6B模型超越Nano Banana 2!上海AI实验室让画图模型有了记忆和技能包
当前的AI生图模型已经非常强,即使普通电脑就能跑的6B小模型,生图性能也堪称惊艳。
但当你输入一段包含多个主体、特定空间位置,或是要求精确生成字符的复杂指令时,哪怕是行业里顶尖闭源模型,也不尽如人意。
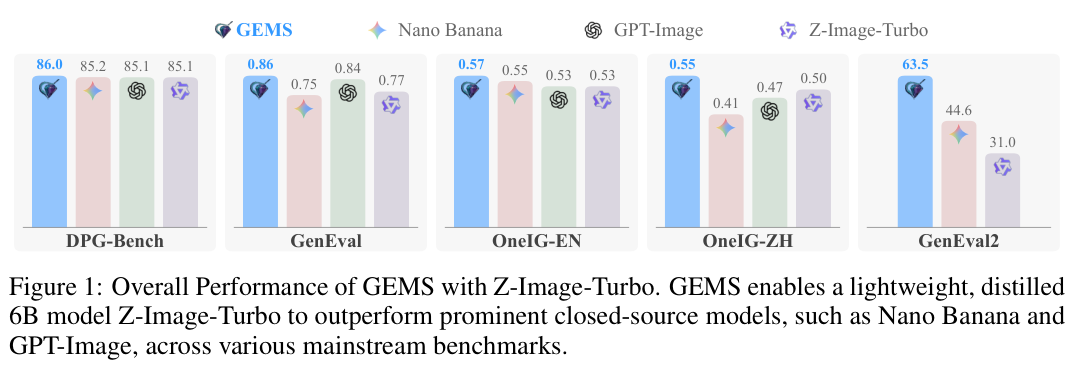
一款仅有6B参数规模的轻量级开源模型Z-Image-Turbo,在引入了名为GEMS的技术后,竟然在极具挑战性的复杂任务评测中,得分大幅超越了行业顶流的闭源巨头大模型Nano Banana 2。
GEMS全称:Agent-Native Multimodal GEneration with Memory and Skills,带有记忆与技能的智能体原生多模态生成框架。由上海AI实验室,南京大学,上海交通大学和香港中文大学团队联合打造。

GEMS框架通过创新构建多智能体闭环优化策略、剔除冗余信息的层次化记忆网络,以及能够按需加载的专业技能包,重构了人工智能单一前向生成的底层逻辑,赋予了模型自我反思、持续进化与精细把控画面的卓越能力。
告别盲盒出图的多智能体循环协同
在现有的技术生态中,绝大多数文本到图像的生成模型,都采用了简单直接的单次推理模式。
用户给出提示词,模型经过内部复杂的注意力机制与扩散计算,一次性输出最终结果。
对于日常的风景或简单的人物特写,上述传统模式游刃有余。面对复杂多面的长尾任务指令时,模型往往难以在一次运算中同时兼顾语义准确性与结构约束。
为了打破单次生成的固有局限,推理期扩展技术逐渐成为学术界与工业界关注的焦点。
早期的优化尝试大多依赖于简单的提示词重写或是盲目的随机搜索,既无法提供精准的优化方向,也极大地消耗了宝贵的计算资源。
GEMS框架的设计思路跳出了传统算法修补,直接从当下极为先进的大语言模型智能体架构中汲取灵感,构建了一个名为Agent Loop(智能体循环)的核心骨干模块。
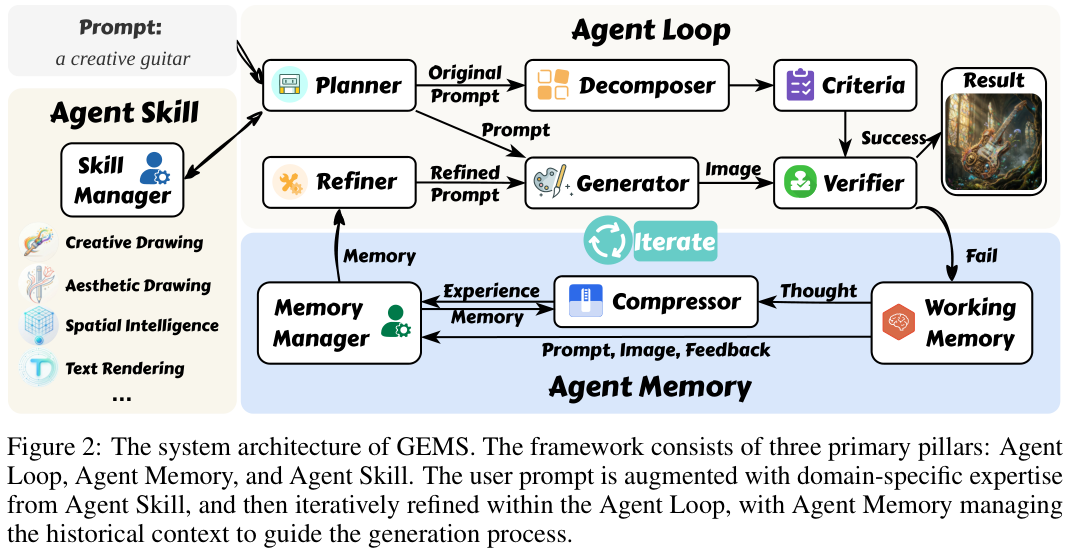
该模块将图像生成过程巧妙地转化为一个多角色协同的闭环优化流水线。
在处理流程的开端,Planner(规划器)作为整个系统的战略大脑,会细致地分析用户输入的初始提示词,并尝试从技能库中检索匹配的专业知识,以此合成一个具备更强引导力的基础提示词。
紧接着,Decomposer(分解器)会将用户复杂的原始指令拆解为一系列原子化的视觉要求。
每一项要求都被转化为一个简单的二元探测节点,例如画面中是否包含红色的汽车、背景是否为赛博朋克风格、文字拼写是否完全一致等。
原子化拆解,为后续的精准评估建立了一个极其严苛且量化的审核标准体系。
Generator(生成器)随后根据当前优化好的提示词完成图像的初步渲染。
此时,充当质检员的Verifier(验证器)正式登场。验证器通常由能力强大的MLLM(多模态大语言模型)驱动,在研究中使用了Kimi K2.5作为底层支持。
验证器会将生成的图像与此前设定好的原子标准进行逐一比对,并输出一份详尽的二进制反馈向量。
只要有一项标准未达标,系统就不会轻易妥协,而是将诊断反馈迅速传递给Refiner(优化器)。
优化器会像一位经验丰富的艺术指导,深度分析当前的画面缺陷与历史迭代轨迹,敏锐地指出生成器在理解上的偏差,并重新编写更加聚焦的提示词进入下一轮循环。
循环往复的打磨机制,彻底根除了单模型容易遗漏细节的通病。
剔除冗余信息的层次化记忆引擎
在多轮迭代的智能体系统中,如何妥善管理历史上下文信息,一直是个棘手的技术难题。
先前的部分多智能体视觉框架,例如Maestro,往往只关注前一次的生成结果,或是仅仅保留历史最佳状态,缺乏对整个生成轨迹的全局视野。
另一些采用迭代逻辑的方法则走向了另一个极端,直接将所有历史提示词、反馈意见和图像简单粗暴地堆砌在内存中。
无节制的信息累加会导致系统在多轮对话后面临严重的认知超载,不仅大幅增加了计算成本,还会让大语言模型在海量的冗余细节中迷失方向,进而产生灾难性的遗忘。
为了从根本上解决信息密度与处理效率之间的矛盾,研究团队为GEMS量身定制了Agent Memory(智能体记忆)模块。
该模块不再采用机械式的上下文堆叠,而是引入了一种极具创新性的层次化压缩策略,将系统在每一轮迭代中产生的状态数据严格划分为两个截然不同的层级。
第一个层级被定义为事实基准锚点。
其中包括每一轮使用的具体提示词、实际生成的图像以及量化的验证反馈结果。上述数据点具备体积小、客观性强、信息密度极高的特征,系统会将它们以最原始的形态完整归档,以此确保历史记录的绝对准确性。
第二个层级则涉及对高阶经验的提炼与压缩。
在每一次优化决策的过程中,多模态大语言模型都会产生大量的内部推理轨迹与思考链条。未经处理的原始推理日志往往冗长且充满重复性的废话,直接塞给优化器只会造成严重的干扰。
基于此,GEMS专门配备了一个Compressor(压缩器)组件。压缩器宛如一位精通归纳总结的学霸,能够从海量繁杂的推理步骤中,精准萃取出简明扼要的高级经验总结。
系统最终会将事实基准锚点与提炼后的高级经验打包组合成一个混合状态元组。通过归档经过层次化压缩的表征数据,该系统有效剔除了信息噪音,同时为优化器提供了一个极其稳健、覆盖全局的长上下文决策基础。
在极具挑战性的GenEval2上开展的消融实验,清晰地印证了层次化记忆引擎的巨大价值。

单纯采用基础的智能体循环只能将模型的基准分数从31.0分提升至52.4分。
加入仅包含历史提示词与反馈的基础记忆后,分数随即上涨了3.4分。
进一步引入历史生成图像的视觉上下文后,分数又攀升了3.1分。
不过,当研究人员尝试将未经处理的完整思考链条直接塞入记忆池时,系统性能几乎停滞不前。反而是利用压缩器提炼出核心经验后,系统再次迎来了2.5分的显著跃升,最终确立了强大的性能优势。
按需灵活加载的专属领域技能库
通用大模型在面对具有极高专业壁垒的垂直下游应用场景时,会显得力不从心。诸如学术图表绘制、特定风格的创意插画或是排版严谨的文字海报等任务,都需要模型具备高度专业化的领域知识与特殊的空间布局逻辑。
过去,学术界解决特定领域生成难题的通用做法是开发孤立的、只针对单一任务优化的专用系统。
孤立系统由于采用了高度定制化的协同机制,极难与现有的主流生成管线无缝整合,导致整个技术生态变得越来越碎片化。
GEMS通过引入Agent Skill(智能体技能)模块,提供了一种优雅且极具扩展性的破局方案。
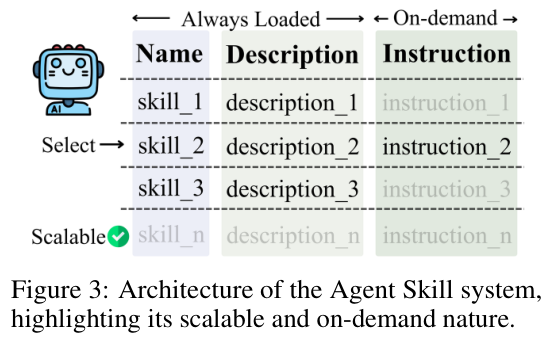
该模块本质上是一个按需加载、渐进式暴露的专业领域知识库。
为了将系统的认知负荷与计算开销降到最低,GEMS巧妙地借鉴了现代软件工程中的依赖管理理念。
在系统日常待机状态下,内存中仅仅保留一份极其轻量级的技能清单,里面只记录了各项技能的名称与基础功能描述。
当用户提交一条涉及专业领域的提示词时,规划器会迅速在轻量级清单中进行意图匹配。
一旦确认触发了某项特定技能,系统才会在进入实质性的迭代循环之前,将该技能背后海量且密集的专业指令规则完整拉取到内存中,并将其与原始提示词进行深度融合。
按需加载的精巧设计直接赋予了GEMS无与伦比的可扩展性与极高的用户友好度。
对于想要为系统贡献新技能的开发者或普通用户而言,使用门槛被无限拉低。
人们完全不需要去深究GEMS底层复杂的运行机制与代码逻辑,只需简单地编写一个包含特定领域规范的Markdown文本文件,系统就能自动解析、理解并激活全新的专业技能。
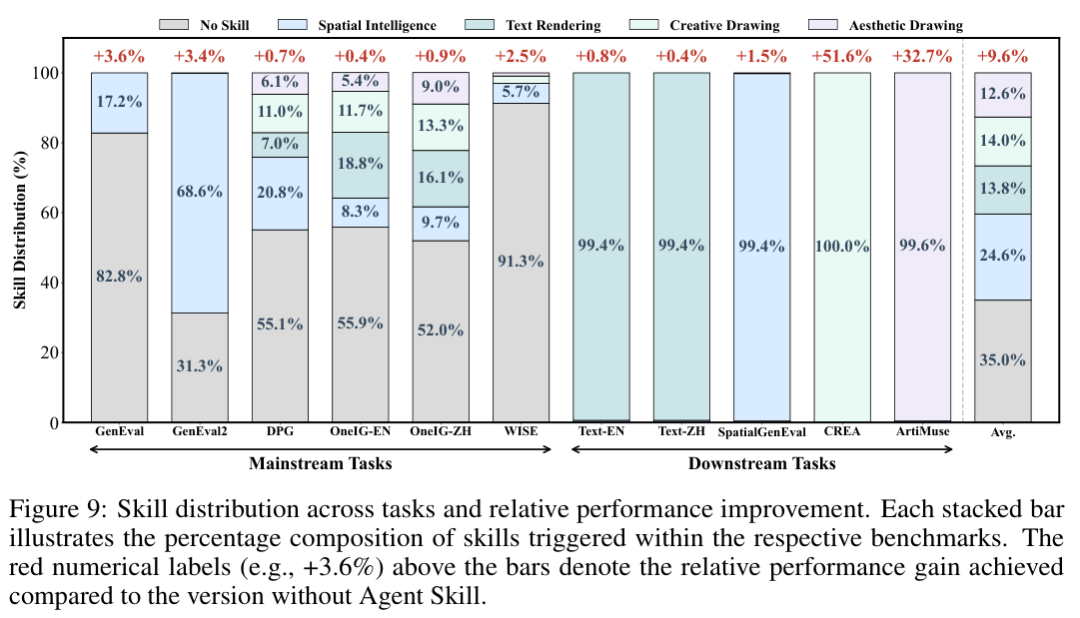
在此次研究的评测环节中,研究团队特意配置了包括创意手绘、唯美审美插画、精确文字渲染以及空间智能布局在内的四项核心技能。

结果显示,系统在面对特定下游任务时,能够精准无误地自主调用对应的技能模块,大幅改善了最终图像的视觉张力与专业构图水准。
跨越参数壁垒的评测数据与洞察
为了全面检验GEMS框架在真实场景下的泛化能力与性能天花板,研究团队精心设计了一场横跨九大不同维度的严苛考核,涵盖了五个主流的通用评估基准,以及四个聚焦专门领域的下游应用任务测试。
评测不仅选用了主打轻量高效的60亿参数模型Z-Image-Turbo,还引入了拥有200亿参数规模的代表性开源模型Qwen-Image-2512,以此验证智能体框架在不同架构与算力体量下的普适性。
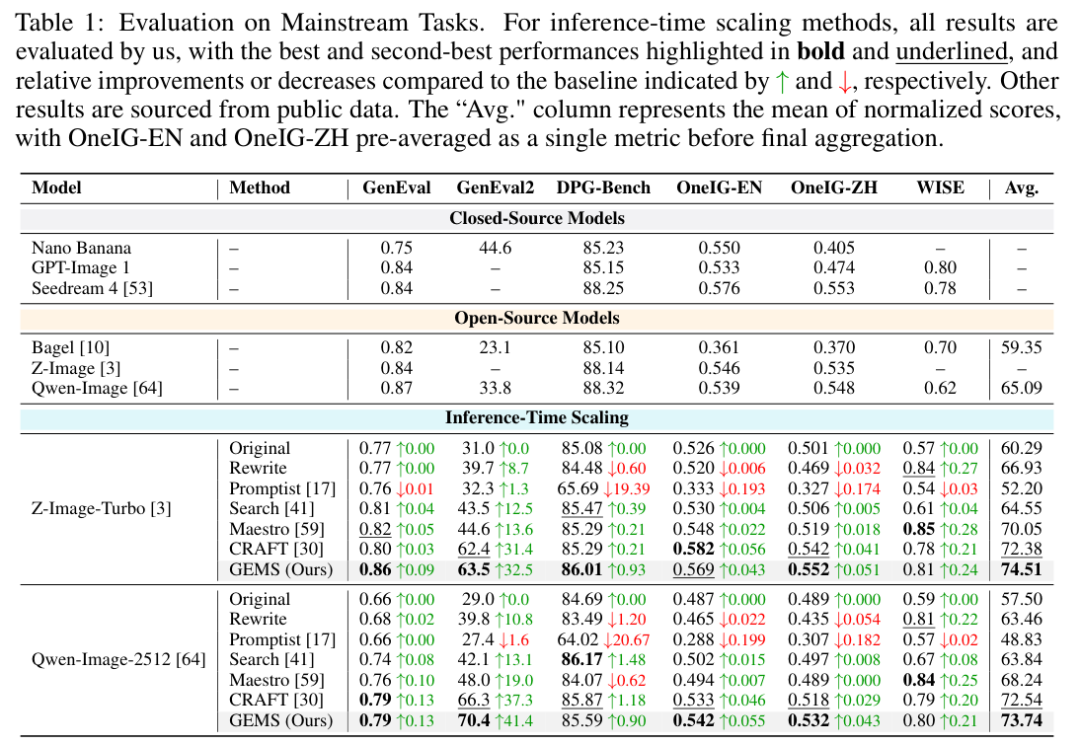
在通用能力评测板块,GEMS赋能下的Z-Image-Turbo展现出了令人赞叹的稳定性与爆发力。
相比于传统的单次生成以及各类早期的推理期扩展基准方法,该框架在各大排行榜上的归一化平均得分猛增了14.22分。
在专为测试复杂多条件指令服从度而设立的GenEval2榜单上,Z-Image-Turbo更是拿下了63.5分的高分,不仅将此前该领域的最佳扩展基准方法甩在身后,更在绝对数值上实现了对闭源巨头Nano Banana 2的强势超越,后者的得分仅为44.6分。
百亿级别参数的开源基础模型在智能体逻辑的加持下,完全有能力突破自身原本的容量瓶颈,激发出超越超级大模型的无穷潜能。
在下游专项领域测试中,GEMS的优势被进一步放大。
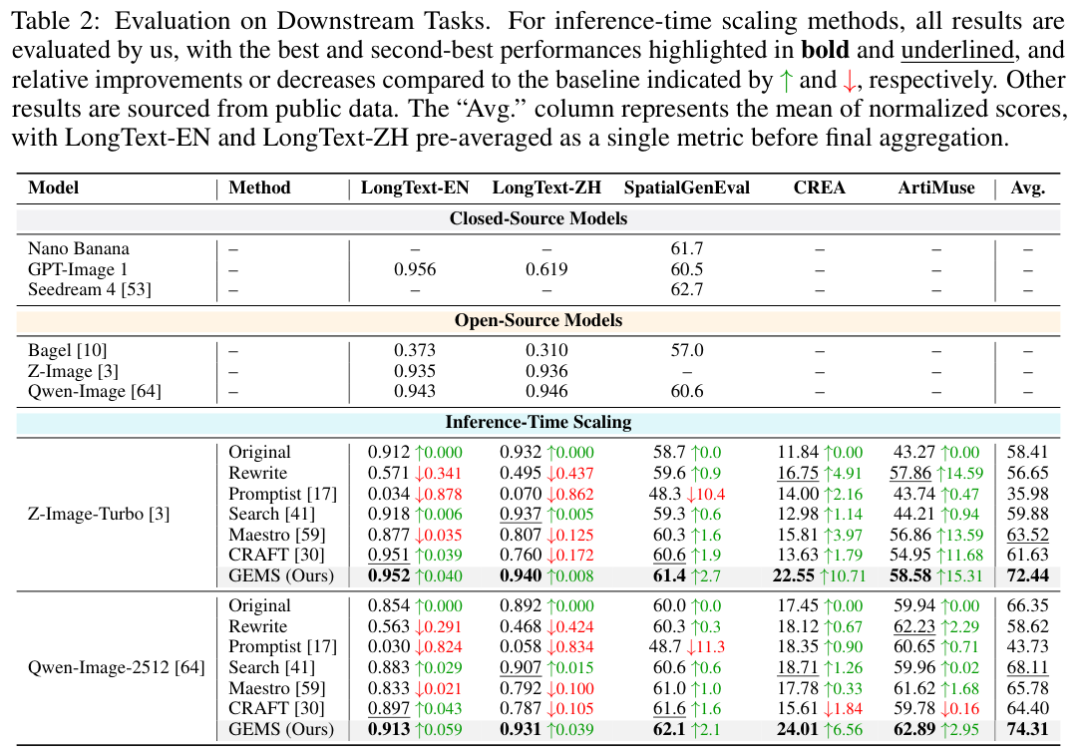
对于涉及复杂长文本渲染、特殊艺术构图以及空间精准排版的应用场景,以往的简单提示词重写基准方法不仅无法带来性能提升,反而常常因为缺乏专业约束规范而导致画面质量严重崩塌。
凭借按需调用的专业技能包加持,GEMS在四大下游任务中斩获了惊人的14.03分平均增长,彻底扭转了通用模型在垂直领域表现不佳的被动局面。
Qwen-Image-2512模型在接入框架后,同样在各类任务中斩获了两位数以上的大幅提升,再次证明了智能体架构在应对多元底层模型时的极速适配能力。
在关注绝对生成质量的同时,算力成本的控制同样是业界极为在意的核心指标。
在GenEval2基准测试的动态追踪中,其他一些诸如启发式搜索或基础多轮迭代的方法,往往需要强制模型生成大量废弃的中间图像,才能撞大运般地碰上一张符合要求的结果。
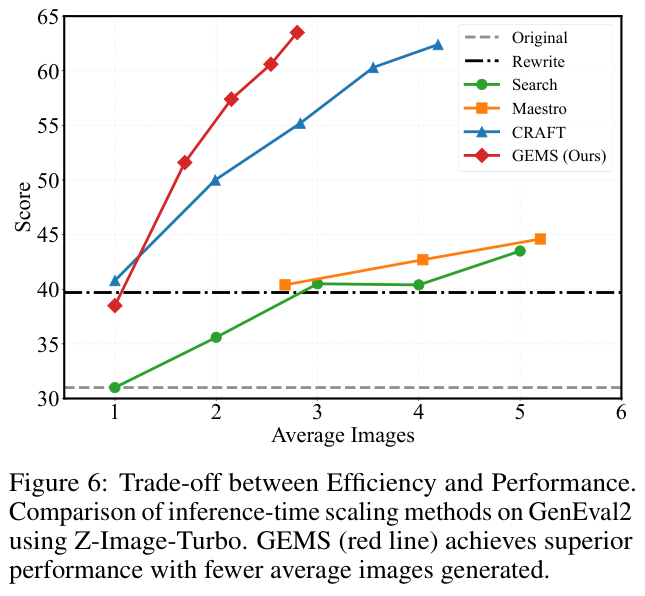
与此形成鲜明对比的是,由于配备了包含底层记忆与外挂技能在内的智能提前终止机制,GEMS平均每个任务仅仅需要生成约三张测试图像,就能稳稳拿下全场最高的分数。
记忆体系的高效压缩与专业技能的精准指引,让原本漫无目的的随机试错彻底升级为了具备高度方向感的定向优化,将整体迭代次数的分布区间显著推向了更加靠前的轮次,最终实现了时间开销与算力支出的双重减负。
作为一项直击多模态大模型固有痛点的前沿探索,GEMS成功地将文本领域成熟的智能体协作理念,迁移并重构至视觉合成的广阔天地。
它用充满韧性的闭环反馈替代了冰冷生硬的单次运算,用层次分明的记忆体系化解了杂乱无章的冗余堆砌,用即插即用的专业技能终结了下游应用的碎片化僵局。
轻量级模型加上GEMS就能超越顶尖模型的辉煌战绩,为未来普及高质量个性化数字内容创作开启了极具想象力的道路。
参考资料:
https://gems-gen.github.io/
https://github.com/lcqysl/GEMS
https://arxiv.org/pdf/2603.28088v1

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 0
0 0
0- 0



 已为社区贡献69条内容
已为社区贡献69条内容

所有评论(0)