用爬虫爬取东方财富新发基金表 - 动态数据爬出
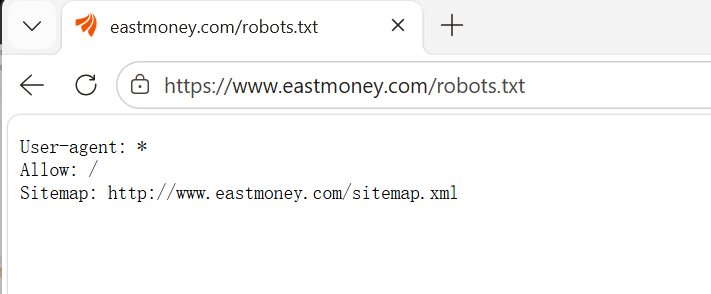
一、 查看robots协议
东方财富的robots协议允许爬取,在爬取任何资源时注意查看robots协议,查看方法:域名/robots.txt
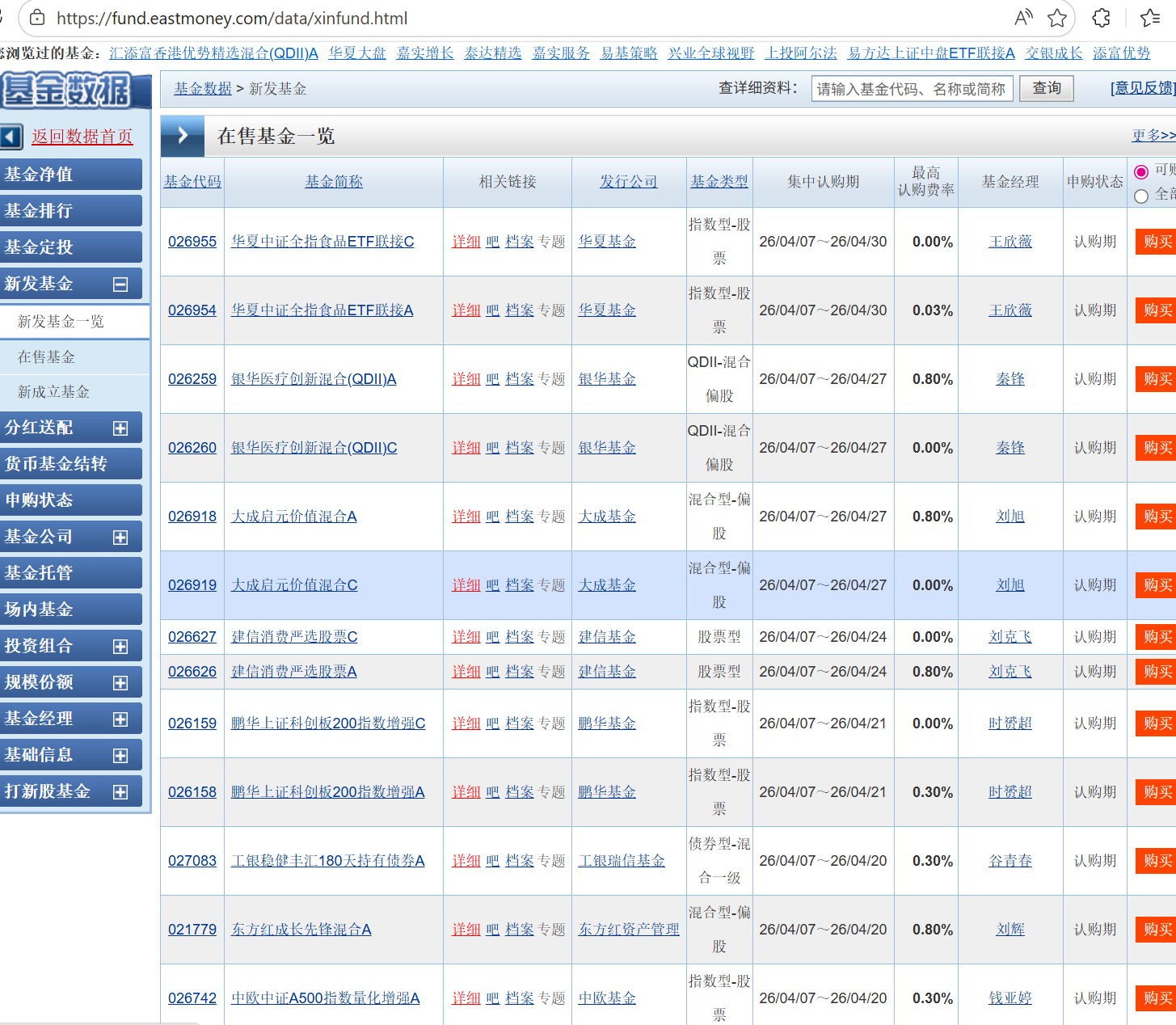
二、 找到想要的数据
我想要爬取这个网址里的第一个表格
在该页面右键检查或者时按F12打开开发者模式,不行的可以按Fn+F12
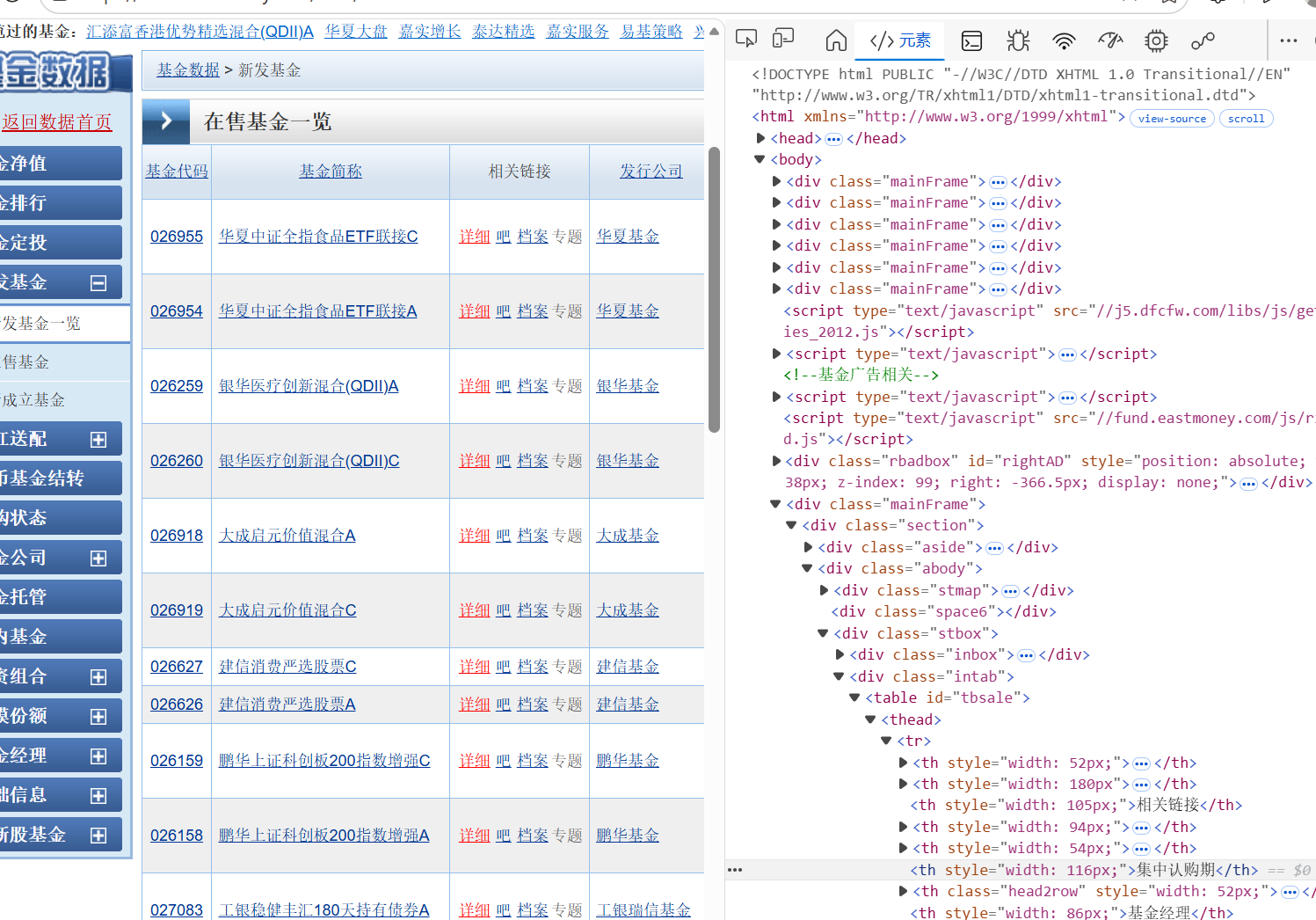
可以看到右边是HTML的代码形式,但是通过浏览是无法看到表格的实际数据。这是因为大部分数据网站将数据放在外部js文件里,通过API获取实时数据,再用javascript动态渲染到表格中。
那么我们需要的是找到真实的数据放在哪里,这里我们在开发者模式里切换到网络,刷新页面后在XHR/Fetch查找,不过我的XHR/Fetch里是空的,所以我使用笨办法,在js里一个一个点击查看响应哪个页面有存放数据。
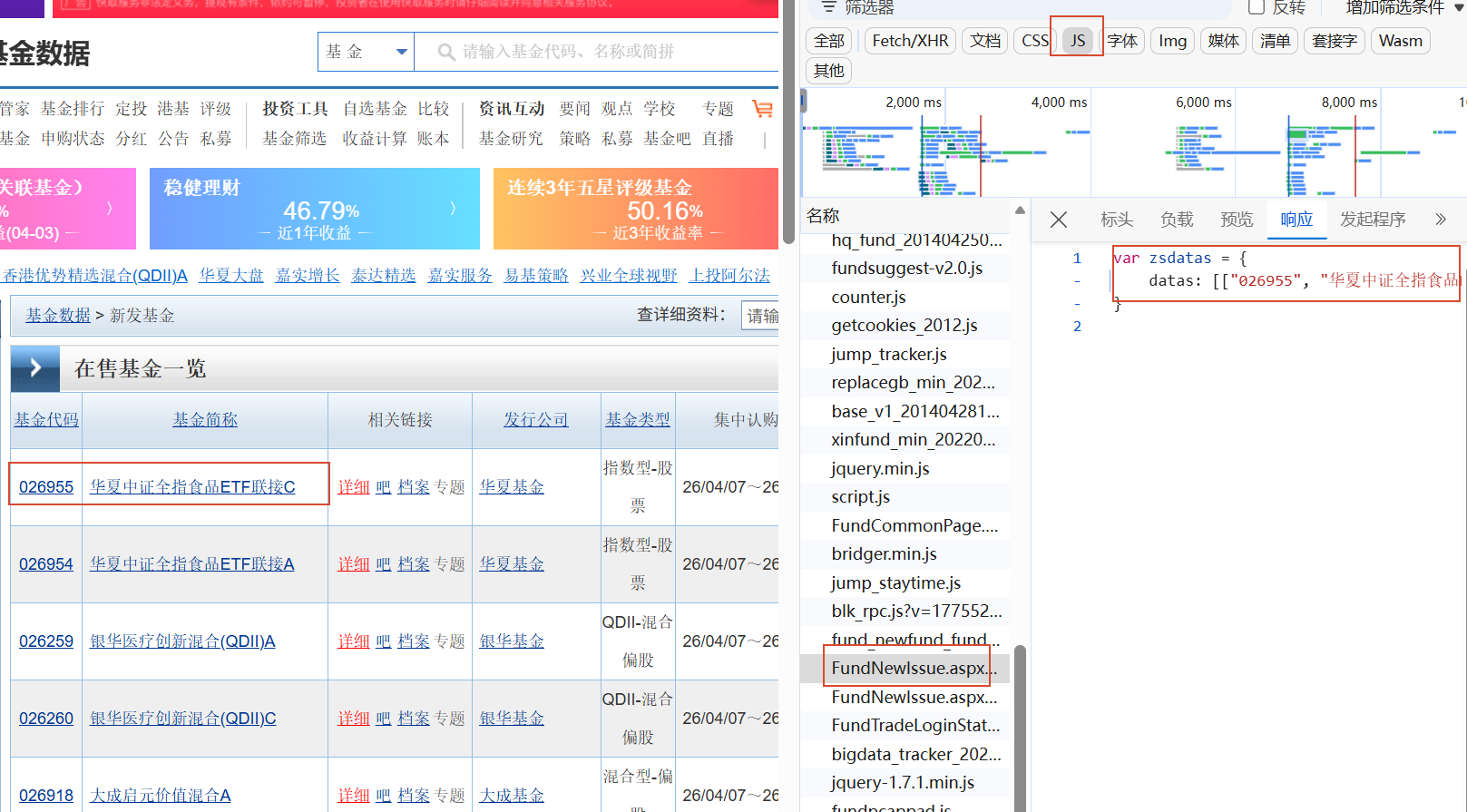
可以看到红色框选出名称的响应里是我所想要的在售基金信息,点击标头可以看到数据存放的url
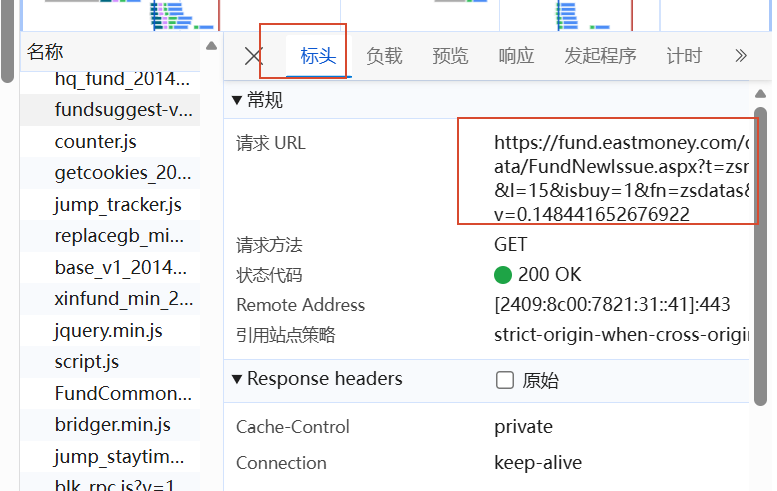
复制url打开,可以看到数据,我们就可以通过程序将数据爬取下来
三、使用python获取数据
需要使用到的方法有python里的requests、正则表达式re、json、csv文件、random
<
import requests
import re
import json
import csv
import random
def getfundinfo(url):
UAlist = ['Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/146.0.0.0 Mobile Safari/537.36 Edg/146.0.0.0',
'Mozilla/5.0 (iPhone; CPU iPhone OS 18_5 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/18.5 Mobile/15E148 Safari/604.1 Edg/146.0.0.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/18.5 Safari/605.1.15 Edg/146.0.0.0'
] #uer-agent池,避免网站识别爬虫程序而不返回一些数据
headers = {'User-Agent': random.choice(UAlist)} #使用random方法,随机选择代理池里的数据给headers
response = requests.get(url,headers=headers)
content = response.content.decode('utf-8')
return content # 返回内容了,单内容只在函数里,要在外面也出现
# print(f'网页内容:{content}')
# print(f'状态码{response.status_code}')
# print(f'{type(content)}') # 这里可以打印看一下有没有获取成功
content = getfundinfo('https://fund.eastmoney.com/data/FundNewIssue.aspx?t=zsn&l=15&isbuy=1&fn=zsdatas&v=0.14893924439939432') #调用函数将内容保存到content里
data = re.compile('\["(\d+)","([^"]+)","([^"]+)","(\d+)","([^"]+)","([^"]+)","([^"]+)","([^"]+)","([^"]*)","([^"]*)","([^"]+)","([^"]+)","([^"]+)"\]') #这里使用正则表达式对js数据进行整理,可以去问ai比自己想会快很多
matches = data.findall(content)
csv_file = 'ready_sale_fund.csv' #将数据写入csv文件,可以让你得到你想要的表格样式,还可以用excel打开
with open(csv_file, 'w', newline='',encoding='utf-8-sig') as f:
writer = csv.writer(f) #
writer.writerow(['基金代码','基金简称','发行公司','基金类型','集中认购期','最高认购费率','基金经理','申购状态'])
writer.writerows(matches)
print(f'已保存{len(matches)}条记录到{csv_file}')
/>
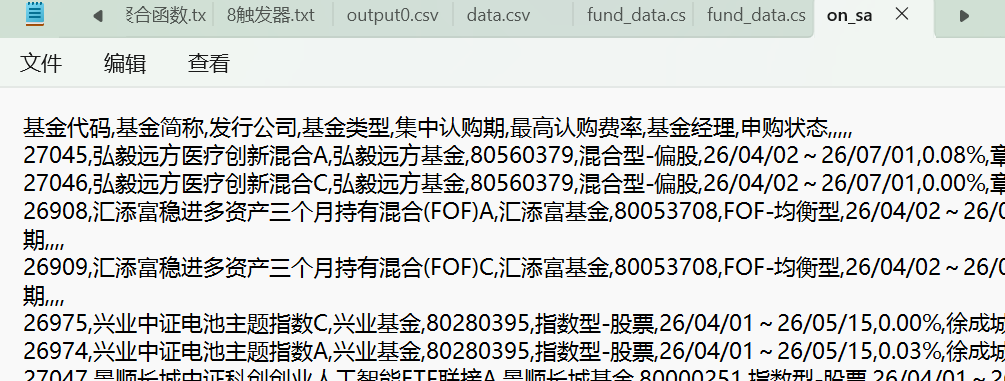
成功后可以打开csv文件如下图:

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)