LangChain 1.x 入门指南:从智能体到实战案例
适合对大模型有初步了解,希望快速上手大模型应用开发的开发者
随着大模型技术的爆发式增长,如何高效地将大模型集成到实际应用中,成为开发者面临的核心挑战。LangChain 作为当前最流行的 LLM 应用开发框架之一,正在快速演进。本文将带你系统了解 LangChain 的发展背景、生态演化,并通过实战案例掌握 LangChain 1.x 的核心用法。
一、智能体(Agent):大模型应用的核心
什么是智能体?
智能体(Agent)是指能够感知环境、做出决策并执行行动的自主系统。在 LLM 领域,基于大模型的智能体以大模型为核心控制器,整合感知、规划、记忆与工具调用等模块,实现复杂任务的自动化处理。
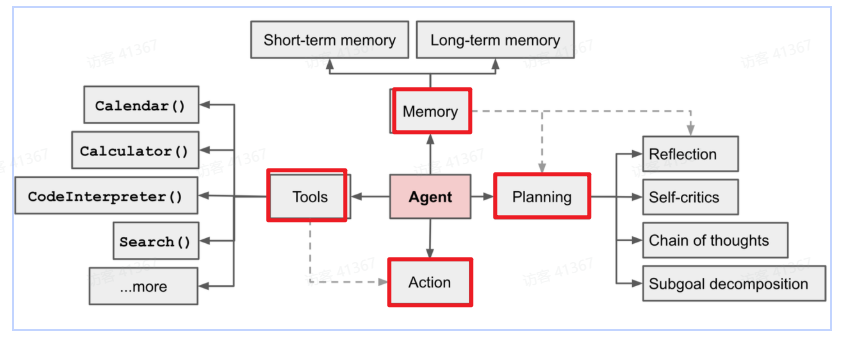
智能体的核心架构
-
大模型:决策中枢,负责任务分解与策略生成(如 GPT-4、DeepSeek)
-
规划能力:分析、拆解复杂任务
-
工具与行动:调用外部工具(如搜索引擎、API)执行操作
-
记忆机制:短期记忆(对话上下文)与长期记忆(向量数据库)
-
多智能体协同:多个专业智能体协作完成复杂任务
常用智能体框架
| 框架 | 是否开源 | 特点 |
|---|---|---|
| LangChain/LangGraph | 开源 | 模块化设计,支持任务编排与记忆问答 |
| CrewAI | 开源 | 基于角色分工的多智能体协作 |
| AutoGen | 开源 | 多智能体对话与动态工具调用 |
| Dify | 开源 | 低代码平台,支持可视化工作流 |
| 字节扣子(Coze) | 商用 | 拖拽式设计,集成 60+ 插件 |
| 百度文心智能体 | 商用 | 低代码开发,500+ 预置 API |
| 腾讯元器 | 商用 | 对接微信/QQ 生态,支持 3D 虚拟形象 |
小结:智能体是大模型应用的核心形态,掌握智能体的开发是进入大模型应用领域的关键一步。
二、LangChain 简介:从副业到生态帝国
发展历史
LangChain 由 Harrison Chase 于 2022 年 10 月发起,最初只是一个 800 行代码的个人副业项目。在 Stable Diffusion 发布后、ChatGPT 问世前的窗口期,Harrison 通过大量技术交流,提炼出开发者构建 LLM 应用的共性需求,最终将 LangChain 发展为全球增长最快的开源项目之一。
2023 年 4 月,LangChain 获得 Benchmark 领投的 1000 万美元种子轮融资,一周后又完成红杉领投的 2500 万美元 A 轮融资,估值达 2 亿美元。
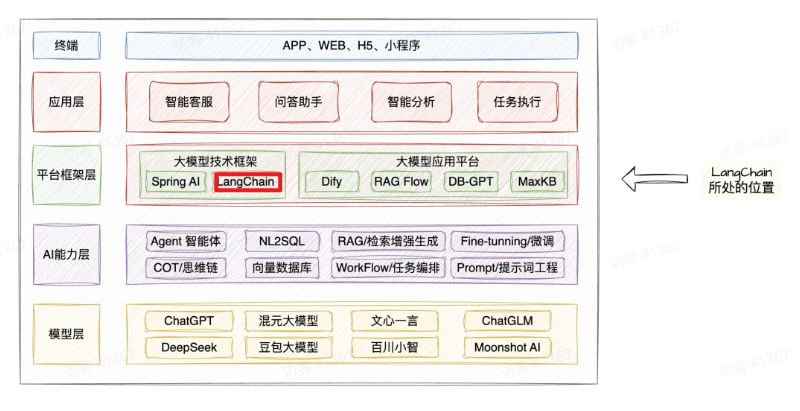
优点
-
高度模块化:提供 700+ 集成,覆盖 10 大类组件
-
模型与基础设施中立:支持多种 LLM、向量数据库、工具
-
快速开发:少量代码即可完成 RAG、智能体等应用
-
双语言支持:Python 与 TypeScript
缺点
-
控制权不足:高层接口易用但定制化困难
-
文档与版本问题:破坏性更改、依赖冲突、文档过时
-
学习曲线:功能丰富导致概念繁多
小结:LangChain 是 LLM 应用开发的“胶水”与“粘合剂”,极大降低了开发门槛,但也带来了控制权与复杂性的挑战。
三、LangChain 1.x 的重大改进
1. 底层更换为 LangGraph
旧版 LangChain 使用有向无环图(DAG)编排任务,无法支持动态流程、分支并行、人工介入等复杂场景。LangGraph 引入图结构(Graph),支持循环工作流与状态管理,成为 LangChain 1.x 的底层引擎。
2. 整合 API
旧版创建智能体有十几种 API(如 create_react_agent、create_json_agent),新版统一为 create_agent,大幅降低学习成本。
3. 引入 Middleware(中间件)
在大模型自主规划与人工控制之间,中间件提供了关键节点的控制与纠偏能力,使智能体行为更可控。
4. DeepAgent
基于 LangGraph 构建的生产级智能体库,具备规划工具、文件系统、子代理与详尽系统提示,能更可靠地处理复杂任务。
四、LangChain 生态演化
早期生态(LangChain 0.x)
-
LangChain-Core:内核与表达式语言
-
LangChain-Community:第三方集成
-
LangSmith:调试、测试、监控平台
-
LangServe:部署为 REST API
LangGraph 时代(1.x)
-
底层统一为 LangGraph
-
集成整合为 Integrations
-
新增 LangGraph Platform 部署工具
-
统一 API:
create_agent -
高级 API:DeepAgent
-
界面组件:AgentChatUI
-
图形化测试:LangSmith Studio
小结:LangChain 1.x 本质上是 LangGraph 的封装,在保留品牌价值的同时,提供了更强大、更可控的智能体开发体验。
五、LangChain 1.x 入门实战
环境准备
安装依赖:
pip install langchain langgraph langchain-community本地需要运行 Ollama 并拉取模型(如 qwen2.5:7b)。
或者选择线上大模型,烧Token的方式
1. 最简代码示例
from langchain.agents import create_agent
from langchain.chat_models import init_chat_model
def get_weather(city: str) -> str:
"""给出指定城市的天气情况"""
return f"{city}的天气一直是万里无云"
model = init_chat_model(
model="qwen2.5:7b",
model_provider="ollama",
base_url="http://localhost:11434/"
)
agent = create_agent(
model=model,
tools=[get_weather],
system_prompt="你是一个功能强大的智能助手",
)
result = agent.invoke(
{"messages": [{"role": "user", "content": "北京的天气怎么样?"}]}
)
print(result["messages"][-1].content)
create_agent的核心是一个 ReAct(Reasoning + Acting,推理+行动)模式 的执行循环。它的工作流程是:思考 -> 行动(可选)-> 观察 -> 再思考 -> ... -> 最终回答。Tool(工具)只是这个循环中“行动”环节的备选项,只有当模型在“思考”后认为需要外部信息时才会调用。
下面我们来详细拆解一下它的执行机制。
Agent的执行机制:一个决策循环
当你调用
agent.invoke后,内部会启动一个循环,其工作流如下图所示:
这个循环的每一步都至关重要:
调用模型进行推理 (LLM Node):
Agent将你提供的
system_prompt(“你是一个功能强大的智能助手”)、历史对话消息(“北京的天气怎么样?”)以及所有工具的描述(函数名、参数、文档字符串)一并发送给大模型(你的qwen2.5:0.5b)。模型的任务不是直接回答,而是思考下一步该做什么。它会根据用户问题的性质来决定是直接生成答案,还是调用某个工具获取更多信息。
模型做出决策:
针对“北京的天气怎么样?”这个问题,模型通过分析工具的描述(
get_weather函数的注释"""给出指定城市的天气情况""")会“意识”到,自己不知道北京的实时天气,但有一个工具可以提供这个信息。于是,模型不会输出文本答案,而是输出一个工具调用指令。这个指令是一个结构化的数据,包含了要调用的工具名(
get_weather)和参数(city: "北京")。执行工具 (Tools Node):
Agent的执行器接收到这个工具调用指令后,会在本地的Python环境中真正执行你的
get_weather("北京")函数。函数执行后返回字符串结果:
"北京的天气一直是万里无云"。将观察结果返回给模型 (Observation):
这个工具执行的结果会被包装成一条消息,再次发送给最初的大模型。
模型生成最终答案:
模型现在拥有了用户的问题和工具返回的“事实”。它会基于这两者进行最后的推理和语言组织。
模型意识到:“我已经通过工具获得了天气信息,用户只是想知道天气,不需要再做其他事了。”于是,它将这些信息组织成自然、友好的最终答案,例如:“根据查询,北京目前的天气是万里无云。”。
循环终止:
Agent检查模型的最终输出,发现没有新的工具调用指令,于是判定任务完成,将这个最终答案作为
invoke的结果返回给你。""" 用户输入 → 模型思考 → 决策分支 ↓ 需要工具? 不需要工具? ↓ ↓ 调用工具 直接回答 ↓ 获得结果 ↓ 再次思考 ↓ 最终回答 """
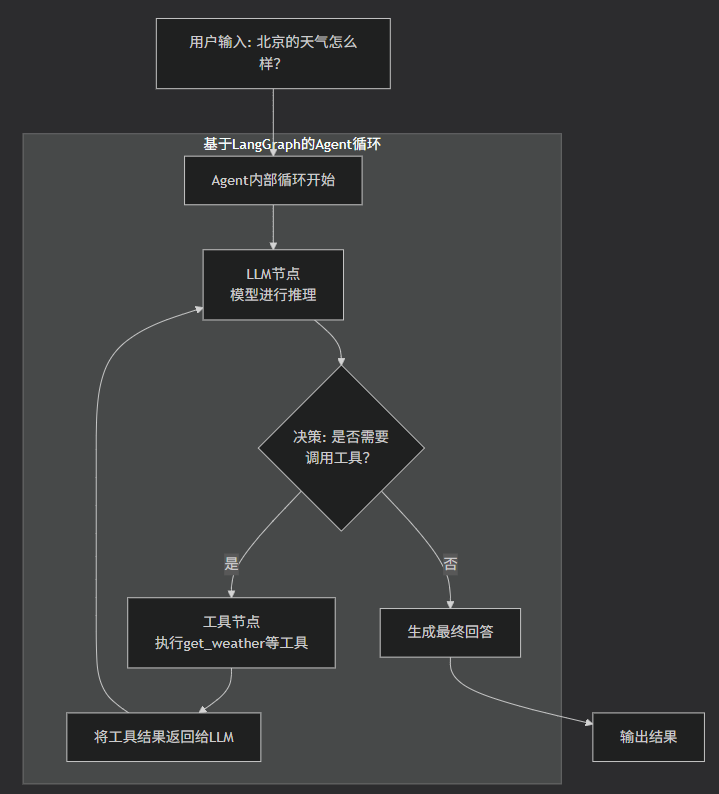
运行逻辑:
-
智能体判断需要调用
get_weather工具,参数city=北京 -
工具返回“北京的天气一直是万里无云”
-
大模型组织最终回答
2. 系统提示词
SYSTEM_PROMPT = """你是一位专业的天气预报人员。
如果用户查询天气,请确认具体地点,必要时使用 get_user_location 工具。"""
agent = create_agent(
model=model,
tools=[get_weather],
system_prompt=SYSTEM_PROMPT,
)3. 创建工具(支持运行时上下文)
from dataclasses import dataclass
from langchain.tools import tool, ToolRuntime
@dataclass
class SessionContext:
user_id: str
session_token: str
user_role: str # "admin", "user", "guest"
request_id: str
@tool
def get_user_permissions(runtime: ToolRuntime[SessionContext]) -> list:
"""根据会话获取用户权限"""
ctx = runtime.context
# 可以根据不同角色返回不同权限
if ctx.user_role == "admin":
return ["read", "write", "delete", "manage_users"]
elif ctx.user_role == "user":
return ["read", "write"]
else:
return ["read"]
# 使用
agent = create_agent(
model=model,
tools=[get_user_permissions],
context_schema=SessionContext
)
# 不同用户会话传入不同上下文
admin_session = SessionContext(
user_id="admin_001",
session_token="token_abc",
user_role="admin",
request_id="req_001"
)
result = agent.invoke(
{"messages": [{"role": "user", "content": "我能删除数据吗?"}]},
context=admin_session # 管理员上下文
)
# Agent会调用get_user_permissions,发现可以删除场景1:使用普通工具
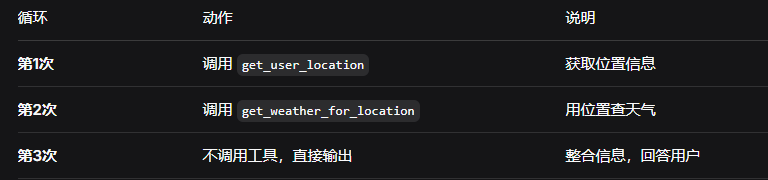
用户:"北京的天气怎么样?" → Agent调用 get_weather_for_location(city="北京") → 结果:"北京的天气一直是万里无云"场景2:使用带上下文的工具
用户:"我这里的天气怎么样?"(用户没有说位置) → Agent思考:用户没说位置,但我有get_user_location工具 → Agent调用 get_user_location() → 工具从 runtime.context.user_id="1" 得知用户是"北京" → 工具返回:"北京" → Agent再调用 get_weather_for_location(city="北京") → 最终回答:"根据您的定位,北京的天气一直是万里无云"
✅
context_schema>> 声明上下文应该长什么样(类型定义)✅
context=实例>> 提供具体的数据(实际对象)✅ 工具通过
runtime.context访问这些数据这种设计模式的好处:
类型安全:IDE可以自动补全和类型检查
解耦:工具定义不依赖具体数据来源
灵活:不同运行场景可以传入不同上下文
可测试:可以轻松mock上下文进行单元测试
4. 配置模型参数
from langchain.chat_models import init_chat_model
# 方法1:直接在初始化时设置
model = init_chat_model(
model="qwen2.5:0.5b",
model_provider="ollama",
base_url="http://localhost:11434/",
temperature=0.8, # 中等创造性
num_predict=256 # 限制输出长度
)
# 方法2:在调用时动态设置
model = init_chat_model(
model="qwen2.5:0.5b",
model_provider="ollama"
)
response = model.invoke(
"给我讲个笑话",
config={
"temperature": 0.8,
"num_predict": 256
}
)1.
temperature=0.8- 控制随机性/创造性作用范围:0.0 到 2.0(不同模型略有差异)
Temperature值 行为特点 适用场景 0.0 - 0.3 确定性高,每次都选概率最高的词 代码生成、数据提取、数学计算 0.4 - 0.7 平衡创造性和准确性 一般对话、问答系统 0.8 - 1.2 创造性高,输出多样化 创意写作、头脑风暴 1.3 - 2.0 非常随机,可能不连贯 实验性应用 temperature=0.8 的影响:
✅ 输出会有一定变化,不会每次都一样
✅ 适合对话场景,显得更自然
⚠️ 可能会有一些"意外"的输出
⚠️ 不适合需要精确答案的场景
2.
num_predict=256- 限制输出长度作用:限制模型生成的最大token数(不是字数)
Token vs 字数:
英文:1 token ≈ 0.75 个单词
中文:1 token ≈ 0.5-1 个汉字
5. 添加记忆(多轮对话)
from langgraph.checkpoint.memory import InMemorySaver
checkpointer = InMemorySaver()
agent_with_memory = create_agent(
model=model,
checkpointer=checkpointer
)
config = {"configurable": {"thread_id": "1"}}
while True:
user_input = input("请输入您的问题:")
response = agent_with_memory.invoke(
{"messages": [{"role": "user", "content": user_input}]},
config=config
)
print("智能助手回答:" + response["messages"][-1].content)6. 完整示例(天气助手 + 记忆)
from langchain.agents import create_agent
from langchain.tools import tool, ToolRuntime
from langgraph.checkpoint.memory import InMemorySaver
from langchain.chat_models import init_chat_model
from pydantic import BaseModel
SYSTEM_PROMPT = """你是一位专业的天气预报人员。
你可以使用下面两个工具:
- get_weather_for_location: 指定一个地点,给出该地点的天气情况
- get_user_location: 获取用户的位置信息
如果用户查询天气,请确认你知道具体地点,如果从用户的问题中能判断出用户要查询他所在地点的天气,使用get_user_location工具来定位"""
class Context(BaseModel):
"""用户运行时上下文的schema."""
user_id: str
@tool
def get_weather_for_location(city: str) -> str:
"""给出指定城市的天气情况"""
return f"{city}的天气一直是万里无云"
@tool
def get_user_location(runtime: ToolRuntime[Context]) -> str:
"""根据user_id确定用户所在位置,仅在需要明确知道用户位置时调用"""
user_id = runtime.context.user_id
return "北京" if user_id == "1" else "上海"
# 配置模型
model = init_chat_model(
model="qwen2.5:0.5b",
model_provider="ollama",
base_url="http://localhost:11434/",
)
# 硅基流动(SiliconFlow)的 API
# model = init_chat_model(
# model="deepseek-ai/DeepSeek-V3",
# model_provider="openai",
# api_key='sk-sksksksksksksksksksksksksksksk',
# base_url="https://api.siliconflow.cn/v1"
# )
# deepseek官网 API
# model = init_chat_model(
# model="deepseek-chat",
# model_provider="deepseek",
# api_key='sksksksksksksksksksksksksksksk',
# base_url="https://api.deepseek.com"
# )
# 设置记忆
checkpointer = InMemorySaver()
# 创建智能体
agent = create_agent(
model=model,
system_prompt=SYSTEM_PROMPT,
tools=[get_user_location, get_weather_for_location],
context_schema=Context,
checkpointer=checkpointer
)
# 如果使用记忆,必须带有config
# `thread_id` 对于每次谈话是唯一的.
config = {"configurable": {"thread_id": "1"}}
# 运行agent
response = agent.invoke(
{"messages": [{"role": "user", "content": "今天外面天气怎样?"}]},
config=config,
context=Context(user_id="1")
)
print(response)
print(response["messages"][-1].content)
# 可以指定`thread_id`选择相应的对话,继续进行对话.
response = agent.invoke(
{"messages": [{"role": "user", "content": "谢谢你"}]},
config=config,
context=Context(user_id="1")
)
print(response)
print(response["messages"][-1].content)
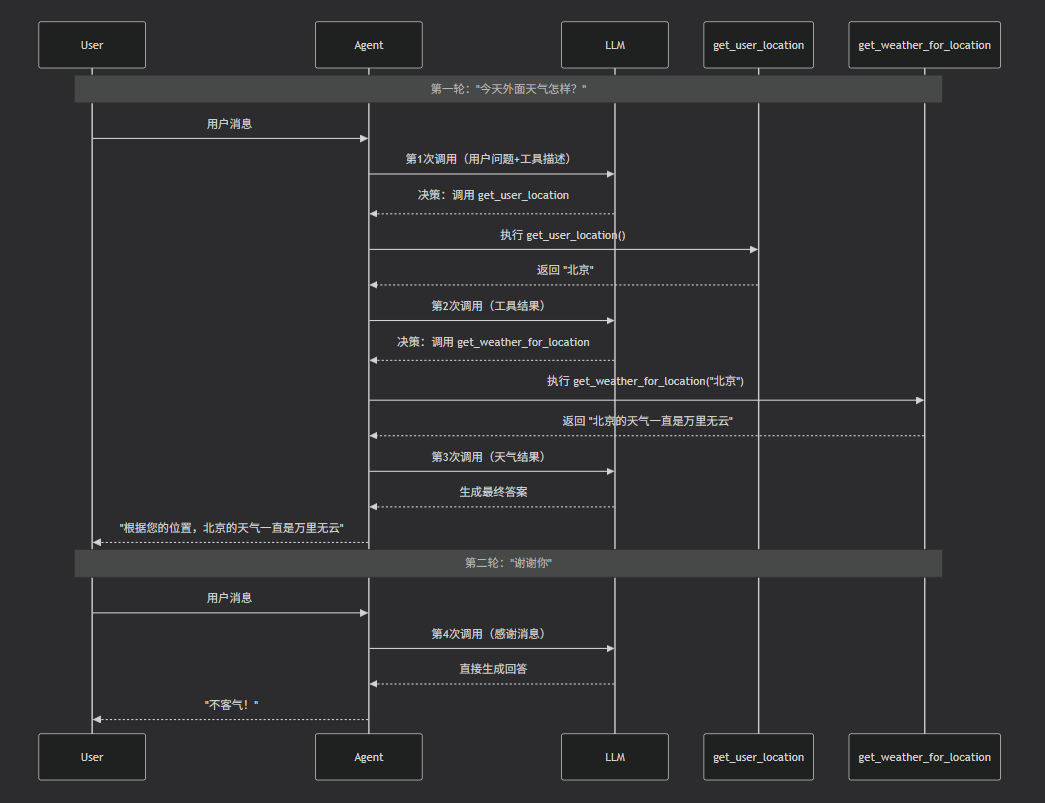
流程图:
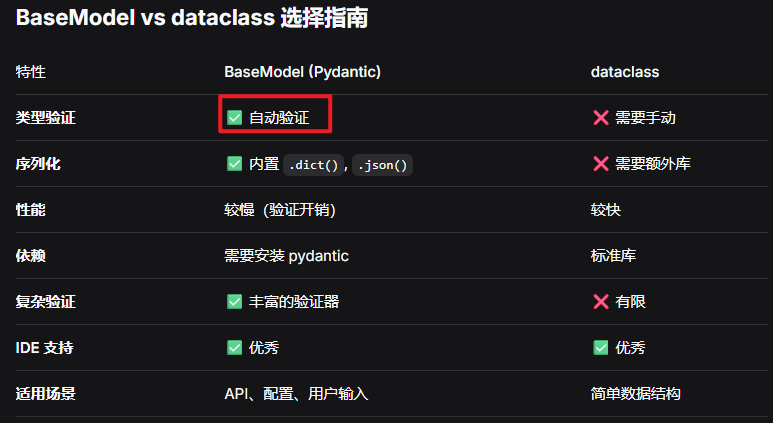
BaseModel细节解析
BaseModel =
dataclass+ 自动验证 + 自动序列化 + 更丰富的功能在 LangChain 中,使用
BaseModel定义上下文能获得更好的类型安全和错误提示对于简单的场景,
@dataclass也完全够用,但BaseModel是更专业的选择
整体流程口述:
第1步:上下文组装
Agent将 system_prompt ➕ 历史对话信息 ➕ 工具描述(函数名、参数、文档说明)发给大模型,⚠️ 工具文档说明很重要——它是给大模型看的"使用说明书"。
第2步:模型决策
大模型思考做出决策是直接返回结果还是去按需使用提供的工具库
第3步:工具执行
如果使用工具库,大模型会将参数和工具调用指令发给Agent,Agent执行完返回给大模型结果
第4步:再次决策
大模型继续思考是直接返回结果还是去按需使用提供的工具库,这里咱们直接返回结果
第5步:任务完成
Agent检查结果,发现没有新的工具调用指令,判定任务完成,返回最终结果

7.模型的输入输出
def useMsg():
from langchain.messages import HumanMessage,AIMessage,SystemMessage
from langchain.chat_models import init_chat_model
# 初始化本地 Ollama 模型
model = init_chat_model(
model="qwen2.5:7b",
model_provider="ollama",
base_url="http://localhost:11434/"
)
systemMsg = SystemMessage("你是一位能力很强的个人助手")
humanMsg = HumanMessage("你好,请介绍一下你自己")
messages = [systemMsg,humanMsg]
print(messages)
response = model.invoke(messages)
print([response])
if __name__ == '__main__':
useMsg()8.结构化输出
def normalOutPut():
from langchain.chat_models import init_chat_model
model = init_chat_model(
model="qwen2.5:7b",
model_provider="ollama",
base_url="http://localhost:11434/"
)
response = model.invoke("输出电影《Inception》的详细信息")
print(response.content)
def pydanticOutPut():
from pydantic import BaseModel,Field
from langchain.chat_models import init_chat_model
class Movie(BaseModel):
"""a movie with details"""
title: str = Field(...,description='电影名称')
year: int = Field(...,description='电影发行年份')
director: str = Field(...,description='电影的导演')
rating: float = Field(...,description="电影的评分(满分为10份)")
model = init_chat_model(
model="qwen2.5:7b",
model_provider="ollama",
base_url="http://localhost:11434/"
)
modelWithStructuredOutput = model.with_structured_output(Movie)
response = modelWithStructuredOutput.invoke("输出电影《Inception》的详细信息")
print(response)
if __name__ == '__main__':
normalOutPut()
pydanticOutPut()9.流式输出
def testStream1():
from langchain.chat_models import init_chat_model
# 初始化本地 Ollama 模型
model = init_chat_model(
model="qwen2.5:7b",
model_provider="ollama",
base_url="http://localhost:11434/"
)
for chunk in model.stream("你好,好久不见"):
print(chunk.text,end="|",flush=True)
if __name__ == '__main__':
testStream1()10.批量输出
#批量启动推理,全部推理完成后统一返回
def returnBatchResult():
from langchain.chat_models import init_chat_model
# 初始化本地 Ollama 模型
model = init_chat_model(
model="qwen2.5:7b",
model_provider="ollama",
base_url="http://localhost:11434/"
)
responses = model.batch(
["你是谁?",
"天空为什么是蓝色的?",
"1+1等于几?"]
)
for response in responses:
print(response)
#批量启动推理,完成的条目随时返回
def returnItemResult():
from langchain.chat_models import init_chat_model
# 初始化本地 Ollama 模型
model = init_chat_model(
model="qwen2.5:7b",
model_provider="ollama",
base_url="http://localhost:11434/"
)
responses = model.batch_as_completed(
["你是谁?",
"天空为什么是蓝色的?",
"1+1等于几?"]
)
for response in responses:
print(response)
#设置最大并发,分批启动推理,统一返回
def setMaxConcurrency():
from langchain.chat_models import init_chat_model
# 初始化本地 Ollama 模型
model = init_chat_model(
model="qwen2.5:7b",
model_provider="ollama",
base_url="http://localhost:11434/"
)
responses = model.batch(
["你是谁?",
"天空为什么是蓝色的?",
"1+1等于几?"],
config={
'max_concurrency':2,
}
)
for response in responses:
print(response)
if __name__ == '__main__':
returnBatchResult()
returnItemResult()
setMaxConcurrency()六、总结与实操要点
| 问题 | 答案 |
|---|---|
| 如何调用大模型? | init_chat_model 指定 model、model_provider、base_url |
| 如何使用系统提示词? | create_agent 的 system_prompt 参数 |
| 如何添加工具? | 使用 @tool 装饰器,放入 tools 列表 |
| 如何配置模型? | init_chat_model 中传入 temperature、num_predict 等参数 |
| 如何添加记忆? | 实例化 InMemorySaver,作为 checkpointer 传入,并在 invoke 时提供 config |
LangChain 1.x 通过统一 API、底层 LangGraph 支持和丰富的生态组件,大幅提升了智能体开发的效率与可控性。掌握这些基础,你就能快速构建属于自己的大模型应用。
下一步:尝试修改系统提示词、添加更多工具,并部署到 LangGraph Platform 上体验生产级能力。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 33
33 0
0- 0



 已为社区贡献34条内容
已为社区贡献34条内容

所有评论(0)