电商知识图谱实战:从业务建模到 Neo4j 图数据库落地
一、 业务背景:电商客服场景下的知识图谱需求
在电商平台中,商品是连接买家与卖家的核心元素。然而,实际业务场景面临着多重挑战:首先,买家与卖家的表达习惯存在差异,难以高效匹配购买意图;其次,不同卖家间的语言习惯、跨市场和跨语言的商品管理存在显著的碎片化问题。
传统的结构化数据库在处理商品间复杂的关联关系(如“同款商品对比”、“跨品类关联推荐”)时,往往需要多表 Join,导致查询效率低下且难以维护。知识图谱(Knowledge Graph) 通过实体、关系和属性三个元素,以“实体-关系-实体”的三元组方式表达数据,具有极强的可解释性。构建电商知识图谱不仅能提升用户体验(如横向对比同款商品),还能辅助平台降低运营成本,通过商品聚合管理实现品类上新和招商分析。
二、 业务建模:实体与关系设计
构建图谱的首步是针对业务场景进行抽象建模。在电商领域,模型设计需涵盖从基础数据到用户行为的全链路。
1. 实体设计 (Entity Design)
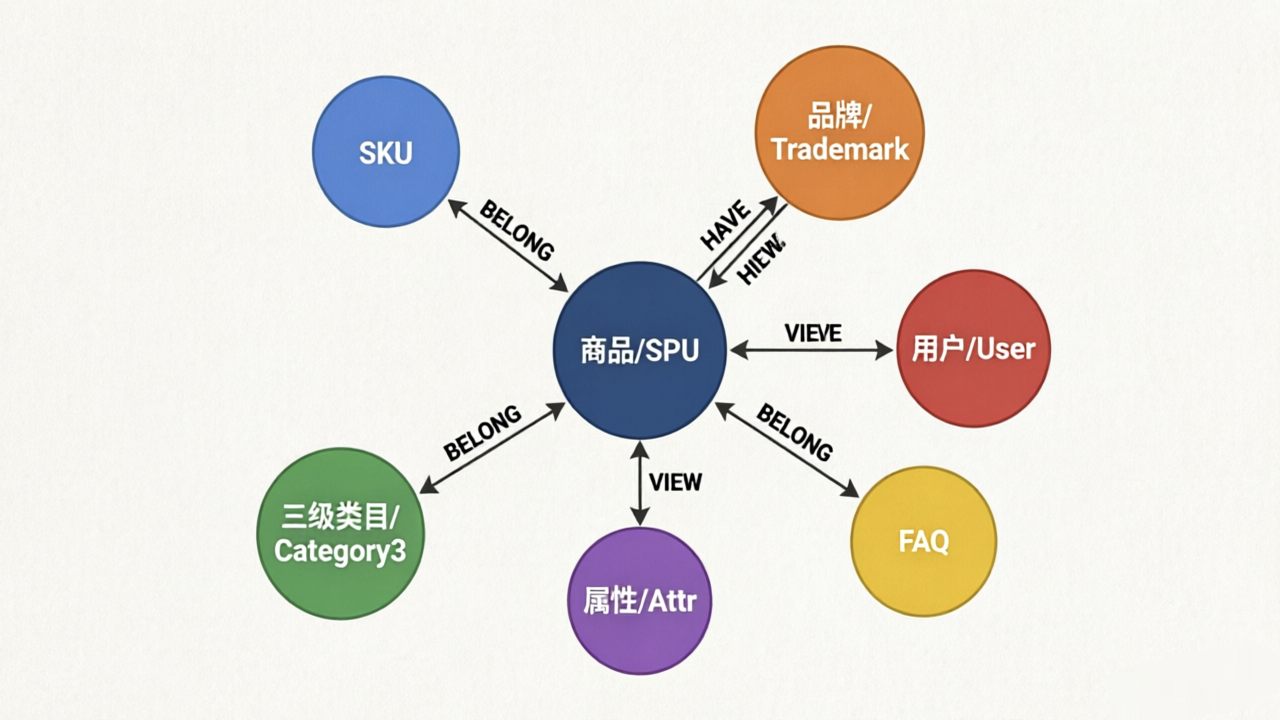
根据电商业务逻辑,该方案设计了以下核心实体:
- SKU (Stock Keeping Unit):单品,具有唯一的 ID 和名称。
- SPU (Standard Product Unit):标准化产品单元,代表一类商品。
- Category (1/2/3):三级类目体系,用于商品的层级划分。
- Trademark:品牌实体。
- Attr (Attribute):属性实体,包括颜色、内存、价格、处理器等。
- User:用户实体,用于记录浏览或购买行为。
- FAQ:常见问题实体(在客服场景中使用)。
2. 关系设计 (Relationship Design)
实体之间的连接定义了图谱的语义网络:
- BELONG:包含关系,如 (SKU)-[:BELONG]->(SPU),(SPU)-[:BELONG]->(Category3),以及类目间的纵向关联。
- HAVE:拥有关系,如 (SKU)-[:HAVE]->(Attr),用于连接单品与其具体的属性值(如价格、尺寸)。
- VIEW:行为关系,如 (User)-[:VIEW]->(SKU),记录用户的点击流数据。
三、 Neo4j 数据导入实战
在完成建模后,需将结构化数据(如存储在 MySQL 中的商品信息)迁移至图数据库。该方案推荐使用 Python 的 neo4j 官方驱动进行批量导入。
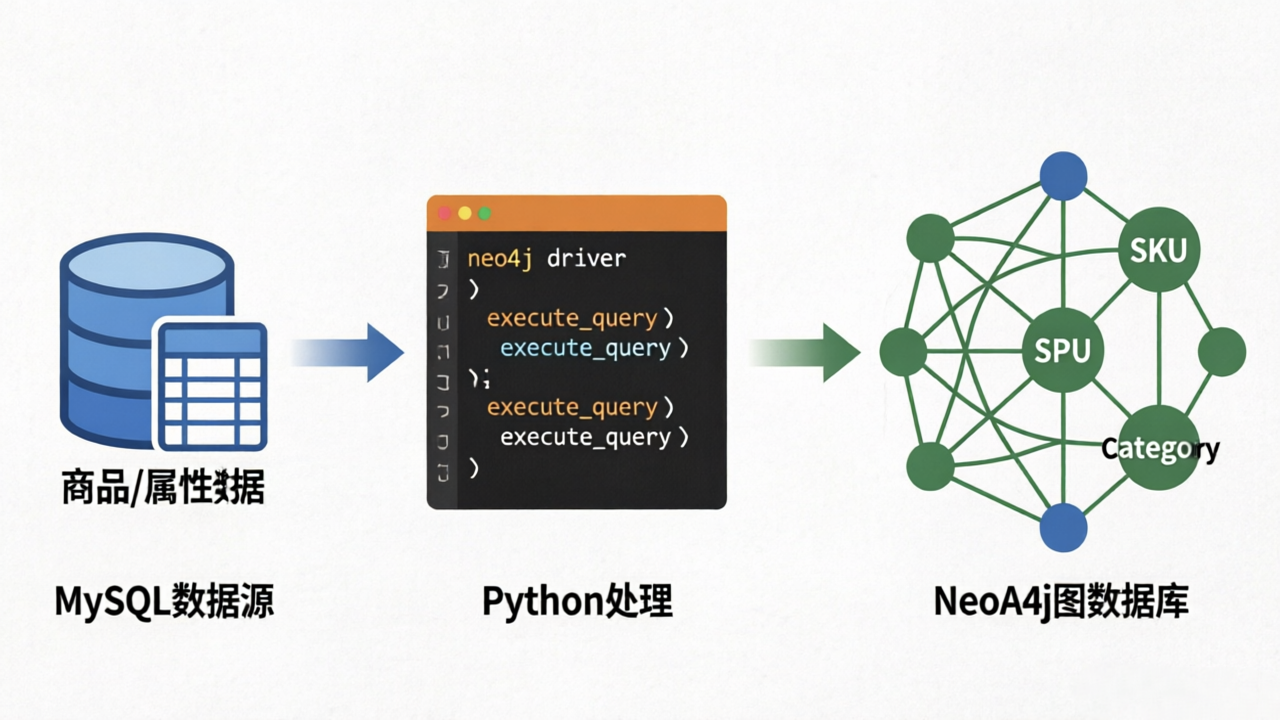
1. 预处理与清洗
在导入前,通常需要对商品描述进行 NLP 处理。例如,利用 UIE(通用信息抽取)模型 从非结构化文本中提取出实体和属性。同时,针对用户输入或商品描述中的拼写错误,需引入拼写纠错模型进行标准化处理,以减少冗余属性值(如将“Nkie”纠正为“Nike”)。
2. Python 批量导入代码
以下代码展示了如何连接 Neo4j 并利用 execute_query 方法批量创建节点与关系:
import torch
from neo4j import GraphDatabase, Driver
from config import NEO4J_URI, NEO4J_AUTH # 假设已在config中配置连接信息
def import_ecommerce_data(mysql_data):
"""
将处理后的电商数据导入 Neo4j
:param mysql_data: 包含 skus, attrs 等信息的字典
"""
# 建立数据库驱动
with GraphDatabase.driver(NEO4J_URI, auth=NEO4J_AUTH) as driver:
# 1. 清空旧数据与约束(生产环境下慎用)
driver.execute_query("MATCH (n) DETACH DELETE n")
# 2. 创建核心节点与 BELONG 关系
for sku in mysql_data.get("skus", []):
driver.execute_query(
"""
MERGE (sku:SKU {sku_id: $sku_id, name: $sku_name})
MERGE (spu:SPU {spu_id: $spu_id, name: $spu_name})
MERGE (trademark:Trademark {name: $trademark_name})
MERGE (cat3:Category3 {name: $cat3_name})
MERGE (cat2:Category2 {name: $cat2_name})
MERGE (cat1:Category1 {name: $cat1_name})
# 建立层级归属关系
MERGE (sku)-[:BELONG]->(spu)
MERGE (spu)-[:BELONG]->(trademark)
MERGE (spu)-[:BELONG]->(cat3)
MERGE (cat3)-[:BELONG]->(cat2)
MERGE (cat2)-[:BELONG]->(cat1)
""",
parameters_={
"sku_id": sku["sku_id"],
"sku_name": sku["sku_name"],
"spu_id": sku["spu_id"],
"spu_name": sku["spu_name"],
"trademark_name": sku["trademark_name"],
"cat3_name": sku["category3_name"],
"cat2_name": sku["category2_name"],
"cat1_name": sku["category1_name"]
}
)
# 3. 导入商品属性关系
for sku_attr in mysql_data.get("sku_attrs", []):
driver.execute_query(
"""
MATCH (sku:SKU {sku_id: $sku_id})
MERGE (attr:Attr {name: $attr_name, type: $attr_type})
MERGE (sku)-[:HAVE]->(attr)
""",
parameters_={
"sku_id": sku_attr["sku_id"],
"attr_name": sku_attr["attr_name"],
"attr_type": sku_attr["attr_type"]
}
)
print("✅ Neo4j 数据同步完成")
四、 Cypher 查询实战:5 个典型场景
基于构建好的图谱,我们可以实现传统 SQL 难以高效处理的关联查询。
场景 1:查询某商品的所有单品型号
通过 SPU 向下钻取所有关联的 SKU。
MATCH (spu:SPU)-[:BELONG]-(sku:SKU)
WHERE spu.name = '联想拯救者Y9000P'
RETURN sku.name
LIMIT 10
场景 2:基于属性筛选特定单品
查询具有特定“颜色”或“内存”属性的商品名称。
MATCH (spu:SPU)-[:BELONG]-(sku:SKU)-[:HAVE]->(attr:Attr)
WHERE spu.name = '小米手机' AND attr.name IN ['8GB', '黑色']
RETURN sku.name
场景 3:跨类目的品牌发现
查询某个三级品类下所有的活跃品牌。
MATCH (cat3:Category3)<-[:BELONG]-(:SPU)-[:BELONG]->(trademark:Trademark)
WHERE cat3.name = '智能手机'
RETURN DISTINCT trademark.name
场景 4:价格区间与类目复合筛选
在特定品类下查找符合价格区间的单品。
MATCH (cat3:Category3)<-[:BELONG]-(spu:SPU)<-[:BELONG]-(sku:SKU)-[:HAVE]->(price:Attr {type: '价格'})
WHERE cat3.name = '电视' AND toFloat(price.name) >= 3000 AND toFloat(price.name) <= 5000
RETURN sku.name, price.name
场景 5:基于共同属性的相似推荐
查找与目标商品具有相同内存或处理器属性的其他商品(协同过滤基础)。
MATCH (s1:SPU)<-[:BELONG]-(:SKU)-[:HAVE]->(a:Attr)<-[:HAVE]-(:SKU)-[:BELONG]->(s2:SPU)
WHERE s1.name = '华为P50' AND a.type IN ['处理器', '运行内存']
RETURN DISTINCT s2.name
五、 性能优化:索引与唯一性约束
图数据库在海量数据下的表现依赖于正确的约束设计。若不建立索引,每次 MATCH 操作都会触发全图扫描。
1. 建立唯一性约束 (Unique Constraints)
在导入数据前,应为各实体的唯一标识符创建约束。这不仅保证了数据一致性,还会自动在这些属性上创建索引以加速查询。
// 为 SKU ID 创建唯一性约束
CREATE CONSTRAINT sku_id IF NOT EXISTS FOR (sku:SKU) REQUIRE sku.sku_id IS UNIQUE;
// 为商品名称创建唯一性约束
CREATE CONSTRAINT spu_name IF NOT EXISTS FOR (spu:SPU) REQUIRE spu.name IS UNIQUE;
// 为属性组合创建约束
CREATE CONSTRAINT attr_unique IF NOT EXISTS FOR (attr:Attr) REQUIRE (attr.name, attr.type) IS UNIQUE;
2. 查询优化技巧
- 避免过度使用 DISTINCT:在图遍历中,应尽量通过精确的关系模式(Pattern)限制结果集,而非在最后进行去重。
- 利用 WITH 子句:将复杂的查询分解,在中间步骤进行结果过滤或排序,减少后续路径搜索的宽度。
六、 踩坑经验分享
在该方案的落地过程中,以下两个坑点具有代表性:
1. 数据类型转换隐患
坑点:在 Python 端提取价格时,价格往往是字符串格式(如 "2999.00")。若直接存入 Neo4j 的 Attr.name 属性中,执行价格区间的数学比较(>= 或 <=)会失效,因为 Cypher 默认进行字符串排序。 对策:在数据导入阶段,务必使用 float() 或 int() 转换数值。在 Cypher 查询时,也可使用 toFloat() 进行动态转换以保证比较逻辑正确。
2. 实体爆炸与冗余节点
坑点:在引入文本抽取(UIE)结果时,如果不对提取出的属性进行去重和标准化(Spell Check),会导致图中出现大量含义相同但名称不同的节点(如“16G”和“16GB”)。 对策:在建立关系前,通过 rapidfuzz 进行模糊匹配或建立标准同义词词典。在 Cypher 导入语句中使用 MERGE 而非 CREATE,确保相同名称的实体只被创建一次。
七、 总结与展望
电商知识图谱的构建是一个持续迭代的过程。通过 Neo4j,该方案实现了商品数据的语义化连接,解决了传统数据库在复杂关联查询上的痛点。未来,图谱可进一步与 大语言模型(LLM) 结合,通过 RAG(检索增强生成) 技术,将图谱中的确定性知识作为背景上下文,构建出具备极高准确度与逻辑推理能力的智能客服系统。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 15
15 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)