RAG技术深度解析:从文档检索到智能问答,打造你的知识库增强生成系统!
一、RAG(检索增强生成)概念
RAG系统整体架构流程
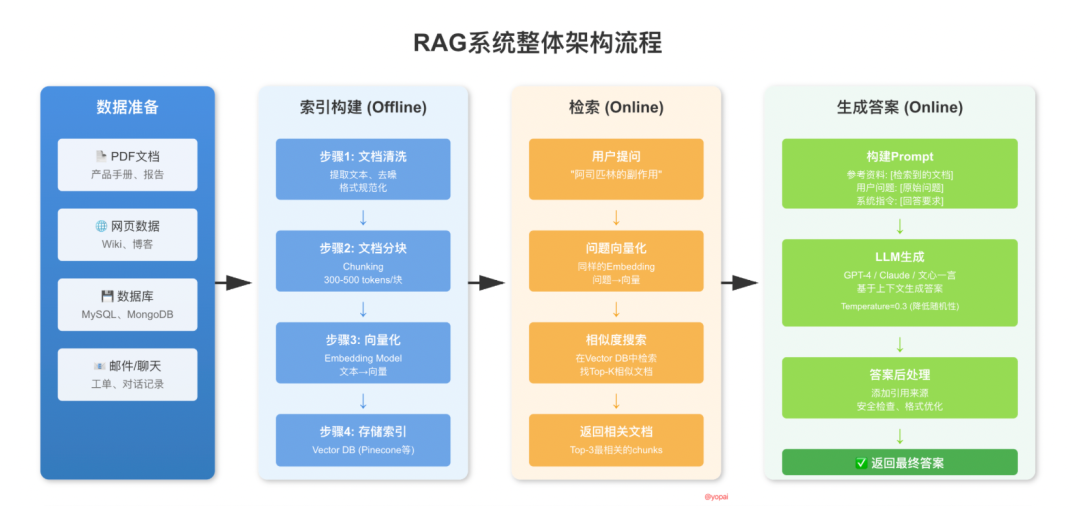
RAG的完整流程可以分为四个核心阶段:
1、数据准备阶段:把你的文档、数据库等各种知识源准备好
2、索引构建阶段:把这些知识“消化”成机器能快速查找的格式
3、检索阶段:用户问问题时,快速找到相关的知识
4、生成阶段:结合找到的知识和问题,生成靠谱的答案
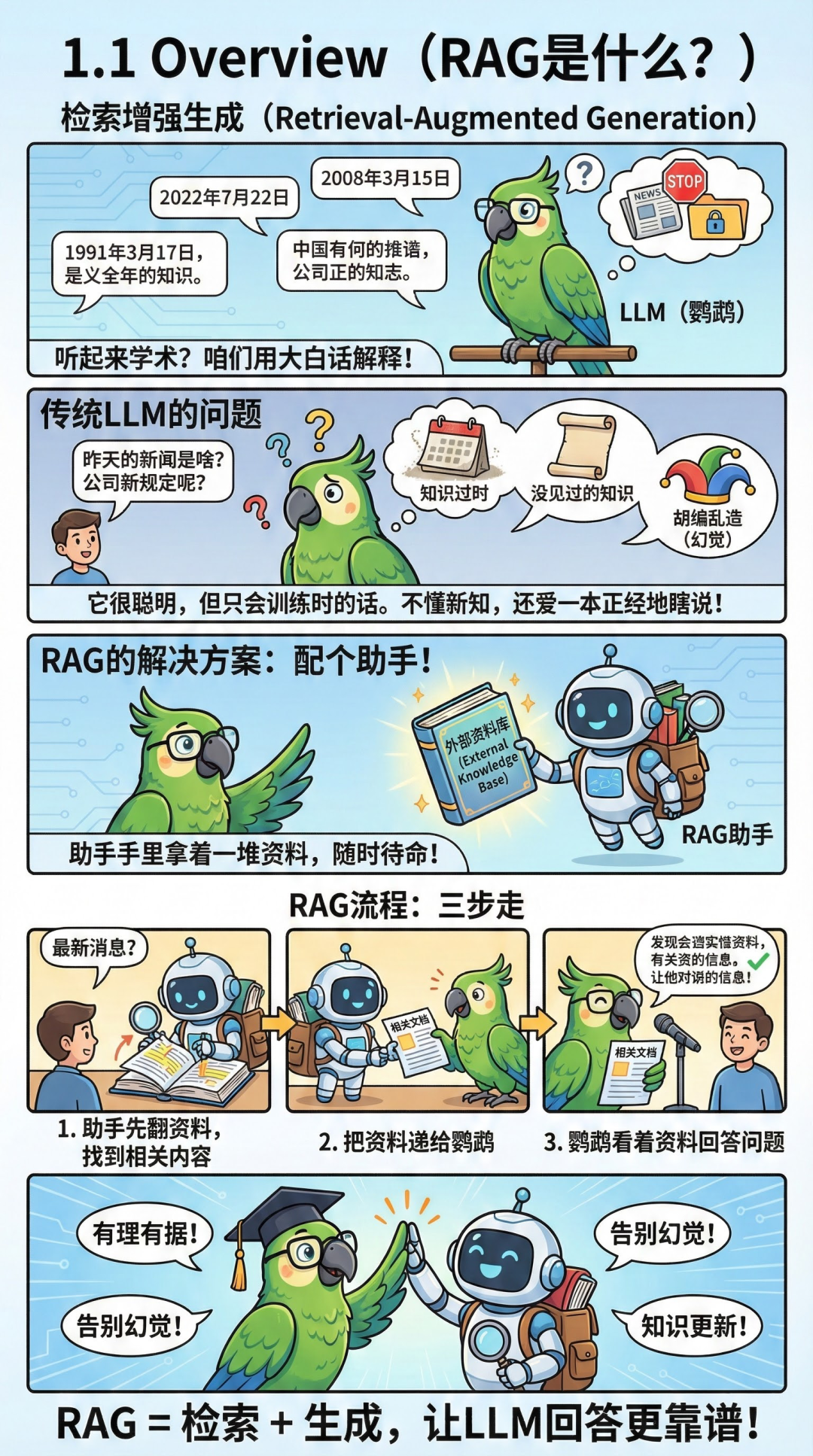
RAG的全程是Retrieval-Augmented Generation,中文叫“检索增强生成”。RAG技术通过将检索机制与生成模型结合,使LLM能够从外部知识源获取相关文档并基于这些文档生成答案,从而解决了传统LLM的知识过时,缺乏领域知识和幻觉等问题。
RAG的核心优势:
| 特性 | 传统LLM | RAG系统 |
| 知识更新 | 需要重新训练(成本高) | 只需要更新知识库(成本低) |
| 事实准确性 | 容易产生幻觉 | 基于检索到的真实文档 |
| 领域适应 | 需要微调模型 | 添加领域文档即可 |
| 可追溯性 | 无法追溯来源 | 可以标注来源和引用 |
| 成本 | 训练和部署成本高 | 相对经济实惠 |
举个实际例子:
假设你在做一个医疗问答系统:
用户问:“阿司匹林的常见副作用是什么?”
传统LLM可能回答:
“阿司匹林可能导致胃部不适、恶心等。(但不确定是否完整或最新)”
RAG系统的工作流程:
检索系统在医学数据库中搜索"阿司匹林 副作用"
找到3篇相关医学文献
提取关键信息:胃肠道反应、出血风险、过敏反应等
LLM基于这些文献生成答案:
"根据医学文献,阿司匹林的常见副作用包括:
胃肠道反应(胃痛、恶心、消化不良)
出血风险增加
过敏反应(如荨麻疹)
参考来源:[文献1]、[文献2]"
二、Indexing索引构建
索引构建是RAG的“预处理”阶段,就像你上学前需要先整理笔记、做好书签一样,这个阶段要把原始文档转化成机器能快速检索的格式。
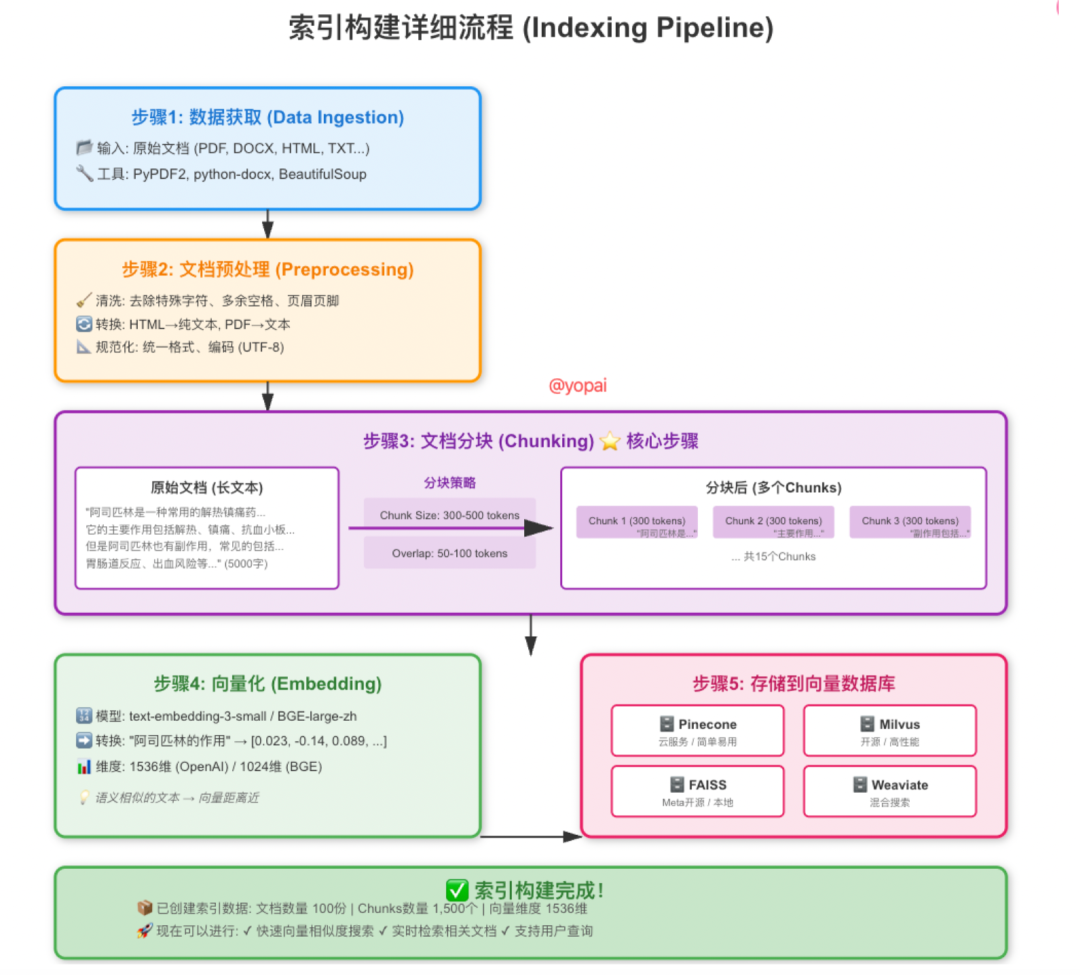
第一步:数据获取
收集数据,可能来自PDF、Word、Markdown文件;网页,Wili;数据库;邮件,聊天记录;Excel, CSV等结构化数据。
实际案例:某电商公司想做客服机器人,他们需要收集:产品说明文档(PDF)、常见问题FAQ(网页)、历史工单数据(数据库)、退换货政策(Word文档)
第二步:文档预处理(Preprocessing)
拿到原始数据后,需要“清洗”一下
# 示例:文档预处理代码
def preprocess_document(doc):
# 1. 移除多余的空格和换行
doc = re.sub(r'\s+',' ',doc)
# 2. 提取纯文本(从pdf, HTML等)
if doc_type == 'pdf':
text = extract_text_from_pdf(doc)
# 3. 规范化格式
text = text.strip().lower()
# 4. 去除无用信息(页眉、页脚等)
text = remove_headers_footers(text)
return text
第三步 文档分块(Chunking)
最关键的一步:把大文档切成小段,每段包含一个相对完整的语义单元
常见的分块策略:
1、固定大小分块(最简单,但可能切断语义)
# 每300个字符一块
chunk_size = 300
chunks = [text[i:i+chunk_size] for i in range(0, len(text),chunk_size)]
2、句子分块(按自然语言边界)
# 按句号、问号、感叹号分割
import nltk
# 段落分块(保留逻辑结构)
sentences = nltk.sent_tokenize(text)
# 按换行符或者段落标记分割
chunks = text.split('\n\n')
# 滑动窗口分块(带重叠、避免信息丢失)
chunk_size = 300
overlap = 50
chunks = []
for i in range(0, len(text), chunk_size - overlap):
chunks.append(text[i:i+chunk_size])
分块的关键参数:
块大小(Chunk Size):太小 ——> 语义不完整;太大 ——> 检索不精准(推荐:200 - 500 tokens (约150 - 400个汉字))
重叠(Overlap):避免关键信息被切断(推荐:10-20%的块大小)
举个例子:
原文:
阿司匹林是一种常用的解热镇痛药。它的主要作用包括:
解热:降低发烧体温
镇痛:缓解轻到中度疼痛
抗血小板:预防血栓形成
但是,阿司匹林也有副作用。常见的副作用包括:
胃肠道反应:胃痛、恶心
出血风险:特别是长期服用
分块后:
Chunk 1: "阿司匹林是一种常用的解热镇痛药。它的主要作用包括:
1. 解热:降低发烧体温
2. 镇痛:缓解轻到中度疼痛
3. 抗血小板:预防血栓形成"
Chunk 2: "阿司匹林的主要作用包括预防血栓形成。但是,阿司匹林也有副作用。
常见的副作用包括:
1. 胃肠道反应:胃痛、恶心
2. 出血风险:特别是长期服用"
注意chunk2有重叠,这样即使用户搜“副作用”,也能同时看到“作用”相关的上下文。
from typing import List
import re
class TextSplitter:
"""文本分割器"""
def __init__(
self,
chunk_size: int = 500,
chunk_overlap: int= 50,
separators: List[str] = None
):
self.chunk_size = chunk_size
self.chunk_overlap = chunk_overlap
self.separtors = separators or ["\n\n","\n","。","! ","? "," "] # 段落 -> 换行 -> 中文句子 -> 单词
def split_text(self, text: str) -> List[str]:
"""分割文本"""
chunks = []
current_chunk = ""
# 按分隔符分割
sentences = self._split_by_separators(text)
for sentence in sentences:
if len(current_chunk) + len(sentence) <= self.chunk_size:
current_chunk += sentence
else:
if current_chunk:
chunks.append(current_chunk.strip())
current_chunk = sentence
if current_chunk:
chunks.append(current_chunk.strip())
return chunks
def _split_by_separators(self, text: str) -> List[str]:
"""按分隔符分割"""
result = [text]
"""
第一轮:按 \n\n 切
第二轮:对结果再按 \n 切
第三轮:再按 。 切
"""
for separator in self.separators: # 逐级分割
new_result = []
for text in result:
new_reuslt.extend(text.split(separator))
resule = new_result
reurn [s for s in result if s.strip()]
# 使用示例
def create_chunks(text: str, chunk_size: int = 500) -> List[str]:
"""创建文本块"""
splitter = TextSplitter(chunk_size = chunk_size)
return splitter.split_text(text)
第四步 向量化(Embedding)
分块后的文本还是人类语言,机器不懂。我们需要把它转换成向量(一串数字)。
什么是Embedding?
把文字转换成数字向量,相似的文字会得到相似的向量。
#使用OpenAI的Embedding模型
from openai import OpenAI
client = OpenAI()
text = "阿司匹林是一种解热镇痛药"
response = client.embeddings.create(
model="text-embedding-3-small",
input=text
)
vector = response.data[0].embedding
print(f"向量维度: {len(vector)}") # 输出: 1536
print(f"前5个值: {vector[:5]}") # 输出: [0.023, -0.014, 0.089, ...]
向量化之后,向量之间可以计算相似度(余弦相似度),数值越接近1越相似:
"感冒药" → [0.1, 0.3, 0.5, ...]
"抗感冒药物" → [0.12, 0.29, 0.51, ...] # 向量很接近!
"汽车" → [0.8, 0.1, 0.2, ...] # 向量差很远
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
vec1 = np.array([0.1, 0.3, 0.5])
vec2 = np.array([0.12, 0.29, 0.51])
similarity = cosine_similarity([vec1], [vec2])[0][0]
print(f"相似度: {similarity:.3f}") # 输出: 0.999(非常相似)
常用的Embedding模型:
| 模型 | 维度 | 优势 | 适用场景 |
| OpenAI text-embedding-3-small | 1536 | 效果好,速度快 | 通用场景 |
| OpenAI text-embedding-3-large | 3072 | 效果最好 | 高精度需求 |
| BGE-large-zh | 1024 | 中文效果好 | 中文为主 |
| Sentence-BERT | 768 | 开源免费 | 资源有限 |
向量嵌入的完整实现:
import openai import AsyncOpenAI
from typing import List
import numpy as np
async def get_embeddings(
texts: List[str],
model: str = "text-embedding-3-small"
) -> List[List[float]]:
client = AsyncOpenAI() # 读取API Key, 通常来自.env;建立连接
response = await client.embeddings.create(
model = model,
input = texts
) # 将文本送入模型,返回向量表示
return [item.embedding for item in response.data]
# 相似度计算
def cosine_similarity(a: List[float], b:List[float]) -> float:
"""计算余弦相似度"""
a = np.array(a)
b = np.array(b)
return np.dot(a, b)/(np.linalg.norm(a)*np.linalg.norm(b))
# 使用示例
async def find_similar(query: str, documents: List[str], top_k: int = 3):
"""找到最相似的文档"""
# 获取查询向量
query_embedding = (await get_embedding([query]))[0]
# 获取文档向量
doc_embedding = await get_embeddings(documents)
# 计算相似度
similarities = [
(i, cosine_similarity(query_embedding, doc_emb))
for i, doc_emb in enmuerate(doc_embeddings)
]
# 排序并返回top_k
similarities.sort(key=lambda x:x[1], reverse = True)
return [(documents[i],sim) for i,sim in similarities[:top_k]]
第五步 存储到向量数据库
最后,把这些向量存起来,用专门的向量数据库(Vector Database)。
为什么不用普通数据库?
普通数据库(MySQL、MongoDB)擅长精确查询:“找ID = 123的记录”,但是向量搜索是相似性查询:“找和[0.1, 0.3, 0.5]最相似的10个向量“。
向量数据库用了特殊的索引算法(如HNSW、IVF),能在百万、千万级向量中毫秒级找到最相似的。
常用向量数据库:
1、Pinecone (云服务,简单好用)
import pinecone
pinecone.init(api_key = "your-api-key")
index = pinecone.Index('my-rag-index')
# 插入向量
index.upsert(
[
("doc1_chunk1", vector1, {"text":"阿司匹林是..."}),
("doc1_chunk2", vector2, {"text":"副作用包括..."})
]
)
# 查询
results = index.query(query_vector, top_k = 3)
2、Milvus (开源,功能强大)
3、FAISS(Facebook开源,本地使用)
4、Weaviate(支持混合搜索)
完整的索引构建代码示例:
# =========================
# 1. 导入
# =========================
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
# =========================
# 2. 加载文档
# =========================
loader = TextLoader("data.txt", encoding="utf-8")
documents = loader.load()
print(f"加载文档数: {len(documents)}")
# =========================
# 3. 文档分块(核心)
# =========================
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50,
separators=["\n\n", "\n", "。", "!", "?", " ", ""]
)
# 核心算法:优先大语义 → 不行再细分 → 最后强制切
chunks = text_splitter.split_documents(documents)
print(f"分块数量: {len(chunks)}")
# =========================
# 4. 向量化模型
# =========================
embeddings = OpenAIEmbeddings(
model="text-embedding-3-small"
)
# =========================
# 5. 构建向量数据库
# =========================
# 内部结构:id → embedding → text → metadata
vectorstore = Chroma.from_documents(
documents=chunks,
embedding=embeddings,
persist_directory="./chroma_db"
)
# 通过pinecone构建
pinecone.init(api_key="your-key")
index_name = "medical-rag"
#5. 创建索引并存储
vectorstore = Pinecone.from_texts(
texts=chunks,
embedding=embeddings,
index_name=index_name
)
# =========================
# 6. 持久化
# =========================
vectorstore.persist()
三、Retrieval (检索:快速找到相关知识)
检索阶段的任务是:从海量知识中快速找出最相关的那几条
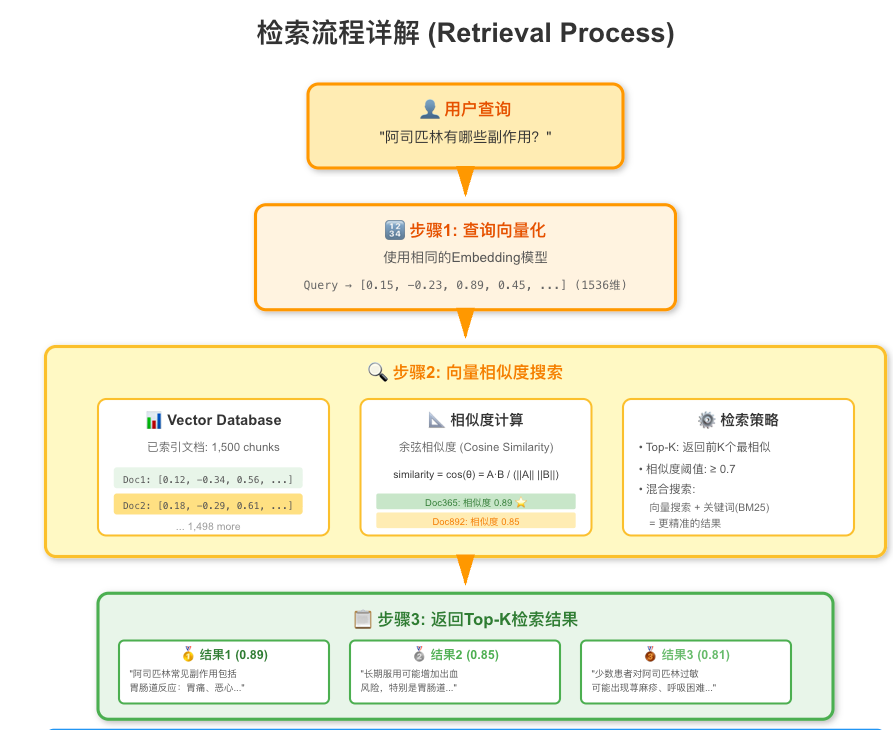
查询处理
用户输入的问题往往不是完美的搜索词。比如:
用户原始问题:"我吃了阿司匹林后胃疼怎么办?"
需要优化为:
"阿司匹林 胃痛 副作用"(关键词提取)
"阿司匹林导致的胃部不适如何处理"(问题改写)
向量检索
1、Vector Retriever: 基于Embedding。能理解语义,但是对专有名词,数字等不敏感。
# 加载数据库
from langchain_core.documents import Document
docs = [
Document(page_content="E.coli is a common pathogen in lung infection", metadata={"species": "E.coli"}),
Document(page_content="Streptococcus pneumoniae causes pneumonia", metadata={"species": "S.pneumoniae"}),
Document(page_content="Normal lung microbiome contains commensal bacteria", metadata={"type": "commensal"}),
]
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
# 向量化
embedding = OpenAIEmbeddings(model="text-embedding-3-small")
vectorstore = Chroma.from_documents(
docs,
embedding,
persist_directory="./db"
)
########### 构建retriever ###########
vector_retriever = vectorstore.as_retriever(
search_kwargs={"k": 3}
)
results = vector_retriever.invoke("lung infection bacteria")
2、Keyword Retriever (关键词/BM25): 传统搜索,基于关键词匹配
########### Keyword Retriever (BM25) ###########
from langchain_community.retrievers import BM25Retriever
bm25_retriever = BM25Retriever.from_documents(docs)
bm25_retriever.k = 3
results = bm25_retriever.invoke("E.coli infection")
3、Hybrid Retriever:检索系统通常采用混合搜索方法,结合向量搜索(找语义相似的文档)和关键词搜索(精确匹配),然后对结果进行排序和过滤。
初步检索后,可以用更精细的模型重新排序,提高精度。
########### Hybrid Retriever ###########
import numpy as np
class HybridRetriever:
def __init__(self, retrievers, weights=None):
self.retrievers = retrievers
self.weights = weights or [1.0] * len(retrievers)
def invoke(self, query):
all_docs = []
scores = []
for retriever, weight in zip(self.retrievers, self.weights):
docs = retriever.invoke(query)
for i, doc in enumerate(docs):
# 简单排名分数(可换更复杂)
score = weight * (1.0 / (i + 1))
all_docs.append(doc)
scores.append(score)
# 排序
ranked = sorted(zip(all_docs, scores), key=lambda x: x[1], reverse=True)
# 去重
seen = set()
result = []
for doc, _ in ranked:
if doc.page_content not in seen:
seen.add(doc.page_content)
result.append(doc)
return result
hybrid = HybridRetriever(
retrievers=[vector_retriever, bm25_retriever],
weights=[0.7, 0.3]
)
results = hybrid.invoke("E.coli infection")
四、Generation (生成:基于知识产生答案)
检索到相关文档后,最后一步就是生成答案
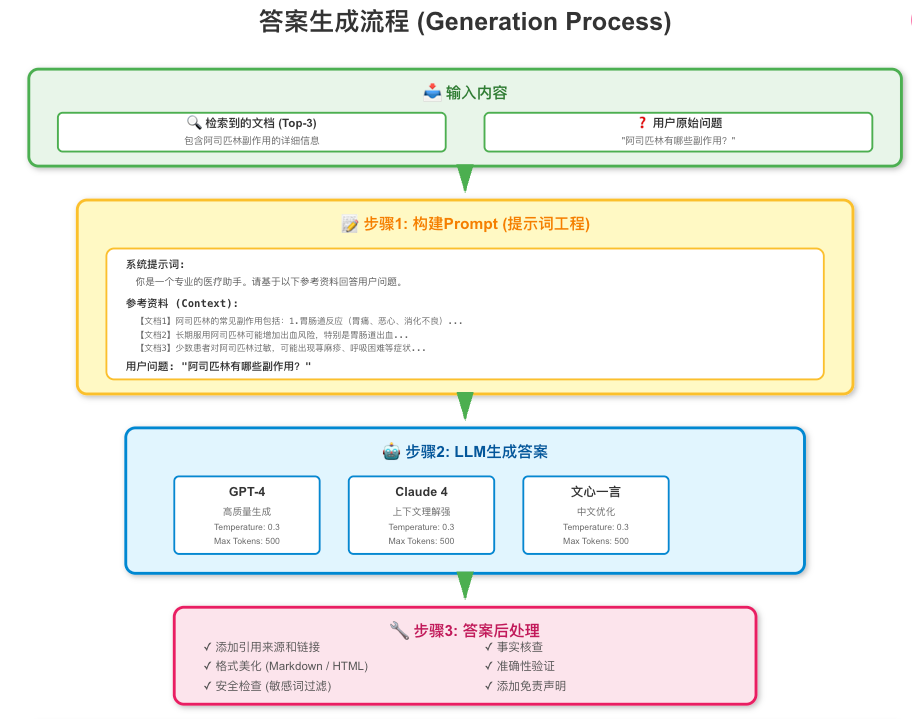
提示词的构建(Prompt Engineering)
把检索到的文档和用户问题组合成一个完整的提示词(Prompt),发给LLM
基础模版:
prompt_template = """
你是一个专业的医疗助手。请基于以下参考资料回答用户的问题。
如果参考资料中没有相关信息,请明确告知用户。
参考资料:
{context}
用户问题:
{question}
请提供详细、准确的回答,并标注信息来源。
"""
#填充内容
context = "\n\n".join([doc.page_content for doc in retrieved_docs])
question = "阿司匹林有哪些副作用?"
prompt = prompt_template.format(context=context, question=question)
进阶模版(结构化输出):
advanced_prompt = """
参考资料:
{context}
用户问题:{question}
请按以下格式回答:
直接回答:用1-2句话概括答案
详细说明:展开解释,分点列出
注意事项:相关的警告或建议
信息来源:标注参考了哪些资料
回答:
"""
调用LLM生成
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model="gpt-4",
messages=[
{"role": "system", "content": "你是一个专业的医疗助手"},
{"role": "user", "content": prompt}
],
temperature=0.3, # 降低随机性,提高准确性
max_tokens=500
)
answer = response.choices[0].message.content
print(answer)
答案后处理
生成答案后,可能还需要:
1、引用标注:给答案加上来源链接
def add_citations(answer, sources):
"""给答案添加引用"""
for i, source in enumerate(sources):
answer += f"\n[{i+1}] {source['title']} - {source['url']}"
return answer
2、安全过滤:检查答案是否包含有害内容
def safety_check(answer):
harmful_keywords = ["自杀","违法","...]
for keyword in harmful_keywords:
if keyword in answer:
return "抱歉,这个问题涉及敏感内容,建议咨询专业人士"
return answer
完整的RAG代码
def rag_query(question):
"""完整的RAG查询流程"""
# 1. 检索相关文档
retrieved_docs = vectorstore.similarity_search(question, k=3)
# 2. 构建prompt
context = "\n\n".join([
f"【文档{i+1}】{doc.page_content}"
for i, doc in enumerate(retrieved_docs)
])
prompt = f"""
参考以下资料回答问题:
{context}
问题:{question}
要求:
1. 回答要准确、专业
2. 必须基于参考资料
3. 标注信息来源
"""
# 3. 调用LLM生成
response = client.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": prompt}],
temperature=0.3
)
answer = response.choices[0].message.content
# 4. 添加引用
sources = [
{"title": f"文档{i+1}", "score": doc.metadata.get('score', 0)}
for i, doc in enumerate(retrieved_docs)
]
return {
"answer": answer,
"sources": sources,
"retrieved_docs": [doc.page_content for doc in retrieved_docs]
}
#使用示例
result = rag_query("阿司匹林有哪些副作用?")
print("答案:", result['answer'])
print("\n参考来源:", result['sources'])
01
什么是AI大模型应用开发工程师?
如果说AI大模型是蕴藏着巨大能量的“后台超级能力”,那么AI大模型应用开发工程师就是将这种能量转化为实用工具的执行者。
AI大模型应用开发工程师是基于AI大模型,设计开发落地业务的应用工程师。
这个职业的核心价值,在于打破技术与用户之间的壁垒,把普通人难以理解的算法逻辑、模型参数,转化为人人都能轻松操作的产品形态。
无论是日常写作时用到的AI文案生成器、修图软件里的智能美化功能,还是办公场景中的自动记账工具、会议记录用的语音转文字APP,这些看似简单的应用背后,都是应用开发工程师在默默搭建技术与需求之间的桥梁。
他们不追求创造全新的大模型,而是专注于让已有的大模型“听懂”业务需求,“学会”解决具体问题,最终形成可落地、可使用的产品。
CSDN粉丝独家福利
给大家整理了一份AI大模型全套学习资料,这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】

02
AI大模型应用开发工程师的核心职责
需求分析与拆解是工作的起点,也是确保开发不偏离方向的关键。
应用开发工程师需要直接对接业务方,深入理解其核心诉求——不仅要明确“要做什么”,更要厘清“为什么要做”以及“做到什么程度算合格”。
在此基础上,他们会将模糊的业务需求拆解为具体的技术任务,明确每个环节的执行标准,并评估技术实现的可行性,同时定义清晰的核心指标,为后续开发、测试提供依据。
这一步就像建筑前的图纸设计,若出现偏差,后续所有工作都可能白费。
技术选型与适配是衔接需求与开发的核心环节。
工程师需要根据业务场景的特点,选择合适的基础大模型、开发框架和工具——不同的业务对模型的响应速度、精度、成本要求不同,选型的合理性直接影响最终产品的表现。
同时,他们还要对行业相关数据进行预处理,通过提示词工程优化模型输出,或在必要时进行轻量化微调,让基础模型更好地适配具体业务。
此外,设计合理的上下文管理规则确保模型理解连贯需求,建立敏感信息过滤机制保障数据安全,也是这一环节的重要内容。
应用开发与对接则是将方案转化为产品的实操阶段。
工程师会利用选定的开发框架构建应用的核心功能,同时联动各类外部系统——比如将AI模型与企业现有的客户管理系统、数据存储系统打通,确保数据流转顺畅。
在这一过程中,他们还需要配合设计团队打磨前端交互界面,让技术功能以简洁易懂的方式呈现给用户,实现从技术方案到产品形态的转化。
测试与优化是保障产品质量的关键步骤。
工程师会开展全面的功能测试,找出并修复开发过程中出现的漏洞,同时针对模型的响应速度、稳定性等性能指标进行优化。
安全合规性也是测试的重点,需要确保应用符合数据保护、隐私安全等相关规定。
此外,他们还会收集用户反馈,通过调整模型参数、优化提示词等方式持续提升产品体验,让应用更贴合用户实际使用需求。
部署运维与迭代则贯穿产品的整个生命周期。
工程师会通过云服务器或私有服务器将应用部署上线,并实时监控运行状态,及时处理突发故障,确保应用稳定运行。
随着业务需求的变化,他们还需要对应用功能进行迭代更新,同时编写完善的开发文档和使用手册,为后续的维护和交接提供支持。
03
薪资情况与职业价值
市场对这一职业的高度认可,直接体现在薪资待遇上。
据猎聘最新在招岗位数据显示,AI大模型应用开发工程师的月薪最高可达60k。
在AI技术加速落地的当下,这种“技术+业务”的复合型能力尤为稀缺,让该职业成为当下极具吸引力的就业选择。
AI大模型应用开发工程师是AI技术落地的关键桥梁。
他们用专业能力将抽象的技术转化为具体的产品,让大模型的价值真正渗透到各行各业。
随着AI场景化应用的不断深化,这一职业的重要性将更加凸显,也必将吸引更多人才投身其中,推动AI技术更好地服务于社会发展。
CSDN粉丝独家福利
给大家整理了一份AI大模型全套学习资料,这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献177条内容
已为社区贡献177条内容

所有评论(0)