这家中国公司的WAM技术闭环,比英伟达早了将近一年……
不唯VLA,三项研究夯实 WAM 基础
——范式布局,早有伏笔
2026年以来,具身智能领域围绕视觉-语言-动作(VLA)范式与世界动作模型(WAM)的路线选择,形成了值得关注的技术分野。
随着英伟达DearmZero等工作的亮相,WAM范式在零样本交互与物理一致性建模上的潜力开始引发广泛关注。
而在这一波关注持续升温之前,2025年初,拓元智慧(X-Era AI Lab)便已布局WAM这一方向——
从构建轻量级世界模拟器(DWS),到无需动作预训练的物理自回归模型(PAR),再到扩展规划视野并落地真实世界的统一框架(PhysGen),向我们展示了如何以不到10亿参数的规模,实现从世界模拟到真实物理操控的完整跨越。
本文将对这三项研究进行盘点,梳理其在动作条件化视频预测、物理知识迁移以及模型基强化学习应用等方面的主要进展。
在详解介绍每篇文章的内容之前,我们先来看一下每篇文章的核心方向以及要解决的关键问题。

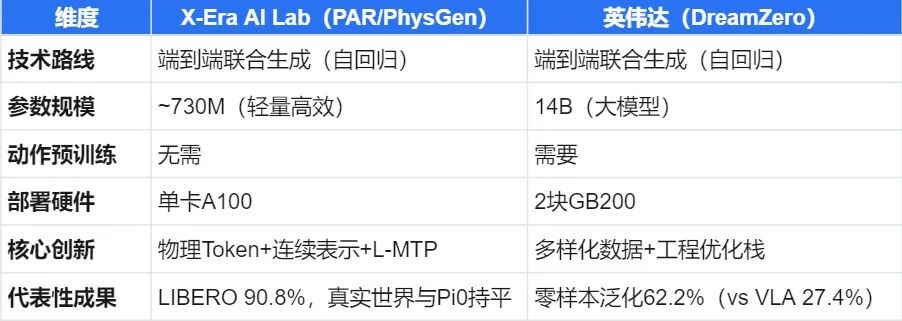
如果我们将这组工作与近期大热的英伟达DreamZero相对比,可以看出两者都坚定地走在WAM(World Action Model)的端到端联合生成路线上,都采用自回归架构,也都坚信"视频预训练优于图文预训练",但二者在技术侧重点上也呈现出了差异化布局——
英伟达选择了一条"大力出奇迹"的道路:用140亿参数和极高的硬件门槛(2块GB200)堆出极致的泛化;
而拓元智慧(X-Era AI Lab)的研究团队则通过精巧的架构设计(连续去分词器、隐式逆运动学、Lookahead-MTP),在不到10亿参数和单卡A100的算力下,实现了优异的操控性能,且完全摆脱了对大规模动作预训练的依赖。
这种从“模拟器构建”到“物理知识迁移”再到“连续交互框架”的递进,在动作精度与物理建模上展现了多元探索。
具体是如何做到的?下面,我们依次来看这三项工作的核心思路与技术迭代路径。
01 DWS:将视频模型爆改为世界模拟器
Motivation:昂贵的世界模型与被忽视的动态变化
近年来,动作条件视频模型(即世界模拟器)在强化学习中展现出巨大潜力。
然而,像Genie或GameNGen这样的模型往往需要庞大的计算资源从头训练(Genie需要256个TPU,GameNGen需要128个TPU)。直接微调现有视频生成模型虽然高效,但传统方法往往将注意力均匀分散在整个画面上。
对于需要学习"动作如何改变状态"的智能体来说,精确捕捉帧与帧之间的动态变化,远比生成完美的静态背景重要得多。
▲DWS框架概览。只需轻量化改造,预训练视频模型便能理解"动作如何改变世界",从而为强化学习提供高质量的推演环境。
技术亮点:轻量插入与运动增强
为了解决上述问题,2025年2月研究团队提出了DWS(Dynamic World Simulation)框架。
-
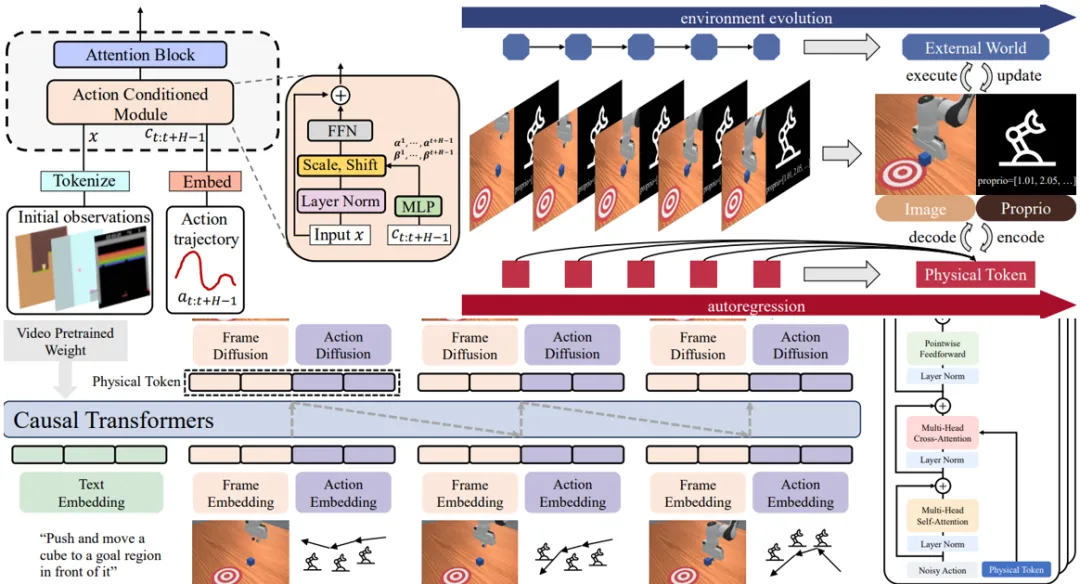
首先,设计了一个极其轻量级的动作条件模块。
这个模块仅包含两个线性层,通过简单的缩放(scale)和偏移(shift)操作,就能无缝插入到任何Transformer架构中(无论是扩散模型还是自回归模型)。这使得每个生成的视频帧都能与其对应的动作指令实现精确的帧级对齐。
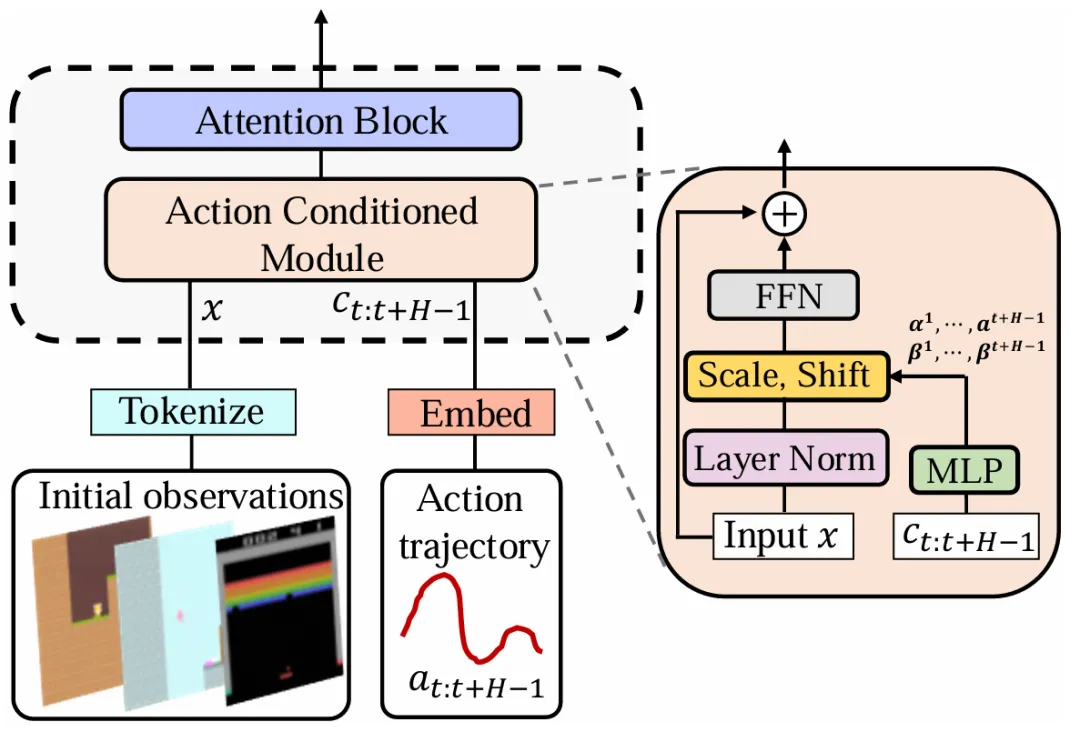
▲DWS的轻量级动作条件模块(Action Conditioned Module),以"即插即用"的方式嵌入任意Transformer架构的注意力块中。
-
其次,针对传统损失函数对静态背景过度关注的问题,DWS引入了运动增强损失(Motion-Reinforced Loss)。
通过计算连续帧之间的像素差异,模型会自动为发生变化的区域(即与动作相关的动态元素)分配更高的训练权重。这就像给模型戴上了一副"动态捕捉眼镜",强迫它忽略无关的背景细节,专注于学习动作引发的物理变化。
-
最后,为了在基于模型的强化学习(MBRL)中更好地利用这个模拟器,提出了优先化想象(Prioritized Imagination)策略。
它不再盲目地从所有初始状态开始推演,而是优先选择那些"时序差分误差(TD loss)"较大的状态进行推演,从而把计算资源用在智能体最需要学习的刀刃上。
实验表现
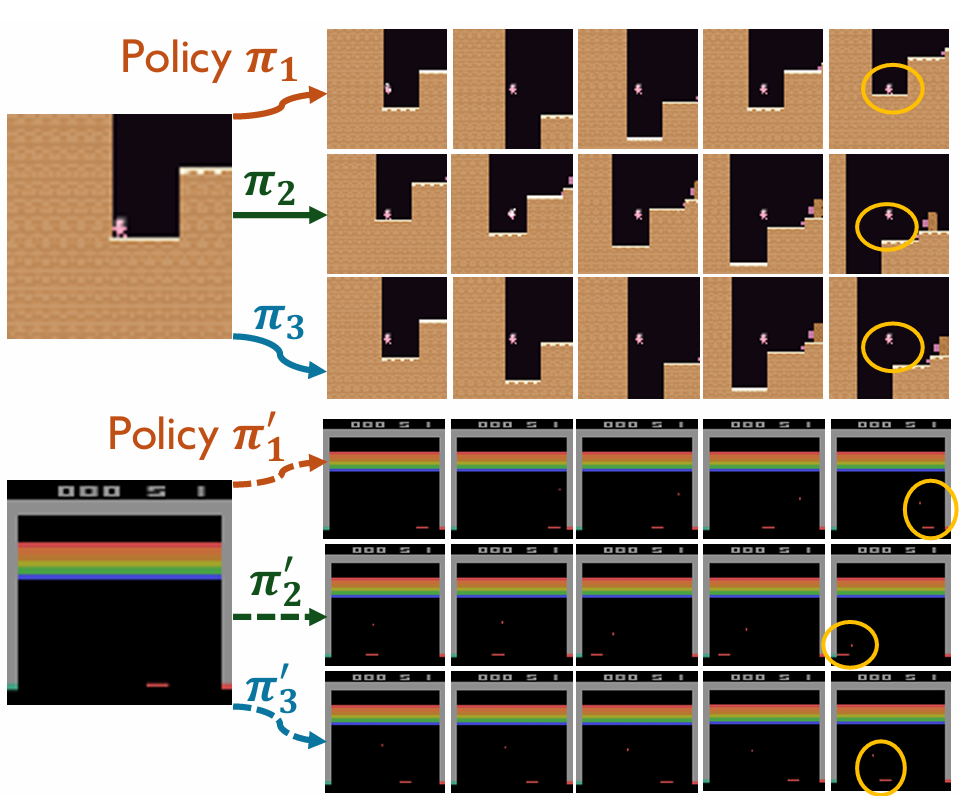
在BAIR机器人推物数据集和多个游戏环境中,DWS展现出了卓越的性能。
在BAIR数据集上,结合DWS的iVideoGPT将FVD,从11.5显著降低至9.1,PSNR(峰值信噪比)提升至43.4;
在Procgen和Atari游戏任务中,使用DWS训练的世界模拟器配合优先化想象,其强化学习累积回报显著超越了此前的SOTA方法。
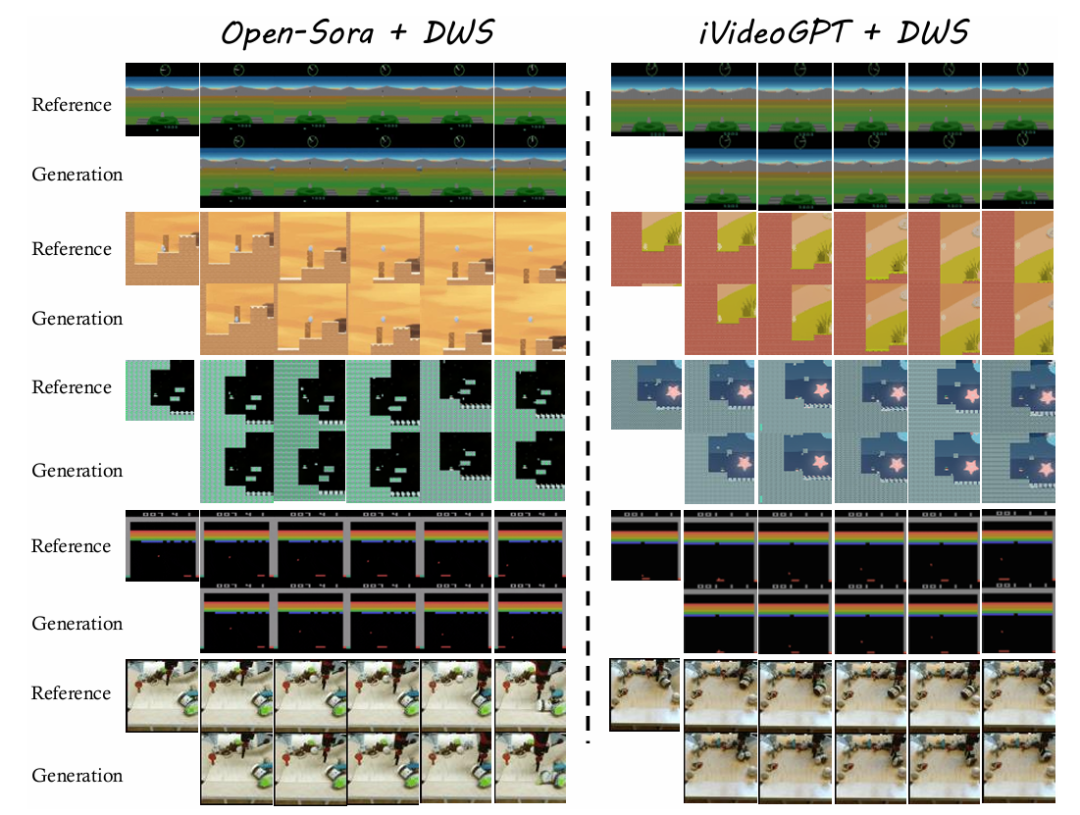
▲DWS在游戏和机器人环境中的视频生成质量对比。图中展示了Open-Sora+DWS(左)和iVideoGPT+DWS(右)在多个领域(游戏场景、机器人操控)中的生成效果。
DWS的成功证明了一件事:预训练视频模型中蕴含的物理先验,只需极其轻量的微调,就能转化为理解因果关系的"世界模拟器"。
然而,DWS主要解决的是"预测未来视频"的问题。
如果我们要让机器人真正在物理世界中执行任务,模型就必须能直接输出控制指令。
既然视频模型已经懂得了物理规律,我们能否跳过昂贵的"动作预训练"阶段,直接让它学会输出动作呢?
PAR模型给出了肯定的答案。
02 PAR:无需动作预训练的物理自回归
Motivation:离散化陷阱与动作数据的匮乏
许多自回归模型在处理图像和动作时,习惯将它们转化为离散的"词元(token)"。对于语言来说这很自然,但对于连续的物理世界,强行离散化会引入分辨率误差。
在长时序的操作中,这些微小的误差会不断累积,最终导致机器人的动作轨迹发生严重漂移。
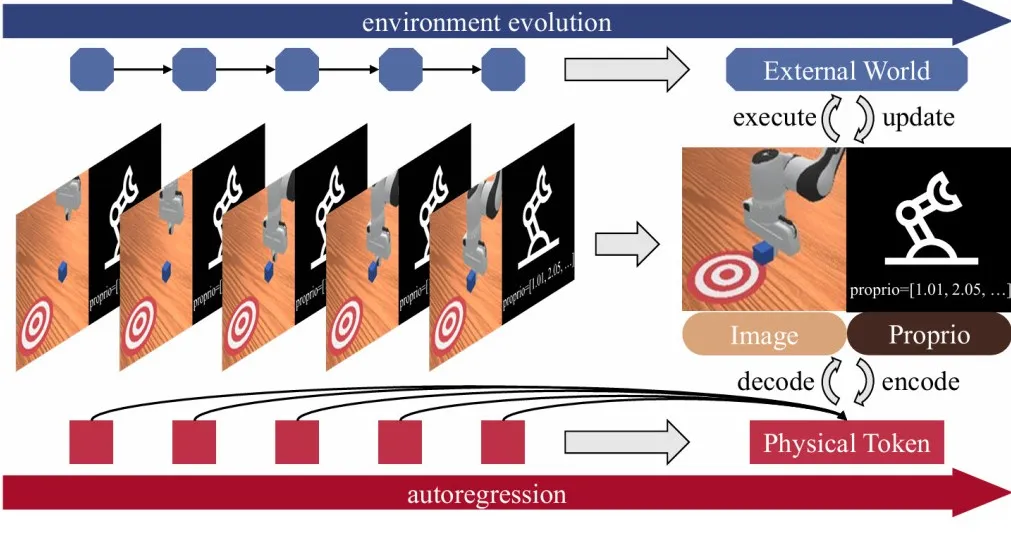
▲物理自回归(Physical Autoregression)过程示意图。
技术亮点:物理Token与连续去分词器
2025年9月研究团队提出的PAR(Physical Autoregressive Model),其核心思想是"统一"。
研究将视频帧和动作序列拼接在一起,创造了一种全新的物理Token(Physical Token)。
在这个框架下,机器人的动作和环境的视觉反馈被视为一个共同演化的整体。模型通过自回归的方式,一步步同时预测未来的世界状态和机器人的下一步动作。
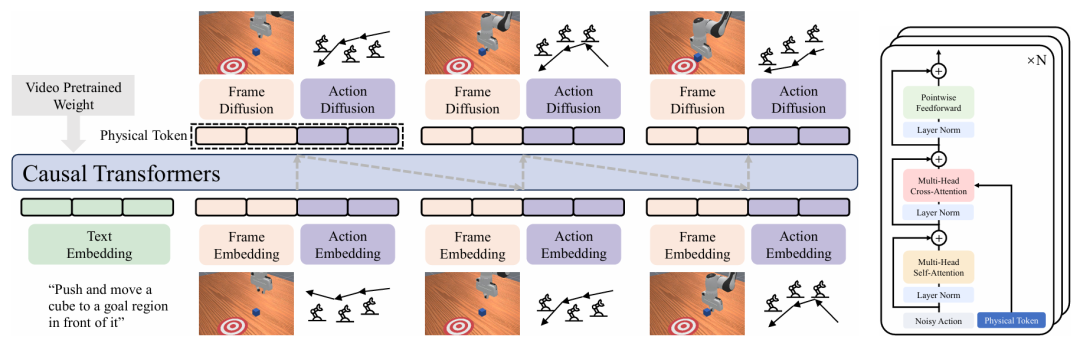
▲PAR(物理自回归模型)的整体架构。
为了彻底消除离散化带来的误差,PAR采用了一种基于扩散模型(DiT)的连续去分词器(De-tokenizer)。
它不再从固定的词表中挑选离散的动作标签,而是通过扩散去噪过程,直接在连续的向量空间中生成动作和图像分布。
这不仅保留了物理信号的连续性,还让视觉和动作两种模态在生成过程中产生了更深层次的交互。
此外,PAR在注意力机制上做了一个巧妙的设计:因果掩码与隐式逆运动学。
在预测动作时,动作Token被允许单向"看到"当前正在生成的未来帧Token。
这意味着,模型在规划动作时,实际上已经参考了它自己对未来视觉状态的预测,从而在神经网络内部隐式地完成了一次"逆运动学"求解——
即从目标状态反推出应该执行的动作序列。
实验表现
在ManiSkill基准测试中,PAR在完全没有进行动作预训练的情况下,完成三项任务。

▲PAR的视频预测与实际执行对比。
图中展示了三个任务:推方块PushCube、拾取方块PickCube、叠放方块StackCube 中,PAR预测的未来视频(上行)与机器人实际执行视频(下行)的逐帧对比。
两者之间高度的视觉一致性,可以直观地看到视频预训练知识被成功迁移到了物理操控中——
模型不仅能"想象"出正确的未来,还能据此生成精准的控制指令。
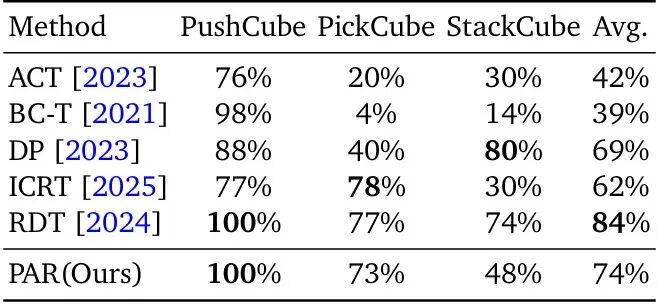
▲PAR在ManiSkill Benchymark上的量化实验结果
在PushCube任务中,PAR达到了完美的100%成功率,远超ICRT基线的77%;在三个测试任务的平均成功率达到74%,仅次于使用了海量动作数据预训练的13亿参数大模型RDT(84%)。
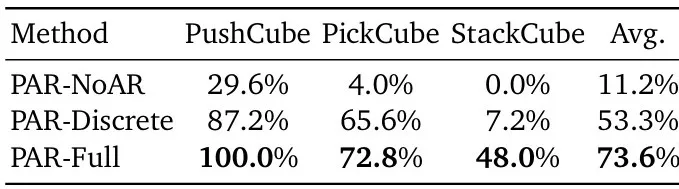
消融实验的结论尤为清晰:去掉自回归架构后性能暴跌至11.2%,而退化为离散表示后成功率也大幅下降至53.3%。
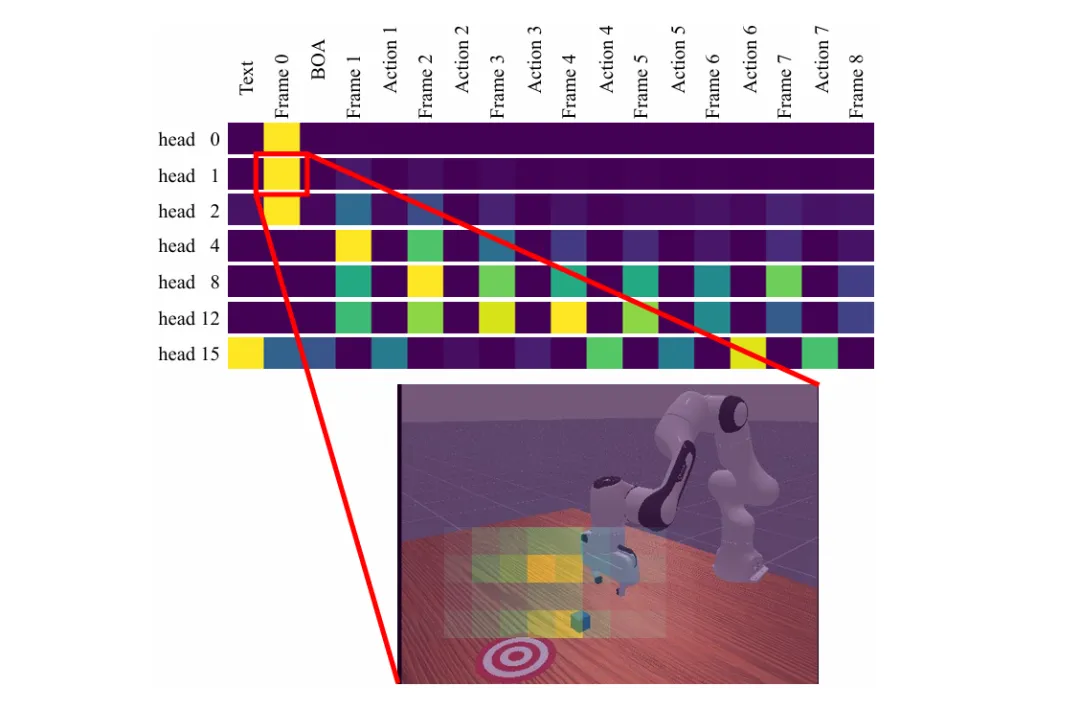
▲PAR消融实验结果与注意力可视化。
PAR通过物理Token和连续表示,成功打通了从视频预训练到机器人操控,并且在仿真环境中证明了"零动作预训练"的可行性。
但这还不够。
面对真实世界中更复杂的物理交互(如透明物体、反光表面),以及更长步骤的任务指令,模型需要看得更远、想得更深。
于是,PhysGen作为这一系列的集大成者,应运而生。
03 PhysGen:落地真实世界的统一交互框架
Motivation:长时序规划的短板与真实世界的挑战
尽管PAR在基础操控上表现优异,但传统的单步自回归预测(每次只预测下一个动作)在面对长时序任务时,往往缺乏全局规划能力,容易陷入局部最优或产生动作卡顿。
此外,仿真环境终究是理想化的,真实世界中充满了视觉歧义和复杂的物理接触。
那么,如何让基于视频先验的模型在真实物理环境中依然保持稳健?
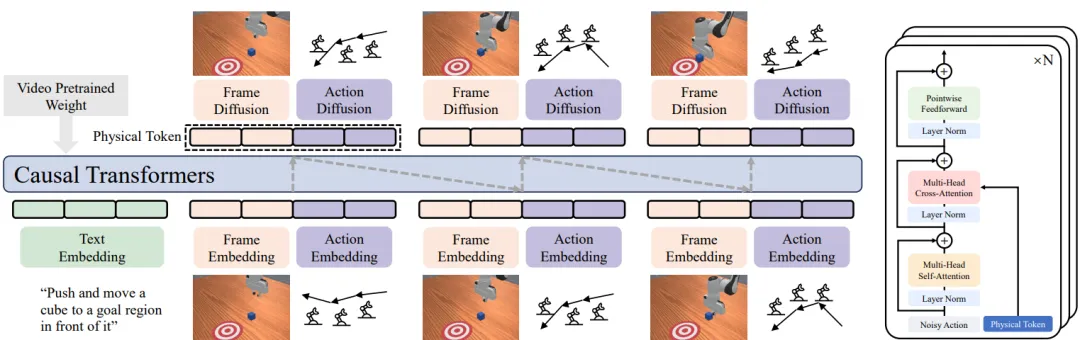
▲PhysGen框架概览。PhysGen将预训练视频生成模型重新定位为物理模拟器
技术亮点:向前看的多步预测
2026年2月PhysGen随之提出,在PAR的架构基础上,引入了一个关键升级:前瞻多Token预测(Lookahead-MTP,L-MTP)。
在每一个决策步骤中,模型的动作去分词器不再只预测下一步动作,而是并行生成未来多个时间步(3个)的动作Token。
在执行时,机器人只执行第一个动作,但剩下的预测动作会作为"前瞻(Lookahead)"信息,去指导后续的预测。这就像是开车时不仅看着眼前的几米,还提前规划好了下一个路口的走法,大大增强了动作的连贯性和长时序规划能力。
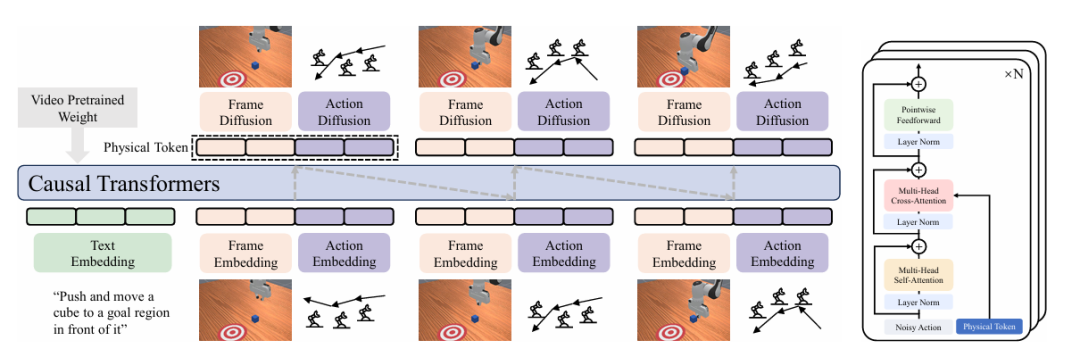
▲PhysGen整体pipeline。
同时,为了在保留视频基座模型庞大物理知识的同时高效适配各种具体任务,PhysGen采用了LoRA微调技术,并结合了KV-Cache机制来加速实时推理。
整个模型(约7.3亿参数)在单张A100显卡上只需不到60小时即可完成训练,相比于动辄需要成百上千卡集群的巨型模型,显得极为亲民。
实验表现
PhysGen在仿真和真机实验中刷新了纪录。
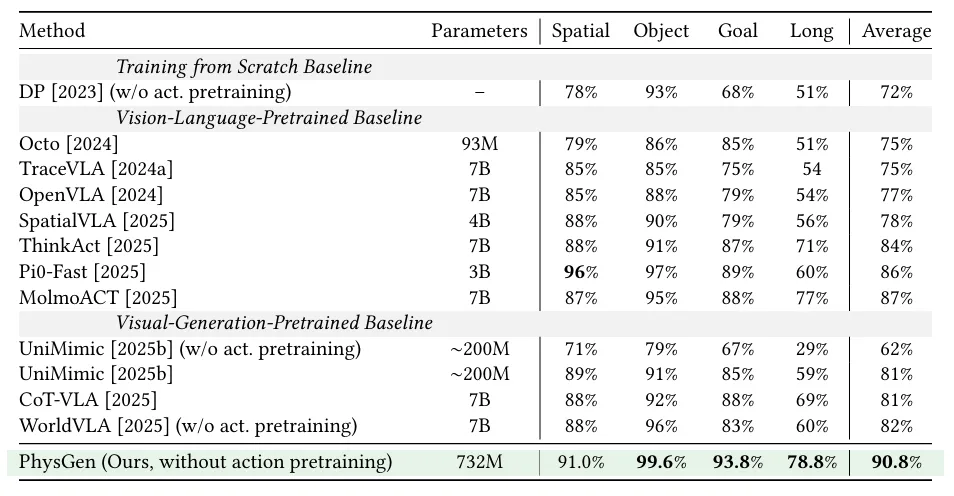
▲PhysGen在LIBERO和ManiSkill基准上的成功率对比。
在LIBERO基准中,仅732M参数的PhysGen以90.8%的平均成功率超越所有对比方法,包括70亿参数的OpenVLA(77%)和WorldVLA(82%),尤其在长时序任务(LIBERO-Long)上领先优势达18.8%(78.8% vs 60%)。
在ManiSkill基准中,PhysGen在无需动作预训练的情况下,平均成功率达74%,与依赖大规模动作数据的RDT(84%)相差无几,并在PushCube上达到完美的100%,充分体现了视频预训练物理先验的强大迁移能力。

▲在ManiSkill(a/b/c)和LIBERO(d/e)仿真环境中,PhysGen预测视频(上行)与机器人实际执行视频(下行)的高度一致性。
在真实世界部署方面,PhysGen在Franka Panda机械臂的四项任务中平均成功率达到75%,与经过大规模动作预训练的Pi0模型持平。
尤为值得一提的是,在极具挑战的"抓取透明水晶块"任务中(存在折射和反光干扰),PhysGen达到了75%的成功率,甚至略高于Pi0(70%)。

▲PhysGen在Franka Panda机械臂上的真实世界部署效果,涵盖抓取透明物体、拾取方块、按压按钮、叠放方块四项任务,蓝色圆圈标注关键操控节点,可以直观地看到视频先验知识向真实物理世界的有效迁移——即便是对折射和反光干扰极强的透明物体,PhysGen依然能够稳健完成抓取。
这证明了视频预训练赋予的强大物理直觉,能够帮助模型在视觉信息不完整的情况下,依然做出正确的物理判断。
04 总结
回顾拓元智慧(X-Era AI Lab)的这三项工作,我们可以清晰地看到了一条从"理解世界"到"改造世界"的技术演进路线。
-
DWS证明了视频模型可以低成本转化为世界模拟器;
-
PAR通过物理Token和连续表示,打通了视频先验与动作生成的桥梁;
-
而PhysGen则通过前瞻规划,让这套无需动作预训练的框架真正在复杂的物理世界中落地。
2026年,具身智能的范式转移已不可逆转。当机器人能内部推演物理世界的流转,属于具身智能的“GPT时刻”,或许就在眼前……
参考文献
[1] Pre-Trained Video Generative Models as World Simulators.
[2] Physical Autoregressive Model for Robotic Manipulation without Action Pretraining.
[3] Learning Physics from Pretrained Video Models: A Multimodal Continuous and Sequential World Interaction Models for Robotic Manipulation.

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 3
3 0
0- 0



 已为社区贡献38条内容
已为社区贡献38条内容

所有评论(0)