SFT 训练到头了?弱模型后训练实战指南(保姆级详解),性能提升从入门到精通,建议收藏!
一、SFT的天花板在哪里
做过SFT的人都有体感:前几个epoch效果飞速上涨,之后就开始"磨"了。loss还在降,评测指标却不动了,甚至回退。
这不是错觉。
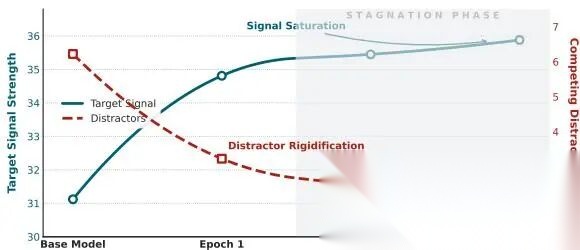
上图是标准SFT在Qwen3-4B-Base上的logit动态。蓝色实线是target token的logit,红色虚线是non-target tokens的平均logit。两条线在Epoch 2之后几乎同时停滞——target logit卡在35.88,non-target logit卡在2.09。
回忆一下SFT的梯度。对于任意non-target token ,交叉熵损失对其logit的梯度为:
梯度大小就等于模型分配给这个token的概率。当模型已经把target token的概率推到接近1,所有non-target token的概率都趋近于零,梯度自然消失。决策边界被"冻住"了——模型并没有完美,只是优化信号没了。
这就是优化饱和(optimization saturation)。继续SFT、做self-revision、reflection-based fine-tuning,本质上都在强化正确目标。但正确目标的logit已经够高了,再怎么推也没有信息增量。
二、反直觉的想法:用弱模型来驱动强模型
论文的洞察来自一个类比:一个能力很强的人和一个弱队友合作解题时,强者反而会被迫打磨自己的推理——提升来自观察和纠正弱者的错误,这些错误暴露了看似合理实际错误的路径,迫使强者更精确地区分对错。
形式化为Weak-Driven Learning(弱驱动学习):
给定一个强模型 和一个弱模型 (比如历史checkpoint),弱驱动学习通过联合利用两者在数据集上的输出来构造训练信号,将强模型优化为更强的 。
方向和知识蒸馏完全相反。蒸馏是"强→弱",强teacher指导弱student。弱驱动学习是"弱→强",用弱模型的不确定性激活强模型已经消失的梯度。
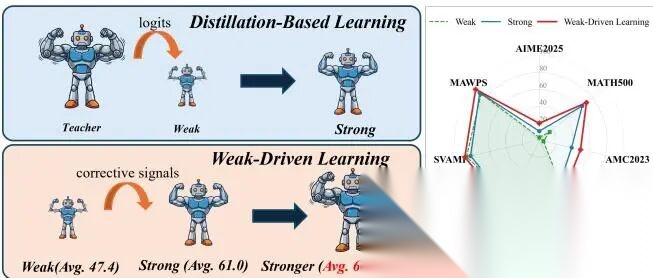
左侧对比了两种范式。蒸馏依赖更强的teacher(通常很贵或不可得),弱驱动学习只需要一个弱模型——自己的历史checkpoint就行。右侧雷达图:弱模型平均47.4%,强模型61.0%,弱驱动学习后达到69.1%,提升8.1个百分点。
三、WMSS:具体怎么做
论文的框架叫WMSS(Weak Agents Make Strong Agents Stronger),三个阶段。
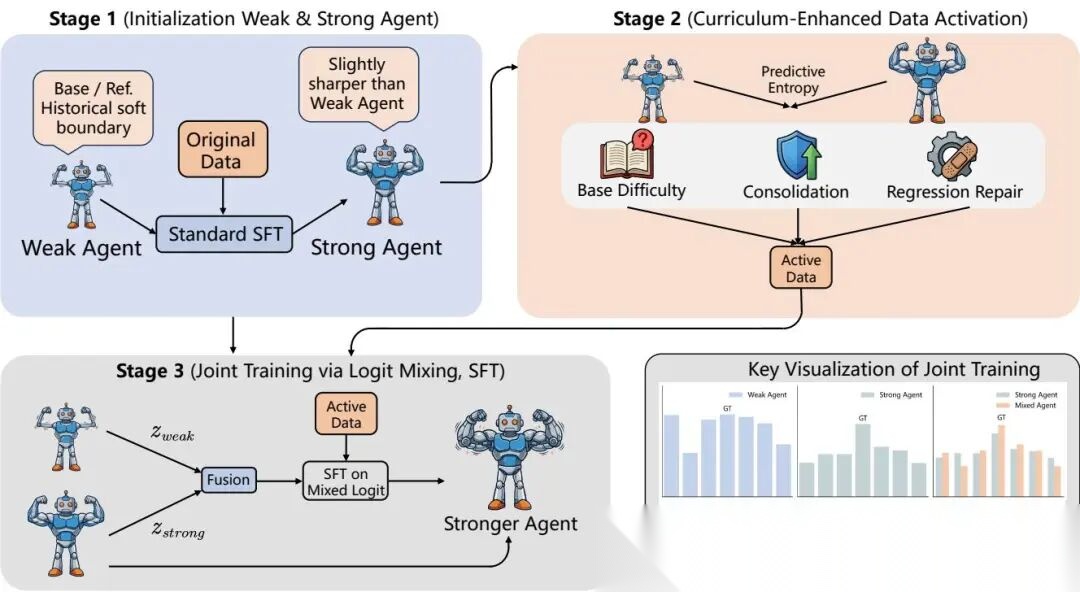
3.1 Phase 1:初始化
从base模型 出发,做一轮标准SFT得到 。然后:
弱模型就是SFT之前的base checkpoint,强模型就是SFT之后的。不需要额外训练。
3.2 Phase 2:基于熵动态的课程数据激活
不是所有样本都值得继续学。WMSS用弱模型和强模型的熵差异来筛选。
对每个样本 ,计算熵变化:
然后按三个信号的加权混合来采样:
三个分量各有用途:
- • 基础难度():弱模型本身就觉得难的样本,概念有挑战性,需要持续关注
- • 巩固(): 说明强模型比弱模型更确定了,但大幅下降可能是脆弱的快速学习,需要回访巩固
- • 回归修复(): 说明强模型反而比弱模型更不确定——弱模型处理得更好,意味着这个样本是可学的(不是噪声),强模型出现了遗忘,需要重点修复
超参选择 ,巩固信号占主导。
3.3 Phase 3:Logit Mixing联合训练
核心操作。对于每个训练样本 ,分别用弱模型和强模型做前向传播得到logits,线性混合:
用混合后的logits计算softmax分布,做标准交叉熵训练:
梯度通过 反传到强模型参数上。弱模型在联合训练中也会被更新(也接收梯度),但最终部署的只有强模型。
整个流程可以迭代:每轮结束后,上一轮的强模型变成新的弱模型,新训出的模型作为强模型,再来一轮。
伪代码:
输入:数据集D,base模型M_0,迭代次数K,混合系数λPhase 1: M_1 = SFT(M_0, D)for t = 1 to K: # 课程数据激活 ΔH = H(M_t) - H(M_{t-1}) D_active = WeightedSample(D, 基于ΔH的采样权重) # 弱驱动联合训练 M_θ = M_t for batch (x, y) in D_active: z_weak = Forward(M_{t-1}, x) z_strong = Forward(M_θ, x) z_mix = λ * z_strong + (1-λ) * z_weak 更新M_θ via ∇CE(z_mix, y) M_{t+1} = M_θ返回 M_{K+1}
四、为什么Logit Mixing能打破饱和
这是论文最扎实的部分。从梯度层面给出了严格分析,不只是"混合一下就好了"的直觉。
4.1 Margin收缩与Hard Negative重激活
定义target margin为 ,衡量target token和某个non-target token 之间的logit差距。
弱模型没怎么训练过,margin普遍比强模型小(更"困惑")。定义hard-negative集合:
这些token在弱模型眼中和正确答案的区分度更低。混合logits后,margin变成凸组合:
对于 ,混合后的margin严格小于强模型单独的margin。Margin缩小,这些hard negatives在softmax中获得更多概率质量,梯度被放大。
4.2 总负概率质量增加
论文证明了一个干净的结论(Theorem 5.1):如果弱模型在所有non-target token上的margin都不大于强模型(实践中几乎总成立),那么:
混合后target token的概率下降,non-target tokens的总概率上升。对应到梯度:non-target方向的梯度被放大,target方向的上推力也增强了(因为 变大了)。
4.3 "压制主导"机制
实验数据验证了理论。下表是Qwen3-4B-Base在Epoch 3时的logit统计:
| 指标 | SFT | WMSS | 变化 |
|---|---|---|---|
| Target Logit () | 35.88 | 36.10 | +0.6% |
| Non-target均值 () | 2.09 | 0.90 | -56.9% |
| Target-Background间距 () | 33.79 | 35.20 | +4.2% |
| Logit方差 () | 2.93 | 3.45 | +17.7% |
提升主要不是来自把target logit推得更高(只涨了0.6%),而是大幅压制non-target logits(降了56.9%)。这是一种"压制主导"机制——让干扰项安静下来,而非让正确答案更突出。由于softmax的指数性质,logit空间的线性间距扩大在概率空间被指数放大,决策边界变得更锐利。
4.4 三阶段动态
论文给出了联合训练的三阶段机制解读:
Stage I:饱和区域放大。 训练早期,弱模型在很多non-target token上更困惑,混合后总负概率质量增加, 偏向hard negatives,强模型主导有效更新。
Stage II:梯度屏蔽。 随着强模型变得自信,softmax Hessian收缩( 时 ),弱模型和强模型之间的交叉Hessian也趋零。弱模型的影响自然减弱——它不会在强模型已经学好的地方制造干扰。
Stage III:零空间漂移。 softmax对全局logit平移不变(),loss在均值方向上没有曲率。梯度很小时,随机更新在这个零空间里漂移,产生logit均值的漂移但不改变centered sharpness。这解释了弱模型logit均值大幅上升(+158.1%)但centered norm反而下降的现象。
五、实验结果
5.1 主实验
论文在Qwen3-4B-Base、Qwen3-8B-Base、Qwen2.5-3B三个模型上实验,训练数据来自AM-1.4M(经质量过滤后约215K样本),对比SFT、UNDIAL、NEFTune三个基线。
Qwen3-4B-Base:
| 方法 | 数学平均 | 代码平均 |
|---|---|---|
| SFT | 64.1 | 63.1 |
| UNDIAL | 61.2 | 63.0 |
| NEFTune | 65.0 | 64.7 |
| WMSS | 69.1 | 66.8 |
Qwen3-8B-Base:
| 方法 | 数学平均 | 代码平均 |
|---|---|---|
| SFT | 66.7 | 71.2 |
| UNDIAL | 67.7 | 70.4 |
| NEFTune | 68.5 | 72.4 |
| WMSS | 72.9 | 77.6 |
几个关键发现:
难题提升最显著。 AIME2025上,4B模型从12.2%到20.0%(+64%相对提升),8B模型从15.6%到20.0%。AMC23上8B从45.0%到52.5%,AQUA上8B从63.0%到77.3%。越难的题,WMSS越有优势。
简单题没退化。 MAWPS上4B达到96.2%,8B达到97.8%,接近饱和但没有灾难性遗忘。
UNDIAL反而有害。 UNDIAL通过随机高斯噪声惩罚target logit来抑制过拟合,但在数学推理上平均掉了1.4%。直接打压正确答案的logit会破坏主训练信号,策略本身就有问题。WMSS不碰target logit,通过抬升hard negatives的概率来间接增强梯度,温和且有效。
NEFTune不够。 NEFTune在embedding层注入随机噪声,是一种盲目的正则化——不知道模型在哪些token上犯错。WMSS利用弱模型的历史困惑构造结构化纠正信号,在数学推理上高出NEFTune 4.1%(4B)和4.4%(8B)。本质上,随机扰动和结构化纠正的差距就在这里。
5.2 收敛分析
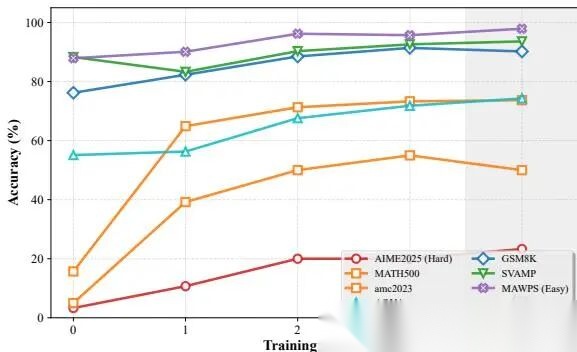
训练轨迹是典型的"快速获取+渐近稳定"两阶段。前3个epoch增益明显,第4个epoch开始有过拟合迹象——AMC2023在Epoch 3之后急剧回退,GSM8K出现波动。Epoch 3-4是停训的最佳窗口。
5.3 消融实验
| 方法 | AIME | MATH500 | GSM8K | 平均 |
|---|---|---|---|---|
| Baseline (SFT) | 12.2 | 66.1 | 83.9 | 54.1 |
| + CEDA | 13.3 | 69.4 | 86.2 | 56.3 |
| + JTWS | 16.7 | 70.2 | 87.6 | 58.2 |
| WMSS (完整) | 20.0 | 71.3 | 88.5 | 59.9 |
CEDA(课程数据激活)提供了+2.2%的基础增益,来自更好的数据筛选。JTWS(弱强联合训练)带来关键突破,AIME从13.3%跳到16.7%。两者结合后AIME达到20.0%,接近baseline的两倍。
数据筛选是必要基础,但打破推理瓶颈的核心是logit mixing。
5.4 混合系数 的敏感性
控制强弱模型在混合logits中的权重,论文在 范围内做了扫描:
| 0.1 | 0.3 | 0.42 | 0.5 | 0.6 | 0.8 | 0.9 | |
|---|---|---|---|---|---|---|---|
| 数学平均 | 71.7 | 72.7 | 75.5 | 74.4 | 69.7 | 70.9 | 67.6 |
呈倒U形,最优区间在 。 太大,混合logits退化为强模型自己的logits,弱模型的补偿消失。 太小,弱模型主导分布,有效的target学习被削弱。
理论上也能验证这个最优区间。从logit统计估算强弱模型的centered norm比值 ,代入梯度份额交叉公式得到 ,落在经验最优区间内。
六、和相关工作的关系
6.1 vs. 知识蒸馏
传统蒸馏(Hinton et al., 2015)和LLM蒸馏(GKD、MiniLLM)的核心是模仿——让student的分布逼近teacher的分布。WMSS不做模仿,弱模型不是target,而是一个"梯度放大器"。它在强模型已经饱和的区域重新注入不确定性,让优化可以继续。
蒸馏需要一个比当前模型更强的teacher。如果你已经是最强的了呢?WMSS只需要自己的历史checkpoint,几乎零成本。
6.2 vs. Weak-to-Strong Generalization
OpenAI的Burns et al.(2023)提出"弱到强泛化":用弱模型的标签训练强模型,强模型能泛化到超越弱标签的水平。但那个工作关注的是缺乏ground truth时如何利用弱监督。
WMSS解决的问题不同:在有ground truth的全监督设定下,如何突破SFT的优化饱和。弱模型的logits不是作为"标签"使用,而是作为"纠正信号"使用。
6.3 vs. 课程学习
传统课程学习(Bengio et al., 2009)按难度排序,从易到难训练。WMSS的CEDA模块也有课程的味道,但排序标准不是固定的难度,而是弱模型和强模型之间的动态熵差异。课程会随着训练自适应调整——上一轮学好的样本权重下降,出现遗忘的样本权重上升。
七、局限与思考
结果亮眼,但有几个点得注意。
复现性。 这是2026年2月的arXiv预印本,还没有外部独立复现。代码仓库已公开,但在更多模型和数据上的泛化性有待验证。
弱模型的选择。 论文用的弱模型就是SFT前的base checkpoint,最简单也最便宜。但如果base模型本身很差(比如在某个领域没有预训练数据),它的"不确定性"可能不是结构化的——不是"在几个合理选项之间犹豫",而是完全随机的困惑。这种情况下logit mixing的效果可能打折扣。
和RL的关系。 论文没有和GRPO、PPO等RL方法做对比。WMSS本质上还是SFT范式内的改进,RL通过探索发现新策略,WMSS通过梯度放大精炼已有决策边界,机制不同。两者能否叠加,是一个有意思的开放问题。
训练开销。 推理阶段零额外开销没问题,但训练阶段需要同时维护弱模型和强模型的前向传播,显存和计算量大约翻倍。论文没怎么讨论这个trade-off。
的选择。 最优 在0.42-0.48之间,论文给了一个基于centered norm比值的启发式估算。但这个比值会随训练变化,固定 可能不是最优的。动态调整 值得探索。
八、总结
WMSS的想法简洁:SFT饱和的根源是梯度消失,弱模型的logits恰好能在饱和区域重新注入概率质量,放大梯度信号。不需要更强的teacher,不需要RL探索,不需要额外推理开销——只需要训练过程中本来就会产生的历史checkpoint。
从更大的视角看,这篇论文质疑了一个默认假设:学习信号必须来自"更好的"来源。蒸馏需要更强的teacher,RLHF需要人类偏好,SFT需要高质量标注。但训练过程中的"废料"——历史checkpoint的困惑和错误——本身就蕴含有价值的训练信号。
这个思路能走多远,现在还不好说。但至少在数学推理和代码生成上,它证明了自己。对于已经把SFT做到头、又没有更强teacher可用的团队,翻出旧checkpoint试一试,可能是一个零成本的选择。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献194条内容
已为社区贡献194条内容

所有评论(0)