【收藏级干货】AI大模型底层技术全解析:从神经网络到算力架构
本节目录&后续章节:
- 神经网络:常见神经网络的适用场景、优势与痛点
- 算法:算法的分类&经典算法原理解析
- 模型:各模型的架构基础、核心能力与落地价值
- 算力:硬件的适配场景与部署架构
【后续章节】:对涉及到的核心技术做深入浅出的补充,按机器学习&深度学习→大模型基础→模型训练体系→模型落地与经典算法的逻辑展开,帮助大家理解算法工程师的模型训练逻辑、模型实现思路、更清晰地认识AI能力边界。
神经网络、算法、模型、架构、算力?
首先,我们先理清楚他们之间的关系
- 神经网络是 AI 领域专属的模型架构类型
- 算法是所有计算的通用核心方法,驱动网络、模型运行
- 架构定义神经网络的组织形式,是模型的整体结构设计方案,举个例子,你可以这么说:使用Transformer架构搭建 Transformer 模型,Transformer架构由编码器 + 解码器 + 自注意力三个模块组成
- 模型是架构 + 网络 + 算法的综合落地产物
- 算力是所有技术环节的硬件支撑
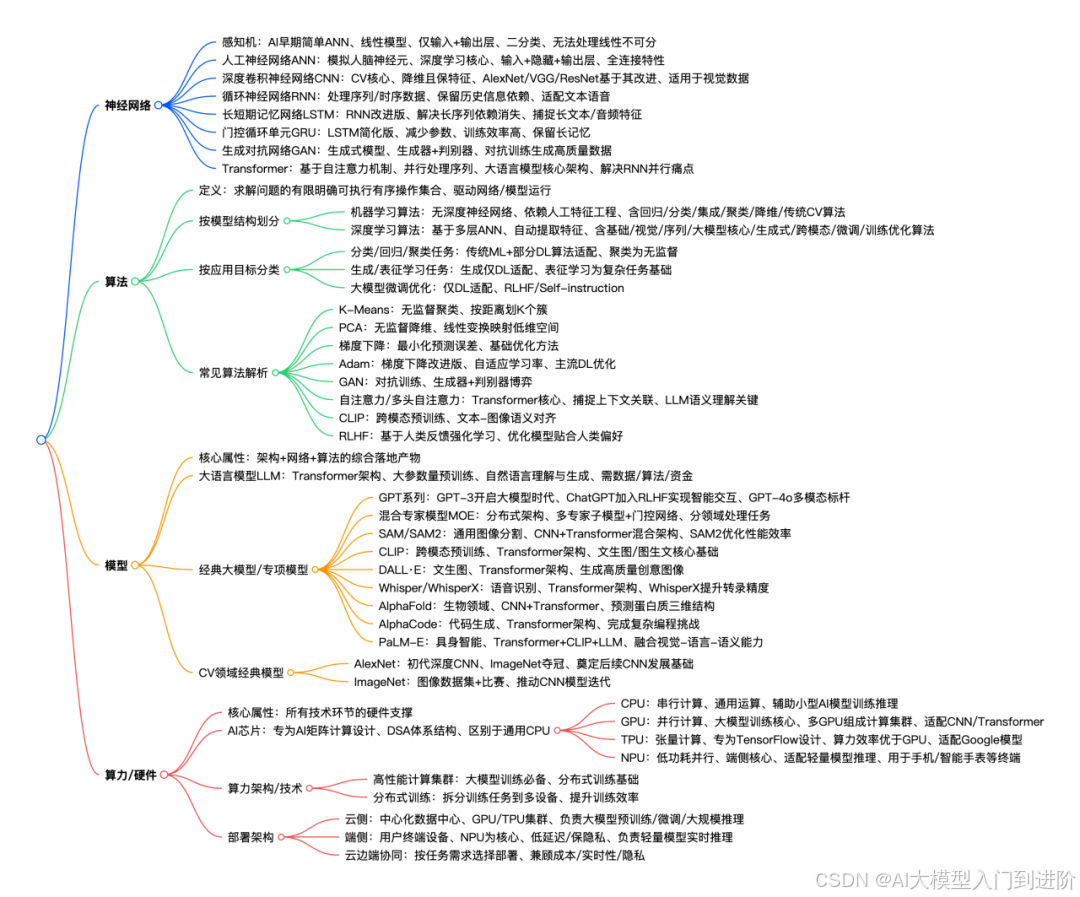
1 神经网络
神经网络,由相互连接的人工神经元(节点)组成,通过学习和训练,从数据中提取规律,完成分类、预测、识别等任务。
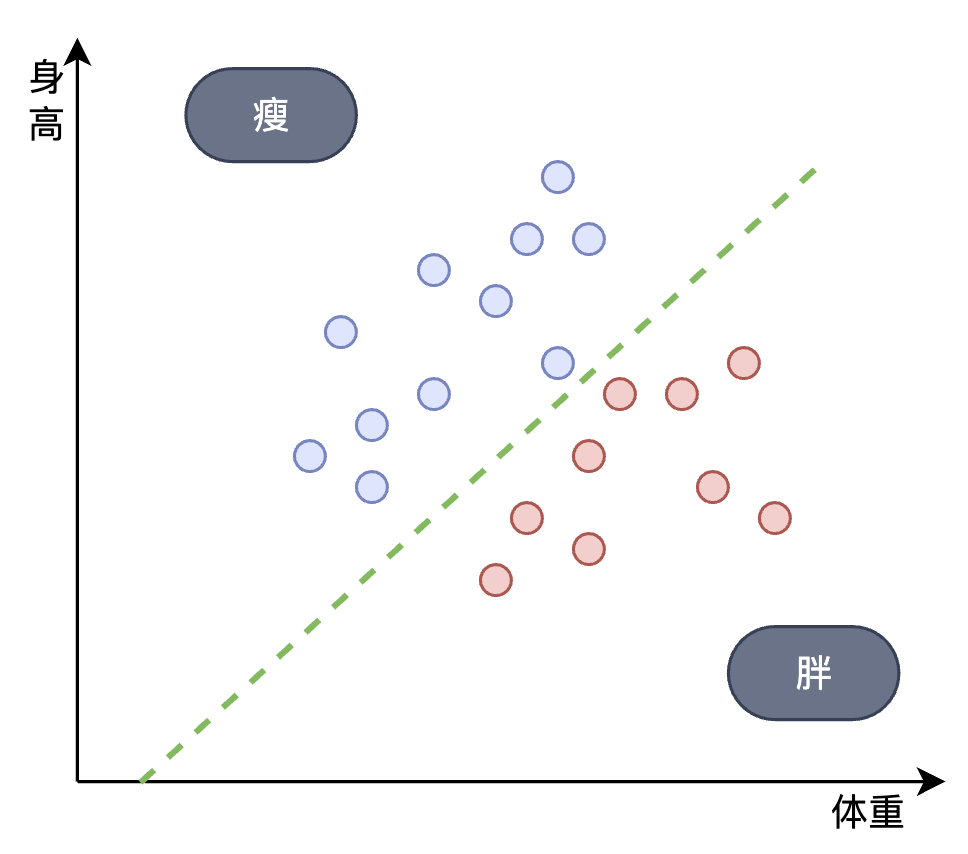
感知机(Perceptron)
AI早期的简单人工神经网络,仅含输入层和输出层,本质上是一种线性模型,可实现基础的二分类任务
缺陷:无法处理线性不可分的问题
人工神经网络
ANN, Artificial Neural Network
模拟人脑神经元的连接结构构建的算法模型,是深度学习、机器学习的核心基础。
神经网络:按照一定规则将多个神经元连接起来的网络,不同的神经网络,具有不同的连接规则。
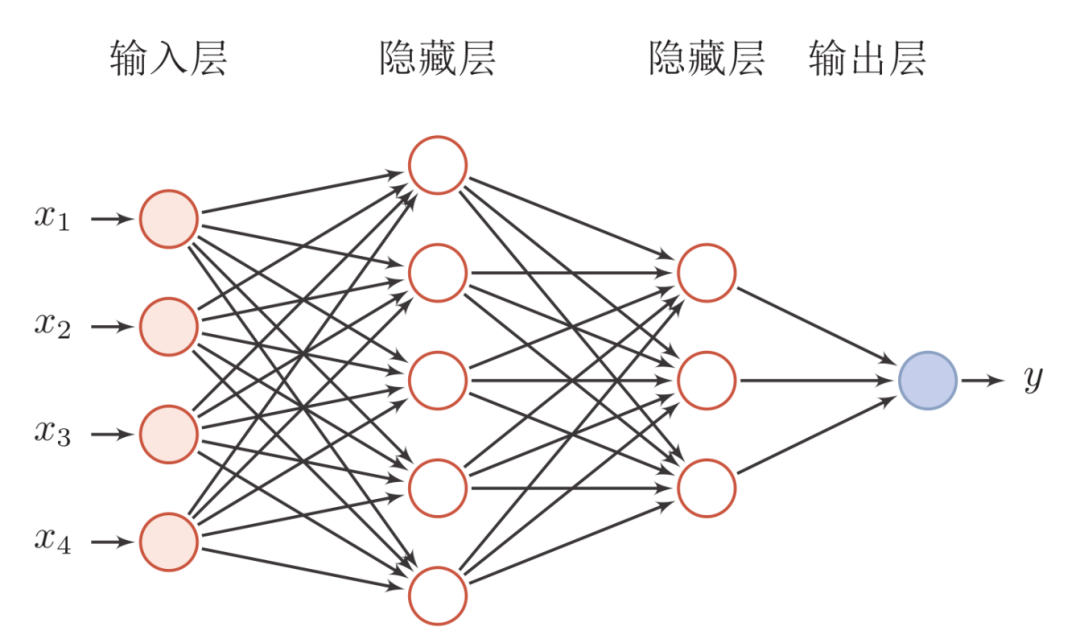
一些规律:
- 层次结构为:输入层(Input Layer)、隐藏层(HiddenLayer)、输出层(OutputLayer)
- 中间的隐藏层可以设置多层
- 同一层的神经元之间没有连接
- 全连接的含义:第 N层的每个神经元和第 N-1层的所有神经元相连,第 N-1 层神经元的输出就是第 N层神经元的输入。
- 每个连接都有一个权值
深度卷积神经网络
CNN, Convolutional Neural Network
专为视觉数据设计的深层神经网络,通过卷积层提取图像、视频的局部特征,是CV的核心,后续经典的 CV 模型,如 AlexNet、VGG、ResNet 等,均在 CNN 的卷积层、池化层基础上做结构改进,进一步提升图像特征提取能力和模型训练效率。
CNN 有2大特点:
- 能够有效的将大数据量的图片降维成小数据量
- 能够有效的保留图片特征,符合图片处理的原则
循环神经网络
RNN, Recurrent Neural Network
RNN也叫递归神经网络,主要对序列数据进行建模,能保留历史数据的信息依赖,适配文本、语音等时序数据处理。
💡时间序列数据,是指在不同时间点上收集到的数据,这类数据反映了某一事物、现象等随时间的变化状态或程度。一般的,在自然语言处理领域,我们的文本信息都是时间序列数据。
CNN等传统神经网络的局限:在传统的卷积神经网络中,输入和输出都是相对确定的,卷积核被设定好大小以后,其对整个图像的每个像素都适用,并且上一个输出结果对下一个输出结果没有任何影响。
但是在文本中,当我们理解一句话的意思时,孤立理解每个单词的意思是不够的,我们需要处理的是这些词语连接起来的完整内容,为了解决一些这样类似的问题,能够更好的处理序列的信息,RNN 就由此诞生。
长短期记忆网络
LSTM, Long Short-Term Memory
RNN的改进版,解决了传统RNN的长序列依赖消失问题,能有效捕捉长文本、长音频的特征。
门控循环单元
GRU, Gated Recurrent Unit
LSTM的简化版,减少了模型参数,训练效率更高,同样能保留长记忆能力,解决长序列依赖问题。
🌟生成对抗网络
GAN, Generative Adversarial Network
生成式模型,由生成器和判别器组成,一个负责造假,一个负责打假,二者对抗训练实现高质量数据生成。
🌟Transformer
基于自注意力机制的深度学习架构,能并行处理序列数据,精准捕捉长序列的上下文关联,是当下所有大语言模型(LLM)的核心底层架构,也是多模态模型的重要基础,LLM 的自然语言理解与生成能力,均基于 Transformer 的自注意力机制实现,解决了传统序列建模网络 RNN/LSTM无法并行计算的痛点,为大模型的海量数据训练和长文本处理提供了技术支撑。
💡为什么要有 Transformer?
Transformer之前的技术存在的问题:
-
RNN:能够捕获长距离依赖信息,但是无法并行计算;
-
CNN:能够并行,无法捕获长距离依赖信息,需要通过层叠或者扩张卷积核来增大感受野。
因此,需要一个可以并行运算,且可以捕获长距离依赖信息的架构,Transformer 架构就此诞生。
在实际应用中,神经网络架构并不是单独部署的,如多模态大模型 GPT-4o 融合Transformer +CLIP +CNN实现理解核心语义、提取图像特征、跨模态对齐。
灵活融合才是 AI 模型的主流研发思路。
2 算法
算法(Algorithm)是什么
是指为求解特定问题、完成特定任务而设计的有序操作集合,告诉神经网络、模型如何学习数据规律、如何优化参数、如何完成具体任务。
人工智能领域的算法分类:
(关注算法类别的含义,尝试理解热门算法原理,对算法名有个印象就可以)
(1)按所依赖的模型结构划分
【机器学习算法】:基于统计学习理论,无深度神经网络结构,依赖人工特征工程
-
🌟回归算法:通过拟合数据规律,输出具体数字,如房价、销量、温度、股价等
线性回归、多项式回归、岭回归、Lasso 回归
-
🌟分类算法:将输入数据映射至预设的离散类别,输出标签结果,如二分类:垃圾邮件or正常邮件;多分类:猫狗鸟。
逻辑回归、K 近邻算法(KNN), 支持向量机(SVM), 朴素贝叶斯, 决策树
-
集成算法:组合多个弱模型,打造强模型
随机森林, XGBoost, LightGBM, AdaBoost
-
🌟聚类算法:自动把相似数据归为一类,如用户分群、商品聚类、异常检测
K-Means、层次聚类(AGNES), DBSCAN
-
🌟降维算法:压缩数据特征维度,剔除冗余信息,加速训练,方便数据可视化
主成分分析(PCA), 线性判别分析(LDA)
-
传统 CV 算法:计算机视觉早期方案,纯手工设计图像特征,用于图像检测、特征匹配
Viola-Jones 人脸检测算法, SIFT, SURF, HOG
【深度学习算法】:基于多层人工神经网络架构,自动提取数据特征
-
基础网络:入门架构,由全连接神经元堆叠而成,处理简单结构化数据
感知机、全连接神经网络(ANN/ML)
-
计算机视觉网络:专门处理图像、视频,提取视觉特征
卷积神经网络(CNN), AlexNet, VGG, ResNet, SAM, CLIP
-
🌟序列建模网络:专门处理有序序列数据,解决数据先后依赖的问题
循环神经网络(RNN)、长短期记忆网络(LSTM)、门控循环单元(GRU)
-
🌟大模型核心网络:千亿参数大模型的底层,依靠自注意力机制实现高效并行
Transformer、混合专家模型(MOE), 大语言模型(LLM)
-
🌟生成式网络:学习数据,生成全新数据,如文生图、图生图、语音生成、文本续写等
生成对抗网络(GAN), 自编码器(AE), VAE、DALL・E
-
🌟跨模态核心算法:打通文本、图像、语音、视频不同类型的数据,实现多模态理解、对齐与交互
CLIP(对比语言 - 图像预训练)
-
🌟大模型微调算法:在预训练大模型基础上,对齐人类意图,使模型更安全听话
RLHF(从人类反馈的强化学习)
-
🌟训练优化算法:神经网络的参数调节器,更新模型权重、最小化误差,决定训练速度和精度。
梯度下降(GD), 批量梯度下降(BGD), 随机梯度下降(SGD), 小批量梯度下降(MBGD), Adam, RMSprop, Adagrad
(2)按应用目标分类
- 分类任务:
- 传统机器学习:逻辑回归、K近邻(KNN)、支持向量机(SVM), 朴素贝叶斯、决策树、随机森林
- 深度学习:全连接神经网络(ANN/MLP), 卷积神经网络(CNN), Transformer(含 LLM), CLIP(跨模态分类)
- 回归任务:
- 传统机器学习:线性回归、多项式回归、岭回归、Lasso 回归、决策树回归、随机森林回归、XGBoost 回归
- 深度学习:全连接神经网络(ANN/MLP), 卷积神经网络(CNN,适用于图像相关回归), 长短期记忆网络(LSTM,适用于时序回归), Transformer(时序 / 复杂场景回归)
- 聚类任务:
- 传统机器学习:K-Means、层次聚类(AGNES), DBSCAN, 密度峰值聚类
- 深度学习:深度自编码器(DAE,基于特征嵌入聚类), GAN 衍生聚类模型、图神经网络(GNN)聚类
- 生成任务:学习原始数据分布特征,生成与真实数据高度相似数据
- 传统机器学习:无,传统模型无能力学习数据分布并生成全新样本
- 深度学习:生成对抗网络(GAN), 变分自编码器(VAE), Transformer(LLM 文本生成、图像 Transformer), 扩散模型(Stable Diffusion), DALL・E(文生图)、Whisper(语音生成)、SAM(分割掩码生成)
- 表征学习:将原始数据转换为低冗余、高语义的特征向量,支撑下游任务
- 传统机器学习:主成分分析(PCA), 线性判别分析(LDA), SIFT(图像局部特征)、HOG(图像梯度特征), 词袋模型(BOW,文本特征)
- 深度学习:自编码器(AE), CNN 特征层(图像表征)、Transformer 嵌入层(文本/多模态表征)、LLM 语义嵌入(如 BERT 嵌入), CLIP(跨模态统一表征)
- 大模型优化任务:针对预训练大模型,提升其适配性、安全性,与人类对齐
- 传统机器学习:无,传统模型无预训练 - 微调范式)
- 深度学习:RLHF(从人类反馈的强化学习)、Self-instruction(自指令微调)、LoRA(低秩适配微调)、Prompt Tuning(提示词微调)
常见算法、原理解析:
K-Means 传统机器学习 - 聚类
是机器学习中最经典的无监督聚类算法,核心是基于距离相似度将无标签的样本数据自动划分为 K 个簇,让同一簇内的样本相似度最高,不同簇间的样本相似度最低。
PCA 传统机器学习 - 降维
Principal Component Analysis,PCA 是机器学习中最经典的降维算法,属于无监督学习,核心是通过线性变换将高维数据映射到低维空间,在最大限度保留数据核心特征的前提下,减少数据的维度,降低计算复杂度。
梯度下降(GD)
最小化模型的预测误差,梯度下降是实现误差最小化的最基础方法
Adam 深度学习优化 - 训练优化
梯度下降的改进版,是深度学习中最主流的优化算法,通过自适应调整每个参数的学习率,让模型训练更稳定、效率更高。
GAN 深度学习优化 - 生成对抗网络
Generative Adversarial Network,核心采用对抗训练思路,由生成器(G)和判别器(D)两个网络相互博弈、共同训练,最终让生成器生成以假乱真、高质量的样本。
⭐️**自注意力机制,**深度学习优化 - 大模型核心网络
Self-Attention,Transformer 架构的核心计算机制,通过计算序列中各位置元素之间的关联权重,实现对上下文信息的动态聚焦,使模型能够精准捕捉序列内部不同元素间的依赖关系。
多头自注意力机制
Multi-Head Attention,自注意力机制的进阶形式,通过多个注意力头,同时捕捉不同维度、不同尺度的上下文关联,提升模型的特征提取能力;让AI从多个角度关注重点,能同时捕捉文字的多种关联信息,理解更全面。
多头自注意力机制是 Transformer 架构的核心升级,也是 LLM 能精准理解复杂语义、长文本上下文的关键,目前主流 LLM 均基于多头自注意力机制做进一步优化,提升模型的语义理解能力。
⭐️CLIP 深度学习优化 - 跨模态预训练
对比语言 - 图像预训练,核心是通过对比学习,让模型建立【文本描述】与【图像特征】之间的强关联,实现文本和图像的跨模态语义对齐,模型无需额外微调即可实现文本找图、图像找文的跨模态匹配,也可快速适配图像分类、文生图、图生文等下游任务。
⭐️RLHF:
Reinforcement Learning from Human Feedback,基于人类反馈的强化学习,通过将人类的反馈纳入训练过程,让模型向符合人类偏好的方向优化。
单一算法无法支撑复杂的 AI 任务,实际应用中通常采用【基础算法】 + 【优化算法】 + 【任务专属算法】的组合形式,多算法协同实现模型能力的迭代升级。
例如,在大语言模型的训练流程中,以Transformer架构为基础,搭配Adam优化算法提升训练效率,再通过RLHF算法做人类偏好微调。
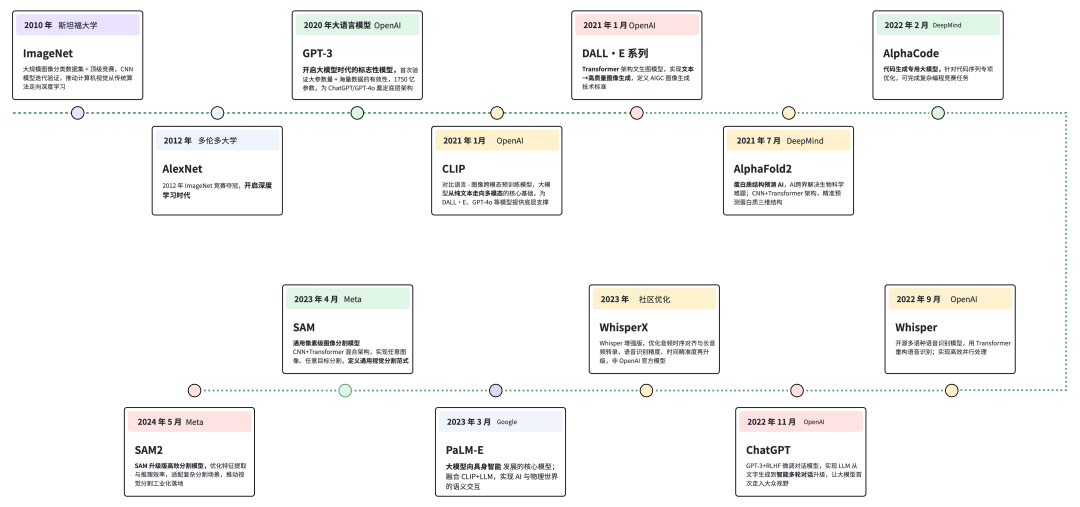
3 模型
AI 核心模型时间表
🌟大语言模型
LLM, Large Language Model
大参数量的预训练语言模型,基于海量文本训练,主打自然语言的理解与生成。
所有 LLM 均以 Transformer 为底层架构,结合多头自注意力机制实现长文本上下文理解,同时搭配 RLHF 等算法做微调优化,是神经网络、算法两大核心技术的综合落地载体。
大语言模型的研发需要同时具备三大要素:数据资源、算法模型、资金
✍️数据资源:需要高质量、大规模、丰富性的数据集
- 高质量:提高模型精度与可解释性,减少训练时长
- 大规模:数据量大、训练参数大,得到的预训练模型效果越好
- 丰富性:提高模型的泛化能力,单一数据容易出现过拟合
🌟混合专家模型
MOE, Mixture of Experts
一种分布式的大模型架构,将模型拆分为多个专家子模型,不同子模型负责处理不同领域的任务,通过门控网络分配任务。
大模型的专家团队模式,一个模型里有多个专业专家,处理不同问题时找对应专家,效率更高、能力更强
Segment Anything(SAM)
Meta发布的图像分割模型,实现任意图像中目标物体的像素级分割,基于 CNN+Transformer 混合架构研发,融合了 CV 领域的经典图像特征提取技术和大模型的上下文理解能力,是计算机视觉与大模型技术结合的典型代表。
Segment Anything 2(SAM2)
SAM 基础上优化特征提取和推理效率,提升图像分割性能和处理效率,适配更复杂的分割场景,进一步强化了CNN与Transformer的融合效果。
🌟CLIP:对比语言-图像预训练
Contrastive Language-Image Pre-training
基于 Transformer 架构研发,实现文本与图像跨模态关联的预训练模型,是文生图、图生文的核心基础,让AI看懂文字也看懂图,是大模型从纯文本向多模态发展的核心基础模型,为 DALL・E、GPT-4o 等多模态模型提供了跨模态特征关联的技术支撑。
DALL·E系列
OpenAI开发的文生图模型,基于Transformer架构,能根据文本描述生成高质量、高创意的图像(文→图),能根据文字描述画出各种风格、各种内容的图片
🌟GPT-3
2020 年,OpenAl开发,纯 Transformer 架构的经典 LLM,经过了将近 0.5 万亿个单词的预训练,是1750 亿个参数的自然语言深度学习模型,比以前的版本 GPT-2 高 100 倍,可以在多个 NLP 任务基准上达到最先进的性能,是开启大模型时代的标志性模型。首次验证大参数量、海量预训练数据对 LLM 能力提升的有效性,为后续的ChatGPT、GPT-4o 奠定了核心架构基础。
ChatGPT
在GPT-3 的 Transformer 架构基础上,加入 RLHF 算法做微调,让模型具备自然的多轮对话能力,实现了 LLM 从文字生成到智能交互的升级。
🌟GPT-4o
OpenAI推出的全能多模态大模型,在 GPT 系列 Transformer 架构基础上,融合了 CLIP 的跨模态关联技术、Whisper 的语音识别技术,可实时处理文本、音频、图像、视频等多模态信息,是目前多模态大模型的标杆。
AlphaFold
DeepMind开发,基于 CNN+Transformer 混合架构,将 AI 的序列建模和特征提取能力应用于生物领域,是 AI 模型跨领域应用的典型代表,可精准预测蛋白质的三维结构,解决生物学经典难题。
Whisper
OpenAI开源的语音识别模型,基于 Transformer 架构研发,打破了传统语音识别模型对 RNN/LSTM 的依赖,实现了语音序列数据的高效并行处理,提升了多语种识别精度。
WhisperX
OpenAI, 是Whisper的升级版本,在Whisper的 Transformer 架构基础上优化了音频特征提取和时序对齐能力,实现长音频的时间精确转录,语音识别精度大幅提升。
PaLM-E
基于 Transformer 架构,融合了 CLIP 的视觉 - 语言关联技术和 LLM 的语义理解能力,是大模型向具身智能发展的核心模型。
AlphaCode
DeepMind开发,基于 Transformer 架构,针对代码序列做专属预训练和算法优化,可完成复杂的编程挑战,性能优于多数人类程序员,能自己写代码,解决复杂的编程问题
ImageNet
大型图像数据集+图像分类比赛,是 CNN 模型迭代的重要推手,2012 年 AlexNet 在 ImageNet 比赛中夺冠,让 CNN 成为 CV 领域的核心技术,后续 VGG、ResNet 等经典 CNN 模型均在 ImageNet 比赛中得到验证和推广。
AlexNet
AlexNet 是初代深度 CNN 模型,在传统 CNN 基础上增加了网络层数、引入了 ReLU 激活函数和 Dropout 正则化,解决了早期 CNN 训练效率低、过拟合的问题,为后续 VGG、ResNet 等 CNN 模型的发展奠定了基础,2012年ImageNet图像分类比赛夺冠,开启了深度学习的快速发展时代。
4 算力
AI 芯片
AI芯片是专门为加速 AI 应用中的大量针对矩阵 计算任务而设计的处理器或计算模块,是所有神经网络、模型、算法落地的硬件基础,不同类型的 AI 芯片适配不同规模的模型训练与推理,如 GPU 适配大模型训练、NPU 适配端侧小模型推理。
与传统的通用芯片如中央处理器(CPU)不同,AI芯片采用针对特定领域优化的体系结构(Domain-Specific Architecture,DSA),侧重于提升执行 Al 算法所需的专用计算性能。
CPU 中央处理器
Central Processing Unit
计算机的核心运算单元,主打串行计算,负责统筹计算机的所有操作,可辅助完成小型AI模型的训练和推理,是计算机的通用大脑,啥活都能干,但处理AI大规模计算时效率不如GPU/TPU
GPU 图形处理器
Graphics Processing Unit
是一种专门用于图像处理和并行计算的微处理器,在游戏渲染、人工智能和科学模拟等领域发挥着核心作用。
GPU技术自20世纪90年代持续演进,1999年NVIDIA推出GeForce 256被视为第一款真正意义上的GPU,它引入了硬件加速三维图形渲染。此后GPU功能从专用图形扩展到通用计算,成为高性能计算的关键组件。GPU 是大模型(LLM)训练的核心算力硬件,其并行计算能力完美适配 Transformer 架构的海量矩阵运算,也是 CNN 模型大规模训练的主流硬件,目前超大规模 LLM 训练均基于多 GPU 组成的高性能计算集群。
TPU 张量处理器
Tensor Processing Unit
由博通公司设计,专为其深度学习框架TensorFlow设计的神经网络计算优化,适配 Google 旗下的 LLM、CNN 模型训练,是比 GPU 更具针对性的 AI 专用算力硬件,算力效率优于GPU。
💡TensorFlow是一套封装好的深度学习开发工具,提供数据处理、模型搭建、训练、部署的全流程能力,帮开发者不用从零写底层代码,就能快速搭建、训练和运行各种深度学习模型,如 CNN、RNN、Transformer。
NPU 神经网络处理器
Neural Processing Unit
NPU 主打低功耗并行计算,适配端侧的轻量 CNN 模型、小型 LLM 推理,是云边端协同架构中端侧算力的核心载体,比如手机、智能手表里的AI芯片。
高性能计算集群
是大参数量 LLM、超大型 CNN 模型训练的必备算力架构,通过分布式训练技术将训练任务拆分到多台设备,解决了单设备算力不足的问题。
分布式训练
Distributed Training
将大模型的训练任务拆分到多台算力设备上,通过设备间的协同计算完成训练,提升训练效率,任务拆分,效率翻倍。
端侧与云端
云侧 Cloud Side:
指位于网络远端的中心化数据中心或服务器集群,拥有强大的集中式计算能力、海量存储资源和高度通用的服务能力。
以 GPU/TPU 集群为核心算力,主要负责大模型(LLM)的预训练、微调,以及大型 CNN 模型的训练和大规模推理。
端侧 Edge Side:
通常指用户直接使用的终端设备,如手机、电脑、汽车。优势:低延迟与实时响应;敏感数据在设备本地处理,无需上传至云端,从根本上降低了泄露风险;摆脱了对网络稳定性和带宽的依赖,在弱网或无网环境中仍可工作。
端侧以 NPU 为核心算力,主要负责轻量 LLM 推理、小型 CNN 模型(如人脸检测、图像识别)的实时推理,是 AI 模型落地到终端设备的关键。
💡云端处理复杂训练与大规模计算,端侧负责实时响应与隐私任务。
云边端协同成为共识:纯粹“能跑在端侧就跑在端侧”的论调减弱,行业更倾向于根据任务需求,考虑成本、实时性、隐私,灵活选择部署方案,构建协同体系。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】
大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:
04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)
05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!
06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 5
5 0
0- 0



 已为社区贡献73条内容
已为社区贡献73条内容

所有评论(0)