OpenVLA-OFT
2025年2月 由斯坦福大学团队推出的 OpenVLA 优化微调方案
它不是一个全新的模型,而是一个微调方案,让你在原 OpenVLA-7B 的基础上,用极低的代价获得速度更快、成功率更高、更灵活的机器人策略。
原OpenVLA 的训练方案是为了最大程度兼容 VLM预训练范式 的稳妥性设计,具体就是:
● 自回归解码
● 离散动作 token 化(把连续动作量化为 256 个 bin [<action_128>, <action_135>, <action_128>, …]
● 下一个token预测,导致了效率低、精度差、无法适配高频控制的问题(OpenVLA 10Hz)
这种设计的好处是训练稳定 、 能直接用 Llama 类的 VLM 预训练权重,但付出的代价非常大:
● 效率极低:每个动作都要逐 token 自回归生成,一步动作需要多次 forward pass -> 推理速度只有 4~10Hz(论文里基准是 4.2Hz)
● 精度损失:离散化引入微量误差,动作不平滑,一卡一卡的
● 无法高频控制:真实机器人通常需要 25~50Hz 以上控制频率,原版根本做不到实时闭环
这正是 OpenVLA 被吐槽”能用但不好用“的根本原因
- 核心创新:OFT 优化微调配方(四大关键改动)
原 OpenVLA 的微调是“vanilla LoRA + diffusion”,OFT 团队通过大量消融实验,总结出了下面这套简单却极强的配方:
改进点 原 OpenVLA OpenVLA-OFT (新方案) 带来的好处
动作解码方式 自回归 并行解码 + Action Chunking 推理速度提升 25~50 倍
动作表示 离散 连续动作表示 更稳定、更容易训练
损失函数 交叉熵损失 简单 L1 回归 抗噪能力强,成功率更高
额外模块 无 可选 FiLM(OFT+ 版) 语言指令跟随能力大幅提升
这些改动加在一起,让7B 参数的 VLA 模型终于能实时控制真实机器人(50Hz 双臂)。 - 性能表现(吊打一大堆 SOTA)
仿真基准(LIBERO):
● 原 OpenVLA:平均成功率 76.5%
● OpenVLA-OFT:97.1%(新 SOTA)
● 同时推理速度提升 26 倍,延迟降低 3 倍
● 四个子任务(Spatial / Object / Goal / Long)全部大幅领先 π₀、MDT、Seer、DiT Policy、Octo、Diffusion Policy 等
真实机器人(ALOHA 双臂):
● 引入 FiLM 后叫 OpenVLA-OFT+
● 在折衣服、按语言指令抓特定食物等灵巧任务上,平均成功率领先其他 VLA 15%
● 能做到真正的语言驱动高频控制(用户说“把黄色玉米放进锅里”就能执行)
项目 原 OpenVLA 仓库 OpenVLA-OFT 仓库
推荐微调方式 2025-03-03 后官方已推荐 OFT 就是官方新推荐方案
代码结构 vla-scripts/finetune.py(老版) 全新 vla-scripts/finetune.py(OFT版)
requirements.txt 有 没有(用 pip install -e .
)
支持特性 单图、慢速 多图输入 + proprio + 高频控制
显存友好度 一般 更好(4090 完全能跑)
预训练 checkpoint openvla/openvla-7b moojink/openvla-7b-oft-xxx(已训好)
3.模型架构
下面是 OpenVLA-OFT的 pipline
1.多模态输入采集
3路相机视觉信号(第三人称全局 + 双腕相机) 、 14维机械臂关节本体状态、自然语言任务指令
在这里插入图片描述
2.视觉编码与FiLM语言编码
● 多视角图像ViT(SigLIP+DINOv2)提取视觉特征
● 语言嵌入生成参数γ/β,通过FiLM仿射变换,将语言信息融合进视觉特征
3. 多模态特征融合
调制后视觉特征、本体状态、语言特征投影至统一嵌入空间,拼接为多模态序列,输入LLM主干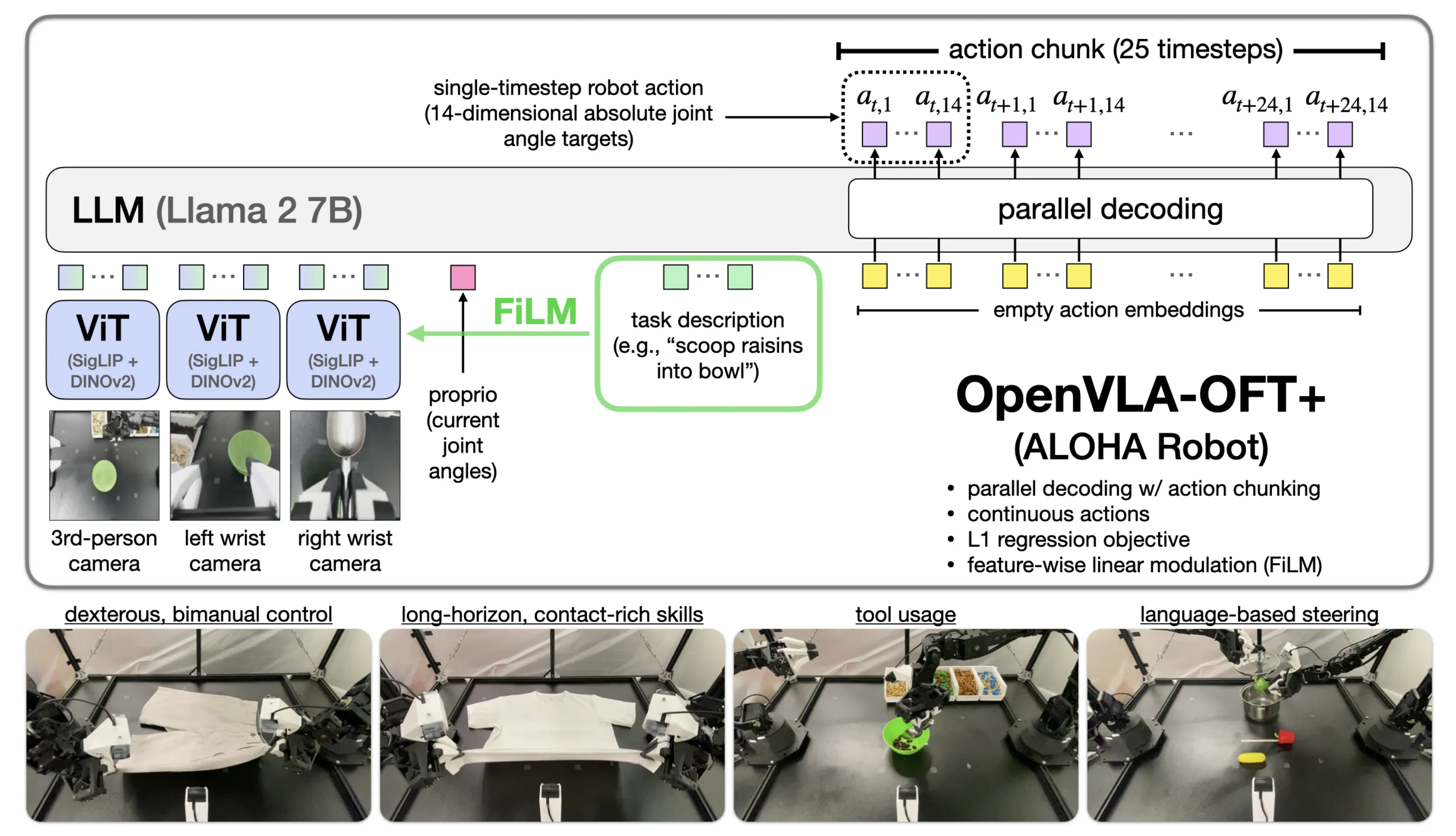
- LLM双向注意力建模
基于 Llama 2 7B主干,替换自回归注意力为双向注意力,模型不再是"猜一个动作,再根据这个动作猜下一个动作",而是一次性看完整块动作,像人类一样"先想好整个动作序列,再细化每个步骤"
视觉 + 语言指令的信息能更充分地跨时间步融合到每个动作预测上,避免了自回归地误差累积 - 并行解码 + 动作分块输出
输入空动作嵌入,单次前向传播 并行生成25步14维连续动作分块,以L1回归为学习目标保证动作鲁棒性
OFT连续动作如何表示
OFT 一次并行输出一个"动作块(Action Chunk)",而不是一个一个 token生成。
每个 chunk 的 形式是:
At=[a0t, a1t, …, aLc−1t]∈RLc×D\mathcal{A}^{t} = [a_{0}^{t},\ a_{1}^{t},\ \dots,\ a_{L_c-1}^{t}] \in \mathbb{R}^{L_c \times D}At=[a0t, a1t, …, aLc−1t]∈RLc×D
● LcL_cLc = chunk 大小(默认 8,可配置,通常 4~25)
● DDD = 动作维度(DoF),例如:
○ Franka Panda 单臂:7(位置+旋转+夹爪)或 14(位置+速度)
○ ALOHA 双臂:通常 14 或更高
● 每个 ai 是一个连续浮点向量,归一化到 [-1, 1](这是机器人控制里的标准做法)
模型每一步只预测一个 chunk,后续直接开环执行这 8 步动作,大大降低延迟。
模型如何输出连续动作?(架构层面) - LLM 输出隐藏状态
- 专用的 Action Head (MLP)
● 一个轻量 4 层 MLP (带 ReLU 或 GELU 激活)
● 把 LLM 的hidden states 直接映射成连续动作向量 - 损失函数
只用 L1 回归 。对机器人噪声鲁棒性好
L1回归
什么是 L1 回归?
L1 回归 也叫最小绝对偏差回归。核心思想:用绝对误差作为损失函数,让模型直接预测连续的动作值。
它本质上就是 Mean Absolute Error (MAE) 作为损失:
LL1=1N∑i=1N∣yi−y^i∣\mathcal{L}_{\text{L1}} = \frac{1}{N} \sum_{i=1}^{N} |y_i - \hat{y}_i|LL1=N1∑i=1N∣yi−y^i∣
和 L2 回归(MSE)的对比
LL2=1N∑(y−y^)2\mathcal{L}_{\text{L2}} = \frac{1}{N} \sum (y - \hat{y})^2LL2=N1∑(y−y^)2
平方误差对大误差惩罚极重,对小误差敏感,但容易被噪声拉偏
机器人动作数据里经常有噪声(摄像头抖动、执行器延迟、人类演示不完美),L1 比L2更稳定,不会偶尔的一次"异常动作"就把模型带偏
在 OpenVLA-OFT中的具体用法
OFT 把动作表示从"离散向量"改成了 连续向量
● 模型最后一层是一个简单的 MLP 头,直接输出连续动作。
● 训练时 只用 L1 回归损失(–use_l1_regression True)。
● 同时开启 Action Chunking(一次预测未来 8 步动作),所有动作并行计算。
这就把原 OpenVLA 的“自回归 + Diffusion 多步去噪”全部扔掉,变成了最简洁、最有效的回归问题。
为什么 OFT 要用 L1? - 训练更稳定、更快
Diffusion 需要多步去噪(几十步), L1 就是一次前向 + 一次损失计算,训练速度大幅度提升。 - 动作更平滑、精度更高
没有离散量化的误差,也没有 Diffusion 的采样噪声,真实机器人执行起来更丝滑。 - 对机器人数据更友好
真实演示数据里噪声多、分布不均匀,L1的鲁棒性让模型更容易学到本质规律。 - 实测结果
● LIBERO 成功率:原版 ~76% → OFT(L1)97.1%
● 推理速度:4.2 Hz → 108 Hz(26 倍加速)
VLA动作解码方法对比:OpenVLA、OpenVLA-OFT、扩散建模、流匹配
VLA 模型的核心瓶颈之一就是动作解码方式。它直接决定了推理速度、动作平滑度、训练稳定性、成功率以及是否支持高频实时控制(25~100Hz)。
下面是 4 种主流动作解码方式
1.OpenVLA 原版 – 自回归 + 离散Token解码
● 动作表示:把连续动作 划分为 256 个 bin,映射成特殊 token(<action_128> 、<action_135>)
● 解码方式:经典自回归 + 因果注意力
○ 每次只预测下一个 token , 必须把已生成的动作 token 重新塞回输入。
● 损失函数:交叉熵(下一个 token 预测)
● 缺点:误差累积严重、无法并行生成
● 优点:最简单、最稳定、完全兼容 VLM 预训练的权重
2.OpenVLA-OFT – 并行解码 + 连续动作 + L1回归
● 动作表示:连续向量
● 解码方式:并行解码
○ 把Llama-2的因果注意力 替换为双向注意力机制
○ 一次 forward pass 同时预测整个 动作chunck
● 损失函数:L1回归
3.Diffusion建模
生成式方法,很多 VLA(如 π₀、部分 OpenVLA-OFT 实验版)都在用。
● 动作表示:连续动作轨迹
● 解码方式:迭代去噪
○ 前向加噪:给干净动作逐步加高斯噪声
○ 反向去噪:模型预测噪声,逐步去噪恢复动作
● 损失函数:Noise Prediction MSE(预测噪声)
● 推理过程:从纯噪声开始,通常采样 10~50 步(DDPM / DDIM / DPM-Solver)。
Diffusion这部分待学习!
4.Flow Matching(流匹配)
最新的生成式方法,已成为 π₀、GR00T-N1 等顶级 VLA 的主力解码方式,被认为是 Diffusion 的高效替代品。
● 动作表示:连续动作轨迹
● 解码方式:学习速度场,让噪声沿直线路径直接"流动"到真实动作。
● 损失函数:Conditional Flow Matching(CFM)(直接回归速度向量)。
● 推理过程:ODE 求解器(通常 5~20 步,比 Diffusion 采样更快、更稳定)。
数学表达(CFM 目标):
LFM=Et, xt[∥vt(xt)−ut(xt∣c)∥2]\mathcal{L}_{\text{FM}} = \mathbb{E}_{t,\; x_t} \left[ \left\| v_t(x_t) - u_t(x_t \mid c) \right\|^2 \right]LFM=Et,xt[∥vt(xt)−ut(xt∣c)∥2]
(vtv_tvt = 真实速度场,utu_tut = 模型预测的速度)
性能:
● 推理速度:比 Diffusion 更快(通常 2~5×),可达 30~80 Hz
● LIBERO / 真实机器人成功率:顶级(π₀ 等模型常用)
● 优点:采样步数少、直线路径更高效、训练更稳定、动作极度平滑。
● 缺点:需要精心设计路径(直线流 / 整流流),对 chunk 大小敏感。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)