Langgraph 初识
什么是LangGraph
基于LangChain构建的,面向智能体多轮交互/状态持久化/分支并行执行的图结构工作流框架。
简单地说: LangGraph = LangChain + 图编排 + 状态机
Langchain像是一条不会停止的流水线,,但是现实世界是复杂的,可能有些节点是需要循环执行多次的。
LangGraph是一条正常的流水线,在有些节点会检查前几个节点的结果是否合理,比如玩具头部组装出问题了,就需要回到组装头部的节点进行返工。
LangGraph的流程充满了循环,判断和分支。
Langchain的节点操作不支持这些,你需要自己写一堆胶水代码进行混合。其次,LangCHain的Agent也能解决这些问题,他的ReAct模式,会自动判断结果是否完整,是否需要继续调用工具。
但是Agent有一个致命问题:Agent运行是一个黑盒子,你根本不知道或者无法干预他的判断。没法强制他的流程,他可能在一个错误的思路循环十几次,浪费token,其次,行为不够稳定,同样的问题,这次是A-B-C,下次可能是A-C-B
充满不可控因素,所以LangGraph应运而生,他就是为了解决这种复杂编排,让你人为能看到/干预流程结果。
LangGraph 提供了强大的状态管理机制,可以在不同节点之间传递信息,像是全局变量,从而实现长期记忆和多轮对话能力,
可以定义节点和边,精确控制Agent执行逻辑,包括条件分支,循环,和并行执行等。图结构使得Agent的运行路径清晰可见,便于理解Agent的决策过程,在出现问题的时候快速定位调试。
模块化和可复用性,每个节点是独立的,可复用的组件。
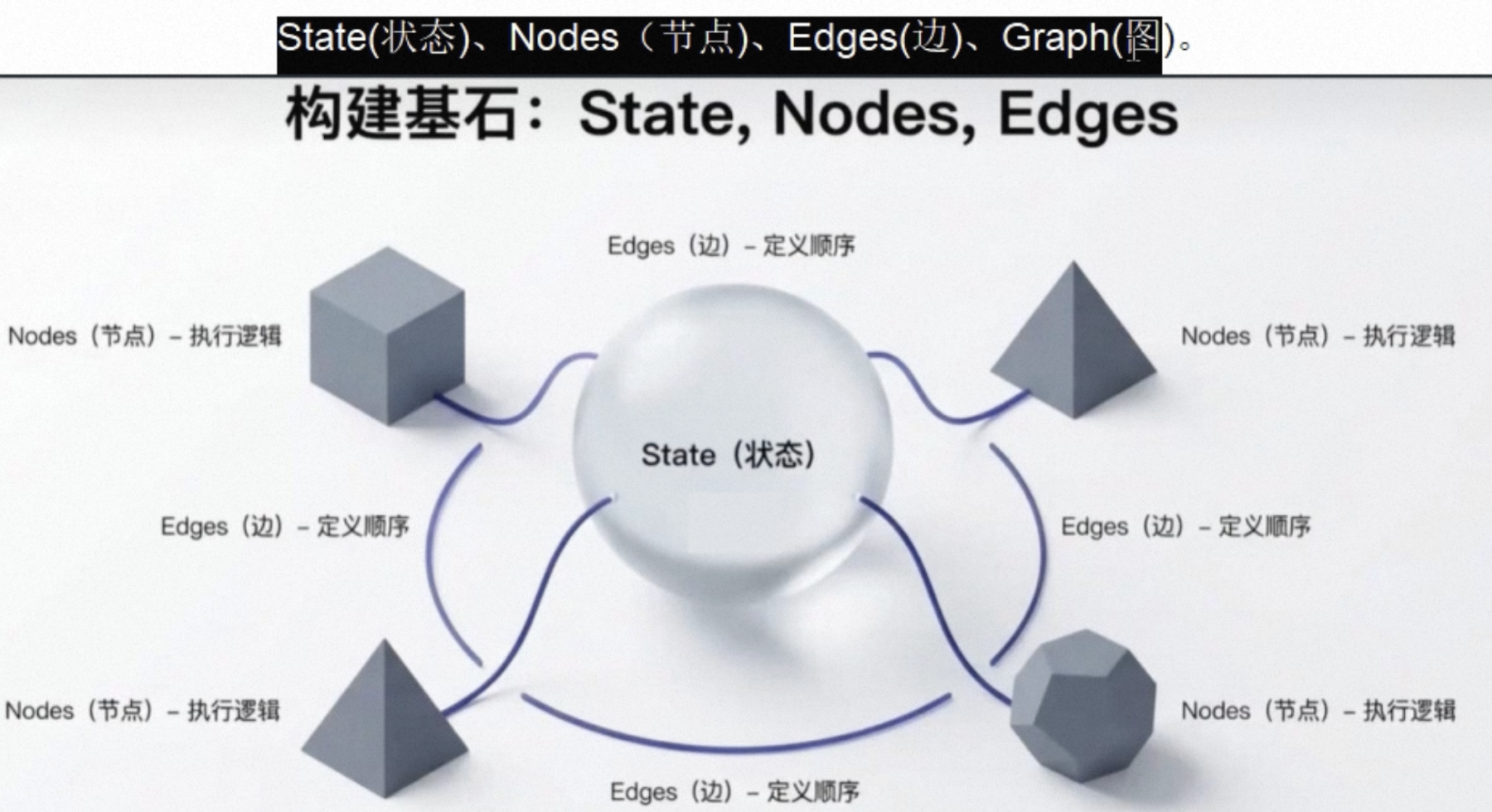
把基础单元从“链”换成了“图”
LangGraph四大灵魂
- 边
- 节点
- 状态
- 图
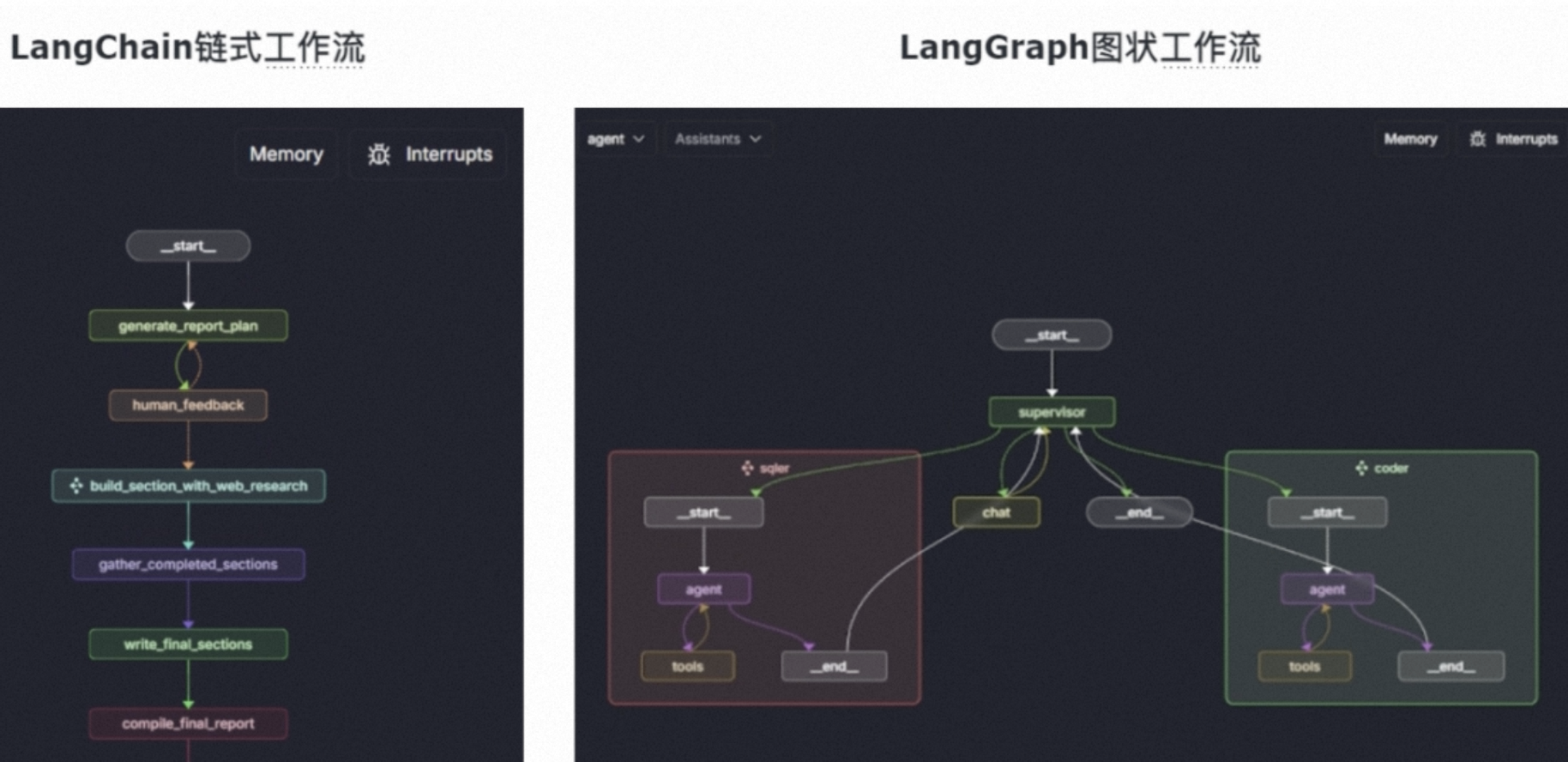
LangGraph是基于langChain构件的,无论图多复杂,单独每个任务执行链路仍然是线性的。底层仍是Chain.
Langgraph的api
demo
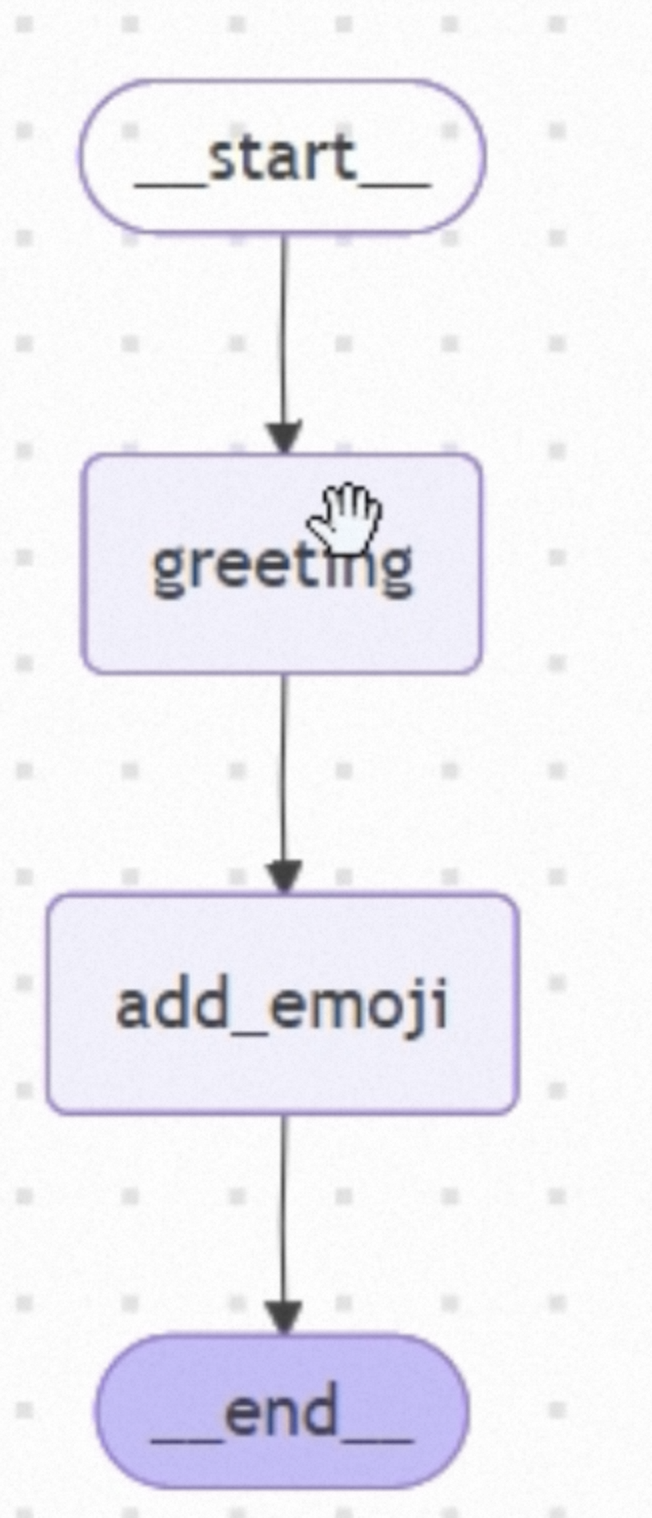
# 1 定义State
class TestState(TypedDict):
name: str;
greeting: str;
# 定义节点
def greet(state: TestState) -> dict:
name = state["name"]
return { "greeting": name }
def add_emoji(state: TestState) -> dict:
greeting = state["greeting"]
return { "greeting": state["greeting"] + "....😂" }
# 构建图,需要传入状态
graph = StateGraph(TestState)
# 添加节点
graph.add_node("greeting", greet)
graph.add_node("emoji", add_emoji)
# 添加边
graph.add_edge(START, "greeting")
graph.add_edge("greeting", "emoji")
graph.add_edge("emoji", END)
# 构建完之后需要编译
app = graph.compile()
result = app.invoke({"name": "test"})
print(result)
print(app.get_graph().print_ascii())
if __name__ == "__main__":
print()
- 1 定义状态
- 2 定义节点
- 3 构建图,添加节点,添加边
- 4编译图
- 5 调用执行‘工作流
四大结构
图(Graph)
langGraph通过有向图定义AI工作流的执行步骤和执行顺序,从而实现复杂的,带有状态的,可循环的应用程序逻辑。
通过StateGraph(状态)创建图
状态 state
状态包含两个部分:1 图的模式 2 规约函数(reducer)
有点类似于redux的reducer。
State三要素
- state_schema (图的完整内部状态)
- input_scheam(state_schema的子集,限制图的输入接口,只能传这些字段,不指定默认等同于state_schema)
- Output_schema(定义图返回什么输出,是state_scheam的子集,不指定默认等同于state_schema)
class InputState(TypedDict):
name: str;
class OuputState(TypedDict):
test: str;
class GlobalState(InputState, OuputState):
pass
graph1 = StateGraph(state_schema=GlobalState, input_schema=InputState, output_schema=OuputState)
规约函数
规约函数规定了节点产生的更新如何作用到State。State中每个字段都拥有自己的规约函数,如果未显示制定,则默认所有对该字段的更新都会直接覆盖旧值。
Reducer规定多个节点的state如何更新(覆盖,合并,添加等),一般有以下几种
- 1 default 默认覆盖更新
- 2 add_messages: 用于消息列表追加
- 3 operator.add 将元素追加到现有元素中,支持列表,字符串,数值类型的追加。
- 4 operator.mul: 用于数值相承
- 5 自定义Reducer: 支持用户自定义合并逻辑
from langgraph.graph import StateGraph, START, END, add_messages
import operator
def MyOperator(current: float, update: float) -> float:
if current == 0.0:
return 1.0 * update
return current + update
class InputState(TypedDict):
name: str;
message: Annotated[List, add_messages]
list: Annotated[List, operator.add]
factor: Annotated[float, operator.mul]
factor2: Annotated[float, MyOperator]
对于messages,所有节点的改动都会追加进去。对于lsit1,多有节点的改动也是追加进去,对于factor,则是相x,但因为langgraph的默认乘reducer会加上初始化值0.0,所以都是0,这里使用自定义reducer,MyOperator函数。
Node节点
节点就是python函数,可以是同步的也可以是异步的。接收三个参数
- state
- config: 一个RunnableCOnfig对象,包含如threa_id等配置信息。
- runtime: 一个Runtime对象,包含运行时的context机器信息。比如store等。
Node是langgraph的一个基本处理单元,可以是一个函数,一个agent,调用大模型,一个工具等。
节点缓存
节点支持设置缓存,如果每一次调用结果一样,就可以采用缓存,可以设置两个值
- key_func 根据节点的输入生成缓存键
- ttl 缓存的生存时间(秒),不设置则永不过期
当一个节点开始执行的时候,系统会根据key_func生成唯一key,langgraph会检查缓存中是否存在这个值,如果存在则命中,返回之前存储的结果,跳过该节点的实际执行。
graph1.add_node("greeting", greet, cache_policy=CachePolicy(ttl=8))
cache_policy缓存策略,如上设置过期时间为8s。
app == graph1.compile(cache = InMemoryCache())
在编译的时候传入缓存配置,可以缓存到redis。
错误处理和异常重试
langgraph提供了错误处理和重试机制来指定重试次数,重试间隔,重试异常等,用于保障系统的可靠性。
retry_policy = RetryPolicy(
max_attempts=3, # 最大重试次数
initial_interval=1, # 初始间隔
jitter=True, # 抖动,添加随机性避免重试风暴
backoff_factor=2, # 退避乘数,每次重试间隔的增长倍数
retry_on=[RequestException, TimeoutError, ValueError], # 只重试这些异常
)
graph1.add_node("process", process, retry_policy=retry_policy)
如果报错了,且报错属于这三种,那么process函数将会最多重试五次。
一般有三种:
- 1 俘获特定异常重试,如上
- 2 自定义重试策略,改写retry_on属性
def custom_retry_on(expection: Exception) -> bool :
"""自定义重试规则"""
err_msg = str(expection)
if "模拟API调用失败" in err_msg:
print(f"俘获到可重试异常,允许重试")
return True
return False
retry_policy = RetryPolicy(
max_attempts=3, # 最大重试次数
initial_interval=1, # 初始间隔
jitter=True, # 抖动,添加随机性避免重试风暴
backoff_factor=2, # 退避乘数,每次重试间隔的增长倍数
retry_on=custom_retry_on, # 只有custom_retry_on函数返回True,才表示需要重试
)
- 不可重试异常
一般报以下的错就不重试: ValueError, TypeError…
Edge边
边定义了节点之间的执行顺序,一个节点可以有多个边,指向多个节点,多个节点也可以通过多条边,指向一个节点。
边的种类
- 普通边: add_edge
- 条件边:调用一个函数决定在一个流程到哪个节点
add_conditional_edge('a', fn, {True: 'b', False: 'c'}),fn跟节点一样,接收参数state,返回值作为判断下一个节点,返回True到b,返回False到c。也可以指定add_conditional_edge('a', fn, {"test1": 'b', "test2": 'c'}),这样fn返回test1就走到b节点,返回test2就走到c节点。 - 入口点:当用户输入到达时,首先到哪个节点,也就是
graph.add_edge(START, 'a')/ graph.set_entry_point('a'),这个a就是入口点。 - 条件入口点:允许你自定义逻辑,从不同的节点开始。
add_conditional_edge(START, fn, {True: 'b', False: "c"),有点像条件边,只不过起点是START
Graph API: Send/Common/Runtime Context
Send
Map-Reducer: 先拆分,再汇总。为了支持这种设计模式,langgraph支持从条件边返回Send对象。
之前边和节点都是写死的固定的,现在支持动态创建多个节点,并且传递不同状态,并行执行,再将它们的执行结果汇总到一个节点进行整合。
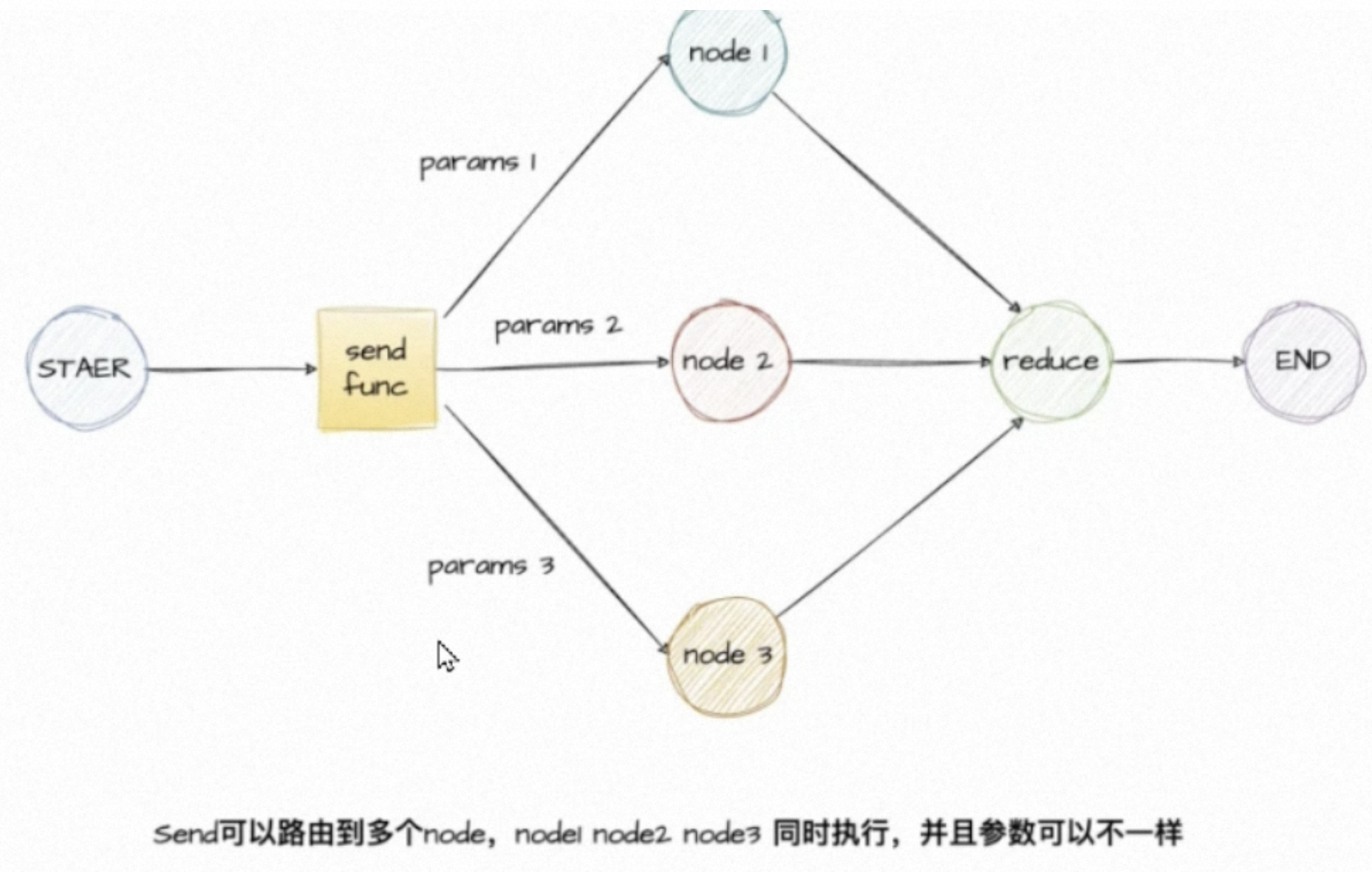
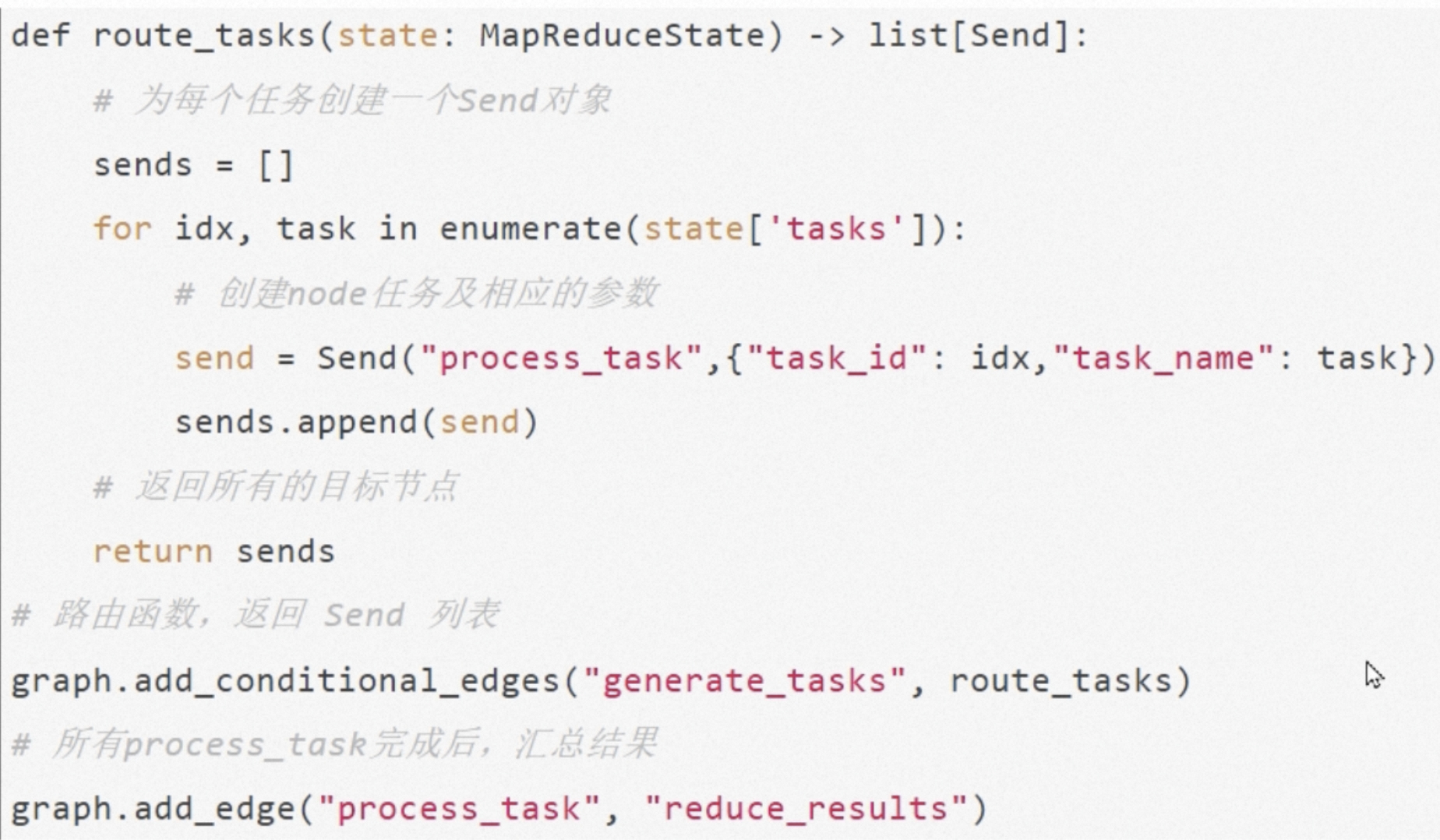
如上,添加一个条件边,从generate_trasks开始,通过route_tasks返回一个Send对象的数组,每个Send对象接受两个参数,一个是节点名称,另一个是节点接受的状态。且这个process_task也是需要定义好的节点。
多路并进,汇总规约。核心思想:拆分任务->并行执行->汇总。
demo
# 1 定义State
class TestState(TypedDict):
name: str;
greeting: str;
list: Annotated[List, operator.add];
# 路由条件函数
def map_reducer(state: TestState) -> dict:
list = state["list"]
send = []
for index, item in enumerate(list):
send.append(Send("test_map_reducer", {"state": item}))
print(send)
return send
def test_map_reducer(state):
state1 = state["state"]
return { "list": [state1] }
def reducer_fn(state):
print(f"reducer_fn: {state}")
return state
graph.add_node("test_map_reducer", test_map_reducer)
graph.add_node("reducer_fn", reducer_fn)
graph.add_conditional_edges("emoji", map_reducer)
graph.add_edge("test_map_reducer", "reducer_fn")
graph.add_edge("reducer_fn", END)
# 构建完之后需要编译
app = graph.compile()
result = app.invoke({"list": [1,2,3]})
结果list: [1,2,3,1,2,3],返回的sen d数组有三个send对象,并行执行test_map_reducer,将内容add到原数组上去,然后通过reducer_fn得到汇总结果。
到emoji节点后,根据输入,动态创建多个节点,并且并行执行,然后汇总到reducer_fn处理。
Command
Command支持指定下一个节点,还可以更新状态,处理中断恢复,以及在嵌套之间导航。
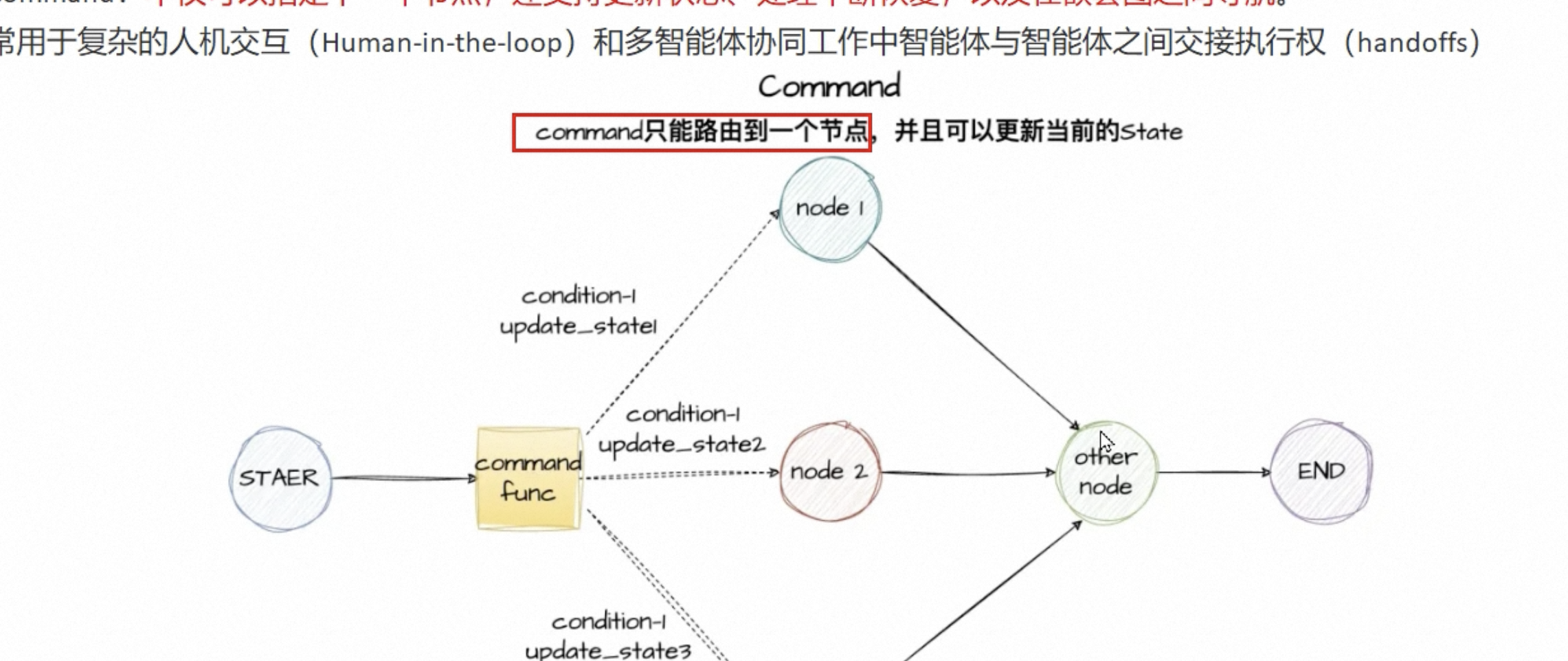
在同一个节点之中,既执行状态更新,又决定下一步执行到哪个节点,Langgraph提供的实现方式就是,从节点函数返回一个Command对象
demo
首先定义我们的路由节点(注意,这里跟send不同,command是由节点返回的,send是由路由函数返回的)
# command 跟 add_conditional_edges的区别是:条件边只能指定下个节点,无法修改状态,而command可以找到定下一个节点并且修改状态
def agent_node(state: TestState) -> Command:
isCompleted = state.get("isCompleted")
if isCompleted:
return Command(goto=END, update={"message": "所有任务已经完成,流向END节点"})
task = state.get("task")
if "数学" in task:
# 决定将任务移交给下一个node,并且更新状态
return Command(goto="math_agent", update={"num": 2})
elif "翻译" in task:
return Command(goto="translate_agent", update={"language": "你好啊"})
else:
return Command(goto="END", update={"message": "没有符合人物,结束"})
需要通过状态防止死循环,如果完成则流向END节点。
如果没完成,就路由到对应的任务去,没匹配到任务也结束
# 数学计算agent
def math_agent(state: TestState) -> Command:
num = state.get("num") * 2
return {"num": num, "isCompleted": True}
# 翻译 agent
def translate_agent(state: TestState) -> Command:
llm = init_llm_clinet()
result = llm.invoke(f"帮我翻译这句话,只返回翻译的结果 {state.get('language')}")
return {"language": result, "isCompleted": True}
# 构建图,需要传入状态
graph = StateGraph(TestState)
# 添加节点
graph.add_node("agent_node", agent_node)
graph.add_node("math_agent", math_agent)
graph.add_node("translate_agent", translate_agent)
# 添加边
graph.add_edge(START, "agent_node")
graph.add_edge("math_agent", "agent_node")
graph.add_edge("translate_agent", "agent_node")
# 构建完之后需要编译
app = graph.compile()
这里有一点需要注意,构建边的时候,agent_node流向math_agent的不用构建,而agent_node到END节点的边也不需要指定,由agent_node节点的Command对象指定。
而反过来,math_agent节点运行后,需要流向agent_node节点去进行确认,最终由agent_node节点路由到END节点。
所以需要加graph.add_edge("math_agent", "agent_node"),translate_agent也是同理。
测试
result = app.invoke({"task": "数学"})
# 结果
{'num': 4, 'isCompleted': True, 'task': '数学', 'message': '所有任务已经完成,流向END节点'}
result = app.invoke({"task": "你好"})
{'task': '你好', 'message': '没有符合人物,结束'}
result = app.invoke({"task": "翻译"})
{'language': AIMessage(content='Hello', a......"isCompleted": True, 'task': '翻译', 'message': '所有任务已经完成,流向END节点'}
可以看到,根据不同任务路由到不同节点进行操作。
Runtime Context 全局对象
类似于我们写代码的全局配置信息,一般我们都是写在config.ts文件,或者是java的application.yml,langgraph的Runtime Context也是类似的道理,一些固定的配置信息,不应该跟图状态混合在一起。如:
@dataclass
class GlobalContext:
model: str = "glm-4.5-air"
sqlUrl: str = "xxxx"
@dataclass装饰器,类似于java的@Data,不用写构造函数等负载繁琐的内容
定义全局变量,这里配置的是默认值,
在构建图的时候,指定上下文的类
# 构建图,需要传入状态
graph = StateGraph(TestState, context_schema=GlobalContext)
调用invoke的时候,通过context传入具体值
result = app.invoke({"task": "数学"}, context=GlobalContext(model="test", sqlUrl="test123123"))
,上述节点我们可以传入三个对象,state,config,Runtime,所以在节点这里可以拿到
# 数学计算agent
def math_agent(state: TestState, runtime: Runtime[GlobalContext]) -> Command:
model = runtime.context.model
sqlUrl = runtime.context.sqlUrl
print(f"model: {model}, sqlUrl: {sqlUrl}")
num = state.get("num") * 2
return {"num": num, "isCompleted": True}
#打印结果
model: test, sqlUrl: test123123
如上,可以正常拿到全局对象的值。
高级特性
Langgraph的流式输出
langgraph的流式输出,主要是看流程的状态。
主要有五种: values,是每一步结束后,输出完整的当前的状态。
values,是每一步结束后,输出完整的当前的状态。
yodates: 是每一步结束后,只输出变化的部分。
messages: 输出LLm的每一个字/词,带上相关信息。
custom: 自定义消息(自定义打印日志)
debug: 输出所有细节,方便调试。
还是以上面的例子,values
# result = app.invoke({"task": "数学"}, context=GlobalContext(model="test", sqlUrl="test123123"))
for chunk in app.stream({"task": "数学", "test_stream": "我是测试"}, stream_mode="values",
context=GlobalContext(model="test", sqlUrl="test123123")):
print(chunk)
结果
# 第一步,到START节点,此时状态全部输出。
{'task': '数学', 'test_stream': '我是测试'}
# 到达agent_node之后,状态变成第二步的样子。
{'num': 2, 'task': '数学', 'test_stream': '我是测试'}
# 到达math_agent之后,计算得到结果,改变了状态
{'num': 4, 'isCompleted': True, 'task': '数学', 'test_stream': '我是测试'}
#再回到agent_node,判断已经完成,流向END节点
{'num': 4, 'isCompleted': True, 'task': '数学', 'message': '所有任务已经完成,流向END节点', 'test_stream': '我是测试'}
如果straem_mode改成updates之后
{'agent_node': {'num': 2}}
{'math_agent': {'num': 4, 'isCompleted': True}}
{'agent_node': {'message': '所有任务已经完成,流向END节点'}}
只会触发已经修改的节点的名字和对应状态。
也可以使用列表,打印多一点信息
# result = app.invoke({"task": "数学"}, context=GlobalContext(model="test", sqlUrl="test123123"))
for chunk in app.stream({"task": "数学", "test_stream": "我是测试"}, stream_mode=["values", "updates"],
context=GlobalContext(model="test", sqlUrl="test123123")):
print(chunk)
# 结果
('values', {'task': '数学', 'test_stream': '我是测试'})
('updates', {'agent_node': {'num': 2}})
('values', {'num': 2, 'task': '数学', 'test_stream': '我是测试'})
('updates', {'math_agent': {'num': 4, 'isCompleted': True}})
('values', {'num': 4, 'isCompleted': True, 'task': '数学', 'test_stream': '我是测试'})
('updates', {'agent_node': {'message': '所有任务已经完成,流向END节点'}})
('values', {'num': 4, 'isCompleted': True, 'task': '数学', 'message': '所有任务已经完成,流向END节点', 'test_stream': '我是测试'})
返回的元祖。
如果使用了messages
for chunk in app.stream({"task": "翻译", "test_stream": "我是测试"}, stream_mode=["values", "updates", "messages"],
context=GlobalContext(model="test", sqlUrl="test123123")):
chunk_type, content = chunk
if chunk_type == "messages":
if content[0].content:
print(content[0].content, end="")
else:
print(chunk)
if __name__ == "__main__":
print()
# 结果
('values', {'task': '翻译', 'test_stream': '我是测试'})
('updates', {'agent_node': {'language': '你好啊'}})
('values', {'language': '你好啊', 'task': '翻译', 'test_stream': '我是测试'})
这句话的翻译是:**"Hi there!"**
### 翻译说明:
1. **"你好"** → **"Hi"**:英语中最常用的非正式问候语,对应中文的“你好”。
2. **"啊"** → **"there"**:中文语气词“啊”在翻译中可通过英语的副词“there”体现亲切感,使问候更自然生动(类似“Hey there!”)。
3. 整体语气:**"Hi there!"** 比 "Hello" 更轻松随意,符合“你好啊”的口语化特点。
### 其他可选译法:
- **"Hey!"**(更简洁,适合熟人)
- **"How's it going?"**(更随意的问候,隐含“你好吗”)
- **"Hello!"**(正式场合,但缺少“啊”的亲切感)
根据语境选择最合适的即可! 😊('updates', {'translate_agent': {'language': AIMessage(content='这句话的翻译是:**"Hi there!"**\n\n### 翻译说明:\n1. **"你好"** → **"Hi"**:英语中最常用的非正式问候语,对应中文的“你好”。\n2. **"啊"** → **"there"**:中文语气词“啊”在翻译中可通过英语的副词“there”体现亲切感,使问候更自然生动(类似“Hey there!”)。\n3. 整体语气:**"Hi there!"** 比 "Hello" 更轻松随意,符合“你好啊”的口语化特点。\n\n### 其他可选译法:\n- **"Hey!"**(更简洁,适合熟人) \n- **"How\'s it going?"**(更随意的问候,隐含“你好吗”) \n- **"Hello!"**(正式场合,但缺少“啊”的亲切感)\n\n根据语境选择最合适的即可! 😊', additional_kwargs={}, response_metadata={'finish_reason': 'stop', 'model_name': 'glm-4.5-air', 'model_provider': 'openai'}, id='lc_run--019d537e-76d2-7841-afb7-1092017b8c43', tool_calls=[], invalid_tool_calls=[], usage_metadata={'input_tokens': 10, 'output_tokens': 410, 'total_tokens': 420, 'input_token_details': {'cache_read': 9}, 'output_token_details': {}}), 'isCompleted': True}})
('values', {'language': AIMessage(content='这句话的翻译是:**"Hi there!"**\n\n### 翻译说明:\n1. **"你好"** → **"Hi"**:英语中最常用的非正式问候语,对应中文的“你好”。\n2. **"啊"** → **"there"**:中文语气词“啊”在翻译中可通过英语的副词“there”体现亲切感,使问候更自然生动(类似“Hey there!”)。\n3. 整体语气:**"Hi there!"** 比 "Hello" 更轻松随意,符合“你好啊”的口语化特点。\n\n### 其他可选译法:\n- **"Hey!"**(更简洁,适合熟人) \n- **"How\'s it going?"**(更随意的问候,隐含“你好吗”) \n- **"Hello!"**(正式场合,但缺少“啊”的亲切感)\n\n根据语境选择最合适的即可! 😊', additional_kwargs={}, response_metadata={'finish_reason': 'stop', 'model_name': 'glm-4.5-air', 'model_provider': 'openai'}, id='lc_run--019d537e-76d2-7841-afb7-1092017b8c43', tool_calls=[], invalid_tool_calls=[], usage_metadata={'input_tokens': 10, 'output_tokens': 410, 'total_tokens': 420, 'input_token_details': {'cache_read': 9}, 'output_token_details': {}}), 'isCompleted': True, 'task': '翻译', 'test_stream': '我是测试'})
('updates', {'agent_node': {'message': '所有任务已经完成,流向END节点'}})
messages返回的是AIMessages(content=“”,xxx)的内容
使用custom可以自己在关键节点输出日志
# 数学计算agent
def math_agent(state: TestState, runtime: Runtime[GlobalContext]) -> Command:
num = state.get("num") * 2
writer = get_stream_writer()
writer({"custom_key": f"到达数学agent,当前计算的值是{num}", "test": "我是测试custom"})
return {"num": num, "isCompleted": True}
需要使用get_stream_writer写入日志,结果
('values', {'task': '数学', 'test_stream': '我是测试'})
('values', {'num': 2, 'task': '数学', 'test_stream': '我是测试'})
('custom', {'custom_key': '到达数学agent,当前计算的值是4', 'test': '我是测试custom'})
('values', {'num': 4, 'isCompleted': True, 'task': '数学', 'test_stream': '我是测试'})
('values', {'num': 4, 'isCompleted': True, 'task': '数学', 'message': '所有任务已经完成,流向END节点', 'test_stream': '我是测试'})
可以看到打印了custom的日志。
状态持久化 presistence
类似于 打游戏时候的存档。
状态持久化:在程序运行的时候,将瞬间的状态进行保存,后续可以重新恢复执行,用于程序退出,重启等事件丢失任务。在Langgraph中使用了持久化,系统会自动将当前整个图的状态,包括所有变量,历史消息,下一步要执行的节点等信息,完整的保存下来,一份存档就是一个chekcpoint(检查点)。
checkpoint通过thread_id(会话id)区分不同对话,拿到不同缓存。
checkpoint: 短期记忆就是保存在内存里面的,主要用于同一个线程的连续对话
Store: 长期记忆是保存在数据库里面的,支持跨线程和会话的长期内存,适用于需要持久化数据的复杂工作流。比如:显示保存用户偏好,背景事实等高密度信息。
还是以上述例子:
# 首先,图编译时需要传入checkpoint
# InMemorySaver表示保存在内存里
app = graph.compile(checkpointer=InMemorySaver())
# 配置会话id
# 配置会话id
config = {"configurable": {"thread_id": "user_test11"}}
for chunk in app.stream({"task": "数学", "test_stream": "我是测试"},
stream_mode=["values", "custom"], config=config):
配置checkpoint以及传入配置id后,状态就会保存在内存,执行结束后,
# 获取内村状态
saved_state = app.get_state(config)
print(f"当前保存的状态是: {saved_state.values}")
print(f"下一个节点是: {saved_state.next}")
# 获取执行历史
history = app.get_state_history(config)
for step in history:
print(step)
print("回复工作流")
result2 = app.invoke(None, config)
print(result2)
可以获取当前的内存状态,他保存了当前的状态,下一个节点等信息,也可以获取执行历史栈,还可以重新开始执行工作流。
执行结果
当前保存的状态是: {'num': 4, 'isCompleted': True, 'task': '数学', 'message': '所有任务已经完成,流向END节点', 'test_stream': '我是测试'}
下一个节点是: ()
StateSnapshot(values={'num': 4, 'isCompleted': True, 'task': '数学', 'message': '所有任务已经完成,流向END节点', 'test_stream': '我是测试'}, next=(), config={'configurable': {'thread_id': 'user_test11', 'checkpoint_ns': '', 'checkpoint_id': '1f130905-bfeb-6e9c-8003-0195ba71104e'}}, metadata={'source': 'loop', 'step': 3, 'parents': {}}, created_at='2026-04-05T01:40:00.204147+00:00', parent_config={'configurable': {'thread_id': 'user_test11', 'checkpoint_ns': '', 'checkpoint_id': '1f130905-bfeb-66e0-8002-b7b290178838'}}, tasks=(), interrupts=())
StateSnapshot(values={'num': 4, 'isCompleted': True, 'task': '数学', 'test_stream': '我是测试'}, next=('agent_node',), config={'configurable': {'thread_id': 'user_test11', 'checkpoint_ns': '', 'checkpoint_id': '1f130905-bfeb-66e0-8002-b7b290178838'}}, metadata={'source': 'loop', 'step': 2, 'parents': {}}, created_at='2026-04-05T01:40:00.203949+00:00', parent_config={'configurable': {'thread_id': 'user_test11', 'checkpoint_ns': '', 'checkpoint_id': '1f130905-bfea-6bdc-8001-7cfd5efc20e4'}}, tasks=(PregelTask(id='322ee5e6-b3d2-39e5-9898-ada0fe70c8e1', name='agent_node', path=('__pregel_pull', 'agent_node'), error=None, interrupts=(), state=None, result={'message': '所有任务已经完成,流向END节点'}),), interrupts=())
StateSnapshot(values={'num': 2, 'task': '数学', 'test_stream': '我是测试'}, next=('math_agent',), config={'configurable': {'thread_id': 'user_test11', 'checkpoint_ns': '', 'checkpoint_id': '1f130905-bfea-6bdc-8001-7cfd5efc20e4'}}, metadata={'source': 'loop', 'step': 1, 'parents': {}}, created_at='2026-04-05T01:40:00.203665+00:00', parent_config={'configurable': {'thread_id': 'user_test11', 'checkpoint_ns': '', 'checkpoint_id': '1f130905-bfe9-6e9e-8000-93fbeac46c81'}}, tasks=(PregelTask(id='511bbcf3-5b6b-6cb7-ed2f-be018734eec2', name='math_agent', path=('__pregel_pull', 'math_agent'), error=None, interrupts=(), state=None, result={'num': 4, 'isCompleted': True}),), interrupts=())
StateSnapshot(values={'task': '数学', 'test_stream': '我是测试'}, next=('agent_node',), config={'configurable': {'thread_id': 'user_test11', 'checkpoint_ns': '', 'checkpoint_id': '1f130905-bfe9-6e9e-8000-93fbeac46c81'}}, metadata={'source': 'loop', 'step': 0, 'parents': {}}, created_at='2026-04-05T01:40:00.203327+00:00', parent_config={'configurable': {'thread_id': 'user_test11', 'checkpoint_ns': '', 'checkpoint_id': '1f130905-bfe8-66e8-bfff-4672c6639ed8'}}, tasks=(PregelTask(id='1fc60147-1e1d-856e-81cc-3c668fa29398', name='agent_node', path=('__pregel_pull', 'agent_node'), error=None, interrupts=(), state=None, result={'num': 2}),), interrupts=())
StateSnapshot(values={}, next=('__start__',), config={'configurable': {'thread_id': 'user_test11', 'checkpoint_ns': '', 'checkpoint_id': '1f130905-bfe8-66e8-bfff-4672c6639ed8'}}, metadata={'source': 'input', 'step': -1, 'parents': {}}, created_at='2026-04-05T01:40:00.202720+00:00', parent_config=None, tasks=(PregelTask(id='e806aced-ebf0-1194-66fb-d9d9a2f47117', name='__start__', path=('__pregel_pull', '__start__'), error=None, interrupts=(), state=None, result={'task': '数学', 'test_stream': '我是测试'}),), interrupts=())
回复工作流
{'num': 4, 'isCompleted': True, 'task': '数学', 'message': '所有任务已经完成,流向END节点', 'test_stream': '我是测试'}
可以清晰地看到,当前的状态,以及执行的历史。
我们可以让agent_node节点报错,然后看下打印
num_test = 1
# command 跟 add_conditional_edges的区别是:条件边只能指定下个节点,无法修改状态,而command可以找到定下一个节点并且修改状态
def agent_node(state: TestState) -> Command:
global num_test
isCompleted = state.get("isCompleted")
if isCompleted:
print(f"num_test: {num_test}")
if num_test >= 2:
return Command(goto=END, update={"message": "所有任务已经完成,流向END节点"})
else:
num_test += 1
raise ValueError("测试报错")
......
# 定义重试机制
retry_policy = RetryPolicy(
max_attempts=1, # 最大重试次数
initial_interval=1, # 初始间隔
jitter=True, # 抖动,添加随机性避免重试风暴
backoff_factor=2, # 退避乘数,每次重试间隔的增长倍数
retry_on=[RequestException, TimeoutError, ValueError], # 只重试这些异常
)
在看结果
测试报错
当前保存的状态是: {'num': 4, 'isCompleted': True, 'task': '数学', 'test_stream': '我是测试'}
下一个节点是: ('agent_node',)
StateSnapshot(values={'num': 4, 'isCompleted': True, 'task': '数学', 'test_stream': '我是测试'}, next=('agent_node',), config={'configurable': {'thread_id': 'user_test11', 'checkpoint_ns': '', 'checkpoint_id': '1f130918-32a6-60d8-8002-af3740c728fc'}}, metadata={'source': 'loop', 'step': 2, 'parents': {}}, created_at='2026-04-05T01:48:15.417974+00:00', parent_config={'configurable': {'thread_id': 'user_test11', 'checkpoint_ns': '', 'checkpoint_id': '1f130918-32a5-6520-8001-d4b746831f40'}}, tasks=(PregelTask(id='e73f0489-2441-437a-4870-66feccc89cee', name='agent_node', path=('__pregel_pull', 'agent_node'), error="ValueError('测试报错')", interrupts=(), state=None, result=None),), interrupts=())
StateSnapshot(values={'num': 2, 'task': '数学', 'test_stream': '我是测试'}, next=('math_agent',), config={'configurable': {'thread_id': 'user_test11', 'checkpoint_ns': '', 'checkpoint_id': '1f130918-32a5-6520-8001-d4b746831f40'}}, metadata={'source': 'loop', 'step': 1, 'parents': {}}, created_at='2026-04-05T01:48:15.417676+00:00', parent_config={'configurable': {'thread_id': 'user_test11', 'checkpoint_ns': '', 'checkpoint_id': '1f130918-32a4-65c6-8000-f29d717f3a51'}}, tasks=(PregelTask(id='c2a9445a-1af9-60d8-b601-db47073529eb', name='math_agent', path=('__pregel_pull', 'math_agent'), error=None, interrupts=(), state=None, result={'num': 4, 'isCompleted': True}),), interrupts=())
StateSnapshot(values={'task': '数学', 'test_stream': '我是测试'}, next=('agent_node',), config={'configurable': {'thread_id': 'user_test11', 'checkpoint_ns': '', 'checkpoint_id': '1f130918-32a4-65c6-8000-f29d717f3a51'}}, metadata={'source': 'loop', 'step': 0, 'parents': {}}, created_at='2026-04-05T01:48:15.417282+00:00', parent_config={'configurable': {'thread_id': 'user_test11', 'checkpoint_ns': '', 'checkpoint_id': '1f130918-32a1-6f06-bfff-81bc659af68a'}}, tasks=(PregelTask(id='3f40da22-77ba-a0ed-28d4-0ef2657e33b4', name='agent_node', path=('__pregel_pull', 'agent_node'), error=None, interrupts=(), state=None, result={'num': 2}),), interrupts=())
StateSnapshot(values={}, next=('__start__',), config={'configurable': {'thread_id': 'user_test11', 'checkpoint_ns': '', 'checkpoint_id': '1f130918-32a1-6f06-bfff-81bc659af68a'}}, metadata={'source': 'input', 'step': -1, 'parents': {}}, created_at='2026-04-05T01:48:15.416291+00:00', parent_config=None, tasks=(PregelTask(id='6fb544a0-9553-ee00-75c2-02fb4bff4189', name='__start__', path=('__pregel_pull', '__start__'), error=None, interrupts=(), state=None, result={'task': '数学', 'test_stream': '我是测试'}),), interrupts=())
回复工作流
num_test: 2
{'num': 4, 'isCompleted': True, 'task': '数学', 'message': '所有任务已经完成,流向END节点', 'test_stream': '我是测试'}
因为第一次报错退出了,所以当前状态停留在match_agent到agent_node那一步
可以看到历史执行栈,next到agent_node结束了。
然后我们恢复执行的话,会继续从当前节点执行下去,然后到结束。其中,match_agent这些已经执行过的,不会再执行一遍。
数据库检查点
上述演示了内存检查点,这次将数据存放到sql中。
检查功能点由符合BaskChecjpointSaver接口的检查点对象提供支持,一般中小项目使用sqlite即可,中大型项目使用postgres.
用法跟内存checkpoint类似,只不过数据库需要声明连接等信息。
构建Agent实现记忆存储。
之前langchain是使用RunnableWithMessageHistory,将chain包裹起来,然后获取内存对象,如
#模拟全局缓存,后续可以换成redis等
store = {}
def get_message_history(session_id: str):
if session_id not in store:
store[session_id] = InMemoryChatMessageHistory();
return store[session_id]
def memoryHistory():
llm = init_llm_client();
prompt1 = ChatPromptTemplate([
("system", "你是一个AI助手"),
MessagesPlaceholder("history"), # 历史数据占位符
("human", "{input}")
])
parser = StrOutputParser()
chain = prompt1 | llm | parser
# 创建内存聊天实例,用于存储会话历史
# 创建带消息历史的可运行对象,用于处理带历史记录的会话
runnbale = RunnableWithMessageHistory(chain,
# 通过id指定历史对象,多个对象历史对象可能不同,每次调用invoke都会自动加对话存到history里面
get_session_history=lambda session_id: get_message_history(session_id),
input_messages_key="input", # 指定输入键
history_messages_key="history", # 消息历史插槽键
)
# 通过RunnableConfig配置运行时参数
config = RunnableConfig(configurable={"session_id": "1"})
print(runnbale.invoke({"input": "我叫小明"}, config))
print(runnbale.invoke({"input": "我是谁"}, config))
if __name__ == "__main__":
# asyncio.run(async_batch_call())
memoryHistory()
在creage_agent调用的时候,我们可以指定checkpoint实现记忆功能。
checkpointer = InMemorySaver()
agent = create_agent(model=init_llm_clinet(), checkpointer=checkpointer)
config1 = {"configurable": {"thread_id": "user_test22"}}
agent.invoke({"messages": [("user", "你好,我叫张三,喜欢足球")]}, config=config1)
msg1 = agent.invoke({"messages": [("user", "我叫什么,我喜欢做什么")]}, config=config1)
print(f"msg1 {msg1["messages"][-1]}")
if __name__ == "__main__":
print()
如上,在创建agetn的时候,指定checkpointer,然后传入对应的thread_id,就可以获取内存历史信息功能。
结果
content='您叫张三,喜欢足球。'
时间回溯功能
Langgraph提供了时间回溯功能来支持,可以从之前的检查点恢复执行,要么重放相同的状态,要么对其进行修改以探索其他可能性。在所有情况下,恢复过去的执行都会在历史记录中产生新一个新的分支。
通俗:打游戏存储了一个节点,结果发现后面任务做错了,重新load到之前存储的节点,用新的办法去通关,此时会产生新的状态(分支)。
时间回溯依赖checkpoint功能,比如MemorySaver,数据库持久化save等,把每一步执行状态保存下来。
还是以上述command例子为例
history = list(app.get_state_history(config))
for i, step1 in enumerate(history):
print(f"步骤 {i}: 下一节点: {step1.next}, 状态值 {step1.values}")
print("回复工作流")
result2 = app.invoke(None, config)
print(result2)
# 时间回溯
checkpoint2 = history[2]
# 更新状态
newConfig = app.update_state(checkpoint2.config, values={"task": "翻译"})
print(f"newConfig.config {newConfig}")
result3 = app.invoke(None, newConfig)
print(f"时间回溯功能 {result3}")
先通过history获取某一个节点的状态,然后通过app.update_state更新状态值,得到新的config,再执行的时候传入新的config即可。
结果:
下一个节点是: ('agent_node',)
步骤 0: 下一节点: ('agent_node',), 状态值 {'num': 4, 'isCompleted': True, 'task': '数学', 'test_stream': '我是测试'}
步骤 1: 下一节点: ('math_agent',), 状态值 {'num': 2, 'task': '数学', 'test_stream': '我是测试'}
步骤 2: 下一节点: ('agent_node',), 状态值 {'task': '数学', 'test_stream': '我是测试'}
步骤 3: 下一节点: ('__start__',), 状态值 {}
回到了步骤二,修改节点状态
回复工作流
num_test: 2
{'num': 4, 'isCompleted': True, 'task': '数学', 'message': '所有任务已经完成,流向END节点', 'test_stream': '我是测试'}
newConfig.config {'configurable': {'thread_id': 'user_test11', 'checkpoint_ns': '', 'checkpoint_id': '1f131694-23a6-6478-8001-938e1f82e691'}}
num_test: 2
时间回溯功能 {'language': AIMessage(content='这句话..., 'isCompleted': True, 'task': '翻译', 'message': '所有任务已经完成,流向END节点', 'test_stream': '我是测试'}
如上,最后执行的时候,不是走match_agent了,而是走到了翻译agent。
子图作为节点加入到父图
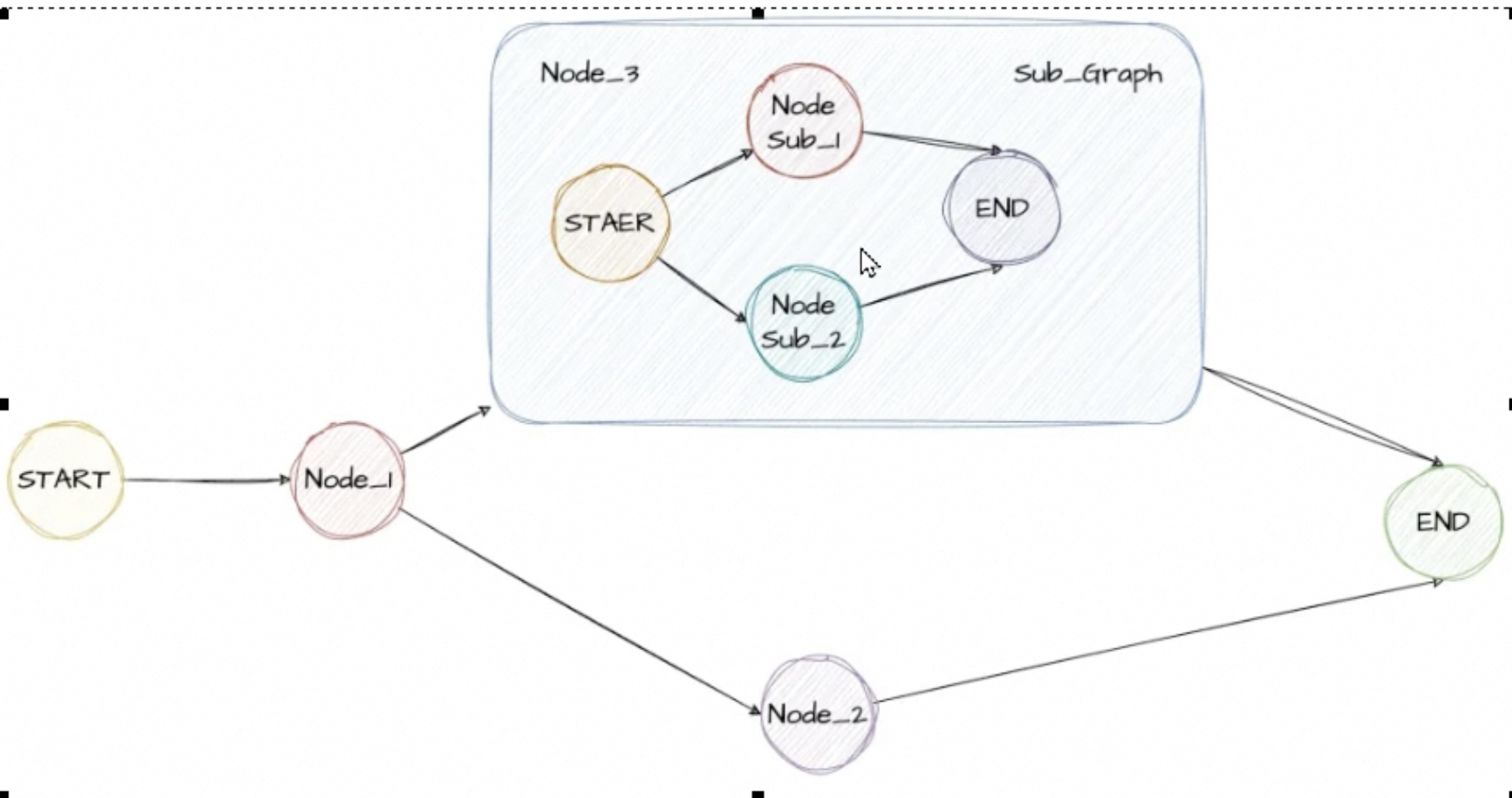
子图可以作为另一个图的节点存在。
子图可以有自己的私有状态,父图无法获取,只能得到子图返回的内容。
还是以上述例子为例
# 数学计算agent
def math_agent(state: TestState, runtime: Runtime[GlobalContext]) -> Command:
print("math_agent执行了")
num = state.get("num") * 2
writer = get_stream_writer()
writer({"custom_key": f"到达数学agent,当前计算的值是{num}", "test": "我是测试custom"})
return {"num": num, "isCompleted": True, "sub_state": [1]}
# 数学计算子图
class SubState(TypedDict):
num: int
isCompleted: bool
sub_state: Annotated[list, operator.add]
graph1 = StateGraph(SubState, context_schema=GlobalContext)
graph1.add_node("math_agent", math_agent, retry_policy=retry_policy)
graph1.add_edge(START, "math_agent")
graph1.add_edge("math_agent", END)
sub_math_graph = graph1.compile()
将match_agent节点改成match_graph子图,如上,子图的第三个状态是私有状态,父图无法拿到,然后修改父图的节点即可
graph.add_node("sub_math_graph", sub_math_graph)
graph.add_node("translate_agent", translate_agent)
# 添加边
graph.add_edge(START, "agent_node")
graph.add_edge("sub_math_graph", "agent_node")
最后结果
步骤 0: 下一节点: (), 状态值 {'num': 4, 'isCompleted': True, 'task': '数学', 'message': '所有任务已经完成,流向END节点', 'test_stream': '我是测试'}
步骤 1: 下一节点: ('agent_node',), 状态值 {'num': 4, 'isCompleted': True, 'task': '数学', 'test_stream': '我是测试'}
步骤 2: 下一节点: ('sub_math_graph',), 状态值 {'num': 2, 'task': '数学', 'test_stream': '我是测试'}
步骤 3: 下一节点: ('agent_node',), 状态值 {'task': '数学', 'test_stream': '我是测试'}
步骤 4: 下一节点: ('__start__',), 状态值 {}
除此之外,可以使用代理节点
# 代理节点
def match_proxy_agent(state: TestState):
count = state.get("num");
result = sub_math_graph.invoke({"count": count})
print(f"代理节点运行结果: {result}")
num = result.get("count")
isCompleted = result.get("isCompleted")
return {"num": num, "isCompleted": isCompleted}
子图跟父图状态可以完全不一致,通过match_proxy_agent代理节点进行数据的转换。
多智能体架构
A2A协议 VS MCP
这两个协议主要代表了AI架构的两个不同发展方向。
A2A 主要是专注于代理写作,建立智能代理之间相互发现,交流和合作的方式,使得不同的AI系统能像人类团队一样,协同工作。
MCP主要是定义一套协议,类似于工具的USB,有了这个协议,Agetn就能获取MCP Server端的工具进行调用。
多智能体:
在LangGraph中,Agent就是一个可调用的节点,通常封装了一个LLM+工具调用逻辑。
多智能体架构 = 多个Agent节点组成一个图(Graph),通过消息传递,条件跳转(Command/Send)和记忆协作。
类似于微服务。
多智能体:可扩展增加Agent,每个Agent专注自己的事情,更可控,人类可以干预闭环,时间回溯来管理执行流程。
多智能体架构

主流的是 Supervisor(主管)/SubAgents(子代理),由一个主agent进行路由,决定分发到其他子agent。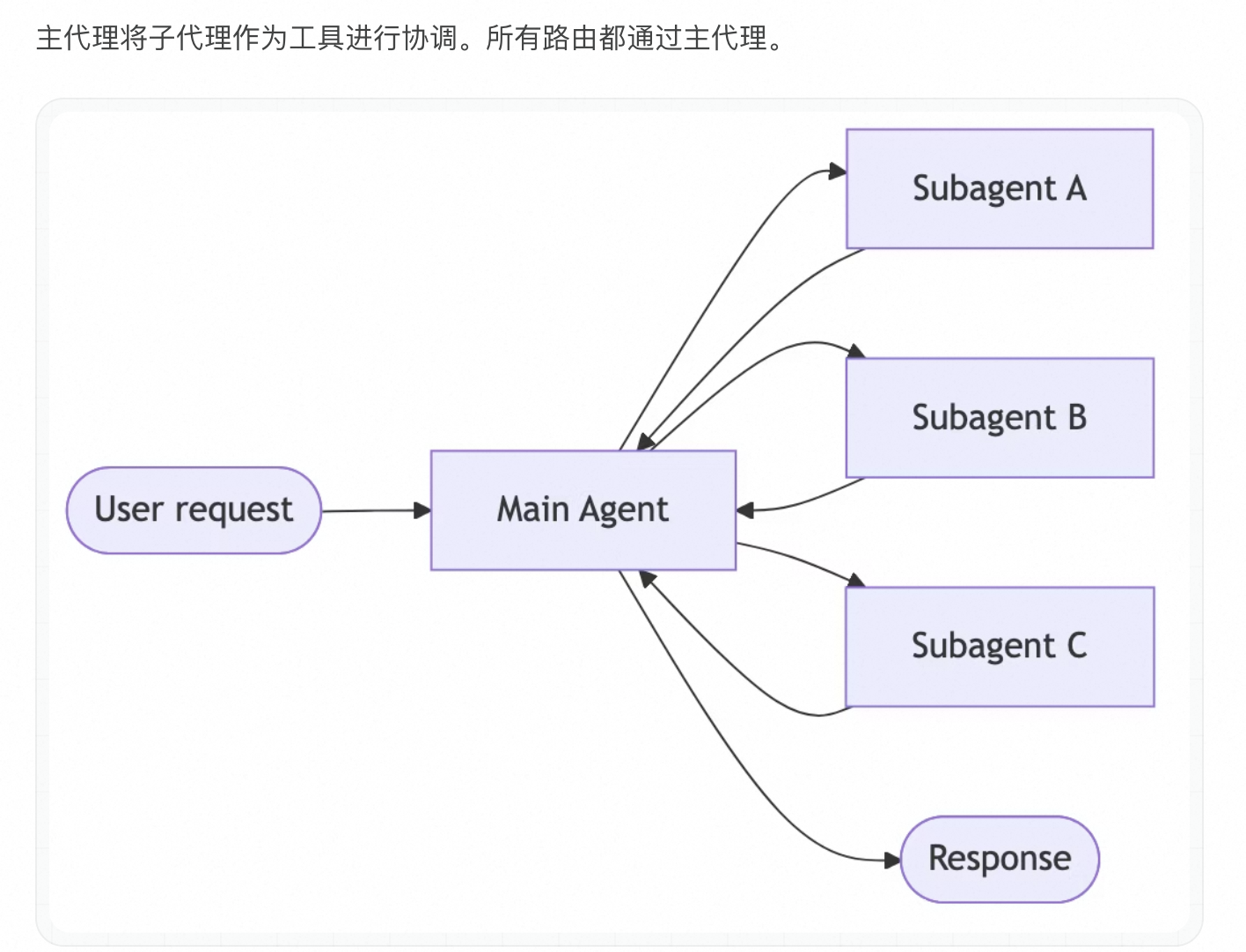
A2A案例
Supervisor 主管模式
pip install langgraph-supervisor
有一个场景:我需要坐飞机从上海到北京,并且需要预定酒店。
这时候,主Agetn会解析我们的需求,调用定酒店agent和定机票agent,根据他们的结果汇总返回。
订机票的agent:
def book_flight(from1: str, to: str):
"""预定机票工具,根据出发和到达机场,预定一张机票,并返回预定结果"""
print(f"成功预订了从 {from1} 到 {to}的航班")
return f"成功预订了从 {from1} 到 {to}的航班"
# fligth_assistant
flight_assistant = create_agent(model=init_llm_clinet(), tools=[book_flight], name="flight_assistant",
定酒店的agent:
# hotel
def book_hotel(hotel_name):
"""预定酒店工具,根据酒店名称完成酒店预订,返回预定结果"""
print(f"成功预订了 {hotel_name}的酒店")
return f"成功预订了 {hotel_name}的酒店"
hotel_assistant = create_agent(model=init_llm_clinet(), tools=[book_hotel], name="hotel_assistant",
langchan1.0之后统一使用create_agent创建智能体。
主agent:
supervisor = create_supervisor(agents=[flight_assistant, hotel_assistant], model=init_llm_clinet(),
prompt=(
"你是一个智能任务调度主管,负责协调航班预订助手(flight_assistant)和酒店预订助手(hotel_assistant)。 \n\n"
"工作流程: \n"
"1. 分析用户需求,确定需要哪些服务(航班、酒店或两者) \n"
"2. 如果需要预订航班,调用flight_assistant一次\n"
"3. 如果需要预订酒店,调用hotel_assistant一次\n"
"4. 收到助手的预订确认后,记录结果\n"
"5. 当所有任务都完成后,向用户汇总所有预订结果,然后立即结束\n\n"
"关键规则: \n"
"- 每个助手只能调用一次,不要重复调用\n"
"- 看到 '成功预订' 的消息后,该任务就已完成\n"
"- 所有任务完成后,必须直接结束,不要再调用任何助手\n"
"- 如果已经看到航班和酒店的预订确认,立即汇总并结束"
)
).compile()
create_supervisor帮我们封装好了一个图,不用我们手写add_edges这些。将子agent传入,然后写好prompt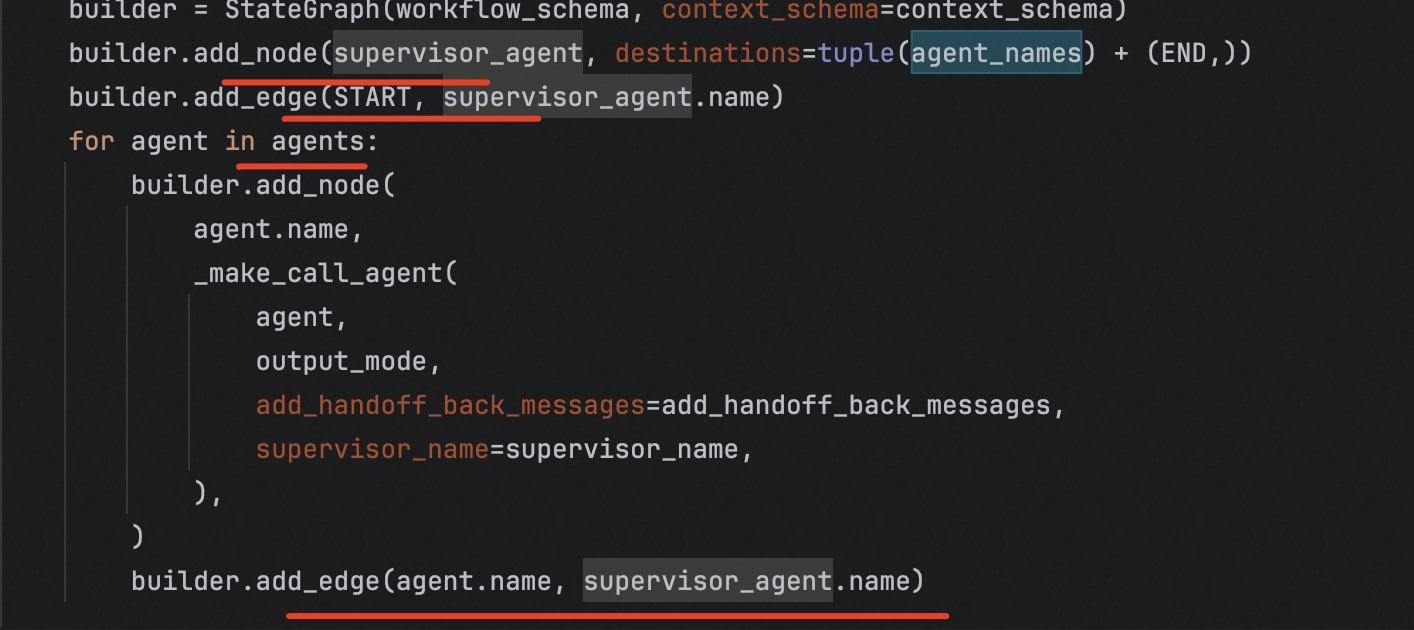
这是create_supervisor源码的一部分。
测试
for chunk in supervisor.stream({
"messages": [
{
"role": "user",
"content": "帮我预定一个从北京到深圳的机票,并且预定一个如家酒店的机票"
}
]
}, stream_mode=["values", "updates"]):
mode, data = chunk
print_chunk(mode, data)
print("\n")
结果:
Handoffs 交接模式
handoffs是指将控制权由一个智能体交到下一个智能体,(强制的),上述的主管是由主agetn去控制,这里的需要我们写死流程去控制,不再使用prompt去控制agetn的流向,而是通过强制定义规则控制。
定义交接工具
# 定义handoffs交接工具
def create_task_descripion_handoff_tool(*, agent_name: str, description: str | None = None):
name = f"transfer_to_{agent_name}"
description = description or f"U移交给 {agent_name}"
@tool(name, description=description)
def handoff_tool(
task_descripton: Annotated[str, "描述下一个Agent应该做什么,包含所有必要信息"],
state: Annotated[MessagesState, InjectedState]) -> Command:
task_descripton_messages = {
"role": "user",
"content": task_descripton
}
agent_input = {
**state,
"messages": [task_descripton_messages]
}
return Command(goto=[Send(agent_name, agent_input)], graph=Command.PARENT)
return handoff_tool
transfer_to_flight_assistant = create_task_descripion_handoff_tool(
agent_name="flight_assistant", description="将任务移交给航班预订助手")
transfer_to_hotel_assistant = create_task_descripion_handoff_tool(
agent_name="hotel_assistant",
description="将任务移交给酒店预订助手"
)
自己定义交接工具,作为tool传入agent,然后自己构建流程
multi_agent_graph = (
StateGraph({}).add_node(flight_assistant).add_node(hotel_assistant)
.add_edge(START,"flight_assistant").compile())
+-----------+
| __start__ |
+-----------+
*
*
*
+------------------+
| flight_assistant |
+------------------+
*
*
*
+---------+
| __end__ |
+---------+
虽然流程只有flight_assistant,但是flight_assistant节点有工具transfer_to_hotel_assistant,他会返回
return Command(goto=[Send(agent_name, agent_input)], graph=Command.PARENT)
返回Command对象,直接到下一个节点。
Agent Skills
渐进式披露三层架构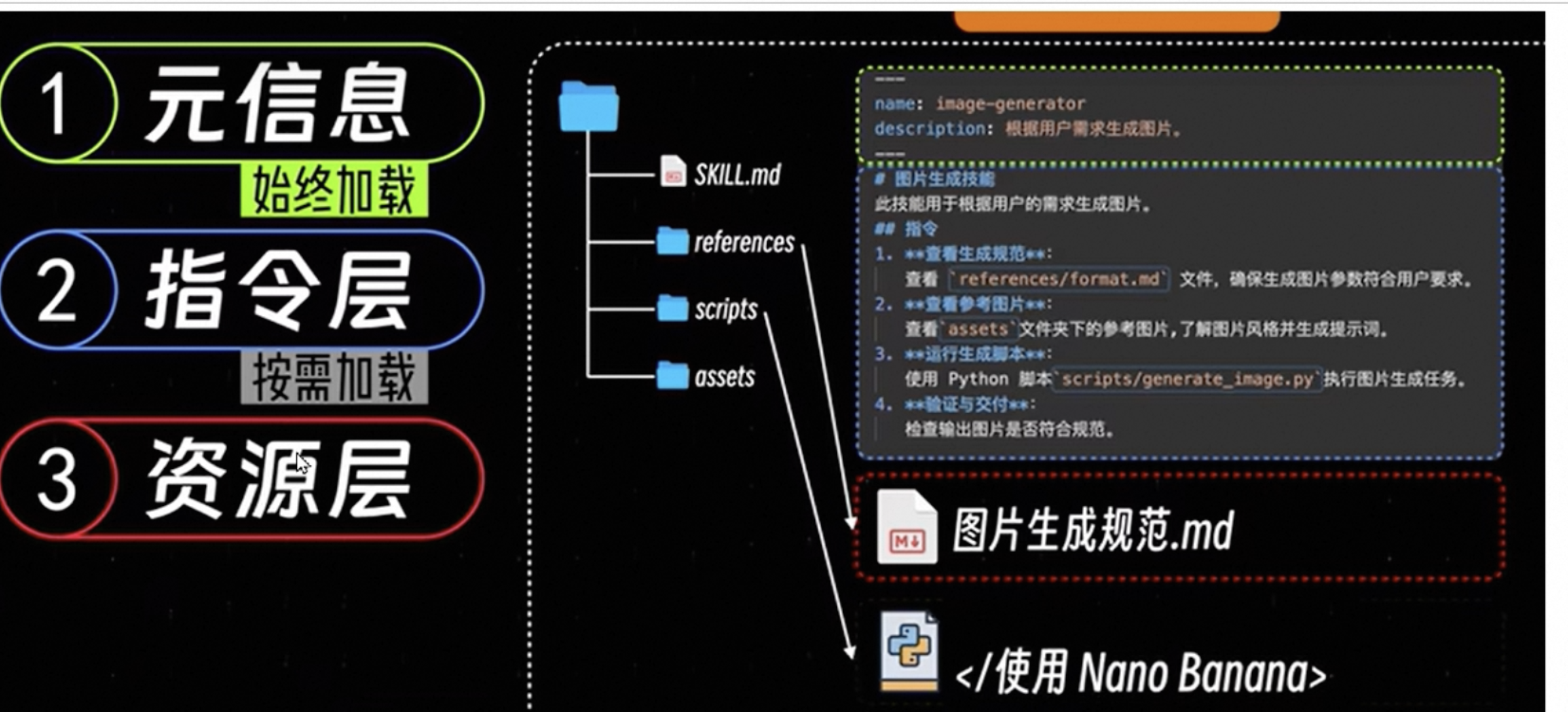
元信息主要就是SKILL.md文件的信息,是必须加载的,指令层则是scrips/reference的东西,按需加载,资源层则是一写图片的内容,真正需要用到才会加载。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 6
6 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)