OCC/VLA硬核标注,核数聚破解智驾标注痛点
现如今自动驾驶领域早就卷到“能看懂场景、会自主决策”的高阶局了!数据标注作为智驾的“核心燃料”,直接决定智驾系统能不能看清路况、能不能适配复杂场景。目前,OCC占据栅格标注和VLA视觉-语言-行动标注,是破解复杂场景感知难题的两大主流手段。核数聚深耕多模态数据标注,靠着OCC+VLA双buff加持,提出高精度、高效率、高合规的全流程数据解决方案,帮助智驾模型突破场景难关!

一、OCC标注:给三维空间“画精准地图”,智驾感知更稳了
OCC标注被称为自动驾驶3D感知的“黑科技”,和传统3D标注的“画框凑数”完全不同——它把车辆周围的三维空间,拆成一个个规整的小格子(例如0.2米×0.2米×0.2米),精准标清每个格子有没有被占用、是什么,直接搭出一张高密度的三维“占用地图”。
1. 告别传统标注,复杂路况轻松应对
传统点云标注只能识别预设好的物体,碰到异形障碍、被挡住的行人和车辆,经常漏标、误标。而OCC标注主打一个“不管啥东西,只看空间占没占”,不管是复杂路况的城市道路,还是乡村土路的零碎障碍,都能精准捕捉。更关键的是,它能统一静态和动态目标,给主流智驾算法搭好标准化接口,让感知和决策配合更丝滑。
2. 核数聚OCC标注:又快又准,还能降本增效
OCC标注格子多、精度要求高,纯人工标不仅慢,成本还高到离谱。核数聚自研AI驱动的OCC智能标注系统,靠“AI预标-人工精修-多层检查”的闭环操作,直接把效率和质量拉满。
-
AI预标注:依托自研模型自动拆分点云、搞定80%基础标注,单场景标注时间从几小时压缩到几分钟,效率翻倍+;
-
多数据融合稳准狠:整合激光雷达、图像等多源数据,标注准确率稳在99.5%以上,轻松满足L4级智驾的严苛要求;
-
场景适配无死角:格子大小可灵活调整,高速、城区、封闭园区等场景全覆盖,不用反复调整参数;
-
质控+合规双保险:三级检查体系+区块链溯源,数据脱敏去标识化,安全合规不踩坑。
二、VLA标注:给场景“做翻译”,智驾更懂路况
如果说OCC标注让智驾系统“看清空间”,那VLA标注就是让它“读懂场景、明白意图”!它用大白话把驾驶场景说清楚,解析行为逻辑和风险,还能关联画面和车辆动作,让AI不仅能认出物体,还能提前预判风险,再也不是“只会识别不会思考”的呆瓜。
1. 填补极端场景空白,智驾“最后一公里”被攻克
现在大多数自动驾驶数据集,只覆盖常规道路,施工、事故、恶劣天气这些极端场景,数据少得可怜,导致智驾系统一碰到就“宕机”。VLA标注正好补了这个坑,能灵活标注这类长尾场景,靠“描述+解析+风险提示”,让模型学会应对未知情况,给智驾系统提供能直接用的决策依据。
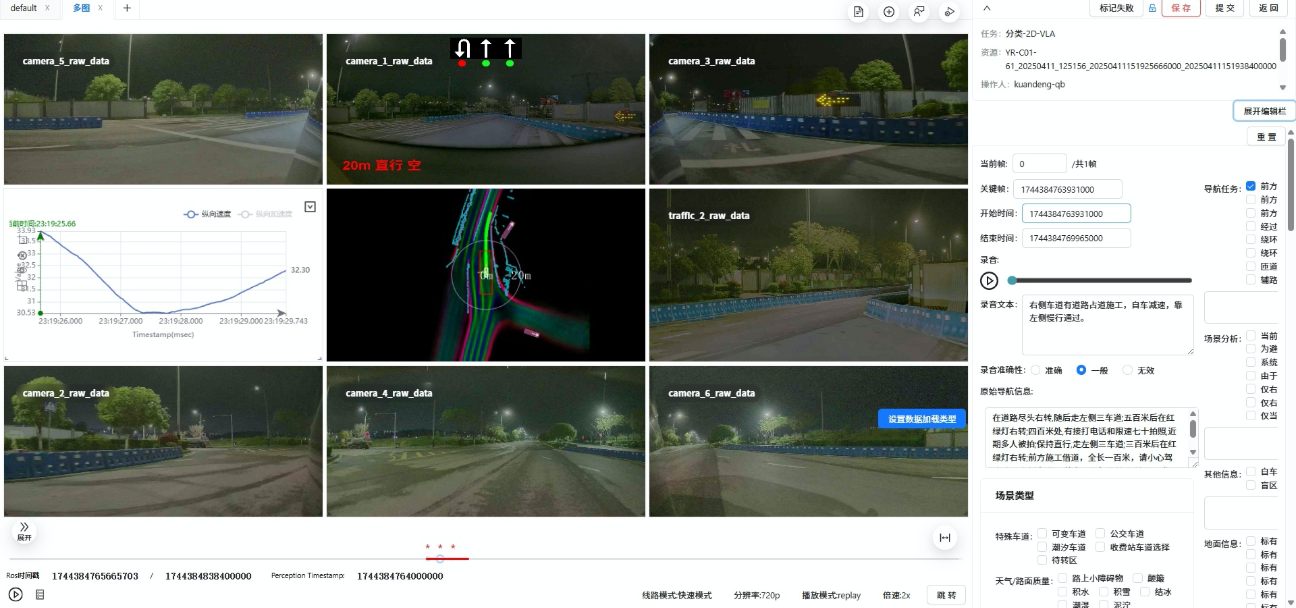
2. 核数聚VLA标注:考虑拉满、专业在线,把场景价值榨干
核数聚组建了一支专业天团,搭起“AI自动生成-人工校对-多模态对齐”的流程,搞出高质量VLA数据集,帮智驾模型实现“看清-读懂-做决策”的三连跳升级。
-
标注维度拉满:涵盖画面、语言、动作、风险四大维度,单条数据就有7类核心信息,给模型完整的场景认知逻辑;
-
标注规范不踩雷:联合高校制定标注规范,给标注人员做专项培训,杜绝表述歧义,避免模型“理解偏差”;
-
跨模态对齐丝滑:自研算法搞定多类型数据精准同步,让模型快速吃透“画面-语言-动作”的对应关系;
-
处理能力顶流:靠着千人标注团队+智能平台,能快速交付标杆级数据集,满足企业大规模极端场景的数据需求。
三、未来展望:核数聚领跑,标注技术再升级
随着智驾不断升级,数据标注也会越来越智能、精准、融合。核数聚将持续深耕赛道,升级OCC全自动标注系统,深化VLA场景推理能力,推动双技术和大模型深度融合,打造下一代智能标注体系,直接领跑行业。
数据是智驾的根基,标注是数据的灵魂。核数聚将以OCC+VLA为核心,守住优质服务的底线,持续输出高质量训练数据,助力中国自动驾驶产业在全球赛道上弯道超车,让更安全、更智能的出行照进现实!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 22
22 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)