深入浅出TCP拥塞控制:研究拥塞控制的底层逻辑

前言
大家好,这里是程序员阿亮,今天来带大家研究一下TCP协议中的拥塞控制算法!
大家可以先思考一下,什么是拥塞控制,为什么需要它?
举个类比的例子:
想象一下早高峰的城市环路。如果每辆车(数据包)都不顾一切地冲上环路(网络),不去感知路况,结果就是灾难性的世纪大堵车。所有的车都停滞不前,整条道路的吞吐量降为零。
也就是类似于高中说的负反馈,造成恶性循环。
在计算机网络中,这被称为拥塞崩溃(Congestion Collapse)。在1980年代中期,早期的互联网真的发生过这种事,导致网络吞吐量下降了成千上万倍。为了拯救互联网,Van Jacobson在1988年提出了一套伟大的算法——TCP拥塞控制。
在深入细节之前,我们必须先澄清一个经典误区:流量控制(Flow Control)与拥塞控制(Congestion Control)的区别。
流量控制:端到端的问题。接收方告诉发送方:“我处理不过来了,你发慢点。”(通过TCP Header中的Window字段,即rwnd实现)。
拥塞控制:全局网络的问题。发送方感知到网络链路:“中间路由器好像堵塞了,我得发慢点。”
最终,发送方的实际发送窗口大小由两者共同决定:
发送窗口 = min(rwnd, cwnd)
注:rwnd (Receiver Window) 是接收窗口,cwnd (Congestion Window) 是拥塞窗口。
一、拥塞控制的核心基石
要理解拥塞控制,必须先认识几个核心变量:
-
MSS (Maximum Segment Size):最大报文段长度。TCP在发送数据时,会将其切分成一个个MSS大小的块(通常以太网中MSS为1460字节)。
-
cwnd (Congestion Window):拥塞窗口。表示发送方在收到ACK之前,可以连续发送多少个数据包。它是拥塞控制的主角,由发送方自己在本地动态维护。
-
ssthresh (Slow Start Threshold):慢启动门限。这是一个分水岭变量,用来决定当前应该使用“慢启动”算法还是“拥塞避免”算法。
-
RTT (Round Trip Time):往返时间。从发送一个数据包到收到它对应的ACK所花费的时间。
拥塞控制的本质是一个动态探测的过程:“有空余带宽就加速,发现丢包就减速”。这被称为 AIMD(Additive Increase Multiplicative Decrease,加法增加乘法减少) 原则。
TCP拥塞控制经典状态机包含四大核心算法:慢启动、拥塞避免、快速重传、快速恢复。
二、四大经典算法详析
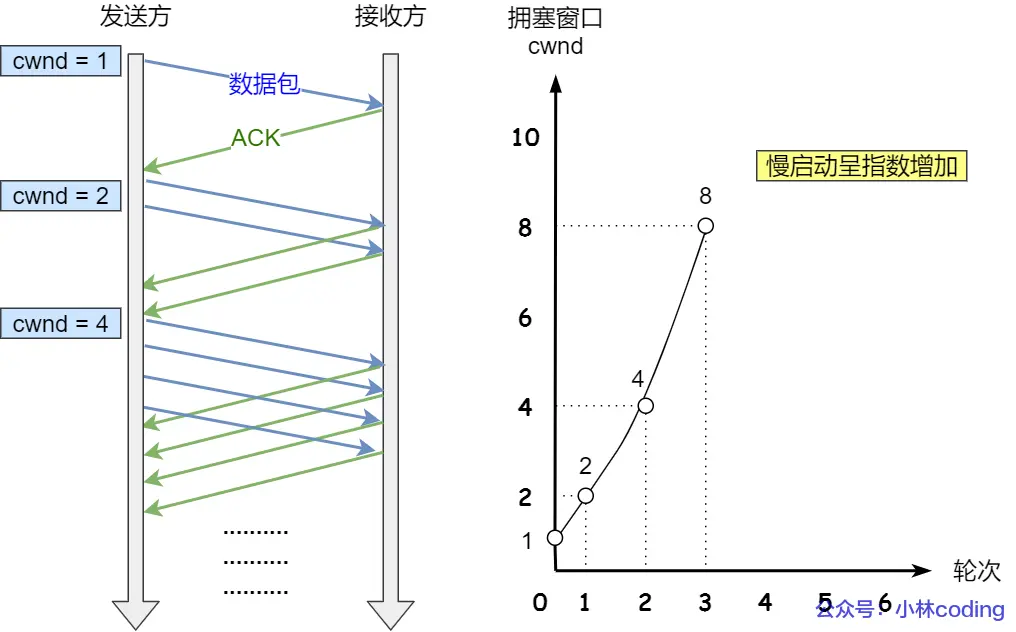
1. 慢启动(Slow Start)—— 名字叫“慢”,实则狂飙
当一个TCP连接刚刚建立时,发送方对网络情况一无所知。如果一下子把大量数据全部注入网络,极易瞬间压垮路由器。因此,TCP采取“摸着石头过河”的策略。
运作机制:
-
初始化阶段:cwnd 被设置为初始窗口大小(IW, Initial Window)。*(注:早期Linux IW=1,后来演进为2、4,目前Linux内核默认IW=10,即一开始可以发10个包)。*为了方便理解,我们假设初始化 cwnd = 1。
-
每当发送方收到一个正确的ACK,cwnd 的值就增加 1 个 MSS。
-
发出 1 个包,收到 1 个 ACK,cwnd = 1 + 1 = 2。
-
发出 2 个包,收到 2 个 ACK,cwnd = 2 + 2 = 4。
-
发出 4 个包,收到 4 个 ACK,cwnd = 4 + 4 = 8。
-
细节揭秘:虽然叫“慢启动”,但这其实是指数级增长(Exponential Growth)。在理想情况下,仅仅经过几个RTT,发送窗口就能达到极其庞大的数值。
何时结束?
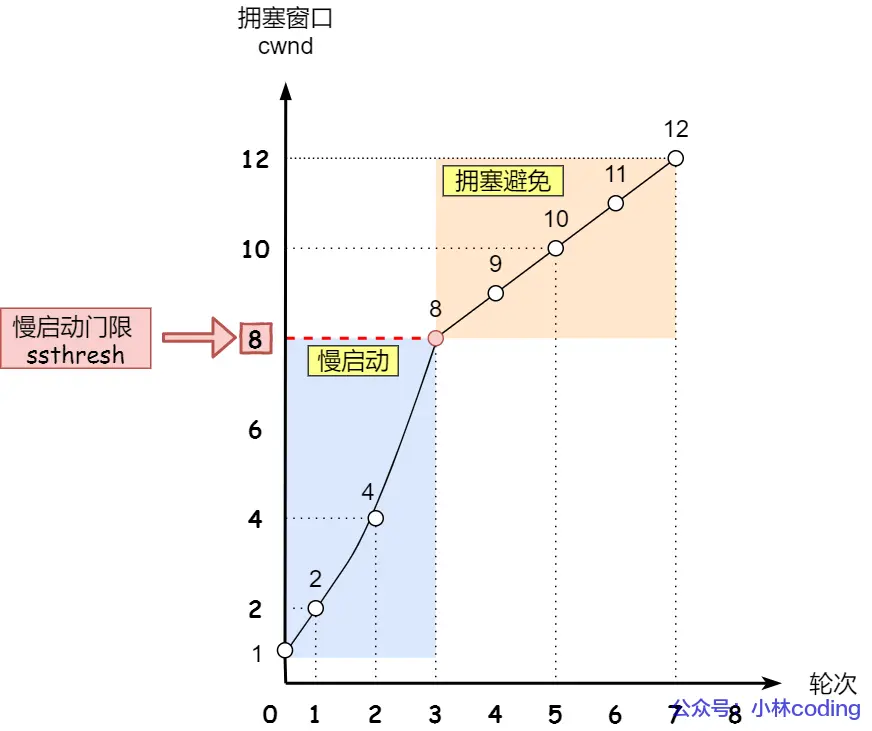
慢启动不能无休止地增长,当 cwnd >= ssthresh 时,慢启动结束,TCP进入“拥塞避免”阶段。
2. 拥塞避免(Congestion Avoidance)—— 稳扎稳打
当窗口达到 ssthresh 时,说明网络可能快要摸到瓶颈了。为了防止突然的拥塞,TCP将指数增长改为线性增长。
运作机制:
-
每经过一个完整的RTT(无论这个RTT内收到了多少个ACK),cwnd 的值只增加 1 个 MSS。
-
代码实现细节:在实际的内核代码中,通常是每收到一个ACK,就让 cwnd = cwnd + 1/cwnd。这样当收到 cwnd 个ACK(即一个RTT)时,整体恰好增加了 1。
在这个阶段,发送方在小心翼翼地试探网络的极限,直到网络丢包发生。
3. 丢包感知与处理 —— 决定生死的十字路口
TCP如何知道网络拥塞了?答案是丢包。TCP通过两种主要方式感知丢包,这两种方式对应的惩罚力度完全不同!
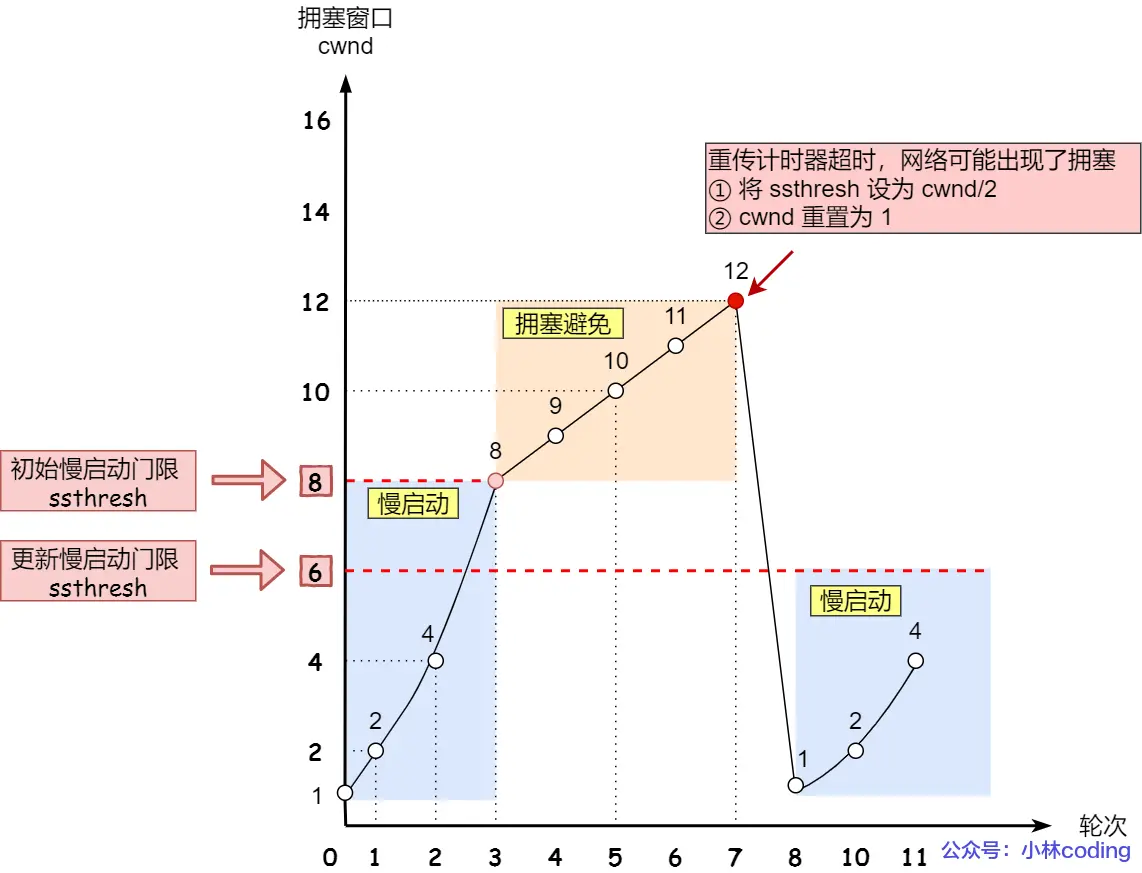
触发条件 A:超时重传(RTO, Retransmission Timeout)
如果发送方发出了一个包,等了漫长的时间(超过RTO计时器设定的时间),仍然没有收到ACK。
-
网络诊断:极其糟糕!这说明网络可能发生了严重的拥塞,连ACK都回不来了,或者路由器缓存完全被打爆。
-
TCP的反应(极度严厉):
-
把 ssthresh 降为当前 cwnd 的一半:ssthresh = cwnd / 2。
-
把 cwnd 直接打回原形,设为 1。
-
重新进入慢启动阶段。
(这种一刀切的做法对性能打击极大,尤其是在高带宽网络下,重新爬坡需要极长的时间)。
-
触发条件 B:收到 3 个重复的 ACK(Duplicate ACKs)
假设发送方发了包 1, 2, 3, 4, 5。包 2 丢失了,但 3, 4, 5 成功到达接收方。
接收方收到 3 时,发现缺少 2,会回复一个“期待包 2”的 ACK。收到 4、5 时,依然回复“期待包 2”的 ACK。
此时,发送方会收到连续的 3 个针对包 2 的重复 ACK。
-
细节:为什么是 3 个? 网络中偶尔会出现数据包乱序到达(Reordering),乱序也会产生重复ACK。TCP作者经过大量实验认为,如果只收到 1 个或 2 个重复ACK,可能是乱序;但如果连续收到 3 个,大概率是真丢包了。
-
网络诊断:轻微拥塞。后续的包(3, 4, 5)还能顺利到达,说明网络并没有彻底瘫痪,只是偶尔掉队。
-
TCP的反应:进入快速重传和快速恢复。
-
4. 快速重传(Fast Retransmit)与 快速恢复(Fast Recovery)
既然网络没有彻底瘫痪,TCP就不应该像超时那样把 cwnd 降为 1。
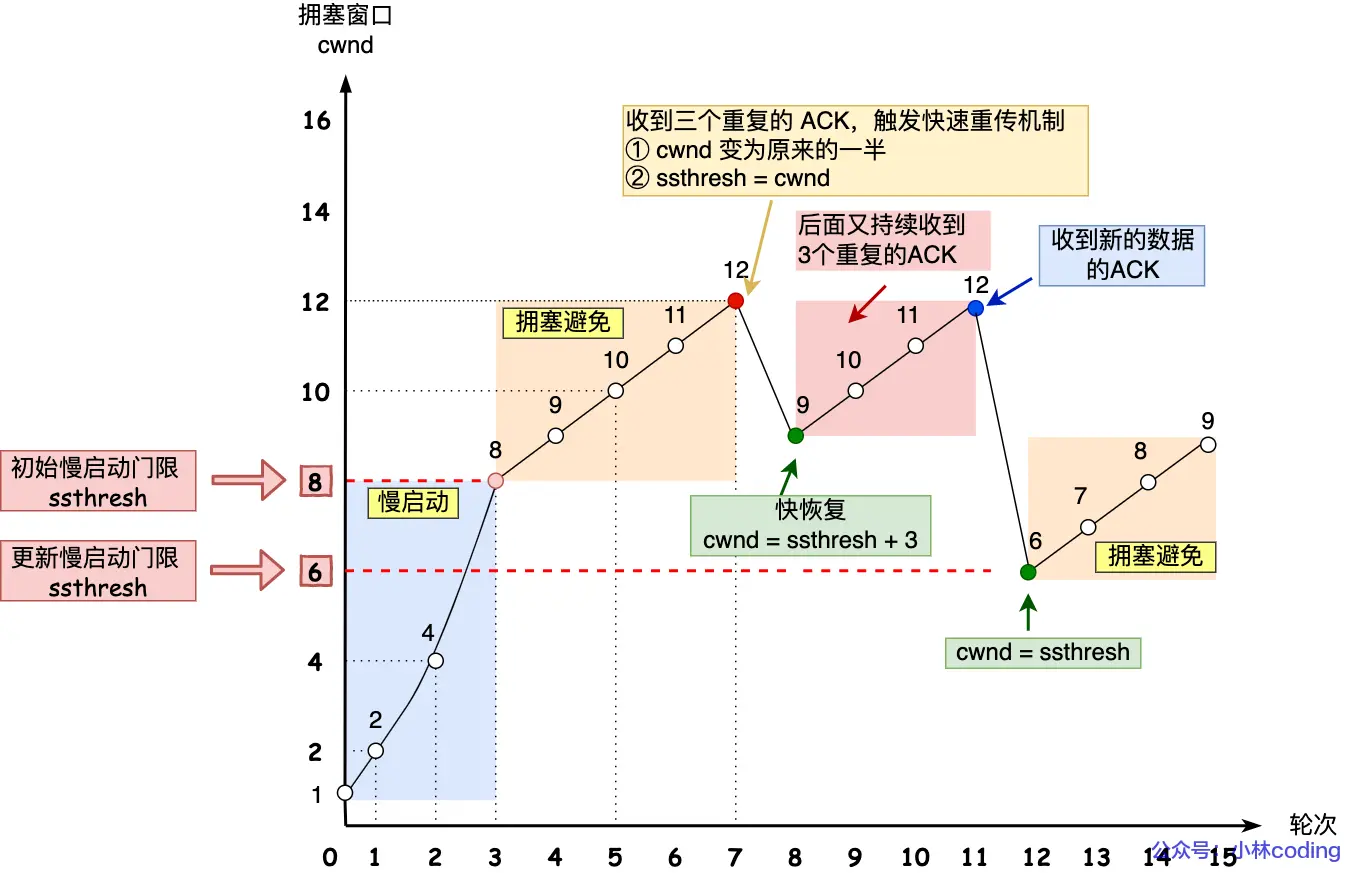
快速重传机制:
无需等待RTO超时计时器结束,立刻重传丢失的包(上例中的包 2)。
快速恢复机制(Reno算法的精髓):
在这个阶段,TCP认为既然有 3 个重复ACK发回来,说明有 3 个数据包已经成功离开了网络(被接收方缓存),网络腾出了空间。
-
把 ssthresh 降为当前 cwnd 的一半:ssthresh = cwnd / 2。
-
把 cwnd 设置为新的 ssthresh + 3 (+3是为了补偿触发机制的那3个数据包)。
-
重传丢失的数据包。
-
如果在此期间依然收到重复的 ACK,说明网络里又有包到达了接收方,发送方可继续膨胀窗口:cwnd = cwnd + 1。这被称为窗口膨胀(Window Inflation)。
-
退出条件:一旦收到一个新的 ACK(比如接收方终于收到了重传的包 2,此时它会直接回复一个“期待包 6”的ACK),意味着丢失的包已被修补。发送方将 cwnd 重置为 ssthresh(窗口收缩,Deflation),并回到拥塞避免状态。
总结
TCP拥塞控制是发送方通过“不断试探”来感知网络路况,动态调整发包速度的机制,核心目的是防止网络发生大面积拥堵瘫痪(拥塞崩溃)。
实际上这个算法不难,但是在实际环境中很有效果,但是实际的TCP拥塞控制要更加的复杂。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 11
11 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)