AI大模型类型、模型调用方式及Token形式介绍
Token的三种形式

Token基本以输入(命中缓存)、输入(未命中缓存)以及输出三种形式存在,它们也是大模型厂商收费的主要依据。
- 输入(命中缓存):这指的是在处理输入数据时,所需的信息已经存在于缓存中。缓存是一种临时存储,用于加速数据访问。当缓存命中时,系统可以直接从缓存中获取数据,处理速度更快,效率更高。
- 输入(未命中缓存):这指的是在处理输入数据时,所需的信息不在缓存中,需要从原始来源(如数据库或计算资源)重新获取或计算。缓存未命中会导致处理速度变慢,因为系统需要额外的时间来加载数据。
- 输出 Token:在AI模型(如语言模型)中,Token 是文本的基本单位,比如一个单词或子词。输出 Token 指的是模型生成的下一个单元,用于构建连贯的文本输出。例如,在对话生成中,模型逐个输出 Token 来形成回复。
大模型调用方式
-
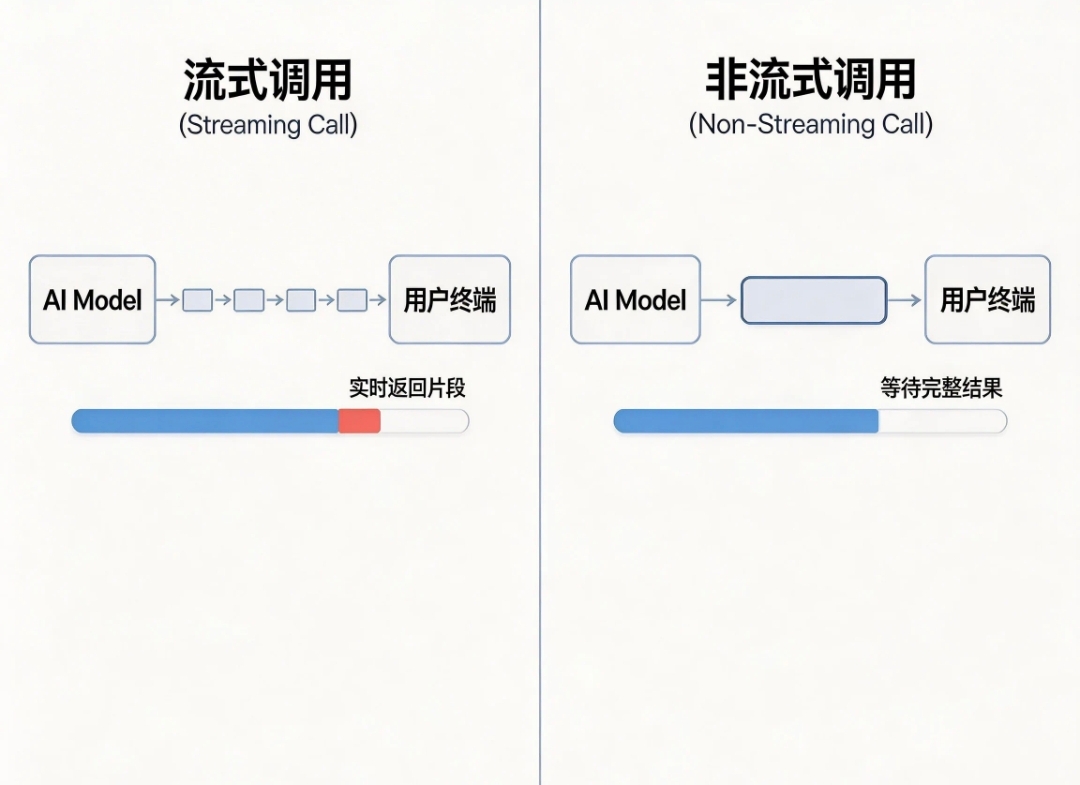
流式调用(Stream):
简单说:像打字机一样,一个字一个字蹦出来
原理:AI 一边思考生成,一边把结果分段、实时推送给你
体验:不用等完整回答,刚生成几个字就立刻显示,你能看到 “正在输出” 的过程
适用:聊天对话、长文本生成
表现:开启流式 → 回答会逐字滚动出现,不卡半天 -
非流式调用(Non-Stream)
简单说:等全部生成完,一次性给你完整答案
原理:AI 把整段话全部生成好,再一次性返回给你
体验:发送问题 → 卡住等待几秒 → 突然弹出完整一大段文字
适用:批量处理、不需要实时显示的场景 -
卷发(curl)
不是发型!是命令行里的 “浏览器 / 接口测试工具”
全称:curl(Command Line URL)
作用:在电脑终端里直接发请求测试 API(比如测试 AI 接口通不通) -
蟒蛇(Python)
就是编程语言:Python(发音像 “蟒蛇”)
作用:AI、大模型、后端开发最常用语言
AI大模型类型
-
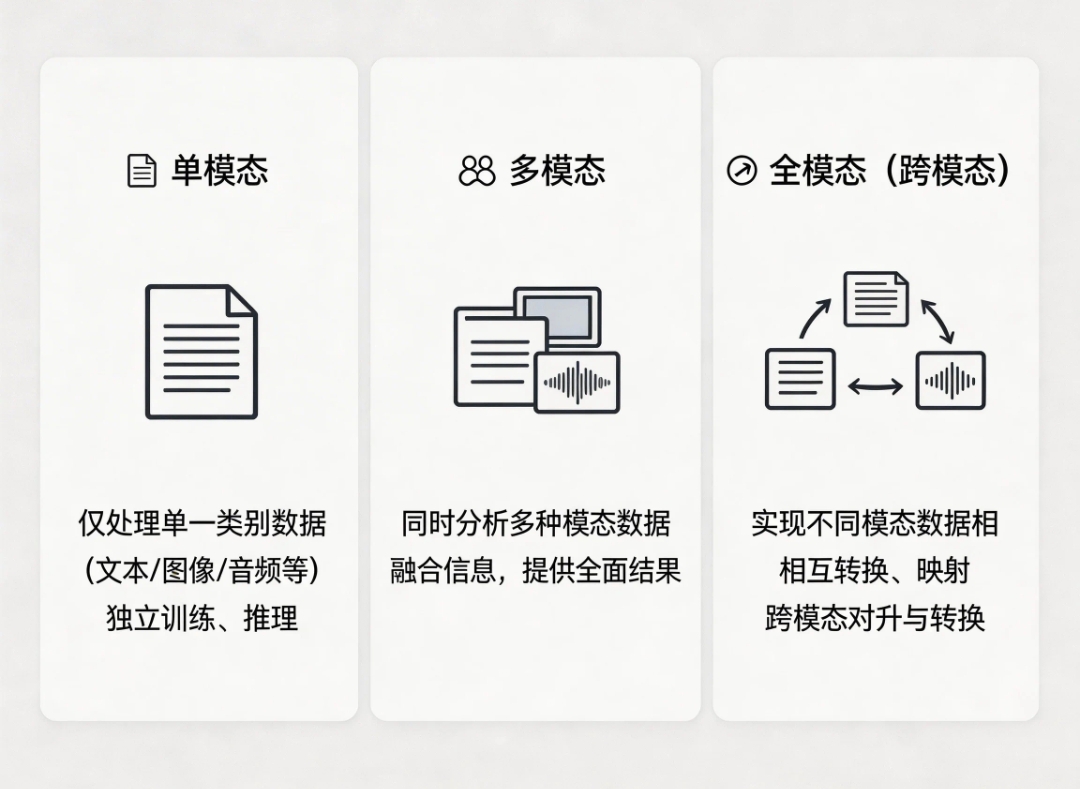
单模态
单模态学习指的就是对同一类别(文本、图像、视频、音频等)的数据进行处理、训练和推理的过程。 -
多模态
多模态学习是指同时使用或分析多种模态的数据(如文本、图像、音频等)共同处理、训练和推理,以提供更加丰富和全面的信息。 -
全模态
多模态学习关注的是两种不同模态语义对齐,而跨模态(全模态)关注的是将不同模态之间的数据进行相互转换和映射。

多模态与全模态大模型的区别
多模态与全模态都能处理文本、图像、音频、视频等多种数据形式,但核心差异在于实现方式与融合深度。
多模态模型通常是针对不同模态输入,调用各自独立的模型进行处理,再将结果在特征级或决策级进行融合。例如,文本由语言模型处理,图像由视觉模型处理,最后在融合层合并。这种方式灵活,但不同模态之间存在割裂,跨模态推理能力有限,且模块串联会带来延迟。
全模态模型则在底层架构上原生支持多种模态输入与输出,同一模型参数空间直接处理跨模态信息,无需多个独立模型拼接。例如 Qwen3-Omni、GPT-4o、Gemini 2.5 Pro 都能在同一推理流中处理语音、图像、视频,并实时生成文本或语音输出。这种方式可实现**低延迟(如 211ms)**的实时交互,并具备更强的跨模态推理能力,例如理解“视频中人物说话时为何皱眉”这类需要语音与视觉同时推理的任务。
关键对比:
架构层面:多模态是“多模型+融合”,全模态是“单模型原生支持多模态”。
推理能力:全模态可直接进行跨模态推理,多模态需依赖后期融合。
延迟表现:全模态延迟更低,适合实时交互场景。
实现复杂度:多模态工程实现相对简单,全模态需在模型训练阶段深度融合模态表示。
示例:
多模态:语音 -> 语音识别模型 -> 文本
图像 -> 图像识别模型 -> 标签
融合层 -> 最终输出
全模态:语音+图像 同时输入 -> 单一模型直接输出结果
总结来说,全模态是多模态的深度一体化升级版,在实时性、跨模态推理和交互体验上更具优势,但训练与实现难度也更高。未来随着计算与数据的进步,全模态有望成为主流。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)