Matlab也能实现扩散模型了?
目录
传统的机器学习创新方法无非是优化算法+模型组合,但是,如果你不会改进算法,或者使用比较新颖的模型,这种方法已经比较难发论文了。
同时,这段时间后台也经常有小伙伴问我,在数据生成部分有没有一些比较好的创新方法。但是,目前大多数数据生成的方法都是基于Python,无法很好地和自己的优化算法结合。而且,Python环境配置较为混乱,不适合新手小白。
因此,今天给大家带来一期基于Matlab实现扩散模型数据生成的方法。与之前的代码一样,都是一键运行即可生成,同时,也附赠LSSVM模型作为回归预测模型,方便小伙伴们查看误差指标。
这样一来,结合扩散模型-优化算法-预测模型三阶段的预测范式,不仅可以让审稿人眼前一亮,也能大大提高Accept的概率,更不会有创新点不足的烦恼。
需要完整代码的朋友可直接拉到最后~
您只需做的工作:替换Excel数据,一键运行main文件!非常适合新手小白!
原理简介
首先用通俗易懂的语言来介绍下扩散模型。
扩散模型是一种数据生成技术,它模拟自然界中常见的扩散过程来合成新数据。就像一滴墨水落在水中会慢慢扩散开来一样,扩散模型也是从简单的噪声信号出发,逐步添加细节和模式,最终生成复杂的新数据。研究人员发现,把这个过程倒过来运行,先由复杂数据开始,逐步移除细节,最后留下简单随机噪声,反过来再运行一次,就可以重新生成新的数据。

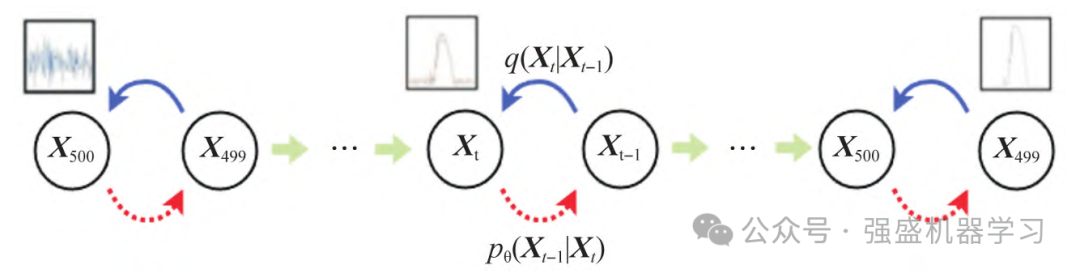
从写论文的角度来讲,扩散概率模型(DDPM)的核心工作机制包含两个过程:前向加噪过程和反向去噪过程,如下图所示。图中,蓝色箭头表示前向过程(q),红色箭头表示反向过程(p)。前向过程为扩散过程,通过逐步向原始数据中添加高斯噪声,将原始数据样本转化为纯噪声。反向过程的目标是从噪声样本中逐步去除噪声,最终重建原始数据样本。前向过程是预定义的,反向过程则需要训练模型学习如何去除噪声。
如果想在论文里阐述这个模型,可以参考这篇文献:
[1]杨健一,张亦涵,汪华,等.基于生成式扩散模型的短期多步太阳辐照度预测[J].中国计量大学学报, 2025, 36(3):402-410.
案例数据及数据替换方法
与先前回归模型采用的数据集一样,本期依旧采用经典的回归预测数据集,也是为了方便大家替换自己的数据集,各个变量采用特征1、特征2…表示,无实际含义,最后一列即为输出。
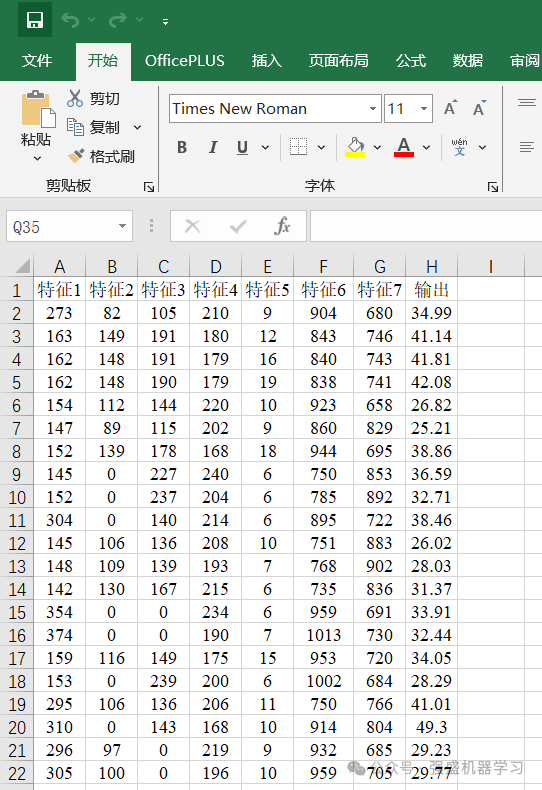
更换自己的数据时,只需最后一列放想要预测的列,其余列放特征即可(特征数量不限),无需更改代码,非常方便!
结果展示
在这里,我们采用基于 DDPM 架构的数据增强方法,也就是在生成阶段,模型从标准高斯噪声采样,利用训练好的网络逐步去除噪声,最终恢复出具有原始数据统计特征的合成样本。在网络结构方面,采用一个包含 3个隐藏层的全连接神经网络,并引入 0.1 的 Dropout 以防止过拟合。
在参数设置方面,我们设定扩散过程为 1000 个时间步,采用10^-4到 0.02的线性噪声调度。最大迭代次数为 50,批量大小为 512。
同时,我们在模型最后采用LSSVM回归作为预测模型。废话不多说,看下效果:
首先是数据生成前后的直方图对比:
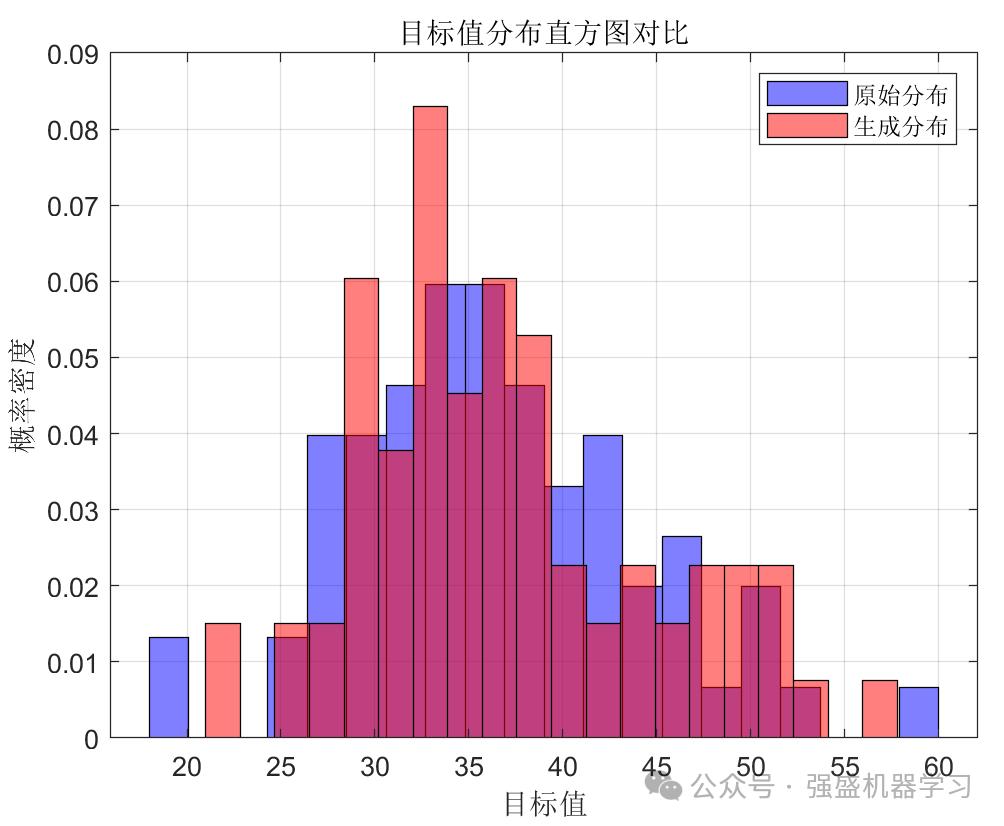
同时,为了更方便地查看数据生成前后的分布,我们利用t-SNE降维可视化查看数据生成前后的分布对比:
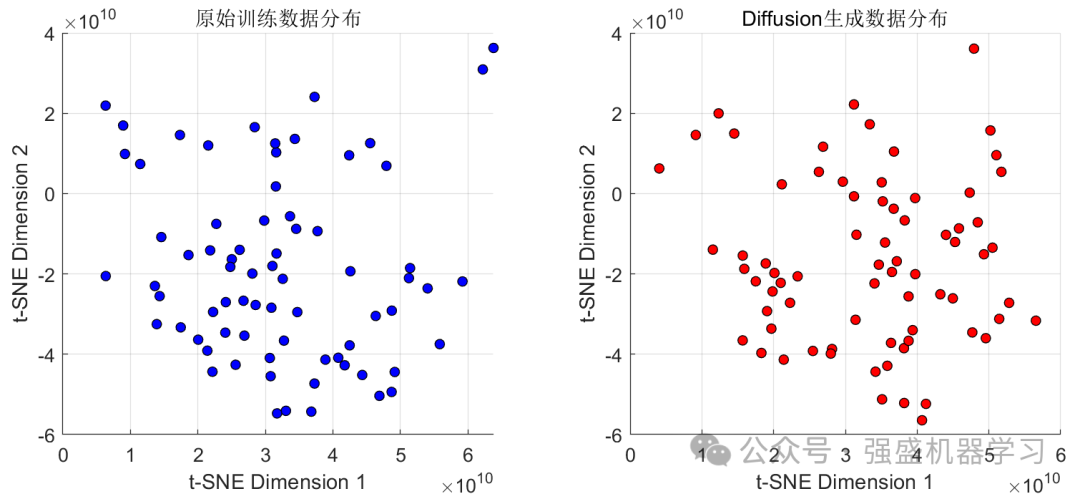
综上两张图可以看到,两个分布非常接近。当然,为了防止信息泄露,我们的数据生成肯定是针对训练集进行的,命令行窗口也会生成相关信息:

扩散模型的网络结构图:
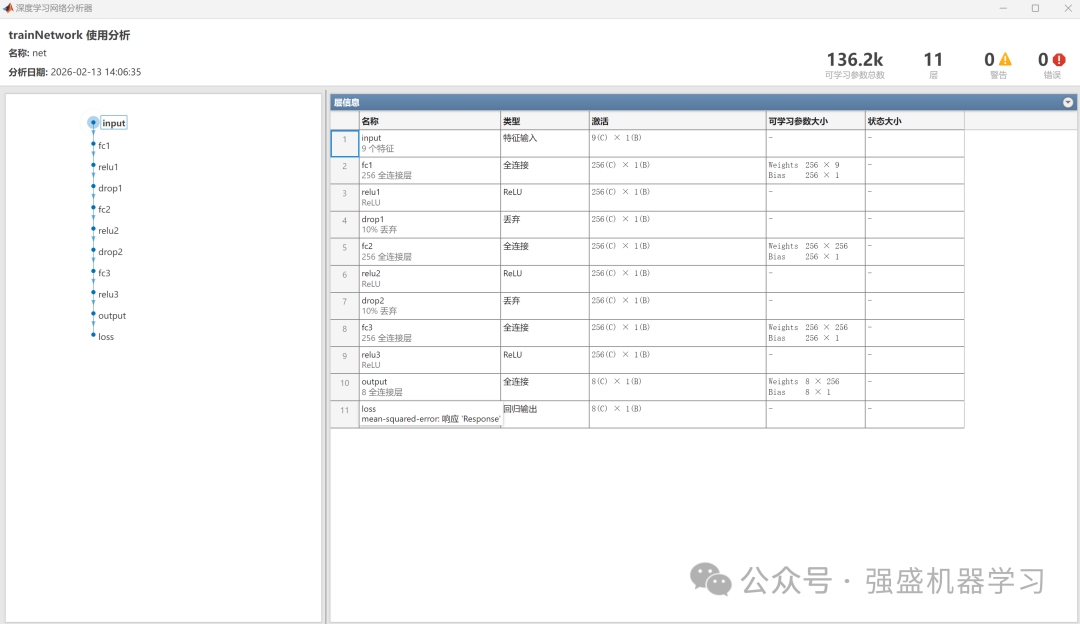
接下来是预测模型的结果:
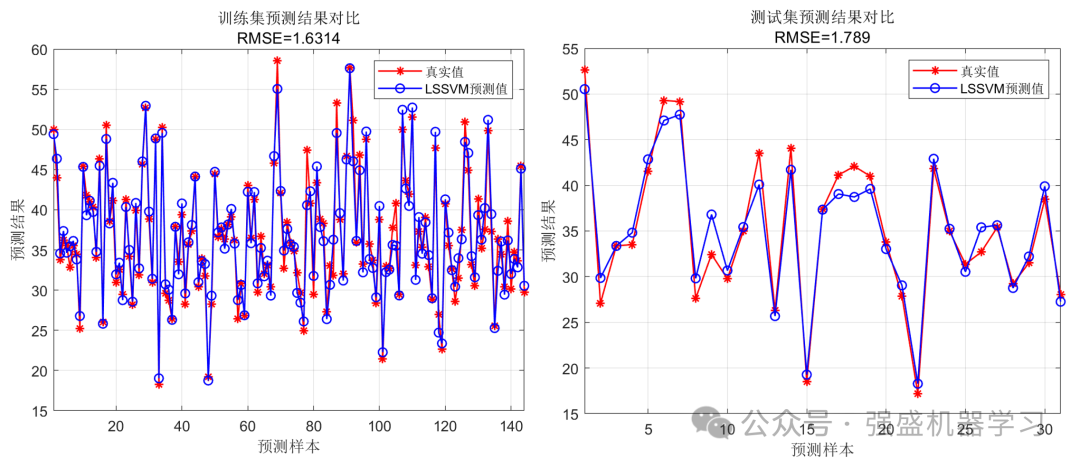
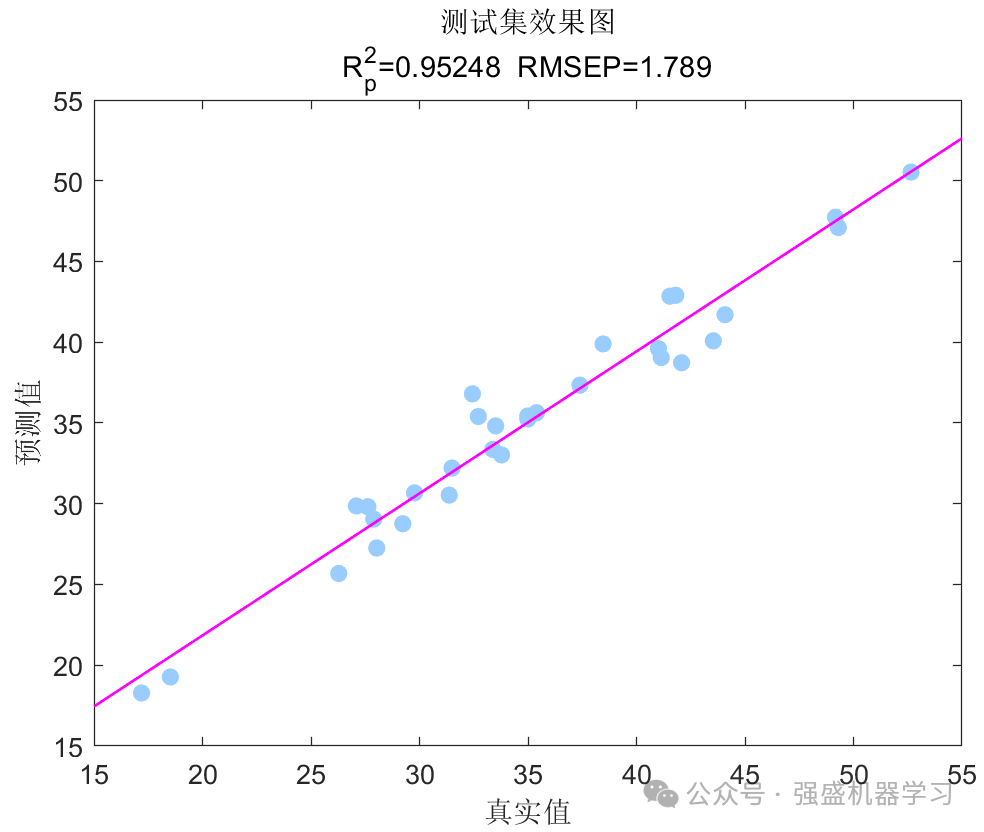
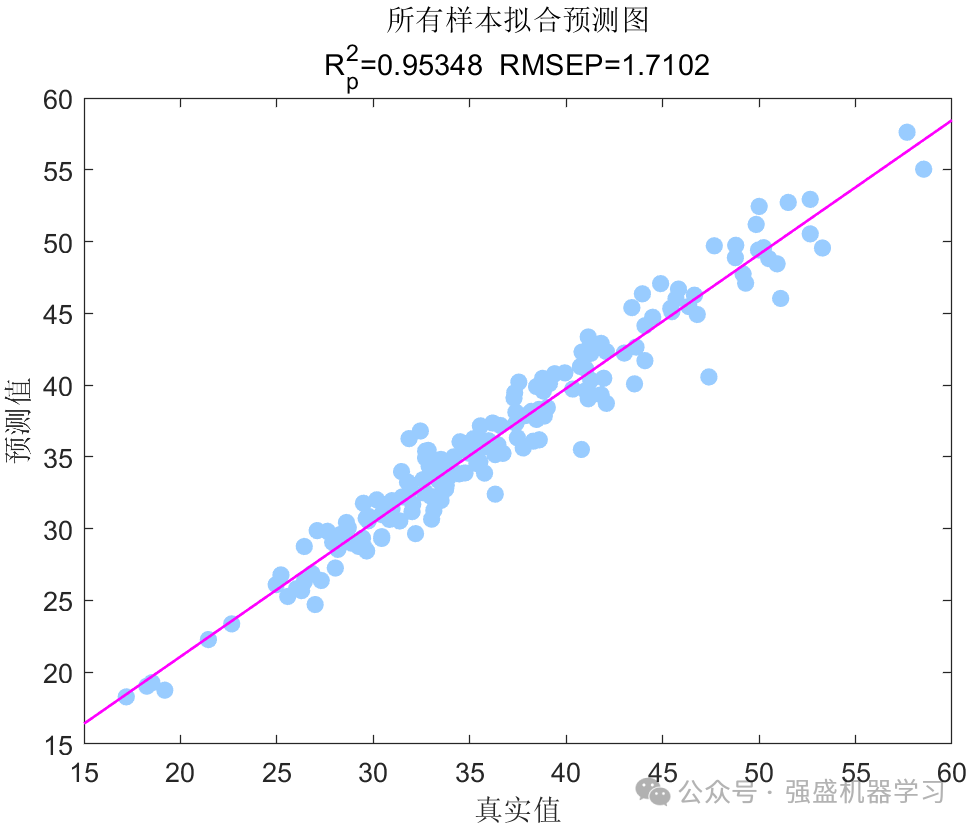
训练集和测试集预测效果图:
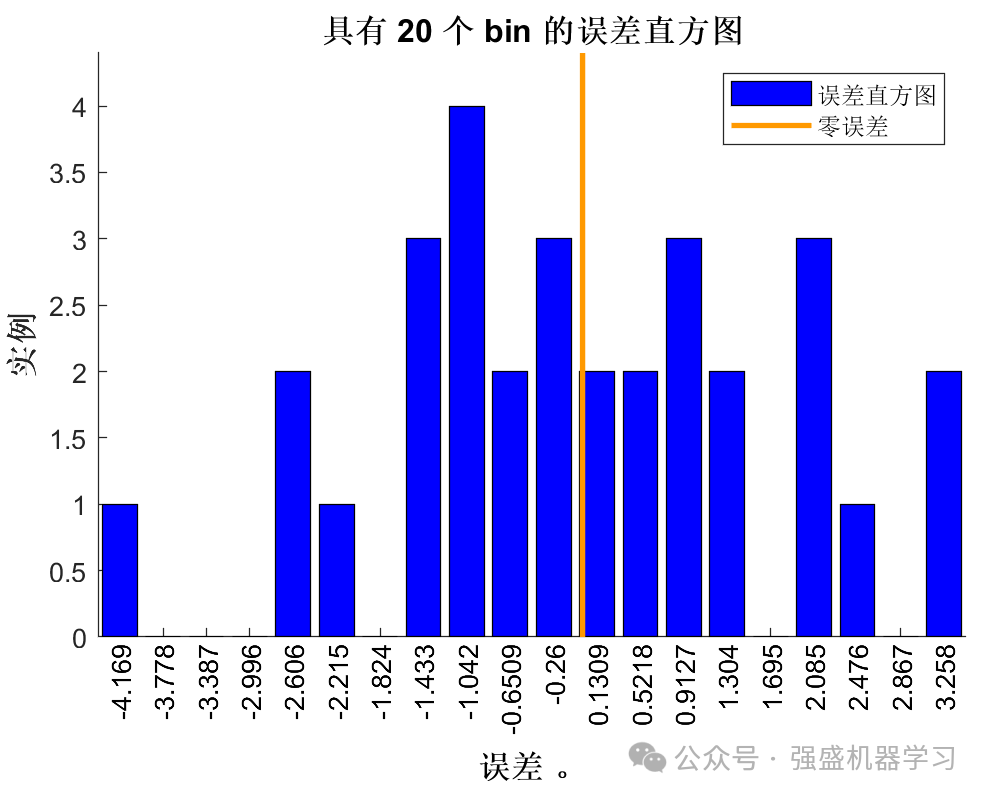
误差直方图:
3张(训练集、测试集、所有样本)线性拟合图:
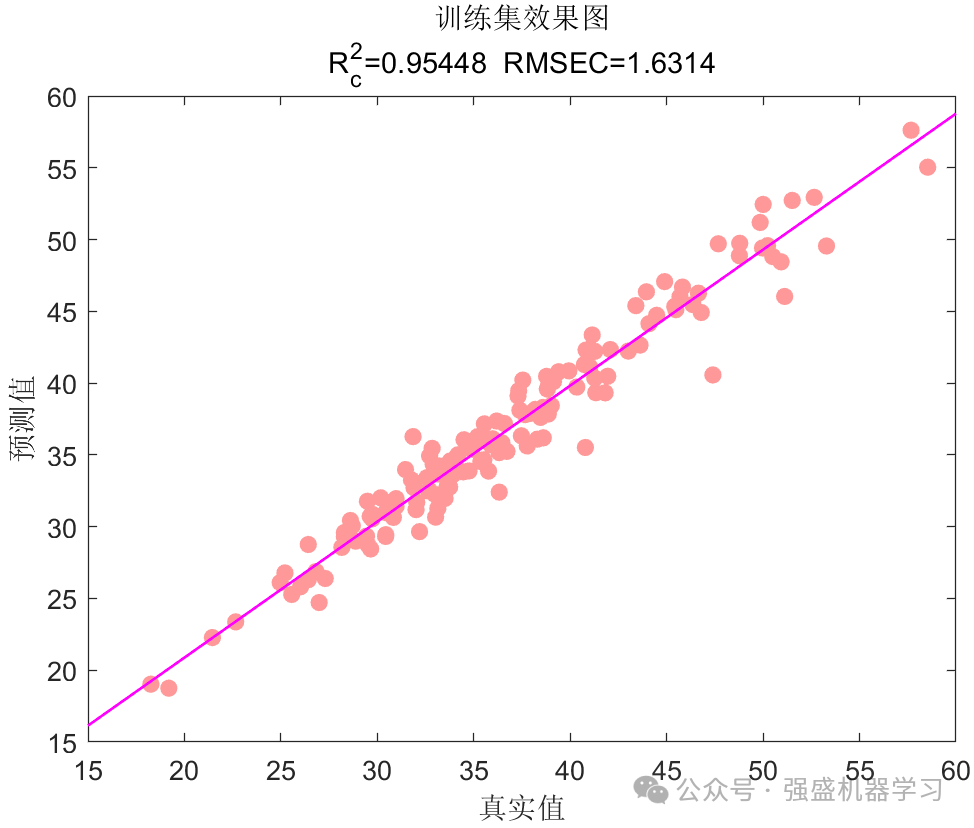
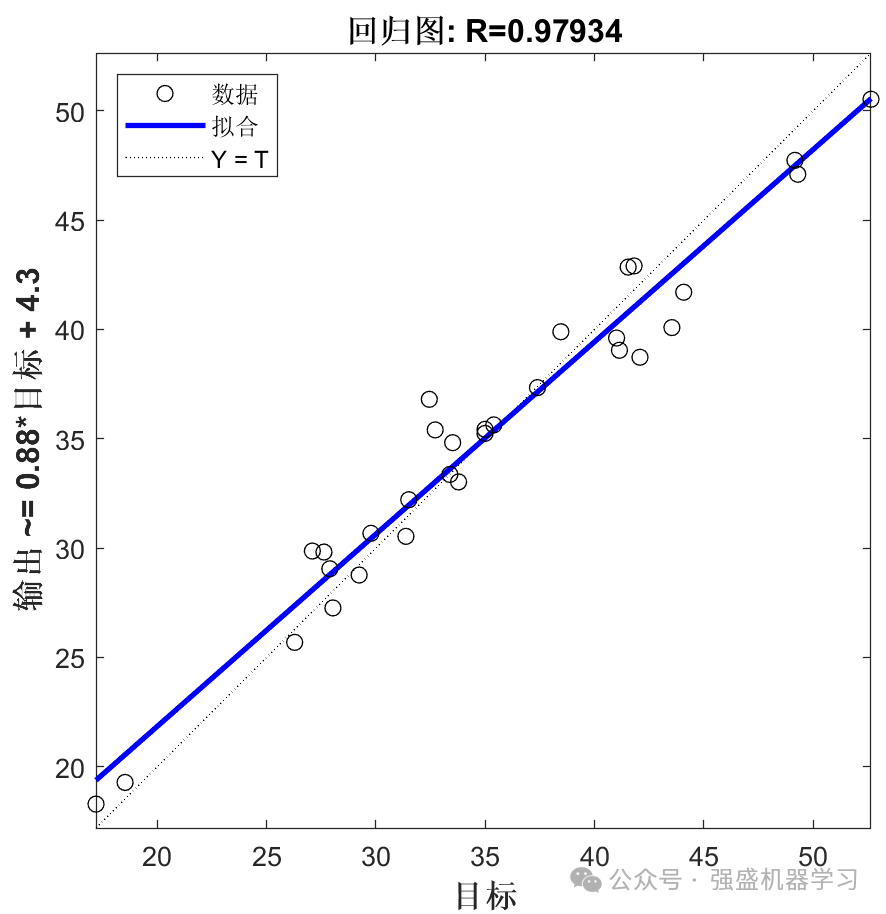
回归拟合图:
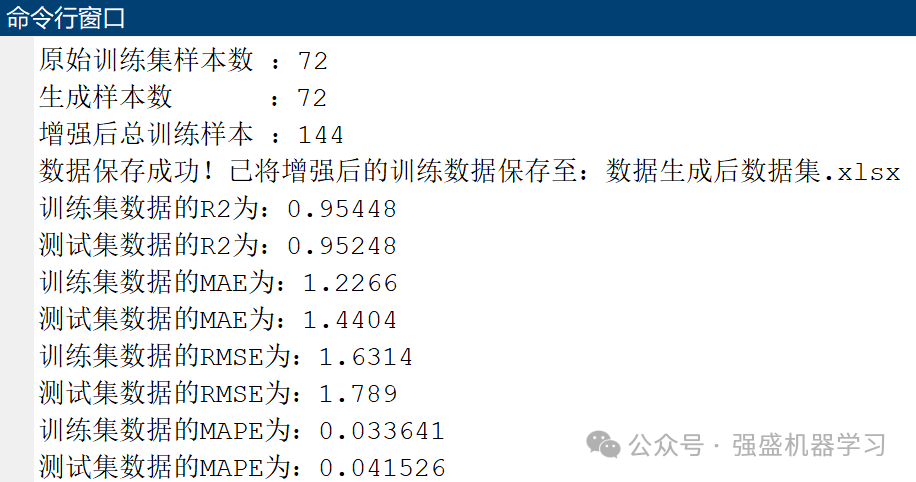
运行完毕后,命令行窗口也会显示各个误差指标的结果,非常清晰:
另外,我们的程序文件夹内也非常清晰,您所需运行的文件只有main一个,非常方便!不信可以看下面截图!
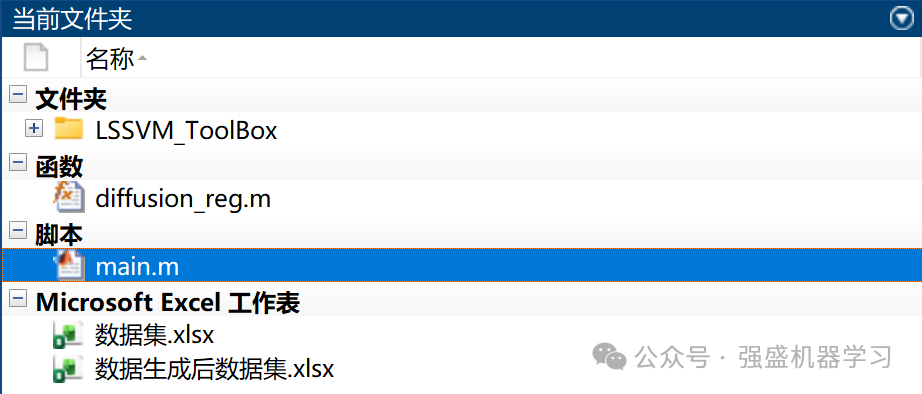
以上所有图片,替换Excel后均可一键运行main生成,无需配置环境!比Python什么方便多了!非常适合新手小白!
完整代码获取
如果需要以上完整代码,只需点击下方小卡片,再后台回复关键字,不区分大小写:
扩散模型

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 19
19 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)