AIOps 落地最强攻略(含 LLM 降噪实操),从原理到代码深度拆解,真正解决告警噪音,看这篇就够了!
昨天有个同学跟我请教有没有研究过用AI做告警降噪。这个话题我确实有一些自己的想法。今天不聊“AI 很强大,未来可期”这类空话,而是试着回答一个更实际的问题:
如果你真的想把LLM用到告警治理里,应该把它放在哪一层?它解决什么问题?又不该替代什么?
我自己的结论很明确:
告警降噪这件事,首先是工程问题,其次才是模型问题。真正靠谱的路线,不是“把告警文本丢给大模型,让它自己理解一切”,而是:先用规则、拓扑、抑制、分组做一轮硬降噪,再让LLM去处理那些规则很难覆盖的语义问题。
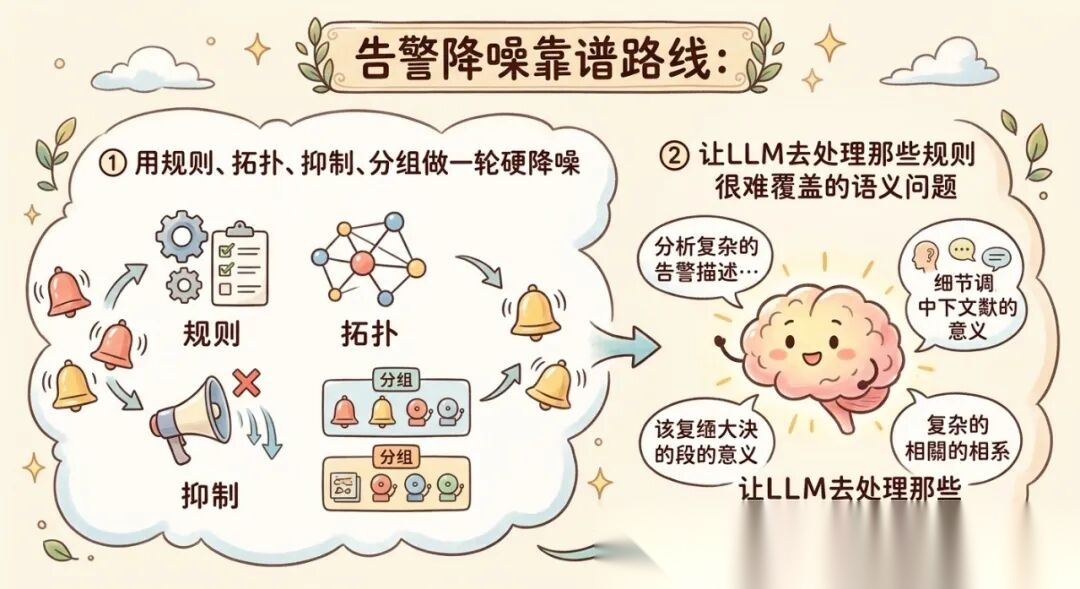
也就是说,LLM在这里更适合当“认知层”和“协同层”,而不是直接替代告警引擎本身。
LLM在告警降噪里最适合做什么
最适合LLM的,不是“直接替代告警引擎”,而是这 5 类任务:
① 语义标准化:把不同监控源的告警文本统一成结构化事件。
② 相似告警聚类:识别“说法不同、实质相同”的重复告警。
③ 上下文补全:结合CMDB、服务拓扑、变更、日志、trace、历史工单补全背景。
④ 根因候选与摘要:把50条告警收敛成“1个可能事件 + 3个证据点”。
⑤ 处置协同:生成给值班同学看的摘要、优先级建议、排查步骤、升级对象。
用LLM做告警降噪的思路
第一层:数据接入
数据源可以来自:
- Prometheus / Alertmanager
- Zabbix
- 云监控
- 自建日志平台
- APM / Trace 系统
- 变更平台 / 发布平台
- CMDB / 服务目录
- 工单系统
这里最关键的,不是“接得多”,而是统一成一个标准事件模型。如果连事件的基本描述都不一致,后面所有关联分析都会变得非常脆弱。我建议至少统一这些字段:
alert_idsourcetitlebodyseveritystatusstart_timefingerprintserviceapplicationclusternamespacepod/node/hostregion/azteamenvrunbook_urldashboard_urltrace_id / span_idchange_id / deploy_idcmdb_citags
这里可以参考OpenTelemetry的语义约定。它的价值不只是“字段命名规范”,更重要的是让指标、日志、trace、资源信息之间更容易打通,减少同一个对象在不同系统里“名字不一样”的问题。
这一层为什么这么重要?
因为后面几乎所有能力都依赖它:
- 去重依赖 fingerprint 和资源标识;
- 拓扑关联依赖 service / resource 标识;
- 变更关联依赖 deploy_id / change_id;
- LLM 补全上下文依赖统一字段输入。
没有统一事件模型,LLM 看到的不是“全局上下文”,而是一堆互相对不上的碎片。
第二层:预处理与硬降噪
这一层不涉及LLM,先做 4 件事:
- 去重:相同fingerprint + 相同资源 + 时间窗口内合并
- 分组:按服务、集群、环境、同一变更窗口、同一异常指标聚合
- 抑制:有上游根因告警时,压制下游症状告警
- 路由:按团队/业务域/优先级发送给正确值班组
Alertmanager基本上全都可以搞定了。
第三层:关联分析
这层的目标不是“压缩文本”,而是把多条告警收敛成问题单元。
可以结合三类方法:
1)规则关联
- 同一服务在 5 分钟内连续爆发;
- 同一个 deploy_id 命中多个异常;
- 同一个 namespace / cluster 下多资源同时告警。
2)拓扑关联
基于依赖关系看链路传播:
- A 调 B,B 调 C;
- C 异常后,B 和 A 先后出现超时和错误率上升。
拓扑不是为了画图好看,而是为了支持两个关键动作:
- 判断谁更可能是根因,谁更像症状;
- 识别“这一串告警其实是一个链路故障”。
3)统计关联
- 时间相关性;
- 历史共现;
- 指标联动模式;
- 相似事件模板。
这层的核心不是“找到所有可能关系”,而是围绕两个问题做收敛:
- 它们是不是同一个事件?
- 哪个更接近根因,哪个更接近用户影响?
这里我特别建议你把下面这句话讲得更重一点:告警不是围绕技术组件来设计的,而应该围绕“用户影响”和“可操作性”来收敛。
因为生产里最糟糕的一种状态就是:组件级告警非常充分,但人仍然不知道应该先处理哪一个。
第四层:LLM语义理解
这里才让LLM上场,主要做三类事:
1)告警归一化
把不同来源的自然语言告警,转成统一JSON:
{
"event_type": "latency_spike",
"affected_service": "checkout-api",
"affected_resource": "pod/checkout-7f9",
"symptom": "p95 latency > 3s",
"possible_cause": "db connection pool saturation",
"user_impact": "payment submission timeout",
"confidence": 0.78,
"evidence": [
"APM latency anomaly",
"DB pool wait time increased",
"error log matched timeout pattern"
]
}
2)相似事件聚类
比如这些文本:
- “checkout timeout”
- “submit order request exceeded 5s”
- “payment API upstream response slow”
这类告警对规则引擎来说可能不同,但对LLM来说能识别为“同一类用户症状”,因为它们都属于“超时、反应慢”。
3)事件摘要
目标就是要把多条告警总结成一个整体事件,这个事件要包含如下要素:
- 发生了什么
- 影响了谁
- 最可能根因
- 当前证据
- 建议先看哪里
第五层:决策与编排
这一层不建议直接让LLM拍板,而是做成策略引擎,让模型只提供建议,最终由规则做二次校验。
例如:
- 高置信度重复 → 自动合并
- 命中上游抑制规则 → 自动静默症状告警
- P3 / P4 + 低用户影响 + 低置信度 → 延迟通知或批量通知
- P1 / P0 或核心业务路径受损 → 永不自动压制,必须通知
- LLM 建议压制 → 仅作为建议,必须满足显式规则后才允许执行
这一层真正要解决的不是“让 AI 更聪明”,而是把自动化动作限制在低风险、高可验证的范围里。否则系统越智能,风险面越大。
第六层:人机协同与反馈
这一层决定系统能不能越用越好。需要回收的反馈至少包括:
- 值班人是否接受 LLM 的聚类结果;
- 是否确认了根因;
- 是否发生误压制;
- 是否误升级;
- 最终工单是否归并为同一事件;
- 推荐的排查步骤是否真的有帮助。
很多团队做AI告警治理时,只做了“在线推理”,没做“闭环学习”。结果就是模型永远停留在“看起来挺聪明”,但始终学不到你们团队真实的处置经验。
只有把这些反馈沉淀下来,LLM才能逐渐从“通用理解能力”走向“你们团队自己的值班经验助手”。
避坑指南
很多朋友说用大模型做告警降噪不好使,结果不准而且还非常耗费Tokens。其实,不是LLM不行,而是你的前置基础没做好,比如
1)标签不统一
如果同一服务在不同系统里叫:
checkout-apicheckout_serviceorder-checkoutsvc-checkout
那关联效果一定差。
所以必须先推进统一tagging / unified labeling。我们用OpenTelemetry语义规范的价值也在这里。
2)没有服务拓扑
没有服务依赖图,就无法做“根因抑制”,比如以下几个问题:
- DB故障导致API慢
- API慢导致网关5xx
- 网关5xx导致前端下单失败
在没有拓扑的情况下,系统可能会发30个告警,而有了拓扑后,这30个告警就能收敛成一个事件:“数据库连接池耗尽导致下游连锁异常”。
3)没有变更数据
生产上很大比例的问题跟变更相关。没有deploy / config change / feature flag事件,LLM很难把根因指向“刚发布的那次变更”。
4)没有历史闭环
没有历史事件、runbook、值班备注,LLM就只能做“看起来合理”的事件摘要,而不能做“基于你们公司真实经验”的建议。
我自己的判断
我并不认为“LLM 做告警降噪”这件事的核心竞争力在模型本身。真正的门槛其实在另外三件事:
- 你有没有比较干净的事件模型;
- 你有没有足够完整的上下文数据;
- 你有没有把自动化边界设计清楚。
模型当然重要,但更多时候,它像是一个“放大器”:
- 地基好,它能把事件收敛和人机协同做得更顺;
- 地基差,它只会把混乱包装得更像那么回事。
所以这件事最值得投入的方向,不是急着追最新模型,而是先把告警系统从“消息流”升级成“事件流”,再把 LLM 接到事件流之上。这样它才能真正发挥价值。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献213条内容
已为社区贡献213条内容

所有评论(0)