改进 Skill Creator:如何测试、度量与优化 Agent Skills
引言:为什么 Skill 作者需要测试工具?
Anthropic 在 2025 年 10 月推出了 Agent Skills,让团队可以将自己的工作流程编码进 Claude,使其在特定场景下自动触发并执行任务。但随着使用推广,一个核心问题逐渐浮现:
大多数 Skill 作者是领域专家,而不是工程师。
他们懂得自己的业务流程,知道 Claude 应该做什么,却没有工具去验证:
- 换了新版模型之后,skill 还能正常运行吗?
- 用户发出的提示词,skill 会在正确的时机被触发吗?
- 我修改了 skill 的描述或指令之后,它真的变好了吗?
过去,这些问题只能靠"感觉"或人工反复试验来回答。这次更新的目标,是把软件工程中成熟的测试与迭代方法带入 skill 创作——而且不需要写一行代码。
一、两类 Skill,各有侧重
在讲新功能之前,需要先理解 Skill 的两种基本形态,因为它们需要测试的原因不同。
能力扩展型(Capability Uplift)
这类 skill 的作用是让 Claude 做到它原本做不到或做不稳定的事。
典型例子是文档创建类 skill。Claude 的基础模型在处理复杂的 PDF 表单填写时表现不稳定,而一个精心设计的 skill 可以将特定的处理技巧编码进去,产出比单纯用提示词更可靠、更高质量的结果。
这类 skill 的测试重点:随着模型能力提升,skill 是否已经变得多余?
偏好编码型(Encoded Preference)
这类 skill 的作用不是弥补模型能力的不足,而是将团队特有的工作流程固化进 Claude 的行为。
例如:
- 按照公司法务标准逐条审查 NDA 合同的 skill
- 每周从多个数据源(MCP)汇总数据并起草周报的 skill
Claude 本身有能力完成每个步骤,但 skill 负责确保它按照你们团队的特定顺序和标准来执行,而不是自由发挥。
这类 skill 的测试重点:流程是否真的忠实于实际工作流?
一句话总结:测试,让一个"看起来能用"的 skill 变成一个"确定能用"的 skill。
二、Evals:给 Skill 写测试用例
什么是 Evals?
Evals(评估用例)是 Skill Creator 新增的核心能力。类比软件开发中的单元测试:你定义一些测试场景,描述"好的输出"应该是什么样子,然后让系统自动验证 skill 是否通过。
具体来说,一个 eval 包含:
- 测试提示词:模拟真实用户会发出的请求
- 附带文件(可选):如果任务涉及文档处理
- 成功标准:描述期望的输出结果或行为
真实案例:PDF Skill 的问题定位
下图展示了 PDF skill 修复前后的对比:
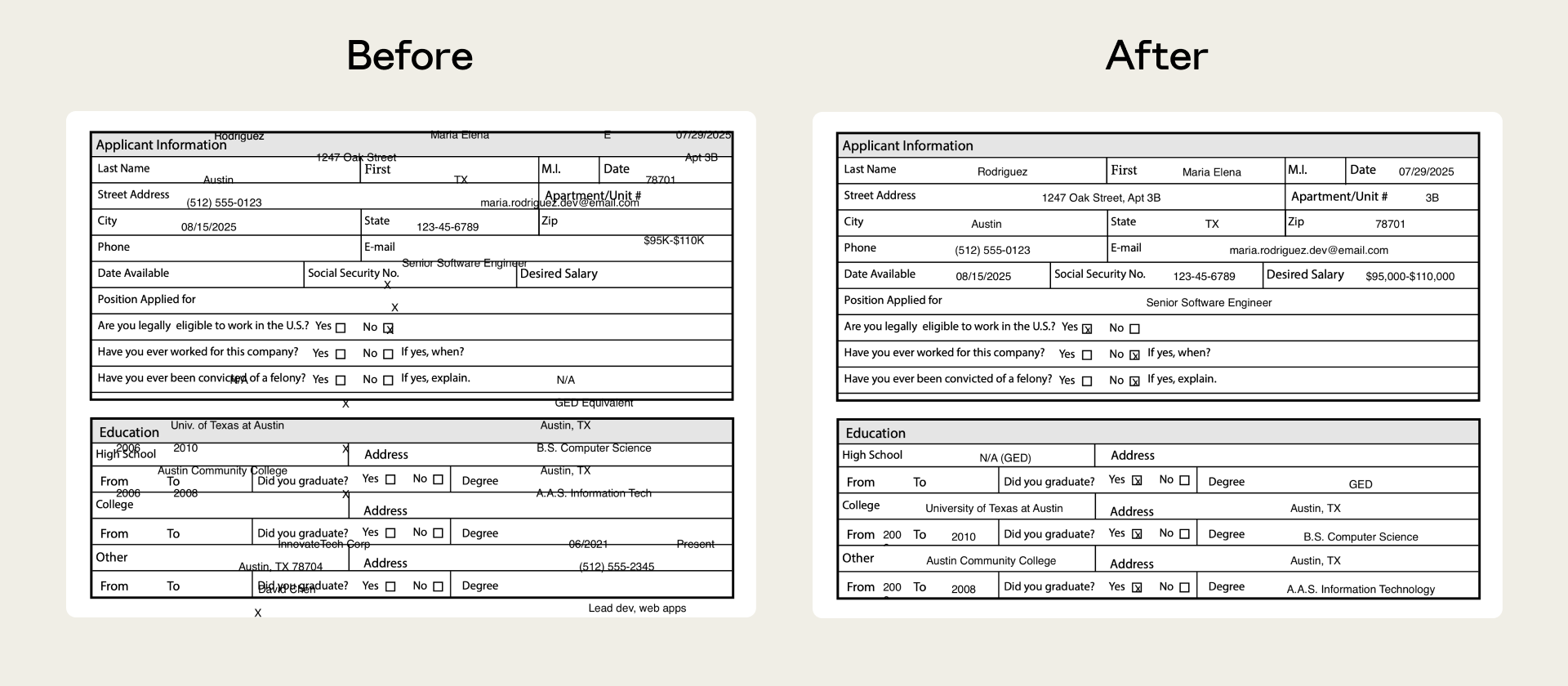
图中左侧(Before)是修复前的状态:Claude 在处理不可填写表单时,需要将文字放置在精确坐标位置,但没有预定义字段可以参照,导致文字定位错乱、表单填写失败。
右侧(After)是通过 evals 定位到失败点、发布修复后的状态:新版本将定位锚点绑定到从文档中提取的实际文字坐标,定位精准,信息填入正确位置。
没有 evals,这类问题很难被系统性地发现。 作者在手动测试时可能碰巧使用了可填写的表单,从未触发这个边界情况。
Evals 的两大核心用途
1. 捕获质量回归(Regression Detection)
模型在持续更新,Claude Sonnet 今天的行为和三个月后的行为可能有所不同。一个上个月还运转良好的 skill,在新模型上可能悄然失效——而你毫不知情,直到用户反馈。
有了 evals,每次模型更新后可以自动运行一遍,提前发现问题,在影响团队工作之前修复。
2. 感知模型自身能力的成长(Model Progress Tracking)
这个用途更加微妙,主要针对能力扩展型 skill。
当你的 evals 显示:不加载 skill 的情况下,基础模型也能通过所有测试——这意味着 skill 中编码的那些技巧,已经被模型默认吸收了。这个 skill 没有坏掉,只是不再必要了。
这是一个好消息,说明模型在进步;但如果不测试,你永远不知道什么时候可以清理掉那些已经过时的 skill。
三、Benchmark Mode:量化比较,数据说话
仅靠"通过/失败"有时还不够,你可能还想知道:这个 skill 到底带来了多少提升?它运行得快不快?消耗 token 多不多?
Benchmark Mode 提供了标准化的量化评估。
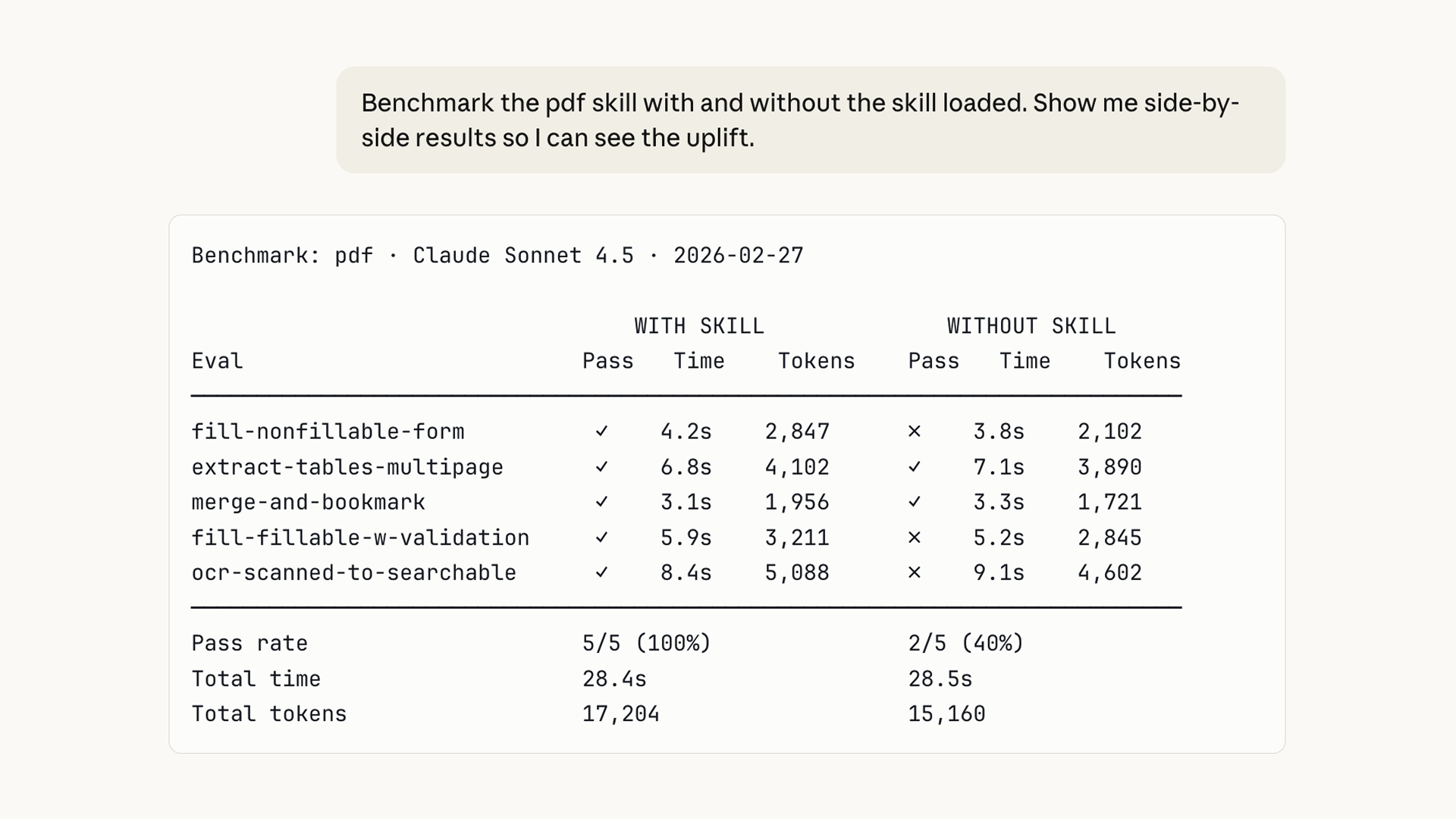
图中展示的是一次针对 PDF skill 的基准测试,用户在对话框中输入:
“Benchmark the pdf skill with and without the skill loaded. Show me side-by-side results so I can see the uplift.”
系统返回了一张对比表格(Benchmark: pdf · Claude Sonnet 4.5 · 2026-02-27),核心数据如下:
| 测试用例 | WITH SKILL(通过/时间/Token) | WITHOUT SKILL(通过/时间/Token) |
|---|---|---|
| fill-nonfillable-form | ✓ 4.2s / 2,847 | ✗ 3.8s / 2,102 |
| extract-tables-multipage | ✓ 6.8s / 4,102 | ✓ 7.1s / 3,890 |
| merge-and-bookmark | ✓ 3.1s / 1,956 | ✓ 3.3s / 1,721 |
| fill-fillable-w-validation | ✓ 5.9s / 3,211 | ✗ 5.2s / 2,845 |
| ocr-scanned-to-searchable | ✓ 8.4s / 5,088 | ✗ 9.1s / 4,602 |
| 汇总 | 5/5 通过(100%)/ 28.4s / 17,204 tokens | 2/5 通过(40%)/ 28.5s / 15,160 tokens |
这张表格直观说明了几件事:
- skill 效果显著:加载 skill 后通过率从 40% 提升到 100%,尤其是不可填写表单、OCR 转换这类难题
- 时间代价极小:总时间几乎持平(28.4s vs 28.5s),说明 skill 引入的额外指令没有造成明显延迟
- token 消耗略增:从 15,160 增加到 17,204,是为了更好输出质量付出的合理代价
这些数据可以本地存储,也可以接入 CI 系统或 Dashboard,实现自动化监控。
四、多 Agent 支持与 A/B 测试
并行运行,消除干扰
当 evals 数量较多时,顺序运行有两个问题:慢,且上下文会在测试之间"泄漏"——前一个测试的信息可能影响后一个测试的判断。
新版本为每个 eval 启动独立的 Agent,并行运行,每个 agent 拥有完全干净的上下文,并有自己独立的 token 和时间统计。速度更快,结果更可靠。
Comparator Agent:盲测对比两个版本
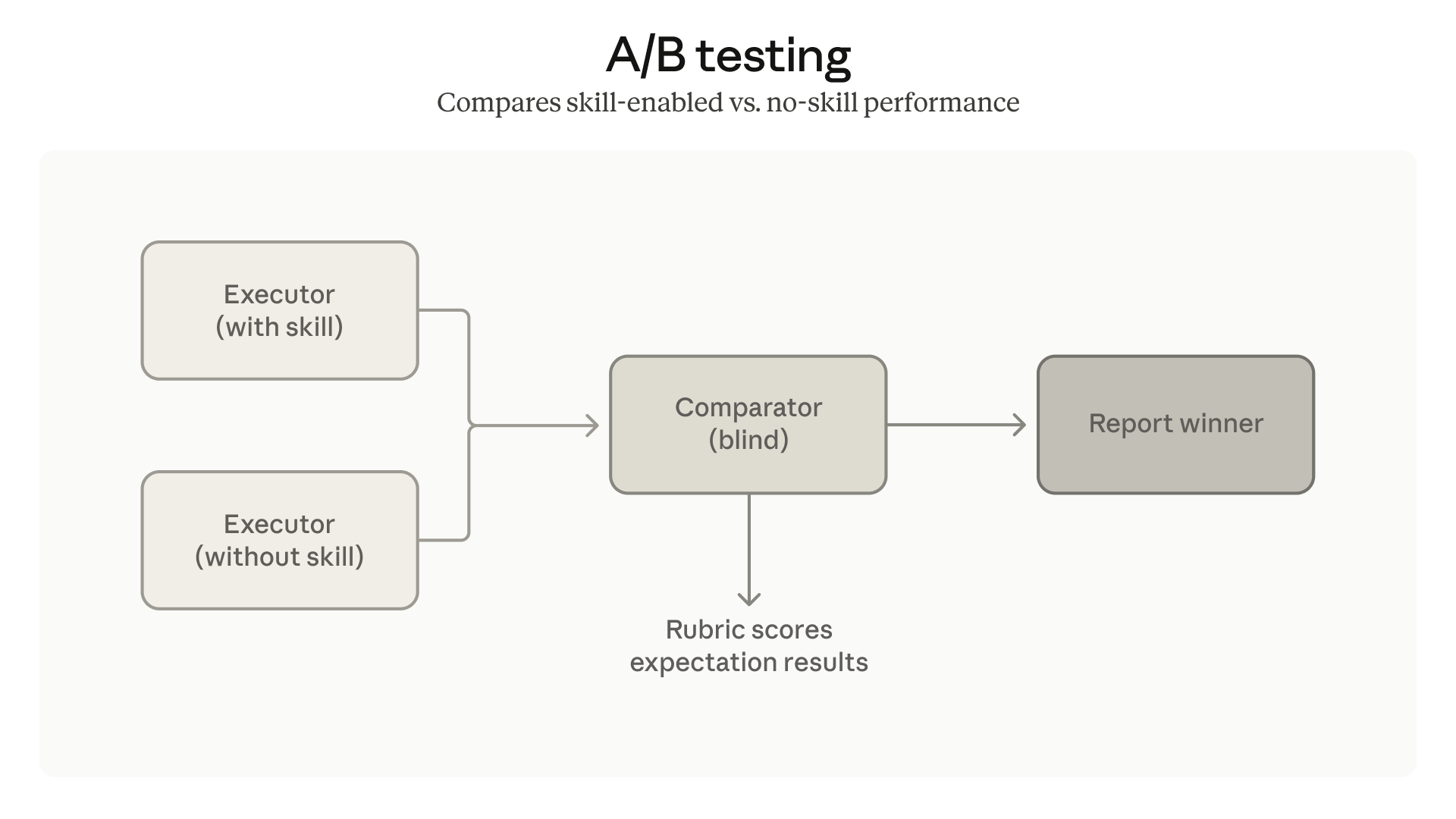
图中清晰展示了 A/B 测试的工作流程:
Executor (with skill) ──┐
├──► Comparator (blind) ──► Report winner
Executor (without skill) ──┘
│
└── Rubric scores / expectation results
两个 Executor agent 分别在"有 skill"和"无 skill"的条件下执行相同任务,产出各自的结果。然后由 Comparator agent 进行盲评——它不知道哪个输出来自哪个版本,只根据评分标准(rubric)和预期结果打分,最终报告哪个版本获胜。
这种盲测设计避免了主观偏差。对于 skill 迭代来说,这意味着你可以客观验证:“我这次修改,到底有没有让 skill 变得更好?”
五、Skill 描述优化:让触发更精准
Evals 解决了"输出质量"的问题,但还有另一个隐患:skill 在该触发的时候没触发,或者不该触发的时候乱触发。
随着一个团队积累的 skill 越来越多,每个 skill 的描述需要足够精准,才能让 Claude 在接收到用户提示时做出正确判断。
- 描述太宽泛 → 误触发(false positives):用户只是随口问了一句,skill 却强行介入
- 描述太窄 → 漏触发(false negatives):用户明确需要这个 skill,它却没有启动
Skill Creator 新增了描述优化功能,它会分析当前 skill 描述与一批样本提示词的匹配情况,然后建议具体的修改方向——哪些词语引发了误触发,哪些场景被遗漏了。
实测数据
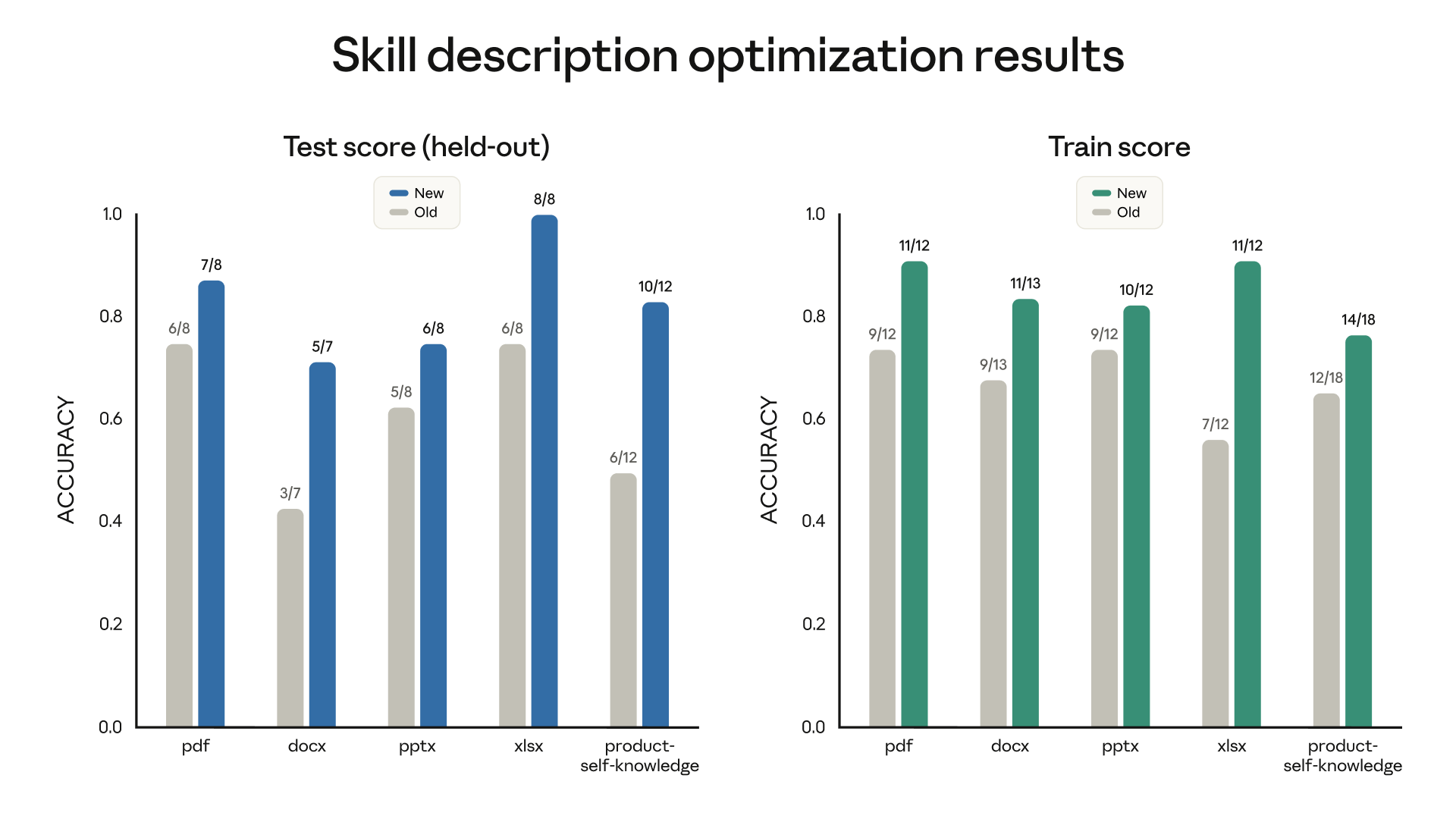
图表展示的是 Anthropic 在自己的 6 个公开文档创建 skill(pdf、docx、pptx、xlsx、product-self-knowledge)上运行描述优化后的结果。
左图(Test score,held-out 测试集)和右图(Train score,训练集)均对比了新旧描述的准确率:
- pdf:测试集从 6/8 提升到 7/8,训练集从 9/12 提升到 11/12
- docx:测试集从 3/7 提升到 5/7,提升明显
- pptx:测试集维持 4/8 → 4/8(无变化,是 6 个里唯一没有改善的)
- xlsx:测试集从 6/8 提升到 8/8(满分),训练集从 7/12 提升到 10/12
- product-self-knowledge:测试集从 6/12 提升到 10/12,提升最为显著
结论:6 个 skill 中有 5 个在触发准确性上得到了改善。 唯一没有改善的 pptx,可能本身描述已经足够精准,或者存在其他原因。
六、未来方向:从"怎么做"到"做什么"
文章最后提出了一个更深远的设想。
今天,一个 SKILL.md 文件本质上是一份实现计划:它详细告诉 Claude 每一步应该怎么做(how),包括调用哪些工具、遵循什么格式、处理哪些边界情况。
但随着模型能力的持续提升,这种详细指令可能越来越不必要。未来,skill 也许只需要描述目标是什么(what),模型自己推断出最佳执行路径。
而 evals 框架,正是朝这个方向迈出的关键一步:
Evals 已经在描述"what"——期望的输出是什么,成功标准是什么。最终,这个描述本身,可能就是 skill 的全部。
总结
| 新功能 | 解决的问题 | 核心价值 |
|---|---|---|
| Evals 评估测试 | 不知道 skill 是否还能用 | 系统化验证,捕获回归 |
| Benchmark Mode | 无法量化 skill 的提升效果 | 通过率、时间、token 三维对比 |
| 多 Agent 并行 | 测试慢、上下文污染 | 隔离运行,结果更可信 |
| Comparator Agent | 无法客观判断版本优劣 | 盲测对比,消除主观偏差 |
| 描述优化 | Skill 触发不准确 | 减少误触发和漏触发 |
这套工具组合,让非工程师背景的 skill 作者也能像软件工程师一样:写测试、跑基准、迭代改进、数据驱动决策。
原文地址
https://claude.com/blog/improving-skill-creator-test-measure-and-refine-agent-skills

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)