论文解读:GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
写在前面:
1. 双引号括起来的来自与原文或者原文的中文翻译。
2. 实验部分因为数据冗杂我会用AI解读,有AI解读的部分会用类似本导言一样包括起来。
3. 有任何建议欢迎在评论区指出。
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
从架构和数据两个维度出发
架构:
GR00T N1是一款双系统架构的视觉-语言-动作(VLA)模型。视觉语言模块(系统2)通过视觉和语言指令解释环境。随后的扩散变压器模块(系统 1)实时生成流体马达动作。
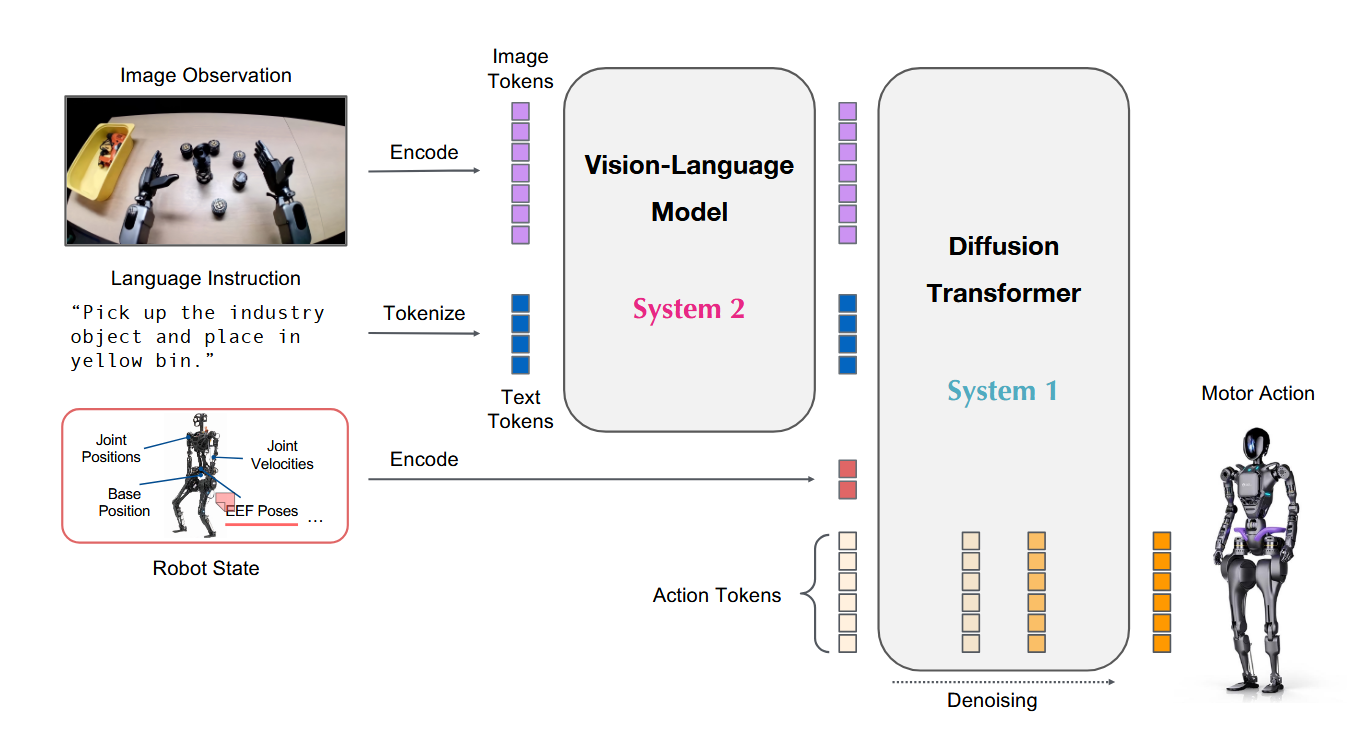
System 2 推理模块是一个预先训练的视觉语言模型NVIDIA Eagle-2 VLM,在 NVIDIA L40 GPU 上以 10Hz 运行。
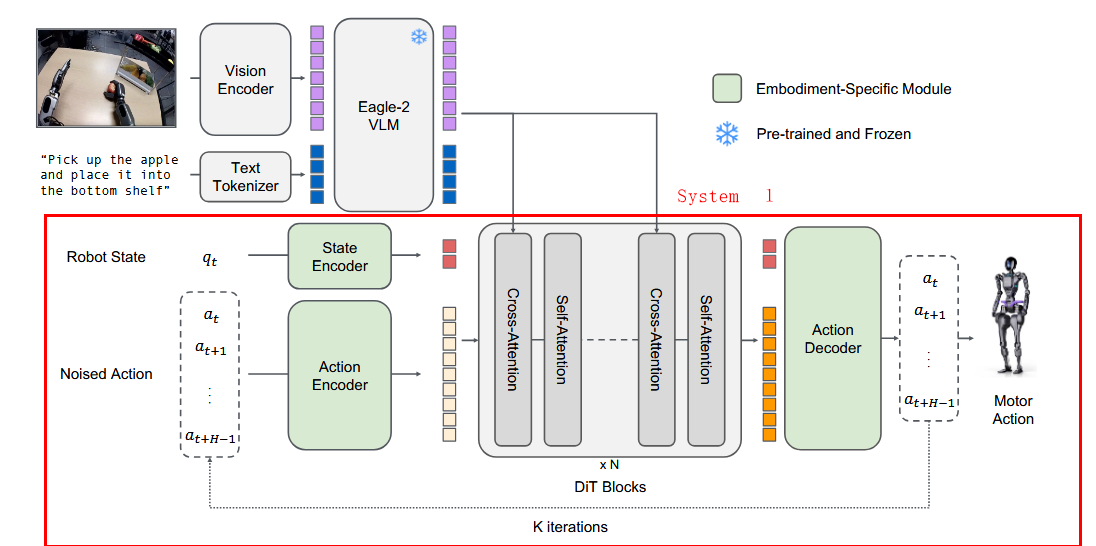
随后,经过动作流匹配训练的扩散变压器充当系统 1 动作模块。它利用交叉注意力机制交叉参与VLM输出令牌并采用实施例特定的编码器和解码器来处理用于运动生成的来自不同数据类型的可变状态和动作维度。它以更高的频率 (120Hz) 生成闭环电机动作。系统 1 和系统 2 模块均实现为基于 Transformer 的神经网络。
encoder是MLP,噪声动作通过类似于ACT的分块机制输入。

——“Eagle-2 is finetuned from a SmolLM2 (Allal et al., 2025) LLM and a SigLIP-2 (Tschannen et al., 2025) image encoder。”
需要注意的是,GR00T里的VLM不是用整个大模型:“我们从 LLM 中提取形状的视觉语言特征(批量大小 × 序列长度 × 隐藏维度)。我们发现,使用中间层而不是最终层 LLM 嵌入可以带来更快的推理速度和更高的下游策略成功率。对于 GR00T-N1-2B,我们使用第 12 层的表示。”
DiT还是比较常规的,用于去噪。
EEF:虽然官方论文未给出解释,查阅资料发现指的是机械臂的末端执行器。但在原文中的位置标注在机器人的腰部并非手臂中心,代码中有提供g1的接口如下,说明可以训练机器人基坐标或底盘坐标的运动。

数据:
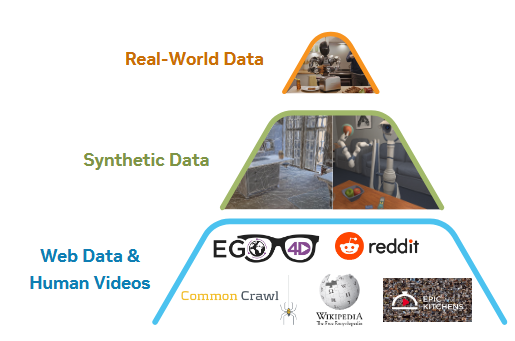
如图,分三层组织异构源数据。
底层的Web Data&Human Video(不过这个数据特指以自我为中心的视频数据)在论文中的数据被称之为latent-action,因为它本身没有直接的动作数据,所以被称之为潜在的动作数据。
针对latent-action,本文使用来自于ICLR2025的Latent action pretraining from videos(LAPA)文章处理方式。非常巧妙:利用 VQ-VAE生成动作
1)为什么用当前帧
和未来帧
来输出潜在动作
?
因为他们想学的不是这一帧长什么样,而是从这一帧变到未来那一帧,中间发生了什么动作变化。这本质上就是一个逆动力学思路:已知前后状态,倒推出导致这个变化的动作。论文也明确说,训练完后他们直接把这个编码器当作 inverse dynamics model 来用。
为什么要固定窗口 H?因为 H 决定了动作的时间尺度:
H太小,两帧几乎没变化,学到的动作会很弱、很噪。
H太大,两帧差异过大,里面混了太多变化,动作会变得含糊,模型也更难学。
LAPA 论文的附录直接说了这个取舍:他们给机器人视频选的是大约 0.6 秒的间隔,而人类视频因为动作更慢、更稀疏,用的是大约 2.4 秒;同时他们也观察到,窗口过大时性能会下降。
所以,
2)为什么 decoder 要拿
这是在强迫
如果只让 encoder 随便输出一个向量,没有重建约束,
直觉上,你可以把它理解成:
decoder:根据“起点 + 变化”预测终点
这样学出来的
使用预先训练的视频生成模型(也就是世界模型)生成合成神经轨迹构成第二层的Synthetic Data(具体哪些开源的数据集名称见论文第11页)。
论文中一句“These simulation data significantly supplement the real-robot data with minimal human costs.”
看起来仿真数据(开源的benchmarks名称见论文第12页)被纳入了第三层real-robot data(开源的数据集名称见论文第9页) ,如下表也印证了这个看法。

实验:
实验方面有两个好的看点:
4.4 定量结果,最核心的结论是什么
1)预训练本身就有可迁移能力
作者先做了两个不依赖任务微调的 real GR-1 测试:
一个是物体放在左手更左边,必须先左手拿、再交给右手、再放到底层架子上的协调任务。
一个是把新物体放进从未见过的新容器的泛化任务。
预训练 GR00T-N1-2B 在这两个任务上分别做到 76.6%(11.5/15) 和 73.3%(11/15)。作者把这当成大规模预训练本身已经学到通用操作先验的证据。
这点很重要,因为它说明:预训练阶段并不只是学视觉语言特征,而是真的把一部分动作组织能力带进来了。
4.4 里神经轨迹 ablation
这一部分不是主结果,但学术价值很高。
他们把神经生成视频也拿来参与 post-training:
RoboCasa 里,每任务额外 co-train 3k 条 neural trajectories;
真实世界里,每任务额外 co-train 100 条 neural trajectories。
结果是:
在 RoboCasa 上,相比只用真实轨迹,加入神经轨迹后,平均提升 +4.2%、+8.8%、+6.8%(分别对应 30/100/300 demos)。
在真实 GR-1 的 8 个任务上,平均再提升 +5.8%。
这部分真正想说明的是:
他们的数据金字塔不是概念包装,而是合成/生成的数据确实能帮助后训练。而且他们还比较了两种给 neural trajectories 打标签的方法:
LAPA latent action
IDM pseudo-action
作者观察到:在低数据(30 demos)下,LAPA 略好;但数据多起来(100/300)后,IDM 反而越来越占优。作者给出的解释是:IDM 本身也在吃更多真实动作数据,所以伪标签会越来越贴近真实动作空间。
这部分可以理解成:
LAPA 更像通用动作语义先验,IDM 更像贴目标机器人动作分布的伪监督器。
所以低数据时前者更有帮助,高数据时后者更能贴近目标控制。这个逻辑其实很合理。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 12
12 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)