《Geometric Deep Learning for Computer-Aided Design: A Survey论文精读》
目录
前言
这篇论文发表于 2025年,作者来自 丹麦奥胡斯大学(Aarhus University) 的电气与计算机工程系。论文发表在 IEEE Access 期刊上。
几何深度学习技术已成为计算机辅助设计(CAD)领域的一股变革力量,并有可能彻底改变设计师和工程师处理及优化设计流程的方式。通过利用基于机器学习的方法,CAD 设计师可以优化工作流程,节省时间和精力,做出更明智的决策,并创造出既创新又实用的设计。处理以几何数据表示的 CAD 设计并分析其编码特征的能力,使我们能够识别不同 CAD 模型之间的相似性,提出替代设计和改进方案,甚至生成全新的设计替代方案。本综述全面概述了计算机辅助设计中基于学习的方法,涵盖多个类别,包括相似性分析与检索、2D 和 3D CAD 模型合成,以及从点云、单视图/多视图图像生成 CAD 模型。此外,本文还提供了基准数据集及其特征的完整列表,以及推动该领域研究的开源代码。最后的讨论部分深入探讨了该领域当前面临的挑战,并提出了这一快速发展领域潜在的未来研究方向。
I. 引言
深度学习已经彻底变革了跨领域的数据处理方式,从欧几里得空间中的网格结构数据(如图像、视频、文本)到具有复杂关系的图结构数据。几何深度学习(Geometric Deep Learning, GDL)涵盖了广泛的神经网络架构,包括卷积神经网络(CNN)、图神经网络(GNN)、循环神经网络(RNN)以及Transformer网络,所有这些架构都将对数据的几何理解(例如对称性和不变性)作为归纳偏置编码到其学习过程中[1]。在过去的十年中,包括CNN、GNN、RNN和Transformer网络在内的GDL方法,在来自不同应用的多样化任务中取得了显著进展,这些应用包括计算机视觉、自然语言处理、计算机图形学和生物信息学。然而,将GDL方法应用于复杂的参数化计算机辅助设计(CAD)数据的研究却很少。边界表示(Boundary Representation, B-Rep)是CAD模型的一种基本数据格式,它编码了CAD模型中高水平的参数化细节,可用于学习这类模型的复杂几何特征。
尽管GDL方法在分析网格[2,3]、体素[4–6]和点云[7,8]数据格式的3D形状方面取得了相当大的成功,但直接从B-Rep数据中提取特征表示仍然面临挑战。将B-Rep数据转换为传统格式(如三角形网格)不仅计算成本高昂,而且会导致信息丢失[9]。因此,直接从B-Rep数据中学习特征表示变得势在必行,这样可以高效地捕捉CAD模型中最具代表性的几何特征用于后续分析,而无需承担大量计算和内存使用的负担。
最近,利用GDL方法学习CAD模型结构并促进不同方面的设计过程引起了巨大的研究兴趣。虽然传统的机器学习和深度学习方法已经被探索用于CAD分类和聚类任务[10–12],但这些方法主要侧重于基于物理特征(如体积、边界框、面积、密度、质量、主轴)学习特征表示,或者直接处理其他3D数据格式(如点云)而不考虑B-Rep。因此,它们往往难以捕捉CAD模型中所蕴含的简洁几何属性。
随着GDL方法的不断发展,它们有望在塑造未来各行业的CAD设计中发挥关键作用。近年来,更先进的GDL方法,如GNN和(图)Transformer网络,在学习CAD模型中嵌入的复杂几何特征方面显示出巨大潜力,特别是从B-Rep数据中学习,而不管其物理特征如何[9,10,13–16]。这些学习到的特征表示服务于多种目的,例如重建CAD模型[15–17]、确定CAD实体之间的接合[18,19]以及自动完成未完成的CAD模型[20–23]。这些基于学习方法的首要目标是提升CAD设计过程的自动化水平。通过减轻专家执行重复性和耗时任务(如草图和绘图)的负担,这些方法有可能使设计师专注于设计过程中更具创造性的方面。通过分析历史设计数据、提取几何特征并识别有价值的见解(如CAD模型之间的相似性),这些方法可以促进在新产品中复用CAD模型。这不仅通过避免重复设计来节省时间和资源,而且还通过基于特定参数和目标生成设计替代方案来帮助设计师进行定制化。
此外,对能够逆向工程模型并根据初步概念草图得出的简洁参数生成多样化设计选项的CAD工具的需求日益增长。基于GDL的方法在满足这一需求方面已经取得了一些进展[22,24]。然而,在该领域引入基于机器学习的方法并非没有挑战。一个主要的挑战是缺乏带有标注的B-Rep格式CAD数据集。与图像、视频或文本等其他数据格式不同,收集CAD模型是复杂且耗时的,通常需要熟练工程师的专业知识。此外,这些数据集通常仍然是专有的,公众无法访问。另一方面,标注CAD数据集,尤其是对于机械物体,需要大量的领域知识。鉴于在没有大规模标注数据集的情况下训练深度学习方法是不可行的,近期的研究工作也通过提供基准CAD数据集做出了宝贵贡献。
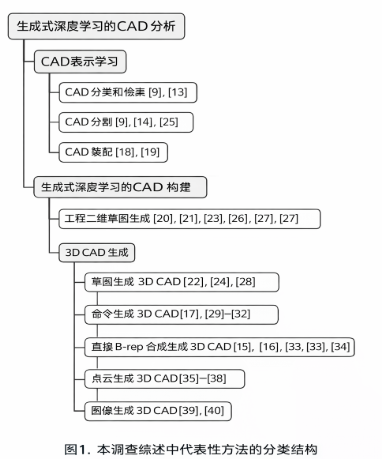
由于这个领域仍处于新兴阶段,未来有大量的研究和发展空间,有几个挑战需要被探索和解决。据我们所知,我们的综述是这个快速发展的领域中第一个全面的综述,它致力于提供对该领域近期进展、挑战和贡献的深入探索。图1展示了综述的结构,并重点介绍了该领域中被更详细回顾的最具代表性的方法。在进行这项综述时,我们的目标是成为研究人员和实践者导航GDL与CAD动态交叉领域的指导性资源。本综述旨在提供:
- 对用于CAD数据分析的最先进GDL方法的全面回顾。这涵盖了不同类别,包括相似性分析、分类和检索,以及分割,还有2D和3D CAD模型的合成。此外,综述还探讨了从替代数据表示(例如点云)生成CAD模型的技术。
- 对推动该领域研究至关重要的基准CAD数据集的详细概述,以及附带的开源代码,这些代码在推动可达到结果的边界方面发挥了重要作用。
- 通过评估现有方法的局限性,深入讨论该领域持续存在的挑战,以及潜在的未来研究方向。
II. 背景
A. 计算机辅助设计 (CAD)
计算机辅助设计(CAD)是一种制造技术,它彻底改变了工程师、建筑师、设计师和其他专业人员创建和可视化设计的方式[41]。CAD过程涉及使用 specialized 软件,在构建物理对象或系统之前,以数字方式设计、修改、分析和优化2D图纸和3D模型。工程制图需要使用点、线、曲线、平面和形状等图形符号,它本质上以图形形式提供了关于任何组件的详细描述。有多种CAD软件选项在工业中广泛用于不同目的。
1) CAD工具与Python API
列举一些最受欢迎的软件选项:AutoCAD [42] 和 Fusion 360 [43](一款基于云的软件)为各种行业提供2D/3D设计工具。SolidWorks [44] 和 CATIA [45] 为机械、航空航天和汽车行业提供参数化建模和仿真。Onshape [46](基于云的软件)和 Creo [47] 提供3D参数化设计和仿真。TinkerCAD [48] 是一款免费、基于网页的CAD设计工具,主要用于初学者和教育目的。
对于CAD解析和开发,有几个Python API可用,它们提供工具和库来处理CAD数据、创建3D模型、可视化CAD模型以及执行各种相关操作。列举一些最流行的CAD Python API:PythonOCC [49] 提供了一个开源的3D建模和CAD Python库。它基于 OpenCASCADE 技术(OCCT)[50],这是一个用于CAD的强大几何内核和建模框架。PythonOCC 提供了对 OpenCASCADE C++ 库的 Python 绑定,允许开发者使用 Python 创建、操作、可视化和分析3D几何与CAD模型。OCCWL [51] 最近作为一个简单、轻量级的 Pythonic 包装器围绕 PythonOCC 发布。CADQuery [52] 是一个用于脚本化3D CAD模型的 Python 库,同样构建在 OpenCASCADE 几何内核之上。
另一个强大的3D几何建模内核是 Parasolid [53],它提供了一组用于创建、操作、可视化和分析3D实体模型的函数和方法。然而,与 OpenCASCADE 不同,Parasolid 不是开源的,软件开发人员需要获得许可才能将其功能集成到CAD应用程序中。
2) CAD设计中的术语
边界表示(B-Rep)是一种基本的建模技术,用于CAD中表示复杂的3D模型及其几何属性。它通过在3D空间中表征曲面、曲线、点以及它们之间的拓扑关系,促进了对3D实体的准确且一致的设计、修改、操作、分析和表示。在表1中,我们介绍了CAD设计的基本术语,这对于理解该领域的概念和方法至关重要。然而,根据行业和用于设计的软件应用程序的不同,可能存在此处未涵盖的更专业的术语和概念。为了保持本文的一致性,我们将对所有后续讨论的方法和数据集使用此术语。
表1: CAD设计中的术语。总结了不同研究工作和CAD平台上广泛使用的术语。
| 术语 | 描述 |
|---|---|
| 模型 | 在CAD软件中创建的真实世界物体或系统的2D或3D表示。 |
| B-Rep | 边界表示,一种通过表示物体的拓扑组件(如曲面、边、顶点及其之间的关系)来几何描述物体的数据格式。 |
| 草图 | 物体的2D图形,作为创建3D模型的基础,由线、曲线和其他基本几何形状构成。 |
| 拉伸 | 一种CAD操作,将2D图形沿特定维度扩展以创建3D模型。 |
| 基元 | 用作更复杂设计基础的基本2D/3D几何形状。对于2D草图,基元是点、线、弧、圆、椭圆和多边形。对于3D形状,基元是立方体、球体、圆柱体、圆锥体。 |
| 约束 | 2D/3D设计中基元之间的几何关系,例如重合、相切、垂直。 |
| 点 | 表示空间中具有3D坐标 X, Y, Z 的特定位置的基本几何实体。 |
| 线 | 3D空间中两点之间的直线路径。 |
| 圆 | 由其圆心和半径定义的闭合曲线。 |
| 弧 | 作为圆或椭圆的一部分的曲线,由圆心、起点和终点定义。 |
| 环 | 形成曲面边界的闭合曲线序列。 |
| 轮廓 | 由一组连接在一起的曲线构成的闭合环。 |
| 面 | 由轮廓围成的2D曲面。 |
| 边 | 由两点界定的曲线片段,定义了面的边界。 |
| 壳 | 一组具有共享边界和点的连接面。 |
| 体/零件 | 通过拉伸面创建的3D形状。 |
| 实体 | 用作设计物体构件的3D形状。 |
| 组件 | 包含一个或多个体(零件)的装配体的构件。 |
| 装配体 | 一组连接在一起以创建更大物体的体(或零件)。 |
| 接合 | 体(零件)之间由坐标和轴定义的连接,以形成装配体。 |
| 拓扑 | 3D模型中点、曲线、面和其他几何组件的结构。 |
| 线框 | 3D B-Rep模型的可视化表示,仅用线和曲线显示物体的结构。也称为3D物体的骨架表示。 |
| 渲染 | 可视化CAD模型以模拟其真实世界外观的过程。 |
| 曲面法向 | 在特定点垂直于曲面的单位向量。 |
表2: 不同文件格式及其相应描述的总结。每个CAD数据集至少提供其中一种数据格式,以便用于不同目的的处理。
| 类型 | 描述 | 格式 |
|---|---|---|
| STEP | 原始参数化B-Rep格式,包含CAD模型拓扑和几何信息的显式描述。 | .txt, .step, .smt |
| STL | 标准曲面细分语言,一种用三角形面片(网格)描述物体3D曲面的格式。 | .stl |
| Obj | 使用三角形网格描述3D曲面几何的格式。 | .obj |
| 统计信息 | CAD模型的统计信息。 | .yml, .txt |
| 特征 | 曲面和曲线属性的描述,以及对离散三角形网格表示的相应顶点和面的引用。 | .yml |
| 图像 | 通过渲染过程产生的物体可视化。 | .png |
| PCD | 点云数据,表示3D模型结构的3D空间点集合。 | .ASC, .PTX, .OBJ |
B. 几何深度学习 (GDL)
几何深度学习(GDL)已成为人工智能(AI)一个特殊且基础的分支,它将深度学习方法从常规的欧几里得数据扩展到复杂的几何结构化数据[1]。传统的深度学习方法通过处理由规则1D、2D和3D网格形成的常规欧几里得数据结构(如音频、文本、图像和视频),在不同应用中取得了巨大进步。而GDL则专门用于处理和提取不规则结构化数据(如3D形状、网格、点云和图)中复杂的空间和拓扑特征。GDL处理的这些不规则数据结构可以是欧几里得的也可以是非欧几里得的,具体取决于它们所拥有的几何属性的上下文。GDL因其学习复杂几何特征和促进工程师与设计师设计过程的能力,在CAD领域获得了显著的研究关注。
用于CAD的几何深度学习领域经历了不同的发展阶段,每个阶段都针对前一代模型在处理CAD数据的结构化、参数化和语义丰富特性方面的局限性进行了改进。
早期方法如MeshCNN [54] 在三角形网格上操作,使用基于边的卷积来捕捉局部表面结构。虽然这对于具有良好形成的流形网格的有机形状有效,但这些方法难以处理工业CAD导出中典型的拓扑复杂性和退化情况,例如T-顶点、非流形边和不一致的三角剖分。
为了提高鲁棒性,引入了基于点云的模型,如PointNet [8] 和 DGCNN [55],它们将3D形状视为无序的点集,并在不依赖网格连接性的情况下学习全局或局部几何特征。这些方法对拓扑不一致性和网格噪声具有更强的鲁棒性。然而,它们有一个关键缺陷:丢弃了CAD模型显式的拓扑和参数化结构,包括解析曲面类型(如平面、圆柱体)、设计特征和约束关系。因此,虽然对分类或分割等任务有用,但它们在需要理解或操作设计意图的应用中表现不足。
为了弥合这一差距,出现了一类新的基于图的模型,它们利用CAD数据固有的原生边界表示(B-Rep)拓扑。这些图神经网络(GNN)在由B-Rep实体(面、边和顶点)构建的结构化图上运行,能够显式编码参数化曲面、拓扑约束以及几何特征之间的层次关系。诸如UV-Net [9]、DeepCAD [17] 和 BRepNet [14] 等模型体现了这一方向,对CAD工作流具有更好的适应性,并支持结构化几何上的特征识别、约束提取和语义分割等任务。
在此基础之上,最近的基于Transformer的模型,如SketchGen [26]、CAD as Language [27]、PolyGen [56] 以及本文图1所示的其它近期生成方法,代表了当前的最先进水平。这些模型直接在标记化的B-Rep元素或设计操作序列上操作,捕捉长距离依赖关系,并支持跨丰富语义和几何上下文的学习。它们不仅能够编码精确的几何形状,还能学习设计历史、可制造性约束,并支持可编辑性和逆向工程,与CAD软件编码和操作几何的方式紧密对齐。
这种从基于网格和点云的方法到基于图和Transformer的架构的技术演进,展示了朝向CAD原生学习的清晰轨迹,与设计数据的结构性、语义性和工程特定属性日益对齐。
C. 图神经网络 (GNN)
图神经网络(GNN)[57, 58] 是最流行的GDL方法类型之一,擅长处理图结构数据。GNN在来自不同应用的各种任务中取得了显著进展,例如计算机视觉[59-61]、生物化学模式识别[62, 63]和金融数据分析[64]。GNN提供了一种专门的方法来建模编码在B-Rep中的复杂CAD几何结构,将其视为一个通过节点和边表示3D形状拓扑和几何的图。GNN模型能够有效捕捉图(B-Rep)中固有的拓扑结构、连接性和属性,并通过考虑局部和全局上下文实现层次化分析,这与B-Rep模型的复杂结构相契合。GNN还能够通过图提取和传播几何特征,捕捉形状和曲率的细微方面,并利用现有B-Rep模型的数据驱动见解,促进实体和/或草图分割[9, 14, 65]、形状重建与生成[16, 20]、形状分析与检索[9, 13]等任务。通过将B-Rep表示为图并利用GNN能力捕捉其拓扑结构、连接性和几何信息,设计师和工程师可以以更高的精度和效率分析、优化和创建复杂的3D模型。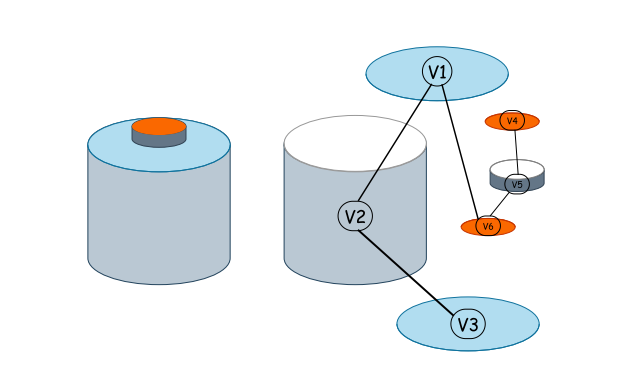
让我们更详细地解释B-Rep模型如何表示为图。在B-Rep的上下文中,图节点可以表示点、线和面,并带有相关属性,如几何坐标、线长、曲率、面积和曲面法向。图中的边表示节点之间的连接。对于B-Rep,这些连接指示基元(如点、线、面等)之间的约束,如邻接、相切或重合。GNN方法嵌入每个节点的特征,创建捕捉几何属性的节点表示,这些属性聚合来自邻居节点的信息。在B-Rep上下文中,这模拟了几何属性通过相邻点、线、曲线和面流动的方式。通过特征聚合,该方法通过将节点自身的特征与其邻居的信息相结合来更新每个节点的表示。这一步捕捉了邻近几何的影响。GNN中的核心操作是图卷积,它与应用于来自邻居节点的融合信息的非线性函数相结合。在多层GNN中,图卷积操作捕捉多跳邻居特征,允许层次化分析。对于B-Rep,此操作有助于捕捉基元之间的层次关系。为了获得B-Rep模型的全局表示,GNN可以采用全局池化,将整个图信息汇总为单个特征向量。图2和图3分别展示了一个3D形状和一个2D草图表示为图的示例。
最流行的GNN架构,即图卷积网络(GCN)[66-68]和图自编码器(GAE)[69],分别用于图上的(半)监督学习和无监督学习,执行不同的图分析任务,如节点/图分类和图重建/生成。随着基于GNN的方法不断发展,它们有望在塑造未来各行业的CAD设计中发挥关键作用。在接下来的章节中,我们将深入探讨该领域当前最先进方法的细节以及面临的挑战。
III. 数据集
大规模数据收集在提升深度学习模型应用于不同领域问题时的性能方面发挥着关键作用。收集此类常规格式(如图像、视频、音频、文本)的大规模数据集,并通过社交媒体等不同平台分发,极大地加速了深度学习和计算机视觉以及自然语言处理的进展。几何深度学习(GDL)在3D形状分析、形状重建和构建几何特征描述符等任务中具有优势。尽管如此,创建和标注高质量的3D几何数据需要高水平的领域知识以及工程和设计技能。由于各种因素,如对专有权和所有权的担忧,以及可用数据源之间缺乏一致性和兼容性,收集此类数据集也具有挑战性。
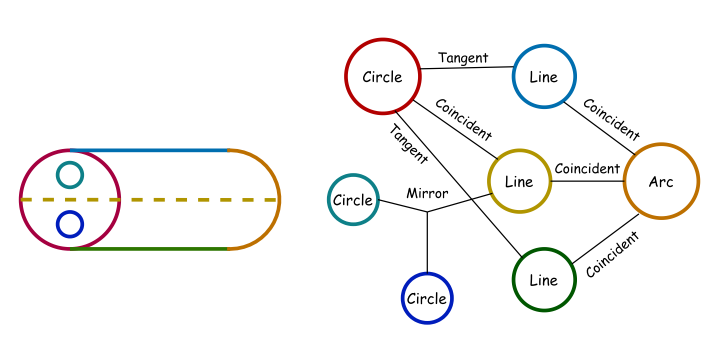
表3提供了现有数据集及其属性的摘要。关于每个数据集的详细信息,请参见与方法论相关的专用章节。表2介绍了不同的CAD数据格式及其相应描述。现有的常用3D CAD数据集主要提供用于3D形状分割、分类和检索的网格几何数据[5,70-73],人体网格配准[74],2D/3D形状对齐[75],以及3D场景分类、语义分割和物体检测[76,77]。工程形状数据集,如ESB [78]、MCB [79]、AAD [80]、FeatureNet [81]和CADNet [82],也提供了带有网格几何的标注数据,用于机械形状分类和分割。这些数据集的主要局限性在于缺乏通常称为边界表示(B-Rep)的曲线和曲面的参数化及拓扑特征。这些B-Rep特征对于进行参数化CAD形状分析至关重要。最近,为了推动GDL在CAD设计上的进展,引入了几个不同规模和属性的几何B-Rep数据集。FabWave [83] 是一个包含5,373个3D形状的集合,标注了52个机械零件类别(如齿轮和支架);Traceparts [84] 是一个小型集合,包含由不同公司生产的600个CAD模型,分为6个类别(每类100个CAD模型),包括螺钉、螺母和铰链,可用于3D形状分类。MFCAD [85] 是一个合成3D分割数据集,包含15,488个形状,标注了16个类别的面,可用于CAD形状中的参数化面分割。
为了在GDL的各项任务中取得进展并有效训练深度学习模型,需要大规模的参数化CAD数据收集。现有的带有B-Rep数据的参数化CAD数据集规模有限,不足以满足这些需求。为了解决这一不足,最近引入了三个大型数据集:ABC [86]、Fusion 360 Gallery [30] 和 SketchGraphs [20],它们为该领域的研究提供了宝贵的资源。ABC [86] 是第一个大规模、真实世界、手工设计的数据集,包含超过100万个高质量的3D CAD模型,涵盖了广泛的物体类型。每个CAD模型由一组精确参数化的曲线和曲面组成,为尖锐几何特征表示、面片分割、解析微分测量以及形状重建过程提供了准确的参考点。ABC数据集中的CAD模型是通过Onshape [46] 托管的可公开访问接口编译和收集的,并且开发了一个开源几何处理管道,用于处理和准备ABC数据集中的CAD模型,以供深度学习方法使用。
训练机器学习模型以促进CAD构建和合成,可以通过减少设计过程所需的时间和精力,极大地惠及设计师。与CAD(重)构建相关的任务的一个基本需求是理解CAD模型是如何设计的,以及如何解释数据集中提供的构建信息。ABC数据集中的构建历史信息只能通过查询Onshape API以专有格式检索,且文档有限,这使得在该数据集上开发CAD(重)构建方法具有挑战性。SketchGraphs数据集旨在填补这一空白,它提供了来自Onshape API的1500万个真实世界CAD模型的人体设计2D草图的集合。2D草图表示几何基元(如线和弧)以及它们之间的约束(如重合和相切),可以被视为3D形状参数化构建的基础。每个2D草图表示为一个几何约束图,其中节点表示2D基元,边表示基元之间的几何约束(图3)。SketchGraphs数据集可用于自动化设计过程中的各种应用,例如通过预测草图构建操作序列来自动完成草图绘制,或交互式地向设计师建议下一步骤,以及自动约束应用(其中方法预测草图几何基元之间的一组约束)。其他潜在应用包括从图像进行CAD推理(方法接收一张嘈杂的2D绘图图像并推断其设计步骤以生成相应的参数化CAD模型),以及学习草图中编码的语义表示。该数据集还附带了一个开源的Python数据处理和准备管道,用于深度学习框架。与SketchGraphs类似,手绘2D草图数据集如[87]、[88]和[89]也被引入,通过提供草图构建序列来解决这一挑战。
Fusion 360 Gallery [30] 是Autodesk最近引入的第一个真实世界人体设计3D CAD数据集和环境,其中包含用于程序化CAD构建的3D操作序列。Fusion 360 Gallery数据集附带了一个名为Fusion 360 Gym的开源Python环境,用于处理和准备用于机器学习方法的CAD操作。该数据集包含由Autodesk Fusion 360 CAD软件用户生成并收集到Autodesk在线画廊中的2D和3D几何CAD数据。基于Fusion 360 Gallery中的总计20,000个真实世界设计,创建了用于不同学习目标的几个数据集,例如CAD重建[30]、CAD分割[14]和CAD装配[18]。
IV. CAD 表示学习
研究广泛的数据存储库并揭示数据中隐藏的特征,以用于相似性分析和形状检索等任务,一直是机器学习和人工智能领域一个活跃的研究方向。这一概念的重要性也延伸到了 CAD 数据。基于机器学习的 CAD 模型相似性分析,可以通过对设计进行分类、检索相似的 CAD 模型作为设计替代方案,有效促进设计师的设计过程。研究表明,大约 40% 的新 CAD 设计可以基于 CAD 存储库中的现有设计构建,并且至少 75% 的设计过程会利用现有知识来设计新的 CAD 模型 [91]。从 CAD 数据中学习并从大量的几何 CAD 形状集合中提取特征,对于 CAD 检索和相似性分析至关重要,这涉及到使用各种机器学习和深度学习方法,从 B-Rep 数据中提取编码的几何属性,以评估 CAD 模型对之间的相似性。
此过程的第一步是根据特定的分析目标,选择 CAD 模型的几何、拓扑、功能和其他属性的子集,并以适合深度学习模型处理的格式(例如数值向量、矩阵、张量或图)进行表示。然而,表示 B-Rep 数据具有挑战性,因为连续的、非欧几里得的几何特征与离散的拓扑属性共存,使得难以适应规则的结构化格式(如张量或固定长度编码)。在该主题的每个最先进方法的一个关键贡献是引入了一种方法,用于将 B-Rep 数据编码或标记化为适合所采用的深度学习架构的格式,并针对其解决的特定应用进行定制。深度学习方法接收这些表示作为输入,并学习根据手头的标注对 CAD 模型进行分类、聚类、分割或重建。然而,由于缺乏以 B-Rep 格式提供的带标注 CAD 数据,机器学习和深度学习方法在 CAD 模型上的应用非常罕见。与诸如 ShapeNet [71] 等几何 CAD 模型相比,许多参数化 CAD 数据集因设计数据的专有性质而未公开发布。
尽管最近发布了一些包含 B-Rep 格式机械零件的小型带标注数据集供机器学习研究使用 [84],但像 ABC 这样的大型公共数据库大多仍未标注。此外,以专门格式手动标注 B-Rep 数据不仅需要工程专业知识,而且非常耗时且成本高昂,因此构成了重大限制。因此,不依赖外部标注的深度学习方法(如无监督和自监督学习)与传统监督学习方法一起,在这种情况下变得尤为重要。基于数据内在特征、无需外部标注或专业知识学习特征表示,被证明在克服带标注 CAD 数据稀缺方面具有高度优势。在本节中,我们介绍现有利用 GDL 从 CAD B-Rep 中提取特征表示的研究工作。这些方法以监督、自监督或无监督的方式运行,服务于分类、分割、相似性分析及检索、装配预测等多种任务。
A. CAD 分类与检索
设计用于对 B-Rep 装配体中的 3D 组件进行分类的方法,对于各种应用(例如在不同装配体中重用相似的 CAD 组件、形状推荐和替代方案建议、产品复杂度估算)非常重要,尤其是当具有显著不同几何形状的 3D CAD 模型属于同一类别并共享相似拓扑时。最早提出的直接处理 3D CAD 模型 B-Rep 数据格式的深度学习方法之一是 UV-Net [9]。UV-Net 提出了一种统一的 B-Rep 数据图表示,通过邻接图对拓扑进行建模,并基于曲线和曲面的 U 和 V 参数域在规则网格格式中对几何进行建模。该工作的主要贡献之一是从 B-Rep 数据中提取关键的几何和拓扑特征,并将复杂的 B-Rep 数据转换为网格数据结构,以提供给深度学习模型执行不同任务,如 B-Rep 分类和检索。为了从 B-Rep 数据生成网格结构的特征表示,该方法通过以固定步长进行曲面采样,将每个 3D 曲面转换为规则的 2D 网格。以类似的方式,它将每个实体曲线转换为 1D 网格。
表 3:现有常见物体和机械 CAD 数据集的概述及其属性。针对每个数据集,报告了 CAD 模型的数量、表示格式(如 B-Rep、网格、草图)以及它们标注的不同任务(如分割、分类和 CAD 重建)。表格的前 4 行显示了为 3D 形状分类标注的常见物体数据集。其余行列出了为 CAD 分析创建的机械物体数据集。
| 数据集 | 类别 | 数量 | 格式 | 标注任务 |
|---|---|---|---|---|
| ShapeNet [71] | 常见物体 | 51,300 | 网格 | 分类、分割 |
| ModelNet [5] | 常见物体 | 127,915 | 网格、体素 | 分类 |
| Thingi10K [72] | 常见物体 | 10,000 | 网格 | - |
| PartNet [73] | 常见物体 | 26,671 | 网格 | 分割、装配 |
| ESB [78] | 机械 | 866 | 网格 | 分类 |
| MCB [79] | 机械 | 61,734 | 网格 | 分类 |
| AAD [80] | 机械 | 15,250 | 网格 | 分类 |
| FeatureNet [81] | 机械 | 16,506 | 网格 | 分割 |
| CADNet [82] | 机械 | 4,037 | 网格 | 分类 |
| FabWave [83] | 机械 | 5,373 | B-Rep, 网格 | 分类 |
| Traceparts [84] | 机械 | 600 | STEP | 分类 |
| MFCAD [85] | 机械 | 15,488 | B-Rep, 网格 | 分割(加工特征) |
| MFCAD++ [90] | 机械 | 59,655 | B-Rep, 网格 | 分割(加工特征) |
| ABC [86] | 机械 | >1,000,000 | B-Rep | 无(自监督) |
| SketchGraphs [20] | 机械草图 | 15,000,000 | 约束图 | 草图生成 |
| Fusion 360 Gallery [30] | 机械 | 20,000 | B-Rep, 序列 | 重建、分割、装配 |
| Fusion 360 Segmentation [14] | 机械 | 35,680 | B-Rep | 分割(构建操作) |
| AutoMate [19] | 机械装配 | 92,529 装配体 | B-Rep | 装配配对 |
| Fusion 360 Assembly-Joint [18] | 机械装配 | 8,251 装配体 | B-Rep | 装配接合 |
| DeepCAD [17] | 机械 | 178,238 | 命令序列 | 重建 |
| CC3D-Ops [25] | 机械 | 37,000 | B-Rep | 分割(操作步骤) |
| SolidGen PVar [15] | 机械 | 120,000 | B-Rep | 类条件生成 |
| CADParser [16] | 机械 | 40,000 | B-Rep + 命令 | 重建(5种操作) |
由此产生的 1D/2D 网格映射被称为 UV-grids。曲面 2D 网格中的每个采样点在 7 个通道上传递三个不同的值:a) 3D 绝对点位置,在 UV 坐标系中表示为 xyz;b) 3D 绝对曲面法向;c) 修剪掩码,其中 1 和 0 分别表示可见区域和修剪区域内的样本。对于曲线 1D 网格中的采样点,编码包括绝对点 UV 坐标以及可选的单位切向量。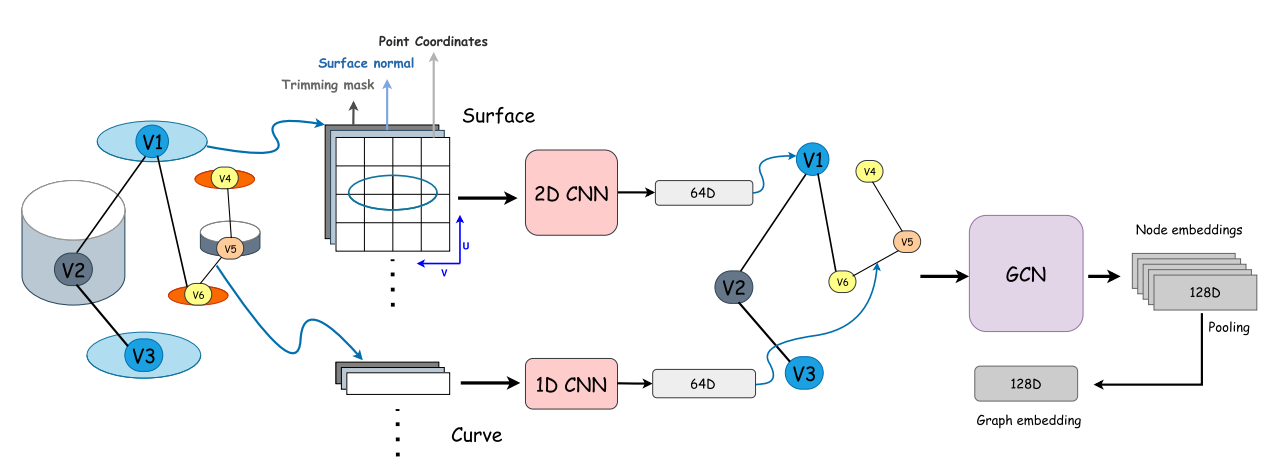
如图 4 所示,UV-Net 模型架构包含 CNN 和 GCN 层,首先从表示曲线和曲面的 1D 和 2D 网格中提取特征,然后通过分层图卷积层捕捉编码为图的 3D 形状的拓扑结构。1D 曲线和 2D 曲面 UV-grids 由 1D 和 2D 卷积及池化层处理,同时卷积层的权重在 B-Rep 中的所有曲线和曲面之间共享,以实现置换不变性。由 CNN 卷积层从曲面和曲线导出的 64 维特征向量,用作面邻接图 G(V, E) 中的节点和边特征,其中节点集 V 表示 B-Rep 中的面(曲面),边集 E 表示面之间的连接。随后,该图被引入到一个多层 GCN 中,其中图卷积层通过网络传播这些特征,从而捕捉形状中固有的局部和全局结构。UV-Net 编码器用作带标签和无标签数据集上的监督和自监督学习的主干网络。对于 CAD 分类(一项监督任务),UV-Net 编码器后接一个 2 层分类网络,将学习到的特征映射到类别,并在三个带标注数据集(SolidLetters [9]、FabWave [83] 和 FeatureNet [81])上以端到端方式训练模型。SolidLetters 是目前最大的合成 3D B-Rep 数据集,在几何和拓扑上都有很大的变化,并标注了分类任务。它包含 96,000 个 3D 形状,代表具有不同字体和尺寸的 26 个英文字母(a-z)。
对于 CAD 检索,前提是缺乏标签数据,因此 UV-Net 编码器需要以自监督方式进行训练。这导致使用为自监督训练设计的深度学习模型,如图对比学习(GCL)[92] 或图自编码器(GAE)[69]。为了将 UV-Net 编码器训练为自监督模型,利用 GCL 对面邻接图应用变换,为每个 B-Rep 样本生成正样本对。这些变换可以通过多种方式进行,例如以均匀概率随机删除节点或边,或者在图中提取随机节点及其 n 跳邻居。假设每个 B-Rep 及其变换版本是正样本对,UV-Net 编码器提取每个对的形状嵌入 {h_i, h_j},然后一个带有 ReLU 激活的 3 层非线性投影头将这些嵌入转换为潜在向量 z_i 和 z_j。对于一个包含 N 个 B-Rep 样本的批次,计算每个样本及其对应正样本对的潜在向量。然后以端到端方式训练整个模型,目标是将每个样本的嵌入与其正样本对拉近。同时,模型将剩余的 2(N-1) 个 B-Rep 视为负样本,试图将它们推离正样本对。通过这个过程,模型学会了捕捉数据内在的特征和模式,无需标签示例。它本质上利用了通过变换或增强生成的数据内部关系来学习有意义的表示。这使得对比学习成为一种自监督学习方法,在获取标签数据具有挑战性或不可行的情况下特别有用。为了检索相似的 CAD 模型,模型在像 ABC 这样的无标签数据集上训练。随后,使用测试集中的随机样本的嵌入作为查询,并在 UV-Net 形状嵌入空间中计算它们的 k 最近邻。
同样地,[13] 中提出的方法利用几何作为自监督,并将其扩展到少样本学习。具体而言,该方法训练一个编码器-解码器结构来栅格化局部 CAD 几何,以 CAD B-Rep 为输入,生成曲面栅格化为输出。B-Rep 通过显式定义的曲面和隐式定义的边界分段组装而成。因此,该方法的编码器采用了 [19] 中提出的 SBGCN 的分层消息传递架构,以有效捕捉用于编码 B-Rep 面的边界特征。解码器则通过同时解码显式曲面参数化和隐式曲面边界来重建面。通过该方法中自监督学习获得的嵌入,作为后续监督学习任务的输入特征,包括 FabWave 数据集上的 CAD 分类。值得注意的是,在仅有非常有限的标注数据(从几十到几百个示例)的情况下,该方法在利用更小训练集的同时,性能超过了先前的监督方法。这强调了可微分 CAD 栅格化器在学习复杂 3D 几何特征方面的有效性。
B. CAD 分割
CAD 分割涉及将以 B-Rep 格式表示的几何实体模型分解为其各个组成部分,包括面和边。CAD 分割在检索 CAD 参数化特征历史、加工特征识别、计算机辅助工程(CAE)和计算机辅助工艺规划(CAPP)中有着应用。这尤其引人入胜,因为它有助于自动化 CAD 设计和分析中的几个繁琐的手动任务,特别是当用户需要根据制造过程重复选择面和/或边组,作为建模或制造操作的输入时 [85, 93, 94]。然而,由于缺乏先进的深度学习方法,直到最近 CAD 分割的进展才受到阻碍。MFCAD [85] 是第一个合成分割数据集,包含 15,488 个带有平面面的 3D CAD 模型,每个模型标注了 16 种类型的加工特征,如倒角、三角形槽、通孔等。图 5 显示了该数据集的一些示例。
CAD 分割任务可以框定为节点分类问题,每个 3D 实体表示为一个面邻接图。图节点对应于 B-Rep 面,然后分类为不同的加工特征类别。CADNet [90] 是在这方面最早提出的方法之一,它将 B-Rep 实体表示为编码面几何和拓扑的图,并利用称为 Hierarchical CADNet 的分层图卷积网络将图节点(或实体面)分类为不同的加工特征。在评估中,该方法不仅利用了 MFCAD 数据集,还创建并发布了该数据集的扩展版本 MFCAD++,其中包含 59,655 个 CAD 模型,具有 3 到 10 个加工特征,包括平面和非平面面。如前所述,UV-Net 方法也以相同方式处理 CAD 分割,以监督方式在 MFCAD 数据集上训练其编码器。然而,将 B-Rep 转换为面邻接图会导致关于附近实体相对拓扑位置的一些信息丢失。此外,基于 UV 坐标构建的图表示缺乏平移和旋转不变性。
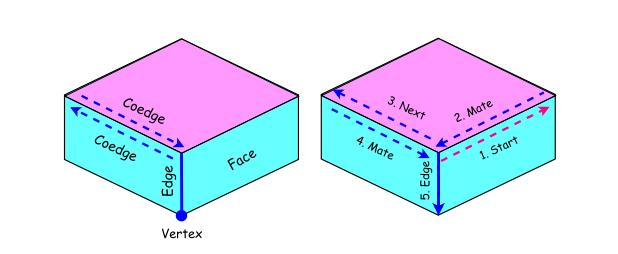
BRepNet [14] 是第一个专门为基于深度学习的 B-Rep 分割设计的方法,值得注意的是,它没有向网络引入任何坐标信息。它直接操作 B-Rep 面和边,利用从其拓扑关系中导出的紧凑信息进行 B-Rep 分割。BRepNet 方法的动机源于用于图像处理的 CNN 中卷积操作的思想。在该操作中,通过在网格数据上滑动称为滤波器或核的小窗口,并对重叠的网格单元执行逐元素乘法,然后对结果进行池化,从而聚合局部特征。这一概念被扩展到 B-Rep,允许在数据结构中相对于每个 coedge 的精确定位位置上识别一组面、边和 coedge。Coedge 是一个双向链表的有向边,表示 B-Rep 实体的邻接结构。每个 coedge 还保留关于其父面、父边、其邻居(匹配)coedge 以及指向面周围环中下一个和前一个 coedge 的指针。图 6 展示了一个从给定 coedge(红色)到其某些邻居实体(如匹配 coedge、下一个和前一个 coedge、面和边)的行走序列遍历的拓扑示例。围绕 coedge 的几何特征信息,包括面和边类型、面面积、边凸度和长度以及 coedge 方向,被编码为 one-hot 向量,并按预定顺序连接,形成面、边和 coedge 的特征矩阵 Xf、Xe、X^c。然后将这些矩阵传入神经网络,通过矩阵/向量乘法执行卷积操作,以识别每个 coedge 周围的模式。此外,BRepNet 的性能还在 Fusion 360 Gallery 的一个分割数据集上进行了评估,该数据集与 BRepNet 方法一起发布,是第一个包含真实 3D 设计的分割数据集。如表 3 所示,该数据集包含 35,680 个 3D 形状,每个形状标注了用于创建模型中面的 8 种建模操作类型。图 7 显示了该数据集的一些示例。
[13] 中提出的自监督方法也在分割任务上进行了评估,首先以自监督方式在 Fusion 360 Gallery 分割数据集的 27,450 个零件子集上预训练网络。这种预训练在不使用面标注的情况下进行。随后,网络以监督方式进行微调,仅暴露于有限数量的标注零件,以展示该方法在少样本设置下在 Fusion 360 和 MFCAD 数据集上的性能。CADOps-Net [25] 从 UV-Net [9] 和 BRepNet [14] 等 CAD 分割方法中汲取灵感,这些方法将 B-Rep 分割成基于其关联 CAD 操作的不同面,并提出了一种神经网络架构,该架构以 3D 形状的 B-Rep 数据为输入,学习将其分解为各种操作步骤及其对应类型。此外,它还引入了 CC3D-Ops 数据集,包含 37,000 个 CAD 模型,标注了每个面的 CAD 操作类型和构建步骤。
C. CAD 装配
我们周围遇到的物理物体主要是由 CAD 设计师通过 CAD 软件设计然后将多个较小和较简单的零件对齐而构建的复杂装配体。CAD 中零件的细致配对是一个费力的手动过程,消耗设计师大约三分之一的时间 [19]。它需要将零件相对于彼此精确定位,并指定它们的相对运动。因此,优化此过程对于提高 CAD 系统的效率至关重要。近年来,这一问题已在各种研究中使用深度学习方法进行探索 [95-102],以简化零件装配并为各种应用开辟途径,如机器人装配 [103]、CAD 装配合成 [104]、零件运动预测 [105]、机器人设计优化 [106] 以及 CAD 装配体中的相似性分析 [107]。然而,所有这些方法都使用非参数化数据结构(如网格、点云和体素网格)进行操作。因此,它们利用为这些数据结构定制的 GDL 方法,如 DGCNN [55]、PCPNet [108]、PointNet [8] 和 PointNet++ [8],来学习表面表示。这些方法主要采用自顶向下的方法来预测一组零件在全局坐标系中装配的绝对姿态。然而,这种方法缺乏对零件参数化变化的支持,无法修改装配或建模自由度,并且当零件无法完全对齐时也可能导致失败。此外,这些方法严重依赖像 PartNet [73] 这样的带标注数据集,该数据集仅提供网格格式的数据。
一种自底向上的方法,依赖于成对约束并利用 B-Rep 数据中可用的接合或接触信息来装配零件对,可以在不需要数据集上类别标注的情况下解决这个问题。然而,当前的 B-Rep 数据集如 ABC [86] 和 Fusion 360 Gallery [30] 缺乏用于 CAD 装配体的配对基准,因此不适合训练装配预测模型。AutoMate [19] 和 JoinABLe [18] 是最近提出的仅有的两项工作,采用自底向上的学习方法局部配对零件以形成装配体。此外,它们还随其方法发布了 B-Rep 数据集,为训练模型提供了配对基准。
1) AutoMate [19]
AutoMate 是该领域中第一个专注于 CAD 装配的工作,操作于参数化 B-Rep 数据格式。此外,这项工作引入了第一个带有配对基准的 B-Rep 格式 CAD 装配体大型数据集,以促进该领域的未来研究。AutoMate 数据集通过从 Onshape API 收集公开可用的 CAD 设计而创建,包含 92,529 个独特的装配体,平均每个装配体有 12 个配对,以及 541,635 个独特的配对。该工作中的配对意味着根据 B-Rep 拓扑定义的成对约束对齐两个零件。这些成对约束被称为配对或接合,它们决定了装配体中零件的相对姿态和自由度(DOF)。两个零件可以通过各种拓扑实体(如面、边和顶点)进行配对。因此,有必要学习不同级别上多个拓扑实体的特征表示,以解决 CAD 装配问题的复杂性。与之前的 CAD 表示学习方法(如 BRepNet [14] 和 UV-Net [9])构建面邻接图以捕捉 B-Rep 的同质结构并专注于学习面实体的特征表示不同,AutoMate [19] 采用了不同的方法。它旨在通过学习异质的 B-Rep 结构来学习面、环、边和顶点的表示。这是通过引入结构化 B-Rep 图卷积网络(SB-GCN)架构实现的,这是一种为学习 B-Rep 的异构图表示而设计的消息传递网络。
SB-GCN 以异构图作为输入,其中面 F、边 E、顶点 V 和环 L 作为图节点,它们之间的有向二分连接集表示图边。具体来说,B-Rep 顶点和边之间的关系用 V:E 及其转置 E:V 表示。类似地,E:L 和 L:E 表示 B-Rep 边和环之间的关系,而 L:F 和 F:L 表示面和环之间的连接。此外,几何相邻面之间存在无向关系(元路径),表示为 F:F。每个节点关联一个编码为 one-hot 特征向量的参数化几何函数。该网络利用结构化卷积为所有图节点生成输出特征向量。不同节点类型的邻接结构在不同的网络层中以有序层次结构被捕获。最初的三层以自底向上的顺序捕获 B-Rep 层次结构中的关系:顶点到边、边到环、环到面。随后,接下来的 k 层专注于捕获面之间的元关系。最后三层反转节点关系:面到环、环到边、边到顶点。网络使用两个不同的输出头来预测配对位置和类型。配对位置预测头评估与两个配对上选定面相邻的配对坐标系(MCF)对。同时,配对类型预测头预测这一对 MCF 应如何配对。这是通过将特征分类为七个不同的配对类别来完成的,即:紧固、旋转、平面、滑块、圆柱、平行、球、销槽。该模型在 AutoMate 数据集的 180,102 个配对上训练,并作为 Onshape CAD 系统的扩展集成。此集成通过在 CAD 设计过程中为零件对提供配对推荐来辅助设计师。
2) JoinABLE [18]
Joinable 是另一种最近的方法,采用自底向上的方法基于成对约束预测零件之间的接合(或配对)。与 AutoMate 依赖于用户在零件上选择接触面来对多个配对解决方案进行排序和推荐不同,JoinABLE 无需局限于预定义的面即可识别零件之间的接合,自动进行且无需任何用户协助。Fusion 360 Gallery Assembly 数据集与 JoinABLE 方法同时被引入并提供,用于训练和评估 JoinABLE 模型。该数据集包含两个相互关联的数据集:Assembly 和 Joint。这些数据集是从 Autodesk 在线画廊中公开可访问的用户设计 CAD 模型收集的。Assembly 数据包含 8,251 个装配体,总计 154,468 个独立零件,以及它们对应的接触面、孔、接合点和相关的图结构。Joint 数据包含 23,029 个独特零件,包含它们之间的 32,148 个接合点。JoinABLE 使用从 Fusion 360 Gallery Assembly-Joint 数据集中提取的接合信息进行训练。Assembly Dataset [18] 是设计的一个子集,其中每个 CAD 模型由多个零件组成。在 CAD 设计上下文中,每个装配体或 3D 形状是一组连接在一起的零件,一组装配体可以构成一个 CAD 设计或 3D 物体。
两个零件通过它们的接合轴对齐,每个轴都有特定的方向。每个零件上的接合轴可以在面或边实体上定义,具有原点和方向向量。例如,在圆形曲面实体上,原点是圆心,方向向量是法向向量。成对零件的这些接合轴信息在 Fusion 360 Gallery Assembly-Joint 数据集中提供,该数据集是 Fusion 360 Gallery Assembly 数据集的一个子集,作为训练接合预测深度学习模型的真实标注。该数据集包含 23,029 个零件,它们之间有 32,148 个接合点。如图 8 所示,给定两个零件,JoinABLE 旨在预测它们之间的参数化接合,包括接合轴预测(两个零件上的原点和方向向量)和接合姿态预测。为此,每个零件被建模为一个图 G(V, E),以 B-Rep 面和边作为图节点,它们的邻接关系作为图边。B-Rep 面被编码为 one-hot 特征向量,表示曲面类型(如平面和圆柱),以及一个指示曲面是否相对于面反向的标志。类似地,B-Rep 边的 one-hot 向量包括曲线特征(如直线和圆)、曲线长度,以及一个表示曲线是否相对于边反向的标志。这些 one-hot 向量作为图节点特征。
对于分别具有 N 和 M 个节点的两个图 G1 和 G2,构建接合图 Gj 以说明两个图之间的连接。Gj 中的这种连接信息可以表示为 N×M 维的二元矩阵。与 Joint 数据集中提供的真实标注接合一致,只有代表两个零件间实体连接的一个矩阵元素应设为 1,其余为 0。JoinABLE 模型旨在找到那一个正元素,它由三个主要组件组成:编码器、接合轴预测和接合姿态预测。编码器采用 Siamese 风格架构,具有两个不同的 MLP 分支。一个分支专注于学习表示 B-Rep 面的节点特征,而另一个分支专注于学习表示 B-Rep 边的节点特征。每个零件中学习到的面和边的嵌入随后被连接起来,形成相应图的节点嵌入。然后将这些节点嵌入输入到图注意力网络 v2(GATv2)[109] 中,该网络通过消息传递捕捉每个图内的局部邻域结构。
接合轴预测被表述为一个链接预测任务,旨在通过链接两个节点来预测图 G1 和 G2 之间的连接。这涉及对接合图 Gj 进行边卷积,Gj 说明了两个图之间的连接,并用编码器在上一步中学习到的节点特征进行更新。假设 h_v、h_u 分别表示来自 G1、G2 的两个节点 v、u 的学习特征,则学习两个图中两个节点之间连接的边卷积执行如下:
h_uv = Φ(h_u ⊕ h_v) (1)
其中 Φ(·) 是一个应用于 h_u、h_v 连接特征的 3 层 MLP。边卷积之后,应用 softmax 函数对特征进行归一化,并预测 Gj 中节点之间最可能的链接。在预测接合轴以对齐两个零件之后,姿态预测头采用神经引导的搜索方法,迭代前 k 个接合轴预测。作为补充工作,JoinABLe 还提出了仅使用单个零件以及从 Assembly 数据集导出的零件对序列来装配多零件设计。然而,在实际应用中,这种明确定义的装配序列和相应的装配图可能无法供网络使用。此外,任何装配步骤中的错位都可能导致整个装配不正确。因此,建议对于大型复杂装配体,自顶向下和自底向上方法的结合可能更有效。
在 CAD 装配问题中,通常会出现两个主要问题:如何选择要接合(或配对)的零件对,以及如何装配它们 [110]。前一个问题可以通过利用相似性分析和检索方法来识别合适的零件对来解决。另一方面,AutoMate 和 JoinAble 专注于通过学习中装配两个零件的过程来回答后一个问题。
V. 基于生成式深度学习的 CAD 构建
基于生成式深度学习的 CAD 构建涉及利用先进的 GDL 方法自动生成或辅助创建参数化 CAD 模型。这些方法可以以多种方式支持设计师,简化设计流程。这包括生成或自动完成草图,以及基于设计的草图生成用于构建 3D 模型的 CAD 操作等任务。在本节中,我们将这些方法分为六个不同的组:1) 专注于 2D 草图的方法,旨在自动化 2D 空间中的草图绘制过程,作为开发 3D CAD 模型的初始步骤;2) 给定模型草图,进行 3D CAD 模型重建的方法;3) 生成 CAD 构建序列的方法,特别专注于用于 CAD 构建的草图和拉伸操作;4) 执行直接 B-Rep 合成以生成 3D CAD 模型的方法;5) 从点云数据生成 3D CAD 模型的方法;6) 从图像生成 CAD 模型的方法。
A. 用于 CAD 的工程 2D 草图生成
工程 2D 草图构成了 3D CAD 设计的基础。2D 草图由一组几何基元(如顶点、直线、圆弧和圆)及其对应的参数(例如半径、长度和坐标)组成,并在基元之间施加显式约束(例如垂直、正交、重合、平行、对称和平等)以确定它们的最终配置。这些 2D 草图随后可以被拉伸以制作 3D 设计。合成参数化 2D 草图并学习其编码的关系结构,可以为设计师在设计复杂工程草图时节省大量时间和精力。然而,在这方面利用深度学习方法需要大规模的 2D 工程草图数据集。现有的大规模数据集大多提供常见物体(如家具、汽车等)的手绘草图。QuickDraw 数据集 [111] 从 Quick, Draw! 在线游戏 [112] 收集,Sketchy 数据集 [88] 是成对的基于像素的自然图像及其对应矢量草图的集合。这些草图数据集基于草图的矢量图像,而不是其底层的参数化关系几何。为了使用深度学习模型推理参数化 CAD 草图并推断其设计步骤,需要一个大规模的参数化 CAD 草图数据集。
1) SketchGraphs [20]
在这方面引入的第一个数据集是 SketchGraphs,它是来自 Onshape 平台 [46] 的 1500 万个真实世界 2D CAD 草图的集合,每个草图表示为一个几何约束图,其中节点是几何基元,边表示设计师施加的基元之间的几何关系。该数据集还附带了一个开源数据处理管道,以促进该领域的进一步研究。SketchGraphs 不仅提供草图的底层参数化几何,还提供几何基元和它们之间约束的真实标注构建操作。因此,它可用于训练深度学习模型,以进行促进设计过程的不同生成应用。其中一个可以用作 CAD 软件高级功能的应用是,给定手绘草图或物体的噪声扫描,自动构建参数化 CAD 模型。SketchGraphs 处理管道可用于生成草图的噪声渲染。这样,可以创建成对几何草图及其噪声渲染图像的大规模数据集,以训练深度学习模型,根据手绘图像预测草图的设计步骤。然后,通过拉伸设计的 2D 草图可以获得模型的 3D 设计。在 [20] 中,提出了一个自回归模型,利用 SketchGraphs 数据集进行两个用例:1) 自动约束,即在给定未约束几何的情况下,通过生成基元之间的约束来条件性完成草图;2) 生成式建模,即通过生成用于添加下一个基元及其之间约束的构建操作来自动完成部分设计的草图。尽管大多数 CAD 软件都有内置的约束求解器用于设计过程,但当未约束的草图作为绘图扫描上传到软件,设计师需要找到草图基元之间的约束和/或完成草图时,这些生成方法非常有用。这个问题与约束编程中的程序合成或归纳非常相似。SketchGraphs 数据集及其生成方法可以作为该方向未来工作的良好基线。下面,更详细地描述两个生成用例。
假设一个草图由一个多超图 G = (V, E) 表示,其中节点 V 表示基元,边 E 表示它们之间的约束。在此图中,每条边可能连接一个或多个节点,多条边可能共享同一组连接的节点。具有单个节点的边表示为自环,显示单个基元(例如线)的单一约束(例如长度),超边应用于三个或更多节点(例如,应用于两个基元的镜像约束,同时指定另一个基元作为对称轴)。图 3 展示了一个草图图的示例。每个约束由其类型标识,每个基元由其类型及其参数标识(不同的基元可能有不同数量的参数)。对于自动约束任务,所有图节点(基元)都已给出,模型以监督方式训练,根据数据集中约束的真实标注顺序预测边的序列。这个问题可以看作是图链接预测 [113] 的一个实例,它预测图节点之间的诱导关系。从第一个构建步骤开始,模型首先预测哪个节点应与当前节点连接,然后在两个相邻节点之间创建链接(边)。然后它预测此边(约束)的类型。对于生成式建模任务,它通过生成新的基元(节点)和它们之间的约束(边)来自动完成部分完成的草图(图),基元仅由其类型表示(忽略基元参数),约束由其类型及其数值或分类参数表示。例如,如果两个基元之间的约束是距离,其参数可以是一个标量值,表示两个基元之间的欧几里得距离。然而,虽然该模型预测约束的类型和参数,但它仅预测基元的类型,而不预测其参数,并且基元的初始坐标可能不适合草图和约束。因此,草图中基元坐标的最终配置需要通过 CAD 软件内置的几何约束求解器找到。这个问题在下一项用于 2D 草图生成的工作 CurveGen-TurtleGen [21] 中得到了解决,该工作在 V-A2 中介绍。
2) CurveGen-TurtleGen [21]
如前文 V-A1 所述,SketchGraphs 中的生成模型依赖于 CAD 软件中内置的草图约束求解器来设置生成草图的最终配置。这个问题通过 [21] 中提出的两个生成模型 CurveGen 和 TurtleGen 得到了解决,它们将约束信息隐式编码在几何坐标中,从而独立于草图约束求解器。在这项工作中,基元类型被简单地限制为直线、曲线和圆,因为它们是 2D 草图中最常见的基元,并且认为草图中基元之间的约束应该以几何基元能够形成封闭轮廓环的方式定义。为此,该方法提出了两种不同的工程草图表示:CurveGen 使用的草图超图表示,以及 TurtleGen 使用的 Turtle Graphics 表示。
在草图超图表示中,草图表示为一个超图 G = (V, E),其中一组顶点 V = {v_1, v_2, …, v_n} 及其对应的 2D 坐标 v_i = (x_i, y_i) 被编码为图节点,而 E 表示连接两个或多个顶点以形成不同基元的超边集。基元类型由超边的基数定义。例如,直线基元由两个连接的顶点构成,圆弧由三个连接的顶点构成,圆可以看作一组四个连接的顶点。图 9 显示了一个由 12 个顶点和 9 条超边组成的简单草图示例。这种表示被 CurveGen 使用,CurveGen 是一个基于 PolyGen [56] 的自回归 Transformer。PolyGen 是一种自回归生成方法,用于使用能够捕捉长距离依赖关系的 Transformer 架构生成 3D 网格。网格顶点由 Transformer 无条件建模,网格面则由 Transformer 和指针网络 [114] 的组合以顶点为条件进行建模。与 PolyGen 类似,CurveGen 也通过首先生成用于制作曲线的图顶点 V,然后以生成的顶点为条件生成图超边 E,来直接生成草图超图表示,如下所示:
p(G) = p(E|V) p(V) (2)
通过这种方式,网络预测每个基元的精确坐标,而基元类型则隐式编码在将顶点分组以形成不同类型基元的超边中。因此,该方法不依赖于任何约束求解器来找到最终的基元配置。通过拥有草图曲线的精确坐标,它们之间的约束可以在后处理步骤中自动获得。然而,隐式推断约束使得在软件中编辑草图更加困难。如果设计师想要更改基元之间的某个约束(例如缩放距离),这种更改不会传播到整个草图和基元,因为基元的精确定位在某种程度上是固定的。
在 Turtle Graphics 表示中,草图由一系列绘图命令(pen-down、pen-draw、pen-up)表示,这些命令可以执行以形成超图表示中的工程草图。TurtleGen 网络是一个自回归 Transformer 模型,生成一系列绘图命令,以迭代绘制形成工程草图的闭合环序列。通过这种方式,每个草图表示为一个环序列,每个环由一个 LoopStart 命令构成,该命令抬起笔,将其移动到指定位置,放下笔,并开始绘制由 Draw 命令指定的参数化曲线。在图 9 中,展示了一个简单草图及其对应的命令序列。该草图包含 2 个环和 9 个 Draw 命令,包括弧、直线和圆类型。初始环从位置 Δ = (int, int) 开始,包含 4 个弧。每个弧从前一个弧的端点开始,经过另外两个顶点。这个环过渡到一个由 4 条直线组成的序列。第一条直线从最后一个弧结束的地方开始,经过一个额外的顶点,随后的直线重复此模式。第二个环是一个圆,从另一个位置 Δ 开始,经过另外 3 个顶点。CurveGen 和 TurtleGen 已在 SketchGraphs 数据集上进行了评估,显示出优于 SketchGraphs 中提出的生成模型的性能。我们请读者参阅 [21] 以了解有关模型架构、训练和评估设置的更多详细信息。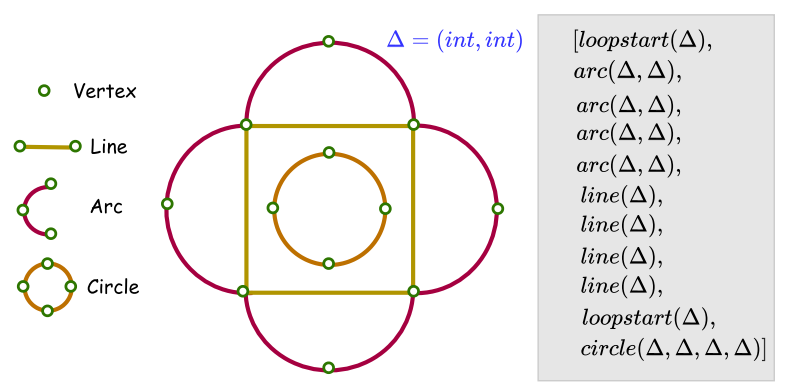
3) SketchGen [26]
与 CurveGen-TurtleGen 同期,SketchGen 被提出,这是一种基于 PolyGen [56] 和指针网络 [114] 的自回归生成方法。与 PolyGen 不同,SketchGen 旨在捕捉草图中基元和约束的异质性,其中每种类型的基元和约束可能有不同数量的参数,每个参数类型不同,因此具有不同大小的表示。输入序列表示的选择对 Transformer 的性能有很大影响,将草图的异质约束图转换为适当的 token 序列相当具有挑战性。一种简单的解决方案是填充所有基元和约束的表示,使它们大小相同。然而,这种技术对于复杂草图来说效率低下且不准确。SketchGen 提出了一种具有简单语法的语言,以有效描述异质约束图。所提出的用于 CAD 草图的语言使用形式语法编码约束和基元参数。用于编码基元类型和参数的终结符是 {Λ, Ω, τ, κ, x, y, u, v, a, b},用于约束的是 {Λ, ν, λ, μ, Ω}。新基元或约束序列的开始和结束分别用 Λ 和 Ω 标记。基元类型用 τ 表示,ν 表示约束类型。κ, x, y, u, v, a, b 表示每个基元的特定参数,如坐标和方向。λ 和 μ 是特定的约束参数,分别指示约束引用的基元和它所针对的基元部分。这种形式语言能够区分不同的基元或约束类型及其各自的参数。例如,直线基元的序列是 Λ, τ, κ, x, y, u, v, a, b, Ω,以 Λ 开始,后跟基元类型 τ = line,构建指示符 κ,起点坐标 x 和 y,直线方向 u 和 v,直线范围 a, b,以 Ω 结束。平行约束的序列是 Λ, ν, λ_1, μ_1, λ_2, μ_2, Ω,以 Λ 开始,后跟约束类型 ν = parallelism,第一个基元的引用 λ_1,第一个基元的部分 μ_1,第二个基元的引用 λ_2,第二个基元的部分 μ_2,以 Ω 结束。通过这种方式,每个 token q_i(符号序列)表示一个基元或一个约束,每个草图 Q 表示为一个 token 序列。
与 PolyGen 和 CurveGen-TurtleGen 类似,如公式 (2) 所述,SketchGen 的生成模型也分解为两部分:首先生成基元 p§,然后以基元为条件生成约束 p(C|P) p§,如下所示:
p(S) = p(C|P) p§ (3)
因此,生成网络通过两个自回归 Transformer 学习约束草图的分布:一个用于基元生成,另一个用于条件约束生成。草图被解析为一个 token 序列,首先迭代所有基元并使用上述语言序列表达它们。随后,对草图中的所有约束应用类似的过程。如图 10 所示,基元生成器网络的输入是一个由 Λ 分隔的基元 token 连接序列,例如 Λ, τ_1, κ_1, x_1, y_1, u_1, v_1, a_1, b_1, Λ, τ_2, κ_2, x_2, y_2, …, Ω,约束生成器的输入是一个由 Λ 分隔的约束 token 连接序列,例如 Λ, ν_1, λ_11, μ_11, λ_12, μ_12, Λ, ν_2, λ_21, …, Ω。
所有基元和约束参数首先被量化,然后通过嵌入层映射,为网络生成输入特征向量。序列中 token 的位置信息也通过添加到每个嵌入向量的位置编码来捕获。生成的 token 序列随后被馈送到 Transformer 架构中以生成基元和约束。约束生成器网络不仅接收约束的嵌入和位置编码 token 作为输入,而且还接收上一步生成的表示基元的嵌入和位置编码 token 序列,以生成以基元为条件的约束。与 [20] 类似,该模型在 SketchGraphs 数据集上评估了两个任务:给定草图基元的约束预测,以及通过顺序生成基元和约束从零开始生成完整草图。最终生成的草图需要通过约束求解器进行正则化,以消除由于量化草图参数引起的潜在错误。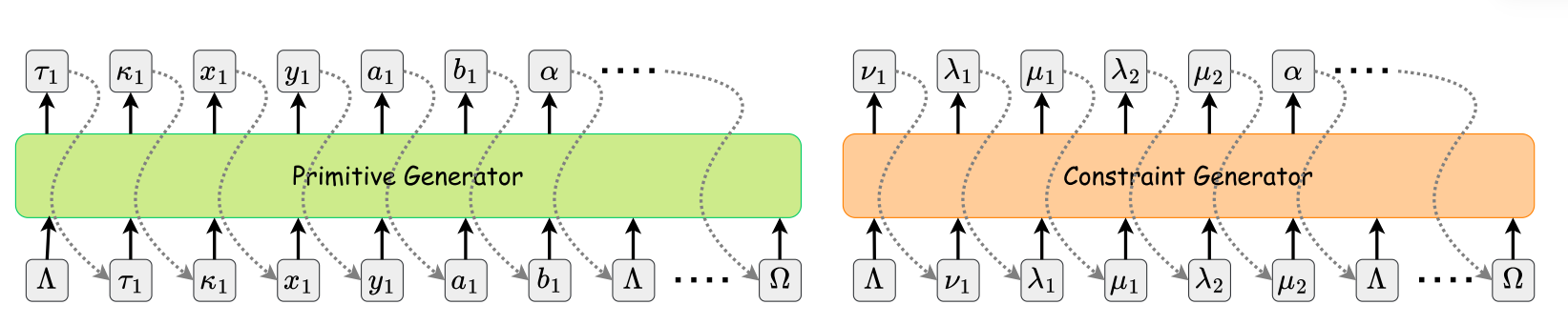
4) CAD as Language [27]
与 CurveGen-TurtleGen 和 SketchGen 同期,CAD as Language 是另一种基于 PolyGen [56] 的用于 2D 草图生成的自回归 Transformer 方法。与仅预测基元参数并带有隐式约束且独立于约束求解器的 CurveGen-TurtleGen 不同,CAD as Language 和 SketchGen 方法生成基元和约束,但依赖于内置约束求解器来获得草图的最终配置。然而,SketchGen 通过两个独立的 Transformer 网络生成基元和约束,同时不支持基元和约束 token 的任意顺序。在 SketchGen 中,草图被解析为一个 token 序列,首先迭代所有基元,然后迭代所有约束。CAD as Language 方法不仅处理基元和约束的任意顺序,而且通过一个 Transformer 网络生成基元和约束。与所有先前在 SketchGraphs 数据集上评估的草图生成方法不同,CAD as Language 在从 Onshape 平台新收集的超过 470 万个草图上评估其生成方法,这避免了 SketchGraphs 中的数据冗余问题。这个收集的数据集和相应的处理管道在 Github 上公开可用。
CAD as Language 使用了一种使用 Protocol Buffers (PB) [115] 描述结构化对象的方法,这比 JSON 格式在表示复杂对象的精确结构方面更高效和灵活。在此格式中,每个草图被描述为一条 PB 消息。与其他基于 Transformer 的方法类似,处理管道中的第一步也是最重要的一步是将草图解析为 token 序列。在该方法中,每个草图(或 PB 消息)表示为一个三元组序列 (d_i, c_i, f_i),其中每个索引 i 的三元组表示一个 token。每个 token(三元组)仅表示草图中一个基元或约束的一个组件(类型或参数),其中 d_i 是一个离散值,表示它所引用的对象类型、实体类型(基元、约束等),c_i 是一个连续值,表示相应实体的参数值。每次,d_i 或 c_i 中有一个是活跃的并获得一个值,另一个设置为零。f_i 是一个布尔标志,指定重复 token 的结束(例如,包含一个实体的对象的结束)。图 11 显示了一个分别指定一条直线和其一个端点上的一个点的 token 示例。
如本例所示,第一个三元组 (objects.kind) 始终与 token 所引用的对象类型相关联。第二个三元组中的值取决于第一个三元组中指定的对象类型。如本例所示,d_1 = 0 表示此 token 序列是关于创建基元(如直线),因此第二个三元组指定基元的类型(entity.kind),0 表示直线,1 表示点。序列中的下一个三元组指定与第二个三元组中标识的相应基元关联的特定参数。例如,直线基元由起点和终点定义,而点基元(在直线基元中也重复)由 x, y 坐标定义。
为了解释这些三元组(token),CAD as Language 方法还提出了一个自定义解释器,该解释器接收一个 token 序列(每个 token 表示一个草图组件,可以是实体类型、参数或任何其他设计步骤)作为输入,并将其转换为有效的 PB 消息。该解释器的设计方式可以处理 token 的任意顺序,并确保所有 token 序列都可以转换为有效的 PB 消息(草图)。该解释器通过草图生成过程引导 Transformer 网络。Transformer 网络接收一个 token 序列作为输入,并在每个时间步输出一个原始值,该值被传递给解释器以推断该值的对应三元组。该三元组是构成最终草图的 PB 消息的一部分。当解释器推断出输出值时,它会将其解释传播回 Transformer,以引导它生成下一个值。因此,该方法提出的将草图解析为 token 并解释它们的结构,使其能够仅通过一个 Transformer 网络生成每个草图组件(基元和约束),同时处理输入 token 的不同顺序。该方法还探索并评估了所提出的 Transformer 模型的条件变体,其中它以草图的输入图像为条件。
5) VITRUVION [23]
该方法是最近提出的用于草图生成的自回归生成模型。与 SketchGen 和 CAD as Language 类似,VITROVION 也自回归地生成基元和约束。然而,该方法与 SketchGen 更相似,因为基元和约束通过训练两个不同的 Transformer 网络独立生成。与先前方法相比,该方法的主要贡献在于以各种上下文(如手绘草图)为条件对模型进行建模。这一贡献朝着 CAD 软件中备受追捧的功能迈出了一步,即根据手绘图或物体的噪声扫描逆向工程机械零件。给定手绘图或噪声图像生成草图的参数化基元和约束,可以在设计过程中节省大量时间和精力。
与先前方法类似,VITROVION 是 PolyGen [56] 的泛化。它首先生成基元 P,然后以基元为条件生成约束 C,从而生成草图的概率分布。然而,在该方法中,基元生成可选地以图像为条件,如下所示:
p(P, C|I) = p(C|P) p(P|I) (4)
其中 I 是一个上下文,例如草图的手绘图像。然而,该方法中的约束建模仅支持具有一个或两个引用基元的约束,而不支持像 CurveGen-TurtleGen 方法中那样连接两个以上基元的超边。生成模型在 SketchGraphs 数据集上针对自动约束、自动完成和条件草图合成任务进行训练和评估。如 V-A1 所述,在自动约束应用中,网络以一组可用的基元为条件生成约束,但在自动完成任务中,通过生成基元和约束来完成不完整的草图。在这两种情况下,约束生成器网络以可能不完美的生成基元为条件。VITROVION 通过以噪声注入的基元为条件来增强约束生成器网络的鲁棒性。最终的基元和约束参数最终通过标准约束求解器进行调整。
对于图像条件草图合成,模型以手绘草图的栅格图像为条件推断基元。为此,使用基于 Vision Transformer [116] 架构的编码器网络来获得图像块的嵌入,然后基元生成器网络交叉注意力到这些块嵌入以预测草图基元。这个想法基于 PolyGen 中用于图像条件网格生成的类似思想。
该方法通过将每个基元和约束表示为三个 token 的元组:value、ID、position,来对草图进行 token 化。value token 有两方面:一个表示基元或约束的类型,另一个表示该基元或约束关联参数的数值。ID token 表示 value token 指定的参数类型,position token 表示该 ID 和 value token 所属的基元或约束的顺序索引。基元的顺序根据 SketchGraphs 数据集中指示的设计步骤,约束的顺序根据其对应引用基元的顺序。
B. 从草图生成 3D CAD
1) Sketch2CAD [24]
第一个通过交互式草图进行顺序 3D CAD 建模的工作是 Sketch2CAD。这项工作是一个基于学习的交互式建模系统,通过将用户的输入草图解释为一系列参数化 3D CAD 操作,统一了 CAD 建模和草图绘制。给定一个现有的不完整 3D 形状和用户在其上添加的输入草图笔划,Sketch2CAD 首先获取草图局部上下文的法向图和深度图,这些被引入到 CAD 操作符分类和分割网络中。分类由一个 CNN 网络完成,预测在 3D 形状上创建相应输入草图所需的 CAD 操作类型。它接收三个 256×256 大小的地图的串联作为输入,即表示笔划像素具有二进制值的草图地图,以及通过从特定视角渲染形状表示局部上下文的法向图和深度图。需要注意的是,该方法仅支持四种最广泛使用的 CAD 操作类型,即拉伸、添加/减除、倒角、扫掠。根据预测的操作类型,操作符的参数通过特定的分割网络进行回归。例如,对于预测的扫掠操作符,训练一个 SweepNet 来推断相应的参数。四个分割网络中的每一个都具有 U-Net 结构,带有一个编码器和两个解码器,一个生成草图的基面概率图,另一个生成相应的曲线分割图。分割之后是一个优化过程,用于拟合操作参数。
所识别操作的参数化特性为逼近输入笔划提供了强正则化,并允许用户通过调整和回归参数来优化结果。该建模系统还集成了标准 CAD 建模功能,如自动捕捉和自动完成。系统的输出是一系列 CAD 指令,可供下游 CAD 工具处理。由于没有成对的草图和 3D CAD 建模操作序列的数据集,Sketch2CAD 引入了一个包含 40,000 个形状用于训练和 10,000 个形状用于测试的合成数据集,其中包含逐步的 CAD 操作序列及其对应的草图图像渲染。数据集、代码和视觉示例已公开可用。
2) Free2CAD [22]
Sketch2CAD 的主要挑战之一是它一次只能处理一个 CAD 操作,这意味着它假设在每一步,用户添加到形状上的绘图仅对应一个 CAD 操作。它要求用户按顺序和部分绘制草图,以便可以将其分解为有意义的 CAD 操作。Free2CAD 被提出来解决这一限制。这是第一个基于草图的建模方法,用户可以输入复杂 3D 形状的完整绘图,而不需要具备如何将此草图分解为 CAD 操作的专业知识,也不需要遵循特定的策略来绘制草图和与系统交互。
Free2CAD 是一个序列到序列的 Transformer 网络,它接收描绘 3D 形状的用户绘制笔划序列作为输入,处理并分析它们,以生成有效的 CAD 操作命令序列,执行这些命令可以创建 CAD 模型。该方法的主要贡献是自动分组草图笔划,并为每组笔划顺序生成参数化 CAD 操作,以先前迭代中已重建的组为条件。该方法包括两个阶段,即笔划分组阶段和操作重建阶段。在笔划分组阶段,首先通过专门设计的 Transformer 编码器网络将每个草图笔划嵌入为一个 token,然后由 Transformer 解码器网络处理,为输入 token 生成组概率。通过这种方式,可能构成形状特定部分的草图笔划被分组在一起。与笔划分组阶段最密切相关的工作是 SketchGNN [65] 方法,它提出了一种用于手绘草图语义分割的图神经网络方法。接下来,在操作重建阶段,候选组被转换为具有相应参数的几何基元,以现有的几何上下文为条件。此步骤之后是几何拟合和分组校正,然后再将更新的组作为几何上下文传递到下一次迭代。在此过程结束时,获得所需的 CAD 形状和 CAD 命令序列。该方法还被扩展为使用滑动窗口方案逐步输出 CAD 模型来处理形成复杂形状的长笔划序列。
与 Sketch2CAD [24] 类似,Free2CAD 还提供了一个大规模的合成数据集,包含 82,000 个成对的 CAD 建模操作序列及其对应的渲染草图,这些草图根据其对应的 CAD 命令进行分割。该方法的代码和数据集已公开可用。Free2CAD 在他们生成的数据集和 Fusion 360 数据集上的评估结果显示了其在处理不同用户绘图和生成由 CAD 工具执行时产生理想 3D 形状的 CAD 命令方面的高性能。
3) CAD2Sketch [28]
与 Sketch2CAD 试图在交互式建模系统中为非专家用户促进设计过程不同,CAD2Sketch 旨在帮助专家工业设计师。顾名思义,CAD2Sketch 是一种专门用于从 CAD 模型合成概念草图的方法。概念草图是 CAD 建模中的一个初步阶段,设计师在此阶段将他们对 3D 物体的心智概念从粗略轮廓细化到复杂细节,通常使用大量的构造线。一个简单概念草图的示例显示在图 12 的左侧,其细化版本显示在右侧。值得注意的是,概念草图反映了设计师思维中的详细步骤,类似于 CAD 建模的阶段,而 Sketch2CAD 数据集中的草图通常呈现最终的手绘草图,没有这些详细的辅助构造线。CAD2Sketch 通过提出一种将 CAD B-Rep 数据转换为概念草图的方法,引入了一个大规模的概念草图合成数据集。CAD2Sketch 通过引入一种将 CAD B-Rep 数据转换为概念草图的方法,建立了一个大规模的概念草图合成数据集。该数据集与 OpenSketch [89] 数据集相当,后者包含 400 个由不同专家设计师制作的真实概念草图。然而,CAD2Sketch 旨在弥合合成数据和真实数据之间的差距,使神经网络能够在概念草图上进行训练。CAD2Sketch 方法首先为 CAD 序列中的每个操作生成构造线。为了避免用太多线条使草图过载,通过解决一个二元优化问题来选择这些线条的子集。随后,调整每条线的不透明度和形状,以实现与真实概念草图的视觉相似性。CAD2Sketch 生成的合成概念草图与其在 OpenSketch 中的对应真实配对非常相似,以至于设计师几乎无法区分它们 [28]。CAD2Sketch 还生成了大量成对的草图和法向图,用于训练神经网络从概念草图推断法向图。该数据集包含大约 6,000 对成对的概念草图和法向图。训练好的神经网络对真实形状的泛化能力在 ABC 数据集的 108 个 CAD 序列测试集上进行了评估,取得了有希望的结果。然而,值得注意的是,由于 OpenSketch 数据集规模相对较小,该方法仅在有限数量的真实草图上进行了评估。此外,CAD2Sketch 方法建立在现有大规模 CAD 数据集的 CAD 序列之上,仅限于由草图和拉伸操作组成的序列。
C. 3D CAD 命令生成
虽然先前的方法已经引入了用于 3D CAD 重建的合成数据集,但缺乏保留 CAD 命令序列的人体设计 3D CAD 模型的标准化集合构成了一个限制。与 SketchGraphs 数据集在 2D 草图合成领域的宝贵贡献类似,一个精心策划的、保留 CAD 命令序列的人体设计 3D CAD 模型数据集将极大地有益于研究和现实世界应用实用方法的开发。Fusion 360 Reconstruction 数据集 [30] 填补了这一空白,作为第一个人体设计的数据集,包含 8,625 个使用草图和拉伸 CAD 操作序列构建的 CAD 模型。该数据集附带一个称为 Fusion 360 Gym 的环境,能够执行这些 CAD 操作。每个 CAD 模型表示为一个领域特定语言(DSL)程序,这是一种有状态语言,作为底层 Fusion 360 Python API 的简化包装器。该语言跟踪当前正在构建的几何体,通过草图和拉伸命令序列迭代更新。数据和相应的代码已公开可用。该数据集通过训练和评估一种基于机器学习的方法进行基准测试,该方法具有神经引导搜索,用于从指定几何体进行程序化 CAD 重建。该方法首先训练一个策略,该策略实例化为一个消息传递网络(MPN)[117, 118],具有状态和动作的原始编码。这种训练通过模仿学习进行,从真实标注的构建序列中获取见解。在随后的推理阶段,该方法结合了一种搜索机制,利用学习到的神经策略与 Fusion 360 Gym 环境迭代交互,直到识别出精确的 CAD 程序。然而,该方法的一个局限性是它假设 2D 几何体已给出,该方法仅预测要在每次迭代中拉伸的草图及其程度。随后,该数据集已被生成方法使用,这些方法处理几何体未提供的情况,需要从头开始使用草图和拉伸操作合成整个 3D 模型。
作为另一种通过神经引导搜索推断 CAD 建模构建序列的努力,[29] 中提出了一种方法,其中每个 CAD 模型的 B-Rep 数据以区域图的形式表示,其中实体区域构成区域,曲面片(曲线)形成边。然后将这种表示引入 GCN 以促进特征学习,随后采用一种搜索方法来推断可以忠实重建该区域图的 CAD 操作序列。然而,这两种方法都没有利用生成方法进行 CAD 操作生成。在本小节中,我们将介绍该领域最新的生成方法。
1) DeepCAD [17]
第一个用于创建 3D CAD 命令的生成深度学习模型是 DeepCAD。鉴于 CAD 操作和 B-Rep 数据的顺序性和不规则性,有必要选择一组最常用的 CAD 操作,并将它们组织成一个统一的结构,以供生成神经网络使用。受早期用于 2D CAD 分析和草图生成的生成技术(如 V-A 节中概述的 CurveGen-TurtleGen、SketchGen、CAD as Language 和 VITROVION)的启发,DeepCAD 遵循类似的方法,将 CAD 操作比作自然语言。它引入了一个用于自动编码 CAD 操作的生成 Transformer 网络。值得注意的是,DeepCAD 与先前的生成方法不同,它采用了前馈 Transformer 结构,而不是在此类上下文中常用的自回归 Transformer。此外,DeepCAD 构建并发布了一个大规模数据集,其中包含来自 Onshape 存储库的 178,238 个通过草图和拉伸操作生成的 CAD 模型,以及它们各自的 CAD 构建序列。该数据集超过了包含大约 8,000 个设计的 Fusion 360 Gallery 数据集的大小。DeepCAD 数据集中设计数量的大幅增加增强了其训练生成网络的适用性。
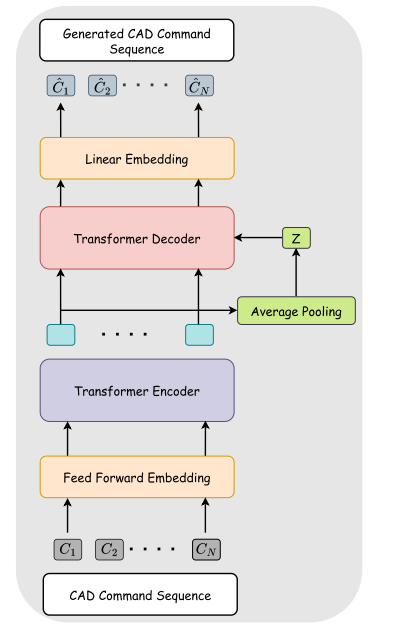
在 DeepCAD 为 CAD 操作建议的标准化结构中,CAD 命令被显式详细说明,提供关于其类型、参数和顺序索引的信息。草图命令包括直线、圆弧和圆类型的曲线及其各自的参数。同时,拉伸命令表示单侧、对称、双侧类型的拉伸操作和新体、合并、切割或相交类型的布尔操作。这些操作用于将修改后的形状与先前构建的形体集成。一个 CAD 模型 M 表示为一个曲线命令序列,这些命令构建草图,并与拉伸命令交织在一起。表示每个 CAD 模型的 CAD 命令总数固定为 60,并使用带有空命令的填充方法来适应命令序列较短的 CAD 模型到这个固定长度结构中。每个命令被编码为一个 16 维向量,表示所有命令的整个参数集。在给定命令的特定参数不适用的情况下,它们被统一设置为 1。如图 13 所示,自编码器网络接收一个 CAD 命令序列作为输入,通过 Transformer 编码器将其转换为潜在空间,随后解码潜在向量以重建一个 CAD 命令序列。生成的 CAD 命令可以导入 CAD 软件供最终用户编辑。
DeepCAD 的性能在两个任务上进行了评估:CAD 模型自动编码和随机 CAD 模型生成。一旦自编码器网络被训练用于重建 CAD 命令,就采用 latent-GAN 技术 [119] 在学习的潜在空间上训练生成器和判别器。生成器通过接收从多元高斯分布中采样的随机向量作为输入来生成潜在向量 z。然后可以将此潜在向量引入到训练好的 Transformer 解码器中以生成 CAD 模型命令。他们的实验还表明,在 DeepCAD 数据集上预训练的模型在应用于 Fusion 360 数据集时表现出良好的泛化能力。值得注意的是,这两个数据集来自不同的来源,即 Onshape 和 Autodesk Fusion 360。
DeepCAD 生成模型的应用进一步体现在将 3D 点云数据转换为 CAD 模型的过程中。在此上下文中,生成自编码器和 PointNet++ 编码器 [8] 被同时训练,以将 CAD 模型从 CAD 命令序列及其对应的点云数据编码到相同的潜在向量 z。在推理过程中,预训练的 PointNet++ [8] 编码器将点云数据嵌入到潜在向量 z 中,该向量随后被输入到预训练的 DeepCAD 自编码器的生成解码器中以产生 CAD 命令序列。
2) SkexGen [31]
尽管 DeepCAD 在生成多样化的形状方面取得了进展,但对生成设计的用户控制有限仍然是一个持续的挑战。用户能够影响输出并定制设计以满足特定要求,对于现实世界的应用将是一个巨大的优势。为了应对这一挑战,SkexGen 提出了一种新颖的自回归 Transformer 网络,具有三个独立的编码器,分别捕捉 CAD 命令序列中的拓扑、几何和拉伸变化。这种方法使用户能够更有效和独特地控制模型的拓扑和几何,促进在相关设计的更广泛搜索空间中进行探索,从而生成更逼真和多样化的 CAD 模型。
受 CurveGen-TurtleGen [21] 和 DeepCAD [17] 方法的启发,SkexGen 中的 CAD 模型由具有草图和拉伸构建序列的基元层次结构表示。在此层次结构中,一个 3D 模型由 3D 实体组成,其中每个实体定义为一个拉伸的草图。一个草图构成一组面,每个面表示一个由环包围的 2D 曲面。一个环由一个或多个曲线(包括直线、圆弧或圆)形成,曲线表示层次结构的基本级别。因此,CAD 模型使用五种类型的 token 编码为 Transformer 的输入:1) 拓扑 token,表示曲线类型;2) 几何 token,指定曲线上的 2D 坐标;3) 基元结束 token;4) 拉伸 token,指示拉伸和布尔操作的参数;5) 序列结束 token。SkexGen 引入的自回归 Transformer 网络由两个独立的分支组成,每个分支单独训练:1) 草图分支由两个不同的编码器组成,专门用于学习草图中的拓扑和几何变化。此外,使用一个单独的解码器,接收连接起来的拓扑和几何编码码本作为输入,并自回归地预测草图子序列。2) “拉伸”分支包含一个专门设计用于学习拉伸和布尔操作变化的编码器和解码器。此外,在顶部有一个额外的自回归解码器,学习几何、拓扑和拉伸码本的有效组合作为 CAD 构建序列。这种复杂的 token 化和多面网络架构允许对拓扑和几何进行细致和全面的控制,通过有效捕捉各种设计方面来生成 CAD 模型。
鉴于 SkexGen 能够独立编码和生成草图和拉伸命令序列,该方法具有通用性,可以应用于 2D 草图生成和 3D CAD 生成任务。评估结果突出了它与 CurveGen-TurtleGen [21] 和 DeepCAD [17] 方法相比,在生成更复杂设计方面的能力。值得注意的是,SkexGen 擅长支持多步草图和拉伸序列,而 DeepCAD 主要产生单步结果。
3) Diffusion-CAD [32]
Diffusion-CAD [32] 引入了一种基于扩散的生成模型,用于合成 3D CAD 构建序列,特别强调细粒度用户控制和结构有效性。与先前的方法(如 DeepCAD 和 SkexGen)要么缺乏显式可控性,要么依赖于从潜在码本中进行离散采样不同,Diffusion-CAD 将 CAD 命令生成表述为嵌入命令序列上的连续去噪扩散过程。这种方法提供了更大的控制力和更平滑的生成采样空间。
在 Diffusion-CAD 中,每个 CAD 模型表示为一个固定长度的 N = 60 命令序列,其中每个命令由一个类型标识符(例如,直线、圆弧、圆、拉伸)和一组最多 17 个几何参数组成。命令被嵌入到连续向量中,并在前向扩散过程中随时间步添加高斯噪声。然后训练一个基于 Transformer 的去噪网络来恢复原始命令向量,这些向量最终被投影回离散命令 token。该框架允许从噪声中生成有效且多样化的 CAD 模型,同时在生成过程中支持多种控制机制。Diffusion-CAD 的一个关键贡献是其支持多种形式的用户定义控制,包括:
- 命令类型控制:将生成限制为特定类型的基元(例如,仅圆和拉伸)。
- 尺寸控制:固定特定的几何参数,如半径或角度。
- 部分草图完成:给定用户提供的前缀,完成完整的 CAD 序列。
- 结构控制:通过约束满足模块强制执行关系,如对称、垂直或共线。
- 类别条件生成:使用分类器引导的扩散从特定语义类别生成形状。
与 Struggles with structural consistency 的 DeepCAD [17] 和缺乏对几何精细控制的 SkexGen [31] 相比,Diffusion-CAD 展示了更鲁棒和灵活的生成。它标志着 CAD 序列生成的重要一步,结合了深度生成建模的优势与显式的、用户引导的可控性,以生成有效且富有表现力的 CAD 模型。
D. 直接 B-Rep 合成的 3D CAD 生成
通过生成 CAD 命令或直接 B-Rep 合成来创建 3D CAD 设计各有利弊。先前工作中介绍的生成方法,即 Fusion 360 Reconstruction、DeepCAD 和 SkexGen,都有一个共同的目标,即通过生成 3D CAD 操作或命令序列来生成 3D CAD 模型。然后,这些命令由 CAD 工具中的实体建模内核处理,以 B-Rep 格式恢复最终的 CAD 设计。生成 CAD 命令(而不是直接创建 B-Rep)有几个优点。将 CAD 命令转换为 B-Rep 格式是可行的,而反向过程更具挑战性,因为不同的命令序列可能导致相同的 B-Rep,存在潜在的二义性。此外,CAD 命令更易于人类解释,使用户能够通过处理 CAD 工具中的命令来编辑设计以用于各种应用。然而,为此类任务训练模型需要保留 CAD 建模操作历史的大规模 CAD 数据集。因此,像 DeepCAD(包含约 190,000 个模型)和 Fusion 360 Reconstruction(约 8,000 个模型)这样的数据集是专门为此目的构建的。相比之下,该领域中的大多数大规模数据集,如 ABC(超过 100 万个模型),仅提供 B-Rep 数据,没有存储的 CAD 建模操作序列。虽然生成 CAD 命令提供了更大的灵活性、互操作性和用户控制,但另一种策略是直接合成 B-Rep。在利用现有大规模数据集时,这种方法可能是有益的。此外,直接 B-Rep 合成允许支持更复杂的曲线和曲面来创建 3D 形状。这与 CAD 命令生成方法形成对比,后者受限于使用有限支持的曲线类型列表通过草图和拉伸命令构建的 CAD 模型。
1) SolidGen [15]
SolidGen [15] 引入了一种直接 B-Rep 合成的方法,消除了对 CAD 命令序列历史的需求。该方法利用指针网络 [114] 和自回归 Transformer 网络来学习 B-Rep 拓扑,并逐步分别预测顶点、边和面。与 SolidGen 并行运行的是 [120] 的工作,专注于给定单个 2D 线框图时 B-Rep 数据中的 3D 面识别。受指针网络启发,该方法也采用自回归 Transformer 网络来识别 2D 线框图中的边环,并一次预测一个 co-edge 索引,对应于 3D 设计中的实际平面和圆柱面。然而,SolidGen 作为一种更有优势的方法脱颖而出。它超越了边环识别,为 3D 形状合成了完整的 B-Rep 数据。此外,它支持设计中所有类型面的表示,提供了更全面和通用的解决方案。
SolidGen 还引入了索引边界表示(Indexed B-Rep)来将 B-Rep 表示为适合神经网络使用的数值数组。这种索引 B-Rep 将 B-Rep 顶点、边和面组织在明确定义的层次结构中,以捕捉几何和拓扑关系。在结构上,它由三个列表组成,表示为 V、E、F,分别表示顶点、边和面。在这种层次结构中,边 E 表示为引用顶点 V 的索引列表,而 F 中的每个面表示一个引用边 E 的索引列表。所提出的自回归网络通过训练三个不同的 Transformer 分别生成顶点、边和面,逐步预测 B-Rep token。形式上,其目标是学习 B-Rep B 上的联合分布:
p(B) = p(V, E, F) (5)
分解为:
p(B) = p(F|E, V) p(E|V) p(V) (6)
这种结构还允许以外部上下文 c(如类别标签、图像和体素)为条件来分布:
p(B) = p(F|E, V, c) p(E|V, c) p(V|c) (7)
训练后,生成一个 Indexed B-Rep 涉及采样顶点、以顶点为条件采样边,以及以边和顶点为条件采样面。随后,获得的 Indexed B-Rep 可以通过后处理步骤转换为实际的 B-Rep。为了更全面地理解这些过程,感兴趣的读者可以参考原始论文 [15]。该方法的有效性使用 DeepCAD 数据集的精炼版本进行评估。此外,SolidGen 引入了参数化变化(PVar)数据集,专门设计用于评估模型在类条件生成任务中的性能。该合成数据集包含分布在 60 个类别中的 120,000 个 CAD 模型。
2) CADParser [16]
与 SolidGen 并行,CADParser 被引入,用于从给定的 B-Rep CAD 模型预测 CAD 命令序列。与先前通常使用合成 CAD 数据集或依赖 DeepCAD 和 Fusion 360 reconstruction 等数据集(这些数据集仅限于仅使用两种操作(即草图和拉伸)创建的 CAD 模型)的方法不同,CADParser 引入了一个包含 40,000 个 CAD 模型的综合数据集。这些模型包含了更广泛的 CAD 操作,包括草图、拉伸、旋转、圆角和倒角。与先前仅限于两种操作的数据集相比,该数据集提供了更多样化的 CAD 模型集合,这些模型使用五种不同类型的 CAD 操作构建。该数据集中的每个 CAD 模型都附有 B-Rep 数据和相应的构建命令序列。
CADParser 还引入了一种称为深度解析器的深度神经网络架构,旨在为每个 B-Rep 模型预测 CAD 构建序列。受 UV-Net 和 BRepNet(均在 Sec. IV 中作为 B-Rep 数据表示学习的开创性方法讨论)的启发,CADParser 将每个 CAD 模型视为一个图 G = (V, E),其中节点表示模型的面、边和 coedge,E 表示图节点之间的连接。BRepNet 架构作为图编码器主干,接收节点特征和构建的邻接矩阵作为输入,并通过图卷积和拓扑行走提取图的局部和全局特征。同时,构建 CAD 模型的 CAD 命令序列 S = (C_1, C_2, …, C_n) 被编码为特征向量。这些与图编码的全局和局部特征相结合,被馈送到 Transformer 解码器中,以自回归地预测下一个命令序列。与先前的方法类似,CAD 命令通过将每个命令 C_i 表示为命令类型 t_i 和命令参数 p_i 的元组来进行 token 化。t_i 被编码为一个 12 维 one-hot 向量,一次表示 12 种不同的命令类型之一,p_i 是一个 257 维向量。该向量表示命令的量化 256 维参数向量和一个 1 维索引,指示此命令是否用于相应的 CAD 模型。为简单起见,所有 CAD 模型的 CAD 命令序列长度固定为 32,每个 CAD 模型未使用的命令通过设置为 -1 的索引指示。Transformer 解码器有两个独立的输出分支,分别用于预测 CAD 命令类型 t_i 和参数 p_i 向量。有关模型架构和训练过程的更多详细信息,可以在 [16] 中找到。这项工作的贡献代表了通过合并各种 CAD 命令生成更多样化 CAD 模型的一步。
3) BRepGen [33]
BRepGen [33] 引入了一种基于扩散的生成模型,直接合成完整的 B-Rep CAD 模型,解决了先前方法(如 SolidGen)通常缺乏几何表现力且难以保证拓扑有效性的局限性。BRepGen 放弃了 SolidGen 中使用的自回归建模,而是采用了一种结构化的潜在几何表示,其中整个 B-Rep 组织为一个层次树:实体包含面,面包含边,边包含顶点。该树中的每个节点都包括拓扑和几何特征,这些特征通过潜在嵌入进行编码。
BRepGen 的一个关键创新是其处理拓扑的方法。它不显式生成邻接矩阵,而是在树的分支之间复制拓扑元素,并通过合并等效节点来重建水密实体。这种隐式处理简化了生成过程,但依赖于事后合并,这有时可能导致不一致或自交。在几何方面,BRepGen 通过 UV 采样的曲面和曲线点云编码几何来支持曲面和自由曲面。这些通过变分自编码器(VAE)进行压缩,允许比 SolidGen(仅限于平面和圆柱等简单曲面)更紧凑地表示复杂几何。几何的每个部分(顶点、边和面)都通过单独的去噪扩散模型生成,从而实现富有表现力和可控的形状合成。
BRepGen 在 DeepCAD 和 ABC 数据集上展示了高性能,在几何完整性(例如 Chamfer 距离)、唯一性、新颖性和拓扑有效性方面均优于 DeepCAD 基于草图的方法和 SolidGen。它还支持条件生成任务,如形状插值和类别引导合成。然而,对潜在几何编码和隐式拓扑推断的依赖引入了一些局限性,例如可解释性降低和对成功合并重复元素的依赖性。这些局限性由后续方法 DTGBreGen [34] 解决,该方法显式地解耦拓扑和几何生成,以确保结构一致性并提高对合成过程的控制。
4) DTGBreGen [34]
DTGBreGen [34] 建立在 BRepGen [33] 的优势之上,通过解决其关键局限性,特别是隐式和事后处理 B-Rep 拓扑的问题。DTGBreGen 没有在潜在树结构内联合建模几何和拓扑,而是引入了拓扑和几何的原则性解耦,分为两个独立的阶段,从而产生更高的结构有效性和更准确的几何输出。
DTGBreGen 的第一阶段完全专注于拓扑生成,使用两个基于 Transformer 的编码器-解码器网络构建有效的边-面和边-顶点邻接矩阵。此步骤确保符合基本的拓扑约束,例如每条边连接两个不同的顶点,并在每个面内形成闭合环。与 BRepGen 通过合并重复节点间接推断这些关系不同,DTGBreGen 以受控方式显式生成它们。一旦生成了有效的拓扑结构,管道的第二阶段使用基于 Transformer 的扩散模型顺序生成几何属性:顶点坐标、边曲线和面曲面。几何使用三次和双三次 B-样条表示,从而能够对复杂的曲线和曲面进行数学精确建模。这种选择避免了使用 BrepGen 中使用的曲面采样和基于点云的编码器,提高了完整性和可解释性。
DTGBrepGen 在多个基准测试中取得了优越的性能,例如在 DeepCAD 和 ABC 数据集上。它还支持类条件和点云条件生成,展示了其跨设计任务的泛化能力。通过首先生成有效的拓扑并以它们为条件生成几何,DTGBrepGen 生成具有更准确和可编辑几何的水密、结构一致的 CAD 模型。这种模块化设计还增强了可解释性,并为未来涉及层次建模或与语义约束集成的扩展奠定了基础。
E. 从点云生成 3D CAD
正如现有 3D CAD 生成模型的概述中所强调的,CAD 形状的逆向工程主要通过使用 CAD 草图、B-Rep 数据或 CAD 命令序列作为输入的方法进行探索。这些方法在重建和生成 CAD 模型方面取得了有希望的进展。然而,同样关键的一个方面是从替代的原始几何数据模态(如点云)生成 CAD 数据。这一考虑也与 DeepCAD 方法概述的未来工作一致。将不同的数据表示无缝转换为 CAD 模型的能力为现实世界的应用开辟了新的途径,弥合了不同数据模态之间的差距,并扩展了 CAD 技术的实用性。这在需要物理对象的新变体或修复没有相应 CAD 模型的机械对象时变得尤为重要,特别是当对象早于数字制造时代时。在这些情况下,该过程通常从使用 3D 传感器扫描对象开始,生成点云。随后,获得的点云数据需要分解为一组几何基元(如曲线或曲面),以便由 CAD 软件解释。传统的三步过程 [121] 包括将点云转换为网格,通过参数化曲面解释它以创建实体(B-Rep),并推断 CAD 程序。最近将基元拟合到点云的进展 [122-124] 已经设法绕过了将点云转换为网格的初始步骤。然而,这些方法的一个显著局限性是它们依赖于一组有限的、固定的和不相交的基元,这对后续步骤中的方便形状编辑构成了挑战。为了解决这个问题,最近提出的 Point2Cyl [35] 方法将问题框定为挤出圆柱分解任务,利用神经网络预测逐点挤出实例、曲面法向以及基面/桶面成员关系。然后,这些几何代理可以通过可微和闭式公式用于估计挤出参数。在该方法中,挤出圆柱被认为是一个基本基元,表示一个挤出的 2D 草图,由挤出轴、中心、草图和草图比例等参数表征,可用于表示 3D CAD 模型。术语基面和桶面用于表示挤出圆柱的特定曲面,分别代表挤出圆柱的基面/顶面和侧面。
Point2Cyl 利用 PointNet++ [8] 学习点云特征嵌入,然后将其传递到两个不同的全连接网络中,用于将点云分割为挤出圆柱、基面/桶面和曲面法向预测。该方法在 Fusion Gallery 和 DeepCAD 数据集上进行了评估,优于基线,并展示了其在重建和形状编辑中的有效性。该方法的代码已公开可用。
然而,值得注意的是,该方法在输入数据无噪声或未失真的情况下处理能力有限。从嘈杂的点云数据重建棱柱形 3D 形状中的尖锐边缘和曲面变得具有挑战性,因为点云本质上仅提供 3D 形状的近似表示。当处理通过低成本扫描仪获取的点云时,这一挑战尤为突出,因为形状中的任何失真或不规则性都可能通过表面重建过程中的平滑处理来解决。Lambourne 等人 [36] 在与 Point2Cyl 同期提出了一种方法,解决了当提供近似圆角(平滑)点云时重建尖锐棱柱形状的挑战。该方法引入了一个可微分的管道,以体素形式重建目标形状,同时提取几何参数。训练一个自编码器网络处理表示为体素网格的有符号距离函数,该函数通过将密集点云转换为有符号距离函数的方法获得 [125, 126]。编码器生成一个嵌入向量,解码器进一步将形状分解为 2D 轮廓图像和 1D 包络数组。在推理过程中,通过搜索 2D 约束草图的存储库,拉伸它们,并通过布尔操作组合它们以构建最终的 CAD 模型来生成 CAD 数据。在 ABC 数据集上的评估表明,与 DeepCAD 方法相比,该方法能够更好地逼近目标形状。
与之前两项工作同期,ComplexGen [37] 引入了一种新方法 ComplexNet,用于从点云直接生成 B-Rep 数据。该方法将重建任务重新框定为几何基元及其相互连接的整体检测,封装在一个链复形结构中。ComplexNet 作为一种神经网络架构,利用稀疏 CNN 嵌入点云特征,并利用三路径 Transformer 解码器生成三组不同的几何基元及其定义为邻接矩阵的相互关系。随后,一个全局优化步骤将预测的概率结构细化为确定的 B-Rep 链复形,同时考虑结构有效性约束和几何细化。在 ABC 数据集上的大量实验证明了该方法在生成结构完整且准确的 CAD B-Rep 模型方面的有效性。
最近,Ma 等人 [38] 提出了一种使用多模态扩散模型从点云重建 CAD 程序的新方法。与先前专注于几何基元或 B-Rep 结构的方法不同,该方法对 CAD 操作和草图进行 token 化,从而能够生成可编辑的 CAD 构建序列。通过基于体积的扩散过程,它逐步重建类似人类的设计步骤,桥接了原始 3D 数据和结构化 CAD 工作流。这项工作通过将抽象层次从几何提升到程序化建模,补充了先前的工作,使其特别适用于交互式逆向工程任务。
F. 从图像生成 3D CAD
虽然前四类中讨论的 CAD 生成方法依赖于结构化输入,如草图、点云或构建序列,但最近的进展探索了直接从非结构化的 RGB 图像生成 CAD 模型。这些方法试图推断结构化的、可编辑的 CAD 表示(如 B-Rep),从单视图或多视图图像中。这一新方向弥合了 2D 视觉理解与 3D 建模之间的差距,在逆向工程、工业检测和从照片进行概念设计等领域实现了应用。
CADDreamer [39] 提出了一个管道,从单视图 RGB 图像重建结构化的、水密的 B-Rep CAD 模型。与产生网格或体素的传统 3D 重建管道不同,CADDreamer 通过将基元感知扩散模型与几何优化相结合,直接针对 CAD 适用的表示。该方法的核心思想是首先使用多视图扩散模型生成法向图和语义基元分割图(覆盖平面、圆柱、圆锥、球体和特征曲线)。然后,这些图在虚拟视图之间融合,以构建物体的多曲面表示。一个可微分渲染器随后从法向图估计粗略网格,而基元图指导分割和基于图割的修补。然后系统执行基元拟合和拓扑修剪,以重建具有尖锐特征和语义结构的有效且可编辑的 B-Rep。该方法的主要优点是能够对单视图 RGB 输入进行操作,消除了对显式几何感测的需求,同时产生紧凑且可编辑的 B-Rep 模型。然而,其重建质量依赖于准确的分割和基元拟合,并且该方法目前缺乏对参数化设计历史和用户引导编辑的支持。
CADCrafter [40] 解决了相同的图像到 CAD 问题,但不是直接生成几何模型,而是专注于恢复可以导入 CAD 软件(如 Fusion360)的 CAD 构建序列(例如,草图和拉伸)。这种方法反映了现实世界的设计工作流,并实现了完全可编辑、参数化的输出。该方法使用一个几何条件的潜在扩散 Transformer,生成一个 CAD token 序列,然后将其解码为构建命令。条件通过一个几何编码器实现,该编码器被训练为纹理不变的,使用从输入图像导出的估计深度和法向图。这有助于弥合合成 CAD 渲染(在训练期间使用)和现实世界、无约束图像之间的领域差距。为了提高正确性,CADCrafter 集成了一个代码检查模块,用于编译和验证生成的 CAD 命令。此外,它引入了一个新的 RealCAD 数据集,其中包含与命令序列配对的真实世界图像,从而实现更好的泛化。CADCrafter 的主要优点是能够在现实世界、无约束的图像上操作,支持单视图和多视图输入。由于其基于几何的条件,它在领域迁移下展示了强大的性能,并且使用了偏好优化。然而,该方法目前仅限于草图和拉伸工作流,尚不支持更复杂或高级的 CAD 操作。
CADDreamer 和 CADCrafter 展示了深度生成模型如何通过解释视觉内容来自动化参数化建模任务,产生既人类可读又机器可执行的 CAD 输出。
VI. 讨论与未来工作
尽管几何深度学习(GDL)方法在分析 CAD 模型和自动化不同层次的设计过程方面取得了显著进展,但该领域仍然存在若干挑战。在本节中,我们将讨论其中一些挑战,并提出应对这些挑战的潜在未来研究方向。
A. 数据集缺乏多样性
现实世界产品设计中使用的许多 CAD 模型受知识产权(IP)保护,无法公开共享。这一限制严重限制了 CAD 数据集的可用性、多样性和规模,给依赖大规模多样数据的机器学习模型训练带来了挑战。因此,研究人员通常需要使用合成或公开发布的数据集,这些数据集可能无法完全捕捉真实世界设计的复杂性。
B. 带标注的 B-Rep 数据有限
尽管近年来发布了一些包含 B-Rep 格式以及传统 3D 数据格式的大规模 CAD 数据集,但用于监督学习方法的带标注数据集仍然存在相当大的需求。为 CAD 模型分类标注的数据集规模仍然有限,缺乏全面分析 CAD 模型所需的多样性和复杂性。虽然存在用于常见物体 CAD 形状的大规模标注数据集(如 ShapeNet [71]),但这些数据集仅以网格格式提供。因此,只有当使用网格或点云数据而非 B-Rep 时,才能将知识从常见物体数据集迁移到机械数据集。另一方面,标注机械 CAD 模型具有挑战性,需要领域专业知识来识别机械物体的类型、功能或其他属性。由于不同行业对这些物体使用的术语不同,专家标注可能会出现不一致。类似的挑战也存在于为不同面分割而标注的 CAD 数据集中。如表 3 所示,这方面有几个标注数据集,具有不同类型的标注,例如不同面的制造方式或用于构建每个面的 CAD 操作。这些数据集的曲面类型缺乏共享的类别,使得使用迁移学习或领域泛化方法将学习到的特征从一个数据集转移到另一个数据集变得困难。该领域需要更大规模的数据集,如扩展 MFCAD 数据集的 MFCAD++,并提供不同类型的标注。收集提供多种数据格式(包括网格、点云和 B-Rep)、具有不同复杂度的各种 CAD 模型,并为不同任务(如 CAD 分类和分割)进行标注的大规模 CAD 数据集,将对该领域的未来研究和发展做出重大贡献。
C. 复杂 CAD 装配体的分析
现有分析 CAD 装配体的工作专注于如何连接简单零件(实体),预测接合的坐标和连接方向。一个未来的研究方向可能是考虑如何将多个实体层次化地装配以形成更复杂的 CAD 模型,或者如何连接两个子装配体(每个子装配体包含多个零件(实体))以形成更大的装配体。然而,现有数据集并未针对此类应用进行标注,因为默认情况下 B-Rep 数据中没有明确指定不同零件之间的接合。AutoMate 和 Fusion 360 Assembly-Joint 数据集是专门为其对应方法 [18, 19] 标注的。分析复杂 CAD 装配体的另一个未解决问题是如何将每个装配体分割为不同级别的构建块(子装配体或零件(实体))。学习如何用存储库中的另一个零件替换装配体中的一个零件,同时考虑其与所有其他零件的连接、其复杂性、功能、材料等,将是自动化 CAD 模型定制过程的一大优势。为此目标标注数据集也是必要的。
D. B-Rep 数据的表示学习
在 B-Rep 数据上训练深度学习模型的第一步也是最关键的一步,是创建适合深度学习架构格式的数值特征表示。许多用于 CAD 分类和分割的方法,特别是基于 UV-Net 的方法,使用 UV 网格采样。然而,UV 网格特征缺乏置换不变性。换句话说,当 CAD 实体表示为面邻接图时,图中节点的排列对于深度学习模型识别图结构及其与其他图(或 CAD 实体)的相似性至关重要,而具有不同节点排列的两个图可能仍然是相似的。因此,探索 B-Rep 图的各种不变性以及在其结构化格式中表示数据的替代方法,同时考虑实体面和边的相对方向,为未来的研究提供了希望。
E. 无监督和自监督方法
鉴于用于监督学习的带标注 CAD 数据的短缺,利用大规模数据集(如 ABC)来增强自监督和/或无监督方法具有巨大潜力。例如,UV-Net 利用图对比学习(GCL)进行自监督学习,而 [13] 探索了形状栅格化以从数据中获取自监督来训练自编码器,并将解码器用于其他监督任务。研究 CAD 数据中各种形式的自监督以训练自编码器或图自编码器将是引人入胜的。在 GCL 方法中检查和评估不同的图变换,以理解 B-Rep 图的局部和全局结构,同时保持各种不变性,是未来研究的一个重要方向。此外,专注于用于 B-Rep 数据直接合成的变分自编码器,从与现有形状相同的分布中生成有意义的新形状,将增强相似性分析和 CAD 检索。
F. CAD 生成与 B-Rep 合成
当前用于 CAD 命令的生成方法通常专注于有限的操作集(如草图和拉伸),限制了所得 CAD 模型的复杂性和多样性。值得注意的是,在某些方法(如 DeepCAD [17])中,不能保证所有生成的 CAD 命令序列都能产生拓扑有效的 CAD 模型,尤其是在具有长命令序列的复杂模型的情况下。因此,未来探索的一个方向是将生成方法扩展到涵盖更广泛的 CAD 操作(如圆角和倒角),从而能够为更复杂的 CAD 形状生成命令序列。此外,像 SolidGen [15] 和 CADParser [16] 这些直接专注于合成 B-Rep 数据而不依赖 CAD 命令序列的方法的进步,标志着一个有前途的方向。尽管取得了这些进展,但该领域仍有创造力和改进的空间。另一个未来的研究方向是将生成方法扩展到从其他 3D 数据格式(如网格、体素和点云)生成 CAD 构建操作或 B-Rep 合成。在将点云转换为 CAD 模型方面的最新进展(在第 V-E 节中描述)为跨不同数据领域迁移知识开辟了可能性。此外,从噪声扫描或手绘草图生成 3D CAD 模型在 CAD 工具中具有很高的需求,并且呈现出显著的改进潜力。尽管在该领域已经引入了一些方法,但缺乏成对的草图和 B-Rep 数据集使得目前训练监督学习方法不可行。例如,SketchGraphs 中的草图和 ABC 数据集中的 3D 模型都是从 Onshape 存储库收集的。然而,这两个数据集中的 2D 和 3D 模型并未配对。收集这样的配对数据集将极大地有助于未来的研究。
G. 制造感知与仿真就绪的几何理解
尽管在形状分类、生成设计和参数化建模等任务的 GDL 方面取得了显著进展,但下游工程应用,如面向制造的设计(DFM)、仿真就绪的 B-Rep 修复和工程约束求解,仍然相对未被充分探索。这些任务对于弥合 CAD 设计与现实世界部署之间的差距至关重要,然而当前 GDL 研究的重点往往忽略了它们。大多数现有工作依赖传统的基于规则或物理驱动的方法来评估可制造性或准备用于仿真的几何体。然而,B-Rep 数据的结构化、语义丰富特性,结合大规模工业存储库,为深度学习模型学习可制造性启发式、预测约束违规甚至自主修复妨碍网格划分或分析的几何缺陷提供了机会。未来的研究可以建立在基于 B-Rep 的 GDL 模型的基础上,针对这些高影响力的工程任务。例如,基于学习的 DFM 检查器可以在设计过程中提供实时反馈;基于学习的修复模型可以自动修复用于仿真的非流形或噪声 CAD 模型;约束预测模型可以支持遗留几何的逆向工程或在生成系统中强制执行设计意图。开发此类系统不仅需要算法进步,还需要基准数据集、真实标注以及与制造和仿真专家的更紧密合作。
H. 可重复性
在该领域,一个显著的挑战在于复现和比较不同方法的实验结果。缺乏大规模的标注基准数据集导致每个提出的基于机器学习的 CAD 分析方法要么引入一个针对特定任务定制的新标注 CAD 数据集,要么修改和标注大规模数据集的一部分用于评估。在这些较小数据集上训练的监督方法通常表现出很高的性能,几乎没有改进的空间。此外,由于每种方法都在为其特定任务调整的数据集上进行基准测试,比较结果变得复杂。例如,在分析 [13] 中在 Fusion 360 分割数据集的子集上评估的不同方法的结果时,不清楚每种方法使用了数据集的哪一部分进行评估。当研究人员不发布他们预处理的数据或没有提供清晰的预处理说明时,复现不同方法的结果和进行性能比较变得尤其具有挑战性。复现研究结果的另一个障碍是代码依赖于非开源的 CAD 内核。例如,复现 AutoMate [19] 的结果需要安装 Parasolid 内核,该内核通常仅对工业开发者和公司可访问。这种有限的可用性使得独立学术研究人员难以利用和构建此类研究工作。虽然依赖于开源 OpenCASCADE 内核的代码更容易获得,但该领域的许多方法要么在训练期间通过 CAD 工具使用约束求解器,要么以某种方式依赖于 CAD 工具内核,因此需要访问和许可至少一个 CAD 软件。为了解决这些问题,强烈建议研究人员为其发布的代码提供全面的文档,详细说明数据预处理设置,并提供关于实验设置和代码依赖性的充分信息。这种透明度可以极大地促进该领域未来的研究工作。
总之,尽管用于 CAD 分析和生成的 GDL 最近取得了进展,但仍然存在几个关键挑战。这些挑战包括数据集多样性有限、缺乏带标注的 B-Rep 数据、处理复杂装配体的困难以及可重复性问题。许多方法依赖专有软件或私有数据集,使得复现结果或建立公平基准变得困难,并且跨任务使用非重叠数据集进一步限制了直接可比性。这些限制也为未来的研究提供了大量机会,例如开发可扩展的表示学习、推进自监督方法、设计更丰富的生成模型以及桥接 CAD 与制造和仿真任务。解决这些方向对于实现鲁棒、智能和自动化就绪的 CAD 系统至关重要。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 14
14 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)