贝叶斯优化LSTM做时间序列单输入单输出预测模型,要求数据是单列的时间序列数据,直接替换数据就可以用
贝叶斯优化LSTM做时间序列单输入单输出预测模型,要求数据是单列的时间序列数据,直接替换数据就可以用。 程序语言是matlab,需求最低版本为2021及以上。 程序可以出真实值和预测值对比图,线性拟合图,可打印多种评价指标。
一、模型概述
本模型是一套面向单列时间序列数据的预测解决方案,通过融合长短期记忆网络(LSTM)与贝叶斯优化算法,实现了从数据预处理到模型训练、参数优化、预测评估的全流程自动化。核心目标是解决传统LSTM模型依赖人工经验调参导致的效率低、精度不稳定问题,通过贝叶斯优化对关键网络参数进行智能搜索,最终输出高精度的时间序列预测结果,适用于工业数据监测、环境指标预测、经济数据趋势分析等场景。
二、核心功能模块
(一)数据预处理模块
该模块是模型运行的基础,负责将原始单列时间序列数据转化为符合LSTM网络输入要求的结构化数据,主要包含数据导入、时序重构、数据集划分、归一化处理、格式转换5个子功能,各功能协同确保数据质量与兼容性。
- 数据导入:支持读取Excel格式的单列时间序列数据文件,自动加载数据并统计样本总数量,为后续处理提供数据基础。同时,通过环境初始化操作(关闭报警信息、清空变量与命令行、关闭冗余图窗),避免历史数据或环境配置对当前模型运行的干扰,保障数据处理过程的稳定性。
- 时序重构:根据用户设定的延时步长(kim)与预测步长(zim),将一维时间序列数据重构为“多输入-单输出”的样本矩阵。其中,延时步长定义了模型用于预测的历史数据长度(如kim=15表示用前15个时间点的数据作为输入),预测步长定义了模型跨越的时间间隔(如zim=1表示预测下一个时间点的数值)。通过滑动窗口机制,自动生成包含输入特征与对应标签的样本集,实现时间序列数据的结构化转换。
- 数据集划分:按照预设的训练集比例(默认70%),将重构后的样本集分为训练集与测试集。训练集用于模型参数学习,测试集用于验证模型泛化能力。划分过程中自动计算输入特征维度(根据延时步长确定)与输出维度(固定为1,因是单输出预测),同时统计训练集与测试集的样本数量,为后续数据处理提供维度依据。
- 数据归一化:采用mapminmax算法将训练集与测试集的输入、输出数据分别归一化到[0,1]区间。该操作可消除不同量级数据对模型训练的影响(如数据范围差异导致的梯度更新失衡),同时保存输入与输出数据的归一化参数(psinput、psoutput),用于后续预测结果的反归一化,确保最终输出结果与原始数据量级一致。
- 格式转换:将归一化后的矩阵型数据转换为LSTM网络要求的单元格(cell)格式。由于LSTM网络在处理时序数据时,需以序列为单位进行输入,通过循环遍历训练集与测试集样本,将每个样本的输入特征与标签分别封装为独立的单元格元素,满足网络对输入数据结构的特殊要求。
(二)贝叶斯参数优化模块
该模块是模型的核心创新点,负责对LSTM网络的关键参数进行智能搜索与优化,解决传统调参方式效率低、易陷入局部最优的问题,通过构建优化目标函数、定义参数搜索空间、执行贝叶斯优化,输出最优参数组合。
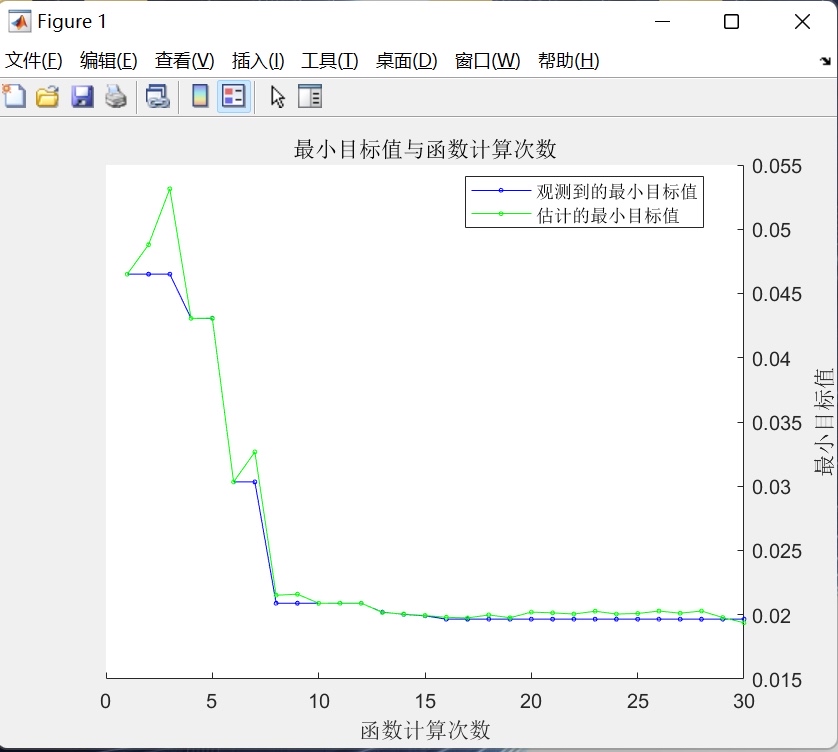
- 优化目标函数构建:以LSTM模型在训练集上的预测误差为优化目标,定义了基于均方根误差(RMSE)的成本函数。该函数首先从全局环境中获取训练集数据,根据待优化参数动态构建LSTM网络结构与训练配置,随后执行模型训练并计算预测值与真实值的RMSE,将其作为参数优化的评价指标——RMSE越小,表明当前参数组合下模型性能越优。
- 参数搜索空间定义:明确了3个对LSTM性能影响显著的关键参数及其搜索范围,兼顾参数的物理意义与模型性能需求:
- 隐藏层单元数(NumOfUnits):整数类型,搜索范围为[10,50]。该参数决定LSTM网络的特征提取能力,过少会导致欠拟合,过多易引发过拟合与计算资源浪费;
- 初始学习率(InitialLearnRate):浮点类型,采用对数变换后在[1e-3,1]区间搜索。学习率控制模型训练过程中参数更新的步长,通过对数变换确保搜索范围覆盖不同量级的学习率,避免因量级差异导致搜索不充分;
- L2正则化系数(L2Regularization):浮点类型,采用对数变换后在[1e-10,1e-2]区间搜索。该参数用于抑制模型过拟合,通过对数变换实现对极小值区间的精细搜索,平衡模型复杂度与泛化能力。 - 贝叶斯优化执行:调用贝叶斯优化算法对参数空间进行高效搜索,核心配置如下:
- 优化约束:设置最大迭代次数(30次),在保证搜索精度的同时控制计算成本;不限制优化时间,确保算法有足够时间探索参数空间;
- 搜索策略:通过“非确定性目标函数”设置,适应模型训练过程中可能存在的微小误差波动;关闭并行计算模式,适用于CPU训练环境,避免多线程资源竞争;
- 结果输出:优化过程中实时显示参数搜索状态,结束后自动筛选出使目标函数(RMSE)最小的参数组合,作为后续LSTM模型训练的最优参数。
(三)LSTM模型训练模块
基于贝叶斯优化输出的最优参数,构建并训练LSTM预测模型,是实现时间序列预测的核心执行单元,包含网络结构构建、训练参数配置、模型训练3个关键环节。
- 网络结构构建:采用分层堆叠方式构建符合回归任务需求的LSTM网络,各层功能与逻辑如下:
- 序列输入层(sequenceInputLayer):接收预处理后的时序输入数据,输入维度与数据预处理阶段确定的特征维度一致,确保数据与网络输入接口匹配;
- LSTM层(lstmLayer):采用贝叶斯优化得到的最优隐藏层单元数,负责捕捉时间序列数据中的长期依赖关系,解决传统循环神经网络(RNN)的梯度消失问题;
- 激活层(reluLayer):引入非线性变换,增强网络对复杂时序特征的表达能力,缓解线性模型的拟合局限性;
- 全连接层(fullyConnectedLayer):将LSTM层提取的高维特征映射到一维输出空间,与预测任务的单输出需求匹配;
- 回归层(regressionLayer):定义均方误差(MSE)作为模型训练的损失函数,适配时间序列回归预测任务的目标。 - 训练参数配置:基于优化后的参数与经验配置,确定模型训练的关键参数,平衡训练效率与模型性能:
- 优化算法:采用Adam优化器,该算法结合动量梯度下降与自适应学习率策略,能快速收敛且对学习率初始值不敏感;
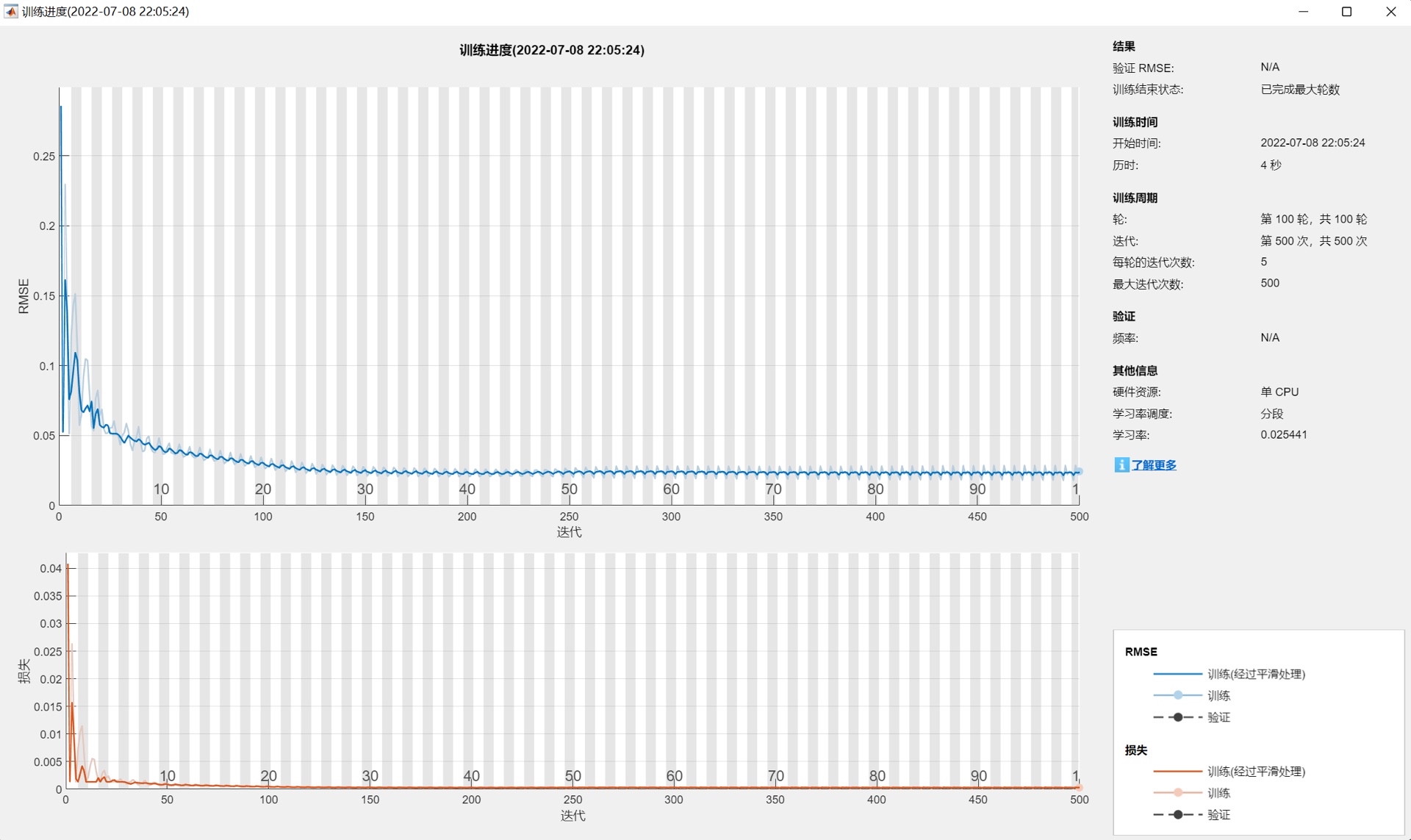
- 训练轮次:最大训练轮次(MaxEpochs)设为100,在保证模型充分学习的同时避免过度训练;
- 梯度控制:设置梯度阈值(GradientThreshold)为1,防止训练过程中出现梯度爆炸问题,保障训练稳定性;
- 学习率调度:采用分段衰减策略(piecewise),训练850次后将学习率乘以0.2的衰减因子,实现前期快速收敛、后期精细优化;
- 正则化:应用贝叶斯优化得到的L2正则化系数,抑制模型对训练集噪声的过度拟合;
- 环境与可视化:指定CPU作为训练环境(兼容无GPU的硬件配置),开启训练进度可视化功能,便于用户实时监控训练过程。 - 模型训练:加载预处理后的训练集数据,按照上述结构与参数配置启动模型训练。训练过程中,网络通过反向传播不断调整参数以最小化损失函数,直至达到最大训练轮次,最终生成训练完成的LSTM模型。
(四)预测与评估模块
该模块是模型价值输出的关键,负责利用训练完成的模型进行预测,并从多个维度评估模型性能,同时通过可视化方式直观呈现预测结果与误差分布。
- 预测执行:分别对训练集与测试集数据进行预测,生成模型输出的预测值。由于预测值是经过归一化处理的结果,需调用数据预处理阶段保存的归一化参数(ps_output),对预测值进行反归一化操作,将结果恢复到原始数据的量级,确保预测结果的实际意义。
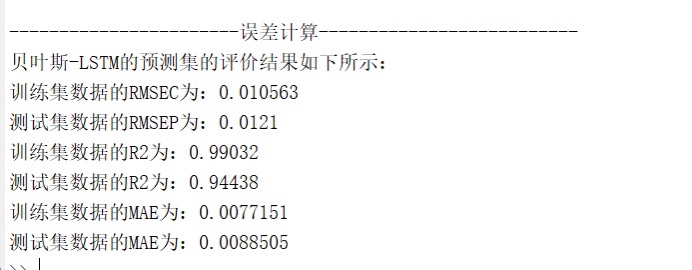
- 性能指标计算:从误差大小、拟合程度两个维度,计算4项核心评价指标,全面衡量模型性能:
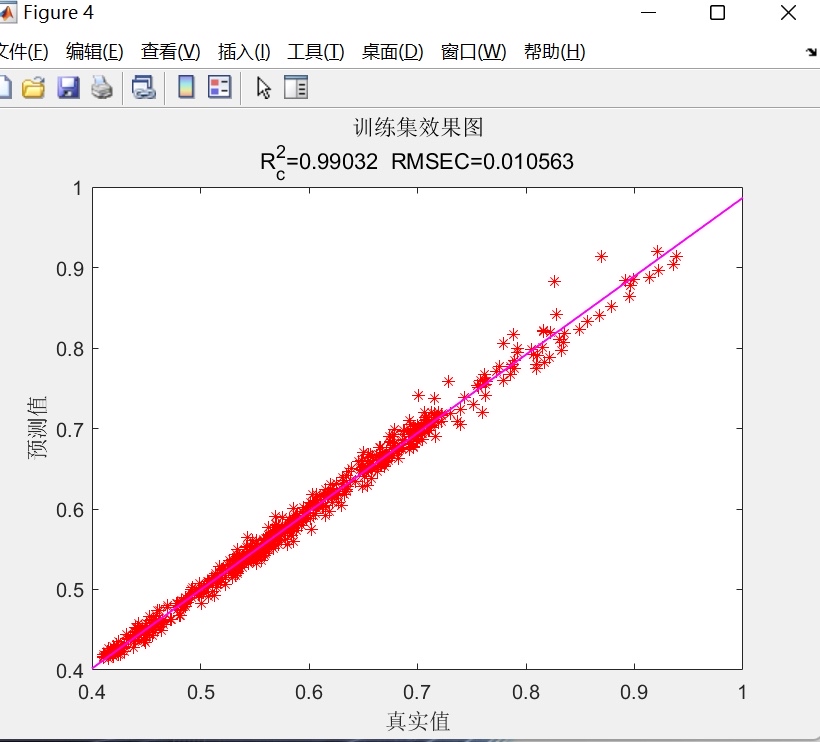
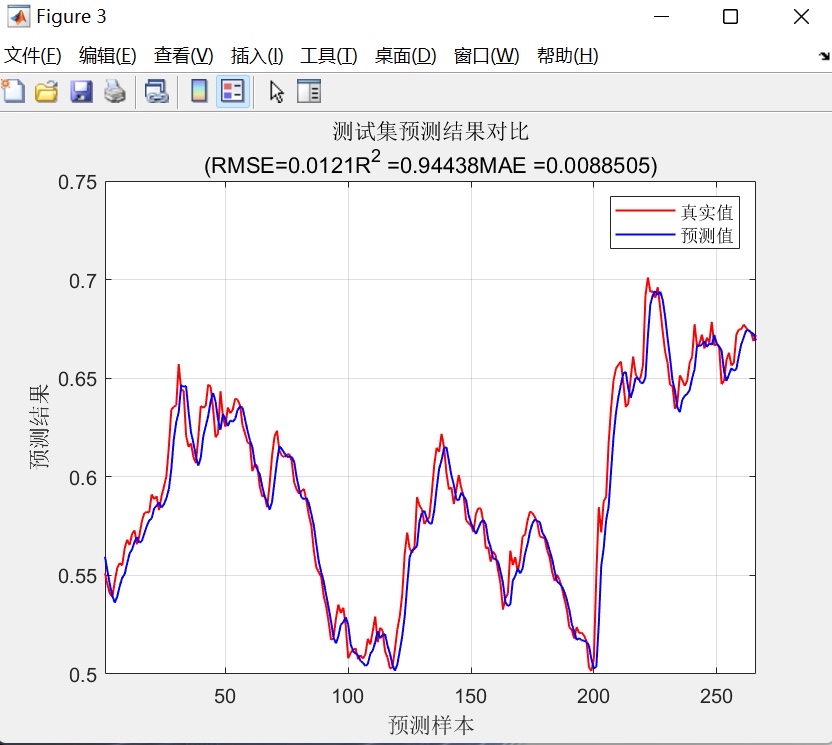
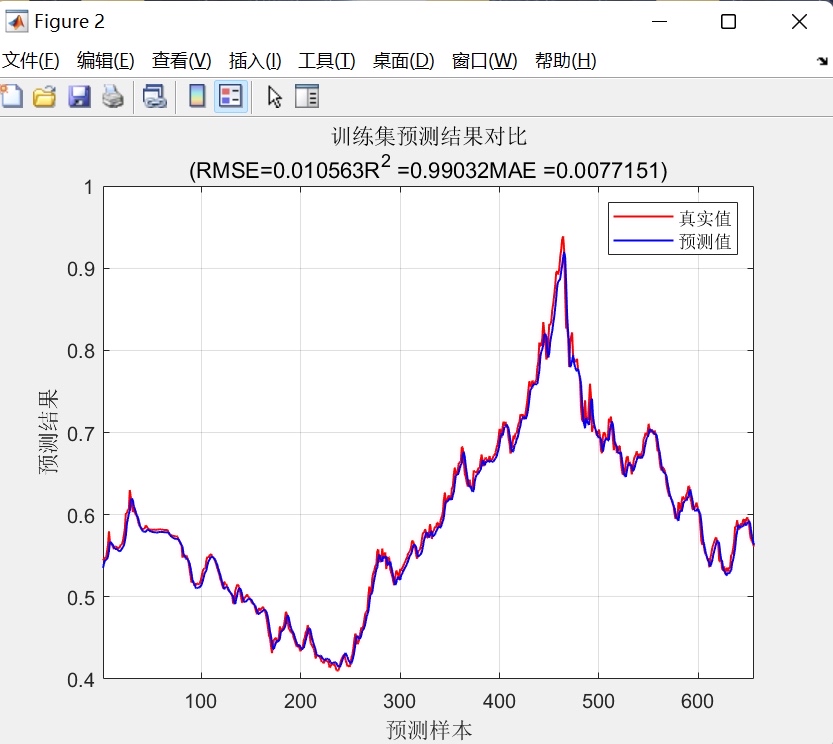
- 均方根误差(RMSE):反映预测值与真实值的整体偏差程度,RMSE越小表明模型误差越小;分别计算训练集(RMSEC)与测试集(RMSEP)的RMSE,用于评估模型在训练数据与未知数据上的误差水平;
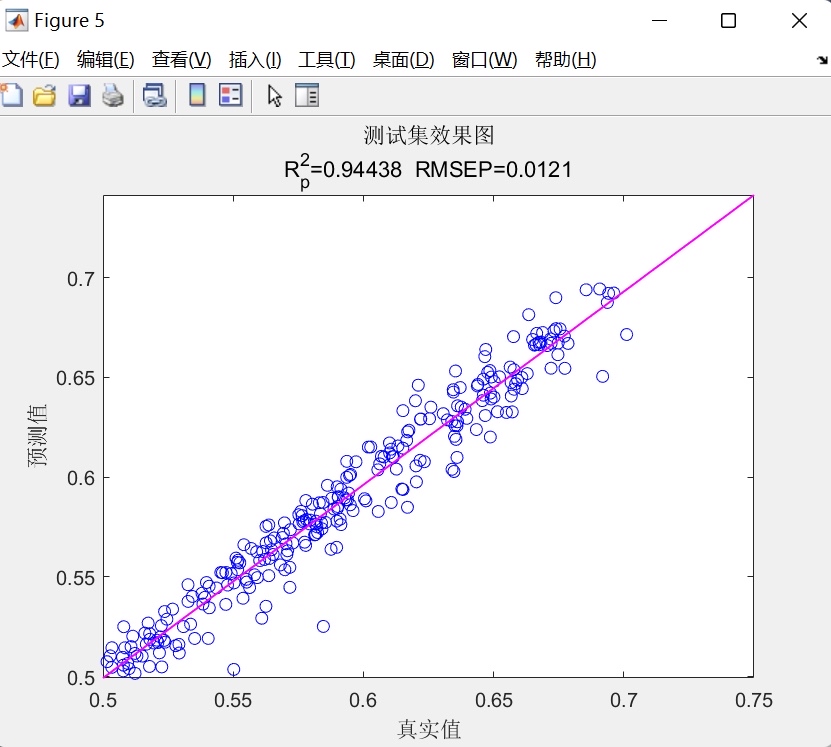
- 决定系数(R²):衡量模型对数据变化趋势的解释能力,R²越接近1表明模型拟合效果越好;同样区分训练集与测试集R²,评估模型的泛化能力;
- 平均绝对误差(MAE):反映预测值与真实值的平均绝对偏差,相较于RMSE更能规避极端异常值的影响,作为误差评估的补充指标;
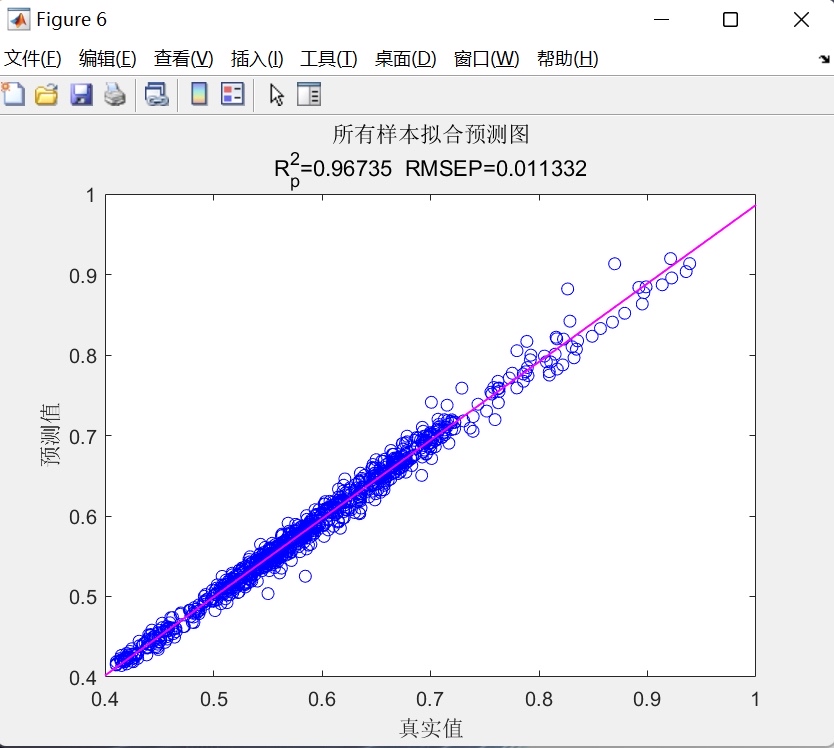
- 整体平均指标:计算训练集与测试集RMSE、R²的平均值,综合评价模型在全量数据上的整体性能。 - 可视化呈现:通过6类图表直观展示预测结果与模型性能,便于用户快速理解模型效果:
- 预测结果对比图:分别绘制训练集、测试集的真实值与预测值曲线,直观展示两者的吻合程度;
- 线性拟合图:分别绘制训练集、测试集、全量数据的“真实值-预测值”散点图,并添加线性拟合线,通过散点分布与拟合线斜率,判断模型的拟合效果;
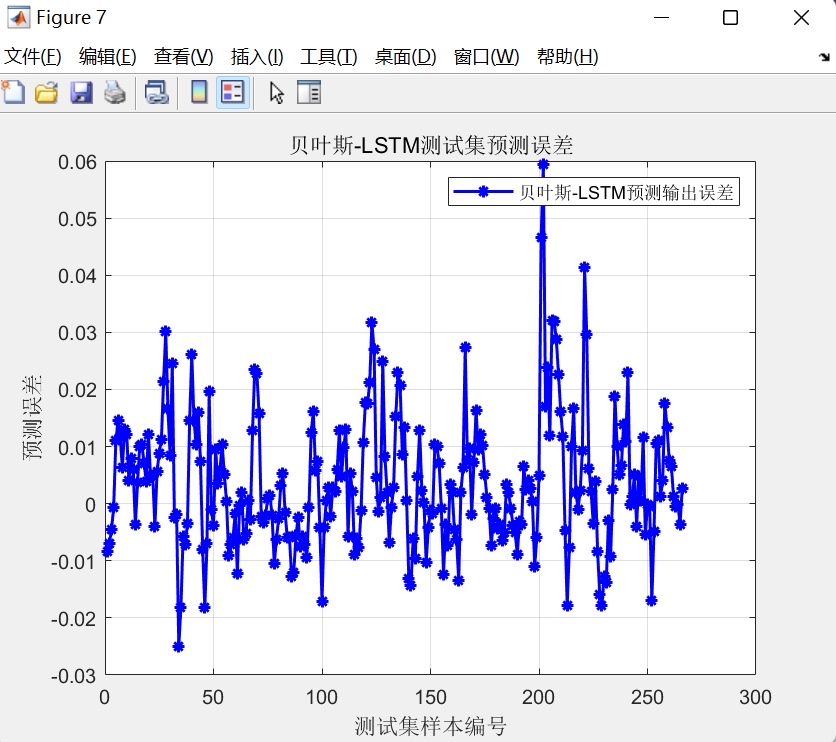
- 误差分布图:绘制测试集每个样本的预测误差(真实值-预测值),展示误差的波动范围与分布规律,帮助用户识别误差较大的样本区间。 - 结果输出:在命令行窗口打印所有评价指标(RMSEC、RMSEP、训练集R²、测试集R²、训练集MAE、测试集MAE),同时保存所有可视化图表,为用户提供完整的模型性能报告,支持后续分析与决策。
三、模型优势与适用场景
(一)核心优势
- 参数优化智能化:通过贝叶斯优化替代人工调参,可在预设参数空间内高效搜索最优组合,避免因经验不足导致的参数配置不合理问题,同时减少调参时间成本,提升模型开发效率;
- 数据处理自动化:从数据导入到格式转换的全流程无需人工干预,支持用户直接替换Excel数据文件即可运行,降低使用门槛,适用于非专业技术人员;
- 性能评估全面化:融合RMSE、R²、MAE三类指标与多维度可视化图表,从定量与定性两个层面评估模型性能,结果呈现直观、可靠;
- 兼容性强:支持CPU训练环境,无需依赖GPU硬件,可在普通计算机上运行;同时支持自定义延时步长、预测步长、训练集比例等参数,适配不同时间序列预测场景的需求。
(二)适用场景
- 工业监测预测:如设备运行温度预测、生产过程中关键工艺参数(如压力、流量)的趋势预测,帮助提前发现异常并调整生产策略;
- 环境指标预测:如空气质量指数(AQI)、降雨量、温度等环境数据的短期预测,为环保决策、灾害预警提供数据支持;
- 经济数据分析:如股票价格、商品销量、GDP增速等经济指标的短期趋势预测,辅助投资决策与经营规划;
- 其他单列时序场景:所有符合“单列时间序列、需基于历史数据预测未来值”的场景,均可通过替换数据文件直接使用模型。
四、使用说明与注意事项
(一)使用流程
- 准备Excel格式的单列时间序列数据文件,命名为“数据集.xlsx”,确保数据无缺失值、异常值(建议预处理前进行数据清洗);
- 根据预测需求,调整代码中延时步长(kim)、预测步长(zim)、训练集比例(num_size)的数值;
- 运行主程序,模型将自动完成数据预处理、贝叶斯参数优化、LSTM模型训练、预测与评估;
- 查看命令行窗口的评价指标与生成的可视化图表,分析模型性能。
(二)注意事项
- 数据要求:输入数据必须为单列时间序列,若存在多列数据需提前筛选目标列;数据中若存在缺失值或异常值,需先进行填充(如均值填充、插值填充)或剔除,否则会影响模型性能;
- 参数调整建议:延时步长(kim)需根据数据的时间相关性确定(如日度数据可尝试10-30的范围),过短会导致特征不足,过长会增加计算量;预测步长(zim)建议设置为1-5,步长过大易导致预测精度下降;
- 计算资源:贝叶斯优化过程(最大迭代30次)与LSTM训练(100轮)均需一定计算时间,若数据量较大(如样本数超过10000),建议适当减少贝叶斯优化迭代次数或LSTM训练轮次,平衡精度与效率;
- 结果解读:若测试集R²远低于训练集R²(如差值超过0.2),可能存在模型过拟合问题,可尝试增大L2正则化系数或减少LSTM隐藏层单元数;若RMSE过大,可调整延时步长或检查数据质量。
贝叶斯优化LSTM做时间序列单输入单输出预测模型,要求数据是单列的时间序列数据,直接替换数据就可以用。 程序语言是matlab,需求最低版本为2021及以上。 程序可以出真实值和预测值对比图,线性拟合图,可打印多种评价指标。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献49条内容
已为社区贡献49条内容

所有评论(0)