带分数正则的一致性蒸馏
论文:Large Scale Diffusion Distillation via Score-Regularized Continuous-Time Consistency

在JVP的架构挑战下(比如BF16精度的数值误差,flash attention、上下文并行的复杂实现),在评估指标缺失的情况下(FID用来评估弱条件的imagenet基准还行,但T2I T2V这些强条件任务更强调一些细节属性,比如文本对齐度),如何将连续时间一致性蒸馏(sCM)应用到企业级图像和视频模型?
实现兼容并行策略(FSDP、CP)的FlashAttention-2 JVP核,将sCM扩展至超百亿参数模型和高维视频数据;引入分数正则器,在保证生成多样性的同时提升画面细节质量,无需多阶段训练、GAN调整、架构或超参搜索。
时间步转换
训练时采用trigflow前向过程()会比较稳定,但现实很多教师模型用的是其他调度方式,比如reflected flow(
)。可以利用不同扩散模型间噪声调度和参数化方法的等价性,对时间步进行包装而不是重训练教师,再把模型教师输出统一成EDM框架下对干净数据的预测
(所以包装操作均在FP64下进行以保证精度):
假设教师原始噪声调度为、
,时间步为
,输出为
。通过信噪比匹配解析出trigflow时间步t到
的映射,即求解
,得到
,
,
,
。
比如,现在给你trigflow下的时间步t,如何获取reflected flow下的预条件化参数?
根据噪声强度匹配,可得
(即
,同时也是
),根据
,可以得到
。再联立
和
,得到
,所以
,
,也就是代码中下列这个类,根据trigflow调度下的时间步得到reflected flow调度下的
、
、
、
sigma_data: float = 1.0
rectified_flow_t_scaling_factor: float = 1000.0 # 时间步在输入网络之前都会乘以一个1000,属于历史习惯
self.scaling = RectifiedFlow_TrigFlowWrapper(config.sigma_data, config.rectified_flow_t_scaling_factor)
...
class RectifiedFlow_TrigFlowWrapper:
def __init__(self, sigma_data: float = 1.0, t_scaling_factor: float = 1.0):
assert abs(sigma_data - 1.0) < 1e-6, "sigma_data must be 1.0 for RectifiedFlowScaling"
self.t_scaling_factor = t_scaling_factor
def __call__(self, trigflow_t: torch.Tensor) -> tuple[torch.Tensor, torch.Tensor, torch.Tensor, torch.Tensor]:
trigflow_t = trigflow_t.to(torch.float64)
c_skip = 1 / (torch.cos(trigflow_t) + torch.sin(trigflow_t))
c_out = -1 * torch.sin(trigflow_t) / (torch.cos(trigflow_t) + torch.sin(trigflow_t))
c_in = 1 / (torch.cos(trigflow_t) + torch.sin(trigflow_t))
c_noise = (torch.sin(trigflow_t) / (torch.cos(trigflow_t) + torch.sin(trigflow_t))) * self.t_scaling_factor
return c_skip, c_out, c_in, c_noise这样就能不改变模型,而是在EDM框架下,包装,调用代码如下
# convert noise level time to EDM-formulation coefficients
c_skip_B_1_T_1_1, c_out_B_1_T_1_1, c_in_B_1_T_1_1, c_noise_B_1_T_1_1 = self.scaling(trigflow_t=time_B_1_T_1_1)
net = {"student": self.net, "teacher": self.net_teacher, "fake_score": self.net_fake_score}[net_type]
net_output_B_C_T_H_W = net( # 预条件化输入
x_B_C_T_H_W=(xt_B_C_T_H_W * c_in_B_1_T_1_1).to(**self.tensor_kwargs),
timesteps_B_T=c_noise_B_1_T_1_1.squeeze(dim=[1, 3, 4]).to(**self.tensor_kwargs),
**condition.to_dict(),
).float()
# EDM reconstruction of x0 预条件化输出
x0_pred_B_C_T_H_W = c_skip_B_1_T_1_1 * xt_B_C_T_H_W + c_out_B_1_T_1_1 * net_output_B_C_T_H_W再联立和
,得到教师在trigflow调度下的等价输出
F_pred_B_C_T_H_W = (torch.cos(time_B_1_T_1_1) * xt_B_C_T_H_W - x0_pred_B_C_T_H_W) / torch.sin(time_B_1_T_1_1)推理流程
学生设置,对应TrigFlow的
,再设定中间三个
为1.5, 1.4, 1.0(n步推理就选前n-1个),对应在Reflected Flow的t[0.9877, 0.9338, 0.8529, 0.6090, 0.0000],其中第一个值也可以由
直接获得。采样流程:初始样本设置为
。迭代
,每轮输入样本、当前时间步、条件信息,由网络预测速度场v_{pred},更新样本
,执行一个去噪加噪的过程。
老师设置,转化为Reflected Flow的的时间
,即最终采样轨迹的最大时间。选用Euler或者UniPC采样器求解flow ODE
,在求解的过程中都不会引入随机性。迭代采样器设置的时间步t,分别将提示词和负提示词输入网络,预测
和
,加权求和得到
,将v、t、
交给求解器,得到
。
ODE求解器:
import torch
class FlowEulerSampler:
def __init__(
self,
num_train_timesteps=1000, # 训练时的时间离散数量
sigma_max=1.0, # 最大时间
sigma_min=0.0, # 最小时间
):
self.num_train_timesteps = num_train_timesteps
self.sigma_max = sigma_max
self.sigma_min = sigma_min
def set_timesteps(self, num_inference_steps=100, shift=3.0, device="cuda"):
self.sigmas = torch.linspace(self.sigma_max, self.sigma_min, num_inference_steps + 1)[:-1] # 均匀采样时间步
self.sigmas = shift * self.sigmas / (1 + (shift - 1) * self.sigmas) # 时间重参数化,调整分布
# 将时间区间从[0,1]变成[0,1000]
self.timesteps = self.sigmas * self.num_train_timesteps
self.sigmas = self.sigmas.to(device)
self.timesteps = self.timesteps.to(device)
def step(self, model_output, timestep, sample):
# 真正的积分步骤。输入模型预测的v,当前时间,潜变量
timestep_id = torch.argmin((self.timesteps - timestep).abs(), dim=0)
sigma = self.sigmas[timestep_id] # 找到最接近的时间步的下标
if timestep_id + 1 >= len(self.timesteps):
sigma_ = 0 # 最后一步直接设为 0
else:
sigma_ = self.sigmas[timestep_id + 1]
prev_sample = sample + model_output * (sigma_ - sigma)
return prev_sampleEuler求解器代码如上,更新形式为,精度只有一阶,而UniPC求解器改用多步法,使用前几步的模型输出,拟合更准确的ODE轨迹,代码太长了,介绍一下原理好了:unified predictor-corrector,将扩散ODE写成
,logSNR空间更加稳定,首先利用历史导数预测下一样本
,根据导数变化量
做修正,得到更准确的
。
在噪声调度这块,为了让细节处理的更精细,会对噪声进行格式重参数化,调节采样密度,比如
幂律衰减;
指数衰减。
对σ的shift操作也有多种,控制每一步的扰动大小和稳定性,比如、
。在教师的采样器内部包含了对时间重参数化
的过程,所以需事先将输入的
转换回未shift的版本,即
。
训练设置
时间步采样
和EDM体系一样,训练时在log-normal中进行采样,即
,具体地,在sCM这一项中
,在DMD这一项以及训练假分数网络时
,训练时从噪声分布中采样噪声强度的代码如下(采样后需要转成trigflow调度下的时间步):
p_G: LazyDict = L(LogNormal)(
p_mean=-0.8,
p_std=1.6,
)
adjust_video_noise: bool = True # whether or not adjust video noise accroding to the video length
state_t: int = 21 # Number of latent frames
...
def draw_training_time_G(self, x0_size: int, condition: Any) -> torch.Tensor:
batch_size = x0_size[0]
# p_G
sigma_B = self.p_G(batch_size).to(device="cuda")
sigma_B_1 = rearrange(sigma_B, "b -> b 1") # add a dimension for T, all frames share the same sigma
is_video_batch = condition.data_type == DataType.VIDEO
multiplier = self.video_noise_multiplier if is_video_batch else 1
sigma_B_1 = sigma_B_1 * multiplier # 视频训练时×帧数的开方,使整体偏向于更高噪声,补偿维度的增加
time_B_1 = torch.arctan(sigma_B_1)
return time_B_1.double()
def draw_training_time_D(self, x0_size: int, condition: Any) -> torch.Tensor:
batch_size = x0_size[0]
if self.config.timestep_shift > 0:
# 在为老师采样时间步时,会设置timestep_shift=5.0
# 选择直接在高斯分布中采样 reflected flow 下的时间步,然后 shift 以覆盖更多的高噪声区域
# 再转换-》EDM下的σ-》trigflow下的时间步
sigma_B = torch.rand(batch_size).to(device="cuda").double()
sigma_B = self.config.timestep_shift * sigma_B / (1 + (self.config.timestep_shift - 1) * sigma_B)
sigma_B_1 = rearrange(sigma_B, "b -> b 1")
time_B_1 = torch.arctan(sigma_B_1 / (1 - sigma_B_1))
return time_B_1
# p_D (和p_G 基本一样)
...
return time_B_1.double()而在diffsynth studio实现Wan2.2-i2v-14b训练时,似乎是均匀采样时间步,只是不同时间不的损失加上不同的权重,而隔离高低噪声模型训练的逻辑就是限制均匀采样区间。我们可以仿照这样的逻辑rCM蒸馏,还是构造一个全局的log-norm采样分布,
def set_training_weight(self):
steps = 1000
x = self.timesteps
y = torch.exp(-2 * ((x - steps / 2) / steps) ** 2)
y_shifted = y - y.min()
bsmntw_weighing = y_shifted * (steps / y_shifted.sum())
if len(self.timesteps) != 1000:
# This is an empirical formula.
bsmntw_weighing = bsmntw_weighing * (len(self.timesteps) / steps)
bsmntw_weighing = bsmntw_weighing + bsmntw_weighing[1]
self.linear_timesteps_weights = bsmntw_weighing我们可视化一下两种采样方案下trigflow时间步的概率分布。
shift方案的采样流程:均匀采样reflected flow下的时间步,对其施加漂移
,计算噪声强度
,转化为trigflow时间步
,现在自变量x是
,和
的变化趋势一致,满足
,于是求解可得
,于是概率密度
(均匀分布的分布函数知道概率密度函数不知道);
log-normal的采样流程就像前文说的那样,只是高斯采样作者原代码如下
cdf_vals = np.random.uniform(size=(batch_size)) # 在[0, 1) 区间内生成均匀分布的随机数
samples_interval_gaussian = [self.gaussian_dist.inv_cdf(cdf_val) for cdf_val in cdf_vals] # 通过反累积分布函数(inverse CDF)将均匀分布的随机数转换为正态分布的随机数
# 直接用高斯分布中采样不好吗?↓
z = torch.randn(batch_size, device=device, dtype=torch.float64) * p_std + p_mean采样,得到
,
,依旧自变量x是
,有
,于是
,求解
(高斯分布的分布函数不知道概率密度函数知道)
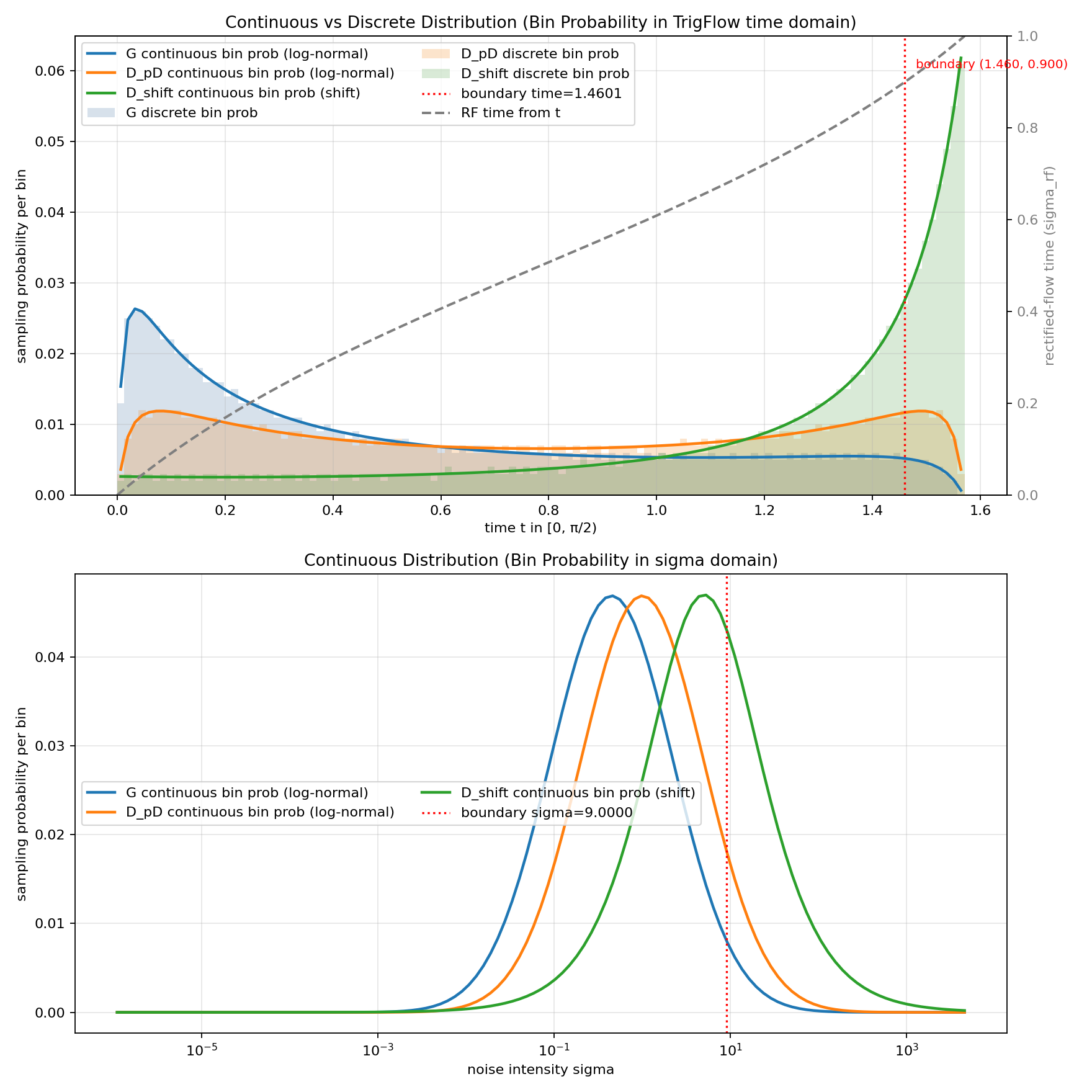
下半部分子图把噪声强度分布也画一下
优化器
优化器决定了在反向传播时,如何根据得到的梯度对模型参数进行更新,比如Adam优化器,假设旧参数为,梯度为
,学习率为
,它会往梯度中加入权重衰减项
,计算一阶矩
和二阶矩
,对它们做偏置修正
、
,得到更新量
,再更新参数
,而AdamW没有权重衰减项调整梯度,而是用在了权重更新上(
),其中
就是衰减项,用来把参数往0拉一点,起正则化的作用,AdamW几乎是transformer的默认优化器了。
FusedAdamW和AdamW的数学本质是一样的,但是AdamW每一步都会从显存都数据,然后做一点计算,又写回显存,受限于显存带宽,还有kernel launch开销,而fusedadam把多个操作融合到一个GPU kernel中,速度会快很多
AdamWConfig = L(get_base_optimizer)(
model=PLACEHOLDER,
lr=1e-4,
weight_decay=0.1,
betas=[0.9, 0.99],
optim_type="adamw",
eps=1e-8,
)
FusedAdamWConfig: LazyDict = L(get_base_optimizer)(
model=PLACEHOLDER,
lr=1e-4,
weight_decay=0.1,
betas=[0.9, 0.99],
optim_type="fusedadam",
eps=1e-8,
master_weights=True, # 参数存储精度
capturable=True,
)
# 实际用的优化器设置可能被覆盖为
optimizer=dict(
lr=2e-6, # 学习率小,意味着参数变化小,更适合对稳定性很敏感的训练,这是 1.3B,14B 设置的是1e-6,假分数网络设的更小,是4e-7
weight_decay=0.01,
betas=(0.0, 0.999), # 0.0意味着没有明显的历史记忆
),
# 学习率调度器的设置如下,用一个线性函数定义学习率的变化情况
LambdaLinearSchedulerConfig: LazyDict = L(LambdaLinearScheduler)(
warm_up_steps=[100],
cycle_lengths=[10000000000000],
f_start=[1.0e-6],
f_max=[1.0],
f_min=[1.0],
)一致性模型
目标是确保教师轨迹上相邻时间步下模型能有一样的输出,离散时间下最小化目标为,其中
、
是权重的无梯度更新版本,
是从
点求解教师轨迹的PF-ODE
得到的
时的样本,有离散误差,怎么设置
也是个麻烦。
连续时间版本下,限制,选择度量函数
,此时一致性损失可简化成
,其中
是
在
点处沿着教师轨迹的切线。
代入TrigFlow噪声调度,损失进步简化
,其中
,可用 pytorch 内置的前向求导运算 torch.func.jvp 自动计算全微分
,所以学生的去噪过程都得伴随着jvp分支。
构造一致性损失就是,希望学生的更新沿着g的方向,实现跨时间一致。
蒸馏代码
具体rCM对学生的一致性蒸馏怎么做的呢?实际训练时有一些不稳定的风险,需额外调整一下,在原始sCM中针对的模型中有稳定性差的Fourier时间嵌入和AdaGN层,而在Wan模型中没有,换成位置时间嵌入、AdaLN、QK正则化等等,故可以保持模型架构不变。将sCM的FP16替换为BF16避免上溢出问题。
会正则化切线,用损失,其中c=0.1、
考虑到几乎是个常量,于是舍弃掉sCM的动态权重。
def _student_scm_step(self, ctx, iteration):
log.debug(f"Student update {iteration} (sCM)")
x0_B_C_T_H_W, condition, uncondition = ctx
time_B_T = self.draw_training_time_G(x0_B_C_T_H_W.size(), condition) # log-normal采样,返回的是 trigflow 框架下的时间步
epsilon_B_C_T_H_W = torch.randn(x0_B_C_T_H_W.size(), device="cuda")
time_B_T, epsilon_B_C_T_H_W = self.sync(time_B_T, epsilon_B_C_T_H_W)
time_B_1_T_1_1 = rearrange(time_B_T, "b t -> b 1 t 1 1")
cost_B_1_T_1_1, sint_B_1_T_1_1 = torch.cos(time_B_1_T_1_1), torch.sin(time_B_1_T_1_1)
# 对来自数据集的x_0进行一次加噪,得到网络输入的xt
xt_B_C_T_H_W = x0_B_C_T_H_W * cost_B_1_T_1_1 + epsilon_B_C_T_H_W * sint_B_1_T_1_1
# 老师对 xt 做一次去噪
with torch.no_grad():
F_teacher_B_C_T_H_W = self.denoise(xt_B_C_T_H_W, time_B_T, condition, net_type="teacher").F
if self.config.teacher_guidance > 0.0: # 默认教师的cfg设置为5.0
F_teacher_B_C_T_H_W_uncond = self.denoise(xt_B_C_T_H_W, time_B_T, uncondition, net_type="teacher").F
F_teacher_B_C_T_H_W = F_teacher_B_C_T_H_W + self.config.teacher_guidance * (F_teacher_B_C_T_H_W - F_teacher_B_C_T_H_W_uncond)
# see Section 5.1 JVP rearrangement discussion https://arxiv.org/pdf/2410.11081
t_xt_B_C_T_H_W = cost_B_1_T_1_1 * sint_B_1_T_1_1 * F_teacher_B_C_T_H_W
t_time_B_T = (cost_B_1_T_1_1 * sint_B_1_T_1_1).squeeze(dim=[1, 3, 4])由
预测,即
,其中导数
前有一个系数
,在t=0时学生会学着向老师靠近,但当
时来自
的监督信号变弱,学习的动态逐渐由数值稳定性更差的JVP运算主导。这里沿用JVP重排,设置
并将其融入JVP计算中,即
,
其中
就是融合后的JVP计算(函数是有两个输入,算偏导数时就定义为相互独立),上列最后两行代码就是两个红色的系数,下列代码中self.config.fd_type = 0时实现JVP精确计算。
JVP就是用一个方向向量v去探测函数在该方向上的变化率,即
(矩阵乘),其中偏导数
,所以直接调用学生伴随JVP的去噪代码,里面会发生什么呢?
def student_F_withT(self, xt_B_C_T_H_W: TensorWithT, time: TensorWithT, condition: TextCondition) -> TensorWithT:
xt_B_C_T_H_W_withT, time_withT = xt_B_C_T_H_W, time
xt_B_C_T_H_W, t_xt_B_C_T_H_W = xt_B_C_T_H_W_withT
time, t_time = time_withT获取x_t和t,以及前文两个红色系数和
(c_skip_B_1_T_1_1, c_out_B_1_T_1_1, c_in_B_1_T_1_1, c_noise_B_1_T_1_1), (
t_c_skip_B_1_T_1_1,
t_c_out_B_1_T_1_1,
t_c_in_B_1_T_1_1,
t_c_noise_B_1_T_1_1,
) = torch.func.jvp(self.scaling, (time_B_1_T_1_1,), (t_time_B_1_T_1_1,))scaling是4个函数,
def _process_input(xt_B_C_T_H_W, c_in_B_1_T_1_1):
return xt_B_C_T_H_W * c_in_B_1_T_1_1
x_B_C_T_H_W, t_x_B_C_T_H_W = torch.func.jvp(_process_input, (xt_B_C_T_H_W, c_in_B_1_T_1_1), (t_xt_B_C_T_H_W, t_c_in_B_1_T_1_1))这里一个函数,通过链式法则
,
,torch.func.jvp输入
,输出便是
# 带 jvp 分支的模型前向
net_output_B_C_T_H_W, t_net_output_B_C_T_H_W = self.net(
x_B_C_T_H_W=(
x_B_C_T_H_W.to(**self.tensor_kwargs),
t_x_B_C_T_H_W.to(**self.tensor_kwargs),
),
timesteps_B_T=(
c_noise_B_1_T_1_1.squeeze(dim=[1, 3, 4]).to(**self.tensor_kwargs),
t_c_noise_B_1_T_1_1.squeeze(dim=[1, 3, 4]).to(**self.tensor_kwargs),
),
**condition.to_dict(),
withT=True,
) # 输出会被转成float32老师的前向函数,依旧链式法则
,
,两者加和
,
对应上torch.func.jvp输入
# 带 jvp 分支的模型前向
net_output_B_C_T_H_W, t_net_output_B_C_T_H_W = self.net(
x_B_C_T_H_W=(
x_B_C_T_H_W.to(**self.tensor_kwargs),
t_x_B_C_T_H_W.to(**self.tensor_kwargs),
),
timesteps_B_T=(
c_noise_B_1_T_1_1.squeeze(dim=[1, 3, 4]).to(**self.tensor_kwargs),
t_c_noise_B_1_T_1_1.squeeze(dim=[1, 3, 4]).to(**self.tensor_kwargs),
),
**condition.to_dict(),
withT=True,
) # 输出会被转成float32
net_output_B_C_T_H_W, t_net_output_B_C_T_H_W = net_output_B_C_T_H_W.float(), t_net_output_B_C_T_H_W.float()
def _process_output(xt_B_C_T_H_W, net_output_B_C_T_H_W, c_skip_B_1_T_1_1, c_out_B_1_T_1_1, time_B_1_T_1_1):
x0_pred_B_C_T_H_W = c_skip_B_1_T_1_1 * xt_B_C_T_H_W + c_out_B_1_T_1_1 * net_output_B_C_T_H_W
F_pred_B_C_T_H_W = (torch.cos(time_B_1_T_1_1) * xt_B_C_T_H_W - x0_pred_B_C_T_H_W) / torch.sin(time_B_1_T_1_1)
return F_pred_B_C_T_H_W
F_pred_B_C_T_H_W, t_F_pred_B_C_T_H_W = torch.func.jvp(
_process_output,
(xt_B_C_T_H_W, net_output_B_C_T_H_W, c_skip_B_1_T_1_1, c_out_B_1_T_1_1, time_B_1_T_1_1),
(t_xt_B_C_T_H_W, t_net_output_B_C_T_H_W, t_c_skip_B_1_T_1_1, t_c_out_B_1_T_1_1, t_time_B_1_T_1_1),
)
return (F_pred_B_C_T_H_W, t_F_pred_B_C_T_H_W.detach())就是链式链式……最终返回的是,以及
。
考虑到对时间步的正余弦编码存在震荡(相邻时间步的嵌入向量可能差很远),会导致对时间的偏导项不稳定,可以采用“半连续时间”,即前半段对样本的偏导项还是用JVP做精确计算,后半对时间的偏导项用采用有限差分(finite difference)近似,即
,其计算对h很敏感,
对于2B的T2I模型是稳定的,不用改架构,而应对模型规模超过10B的视频任务下(比如Wan)时,需要用torch.amp.autocast包裹所有时间嵌入层,强制使用FP32精度。具体的看下列代码中self.config.fd_type = 1时。
解释一下这种trig flow路径下的差分近似方法,还挺新奇的,不保证理解正确。已知在trigflow路径下,速度场为,可精确求解
,区别于差分近似
,于是
得到,将速度场F(t)替换成模型输出
就能得到上面的有限差分近似公式了。
离散时间版本的一致性蒸馏就更好理解了,看下列代码中self.config.fd_type = 2时,计算、
,这个公式和前面的
很像,因为它们都是由trigflow的动力学结构决定的“精确离散化”,证明的展开式类似的。然后计算
,同理近似
。
with torch.no_grad():
if self.config.fd_type == 1: # semi-continuous
_, t_F_theta_B_C_T_H_W = self.student_F_withT((xt_B_C_T_H_W, t_xt_B_C_T_H_W), (time_B_T, 0 * t_time_B_T), condition)
h = self.config.fd_size
F_theta_B_C_T_H_W_n1 = self.denoise(xt_B_C_T_H_W, time_B_T - h, condition, net_type="student").F
pF_pt_B_C_T_H_W = (np.cos(h) * _ - F_theta_B_C_T_H_W_n1) / np.sin(h)
t_F_theta_B_C_T_H_W += cost_B_1_T_1_1 * sint_B_1_T_1_1 * pF_pt_B_C_T_H_W
elif self.config.fd_type == 2: # discrete
h = self.config.fd_size
_ = self.denoise(xt_B_C_T_H_W, time_B_T, condition, net_type="student").F
xt2_B_C_T_H_W = np.cos(h) * xt_B_C_T_H_W - np.sin(h) * F_teacher_B_C_T_H_W
_2 = self.denoise(xt2_B_C_T_H_W, time_B_T - h, condition, net_type="student").F
dF_pt_B_C_T_H_W = (np.cos(h) * _ - _2) / np.sin(h)
t_F_theta_B_C_T_H_W = cost_B_1_T_1_1 * sint_B_1_T_1_1 * dF_pt_B_C_T_H_W
else: # just JVP
_, t_F_theta_B_C_T_H_W = self.student_F_withT((xt_B_C_T_H_W, t_xt_B_C_T_H_W), (time_B_T, t_time_B_T), condition)JVP计算解决了,打开梯度构造带计算图的,计算切线
,其中r是一个热身系数,记录
用来debug,检查
和g,一旦某个样本中出现NaN的元素,则这个样本的所以元素都被mask掉
F_theta_B_C_T_H_W = self.denoise(xt_B_C_T_H_W, time_B_T, condition, net_type="student").F
F_theta_B_C_T_H_W_sg = F_theta_B_C_T_H_W.clone().detach()
warmup_ratio = min(1.0, iteration / self.config.tangent_warmup)
g_B_C_T_H_W = -cost_B_1_T_1_1 * torch.sqrt(1 - warmup_ratio**2 * sint_B_1_T_1_1**2) * (F_theta_B_C_T_H_W_sg - F_teacher_B_C_T_H_W) - (
warmup_ratio * cost_B_1_T_1_1 * sint_B_1_T_1_1 * xt_B_C_T_H_W + t_F_theta_B_C_T_H_W
)
with torch.no_grad():
df_dt = -cost_B_1_T_1_1 * (F_theta_B_C_T_H_W_sg - F_teacher_B_C_T_H_W) - (sint_B_1_T_1_1 * xt_B_C_T_H_W + t_F_theta_B_C_T_H_W)
nan_mask_g = torch.isnan(g_B_C_T_H_W).flatten(start_dim=1).any(dim=1).view(*g_B_C_T_H_W.shape[:1], 1, 1, 1, 1).expand_as(g_B_C_T_H_W)
nan_mask_F_theta = (
torch.isnan(F_theta_B_C_T_H_W) # 逐元素返回布尔值
.flatten(start_dim=1) # 将第一个维度之后的维度全部展平 (B, C, T, H, W) -> (B, CTHW)
.any(dim=1) # 为每个batch样本检查里面是否有NaN(梯度爆炸、开方负数、数值移除)
.view(*F_theta_B_C_T_H_W.shape[:1], 1, 1, 1, 1)
.expand_as(F_theta_B_C_T_H_W) # 出现了NaN的样本中所有元素都mask
)
nan_mask = nan_mask_g | nan_mask_F_theta
g_B_C_T_H_W[nan_mask] = 0
F_theta_B_C_T_H_W = torch.where(nan_mask, torch.tensor(0.0, device=F_theta_B_C_T_H_W.device), F_theta_B_C_T_H_W)
F_theta_B_C_T_H_W_sg[nan_mask] = 0归一化,计算带计算图的损失
。函数的返回值有来自数据集的
、单步加噪的
、log-normal采样的时间步t、条件、用来debug的
、两个异常样本掩码、来自老师的
和
、来自学生的
和
、加权损失
g_B_C_T_H_W = g_B_C_T_H_W.double() / (g_B_C_T_H_W.double().norm(p=2, dim=(1, 2, 3, 4), keepdim=True) + 0.1)
loss_scm = ((F_theta_B_C_T_H_W - F_theta_B_C_T_H_W_sg - g_B_C_T_H_W) ** 2).sum(dim=(1, 2, 3, 4))
kendall_loss = self.config.loss_scale * loss_scm
x0_teacher_B_C_T_H_W = cost_B_1_T_1_1 * xt_B_C_T_H_W - sint_B_1_T_1_1 * F_teacher_B_C_T_H_W
x0_theta_B_C_T_H_W = cost_B_1_T_1_1 * xt_B_C_T_H_W - sint_B_1_T_1_1 * F_theta_B_C_T_H_W
output_batch = {
"x0": x0_B_C_T_H_W.detach().cpu(),
"xt": xt_B_C_T_H_W.detach().cpu(),
"time": time_B_T.detach().cpu(),
"condition": condition,
"df_dt": df_dt.detach().cpu(),
"nan_mask_g": nan_mask_g.detach().cpu(),
"nan_mask_F_theta": nan_mask_F_theta.detach().cpu(),
"teacher_pred": DenoisePrediction(x0_teacher_B_C_T_H_W.detach().cpu(), F_teacher_B_C_T_H_W.detach().cpu()),
"model_pred": DenoisePrediction(x0_theta_B_C_T_H_W.detach().cpu(), F_theta_B_C_T_H_W.detach().cpu()),
}
return output_batch, kendall_loss分数蒸馏
目标是将学生分布和教师分布
进行匹配,直接匹配干净的高维分布相当困难,曲线救国一下:通过一次前向加噪得到
和边缘分布
,最小化某些反向散度,即
,其中
,变分分数蒸馏VSD和分布匹配蒸馏DMD选择KL散度
,分数一致性蒸馏SiD选择Fisher距离
。
假分数网络
损失梯度一般包含生成器梯度
和分数函数
、
,其中学生分数需要引入一个额外的假分数网络获取,这个网络通过最小化
训练,类似于GANs中的critic,这个假分数网络和学生通过对抗进行协同优化。那如何决定当下该不该更新学生呢?
def is_student_phase(self, iteration: int):
# 没有假分数网络 or 处于预热阶段 or 预热后轮到了学生更新时
return (
self.net_fake_score is None
or iteration < self.config.tangent_warmup
or (iteration - self.config.tangent_warmup) % self.config.student_update_freq == 0 # 1.3B -> 5, 14B -> 10
)
# 学生更新次数的计算如下
def get_effective_iteration(self, iteration: int):
return (
iteration
if self.net_fake_score is None or iteration < self.config.tangent_warmup
else self.config.tangent_warmup + (iteration - self.config.tangent_warmup) // self.config.student_update_freq
)
def get_effective_iteration_fake(self, iteration: int):
return iteration - self.get_effective_iteration(iteration) - 1在训练假分数网络或者后文DMD蒸馏学生时,都会让学生模拟反向多步去噪生成原始数据(区别于真实数据
),不考虑jvp分支
def backward_simulation(self, condition, x_B_C_T_H_W_size, n_steps, with_grad: bool = False):
G_time_B_1 = math.pi / 2 * torch.ones(x_B_C_T_H_W_size[0], 1, device="cuda")
x_B_C_T_H_W = torch.randn(x_B_C_T_H_W_size, device="cuda")
x_B_C_T_H_W = self.sync(x_B_C_T_H_W) # 上下文场景下序列划分
t_traj, x_traj = [G_time_B_1], [x_B_C_T_H_W] # 初始时间步π/2,初始样本标准高斯
for _ in range(n_steps - 1):
# log-normal分布采样新时间,和当前时间取min,确保时间单调递减
G_time_B_1 = torch.minimum(self.draw_training_time_D(x_B_C_T_H_W_size, condition), G_time_B_1)
G_time_B_1 = self.sync(G_time_B_1)
t_traj.append(G_time_B_1)
t_traj.append(0 * G_time_B_1) # 最后一步时间为0,确保反向模拟结束在干净数据
for step, (t_cur_B_1, t_next_B_1) in enumerate(zip(t_traj[:-1], t_traj[1:])):
context_fn = torch.enable_grad if with_grad and step == n_steps - 1 else torch.no_grad # 只有在最后一步去噪开梯度
with context_fn():
x_B_C_T_H_W = self.denoise(x_B_C_T_H_W, t_cur_B_1, condition, net_type="student").x0.float()
if step < n_steps - 1:
x_B_C_T_H_W = torch.cos(rearrange(t_next_B_1, "b t -> b 1 t 1 1")) * x_B_C_T_H_W + torch.sin(
rearrange(t_next_B_1, "b t -> b 1 t 1 1")
) * self.sync(torch.randn_like(x_B_C_T_H_W))
x_traj.append(x_B_C_T_H_W.detach())
return x_B_C_T_H_W, (t_traj, x_traj)让学生模拟的去噪步数(假分数网络的有效更新次数 % 4)就是1~4反复设置,每次得到后,还是log-normal采样的时间步t,单步加噪得到
,交给假分数网络输出
,计算损失
,像普通的mse。
蒸馏代码
和训练假分数网络时一样的获取的流程
def _student_dmd_step(self, ctx, iteration):
log.debug(f"Student update {iteration} (DMD)")
x0_B_C_T_H_W, condition, uncondition = ctx
# 学生的有效更新次数 % 4
num_simulation_steps_fake = self.get_effective_iteration(iteration) % self.config.max_simulation_steps_fake + 1
G_x0_theta_B_C_T_H_W, _ = self.backward_simulation(condition, x0_B_C_T_H_W.size(), num_simulation_steps_fake, with_grad=True)
D_time_B_T = self.draw_training_time_D(x0_B_C_T_H_W.size(), condition)
epsilon_B_C_T_H_W = torch.randn(x0_B_C_T_H_W.size(), device="cuda")
D_time_B_T, epsilon_B_C_T_H_W = self.sync(D_time_B_T, epsilon_B_C_T_H_W)
D_time_B_1_T_1_1 = rearrange(D_time_B_T, "b t -> b 1 t 1 1")
D_xt_theta_B_C_T_H_W = torch.cos(D_time_B_1_T_1_1) * G_x0_theta_B_C_T_H_W + torch.sin(D_time_B_1_T_1_1) * epsilon_B_C_T_H_W让假分数网络和老师分别获取它们认为的原始数据和
,算自适应尺度
(为每个样本算所有元素的平均值),构造分布匹配梯度
,本质是对
的近似,然后构造损失
,希望学生的更新能沿着-g的方向,努力减少分布差距。
with torch.no_grad():
x0_theta_fake_B_C_T_H_W = self.denoise(D_xt_theta_B_C_T_H_W, D_time_B_T, condition, net_type="fake_score").x0
with torch.no_grad():
x0_theta_teacher_B_C_T_H_W = self.denoise(D_xt_theta_B_C_T_H_W, D_time_B_T, condition, net_type="teacher").x0
if self.config.teacher_guidance > 0.0:
x0_theta_teacher_B_C_T_H_W_uncond = self.denoise(D_xt_theta_B_C_T_H_W, D_time_B_T, uncondition, net_type="teacher").x0
x0_theta_teacher_B_C_T_H_W = x0_theta_teacher_B_C_T_H_W + self.config.teacher_guidance * (
x0_theta_teacher_B_C_T_H_W - x0_theta_teacher_B_C_T_H_W_uncond
)
with torch.no_grad():
weight_factor = (
torch.abs(G_x0_theta_B_C_T_H_W.double() - x0_theta_teacher_B_C_T_H_W.double()).mean(dim=[1, 2, 3, 4], keepdim=True).clip(min=0.00001)
)
grad_B_C_T_H_W = (x0_theta_fake_B_C_T_H_W.double() - x0_theta_teacher_B_C_T_H_W.double()) / weight_factor
loss_dmd = (G_x0_theta_B_C_T_H_W.double() - (G_x0_theta_B_C_T_H_W.double() - grad_B_C_T_H_W).detach()) ** 2
loss_dmd[torch.isnan(loss_dmd).flatten(start_dim=1).any(dim=1)] = 0
loss_dmd = loss_dmd.sum(dim=(1, 2, 3, 4))
kendall_loss = self.config.loss_scale_dmd * loss_dmd
output_batch = {
"G_x0": G_x0_theta_B_C_T_H_W.detach().cpu(),
"D_xt": D_xt_theta_B_C_T_H_W.detach().cpu(),
"D_time": D_time_B_T.detach().cpu(),
"x0_theta_fake": x0_theta_fake_B_C_T_H_W.detach().cpu(),
"x0_theta_teacher": x0_theta_teacher_B_C_T_H_W.detach().cpu(),
}
return output_batch, kendall_loss总体损失
sCM 让图像更清晰了,但在精细细节(提示词描述的文字细节,在生成的手表图片中看不清)和视频时序一致性(生成的视频中物体莫名穿透)上存在根本缺陷,尤其在蒸馏场景下会导致严重的视觉失真,而且这些问题无法通过简单增大模型规模解决。这里在长跳一致性上引入基于分数的正则项,通过反向散度解决sCM的质量问题,得到rCM。考虑到SiD在T2I和T2V任务上并未展现出明显的优势,所以采用更省内存的DMD,最终的rCM目标为,选择
。
仔细观察两类蒸馏的方案的损失函数,似乎都是类似于的形式,区别于直接回归目标值,这里学习的是“更新方向”,其中g表示模型输出a在某条理想演化轨迹上的切向量,即
,
是某个“演化坐标”,
的含义可以是原始数据、分数、噪声、速度场,选蒸馏起来稳定的那个,
是
的关闭计算图的版本、ema版本或者旧参数的一份快照,w决定了每一步让学生沿方向g走多远,应和g的物理量纲、噪声尺度、局部曲率、训练阶段相匹配。
在一致性蒸馏中,采用输出,希望跨时间一致,故选择
;在分布匹配蒸馏中,采用学生的模拟反向结果
,希望让生成分布靠近教师分布,演化坐标不是时间,而是在样本空间中沿分数流移动,故选择
。
下面是交替训练+双损失调度器,预热阶段只返回sCM的closure,过后训练学生时返回sCM和DMD两个closure,训练假分数网络时仅critic一个:
def training_step_closures(self, data_batch, iteration: int):
_, x0_B_C_T_H_W, condition, uncondition = self.get_data_and_condition(data_batch)
if self.is_student_phase(iteration):
self.net.train().requires_grad_(True)
if self.net_fake_score:
self.net_fake_score.eval().requires_grad_(False)
# 学生阶段一个iteration可能含多个closure(sCM和DMD),全局通过_make_student_ctx只做一次 sync,避免重复同步
ctx = self._make_student_ctx(x0_B_C_T_H_W, condition, uncondition, iteration)
if self.config.loss_scale > 0:
yield "scm", lambda: self._student_scm_step(ctx, iteration)
if self.net_fake_score and iteration > self.config.tangent_warmup and self.config.loss_scale_dmd > 0:
yield "dmd", lambda: self._student_dmd_step(ctx, iteration)
else:
self.net.eval().requires_grad_(False)
# 假分数网络中是单一路径,函数内部直接 sync 即可
if self.net_fake_score:
self.net_fake_score.train().requires_grad_(True)
yield "critic", lambda: self.training_step_critic(x0_B_C_T_H_W, condition, uncondition, iteration)工程细节
imaginaire 是一个由 NVIDIA 开发和维护的 PyTorch 开源库,可以理解为一个专门用于“图像和视频生成”研究的高级工具箱,包含了大模型训练的基本函数,包括数据并行(DDP/FSDP)、模型权重平均(EMA)、混合精度训练(fp16/bf16)。
前面说过,全微分可以用内置的jvp计算,但是原生并不支持大规模训练设置,所以这里要做一些兼容:
-
FlashAttention-2有效减少内存开销、提升吞吐,这里开发了一种Triton核,将JVP集成到FlashAttention-2伴随分块的前向运算;
-
FSDP(全分片数据并行)将模型划分到不同GPU,减少内存占用,这里重构网络,在每一层都执行JVP,即每一层在执行标准前向的同时接收切线输入,并产生切线输出,只要不把层内部拆开,就能兼容;
-
针对形状为[B, H, L, C]的输入张量,P个GPU,CP(上下文并行)会在序列维度L进行切分,使能在长输入上的训练,在Ulysses策略中,每个GPU先持有形状为[B, H, L/P, C]的QKV分片,通过all-to-all构建[B, H/P, L, C]的QKV,执行本地注意力计算,然后再通过all-to-all还原序列分片,这里只需要对QKV的切线用同样的方式进行划分,并将局部注意力替换成前面实现的FlashAttention-2 JVP核即可。
注意力
普通注意力的实现
def naive_attention_op(q_B_S_H_D, k_B_S_H_D, v_B_S_H_D):
# LLM 自回归生成token序列的推理场景下,可以使用kv cache,只会为最后一个token计算query,最终得到新token(序列长度为1),注意力计算复杂度仅O(s)
# 但在扩散模型中。每次模型前向都需要将当前的样本打成token序列,产生完整形状[b, s, d]的query,最终得到新样本的token序列,复杂度回归原始注意力的O(s^2)
return naive_scaled_dot_product_attention(q_B_S_H_D.transpose(1, 2), k_B_S_H_D.transpose(1, 2), v_B_S_H_D.transpose(1, 2)).transpose(1, 2)
def naive_scaled_dot_product_attention(
query, key, value, attn_mask=None, dropout_p=0.0, is_casual=False, scale=None, enable_gqa=False
# 形状为 [b, h, s, d]
) -> torch.Tensor:
L, S = query.size(-2), key.size(-2) # 获取两个序列长度
scale_factor = 1 / math.sqrt(query.size(-1)) if scale is None else scale
attn_bias = torch.zeros(L, S, dtype=query.dtype, device=query.device)
if is_casual:
assert attn_mask is None
temp_mask = torch.ones(L, S, dtype=torch.bool).tril(diagonal=0)
attn_bias.mask_fill_(temp_mask.logical_not(), float("-inf")) # 上三角位置置为 -inf,直接禁止用户传入掩码
attn_bias.to(query.dtype)
if attn_mask is not None: # 必然不是因果注意力
if attn_mask.dtype == torch.bool:
attn_bias.masked_fill_(attn_mask.logical_not(), float("-inf"))
else:
attn_bias = attn_mask + attn_bias
# grouped query attention
# 当query的头数比key/value多时,需要在head维度将key/value复制到和query一致,才能做矩阵乘
if enable_gqa:
key = key.repeat_interleave(query.size(-3) // key.size(-3), -3)
value = value.repeat_interleave(query.size(-3) // value.size(-3), -3)
attn_weight = query.float() @ key.float().transpose(-2, -1) * scale_factor
attn_weight += attn_bias
attn_weight = torch.softmax(attn_weight, dim=-1).to(query.dtype)
attn_weight = torch.dropout(attn_weight, dropout_p, train=True)
return attn_weight @ value在flash attention中,将沿序列维度进行切块,假设被切成了n块,每块
,当前计算出了新的
(用LLM的kv cache场景做个简单讲解,序列长度大于1同理,也就是所有中间变量和输出的序列维度相应调整即可)。首先初始化两个全局变量
、s = 0和一个全零输出向量
。流式读取每对
,计算
(暂且忽略scale),找出其中的最大值
,记录新的全局最大
,同时为当前块计算
,更新全局指数和
,输出
,全局最大
。遍历完全后补上分母
。
加上JVP运算呢?将SPVO对时间的导数表示成,于是带JVP的运算就是
,根据链式法则,
,
(行向量乘对角矩阵
就是两个行向量
和P逐元素相乘,得到的行向量元素加和得到的数字就是
,也是
),
。
在flash attention的场景下,P和S都不再被显式构造,所有涉及它们的运算同样需要用m迭代更新。依旧是当前计算出了新的,首先初始化三个全局变量
、s = 0、r=0和三个全零输出向量O/A/B 。流式读取每组
,计算
、
,找出
中的最大值
,记录新的全局最大
,同时为当前块计算
,更新全局指数和
,输出
、
,并为当前块计算
,更新
、
,更新全局最大
。遍历完全后补上分母
,组装
。
具体看带jvp分支且用triton优化的flashattention实现:
def torch_attention_op_withT(q_B_S_H_D_withT: TensorWithT, k_B_S_H_D_withT: TensorWithT, v_B_S_H_D_withT: TensorWithT):
q_B_S_H_D, t_q_B_S_H_D = q_B_S_H_D_withT
k_B_S_H_D, t_k_B_S_H_D = k_B_S_H_D_withT
v_B_S_H_D, t_v_B_S_H_D = v_B_S_H_D_withT
# apply是 torch.autograd.Function 的入口,它会创建这个操作对应的 autograd 上下文,调用 forward,构造计算图节点,在反向传播时关联 backward
result_B_H_S_D, t_result_B_H_S_D = _attention.apply(
q_B_S_H_D.transpose(1, 2),
k_B_S_H_D.transpose(1, 2),
v_B_S_H_D.transpose(1, 2),
t_q_B_S_H_D.transpose(1, 2),
t_k_B_S_H_D.transpose(1, 2),
t_v_B_S_H_D.transpose(1, 2),
)
return (result_B_H_S_D.transpose(1, 2), t_result_B_H_S_D.transpose(1, 2).detach())实际上,通过继承torch.autograd.Function,你自定义一个可参与 pytorch 自动求导系统的算子_attention,意味着你需要告诉 pytorch 前向和反向梯度怎么计算,比 nn.Module 更底层,其中当你调用_attention.apply(...)时,会执行 forward,如果的 x.requires_grad=True,pytorch会将这次操作记录在计算图,后续loss.backward() 时会自动调用 backward
前向
class _attention(torch.autograd.Function):
"""
继承torch.autograd.Function这个类说明你在自定义一个可参与 pytorch 自动求导系统的算子
你需要告诉 pytorch 前向和反向梯度怎么计算,比 nn.Module 更底层
当通过 y=Func.apply(x) 调用时,会执行 forward,如果的 x.requires_grad=True,pytorch会将这次操作记录在计算图,
后续 loss.backward() 时会自动调用 backward
Arguments:
q, tq: (batch_size, nheads, seqlen_q, d_qk)
k, tk: (batch_size, nheads, seqlen_kv, d_qk)
v, tv: (batch_size, nheads, seqlen_kv, d_v)
Returns:
o, to: (batch_size, nheads, seqlen_q, d_v)
Backward is only supported when d_qk=d_v.(本是同根生)
"""
@staticmethod
def forward(ctx, q, k, v, tq, tk, tv, sm_scale=None):
is_grad = any(x.requires_grad for x in [q, k, v]) # 任何一个输入需要梯度都会计算梯度
# shape constraints 为了能够矩阵乘,要求批量大小、头数匹配,
# key 和 value 的序列长度要一致,query 和 key 的隐藏维度要一致
assert q.shape[:-2] == k.shape[:-2] and k.shape[:-2] == v.shape[:-2]
assert k.shape[-2] == v.shape[-2] and q.shape[-1] == k.shape[-1]
B, H = q.shape[:-2]
SEQ_LEN_Q, SEQ_LEN_KV = q.shape[-2], k.shape[-2]
HEAD_DIM_QK, HEAD_DIM_V = q.shape[-1], v.shape[-1]
# triton 核只支持下列这些 block-friendly 的维度大小
assert HEAD_DIM_QK in {16, 32, 64, 128, 256}
assert HEAD_DIM_V in {16, 32, 64, 128, 256}
# 要求切线 tensor 和原 tensor 的内存布局一致
assert tq.shape == q.shape and tk.shape == k.shape and tv.shape == v.shape
assert tq.stride() == q.stride() and tk.stride() == k.stride() and tv.stride() == v.stride()
if sm_scale is None:
sm_scale = HEAD_DIM_QK ** (-0.5)
# 预先分配输出张量和切线张量
o = torch.empty((B, H, SEQ_LEN_Q, HEAD_DIM_V), device=q.device, dtype=q.dtype)
to = torch.empty_like(o)
# 全局最大
M = torch.empty((B, H, SEQ_LEN_Q), device=q.device, dtype=torch.float32)把triton涉及的代码摘出来,(triton.cdiv(SEQ_LEN_Q, args["BLOCK_M"]), B * H, 1)是在triton kernel launch中定义执行网格的尺寸,决定了在GPU上总共启动多少个program instance(线程块级任务),沿用了CUDA的执行模型,默认把每个kernel的program instance放在一个三维索引空间中。cdiv是ceiling divide(向上取整),在GPU上启动的总的program数为
,其中
是autotune参数,表示一个program实例一次处理多少个query token
def grid(args):
return (triton.cdiv(SEQ_LEN_Q, args["BLOCK_M"]), B * H, 1)
_attn_fwd[grid](
q, k, v,
tq, tk, tv,
sm_scale,
M,
o, to,
q.stride(0), q.stride(1), q.stride(2), q.stride(3),
k.stride(0), k.stride(1), k.stride(2), k.stride(3),
v.stride(0), v.stride(1), v.stride(2), v.stride(3),
o.stride(0), o.stride(1), o.stride(2), o.stride(3),
B, H,
SEQ_LEN_Q, SEQ_LEN_KV,
HEAD_DIM_QK, HEAD_DIM_V,
)
if is_grad:
ctx.save_for_backward(q, k, v, o, M)
ctx.sm_scale = sm_scale
return o, to前向的triton核实现如下,triton的autotune本质是“运行时自动搜索最快的kernel配置”,下列设置了36种配置,其中除了前文介绍的外,还有每个线程块一次处理的key/value的token数
、每个线程块中的warp数
,
好像是load和compute流水线并行度,具体的不知道了,累累的T.T,在用户设置的["SEQ_LEN_Q", "SEQ_LEN_KV", "HEAD_DIM_QK", "HEAD_DIM_V"]的情况下,选出吞吐率最大的配置(FLOPs/(访存+计算+launch开销))。
线程块(program)是任务单元,SM(streaming multiprocessor)是GPU的硬件执行单元,如果把GPU比做一个工厂,则SM就像一个个车间,shared memory(同一个thread block/triton program内共享的高速缓存)是车间内的公共工作台,warp(32个线程)是工人小组,register(GPU上最快的存储器)是每个工人(线程)随身携带的工具包,occupancy就是一个车间内同时开工的小组数量。
如果一个kernel的GEMM块头太大,即单块计算更密集,launch开销降低,但同时也意味着每组工人需要用更多工具(register),占用更多工作台(shared memory),一个车间里能同时容纳的小组数变少,即occupancy(某个SM上活跃的warps数/硬件决定最大warps数)下降,而GPU依靠大量warp隐藏延迟,当前warp处于等待状态时,其他活跃warp太少可能导致无人可以切换。
configs = [
triton.Config({"BLOCK_M": BM, "BLOCK_N": BN}, num_stages=s, num_warps=w)
for BM in [64, 128]
for BN in [16, 32, 64]
for s in [3, 4, 7]
for w in [4, 8]
]
# 共36种配置
@triton.autotune(configs, key=["SEQ_LEN_Q", "SEQ_LEN_KV", "HEAD_DIM_QK", "HEAD_DIM_V"])
@triton.jit # 本装饰器表示把python kernel编译成GPU kernel
def _attn_fwd(
Q, K, V,
tQ, tK, tV,
sm_scale, # fp32 scalar
LSE, # [B, H, SEQ_LEN_Q] fp32 (natural log) 全局最大?指数和?
O, tO, # [B, H, SEQ_LEN_Q, HEAD_DIM_V]
stride_qb, stride_qh, stride_qm, stride_qd,
stride_kb, stride_kh, stride_kn, stride_kd,
stride_vb, stride_vh, stride_vn, stride_vd,
stride_ob, stride_oh, stride_om, stride_od, # tensor各维步长,用于访存
# 批量大小、头数、query序列长度、key/value序列长度、query/key的头维度、value的头维度
B: tl.constexpr, H: tl.constexpr,
SEQ_LEN_Q: tl.constexpr, SEQ_LEN_KV: tl.constexpr,
HEAD_DIM_QK: tl.constexpr, HEAD_DIM_V: tl.constexpr,
# 每个program一次实例处理的query序列长度、一次加载的key/value序列长度
BLOCK_M: tl.constexpr, BLOCK_N: tl.constexpr,
):
# program网格的形状为[query组数, B*H, 1]
pid_m = tl.program_id(0).to(tl.int64) # query block id
pid_bh = tl.program_id(1).to(tl.int64) # fused batch-head
off_b = pid_bh // H
off_h = pid_bh % H
# offsets
offs_m = pid_m * BLOCK_M + tl.arange(0, BLOCK_M) # [BM]当前处理哪些 query 行
offs_n = tl.arange(0, BLOCK_N) # [BN]key 的内部列号
offs_dq = tl.arange(0, HEAD_DIM_QK) # [Dq]d_key
offs_dv = tl.arange(0, HEAD_DIM_V) # [Dv]d_value
# base pointers for this (b, h)
q_base = off_b * stride_qb + off_h * stride_qh
k_base = off_b * stride_kb + off_h * stride_kh
v_base = off_b * stride_vb + off_h * stride_vh
o_base = off_b * stride_ob + off_h * stride_oh
# Q / tQ: [BM, Dq] 读取
Q_ptrs = Q + q_base + offs_m[:, None] * stride_qm + offs_dq[None, :] * stride_qd
tQ_ptrs = tQ + q_base + offs_m[:, None] * stride_qm + offs_dq[None, :] * stride_qd
m_mask = offs_m < SEQ_LEN_Q # 防止最后一块越界
q = tl.load(Q_ptrs, mask=m_mask[:, None], other=0.0)
tq = tl.load(tQ_ptrs, mask=m_mask[:, None], other=0.0)
# streaming softmax stats (base-2)
m_i = tl.full([BLOCK_M], -float("inf"), dtype=tl.float32) # row max in log2 domain
l_i = tl.zeros([BLOCK_M], dtype=tl.float32) # row sum of exp2
# JVP-specific accumulators (Algorithm 2: O, A, r, B)
o_i = tl.zeros([BLOCK_M, HEAD_DIM_V], dtype=tl.float32) # O~ (unnormalized)
A_i = tl.zeros([BLOCK_M, HEAD_DIM_V], dtype=tl.float32) # A~ = P~ tV
B_i = tl.zeros([BLOCK_M, HEAD_DIM_V], dtype=tl.float32) # B~ = H~ V
r_i = tl.zeros([BLOCK_M], dtype=tl.float32) # r~ = rowsum(H~)不好算,改成
,先算
,那么
,
qk_scale_log2 = sm_scale * 1.4426950408889634 # scale for exp2
# loop over K/V blocks
for start_n in range(0, SEQ_LEN_KV, BLOCK_N):
start_n = tl.multiple_of(start_n, BLOCK_N)
n_idx = start_n + offs_n
n_mask = n_idx < SEQ_LEN_KV
# K / tK in transposed tile layout: [Dq, BN]
K_ptrs = K + k_base + n_idx[None, :] * stride_kn + offs_dq[:, None] * stride_kd
tK_ptrs = tK + k_base + n_idx[None, :] * stride_kn + offs_dq[:, None] * stride_kd
k = tl.load(K_ptrs, mask=n_mask[None, :], other=0.0)
tk = tl.load(tK_ptrs, mask=n_mask[None, :], other=0.0)
# scores in log2 domain: qk = (QK^T) * sm_scale / ln2
qk = tl.dot(q, k).to(tl.float32) * qk_scale_log2
qk = tl.where(n_mask[None, :], qk, -float("inf"))
# update streaming max + exp2 sums (FlashAttention-2 core)
m_ij = tl.maximum(m_i, tl.max(qk, axis=1))
p = tl.math.exp2(qk - m_ij[:, None]) # P~ (unnormalized)
l_ij = tl.sum(p, axis=1)
alpha = tl.math.exp2(m_i - m_ij) # rescale factor
l_i = l_i * alpha + l_ij
o_i = o_i * alpha[:, None]
A_i = A_i * alpha[:, None]
B_i = B_i * alpha[:, None]
r_i = r_i * alpha
# V / tV: [BN, Dv]
V_ptrs = V + v_base + n_idx[:, None] * stride_vn + offs_dv[None, :] * stride_vd
tV_ptrs = tV + v_base + n_idx[:, None] * stride_vn + offs_dv[None, :] * stride_vd
v = tl.load(V_ptrs, mask=n_mask[:, None], other=0.0)
tv = tl.load(tV_ptrs, mask=n_mask[:, None], other=0.0)
# ---- JVP pieces ----
# tS = (tQ K^T + Q tK^T) * sm_scale
tS = (tl.dot(tq, k).to(tl.float32) + tl.dot(q, tk).to(tl.float32)) * sm_scale
tS = tl.where(n_mask[None, :], tS, 0.0)
# H~ = P~ ⊙ tS (use unnormalized P~)
Htilde = p * tS
r_i += tl.sum(Htilde, axis=1)
# accumulate O~, A~, B~ (Algorithm 2)
p = p.to(v.dtype)
Htilde = Htilde.to(v.dtype)
o_i = tl.dot(p, v, o_i)
A_i = tl.dot(p, tv, A_i)
B_i = tl.dot(Htilde, v, B_i)
m_i = m_ij
# ---- epilogue ----
# O = O~ / l, LSE = (m + log2(l)) * ln2
# tO = (A~ + B~ - diag(r) O) / l
inv_l_i = 1.0 / l_i
O_i = o_i * inv_l_i[:, None]
A_i = A_i * inv_l_i[:, None]
B_i = B_i * inv_l_i[:, None]
mu_i = r_i * inv_l_i
tO_i = A_i + B_i - mu_i[:, None] * O_i
lse = (m_i + tl.math.log2(l_i)) * 0.6931471805599453 # 数值是ln2
# store
O_ptrs = O + o_base + offs_m[:, None] * stride_om + offs_dv[None, :] * stride_od
tO_ptrs = tO + o_base + offs_m[:, None] * stride_om + offs_dv[None, :] * stride_od
LSE_ptrs = LSE + pid_bh * SEQ_LEN_Q + offs_m
tl.store(O_ptrs, O_i.to(O.type.element_ty), mask=m_mask[:, None])
tl.store(tO_ptrs, tO_i.to(tO.type.element_ty), mask=m_mask[:, None])
tl.store(LSE_ptrs, lse, mask=m_mask)反向
当我们执行反向传播时又会发生什么?看看自定义算子_attention的反向实现,它并没有自己重写triton kernel,而是直接调用官方的flash-attn库的CUDA backward kernel
from flash_attn.flash_attn_interface import _flash_attn_backward, _flash_attn_varlen_backward
# 给官方flash-attn kernel做一层python适配包装器
def _make_flash_bwd_caller(flash_bwd_fn):
params = _get_param_names(flash_bwd_fn) # 识别底层函数支持的参数
def call( # 获取用户调用时传入参数
*pos_args,
dropout_p=0.0,
softmax_scale=None,
causal=False,
window_size=(-1, -1),
softcap=0.0,
alibi_slopes=None,
deterministic=False,
**extra_kwargs,
):
ws_left, ws_right = window_size
kw = dict(
dropout_p=dropout_p,
softmax_scale=softmax_scale,
causal=causal,
window_size=window_size,
window_size_left=ws_left,
window_size_right=ws_right,
softcap=softcap,
alibi_slopes=alibi_slopes,
deterministic=deterministic,
)
kw.update(extra_kwargs) # 准备所有候选参数
kw = {k: v for k, v in kw.items() if k in params} # 过滤掉底层不支持的参数
return flash_bwd_fn(*pos_args, **kw)
return call
_flash_bwd = _make_flash_bwd_caller(_flash_attn_backward)
_flash_varlen_bwd = _make_flash_bwd_caller(_flash_attn_varlen_backward)当qk序列长度一致时,调官方 flash-attn backward kernel
@staticmethod
def backward(ctx, dout, *args):
q, k, v, out, softmax_lse = ctx.saved_tensors # 读取前向时保存的数据
# 要求 QKV 的 head dim 都要一致
assert q.shape[-1] == k.shape[-1] and k.shape[-1] == v.shape[-1], "Backward not supported with different headdim."
# flash_attn uses the shape (batch_size, seqlen, nheads, headdim)
# torch.nn.functional.scaled_dot_product_attention and this implementation use (batch_size, nheads, seqlen, headdim)
if q.shape[-2] == k.shape[-2]:
dq, dk, dv = torch.empty_like(q), torch.empty_like(k), torch.empty_like(v)
_flash_bwd( # 这又把序列长度放在头数之前了
dout.transpose(1, 2),
q.transpose(1, 2),
k.transpose(1, 2),
v.transpose(1, 2),
out.transpose(1, 2),
softmax_lse,
dq.transpose(1, 2),
dk.transpose(1, 2),
dv.transpose(1, 2),
dropout_p=0.0,
softmax_scale=ctx.sm_scale,
causal=False,
)在官方 flash-attn backward kernel的反向内部具体在做什么呢?已知上游梯度dO,为O=PV反向,计算、
,然后为
反向,有
(矩阵运算前可以广播形状),再为
反向,计算
、
。
在应对cross-attention或者说qk序列长度不一致时又有什么特别的呢?需事先把qkv的批量和序列维度展平,然后调用_flash_varlen_bwd,其内部和self-attention backward 一样,只是支持不同长度,最后恢复形状。自注意力中QKV来自同一序列,S是方阵,而当Q和KV的序列长度不同时,
按query token并行,而计算
按key token并行,需要两套tile策略。前向时输入(q, k, v, tq, tk, tv, sm_scale)七个数值,反向时就得返回对应梯度(dq, dk, dv, None, None, None, None),JVP切线张量(tangent)不是训练参数,仅供forward-mode autodiff使用:
else:
unpad_fn, lse_unpad_fn, pad_fn, cu_seqlens_q, cu_seqlens_k, max_seqlen_q, max_seqlen_k = generate_qkv(q, k, v)
q_unpad, k_unpad, v_unpad = unpad_fn(q), unpad_fn(k), unpad_fn(v)
dq, dk, dv = torch.empty_like(q_unpad), torch.empty_like(k_unpad), torch.empty_like(v_unpad)
_flash_varlen_bwd(
unpad_fn(dout),
q_unpad,
k_unpad,
v_unpad,
unpad_fn(out),
lse_unpad_fn(softmax_lse),
dq,
dk,
dv,
cu_seqlens_q,
cu_seqlens_k,
max_seqlen_q,
max_seqlen_k,
dropout_p=0.0,
softmax_scale=ctx.sm_scale,
causal=False,
)
dq, dk, dv = pad_fn(dq), pad_fn(dk), pad_fn(dv)
return dq, dk, dv, None, None, None, None分布式设置
pytorch fsdp的hsdp (hybrid sharding data parallel)混合分片技术:它会根据当前分布式训练的总GPU数量,构建一个device mesh(设备网格),将设备分成两个维度,复制维(replicate)(不同副本之间做纯数据并行)和分片维(shard)(模型参数在组内做分片数据并行),默认情况下每个GPU处理的batch size就是1
def hsdp_device_mesh(replica_group_size=None, sharding_group_size=None, device=None):
"""
Initializes a device mesh for use with Hybrid Sharding strategy in FSDP (HSDP) training.
This function requires explicit sizes for replica and sharding groups to accommodate models
whose GPU fit is unknown, providing flexibility in distributed training setups.
这个函数希望用户能明确提供 replica_group_size 和 sharding_group_size 两个参数,因为它并不清楚模型到底能放进多少张 GPU 中
Args:
replica_group_size (int): The size of each replica group. Must be provided to ensure
the model fits within the available resources. 数据并行副本数
sharding_group_size (int): The size of each sharding group that the model can fit. Must be provided to
ensure the correct distribution of model parameters. 模型会在多少个设备之间切分
device (str, optional): The device to use (e.g., "cuda:0"). If None, defaults to "cuda"
with the local rank as the device index.
Returns:
A device mesh object compatible with FSDP.
Raises:
未提供组大小或者 GPU 数不能被组大小整除都会报错(但实际上没提供的话会设置默认值 min(world_size, 8))
ValueError: If replica_group_size or sharding_group_size are not provided, or if the
world size is not evenly divisible by the sharding group size.
RuntimeError: If a valid device mesh cannot be created.
Usage:
If your model fits on 4 GPUS, and you have 3 nodes of 8 GPUs, then:
Sharding_Group_Size = 4
Replica_Groups_Size = (24 total gpus, 4 per sharding group) = 6 Replica Groups
>>> device_mesh = initialize_device_mesh(replica_group_size, sharding_group_size)
>>> sharded_model = FSDP(model, device_mesh=device_mesh, ...)
"""
world_size = distributed.get_world_size()
if sharding_group_size is None:
sharding_group_size = min(world_size, 8)
sharding_group_size = min(sharding_group_size, world_size)
if replica_group_size is None:
replica_group_size = world_size // sharding_group_size
device = device or "cuda"
if world_size % sharding_group_size != 0:
raise ValueError(f"World size {world_size} is not evenly divisible by sharding group size {sharding_group_size}.")
# 如果world_size=8,用户设置的sharding_group_size=2,replica_group_size=2,那么设备网格就只会覆盖 4 张 GPU
if (world_size // sharding_group_size) % replica_group_size != 0:
raise ValueError(f"The calculated number of replica groups is not evenly divisible by " f"replica_group_size {replica_group_size}.")
device_mesh = init_device_mesh(device, (replica_group_size, sharding_group_size), mesh_dim_names=("replicate", "shard"))
if device_mesh is None:
raise RuntimeError("Failed to create a valid device mesh.")
log.critical(f"Device mesh initialized with replica group size {replica_group_size} and sharding group size {sharding_group_size}")
return device_mesh
# 复制维会通过广播保证参数一致
from imaginaire.utils.misc import get_local_tensor_if_DTensor
def broadcast_dtensor_model_states(model: torch.nn.Module, mesh: DeviceMesh):
"""Broadcast model states from replicate mesh's rank 0."""
replicate_group = mesh.get_group("replicate")
all_ranks = dist.get_process_group_ranks(replicate_group) # 拿到group内所有rank
if len(all_ranks) == 1:
return
for _, tensor in itertools.chain(model.named_parameters(), model.named_buffers()):
# Get src rank which is the first rank in each replication group
src_rank = all_ranks[0]
# Broadcast the local tensor
local_tensor = get_local_tensor_if_DTensor(tensor) # 取当前GPU上属于自己的那一块
dist.broadcast(
local_tensor,
src=src_rank,
group=replicate_group,
)结合HSDP进行模型初始化
# 在分布式+低显存条件下安全快速初始化超大模型
def build_net(self, net_dict: LazyDict):
init_device = "meta" # pytorch的空设备,不分配显存、不存参数、只创建“结构”,后续再分布式加载权重
with misc.timer("Creating PyTorch model"):
with torch.device(init_device):
net = lazy_instantiate(net_dict) # 根据 net_dict 的配置创建模型结构
if self.fsdp_device_mesh: # 如果启用FSDP分布式切片
# 模块级shard,将每一层参数切分到不同 GPU(把每个 parameter 变成 DTensor)
net.fully_shard(
mesh=self.fsdp_device_mesh,
mp_policy=MixedPrecisionPolicy(reduce_dtype=torch.float32)
)
# 对整个模型执行逻辑做控制,做全局 wrapper
net = fully_shard(
net,
mesh=self.fsdp_device_mesh,
mp_policy=MixedPrecisionPolicy(reduce_dtype=torch.float32), # 梯度reduce采用FP32
reshard_after_forward=True # forward完立刻把参数再切回去
)
# 真正分配显存的地方(meta-》cuda)
with misc.timer("meta to cuda and broadcast model states"):
net.to_empty(device="cuda") # 不同于.to("cuda"),它在GPU上分配tensor但不复制数据
net.init_weights() # 随机初始化权重
if self.fsdp_device_mesh:
broadcast_dtensor_model_states(net, self.fsdp_device_mesh) # 同步 shard,保证所有GPU权重来自同一个初始化
for name, param in net.named_parameters():
assert isinstance(param, DTensor), f"param should be DTensor, {name} got {type(param)}"
return net
def set_up_model(self):
config = self.config
with misc.timer("Creating PyTorch model and ema if enabled"):
self.conditioner = lazy_instantiate(config.conditioner)
assert sum(p.numel() for p in self.conditioner.parameters() if p.requires_grad) == 0, "conditioner should not have learnable parameters" # 条件器不参与训练
self.net, self.net_teacher = self.build_net(config.net), self.build_net(config.net_teacher)
self.net_fake_score = self.build_net(config.net_fake_score) if config.net_fake_score else None
if config.net_fake_score:
assert config.loss_scale_dmd > 0
if config.teacher_ckpt:
# load teacher checkpoint
self.load_ckpt_to_net(self.net_teacher, config.teacher_ckpt)
self.net.load_state_dict(self.net_teacher.state_dict(), strict=False)
if self.net_fake_score: # 假分数网络复制教师权重做初始化
self.net_fake_score.load_state_dict(self.net_teacher.state_dict())
self.net_teacher.requires_grad_(False)
self._param_count = count_params(self.net, verbose=False) # 统计参数量
# Enable/disable CP once; all CP comm/split/gather happens inside net.forward now.
cp_group = self.get_context_parallel_group()
if cp_group is not None and cp_group.size() > 1:
self.net.enable_context_parallel(cp_group)
self.net_teacher.enable_context_parallel(cp_group)
if self.net_fake_score:
self.net_fake_score.enable_context_parallel(cp_group)
else:
self.net.disable_context_parallel()
self.net_teacher.disable_context_parallel()
if self.net_fake_score:
self.net_fake_score.disable_context_parallel()
if config.ema.enabled:
self.net_ema = self.build_net(config.net)
self.net_ema.requires_grad_(False)
if self.fsdp_device_mesh:
self.net_ema_worker = DTensorFastEmaModelUpdater()
else:
self.net_ema_worker = FastEmaModelUpdater()
s = config.ema.rate
self.ema_exp_coefficient = np.roots([1, 7, 16 - s**-2, 12 - s**-2]).real.max()
self.net_ema_worker.copy_to(src_model=self.net, tgt_model=self.net_ema)
torch.cuda.empty_cache()
ema更新
滑动平均更新公式中的系数
可能是认为设定的类似0.999的数值,但这里会通过幂函数随训练动态变化,训练开始时几乎为0,最后靠近1,几乎不变:
PowerEMAConfig: EMAConfig = EMAConfig(
enabled=True,
rate=0.10,
iteration_shift=0,
)
...
s = config.ema.rate
self.ema_exp_coefficient = np.roots([1, 7, 16 - s**-2, 12 - s**-2]).real.max()
...
def ema_beta(self, iteration: int) -> float:
"""
Calculate the beta value for EMA update.
weights = weights * beta + (1 - beta) * new_weights
Args:
iteration (int): Current iteration number. 迭代数,在 0~1000 之间
Returns:
float: The calculated beta value.
"""
iteration = iteration + self.config.ema.iteration_shift
if iteration < 1:
return 0.0
return (1 - 1 / (iteration + 1)) ** (self.ema_exp_coefficient + 1)用户设置超参s,求解三阶方程的最大根
,借此调节ema系数
,注意这里的t是迭代轮数,s的默认设置是0.1,对应
。更新的实现如下
# 在DTensor 场景下维护 EMA(指数滑动平均)模型参数
class DTensorFastEmaModelUpdater:
"""
Similar as FastEmaModelUpdater
"""
def __init__(self):
# Flag to indicate whether the cache is taken or not. Useful to avoid cache overwrite
self.is_cached = False
def copy_to(self, src_model: torch.nn.Module, tgt_model: torch.nn.Module) -> None:
with torch.no_grad(): # 将源模型参数逐个复制到另一个模型(要求参数顺序匹配)
for tgt_params, src_params in zip(tgt_model.parameters(), src_model.parameters()):
# 得先取出分布式张量(DTensor)的数据 tensor
tgt_params.to_local().data.copy_(src_params.to_local().data)
@torch.no_grad()
def update_average(self, src_model: torch.nn.Module, tgt_model: torch.nn.Module, beta: float = 0.9999) -> None:
target_list = []
source_list = []
for tgt_params, src_params in zip(tgt_model.parameters(), src_model.parameters()):
assert tgt_params.dtype == torch.float32, f"EMA model only works in FP32 dtype, got {tgt_params.dtype} instead." # 注意!这个 EMA 更新器要求 EMA 模型参数必须是 FP32
target_list.append(tgt_params.to_local())
source_list.append(src_params.to_local().data) # 先准备tensor列表
torch._foreach_mul_(target_list, beta) # 滑动平均更新
torch._foreach_add_(target_list, source_list, alpha=1.0 - beta)
@torch.no_grad() # 缓存当前参数
def cache(self, parameters: Any, is_cpu: bool = False) -> None:
assert self.is_cached is False, "EMA cache is already taken. Did you forget to restore it?"
device = "cpu" if is_cpu else "cuda"
self.collected_params = [param.to_local().clone().to(device) for param in parameters] # 当前所有参数本地shard的一份独立快照
self.is_cached = True
@torch.no_grad() # 将缓存恢复回去
def restore(self, parameters: Any) -> None:
assert self.is_cached, "EMA cache is not taken yet."
for c_param, param in zip(self.collected_params, parameters, strict=False):
param.to_local().copy_(c_param.data.type_as(param.data))
self.collected_params = []
# Release the cache after we call restore
self.is_cached = False每次到学生训练时,都会事先调用更新ema,具体实际在参数更新后,梯度清零前
def on_before_zero_grad(self, optimizer: torch.optim.Optimizer, scheduler: torch.optim.lr_scheduler.LRScheduler, iteration: int) -> None:
if self.config.ema.enabled and self.is_student_phase(iteration):
ema_beta = self.ema_beta(self.get_effective_iteration(iteration))
self.net_ema_worker.update_average(self.net, self.net_ema, beta=ema_beta)训练开始时就有self.net_ema.to(dtype=torch.float32)。如果我没理解错的话,ema版本参数似乎只用于定期评估训练效果。
实验
架构支持FSDP2、Ulysses CP、可选激活值检查点(SAC);训练时在用rCM损失优化学生和用流匹配损失更新假分数网络之间迭代,两个网络都用教师权重做初始化;结合cfg蒸馏;采用全参微调而不是LoRA,这很考验rCM的稳定性和性能。
用GenEval评估在应对复杂组合性提示词下T2I模型的表现,考察数量计数、空间关系、属性绑定的能力;用VBench评估视频生成时的运动质量和语义对齐。用模型调用次数NFE作为推理效率的量化指标,对于视频模型同时还会报告在单张H100上设置批量为1,涵盖扩散采样和VAE解码阶段的,每秒在帧数上的吞吐(FPS)。结果就是一堆的不错啦~
DMD2在假分数网络上加了一个分支作为判别器,提取中间特征,再拿一个可学习token去查询这些中间特征,判断这个图片/视频是真是假,通过加入这样的GAN损失,让学生能生成更真实的数据,但GAN容易模式坍塌,即模型找到最容易骗过判别器的模式,便会反复生成类似的内容,多样性下降。
视屏分辨率对应表:
"480p": {
"1:1": (640, 640), "4:3": (640, 480), "3:4": (480, 640),
"16:9": (832, 480), "9:16": (480, 832)
},
"720p": {
"1:1": (960, 960), "4:3": (960, 720), "3:4": (720, 960),
"16:9": (1280, 720), "9:16": (720, 1280)
},碎碎念
当我们希望模型生成的内容兼具质量和多样性时,组合“模式检索”和“模式覆盖”的损失项的确是个不错的考量。我们复现了论文中 Wan-t2v模型的蒸馏,也像作者说的那样把 Wan-t2-14b模型蒸馏后权重增量加到 I2V 模型上,验证生成效果就像作者说的那样确实不错(很依赖提示词增强),很感谢大佬们的工作。一致性模型有诸多好处,比如迭代去噪加噪,可以支撑任意去噪步数,在采样过程中引入随机性,但 jvp的实现复杂,需要各种兼容,存在很多造成训练不稳定的风险,似乎现在主流的生视频模型蒸馏框架用的是 DMD/2。我想尝试着把 rCM 蒸馏迁移到论文中实现了的以外的模型上,希望能成功💪

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 11
11 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)