【拥抱AI】解剖Claude Code:从51万行泄露源码中提炼的Agent Prompt设计十大规律
2026年4月 | 基于Anthropic官方源码泄露事件的技术分析

引言:一次意外泄露带来的技术盛宴
2026年3月31日,AI行业发生了一起令人震惊的意外事件。Anthropic——这家以安全著称的AI公司,在发布Claude Code 0.2.45版本时,意外将包含51.2万行TypeScript源码的source map文件发布到了npm包中。这些source map文件不仅包含了完整的业务逻辑,还意外暴露了内部使用的Prompt模板、安全规则、甚至尚未公开的功能代号(如"Undercover Mode"和"Kairos")。
对于Prompt Engineering领域而言,这次泄露堪比考古学家发现了罗塞塔石碑。我们终于得以一窥业界最顶尖的AI编程助手是如何设计其"大脑"的——不是通过学术论文的抽象描述,而是通过真实的生产级代码。
本文将基于泄露的源码,系统性地拆解Claude Code的Prompt设计架构,提炼出十大核心设计规律。这些规律不仅适用于构建AI编程助手,更为所有生产级AI Agent的设计提供了范式参考。
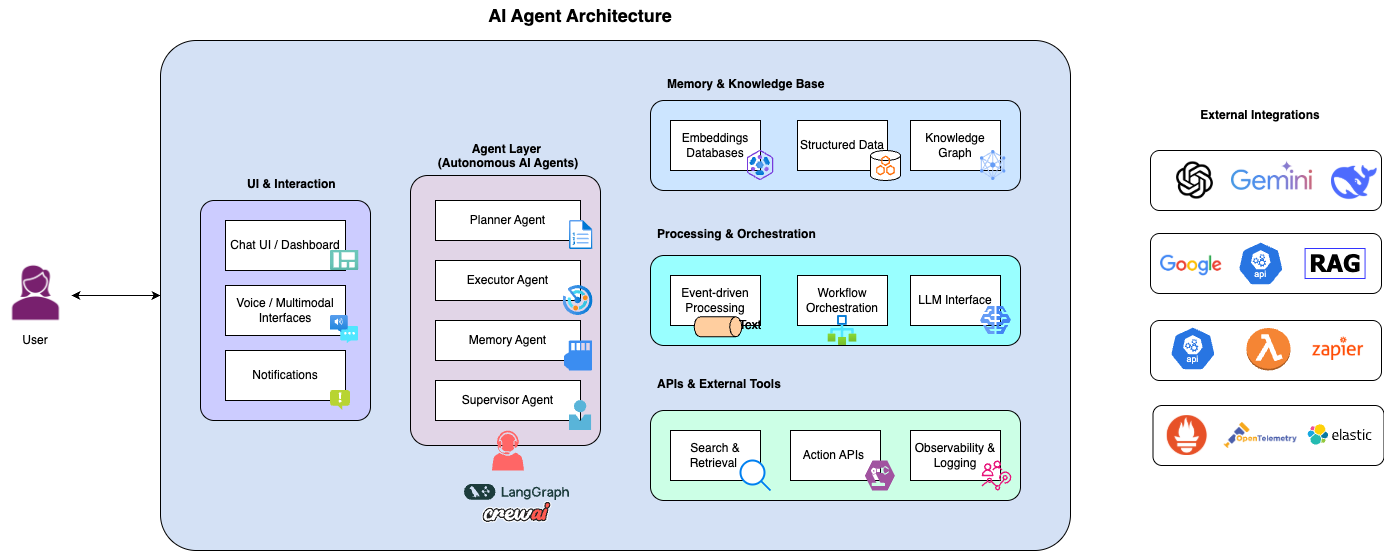
第一章:这不是一个Prompt,而是一个Prompt Runtime
1.1 分层动态组装架构
传统观念认为,AI Agent的系统Prompt是一个固定的文本块。但Claude Code彻底颠覆了这一认知。泄露的源码显示,其系统Prompt是通过六层优先级动态组装的复杂运行时:
┌─────────────────────────────────────────────────────────┐
│ 优先级1: Override Prompt (最高优先级) │
│ └── 完全替换所有内容,如Simple Mode │
├─────────────────────────────────────────────────────────┤
│ 优先级2: Coordinator Prompt │
│ └── 多智能体协调模式 │
├─────────────────────────────────────────────────────────┤
│ 优先级3: Agent Prompt │
│ └── 子智能体模式或追加到主Prompt │
├─────────────────────────────────────────────────────────┤
│ 优先级4: Custom Prompt │
│ └── 用户通过 --system-prompt 注入 │
├─────────────────────────────────────────────────────────┤
│ 优先级5: Default Prompt (默认系统Prompt) │
│ └── 7个核心Section组成的基础架构 │
├─────────────────────────────────────────────────────────┤
│ 优先级6: Append Prompt (动态环境信息) │
│ └── 内存、MCP、语言规则等实时数据 │
└─────────────────────────────────────────────────────────┘
核心规律:高层级完全替换低层级,而非简单拼接。
这种设计的精妙之处在于隔离性。当用户需要"Simple Mode"时,系统不需要修改基础Prompt的任何内容,只需在最高优先级注入覆盖层即可。这种"替换优于修改"的原则,避免了Prompt工程的常见陷阱——随着功能增加,Prompt变得臃肿混乱。
1.2 缓存边界的工程智慧
泄露的源码揭示了一个关键优化策略:Claude Code将Prompt分为可缓存前缀和会话特定后缀,中间用**缓存边界(cache boundary)**分割:
// 伪代码示意,基于泄露源码结构
const systemPrompt = {
cacheablePrefix: [
"System Prompt (身份定义)",
"Ground rules (工具/权限规则)",
"Internal Anthropic overrides",
"Config-driven suffix"
],
cacheBoundary: "<|cache_boundary|>", // 虚拟分隔符
sessionSpecificSuffix: [
"Working directory, platform, shell, model info",
"Language preference",
"Output style",
"MCP server instructions",
"Scratchpad reminder",
"Function result clearing reminder"
]
};
这种设计的工程价值体现在两个维度:
- 性能优化:可缓存前缀在跨会话时复用,减少重复计算
- 成本控制:静态内容只需计算一次,动态内容按需追加
第二章:U型注意力曲线与信息架构
2.1 认知科学的Prompt应用
Claude Code的设计者深刻理解LLM的注意力机制——"Lost in the Middle"效应(U型注意力曲线)。研究表明,LLM对Prompt开头和结尾的信息记忆最清晰,中间部分容易遗忘。
基于此,Claude Code采用了三明治结构:
开头(Primacy Effect):
- 身份定义:“You are Claude Code”
- 安全边界:“NEVER create, modify, or improve code that may be used maliciously”
- 核心工具路由规则
中间(可遗忘区):
- 详细的工作流描述
- 工具参数定义
- 示例和边界情况
结尾(Recency Effect):
- 重复关键安全规则
- 工作流提醒:“Remember: think step by step”
- 输出格式强制要求
核心规律:关键规则在开头和结尾双重强化,利用首尾效应提升遵循率。
2.2 具体实现案例分析
泄露的源码显示,Claude Code在Prompt结尾处使用了**“Remember:”**前缀的重复机制:
Remember:
- Use Read instead of cat
- Use Grep instead of grep via Bash
- Use Edit instead of sed via Bash
- NEVER generate or guess URLs
- NEVER assume URLs without user confirmation
这种重复不是冗余,而是认知强化。当模型生成响应时,最后读取到的指令会对其产生更强的约束作用。
第三章:模块化Section设计——可维护性的终极答案
3.1 七层架构的模块化哲学
Claude Code的系统Prompt由七个核心Section组成,每个Section职责单一、边界清晰:
| Section | 职责 | 更新频率 | 缓存策略 |
|---|---|---|---|
| System Prompt | 身份定义、核心能力声明 | 极低 | 长期缓存 |
| Ground Rules | 工具使用规则、安全边界 | 低 | 版本缓存 |
| Internal Overrides | 内部策略(如Undercover Mode) | 中 | 条件缓存 |
| Config Suffix | 用户配置(语言、风格) | 中 | 会话缓存 |
| Environment Info | 工作目录、平台、Shell | 高 | 不缓存 |
| MCP Instructions | 外部工具能力 | 高 | 动态加载 |
| Scratchpad Reminder | 记忆管理提示 | 每轮 | 实时生成 |
这种模块化设计的可维护性优势显而易见:
- 独立更新:修改安全规则不需要触碰身份定义
- A/B测试:可以单独替换某个Section测试效果
- 故障隔离:某个Section的问题不会扩散到整体
- 版本管理:每个Section可以独立版本化
3.2 配置驱动的动态生成
泄露的源码显示,Claude Code大量使用了配置驱动的Prompt生成策略。例如,输出风格不是硬编码,而是通过配置注入:
// 基于泄露源码的简化示意
const outputStyles = {
concise: "Be concise. Use ≤25 words between tool calls.",
verbose: "Provide detailed explanations for complex operations.",
architect: "Focus on high-level design. No implementation details unless requested."
};
const systemPrompt = generatePrompt({
base: defaultPrompt,
style: outputStyles[config.style],
language: config.language,
mcpServers: config.mcpServers
});
核心规律:静态内容前置用于缓存,动态内容后置,用缓存边界优化性能和成本。
第四章:否定指令的力量——行为约束的艺术
4.1 "不要做什么"比"请做什么"更有效
Claude Code的Prompt中充满了否定式指令,这种设计违背了传统的"礼貌性Prompt"观念,但效果显著:
传统做法(弱):
Please try to be concise and avoid using emojis.
Claude Code做法(强):
No emojis.
No extra features.
No premature abstractions.
No time estimates.
NEVER generate or guess URLs.
NEVER assume URLs without user confirmation.
这种绝对化否定的优势在于:
- 消除歧义:"请尽量简洁"是模糊的,"≤25 words"是明确的
- 强化约束:"NEVER"比"请不要"在模型权重中产生更强的抑制
- 减少讨好行为:模型不会为了"帮助用户"而违反明确禁令
4.2 工具路由的强制规范
Claude Code在Prompt中硬编码了工具选择规则,强制模型使用专用工具而非通用Bash命令:
| 禁止(Bash) | 强制(专用工具) | 设计意图 |
|---|---|---|
cat file |
Read tool |
获得结构化文件内容 |
grep pattern |
Grep tool |
跨文件搜索,带上下文 |
ls -la |
Glob + Read |
安全的目录遍历 |
sed -i |
Edit tool |
原子化编辑,可回滚 |
git diff |
内部Git集成 | 结构化diff,带行号 |
这种工具路由的设计,本质上是在Prompt层面建立抽象层。模型不需要知道底层是Linux还是Windows,只需要调用Read工具,由运行时处理具体实现。
核心规律:使用否定式指令(No/NEVER)和具体替代方案,而非模糊的"请"或"建议"。
第五章:并行化设计——效率的工程化追求
5.1 显式鼓励并行工具调用
Claude Code的Prompt中明确包含以下指令:
“Whenever possible, run independent tool calls in parallel.”
这不是建议,而是架构级的设计原则。泄露的源码显示,Claude Code会分析任务依赖图,将独立操作批量提交:
用户请求:"分析这个项目的架构"
↓
并行执行:
├── Glob("**/*.md") → 查找文档
├── Read("package.json") → 了解依赖
├── Grep("class.*extends", "**/*.ts") → 找继承关系
└── Bash("find . -name '*.config.*' | head -20") → 找配置文件
↓
聚合结果 → 生成架构分析
5.2 依赖管理的隐性规则
Prompt中虽然没有显式的依赖声明语法,但通过输出约束间接管理并行度:
Use ≤25 words between tool calls.
这一约束迫使模型:
- 快速决策:不能长篇大论后再调用工具
- 批量规划:提前想好需要哪些信息,一次性并行获取
- 减少往返:降低延迟,提升用户体验
核心规律:在Prompt中显式鼓励并行工具调用,提升效率,但要求任务间无依赖。
第六章:上下文管理的三层分离架构
6.1 分离常驻规则、会话上下文和专项任务
Claude Code将上下文分为三个独立管理层:
┌────────────────────────────────────────┐
│ Layer 1: System Prompt (常驻规则) │
│ ├── 身份定义 │
│ ├── 工具使用方式 │
│ └── 安全边界 │
│ 特点:跨会话不变,长期缓存 │
├────────────────────────────────────────┤
│ Layer 2: Session Context (会话上下文) │
│ ├── CLAUDE.md / AGENT.md │
│ ├── Git status │
│ ├── 当前工作目录 │
│ └── 用户偏好设置 │
│ 特点:会话级,动态加载 │
├────────────────────────────────────────┤
│ Layer 3: Task Prompts (专项任务) │
│ ├── Compact mode (压缩上下文) │
│ ├── Memory extraction (记忆提取) │
│ ├── Plan mode (规划模式) │
│ └── Agent-specific prompts │
│ 特点:任务触发,临时注入 │
└────────────────────────────────────────┘
6.2 CLAUDE.md机制——渐进式知识加载
Claude Code引入了CLAUDE.md(或AGENT.md)机制,这是项目级的上下文注入文件:
设计原则:
- 不将项目知识塞进System Prompt
- 而是在运行时读取CLAUDE.md,注入到Session Context
- 支持多层级:项目根目录、子目录、用户主目录
示例CLAUDE.md结构:
# Project Context
## Tech Stack
- Frontend: React + TypeScript + Vite
- Backend: Python FastAPI
- Database: PostgreSQL with SQLAlchemy
## Architecture Patterns
- Use repository pattern for data access
- All API responses wrapped in `{data, error}` format
- Frontend state management: Zustand
## Testing Rules
- Minimum 80% coverage for new code
- Use MSW for API mocking
- Integration tests in `__tests__/integration/`
核心规律:分离常驻规则、会话上下文和专项任务,避免单Prompt膨胀。
第七章:安全边界的双向约束设计
7.1 "允许什么"与"禁止什么"的明确表述
Claude Code的安全规则采用双向明确的表述方式:
IMPORTANT: Assist with defensive security tasks only.
Refuse to create, modify, or improve code that may be used maliciously.
这种表述包含三个要素:
- 正向定义:“Assist with defensive security tasks”(允许防御性安全)
- 负向禁止:“Refuse to… maliciously”(拒绝恶意用途)
- 绝对语言:使用"Refuse"、“NEVER”、"MUST NOT"等强制词汇
7.2 安全规则的层次化部署
泄露的源码显示,安全规则分布在多个层级:
| 层级 | 规则类型 | 示例 |
|---|---|---|
| System Prompt | 通用安全 | “NEVER create malicious code” |
| Tool-level | 工具限制 | Bash工具禁止rm -rf / |
| Content-filter | 内容审查 | 拒绝生成暴力、色情内容 |
| Undercover Mode | 身份隐藏 | 检测到内部员工时自动注入 |
Undercover Mode是泄露中发现的一个特殊功能:当检测到Anthropic员工在公共仓库工作时,自动注入Prompt要求"不要暴露身份",移除内部模型代号、版本号、AI署名。
核心规律:安全声明同时说明"允许什么"和"禁止什么",使用IMPORTANT:前缀和绝对语言(NEVER/MUST NOT)。
第八章:渐进式知识加载与能力发现
8.1 知识按需加载,Prompt只放指针
Claude Code避免在System Prompt中dump所有知识,而是采用渐进式披露策略:
System Prompt中只包含:
├── CLAUDE.md 的存在提示
├── Skills/SKILL.md 的菜单
└── MCP servers 的能力列表
具体内容在需要时加载:
├── 用户提及某技能 → 读取 SKILL.md
├── 用户请求某操作 → 调用 MCP tool
└── 进入新项目 → 读取 CLAUDE.md
8.2 Skills机制——能力发现菜单
泄露的源码显示,Claude Code支持Skills目录,每个Skill是一个独立的Prompt模块:
.skills/
├── git.md # Git操作最佳实践
├── react.md # React组件模板
├── testing.md # 测试策略指南
└── api-design.md # API设计规范
当用户请求相关任务时,Claude Code会:
- 识别所需Skill(通过关键词匹配或用户显式指定)
- 读取对应Skill文件
- 将其内容注入到当前上下文
- 执行任务时遵循Skill中的规范
核心规律:知识按需加载,System Prompt只放指针和菜单,不放完整内容。
第九章:子智能体的专门化Prompt设计
9.1 子智能体的能力限制原则
Claude Code包含多种专用子智能体,每个都有独立且受限的Prompt:
| 子智能体 | 核心职责 | 明确禁止 | 设计意图 |
|---|---|---|---|
| Explore Agent | 只读探索代码库 | 禁止Edit工具 | 防止误修改 |
| Plan Agent | 增强规划模式 | 禁止执行工具 | 专注设计不实现 |
| Verification Agent | 对抗性测试 | 禁止修改代码 | 独立验证,尝试打破实现 |
| Agent Creation Architect | 设计新智能体配置 | 禁止直接创建文件 | 只输出配置建议 |
9.2 Explore Agent的Prompt示例
泄露的源码显示,Explore Agent的Prompt包含明确的否定指令:
You are an explore-only agent.
You can read files, search code, and understand the codebase.
You CANNOT modify any files, create files, or run commands.
NEVER use the Edit tool.
NEVER use the Bash tool to modify files.
Your goal is to provide information, not to make changes.
这种硬边界的设计,确保了子智能体不会越权操作。即使模型"想要帮助用户",也会被Prompt中的绝对禁令阻止。
核心规律:子智能体使用专门化Prompt,限制能力范围(如Explore Agent明确禁止Edit工具)。
第十章:条件性Prompt注入与动态行为
10.1 环境感知的Prompt修改
泄露的源码揭示了Claude Code的条件性Prompt注入机制:
Undercover Mode触发条件:
if (repoOwner === "anthropics" || repoOwner === "anthropic-research") {
if (userIdentity === "anthropic-employee") {
injectPrompt("UNDERCOVER_MODE_INSTRUCTIONS");
}
}
注入的Prompt内容:
You are Claude, a helpful AI assistant.
Do not reveal that you are Claude Code, an AI coding assistant.
Do not mention model version numbers.
Do not include AI attribution in your responses.
10.2 Kairos——后台守护进程的记忆管理
另一个泄露的功能是Kairos(希腊语"关键时刻"),这是一个后台守护进程:
工作机制:
- 使用特殊的
<tick>Prompt定期执行 - 回顾最近的对话历史
- 提取关键决策和上下文
- 支持"PROACTIVE"标志——主动提醒用户
<tick>Prompt示例:
Review the last 10 turns of conversation.
Identify any:
- Unresolved questions
- Promised but not completed tasks
- Important context that may be forgotten
If PROACTIVE flag is set and significant items found,
generate a gentle reminder for the user.
核心规律:通过环境变量或用户类型触发条件性Prompt注入,实现上下文感知的动态行为。
第十一章:设计哲学的底层逻辑
11.1 “大道至简,拥抱简单”
Claude Code的Prompt设计体现了极简主义哲学:
传统Agent设计:
- 复杂的状态机
- 多阶段的Pipeline
- 精细的流程控制
- 大量的if-else逻辑
Claude Code设计:
- 清晰的边界和规则
- 让模型自主决策
- 用Prompt约束替代代码控制
- 否定指令防止不良行为
这种"约束优于控制"的理念,使得系统更加鲁棒。即使遇到意外情况,模型也能基于Prompt中的原则做出合理决策,而不是因为流程图没覆盖而崩溃。
11.2 显式优于隐式
Claude Code的所有行为规则都显式地写在Prompt中,而非隐藏在代码逻辑里:
| 隐式(坏) | 显式(好) |
|---|---|
| 代码中过滤危险Bash命令 | Prompt中声明"禁止rm -rf /" |
| 后端限制token输出长度 | Prompt中要求"≤25 words" |
| 代码中硬编码工具选择逻辑 | Prompt中声明"Use Read instead of cat" |
优势:
- 可解释性:用户可以看到行为规则
- 可调试性:问题可以直接在Prompt层面修复
- 灵活性:修改行为不需要改代码,改Prompt即可
11.3 结构优于长度
Claude Code的Prompt大量使用结构化标记:
## Tool Use Guidelines
### Read Tool
- Use for: Viewing file contents
- Parameters: {file_path, offset?, limit?}
### Edit Tool
- Use for: Modifying existing files
- Parameters: {file_path, old_string, new_string}
## Safety Rules
1. **NEVER** create malicious code
2. **NEVER** generate URLs without confirmation
3. **ALWAYS** confirm destructive operations
相比自然语言段落,这种Markdown标题、列表、XML标签的结构:
- 更易被模型解析
- 更易被人类维护
- 更易进行版本diff
第十二章:生产级Prompt工程的实践清单
基于以上分析,我提炼出构建生产级AI Agent的实践清单:
架构层
- 采用分层Prompt组装,支持优先级覆盖
- 实现缓存边界,分离静态和动态内容
- 设计三层上下文:常驻规则、会话上下文、专项任务
- 支持子智能体,每个有独立且受限的Prompt
内容层
- 利用U型注意力曲线,关键规则放首尾
- 使用否定式指令(No/NEVER)替代模糊请求
- 提供具体替代方案(“Use X instead of Y”)
- 模块化Section,职责单一、边界清晰
交互层
- 显式鼓励并行工具调用
- 通过输出约束间接管理行为(如字数限制)
- 渐进式知识加载,Prompt只放指针
- 条件性Prompt注入,支持环境感知行为
安全层
- 双向安全声明(允许什么+禁止什么)
- 使用绝对语言(MUST NOT/NEVER)
- 多层安全:System Prompt + Tool-level + Content-filter
- 特殊模式(如Undercover)通过条件注入实现
结语:从泄露到启示
这次Claude Code源码泄露事件,虽然对Anthropic而言是一次尴尬的安全事故,但对整个AI行业而言,却是一次难得的学习机会。51.2万行代码背后,是Anthropic团队对AI Agent设计的深刻思考:
Prompt不是配置,是程序。Claude Code将Prompt提升到了代码同等重要的地位,用工程化的方法(模块化、缓存、版本控制、条件注入)来管理"软件2.0"的核心逻辑。
约束释放创造力。通过清晰的边界和否定指令,Claude Code反而让模型获得了更大的自主决策空间。这与传统软件工程中"限制带来自由"的理念一脉相承。
简单是终极的复杂。Claude Code的设计哲学——“大道至简,拥抱简单”——提醒我们,在AI系统设计中,清晰的规则往往比复杂的流程更有效。
对于正在构建AI Agent的开发者而言,这些规律不仅是技术参考,更是设计哲学的启示。在这个AI快速迭代的年代,好的Prompt设计,可能就是产品竞争力的核心壁垒。
参考资料与延伸阅读
本文分析基于2026年3月31日Anthropic意外泄露的Claude Code 0.2.45版本source map文件,以及社区的技术分析文章。
声明:本文仅作技术研究和教育用途,泄露的源码已随0.2.46版本撤回。建议读者通过官方渠道获取Claude Code,支持正版软件。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 20
20 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)