Agent 记忆终于有救了!5 款开源框架横评,附落地架构选型指南
做 AI Agent 的朋友,你有没有遇到过这个让人崩溃的场景——
用户昨天告诉 Agent:“我是素食主义者,别给我推荐含肉的食谱。”
今天 Agent 回来了,热情洋溢地推荐了:红烧肉。
用户已经把你拉黑了。
这就是没有记忆的 Agent 的悲剧。
每次对话,都是一张白纸。
它不知道你是谁,不记得你说过什么,也不知道上次你们聊到哪里。
一个没有记忆的 Agent,只是一个高配版计算器。
所以,今天我来整理了 5 款最主流的 AI 记忆开源框架,帮你在架构选型上少走弯路。

先搞清楚:Agent 记忆分几种?
在选框架之前,你要先搞清楚你的 Agent 需要哪种记忆。
记忆类型标准已经趋于统一,分三种:

① 情景记忆(Episodic Memory)
具体发生过什么事——“用户上次说他不喜欢辣的”。
存的是对话片段、交互历史、事件记录。
② 语义记忆(Semantic Memory)
用户是什么人——“这个用户是个素食主义者,在上海工作,喜欢健身”。
存的是事实、偏好、用户画像,跨会话持久存在。
③ 程序记忆(Procedural Memory)
Agent 学会了什么——“每次用户问价格,先问他预算范围再推荐”。
存的是行为规则、学到的工作流、反思后的策略。
三种记忆叠加,才是一个真正"有脑子"的 Agent。
横评:5 款开源记忆框架
框架一:Mem0 — 最成熟的生产级选择
⭐ 4.8万 stars|GitHub:https://github.com/mem0ai/mem0|$24M 融资

一句话定位:给 Agent 装一个自动去重、三层隔离的智能记忆层。
架构特点:混合存储(Vector + Graph + KV)
Mem0 的核心设计有三层记忆作用域:
- User 层:用户偏好、历史画像(跨所有会话持久)
- Session 层:当前对话上下文(会话级别)
- Agent 层:Agent 自身的知识(Agent 私有)
最亮眼的是自编辑机制——当新事实与旧记忆冲突时,Mem0 自动更新旧记录而不是追加,保持记忆精简不冗余。
代码接入极简:
from mem0 import Memory
m = Memory()
# 存记忆
m.add("我是素食主义者,不吃肉", user_id="alice")
# 取记忆
memories = m.search("用户饮食偏好", user_id="alice")
print(memories)
# [{'memory': '用户是素食主义者,不吃肉', 'score': 0.95}]
LongMemEval 基准:49.0%(时序推理场景有局限)
适合谁:个性化推荐 Agent、客服 Agent、需要快速落地的团队。
缺点:图记忆需要 $249/月 Pro 订阅;无时序建模能力。
框架二:Zep / Graphiti — 时序推理最强
⭐ 5K stars|GitHub:https://github.com/getzep/graphiti|官网:getzep.com
一句话定位:把每条记忆都打上时间戳有效期,能推理"这个事实什么时候变了"。
架构特点:时序知识图谱
Zep 背后的核心引擎是 Graphiti,把每个事实存为知识图谱节点,并附带有效时间窗口:
"Kendra 喜欢 Adidas 球鞋"(有效期:2025-01 至 2026-03)
→ 被新事实覆盖 →
"Kendra 喜欢 Nike 球鞋"(有效期:2026-03 至今)
旧事实不删除,只是失效——历史记录完整保留,Agent 可以追溯"她什么时候改变偏好的"。
LongMemEval 基准:63.8%——比 Mem0 高 15 个百分点,时序任务碾压级优势。
检索延迟 P95 约 300ms,查询时不需要额外 LLM 调用(混合语义 + BM25 + 图遍历)。
适合谁:金融风控 Agent、医疗 Agent、CRM 类需要追踪事实变化的场景。
缺点:部署复杂度高于 Mem0;社区规模较小。
框架三:Letta / MemGPT — OS 级记忆管理
⭐ 3.6万 stars|GitHub:https://github.com/letta-ai/letta|前身:MemGPT
一句话定位:把操作系统的分层内存管理思路搬到 Agent 上。
架构特点:分层内存(OS-Inspired Tiered Memory)
Letta 把记忆分成三层,模仿操作系统的内存层级:
| 层级 | 类比 | 内容 | 特点 |
|---|---|---|---|
| Core Memory | 内存 RAM | 当前对话核心信息 | 始终在 context 窗口内 |
| Recall Memory | 缓存 Cache | 近期对话历史 | 按需检索 |
| Archival Memory | 硬盘 HDD | 长期知识存储 | 无限扩展 |
Agent 可以主动调用工具来读写记忆:
core_memory_replace()— 修改核心记忆archival_memory_search()— 搜索归档知识archival_memory_insert()— 写入长期记忆
这是跟其他框架最大的不同——Agent 自己知道自己在管理记忆,而不是框架在后台默默做。
原生支持多 Agent 协作:多个 Agent 可以共享同一个记忆池。
适合谁:需要长期自我进化的 Agent、研究型 Agent、需要多 Agent 协作的复杂系统。
缺点:上手成本高;需要部署 Letta Server。
框架四:A-MEM — NeurIPS 2025 论文级别的算法创新
GitHub:https://github.com/agiresearch/A-mem|论文:arXiv 2502.12110
一句话定位:用"卡片笔记法(Zettelkasten)"组织 AI 记忆,让记忆之间自动建立关联网络。
架构特点:动态笔记网络(Zettelkasten-Inspired)
A-MEM 的灵感来自德国社会学家卢曼的卡片笔记法——每条记忆都是一张"知识卡片",卡片之间自动建立关联链接。
当 Agent 获得新记忆时,A-MEM 做三件事:
-
1. 构建笔记:提取关键概念、上下文、标签
-
2. 动态链接:分析与已有记忆的关联,自动建立索引链接
-
3. 进化更新:已有记忆根据新信息动态更新,不是简单追加
from amem import AgenticMemorySystem
memory = AgenticMemorySystem()
# 存记忆(自动构建关联网络)
memory.add("用户喜欢科幻小说,最近在读三体")
# 搜索(返回关联记忆网络,不只是单条结果)
results = memory.search("用户阅读偏好")
被引用 412 次(arXiv),2025 年记忆领域引用量最高的论文之一。
适合谁:知识密集型 Agent、学术研究助手、需要复杂推理关联的场景。
缺点:工程化程度不如 Mem0/Letta;生产案例较少。
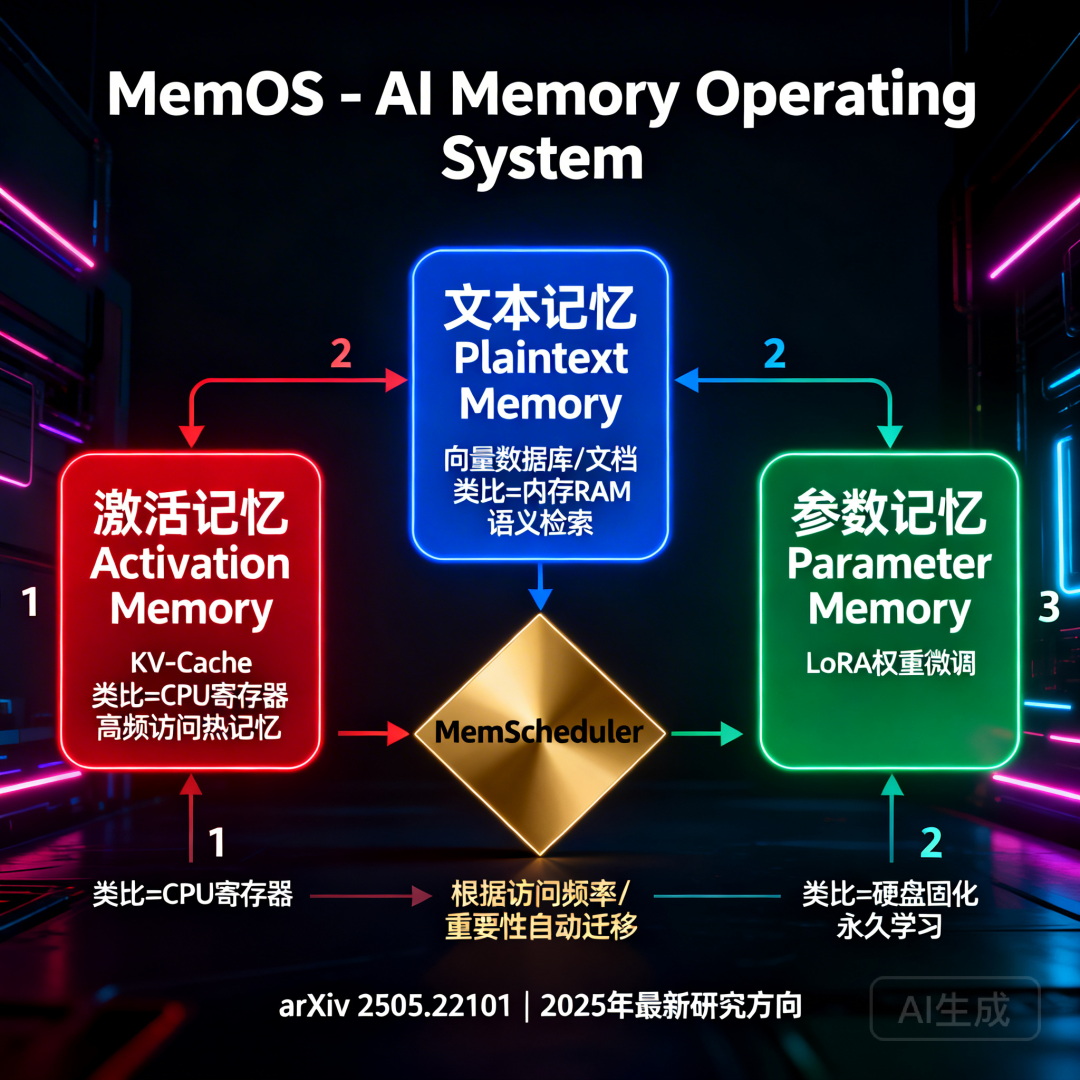
框架五:MemOS — 最有野心的系统级方案
GitHub:https://github.com/MemTensor/MemOS|论文:arXiv 2505.22101
一句话定位:不只是记忆框架,而是把"记忆"当成操作系统资源来统一调度。
架构特点:三态记忆统一调度(MemCube)
MemOS 是 2025 年最新提出的概念,核心论文于 2025 年 5 月发表。它把 LLM 的记忆分成三种形态,统一纳入一个调度系统:
| 记忆类型 | 实现形式 | 类比 |
|---|---|---|
| 激活记忆(Activation Memory) | KV-Cache | CPU 寄存器 |
| 文本记忆(Plaintext Memory) | 向量数据库 / 文档 | 内存 RAM |
| 参数记忆(Parameter Memory) | LoRA 权重微调 | 硬盘固化知识 |
三态可以互相转化:
- 高频访问的文本记忆 → 自动转为 KV-Cache(激活记忆)加速访问
- 持续活跃的激活记忆 → 可调度为参数记忆永久固化
调度器(MemScheduler) 根据访问频率、重要性、时效性自动管理三态之间的迁移。
适合谁:做底层 LLM 系统的团队、研究记忆机制的学者、有定制化需求的大型 Agent 平台。
缺点:工程成熟度最低,仍处于研究阶段。
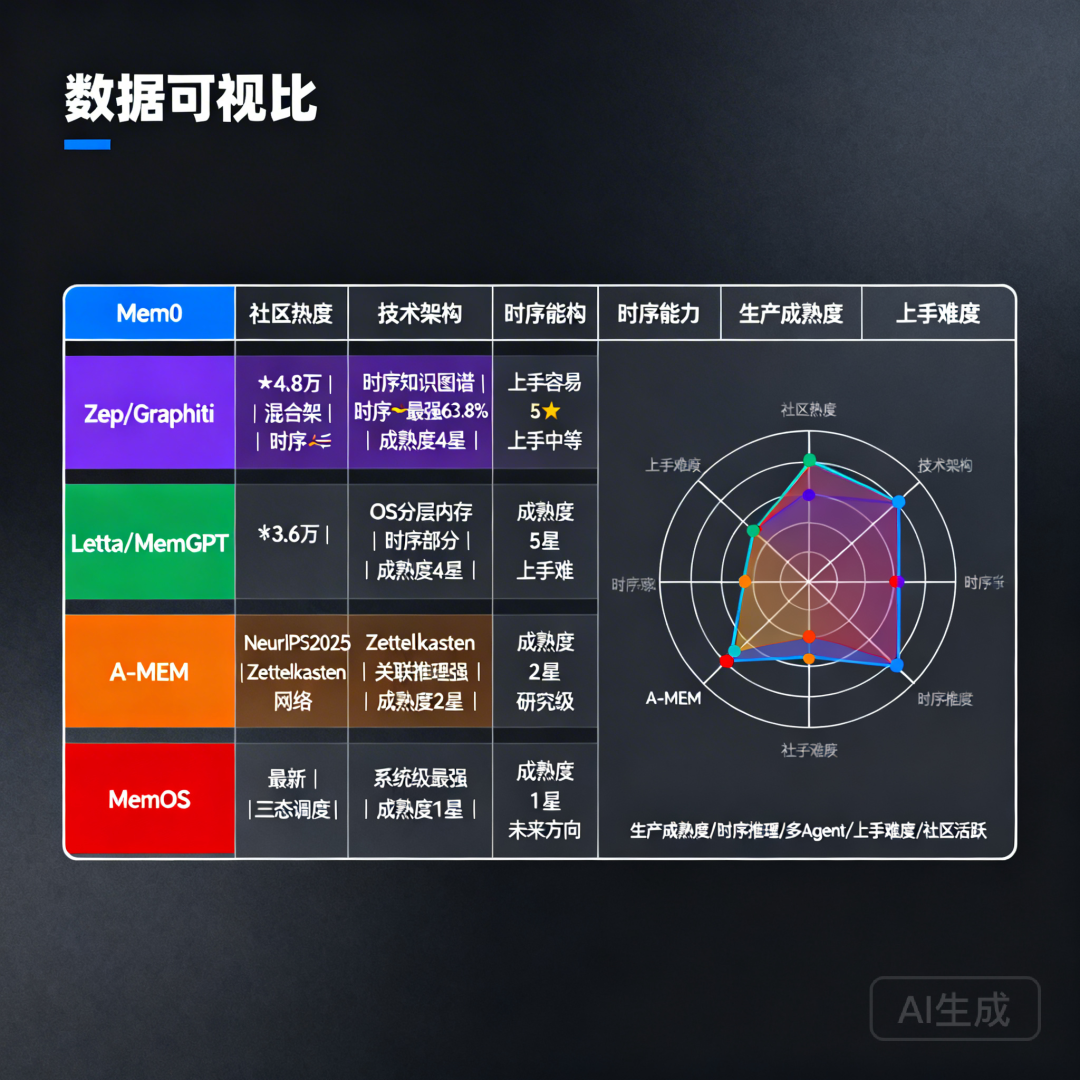
横向对比:一张表选型
| 框架 | GitHub Stars | 架构类型 | 时序推理 | 多Agent | 生产成熟度 | 上手难度 |
|---|---|---|---|---|---|---|
| Mem0 | 4.8万⭐ | 混合(向量+图+KV) | ❌ | 部分 | ⭐⭐⭐⭐⭐ | 低 |
| Zep/Graphiti | 5千⭐ | 时序知识图谱 | ✅ 最强 | 部分 | ⭐⭐⭐⭐ | 中 |
| Letta/MemGPT | 3.6万⭐ | OS 分层内存 | 部分 | ✅ 原生 | ⭐⭐⭐⭐ | 高 |
| A-MEM | 研究级 | Zettelkasten 网络 | 部分 | ❌ | ⭐⭐ | 中 |
| MemOS | 新兴 | 三态统一调度 | 部分 | 部分 | ⭐ | 极高 |
架构选型:怎么选?
根据你的场景快速匹配:
场景 1:快速上线,个性化推荐 / 客服 Agent → 选 Mem0。API 接入 3 行代码,有托管云,社区最大,文档最全。
场景 2:金融、医疗、法律——需要追踪事实如何随时间变化 → 选 Zep / Graphiti。时序知识图谱是这个场景的唯一正解,63.8% LongMemEval 不是白来的。
场景 3:长期运行、自我进化、多 Agent 协作的复杂系统 → 选 Letta。OS 级记忆调度 + 原生多 Agent 协作,适合有工程能力的团队。
场景 4:研究型 Agent、知识关联推理 → 选 A-MEM。NeurIPS 2025 论文级算法,关联推理能力最强,适合学术 / 实验场景。
场景 5:做 LLM 底层系统,有定制化需求 → 关注 MemOS。三态记忆调度是未来方向,现在跟进研究,未来在生产落地有先发优势。
落地架构参考
一个典型的 Agent 记忆系统落地架构:
用户输入
↓
[记忆检索层] ← Mem0 / Zep(语义检索 + 时序推理)
↓
[上下文构建] ← 将相关记忆注入 Prompt
↓
[LLM 推理] ← Claude / GPT-4o / Qwen
↓
[记忆写入层] ← 自动提取关键信息存入记忆
↓
[记忆存储] ← Vector DB(Qdrant/Chroma)+ Graph DB(Neo4j)
推荐组合:
- 快速场景:Mem0 托管云 + OpenAI API → 一周上线
- 高精度场景:Zep + 自建 Neo4j → 两周上线
- 长期进化场景:Letta Server + PostgreSQL → 一个月上线
最后说一句
Agent 记忆不是"有就行"的问题。
错误的记忆比没有记忆更危险——
医疗 Agent 记错了药物禁忌,金融 Agent 记错了用户风险偏好,客服 Agent 记错了用户投诉状态……
选对架构,从一开始就设计好记忆的边界和机制。
这 5 款框架,各有各的战场:
- Mem0 是现在最快的路
- Zep 是时序场景的最优解
- Letta 是长期复杂系统的基石
- A-MEM 是算法创新的前沿
- MemOS 是未来系统级方向的赌注
你需要哪种记忆,你就选哪种框架。
加油,太阳鸟。
参考资料:
- Mem0:https://github.com/mem0ai/mem0
- Zep/Graphiti:https://github.com/getzep/graphiti
- Letta:https://github.com/letta-ai/letta
- A-MEM:https://github.com/agiresearch/A-mem
- MemOS:https://github.com/MemTensor/MemOS
- 框架横评数据来源:https://atlan.com/know/best-ai-agent-memory-frameworks-2026/
- LongMemEval 基准:arXiv 2501.13956

这里给大家精心整理了一份全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!
👇👇扫码免费领取全部内容👇👇
1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。
2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 2026行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

7. 资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 10
10 0
0- 0



 已为社区贡献91条内容
已为社区贡献91条内容

所有评论(0)