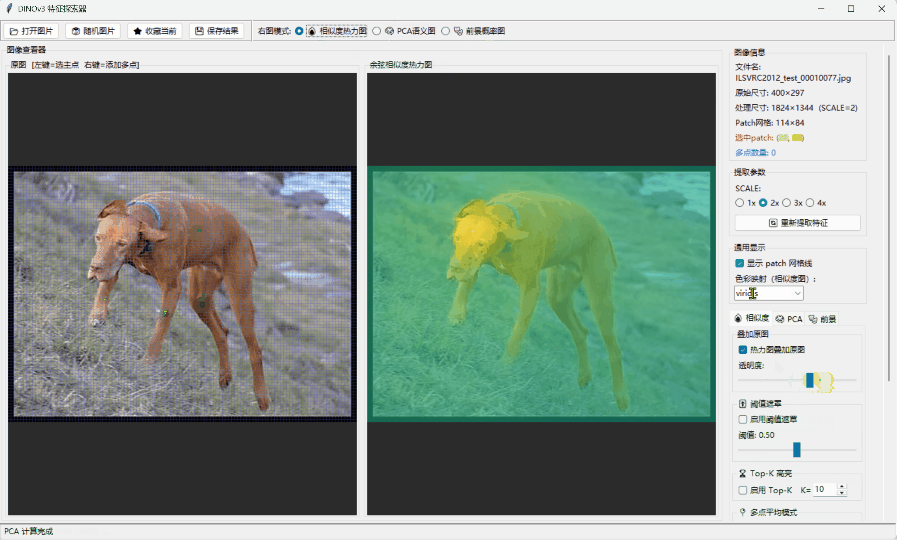
🖱️ 实时相似度分析: 当你在图中点击一个物体(比如猫的耳朵),系统会实时计算全图 Patch 与点击点之间的余弦相似度(Cosine Similarity)。你会发现,即使没有标签,模型也精准地捕捉到了语义的一致性——它知道哪些像素属于“同类”,这种跨目标的特征对应能力是惊人的 。
🧠 PCA 语义聚类: 通过主成分分析将高维 Token 降维到 RGB 空间,你会看到一种“涌现出的分割能力”。不同颜色的区域代表了模型自发学习到的语义簇,这证明了 DINOv3 在潜在空间中已经完成了对世界结构的解构。
一个极简的实验:10 张图的分割上限
为了验证特征的强度,我在 DINO-Lens 中加入了一个极端实验:
如果只用一个单层逻辑回归(Logistic Regression)做前景分割,且训练集只有 10 张图,效果会怎样?
结果超出了我的预期。在完全冻结 DINOv3 骨干网络的情况下,这种极简的“线性探测(Linear Probing)”不仅跑通了,而且分割边缘非常锐利 。
这验证了一个深刻的硬核结论:强大的特征本身就是任务的答案。 我们不再需要复杂的解码器或数万张标注图,因为 DINOv3 已经帮我们将语义信息在特征空间里排布好了。
技术细节:为什么 DINOv3 没崩?
很多人会问,为什么之前的 ViT 大模型训练久了,局部特征会退化?DINOv3 的硬核之处在于引入了 Gram Anchoring(Gram 锚定) 。
其核心损失函数公式为:
通过对齐学生模型与稳定“教师”模型之间的 Gram 矩阵,它成功防止了 Patch Token 向全局信息坍塌,保证了我们在 GUI 中看到的相似度热力图依然保持极高的空间分辨率 。
结语:让工具回归直觉
DINO-Lens 并不是什么改变世界的架构创新,它只是一个开箱即用的“显微镜”。
我做这个项目的初衷,是希望打破代码的壁垒,让每一位研究者都能零门槛地“摸一摸”大模型的特征。如果你也想看看 DINOv3 眼中的世界,欢迎来 GitHub 试试看。详细的运行代码和依赖说明都在 GitHub 上,欢迎直接 Clone 下来跑跑看。
PS:本项目将持续维护和更新,欢迎大家提出不同的建议和看法!
项目地址:(https://github.com/gongzhijie535-ctrl/DINO-Lens)
核心支持: 基于 Meta AI DINOv3 ViT-B/16 distilled 版本 (目前只做了这个版本,这个大小的权重大家用起来也比较方便哒)。
(如果你觉得这个小工具有点意思,欢迎在 GitHub 点个 Star ⭐呀,这也是对我这种“工具人”最大的鼓励,谢谢啦!)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)