【AI技术洞察】ICL核心论文对提示词工程的启示(2)| 上下文学习运行机制 | 归纳头 | 临时函数/小模型 | CoT
【AI技术洞察】ICL核心论文对提示词工程的启示(2)|上下文学习运行机制 | 归纳头 | 临时函数/小模型
这是我们《AI开发实践》系列的第11篇,我们继续Langchain的番外,来解决ICL学习这个最玄学的东西,为写好提示词做准备。上一篇,我们学习了从业界和学界的核心论文中梳理出来的ICL提示词写作的22条黄金准则,今天继续由论文来了解一下提示词在ICL中的运行过程。我们期望能过对其运行过程的了解,来理解为什么要像写程序一样来写提示词?
一、主要概念
1. 归纳头Induction Heads
归纳头是Transformer 里一种学会了固定模式的注意力头,有着固定的行为:看到序列 [A][B]...[A] 时,自动预测下一个是 [B](匹配 - 复制)。
比如:
下面是一些例子:
苹果 → 红色
香蕉 → 黄色
葡萄 → 紫色
西瓜 → 绿色
规则:
1. 后面的答案**只能从上面出现过的颜色里选**,只能是:红色、黄色、紫色、绿色 其中一个。
2. 不允许创造新颜色,不允许解释,只输出“物品 → 颜色”。
现在请严格按照前面的格式继续:
西瓜 →
归纳头会自动的:
- 在前序中找
[西瓜]- 复制它后面的
[绿色]- 预测下一个 token ≈
[绿色]
西瓜 → 绿色
3. 隐状态 Hidden State
隐状态 hththt 是序列模型在位置 t 计算得到的核心内部表征,它编码了模型在当前拥有的所有信息(上下文信息,输入、输出,中间处理过程,计算记忆,待更新状态等等),是模型进行后续预测与计算的全部依据。
在RNN(Recurrent Neural Network,循环神经网络)中,相邻两次token生成间传递的隐状态是完整继承的****,即hi+1hi+1hi+1能看到是前序步骤hihihi中看到的所有的信息,没有信息丢失******。
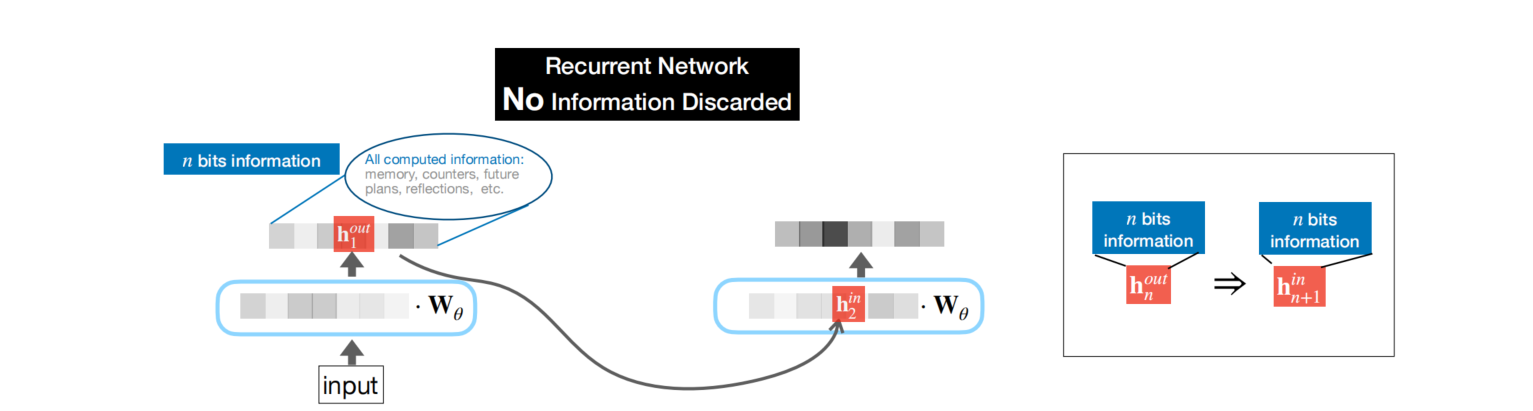
以机器翻译为例:
Encoder:
1)I → h₁
2)love → h₂ (依赖 h₁)
3)you → h₃ (依赖 h₂) ← 整个句子的语义向量
Decoder:
4) <sos> → h_dec₀ = h₃ → 我
5)我 → h_dec₁ (依赖 h_dec₀) → 爱
6)爱 → h_dec₂ (依赖 h_dec₁) → 你
每一步生成的h都包含了前序的所有的语义,比如:到了第3)步时,h3中,浓缩了整个英文句子 I love you 的完整语义,相当于 “句子的向量表示”;同样,第5)步中,h_dec₁ 里包含了原句语义“I love you” + 已生成 我 的信息。
但是在自回归模型中,在相领的两次token生成间,Transformer传递的是生成的答案,不是隐状态hhh, 中间推理结果、计算记忆、待更新状态等等 已经丢失,不足以支撑多数任务的持续推理。
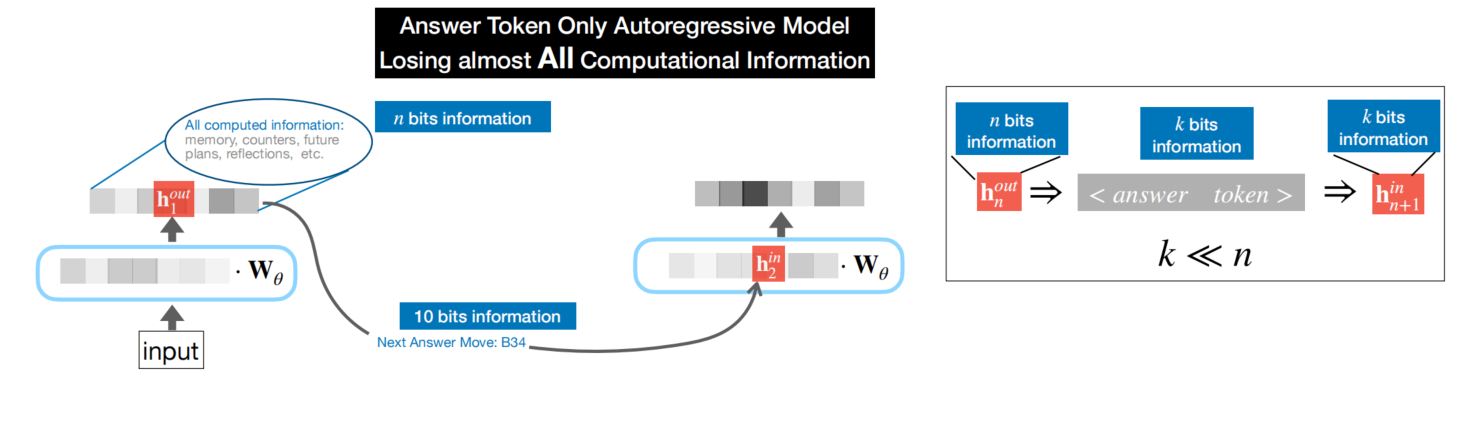
循环神经网络(RNN)等循环结构会执行该操作,将隐状态持续的传递下去;**Transformer在计算t时刻隐状态hₜ时,不会复用t-1时刻的隐状态hₜ₋₁,在预测下一个词时,上一次的隐状态已经丢弃。与程序做类比的话,RNN相当于是上下文以及公式传递,而Transformer中前后时序任务间仅是值传递。
5. 思维链 CoT
因为在Transformer架构中,传递的是结果,而不是包含了所有的信息的隐状态,信息丢失导致了后续推理的断链。因此,需要一个方法来弥补这个缺点,将丢失的信息传递下去。
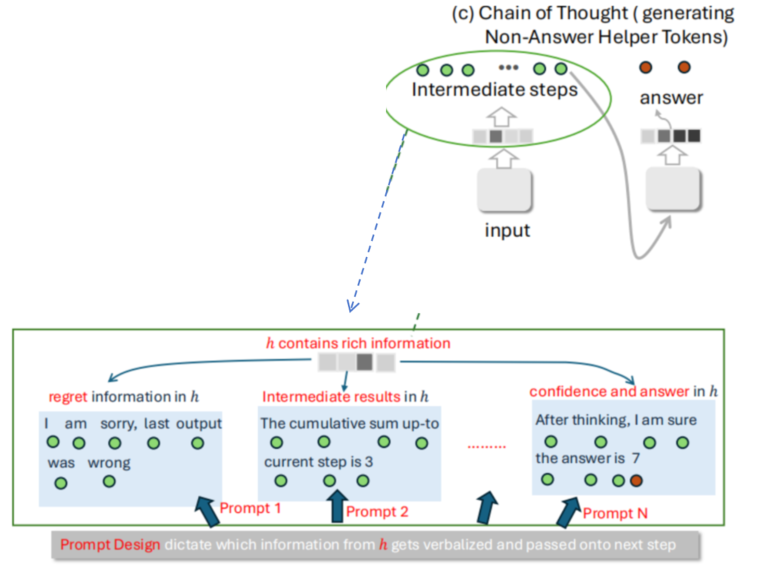
CoT 思维链,通过**“把 隐状态hi 导出成显式文字oi,再变回隐状态 hi+1”的方式,模拟了RNN中隐状态的传递**。
- 模型算出隐状态 hi(内部向量,含regret, Intermediate results, confidence and answer,… )
- CoT 从隐状态 hi提取信息并 写成文字(比如,提取中间结果输出文字“The cumulative sum up-to current step is 3”)《== 提示词干预位置
- 文字被重新输入模型 → 变成新向量 hi+1
- hi+1继承了 hi 的推理信息
- 再算下一步 → 再写文字 → 再变 hi+2
……
无限循环
而在这个过程中,第2步时,提示词对将哪些隐信息转换为自然语言文字进行了过滤和筛选。提示词 = 信息过滤器,它决定了 h 里哪部分信息被 “说出来”,哪部分被直接丢弃:
- Prompt 1:提取「后悔信息」→ 文字:
I am sorry, last output was wrong→hi+1 只包含 “纠错” 信息 - Prompt 2:提取「中间结果」→ 文字:
The cumulative sum up-to current step is 3→hi+1 只包含 “当前计算值” - Prompt N:提取「置信度 + 答案」→ 文字:
After thinking, I am sure the answer is 7→hi+1 包含 “最终结论”
CoT思维链将推理从隐空间H拓展到自然语言token空间O,利用自然语言强大的表达能力支持中间推理步骤的存储与传递,从而提升了模型的推理能力。
4. 步骤模板Step template
CoT 是「让模型分步思考」的目标,而Step template 是「让模型按规范分步思考」的实现手段。
形式上step template就是一段固定结构的格式,告诉模型:
- 先输出什么
- 再输出什么
- 用什么句式
- 分几步思考
- 输出要长成什么样
它不提供答案,只提供 “架子”。
比如,售后客服场景:
步骤1:先确认用户订单信息(订单号、购买时间、商品类型)
步骤2:核对退款申请原因与商品售后政策是否匹配
步骤3:告知用户退款审核进度与预计到账时间
步骤4:同步后续跟进方式与客服联系方式
或者函数拟合场景:
输入:x
先计算 x²
再加上 x
得到 y =
这些固定结构、固定句式、固定流程,就是 step template。
Step template 相当于给 CoT 套了一个「标准化的壳」:
- 强制分步:模板规定了固定的步骤数和顺序,相邻步骤间的输出和输入,避免模型跳步、漏步、漏数据
- 统一格式:固定句式、固定结构,让输出可预期、可解析
- 引导推理:模板的步骤本身就是一种「推理路径提示」,帮模型沿着正确的逻辑走,提升推理准确率
- 可复用性:同一类任务(比如客服、写作、故障排查)可以用同一个模板,批量提升输出质量
6. 三种空间:Prompt Space,Answer Space , Search Space
CoT在理论上是具有通用问题的求解能力的,但实际应用中受限于 有限步数 与H->O的不完美转换。由于每步仅能从H中获得部分信息,如何筛选出所需的相关数据就变得极为重要。
通过将CoT拆解为:提示空间的模板搜索,答案空间的答案搜索。通过step template 约束高效的提示空间搜索可以降低答案空间复杂度。
| 名称 | 定义(论文原文) | 模型行为 |
|---|---|---|
| 提示空间Prompt Space | 所有可能的步骤模板(step template)的集合**(代表所有可能的方案) | 模型自主寻找 或者根据人工指定选择推理步骤模板 |
| 答案空间Answer Space | 给定任务下所有可能输出结果、推理路径与最终解的集合(代表所有可能的候选答案) | 基于选定的提示模板,搜索正确结果 |
搜索空间Search Space ,是描述模型探索范围的总概念,模型在提示空间找模板、在答案空间找答案 ,是提示空间 + 答案空间 所有可能性的统称 。
比如:针对于用户问题: find a sequence of legal moves that leads to the end game
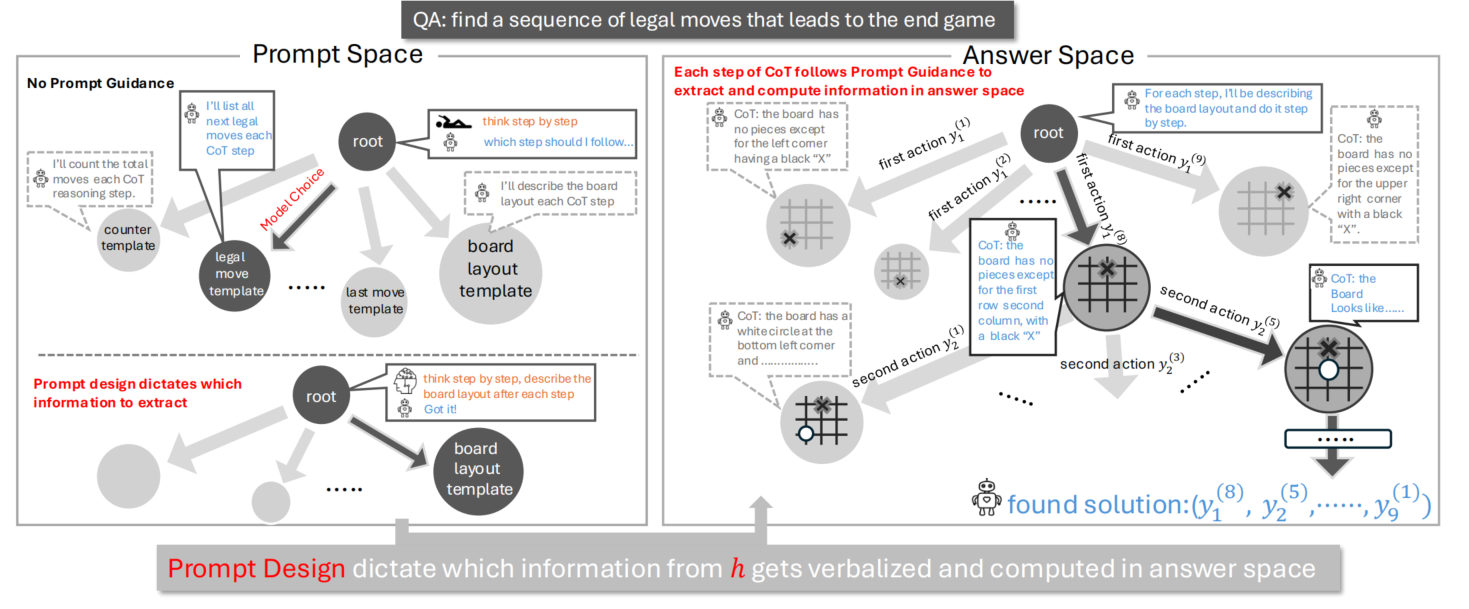
-
左边提示空间,决定「模型该提取什么信息、怎么说话」。当没有提示词指引时,模型可以自由的选择各种模板,模型在提示空间内随机游走,信息提取混乱,推理的正确率和效率极低 ;而当有提示词指引时,可以强制锁定到指定的“board layout template”,要求模型在每一步只从隐状态中提取出来棋盘布局的信息,描述每一步棋盘布局的状态, 而不需要其它的信息。信息高度的聚焦,只保留对任务相关的信息,避免了冗余干扰。
-
右侧答案空间,包含了所有的可能的棋盘走法/推理步骤,模型会在提示引导下,一步步探索问题的解。 在CoT提示词的指引下,模型会一步一步的推理,在每一步完成后,都从隐信息中提取出来当前的棋盘布局信息,再将提取出来的信息作为下一步的输入。具体就是,每一步,都会在看了上一步之后的棋盘状态后,再采取的走法。其中,
CoT提示词在提示空间的作用是“空间收缩”,将“无限迷宫”变成“唯一赛道”;在答案空间起到的作用是“信息过滤和路径导航”,从每一步的隐信息中只提取棋盘状态,从而也约束了下一步的可能走向。CoT提示词相当于给你和目的地之间选了一条高速公路,同时路上只给你保留与目标相关的路牌。
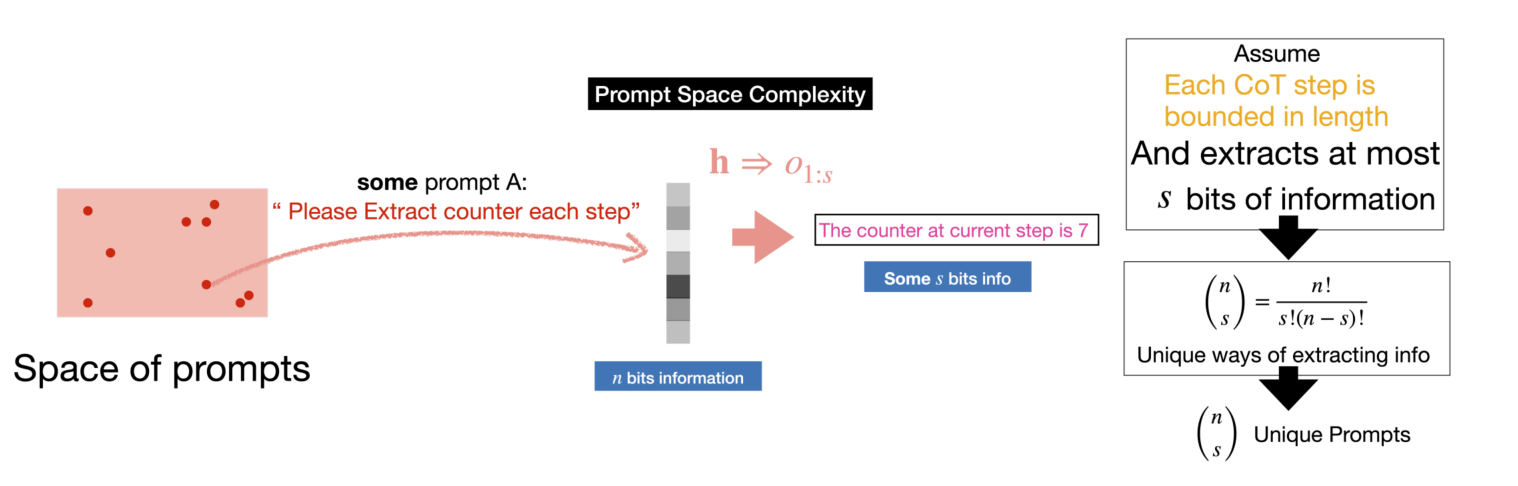
7. 提示空间搜索复杂度C(n,s)
提示信息搜索复杂度C(n,s)代表从 n 比特里选 s 比特的组合数
(ns)=n!s!(n−s)!\binom{n}{s} = \frac{n!}{s!(n-s)!}(sn)=s!(n−s)!n!
提示搜索复杂度C(n,s)依赖h中的隐信息中的信息总量n与每步CoT可提取的信息量s。
其中,
d:隐状态向量 h 的维度长度,对于已发布的模型是个固定值,相当于一个固定大小的信息盒子。比如:LLaMA-7B,隐状态维度 d = 4096;GPT-3 2.7B ,隐状态维度 **d = 2560。
n:h 中实际编码的任务信息量(bit),任务不同,实际存放的信息类型和总量都不同。 如果模型训练充分,任务信息量n与h的维度d、任务性质均成正比,即n∝d且n∝任务 。
s:从n中提取的信息(bit),s与CoT的token序列o长度相关,更长的CoT步骤通常能从n中提取更多信息。
由于提取什么样的信息S由CoT提示词来确定,因此,合适的CoT提示词能够降低搜索到的某个step template.
-
任务越复杂,过程需要生成的信息越多,n越大,提示信息搜索复杂度C(n,s)就越大;《== 如果可能,人类要提前自己通过代码将复杂任务分解成多个简单任务
-
要提取一半信息时,s 接近 n/2 ,复杂度最高;s 接近 0(啥也不提取–>信息太少,推理断线) 或 n (全部提取,信息过载,冗长干扰,无法聚焦,且受限于h维度,做不到)时复杂度最低。《== 要通过提示词去引导模型找到一个合适的s, 信息完整且搜索可行(刚好包含下一步推理需要的完整的信息,同时C(s,n)不能太大)。
注: 隐状态 h 里存储的信息n中,大部分信息对任务没用,真正有用的只有 m 比特,且 m << n。模型用启发式规则缩小搜索空间,用互信息 I (n, y)衡量 n里有多少信息是对 任务输出y 真正有用的。 所以, 实际的提示搜索复杂度可估算为C(I(n,y),s).
8. 答案空间复杂度len(CR)len(S)∣p\frac{\text{len}(\mathcal{CR})}{\text{len}(\mathcal{S})} \mid plen(S)len(CR)∣p
len(CR)len(S)∣p\frac{\text{len}(\mathcal{CR})}{\text{len}(\mathcal{S})} \mid plen(S)len(CR)∣p , 是指在给定一个提示词模板p时, 解决方案空间(Solution Set) 在 the entire answer space中的比例, 即有效解占比,用于衡量模板p对答案空间的筛选效果。其中:
-
the answer space S = (s1*,* s2*, . . . ,* s∞) contains all possible combinations of action sequences s.
-
The solution set CR ⊂ S includes all valid action sequences that lead to the end of the game, being a subset of the entire answer space S.
-
a specific step template p(即从隐状态 h 中提取信息的策略)
因为 p 决定了在 ht⇒ht+1 过程中需要传递(overlay)的信息,这些传递给下一步的信息决定了下一步计算时答案空间的大小。需要找到一个合适的P,让$\frac{\text{len}(\mathcal{CR})}{\text{len}(\mathcal{S})} $ 最小, 即有效解在整个空间的占比最小,模型越容易搜索到答案。
可以把这个过程想象成「找钥匙」:
-
SSS:整个房子(所有可能放钥匙的地方,答案空间)
-
CRCRCR:钥匙实际在的那几个房间(有效解集合)
-
ppp:朋友给你的提示(step template,比如「钥匙在客厅 / 卧室,不在厨房 / 卫生间」)
-
len(CR)len(S)∣p\frac{\text{len}(\mathcal{CR})}{\text{len}(\mathcal{S})} \mid plen(S)len(CR)∣p:给了提示后,「钥匙可能在的区域」占「整个房子」的比例
没提示时,你要搜索整个房子,而有了提示之后,你只搜客厅 / 卧室,不确定性大幅降低,找钥匙就越简单.
可以看到,一份对「有效解集合」进行了约束的提示词可以大幅降低答案空间复杂度。
二、ICL运行机制
1. ICL是个计算系统
通过前面的论文的研究, 我们可以认为:
-
Prompt :是外部程序,存储了任务参数 / 计算逻辑;模型把 Prompt 当作 “可寻址的内存”,从中可以读出任务参数(常量/变量),也可以读出计算逻辑(方法);
-
Transformer 是执行器,包括 三大部件:
1)Attention(注意力):作为结构化路由 / 检索器—— 从 Prompt 这个 “内存空间” 中,根据任务需要精准检索对应的信息(比如检索目标是 “推理” 而非 “总结”);
2) FFN(前馈网络):电路实现子系统—— 用 Attention 检索到的 Prompt 信息,结合模型当前的输入状态,执行本地局部计算Local computation(如线性变换、ReLU 激活等),完成子程序级的算术/逻辑操作;
3) Depth-wise stacking(深度堆叠):模块化计算系统—— 单一层的 Attention+FFN 只能做简单本地局部计算,多层堆叠能把这些局部计算逐步累积、组合成为多步程序(multiple-step program),最终实现复杂的多步骤计算任务(比如逻辑推理、多步预测)。
2)ICL具备图灵完备性
通用图灵机由纸带(内存)、读写头和状态转移函数组成。ICL 可通过以下方式模拟这些组件:
| 通用图灵机(UTM)组件 | 高级语言程序 | ICL |
|---|---|---|
| 纸带(内存) | 程序里的变量 / 对象 / 内存状态 | 隐状态hi 显式化:将模型内部的隐藏状态外化为上下文文本序列( o1,o2,…,oko1,o2,…,o**k )。这些 Token 充当“外部记忆体”,承载中间推理结果、待更新的状态及历史计算痕迹。 |
| 读写头 | 函数间传递对象引用(&h)或指针操作 |
注意力聚焦与上下文更新:模型通过自注意力机制“读取”上下文中的特定 Token(聚焦),并通过生成新的 Token 来“写入”状态。这表现为将变量 ht序列化为字符串输入,再输出更新后的 ht+1,实现状态的传递与修改。 |
| 状态转移函数 | for/while 循环,逻辑判断 |
思维链(CoT)与迭代推理:编码在提示模板中的算法逻辑。引导模型基于当前上下文(纸带)执行“读取→推理→生成”的循环,通过“文字→向量→文字”的转换,在 Transformer 架构中模拟出逐步推进的计算过程。 |
由于提示模板可设计为编码任意状态转移函数,且CoT步骤可无限延伸(理想条件下),搭载CoT的LLM可模拟任意通用图灵机,进而实现图灵完备性。即通过提示模板可以实现与现有高级语言同样的能力。
3)Prompt执行与程序类似
在一个prompt中,至少包括了:
- 任务目标:说明任务的作用,输入和输出,是程序的方法名,输入参数,输出参数
- Step template,规定了执行顺序,格式,步骤,是外部程序结构,包含了控制流,执行流程
- 示例,展示了“输入->输出” 行为模式,用于引导、激活任务函数,起到了“梯度下降”校验并减少误差的作用
当模型根据prompt来执行时:
- 在读取完
任务目标、step template后,模型会初始化拟合出来一个临时函数/小模型,并通过示例来校验降低误差。- 在读取用户输入问题时,在任意的第i步
1). Attention中的归纳头从前序文本中提取相关的参数数据,传递给 模型拟合出来的临时函数作为输入参数
2). 临时函数执行运算
3). 从隐状态hi中根据step template中规定的输了提取出显性文本。- 前序所有的文本+第i步中提取出的显性文本一起,作为输入,进入到第i+1步的计算。
直至迭代完成。
以下,分别用两个例子来讲一下过程:
示例1. 数学计算
请根据下面的示例,先提取特征,再做非线性变换,最后输出结果。
输出必须严格按照以下步骤格式:
输入:x
步骤1:输入x
步骤2:计算x的平方
步骤3:计算x的2倍
步骤4:将平方结果与2倍结果相加,得到y
输出:y
示例1:
输入:1
步骤1:输入x=1
步骤2:平方:1²=1
步骤3:2倍:2×1=2
步骤4:相加:1+2=3
输出:3
示例2:
输入:2
步骤1:输入x=2
步骤2:平方:2²=4
步骤3:2倍:2×2=4
步骤4:相加:4+4=8
输出:8
现在请你计算:
输入:3
模型先根据任务指令和步骤模板拟合出临时函数 *y=x2+2x*,然后在每一步通过归纳头提取参数,传递给临时函数计算,再从隐状态按固定格式解码出步骤文本,不断把前文 + 当前步骤文本迭代输入下一步,直到 4 步全部完成,输出最终结果。
阶段 1:初始化与拟合临时函数
第一步执行: 模型首先任务指令及Step template
请根据下面的示例,先提取特征,再做非线性变换,最后输出结果。
输出必须严格按照以下步骤格式:
输入:x
步骤1:输入x
步骤2:计算x的平方
步骤3:计算x的2倍
步骤4:将平方结果与2倍结果相加,得到y
输出:y
根据这个固定步骤结构,拟合出一个临时函数,可以理解为:f(x)=x2+2x,函数的执行步骤为4步
第二步执行: 读入示例
示例1:
输入:1
步骤1:输入x=1
步骤2:平方:1²=1
步骤3:2倍:2×1=2
步骤4:相加:1+2=3
输出:3
示例2:
输入:2
步骤1:输入x=2
步骤2:平方:2²=4
步骤3:2倍:2×2=4
步骤4:相加:4+4=8
输出:8
模型再用示例 1(x=1)、示例 2(x=2)去校验这个临时函数,修正误差,确保步骤格式和计算逻辑完全对齐。
此时模型内部已经准备好了:
- 拟合得到的临时函数,以及该函数对应的固定 4 步执行模板
- 临时函数在每一步对应的数学运算逻辑
- 按照 step template,每一步应生成何种显性文本的输出规则
阶段2: 正式执行
整个过程拆成 输入→ 第 1 步 → 第 2 步 → 第 3 步 → 第 4 步→ 输出,涉及Attention 归纳头、临时函数、隐状态、显性文本。
-
归纳头提取参数
从前文提取用户输入的数值:3 -
传入临时函数
函数执行:记录输入值 -
从隐状态 h0 提取显性文本
按模板输入段格式输出:输入:3
-
构建下一步输入
前序文本 + 本段文本 → 传入第 1 步
-
归纳头提取参数
Attention 归纳头扫描当前所有输入:-
任务指令
-
步骤模板
-
新输入:3
从中提取关键参数: x=3
-
-
临时函数执行
临时函数执行执行赋值操作:x=3 -
从隐状态 h1 提取显性文本
模型根据 Step template 规定的步骤 1 格式,从隐状态中解码出显性文本:步骤 1:输入 x=3
-
构建下一步输入
前序文本 + 步骤 1 显性文本 → 作为第 2 步的输入。
-
归纳头提取参数
Attention 归纳头从前序所有内容中找到:- 步骤模板要求:计算平方
- 已确定:x=3
提取参数:x=3,操作:平方。
-
临时函数运算
临时函数执行:x2=32=9x^2=3^2=9x2=32=9
-
从隐状态 h2 提取显性文本
按步骤 2 模板解码:步骤 2:平方:3²=9
-
构建下一步输入
前序文本 + 步骤 1 + 步骤 2 → 第 3 步输入。
-
归纳头提取参数
Attention 归纳头从前序所有内容中找到:- x=3
- 操作:计算 2 倍
-
临时函数运算
临时函数执行2x=2×3=62x=2×3=62x=2×3=6 -
从隐状态 h3 提取显性文本
按模板输出:步骤 3:2 倍:2×3=6
-
构建下一步输入
前序文本 + 步骤 1+2+3 → 第 4 步输入。
-
归纳头提取参数
Attention 归纳头从前文提取两个关键结果:- 平方结果:9
- 2 倍结果:6
- 操作:相加。
-
临时函数运算
临时函数执行 9+6=15 -
从隐状态 h4 提取显性文本
按步骤 4 模板输出:步骤 4:相加:y=9+6=15
-
最终输出
再从隐状态提取最终显性结果:输出:15
-
归纳头提取参数
提取最终计算结果:
y=15 -
临时函数执行
临时函数执行返回结果 y -
从隐状态 h₆ 提取显性文本
输出:15
-
终止迭代
已完成 Step Template 全部 6 段,不再继续生成
场景2:售后客服
你是专业售后智能分析师
你的任务是分析用户的备注信息,识别并提取出来关键信息。
处理客户备注时,请严格按照以下步骤思考(CoT),不要跳过任何一步:
输入:用户的原始备注内容
步骤 1:提取客户描述的所有事实
步骤 2:识别客户明面上的诉求
步骤 3:挖掘客户未明说的隐性诉求
步骤 4:判断情绪与紧急程度
步骤 5:综合所有信息,给出状态机可执行的结构化结果
输出:按以下指定字段输出 JSON
{
fact:提取的关键事实
explicit_intent:显性诉求
implicit_intent:隐性诉求
emotion:情绪(不满 / 焦虑 / 生气 / 失望 / 无奈 / 平静)
priority:高 / 中 / 低
next_action:回电安抚 | 优先处理 | 催促补发 | 发起退款 | 升级专员 | 核实物流 | 驳回申请
}
示例:
输入:我上周申请换货,客服说 3-5 天到货,现在第 8 天还没收到。联系客服,他们说查不到物流,让我继续等,但我下周要出差,很急。
CoT 思考过程(模型内部执行):
步骤 1:事实:已申请换货,超过承诺时间未收到,客服查不到物流,用户下周出差。
步骤 2:显性诉求:想知道换货物流状态。
步骤 3:隐性诉求:希望尽快拿到商品,担心出差前收不到,担心平台不作为。
步骤 4:情绪:焦虑 + 不满。
步骤 5:优先级高,下一步动作:核实物流 + 优先处理。
输出 JSON:
{
"fact": "换货超时未送达,客服无法查询物流,用户即将出差",
"explicit_intent": "查询物流",
"implicit_intent": "希望尽快收到,担心收不到",
"emotion": "焦虑",
"priority": "高",
"next_action": "核实物流并优先处理"
}
==================================================
请处理以下客户备注,先内部思考,最后只输出 JSON:
客户备注:
商品刚收到就是坏的,申请退款三天没人处理,客服每次都说 24 小时回复,结果一直没人联系我。我现在不想要了,必须退款,否则我要投诉。
阶段 1:初始化拟合临时函数
你是专业售后智能分析师
此步的实质是通过角色来限定答案搜索空间为与“专业售后智能分析师”相关的空间
你的任务是分析用户的备注信息,识别并提取出来关键信息。
处理客户备注时,请严格按照以下步骤思考(CoT),不要跳过任何一步:
输入:用户的原始备注内容
步骤 1:提取客户描述的所有事实
步骤 2:识别客户明面上的诉求
步骤 3:挖掘客户未明说的隐性诉求
步骤 4:判断情绪与紧急程度
步骤 5:综合所有信息,给出状态机可执行的结构化结果
输出:按以下指定字段输出 JSON
{
fact:提取的关键事实
explicit_intent:显性诉求
implicit_intent:隐性诉求
emotion:情绪(不满 / 焦虑 / 生气 / 失望 / 无奈 / 平静)
priority:高 / 中 / 低
next_action:回电安抚 | 优先处理 | 催促补发 | 发起退款 | 升级专员 | 核实物流 | 驳回申请
}
此时,模型会根据任务指令和步骤,拟合出来一个临时任务函数(此处也可以称为执行特定任务的小模型,因为大模型本质上就是一个超大参数的拟合函数)。此处,规定了这个函数的输入参数、输出参数、执行步骤。
示例:
输入:我上周申请换货,客服说 3-5 天到货,现在第 8 天还没收到。联系客服,他们说查不到物流,让我继续等,但我下周要出差,很急。
CoT 思考过程(模型内部执行):
步骤 1:事实:已申请换货,超过承诺时间未收到,客服查不到物流,用户下周出差。
步骤 2:显性诉求:想知道换货物流状态。
步骤 3:隐性诉求:希望尽快拿到商品,担心出差前收不到,担心平台不作为。
步骤 4:情绪:焦虑 + 不满。
步骤 5:优先级高,下一步动作:核实物流 + 优先处理。
输出 JSON:
{
“fact”: “换货超时未送达,客服无法查询物流,用户即将出差”,
“explicit_intent”: “查询物流”,
“implicit_intent”: “希望尽快收到,担心收不到”,
“emotion”: “焦虑”,
“priority”: “高”,
“next_action”: “核实物流并优先处理”
}
通过这个示例,模型会校验并修正这个临时函数或者小模型的参数。形成最终的执行函数(小模型)
此时模型内部已经准备好了:
- 拟合得到的临时函数,包知该函数的输入、输出以及对应的固定 5 步执行步骤
- 临时函数在每一步对应的运算逻辑(此处为根据自然语言提取标签, 模型训练出来的能力)
- 按照 step template,每一步应生成何种显性文本的输出规则
阶段2: 正式执行
整个过程拆成 输入→ 第 1 步 → 第 2 步 → 第 3 步 → 第 4 步 → 第 5 步 → 输出,涉及 Attention 归纳头、临时函数、隐状态、显性文本。
- 归纳头提取参数
Attention 归纳头扫描所有前文,提取用户提供的原始客户备注内容:
商品刚收到就是坏的,申请退款三天没人处理,客服每次都说24小时回复,结果一直没人联系我。我现在不想要了,必须退款,否则我要投诉。
- 传入临时函数
临时函数接收并记录原始输入文本,作为后续所有步骤的依据。 - 从隐状态 h₀ 提取显性文本
按模板输入段格式输出:
输入:商品刚收到就是坏的,申请退款三天没人处理,客服每次都说24小时回复,结果一直没人联系我。我现在不想要了,必须退款,否则我要投诉。
- 构建下一步输入
前序文本 + 本段文本 → 传入第 1 步。
- 归纳头提取参数
Attention 归纳头从当前所有输入中提取:
- 任务要求:提取客户描述的所有事实
- 原始输入文本:商品刚收到就是坏的,申请退款三天没人处理,客服每次都说24小时回复,结果一直没人联系我。我现在不想要了,必须退款,否则我要投诉
提取参数:任务要求(“提取客户描述的所有事实”)、原始输入文本(上述用户输入完整原文)
- 临时函数执行
临时函数接收归纳头提取的原始输入文本,按“提取客户描述的所有事实”的任务要求,对原始文本进行整理、去重、精炼,筛选出客观、可验证的关键事实信息,形成结构化事实描述 - 从隐状态 h₁ 提取显性文本
按步骤 1 模板解码:
步骤1:事实:商品收到即损坏,申请退款三天未处理,客服承诺24小时回复但未兑现。
- 构建下一步输入
前序文本 + 步骤1 显性文本 → 作为第 2 步的输入。
- 归纳头提取参数
Attention 归纳头从前序所有内容中找到:
- 步骤模板要求:识别客户明面上的诉求
- 用户的原始诉求语句
- 已提取的事实内容:事实:商品收到即损坏,申请退款三天未处理,客服承诺24小时回复但未兑现
提取参数:步骤模板要求(“识别客户明面上的诉求”)、步骤1显性文本(“事实:商品收到即损坏,申请退款三天未处理,客服承诺24小时回复但未兑现”)、用户需求原句相关内容(“我现在不想要了,必须退款,否则我要投诉”)。
- 临时函数运算
临时函数接收归纳头提取的参数,聚焦用户需求原句,对显性意图进行归类与概括,剔除冗余表述,形成清晰、规范的显性诉求。 - 从隐状态 h₂ 提取显性文本
按步骤 2 模板解码:
步骤2:显性诉求:要求立即退款。
- 构建下一步输入
前序文本 + 步骤1+2输出 → 第 3 步输入。
- 归纳头提取参数
Attention 归纳头从前序所有内容中找到:
- 步骤模板要求:挖掘未明说的隐性诉求
- 用户的原始诉求语句
- 已提取的事实内容
提取参数:步骤模板要求(“识别客户明面上的诉求”)、步骤1显性文本(“事实:商品收到即损坏,申请退款三天未处理,客服承诺24小时回复但未兑现”)、用户原句中情绪相关内容(“否则我要投诉”)。
- 临时函数运算
临时函数基于归纳头提取的参数,对步骤1显性文本中的事实(商品收到即损坏,申请退款三天未处理,客服承诺24小时回复但未兑现)和情绪原句(否则我要投诉)进行推理归纳,提炼出用户未直接说出的深层需求——希望得到快速响应和解决方案,对服务效率不满并可能寻求外部投诉施压。 - 从隐状态 h₃ 提取显性文本
按步骤 3 模板解码:
步骤3:隐性诉求:希望得到快速响应和解决方案,对服务效率不满并可能寻求外部投诉施压。
- 构建下一步输入
前序文本 + 步骤1+2+3输出→ 第 4 步输入。
- 归纳头提取参数
Attention 归纳头从前文提取:
- 步骤模板要求:判断情绪与紧急程度
- 用户表述关键词:坏的、没人处理、一直没人联系、必须退款、投诉
提取参数:步骤模板要求(“判断情绪与紧急程度”)、原始输入中的情绪和紧急程度相关的原句(“坏的“、“没人处理“、“一直没人联系“、“必须退款“、“投诉“)。
-
临时函数运算
临时函数接收归纳头提取的关键词原句,结合关键词的语气和语义,进行情绪分类与优先级判定,最终得出情绪为生气,优先级为高。 -
从隐状态 h₄ 提取显性文本
按步骤 4 模板解码:
步骤4:情绪:生气;紧急程度:高。
- 构建下一步输入
前序文本 + 步骤1+2+3+4 → 第 5 步输入。
- 归纳头提取参数
Attention 归纳头从前文提取所有关键信息:
- 事实:商品收到即损坏,申请退款三天未处理,客服承诺24小时回复但未兑现
- 显性诉求:要求立即退款
- 隐性诉求:希望得到快速响应和解决方案,对服务效率不满并可能寻求外部投诉施压。
- 情绪:生气
- 优先级:高
提取参数:事实,显性诉求,隐性诉求,情绪,优先级
-
临时函数运算
临时函数综合所有信息,映射到可执行动作,确定下一步操作为优先处理并升级专员。 -
从隐状态 h₅ 提取显性文本
按步骤 5 模板解码:
步骤5:综合结果:优先级高,下一步动作:优先处理并升级专员。
- 构建下一步输入
前序文本 + 步骤1~5 所有显性文本 → 进入最终输出步骤。
- 归纳头提取参数
归纳头从前序所有步骤结果中提取指定字段内容:
- 事实:商品收到即损坏,申请退款三天未处理,客服承诺24小时回复但未兑现
- 显性诉求:要求立即退款
- 隐性诉求:希望得到快速响应和解决方案,对服务效率不满并可能寻求外部投诉施压。
- 情绪:生气
- 优先级:高
- 下一步动作:优先处理并升级专员
提取参数:事实,显性诉求,隐性诉求,情绪,优先级,下一步动作
- 临时函数执行
临时函数按指定 JSON 结构对各字段进行组装,保证格式规范、无多余文字。
- fact:完整事实
- explicit_intent:显性诉求
- implicit_intent:隐性诉求
- emotion:情绪
- priority:优先级
- next_action:执行动作
- 从隐状态 h₆ 提取显性文本
输出:
{
“fact”: “商品收到即损坏,申请退款三天未处理,客服承诺24小时回复但未兑现”,
“explicit_intent”: “要求立即退款”,
“implicit_intent”: “希望得到快速响应和解决方案,对服务效率不满并可能寻求外部投诉施压”,
“emotion”: “生气”,
“priority”: “高”,
“next_action”: “优先处理并升级专员”
}
- 终止迭代
已完成 Step Template 全部 7 段结构,不再继续生成。
三、总结
从上面的过程中可以看出,ICL的运行过程,本质上是在提示词指引下的程序执行过程。提示词定义了任务的目标、输入、输出以及执行过程,与程序中一个方法的方法名,输入参数、返回值,以及过程代码是等同的。
在执行过程中,模型会首先根据任务目标和step template 初步化一个临时的函数/小模型 ,经过 示例 的校验和更正,形成运行期方法栈;然后开始根据用户的输入,依次执行每一个步骤。
在相邻的两个步骤之间:前一步模型按提示词指引“将模型内部隐藏的数据转换为明文字符显式输出”作为下一步的输入参数;在后一步,通过归纳头“从前序输出的明文文本中提取出来数据作为输入参数”参与本步骤运算;如引循环迭代,直至完成所有的步骤。
了解了以上ICL的运行过程,以及提示词在其中的“类程序”作用,作为一名程序员,我们应该能深刻的理解我们在上一篇中,《提示词写作的22条黄金法则》中的第一条“把提示词写成外部程序一样的严格指令,结构固定、逻辑清晰,语义明确”的含义所在。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 24
24 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)