从“识别目标”到“控制目标”:3D Spatial Agent 的范式革命——当行业还在“看见谁”,镜像视界已经开始“理解他在哪里、要去哪、该如何控制”

一、真正的分水岭,从来不是识别精度,而是控制能力
过去很多年,视频智能行业一直在做一件事:
识别目标。
人脸识别、人体识别、车辆识别、ReID、属性识别、行为识别……
技术名词越来越多,模型越来越大,参数越来越复杂,宣传也越来越震撼。
但一个最根本的问题,始终没有被真正解决:
识别目标,不等于掌控目标。
你知道他是谁,不代表你知道他在哪。
你知道他出现过,不代表你知道他从哪里来、经过哪里、接下来会往哪去。
你能在某一个摄像头里框住他,不代表你能够在整个真实世界里持续掌握他。
这就是今天绝大多数视频系统的共同困境:
它们会“认”,
却不会“控”。
它们能输出标签,
却不能形成空间级闭环。
它们可以告诉你“这个人出现了”,
却无法告诉你“这个人此刻在真实空间中的连续位置、轨迹趋势、可达路径与最优控制点”。
所以,行业的核心矛盾从来不是“识别能力够不够强”,
而是:
视频系统究竟是在猜目标,还是在控制目标。
而这,正是 3D Spatial Agent(三维空间智能体) 出现的意义。
二、为什么“识别目标”这条路,注定走不到终局
今天大量系统之所以看起来“智能”,只是因为它们在二维图像平面上做了大量分类与匹配工作。
它们的典型逻辑是:
- 看见一个人
- 提取外观特征
- 生成向量
- 在其他摄像头里进行匹配
- 依靠概率判断“可能是同一个人”
这条路径在演示中很好看,在实验室里也能拿到不错指标,
但一旦进入真实复杂场景,就会迅速暴露结构性缺陷。
1. 它依赖外观,而不是依赖空间真实
衣服相似、身形接近、背影重叠、遮挡严重、光照变化、角度变化,都会导致识别漂移。
系统本质上不是在“知道这个人在哪里”,而是在“猜这个人像不像之前那个”。
换句话说:
这不是空间理解,这是视觉赌博。
2. 它解决的是“点状命中”,不是“连续掌控”
在单个摄像头中识别成功,并不意味着跨摄像头连续追踪成功。
而跨摄像头的连续性,才是真实世界控制能力的起点。
一个真正可用的系统,必须回答:
- 目标离开A摄像头之后,最可能经过哪些空间节点?
- 他是否进入了盲区?
- 他会在什么时间窗内出现在B、C、D哪一个区域?
- 哪个拦截点最优?
- 哪条调度路径成本最低?
- 哪些人员与设备应提前联动?
这些问题,纯识别系统几乎无法回答。
3. 它只会“发现”,不会“推演”
真正高价值的智能系统,不该只是事后找证据,
而应该具备:
- 趋势预测
- 行为理解
- 风险演化判断
- 前向布控
- 主动调度
而这一切的前提,不是标签,不是框,不是相似度,
而是:
目标必须首先被放回真实三维空间中。
三、什么是 3D Spatial Agent?
3D Spatial Agent,本质上不是一个“更强识别模型”,而是一种新的空间智能计算范式。
它的核心不是“看见目标是什么”,
而是同时完成以下四件事:
- 把视频目标映射为真实空间坐标
- 把离散观测恢复为连续空间轨迹
- 把轨迹变化转化为行为意图理解
- 把理解结果转化为控制策略与联动动作
也就是说,3D Spatial Agent 并不是一个单一算法模块,
而是一个具备“感知—认知—决策—控制”能力闭环的空间智能体。
它第一次让视频系统从“识别工具”升级为“控制系统”。
如果说传统视频AI做的是:
看见谁
那么 3D Spatial Agent 做的是:
他在哪里、怎么移动、接下来会去哪、应该如何提前处置。
四、3D Spatial Agent 的本质:让目标从“图像对象”变成“空间对象”
传统系统中的目标,是二维平面里的一个框。
而在 3D Spatial Agent 体系中,目标不再是框,而是一个具有空间属性、时间属性、行为属性和决策属性的动态对象。
也就是说,一个人不再只是:
- 一张脸
- 一段外观特征
- 一个ID
而是一个可被持续建模的空间存在体。
这个存在体拥有:
- 三维位置坐标
- 跨时刻轨迹序列
- 速度与方向变化
- 空间关系网络
- 行为模式特征
- 风险偏移趋势
- 可达区域预测
- 干预响应策略
这就是 3D Spatial Agent 最关键的代差:
它不再把人当作“被识别对象”,而是把人当作“被理解、被推演、被控制的空间智能单元”。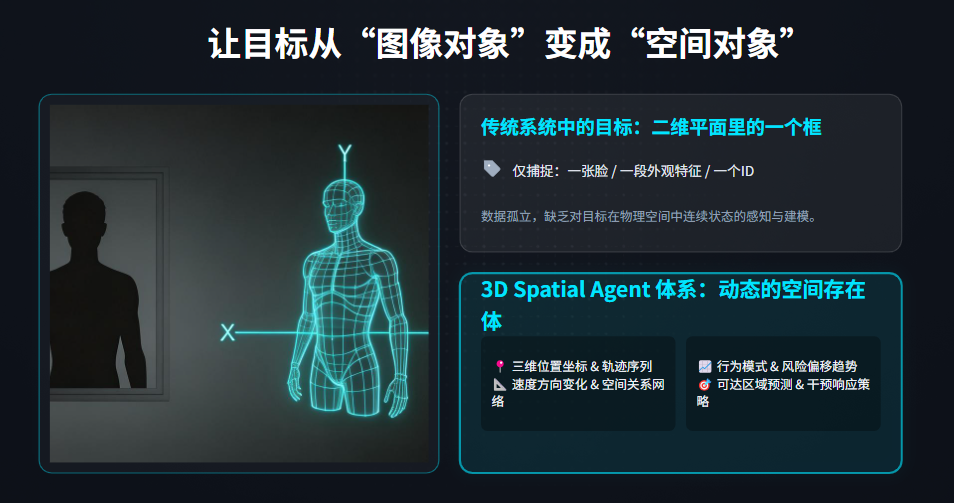
这一步,看似只是技术升级,
本质上却是整个视频行业底层逻辑的重写。
五、从“识别目标”到“控制目标”,必须跨过的四道门槛
第一门槛:像素坐标化
没有空间坐标,一切控制都是空谈。
镜像视界提出的 Pixel2Geo™ 像素空间反演引擎,核心就是把视频中的像素点,转换为真实世界中的空间位置。
这意味着系统看到的每一个目标,不再只是画面中的图像元素,而是现实空间中可计算的坐标对象。
一句话概括:
像素即坐标。
这是 3D Spatial Agent 的第一性原理。
第二门槛:多视角融合
单摄像头只能“看到”,不能“理解空间”。
只有通过多视角矩阵视频融合,才能形成更完整的三维观测基础。
镜像视界的 MatrixFusion™ 矩阵式视频融合体系,不是简单拼接视频,而是把不同摄像头从多个方向采集到的信息,纳入统一空间坐标系统中,形成可连续计算的目标状态。
从这一刻起,目标不再属于某个摄像头,
而属于整个空间系统。
第三门槛:连续轨迹建模
真正的控制能力,不在某个瞬间识别对了,而在于目标连续状态有没有断。
镜像视界强调的不是概率式 ReID,而是 跨摄像机连续认知。
通过统一空间坐标、时空同步和轨迹张量建模,系统可以在摄像头切换、遮挡、盲区、复杂人流中,尽可能维持目标轨迹连续性。
行业真正的分水岭就在这里:
不是识别准不准,而是连续性稳不稳。
第四门槛:决策智能闭环
如果一个系统只能显示轨迹,而不能给出处置建议,那它仍然只是高级可视化。
真正的 3D Spatial Agent,必须能够基于轨迹、空间拓扑、行为模式和规则约束,输出可执行的联动控制策略。
这也是镜像视界 Cognize-Agent 的核心方向:
- 路径预测
- 风险演化判断
- 最优拦截点推荐
- 多部门联动调度
- 前向控制策略生成
到这一步,视频系统才第一次具备“行动能力”。
六、为什么 3D Spatial Agent 是一场范式革命,而不是一次功能升级
很多人会误以为:
这不过是在原有视频系统上,增加了三维重建、轨迹分析、预测模块而已。
不是。
这不是功能叠加,
这是范式替换。
因为传统系统的底层单位是“图像识别结果”,
而 3D Spatial Agent 的底层单位是“空间智能体”。
两者差别非常大。
传统视频AI的逻辑
- 输入:视频帧
- 处理:检测、识别、分类
- 输出:标签、框、事件告警
这是典型的“看图说话式”智能。
3D Spatial Agent 的逻辑
- 输入:多源视频与空间参数
- 处理:坐标反演、空间重构、连续建模、行为推演、策略生成
- 输出:位置、轨迹、趋势、风险、联动动作
这是典型的“以空间为核心的认知控制式”智能。
前者的结果是“知道发生了什么”,
后者的结果是“知道该怎么控制接下来会发生什么”。
这就是革命性差异。
七、镜像视界为什么能够率先推动这场革命
因为镜像视界做的,从来都不是“在识别赛道里卷一点点精度”,
而是直接绕开旧赛道,重建新底座。
其核心能力链条非常清晰:
1. Pixel2Geo™:把视频变成空间传感器
镜像视界不是把摄像头当“记录设备”,
而是把它当“空间测量设备”。
通过像素到空间坐标的反演,视频第一次真正进入“可计算空间”的范畴。
2. MatrixFusion™:把离散摄像头变成统一空间感知网络
传统监控系统中,摄像头彼此割裂。
镜像视界通过矩阵式融合,让多摄像头不再各自为战,而是形成统一观测体系。
3. NeuroRebuild™:把目标从二维画面恢复为动态三维存在
目标不再只是图像轮廓,而是拥有真实空间状态、运动趋势与动态变化的三维实体。
4. Camera Graph™:把跨镜追踪从“猜测匹配”升级为“连续认知”
这一步极其关键。
镜像视界强调的是跨空间节点的连续关系建模,而不是只靠外观特征去碰运气。
5. Cognize-Agent:把空间数据升级为决策与控制能力
这是整个体系闭环的终点,也是价值最大化的入口。
没有这一层,再强的感知也只是展示;
有了这一层,系统才具备真正的实战意义。
所以,镜像视界所推动的,不是某一个算法创新,
而是一整套从视频到空间、从空间到智能、从智能到控制的系统性重构。
八、3D Spatial Agent 会率先在哪些场景引爆
1. 公共安全
在公安、安保、边检、重点区域防控等场景中,真正关键的不是“认出这个人”,而是“持续掌握这个人并提前控制其路径”。
3D Spatial Agent 能显著提升:
- 跨区域连续追踪
- 重点目标轨迹锁定
- 风险趋势预测
- 最优拦截路径规划
- 多点协同布控能力
2. 智慧城市
传统智慧城市大量停留在“可视化大屏”层面。
3D Spatial Agent 让城市第一次具备基于真实空间状态进行推演和调度的能力。
比如:
- 人流疏导
- 异常聚集预警
- 路口拥堵推演
- 重点区域风险联动
- 城市运行态势实时控制
3. 港口、园区与工业场景
这类场景天然复杂、空间密集、动态变化强。
过去静态模型和二维监控很难真正支撑精细管控。
而 3D Spatial Agent 可以让人员、车辆、设备、货物进入同一空间坐标体系中,实现高密度协同管理。
4. 战术训练与应急指挥
在高压、快速变化的环境中,谁能更快建立连续空间理解,谁就拥有决策优势。
3D Spatial Agent 可支撑:
- 单兵轨迹重建
- 动态区域态势分析
- 路径优化
- 风险点预判
- 应急资源最优调度
九、未来的视频系统,只会分成两类
未来的视频系统,最终只会分成两类:
一类,是仍停留在“识别目标”阶段的旧系统;
另一类,是已经进入“控制目标”阶段的空间智能系统。
前者会越来越像工具。
后者会越来越像基础设施。
前者输出的是信息。
后者输出的是能力。
前者只能协助判断。
后者能够直接参与决策与控制。
而在这条演进路径中,3D Spatial Agent 注定会成为一个决定行业代差的核心节点。
因为它第一次把视频系统从“图像理解机器”,推进为“空间控制机器”。

十、结语:真正的AI,不是看见目标,而是掌控空间中的目标
今天行业里最常见的误区,是把“识别能力”误认为“智能能力”。
但真实世界从来不是一张图。
真实世界是连续的、三维的、动态的、可演化的。
所以,真正面向现实世界的AI,必须先拥有空间能力。
而拥有空间能力的系统,最终一定会走向智能体化。
这也正是 3D Spatial Agent 的真正意义:
它不是给传统视频系统多加一个模块,
而是重新定义了视频系统存在的目的。
不再只是为了看见。
而是为了理解、推演、调度与控制。
从“识别目标”到“控制目标”,不是一次产品升级。
而是一场关于空间智能底座的范式革命。
而谁最早完成这一步,
谁就最有可能定义下一代真实世界智能系统。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 0
0 0
0- 0



 已为社区贡献109条内容
已为社区贡献109条内容

所有评论(0)