揭秘 Cortex Memory:三层记忆架构如何实现 18 倍效率提升?
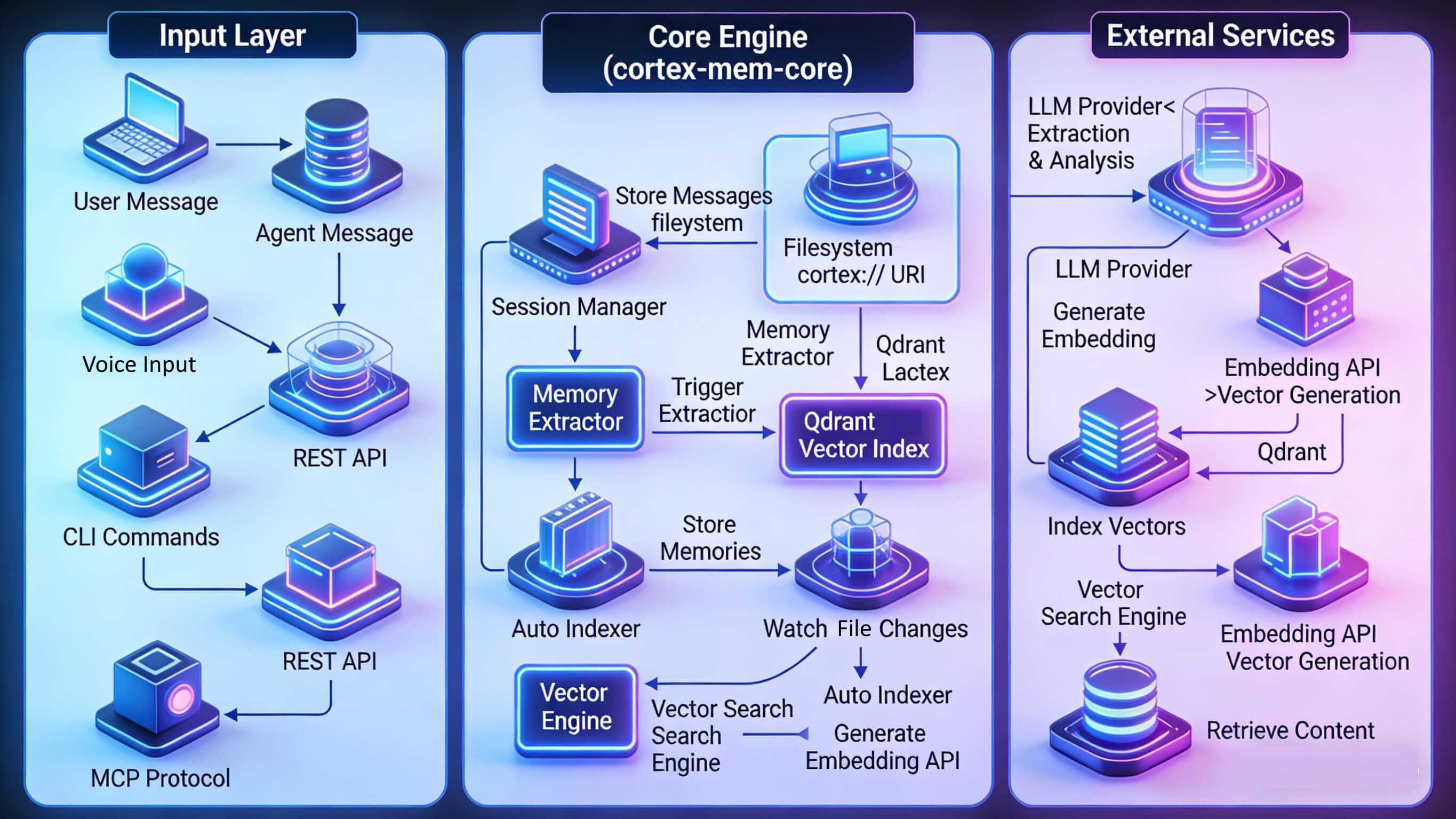
上一篇我们介绍了 Cortex Memory (https://github.com/sopaco/cortex-mem)的核心价值——在 LoCoMo 评测中拿下最高分的同时,Token 效率比竞品高出 18 倍。你可能会好奇:这背后到底用了什么黑科技?
答案其实很简单:三层记忆架构 + 渐进式检索。但"简单"不等于"简陋",这套架构背后的设计哲学值得每一个 AI 工程师深思。
让我们深入引擎舱,看看 Cortex Memory 是如何运转的。
核心设计哲学:分层是解药
在讨论具体实现之前,我们需要先理解 Cortex Memory 试图解决的根本矛盾: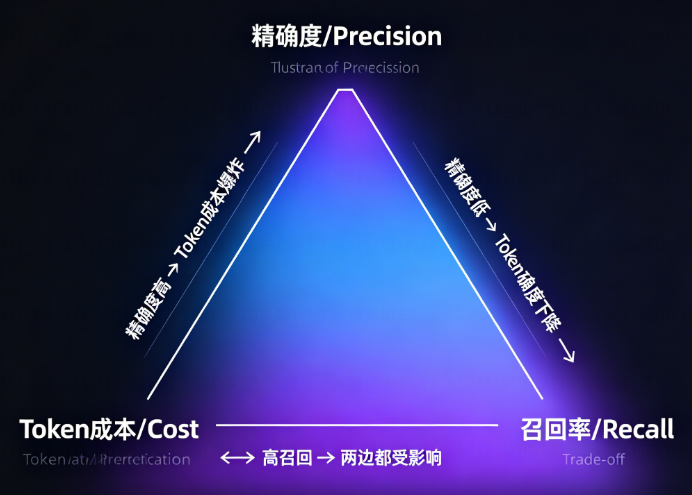
记忆检索的"不可能三角"
- **想要精确度高** → 需要加载更多上下文 → Token 成本爆炸
- **想要 Token 低** → 只能存摘要 → 精确度下降
- **想要高召回** → 需要扩大搜索范围 → 两边都受影响
传统方案的困境在于:**把所有记忆当作同一粒度处理**。要么全部加载(OpenClaw 原生方案),要么全部压缩成摘要(部分 RAG 方案)。
Cortex Memory 的解法是:**承认记忆天然有层次,让不同粒度的记忆各司其职**。
---
## 三层记忆架构详解
### L0 抽象层:快速定位的"索引卡片"
**Token 消耗**:~100 tokens
**核心职责**:粗粒度候选筛选
**权重**:20%
想象你在图书馆找书,L0 层就是书脊上的标签——"计算机科学"、"小说"、"历史"。你不会读完每本书再决定,而是先看标签快速筛选。
**L0 层的实现**:
```markdown
# 抽象示例
2024-03-15 与张三讨论 TypeScript 项目架构决策,确定使用 Monorepo 方案,
核心争议点是是否引入 Nx 工具链。最终决策:采用轻量级 pnpm workspace。
关键特征:
- 单段话,2-4 句
- 捕获"谁、什么、何时、什么决策"
- LLM 自动生成,按需缓存到
.abstract.md文件
L1 概览层:结构化的"读书笔记"
Token 消耗:~500-2000 tokens
核心职责:上下文精炼、关键信息提取
权重:30%
当你决定"这本书值得深读"后,L1 层就是你的读书笔记——核心观点、关键数据、待跟进问题。
L1 层的实现:
# 概览示例
## 核心主题
- 项目架构设计
- 工具链选型
## 关键决策
1. **Monorepo 方案确定**:pnpm workspace + Turborepo
2. **TypeScript 配置**:strict mode 全量开启
## 关键实体
- 张三:技术负责人
- pnpm workspace:选定的包管理方案
## 时间线
- 2024-03-15 10:30:开始架构讨论
- 2024-03-15 11:45:确定最终方案
## 待办事项
- [ ] 配置 shared packages
- [ ] 迁移现有代码
关键特征:
- 结构化 Markdown,带 YAML frontmatter
- 包含摘要、关键点、实体、时间线
- 支持后续增量更新
L2 细节层:完整的"原始对话"
Token 消耗:完整内容(可变)
核心职责:精确匹配、完整上下文
权重:50%
L2 层就是原始对话记录,一字不改。只有在 L0/L1 层都确认"这个记忆高度相关"后,才会加载 L2。
L2 层的实现:
# 原始对话片段
**张三**:我觉得 Nx 工具链太重了,我们团队之前踩过坑
**李四**:确实,我们之前用 Nx,CI 时间从 5 分钟涨到 15 分钟
**张三**:那 pnpm workspace + Turborepo 的组合怎么样?
听说 Vercel 团队就是用这个方案
**李四**:我调研过,轻量很多,而且支持增量构建
...(完整对话继续)
渐进式检索算法
理解了三层结构,我们来看检索是如何进行的:
评分公式
最终得分 = 0.2 × L0得分 + 0.3 × L1得分 + 0.5 × L2得分
为什么是这个权重?
- L0 权重低(20%):因为它只是粗筛,精确度有限
- L1 权重中(30%):提供了结构化信息,但仍是摘要
- L2 权重高(50%):这是真正的内容,精确匹配最重要
降级策略
当某一层搜索结果不足时,系统会自动降级:
1. 初始阈值:0.45
2. 无结果?→ 降到 0.35
3. 仍不足?→ 降到 0.28
4. 还是不行?→ 启用"用户域补充搜索"
5. 最终兜底?→ 文件内容关键词扫描(词法回退)
虚拟文件系统:cortex:// URI 方案
Cortex Memory 的另一个创新点是用文件系统的思维组织记忆。
URI 结构
cortex://{维度}/{范围}/{类别}/{资源ID}
示例:
cortex://session/abc123/timeline/2024-03-15_001.md
cortex://user/default/preferences/typescript.md
cortex://agent/tars/cases/api-design-001.md
cortex://resources/docs/architecture.md
四大维度
| 维度 | 用途 | 示例场景 |
|---|---|---|
session |
会话记忆 | 对话时间线、消息历史 |
user |
用户记忆 | 偏好、实体、事件、目标 |
agent |
Agent 记忆 | 案例、技能、学习经验 |
resources |
知识资源 | 文档、事实库 |
物理存储映射
URI 会映射到实际的文件系统路径:
cortex://session/abc123/timeline/2024-03-15_001.md
↓
{data_dir}/tenants/{tenant_id}/session/abc123/timeline/2024-03-15_001.md
好处:
- 人类可读:直接打开文件查看/编辑
- 版本控制友好:可以用 Git 管理记忆变更
- 调试方便:出问题时直接看文件
- 备份简单:复制目录即可
增量更新系统:记忆不是静态的
记忆系统最怕的是"只存不更"。Cortex Memory 实现了一套完整的增量更新机制: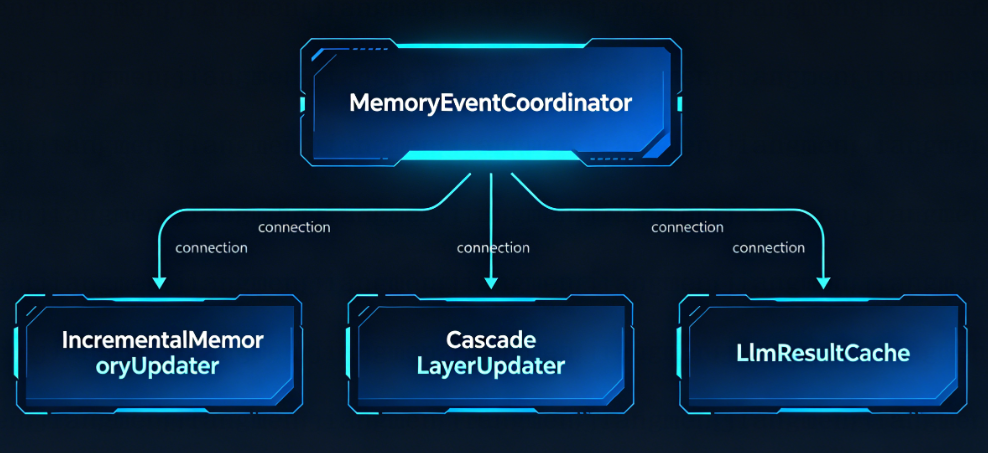
核心组件
┌─────────────────────────────────────────────────────────┐
│ MemoryEventCoordinator │
│ (事件协调器) │
└────────────────────┬────────────────────────────────────┘
│
┌───────────────┼───────────────┐
▼ ▼ ▼
┌──────────┐ ┌──────────────┐ ┌───────────────────┐
│Incremental│ │CascadeLayer │ │LlmResultCache │
│MemoryUpdater│ │Updater │ │(LLM 结果缓存) │
│(增量更新) │ │(级联更新) │ │ │
└──────────┘ └──────────────┘ └───────────────────┘
工作流程
- 变更检测:文件系统监视器检测到
.md文件变更 - 事件触发:
MemoryEventCoordinator接收变更事件 - 增量更新:
IncrementalMemoryUpdater只处理变化的部分 - 级联同步:
CascadeLayerUpdater更新受影响的 L0/L1 层 - 缓存命中:
LlmResultCache避免重复的 LLM 调用
关键优化:内容哈希检查
// 伪代码示意
if content_hash(file) == stored_hash {
skip_update(); // 内容未变,跳过
} else {
update_and_store_new_hash();
}
效果:在基准测试中,这套机制减少了 50-80% 的冗余处理。
记忆遗忘机制:艾宾浩斯遗忘曲线
记忆不能只增不减,否则存储会无限膨胀。Cortex Memory 实现了基于艾宾浩斯遗忘曲线的清理机制:
工作原理
记忆强度 = f(访问频率, 距上次访问时间, 重要性评分)
当 记忆强度 < 阈值:
归档或删除
配置示例
[memory_cleanup]
enabled = true
min_strength = 0.3 # 低于此强度的记忆会被清理
archive_before_delete = true # 删除前先归档
scan_interval_hours = 24 # 每天扫描一次
好处:
- 自动控制存储增长
- 保留高价值记忆
- 符合人类记忆规律
混合存储架构:文件系统 + 向量数据库
Cortex Memory 采用双重存储策略:
┌─────────────────────────────────────────────────────────┐
│ 存储层 │
├────────────────────────┬────────────────────────────────┤
│ 文件系统(真相来源)│ Qdrant(搜索索引) │
│ │ │
│ • 持久化保证 │ • 向量相似度搜索 │
│ • 人类可读 │ • 元数据过滤 │
│ • 版本控制友好 │ • 租户隔离 │
│ • 易备份恢复 │ • 毫秒级响应 │
└────────────────────────┴────────────────────────────────┘
同步机制
文件系统是"真相来源",向量数据库是"搜索索引"。两者通过 VectorSyncManager 保持同步:
- 写入:先写文件系统,再更新向量索引
- 读取:搜索走向量,内容取文件
- 同步:定期扫描,修复不一致
租户隔离
每个租户有独立的存储空间:
文件系统:
{data_dir}/tenants/tenant-a/
{data_dir}/tenants/tenant-b/
Qdrant 集合:
cortex-mem-tenant-a
cortex-mem-tenant-b
保证:即使配置错误,也不会发生跨租户数据泄漏。
性能优化:为什么 Rust 是正确选择
Cortex Memory 选择 Rust 而非 Node.js,背后有深刻的技术考量:
1. 异步 I/O 无阻塞
// Rust 的异步文件操作
pub async fn read_file(&self, path: &str) -> Result<String> {
tokio::fs::read_to_string(path).await?;
}
对比 Node.js:虽然 Node.js 也是异步,但某些操作会阻塞事件循环。
2. 零成本抽象
Rust 的泛型和 trait 在编译时展开,没有运行时开销。这意味着:
- 抽象层次可以很高
- 性能不会因为抽象而下降
3. 内存安全无 GC
Rust:编译时保证内存安全,无 GC 停顿
Node.js:V8 GC 在高负载下可能造成延迟抖动
4. 并发安全
Rust 的所有权系统在编译时防止数据竞争:
// 这段代码在编译时就会报错
let data = Arc::new(Mutex::new(vec));
let clone = data.clone();
thread::spawn(move || {
clone.lock().unwrap().push(1); // 编译通过
});
data.lock().unwrap().push(2); // 编译通过
实测数据:架构优势转化为性能优势
回到文章开头提到的 LoCoMo 评测数据,让我们从架构角度解读:
| 系统 | 得分 | Token 效率 | 架构特点 |
|---|---|---|---|
| Cortex Memory v5 | 68.42% | 23.6 | 三层架构 + 渐进检索 |
| OpenViking | 52.08% | 18.8 | 单层摘要 + 向量搜索 |
| OpenClaw+LanceDB | 44.55% | 1.3 | 全量注入 |
为什么 Cortex Memory 得分更高?
分层检索的"漏斗效应":
查询 → L0 筛选 100 条 → L1 精炼 20 条 → L2 确认 5 条
每一层都在缩小范围,提高精度。而传统方案要么全量比较(效率低),要么只比较摘要(精度差)。
为什么 Token 效率高出 18 倍?
按需加载策略:
传统方案:检索 100 条 × 平均 3000 tokens = 300,000 tokens
Cortex Memory:
- L0 层:100 条 × 100 tokens = 10,000 tokens
- L1 层:20 条 × 1500 tokens = 30,000 tokens
- L2 层:5 条 × 3000 tokens = 15,000 tokens
- 总计:55,000 tokens
节省比例:(300,000 - 55,000) / 300,000 = 81.7%
总结:架构的力量
Cortex Memory 的成功不是某个单一技术的突破,而是架构设计的胜利:
- 三层记忆架构:解决了精度与效率的矛盾
- 虚拟文件系统:让记忆可读、可管理、可版本控制
- 增量更新系统:让记忆保持新鲜,同时控制成本
- 遗忘机制:让存储可持续增长
- Rust 实现:保证性能和稳定性
这套架构的价值不仅在于 Cortex Memory 本身,更在于它为 AI Agent 记忆系统 提供了一个可参考的设计范式。
下一篇文章:我们将带来 MemClaw 插件的实战教程——从安装配置到高级用法,手把手教你给 OpenClaw 装上"超级大脑"。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)