GR00T 1.5前戏:FLARE: Robot Learning with Implicit World Modeling
写在前面:
1. 双引号括起来的来自与原文或者原文的中文翻译。
2. 实验部分因为数据冗杂我会用AI解读,有AI解读的部分会用类似本导言一样包括起来。
3. 有任何建议欢迎在评论区指出。
FLARE: Robot Learning with Implicit World Modeling
GR00T 1.5相较于1.0改进的核心的点。都是nvidia的工作。
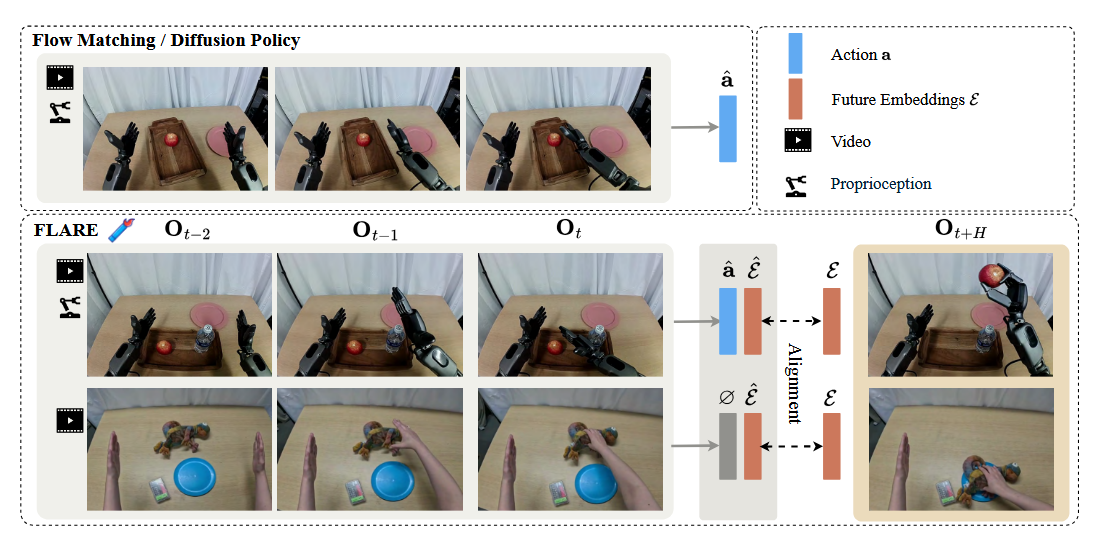
本质上通过流匹配扩散模型生成预测的动作,然后通过可学习的未来标记与来自VL embedding生成的未来标记嵌入进行对齐(Alignment)。相当于用未来标记来当作桥梁(因为有些方法是通过生成未来的图片和真实未来图片进行对齐,计算量特别大,该方法明显降低了计算量)
接着这里可以注意的一点是,本文没有直接用到VLM,是直接用视觉backbone和语言backbone的直接针对图像和语言进行编码,之后用到第4页提到来自ICML2023的Q-former进行压缩视觉和语言信息,就有点像pi最近推出来的RLT工作,也都是通过任务逼着往提前预设的信息空间(Vision Language Embedding Tokens)里塞信息。
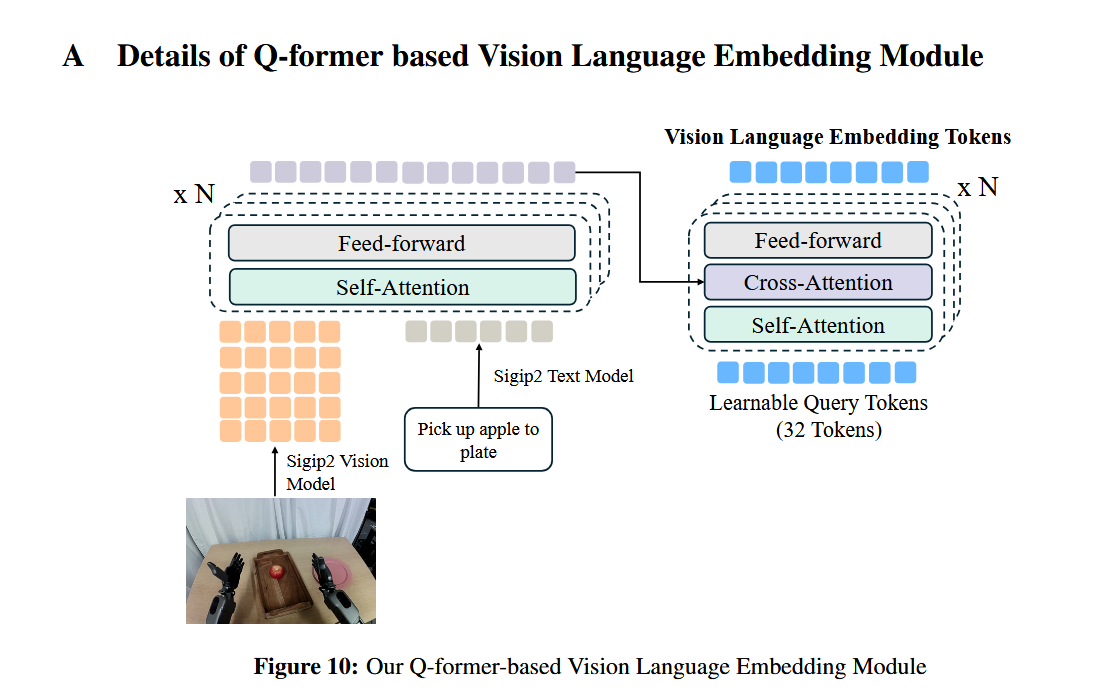
Q-former的详细解读:
第一步:先把图像和文本融合
图像 observation 先过视觉编码器,文本 instruction 过文本编码器,然后做跨模态融合。
这时得到的还是一串比较长的 token sequence。
如果有多张相机图像,这串 token 会更长。第二步:用 Q-former 把长序列压成 32 个 query token
这里的 Q-former 本质上是在做:
准备一组固定数量的可学习 query,论文里是 M = 32
让这 32 个 query 去“从长序列里取信息”
最终输出固定长度的 32 个 latent tokens
所以它不是随便平均池化,也不是截断,而是:
用 32 个“可学习的信息槽位”去主动摘要原始多模态序列。
这就是为什么作者说它得到的是 compact, fixed-size representation。
不管原始输入 token 有多少,最后都被压成 固定的 32 个 token。第三步:再用动作预测任务逼这 32 个 token 学“对动作有用”的信息
如果只是压缩,压出来的 token 未必适合控制。
所以他们在这组 latent token 后面再接 8 个 DiT blocks,用正常的 action flow-matching objective 去预测机器人动作。这样一来,这 32 个 token 就不能只保留“看起来像视觉摘要”的信息,而必须保留:
物体在哪里
手和物体的相对位置
哪些部分和动作决策有关
指令要求当前该做什么
否则后面的 DiT 就预测不好动作。
然后接着就用这个预设的信息空间来DiT去噪生成动作。
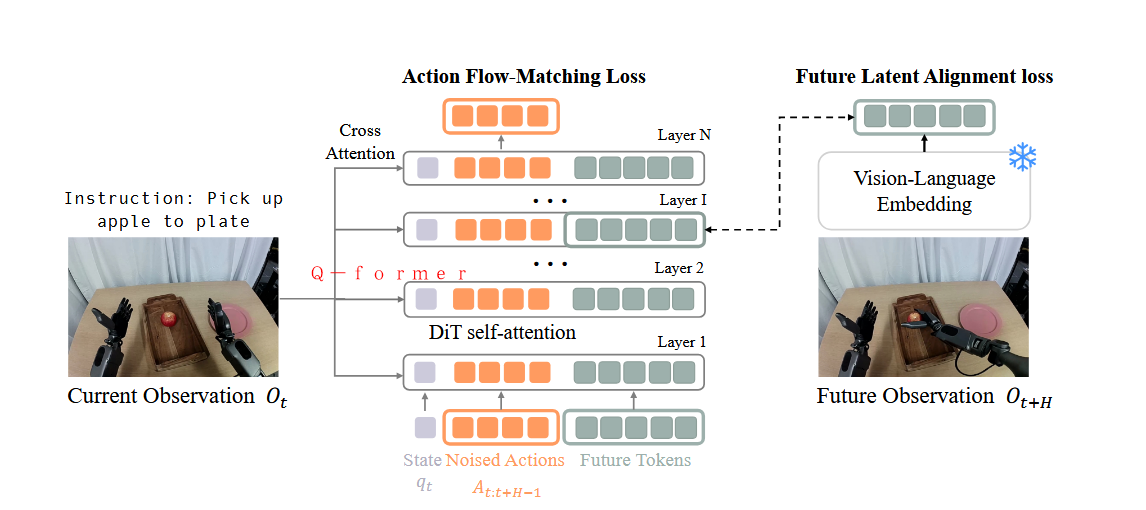
输入为三个组件:(1)通过状态编码器编码的当前本体感受状态,(2)由动作编码器编码的噪声动作块,以及(3)一组 M 个可学习的未来标记。
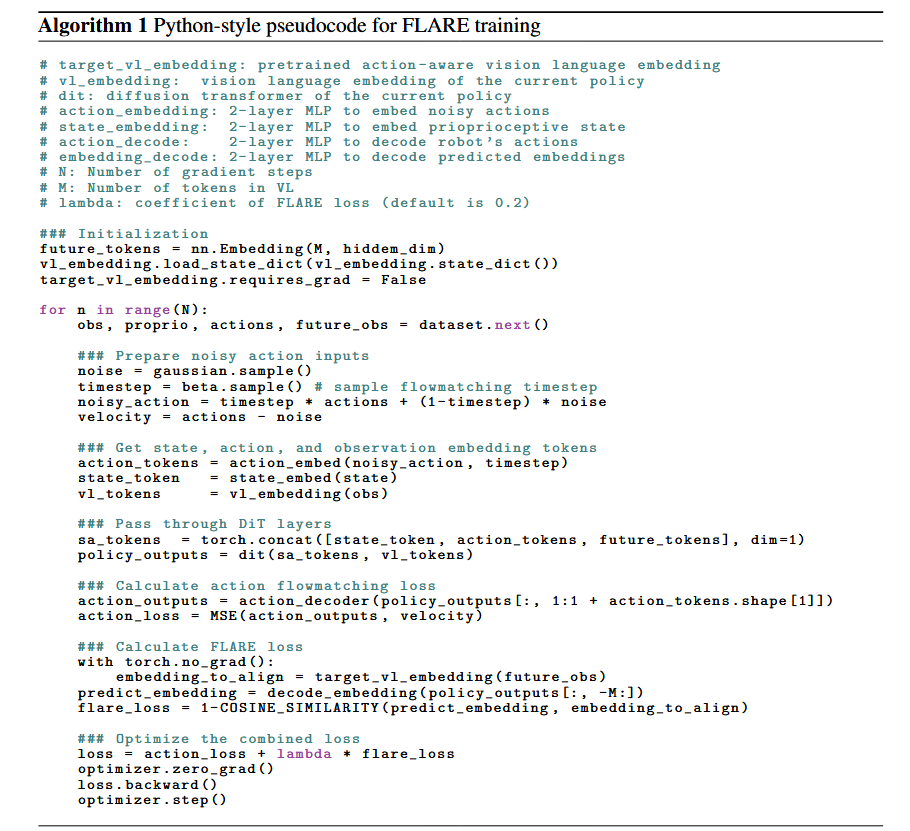
针对N层均进行下述算法(算法中没直接标注Q-former,推测因为是别人的工作,应该是囊括在vl_embedding或者dit中)操作:
实验方面:
除了常规的消融实验来验证未来标记嵌入进行对齐(Alignment)的有效性以外。有个最巧妙的实验点,也是作者想借该技术进行少样本训练的目的,见如下。
4.3 用人类第一视角视频
这一节是最能体现 FLARE 思想的一节,因为它把 future latent alignment 从有动作标签的机器人数据扩展到了没有动作标签的人类视频。作者的设置是:
选 5 个训练集中没有出现过、几何形状很特别的新物体;
每个物体采集 150 条人类第一视角演示,通过 GoPro 头戴拍摄;
机器人侧只采集 10 条 teleop demo/物体;
训练时混合:少量机器人 demo + GR-1 pretraining data + 人类 ego videos。
最关键的机制是:
对于机器人 demo,因为有动作标签,所以同时用 action flow-matching loss + future alignment loss;
对于人类视频,因为没有动作标签,所以只能用 future alignment loss。这正好验证了 FLARE 的一个很强的性质:
它新增的 supervision 并不要求动作标签,它只要求有未来观测。因此只要有视频序列,就能给 policy 的 future token 提供学习信号。结果也很漂亮:
每个物体只有 1 条机器人轨迹时,FLARE 已能达到 最高 60% 成功率;
每个物体 10 条机器人轨迹,再联合人类视频训练后,成功率提升到 80%,大约是只用 action-labeled 数据 baseline 的两倍。
这节实验要你记住的不是具体数字,而是这个结论:
FLARE 把世界模型式监督变成了一种可以从纯视频里吸收的训练信号。
这比单纯提升 benchmark 分数更重要,因为它回答了一个很现实的问题:机器人动作标注贵,但人类演示视频便宜。FLARE 让这两类数据第一次可以在一个统一框架里共同训练 policy。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 3
3 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)