从Java老兵到AI架构师:我的80薪翻倍转型血泪史,2026年最短AI落地路径!
转折发生在2025年初。当我发现带了一年多的徒弟,靠着一个基于LangChain4j的RAG项目,跳槽去了一家AI公司,薪资直接翻倍,变成了我的1.8倍。那一刻,我破防了。
我焦虑的不是薪资,而是职业天花板的触手可及。干了这么多年,我依然是“写接口的”,而市场上却开始疯狂抢夺“懂AI的后端”。
经过近一年的“魔鬼式”转型,现在我是一家独角兽公司AI应用架构团队的负责人。薪资涨幅超过80%,更重要的是,我从那个随时可能被优化掉的“资源”,变成了定义产品智能化的“核心资产”。
我知道屏幕前的你,正经历着我当年的犹豫:想转AI,但怕踩坑;怕学了一堆用不上;更怕刚学会,技术又迭代了。
今天,我用这篇文章,把这一年的血泪教训、面试官的灵魂拷问,以及那条被验证过的**“Java转AI应用开发”**最短路径,一次性交给你。
⚠️ 第一盆冷水:这三类人,我不建议你现在转AI
转型不是逃避,是跃迁。在决定All in之前,你可以用下面三个面试官最常用的“劝退题”来自测一下:
第一类:把“调API”当成“搞AI”的人
- 面试官问: “如果OpenAI的服务挂了,你的智能客服如何保证3个9的可用性?如果调用量暴涨10倍,如何保证成本不爆炸?”
- 错误回答: “这个……我主要关注业务逻辑,运维有专门的同事吧。”
- 真实反馈: 这是典型的**“框架思维”**。以为用了Spring AI、配个Prompt就是AI开发了。但在生产环境中,高可用、降级熔断、成本控制才是企业付费的理由,而这些恰恰是我们后端最擅长的 。
第二类:简历里只有“大模型”关键词,毫无工程体感的人
- 面试官问: “描述一下你做过最复杂的RAG项目,文档切分你是怎么做的?切片长度是多少?为什么?召回率怎么提升的?”
- 错误回答: “我用LangChain的默认加载器,直接把PDF切了扔进了向量库……”
- 真实反馈: 这种简历我见得最多。技术深度在“细节”里。默认的RecursiveCharacterTextSplitter会导致严重的语义割裂 。没有经历过数据清洗、Chunk Size调优、Hybrid Search(混合检索)实战,只能算是“看过科普文”。
第三类:只看新闻,不写一行代码的人
- 面试官问: “最新的o4-mini模型和GPT-4.1在实际的Tool Calling(工具调用)准确率上,你觉得哪个更适合做Agent?有数据支撑吗?”
- 错误回答: “我看评测说o4-mini性价比很高……”
- 真实反馈: 评测是别人的,体感是自己的。2026年的AI开发,不仅要懂原理,更要有“码感” 。
如果你属于上述三类,先别急着跳槽,我们先把后端工程师的“护城河”挖深,再去引AI的水。
核心认知:2026年,复合型人才正在“通吃”
现在的就业市场很奇怪:
- 纯算法岗:卷到飞起,论文、顶会、博士学历,且离业务太远,落地难。
- 纯后端岗:内卷严重,薪资增长乏力。
- 最大缺口:是 “懂工程落地的AI应用架构师” 。
为什么是我们Java后端?
因为我们天生懂 “稳定性” 。当算法工程师还在Notebook里跑通单次调用时,我们在考虑:
- RAG系统的工程化:如何通过Query改写、重排(Rerank)让召回率从60%提升到90%?
- 性能与成本:如何用流式输出优化TTFT(首字延迟)?如何用语义缓存降低40%的Token成本?
- 生产级高可用:大模型接口超时了怎么办?降级方案是返回本地知识库的模糊匹配,还是提示用户稍后重试?
这些工程落地题,是面试中区分“API Caller”和“架构师”的分水岭 。
五阶段“作战地图”:从Curd Boy到AI应用架构师
这是我结合自身经历和带团队的经验,总结出的最科学、最省时间的学习路径。全程贯彻**“工程化优先”**原则。
阶段一:破冰与祛魅(1-2个月)
- 目标: 打通第一行代码,消除对AI的恐惧。
- 核心: 不要上来啃Transformer论文!先学会“用”。
- 搞定Python基础(能看懂开源项目代码即可,不要求精通) 。
- 掌握Prompt Engineering:结构化Prompt、思维链(CoT)、少样本学习(Few-Shot)。这是你未来“调教”模型的基础 。
- 熟悉主流API调用:OpenAI、DeepSeek、通义千问,对比它们的差异。
- 产出: 一个调用大模型API实现简历解析或者周报生成的小工具。
阶段二:原理与微调(2-3个月)
- 目标: 理解模型“黑盒”内部发生了什么,能本地跑起开源模型。
- 核心:
- Transformer架构:理解Attention机制,这是所有大模型的地基。
- 微调(LoRA/P-Tuning):知道什么时候该微调,什么时候用RAG。别当“调参侠”,重点是理解微调能解决什么问题(改变语气、遵循复杂格式),不能解决什么问题(注入新知识) 。
- 产出: 在本地部署Llama 3或ChatGLM模型,并用自己的数据做一次LoRA微调。
阶段三:RAG全栈落地(2个月 - 重中之重)
- 目标: 掌握当前企业落地最广、需求最旺的RAG技术。
- 核心工程细节:
- 切分策略:按语义切分,设置重叠窗口(Overlap),防止上下文被切断 。
- 检索优化:**混合检索(Hybrid Search)**是标配(关键词BM25+向量检索),解决专有名词匹配不准的问题 。
- 重排序(Rerank):初筛Top 50,再用Rerank模型精排Top 5,效果立竿见影。
- 产出: 一个企业级知识库问答系统,支持多轮对话和文档溯源。
阶段四:Java AI 工程化(1个月 - 发挥你的优势)
- 目标: 将AI能力无缝集成到你熟悉的Java生态中。
- 核心:
- 框架选型:Spring AI 或 LangChain4j。我个人更倾向于Spring AI,因为它完美契合Javaer的编程习惯 。
- 流式编程:WebFlux或Servlet异步化,实现打字机效果,优化用户体验。
- Function Calling:让AI根据意图,调用你写好的Java方法(查库存、下单、查询数据库),这是Agent的雏形 。
- 性能与成本:实现语义缓存、限流熔断(Resilience4j)、监控(Prometheus + Grafana)。
阶段五:Agent与产品思维(持续进行)
- 目标: 从“功能开发”向“服务重塑”跃迁 。
- 核心: 学习LangGraph或AutoGen,设计多智能体协作流程。思考如何用AI重构现有的业务流程。
踩坑实录:
在第一次面试某大厂“AI应用开发”岗时,我被虐得体无完肤。分享两个典型场景,希望你能绕过去:
坑位1:RAG系统“答非所问”
- 问题场景: 我搭建的基于公司财报的问答系统,问“去年营收是多少?”,它总是答非所问,或者引用错误段落。
- 面试官追问: “你的检索召回是第几名?有没有可能是召回的Top 1片段虽然是相关段落,但并不包含具体的营收数字,导致模型没看到数据?”
- 错误方案: 我当时想的是换个更好的Embedding模型。
- 正确方案: 加入重排序(Rerank)环节。让粗召回的20个片段,经过精排后,将最相关的排在前面。同时采用**HyDE(假设文档嵌入)**技术,先让模型生成一个包含答案假设的“伪文档”,再用它去检索,极大提升了含数字类问题的命中率。
- 优化结果: 回答准确率从72%提升至91%。
坑位2:流式输出的“雪花”崩溃
- 问题场景: 我们将AI客服做成流式输出,并发一高,服务就OOM。
- 面试官追问: “流式输出的背压(Backpressure)怎么处理的?数据 buffer 是在内存里还是直接刷给前端?”
- 错误方案: 我当时的同事用List把所有Token全量收集起来,最后才flush。
- 正确方案: 使用Spring WebFlux的Flux,实现真正的非阻塞流式处理。数据以512字节的chunk直接下发,不暂存全量结果,内存占用降低80% 。
🎯 备战2026:给你的“加分项”清单
想拿到Offer,简历和面试必须量化你的后端优势:
- 简历包装技巧
- ❌ 错误:负责AI对话系统的开发。
- ✅ 正确:主导RAG知识库的工程化落地**,通过优化Chunk重叠策略和引入Rerank,使知识召回准确率从72%提升至91%,并基于Spring Cloud Circuitbreaker实现了大模型接口的**熔断降级,保障了核心业务99.9%的可用性。
- 面试应答技巧
- 当被问及不懂的算法时,别慌。
- 话术:“具体的训练细节我还在深入学习,但从工程落地的角度,我更关注这个模型在实际业务中的表现,比如它的推理延迟、上下文窗口以及Function Calling的成功率。如果我们需要用到这个能力,我会……”
- 这展现了你作为应用架构师的定位,而非算法研究员。
01
什么是AI大模型应用开发工程师?
如果说AI大模型是蕴藏着巨大能量的“后台超级能力”,那么AI大模型应用开发工程师就是将这种能量转化为实用工具的执行者。
AI大模型应用开发工程师是基于AI大模型,设计开发落地业务的应用工程师。
这个职业的核心价值,在于打破技术与用户之间的壁垒,把普通人难以理解的算法逻辑、模型参数,转化为人人都能轻松操作的产品形态。
无论是日常写作时用到的AI文案生成器、修图软件里的智能美化功能,还是办公场景中的自动记账工具、会议记录用的语音转文字APP,这些看似简单的应用背后,都是应用开发工程师在默默搭建技术与需求之间的桥梁。
他们不追求创造全新的大模型,而是专注于让已有的大模型“听懂”业务需求,“学会”解决具体问题,最终形成可落地、可使用的产品。
CSDN粉丝独家福利
给大家整理了一份AI大模型全套学习资料,这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】

02
AI大模型应用开发工程师的核心职责
需求分析与拆解是工作的起点,也是确保开发不偏离方向的关键。
应用开发工程师需要直接对接业务方,深入理解其核心诉求——不仅要明确“要做什么”,更要厘清“为什么要做”以及“做到什么程度算合格”。
在此基础上,他们会将模糊的业务需求拆解为具体的技术任务,明确每个环节的执行标准,并评估技术实现的可行性,同时定义清晰的核心指标,为后续开发、测试提供依据。
这一步就像建筑前的图纸设计,若出现偏差,后续所有工作都可能白费。
技术选型与适配是衔接需求与开发的核心环节。
工程师需要根据业务场景的特点,选择合适的基础大模型、开发框架和工具——不同的业务对模型的响应速度、精度、成本要求不同,选型的合理性直接影响最终产品的表现。
同时,他们还要对行业相关数据进行预处理,通过提示词工程优化模型输出,或在必要时进行轻量化微调,让基础模型更好地适配具体业务。
此外,设计合理的上下文管理规则确保模型理解连贯需求,建立敏感信息过滤机制保障数据安全,也是这一环节的重要内容。
应用开发与对接则是将方案转化为产品的实操阶段。
工程师会利用选定的开发框架构建应用的核心功能,同时联动各类外部系统——比如将AI模型与企业现有的客户管理系统、数据存储系统打通,确保数据流转顺畅。
在这一过程中,他们还需要配合设计团队打磨前端交互界面,让技术功能以简洁易懂的方式呈现给用户,实现从技术方案到产品形态的转化。
测试与优化是保障产品质量的关键步骤。
工程师会开展全面的功能测试,找出并修复开发过程中出现的漏洞,同时针对模型的响应速度、稳定性等性能指标进行优化。
安全合规性也是测试的重点,需要确保应用符合数据保护、隐私安全等相关规定。
此外,他们还会收集用户反馈,通过调整模型参数、优化提示词等方式持续提升产品体验,让应用更贴合用户实际使用需求。
部署运维与迭代则贯穿产品的整个生命周期。
工程师会通过云服务器或私有服务器将应用部署上线,并实时监控运行状态,及时处理突发故障,确保应用稳定运行。
随着业务需求的变化,他们还需要对应用功能进行迭代更新,同时编写完善的开发文档和使用手册,为后续的维护和交接提供支持。
03
薪资情况与职业价值
市场对这一职业的高度认可,直接体现在薪资待遇上。
据猎聘最新在招岗位数据显示,AI大模型应用开发工程师的月薪最高可达60k。
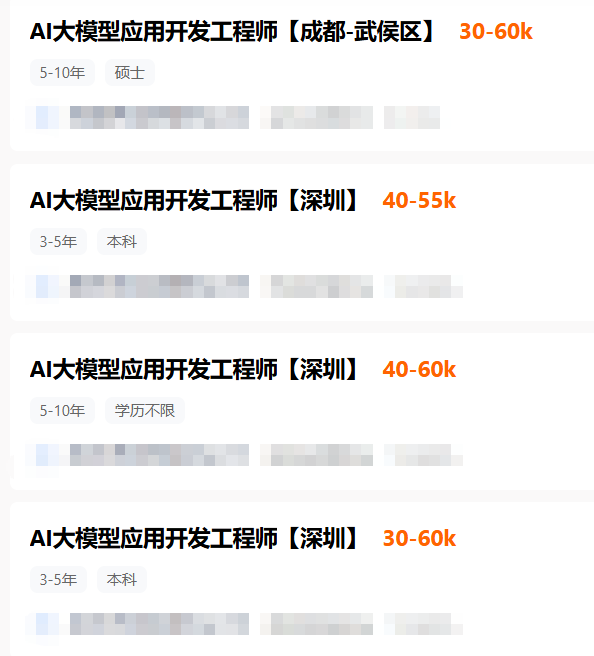
在AI技术加速落地的当下,这种“技术+业务”的复合型能力尤为稀缺,让该职业成为当下极具吸引力的就业选择。
AI大模型应用开发工程师是AI技术落地的关键桥梁。
他们用专业能力将抽象的技术转化为具体的产品,让大模型的价值真正渗透到各行各业。
随着AI场景化应用的不断深化,这一职业的重要性将更加凸显,也必将吸引更多人才投身其中,推动AI技术更好地服务于社会发展。
CSDN粉丝独家福利
给大家整理了一份AI大模型全套学习资料,这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 2
2 0
0- 0



 已为社区贡献190条内容
已为社区贡献190条内容

所有评论(0)