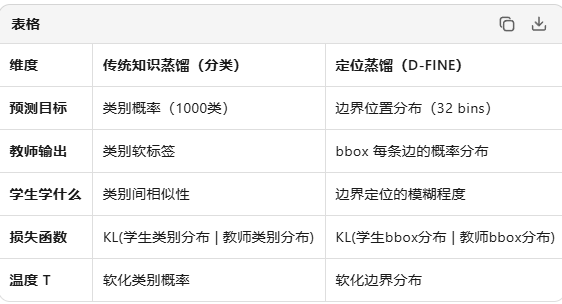
D-FINE
bbox分布与定位模糊性
bbox分布与定位模糊性 的核心思想是:用"概率分布"代替"固定数值"来表示物体边界,从而显式建模模型对定位的不确定性。
1. 啥是bbox分布?
传统方法:模型直接输出4个数字(中心点x,y + 宽高w,h),比如 "这个物体在 (100, 200),宽50,高80"。这是硬预测。
分布方法(D-FINE/DFL):模型不再说"宽是50",而是说"宽度可能是50,也可能是49或51,各自概率是多少"。具体来说:
- 把 [0-32] 的像素范围切成32个区间(bins)
- 模型输出32个概率值(比如 [0.01, 0.01, ..., 0.8, 0.15, 0.02])
- 这32个数的形状就是"分布"
2.什么是定位模糊性?
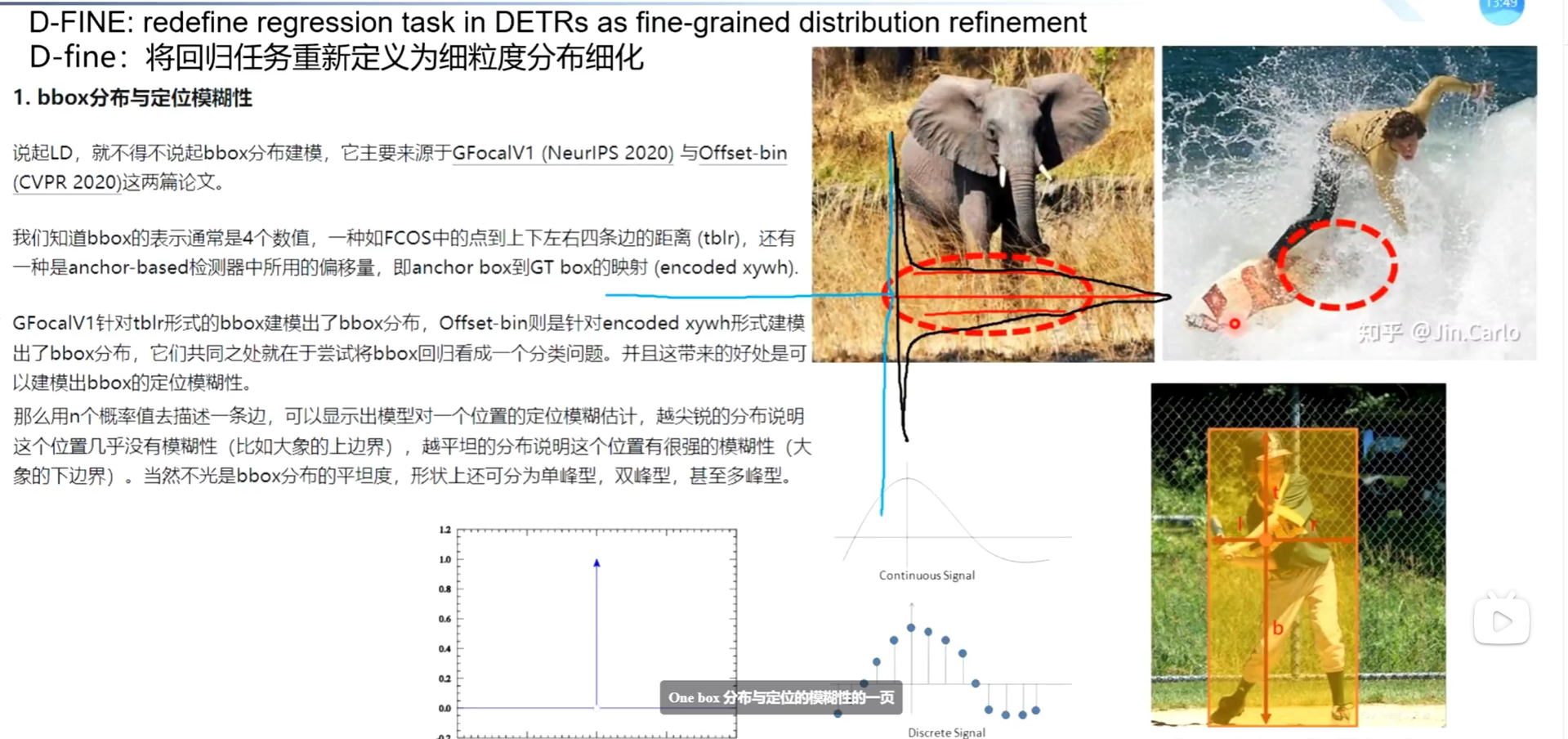
看图中的大象例子:
- 上边界(大象背部):清晰可见,与天空对比明显。模型很确定边界在哪里。
- 下边界(大象腿部):被草丛遮挡,腿和草混在一起。模型不确定边界到底在草的前面还是后面。
模糊性 = 模型对"边界到底在哪"的不确定程度
3.分布如何反应模糊性?
分布形状 = 定位置信度:
- 尖锐单峰(一个高尖峰)模型很确定边界就在这个位置,几乎没有模糊性大象的上边界(背部轮廓清晰)
- 平坦分布(矮胖平缓)模型觉得边界可能在这几个像素之间,但不确定具体是哪个,存在强模糊性大象的下边界(被草丛遮挡)
- 双峰/多峰模型觉得边界可能在A处,也可能在B处(比如遮挡物后面),存在歧义冲浪者被浪花遮挡时
4. 为啥这样更好?
传统回归:模型被迫给出一个确定值(比如必须说"下边界在y=300"),哪怕它其实不确定。这会导致:
- 训练时 loss 计算不准确(强行拟合模糊边界)
- 小目标定位不准(对1-2像素的误差很敏感)
分布方法:
- 允许模型说"我不确定",用平坦分布表示模糊区域
- 允许模型说"我很确定",用尖锐分布表示清晰区域
- 自适应:清晰的地方精细定位,模糊的地方允许一定范围波动
一句话总结:bbox分布就是用32个概率值画出一条"置信度曲线"——曲线越尖,边界越清晰;曲线越平,边界越模糊(被遮挡/纹理不清)。这样模型既能精准定位清晰的边缘,又能合理处理模糊的遮挡区域。
知识蒸馏
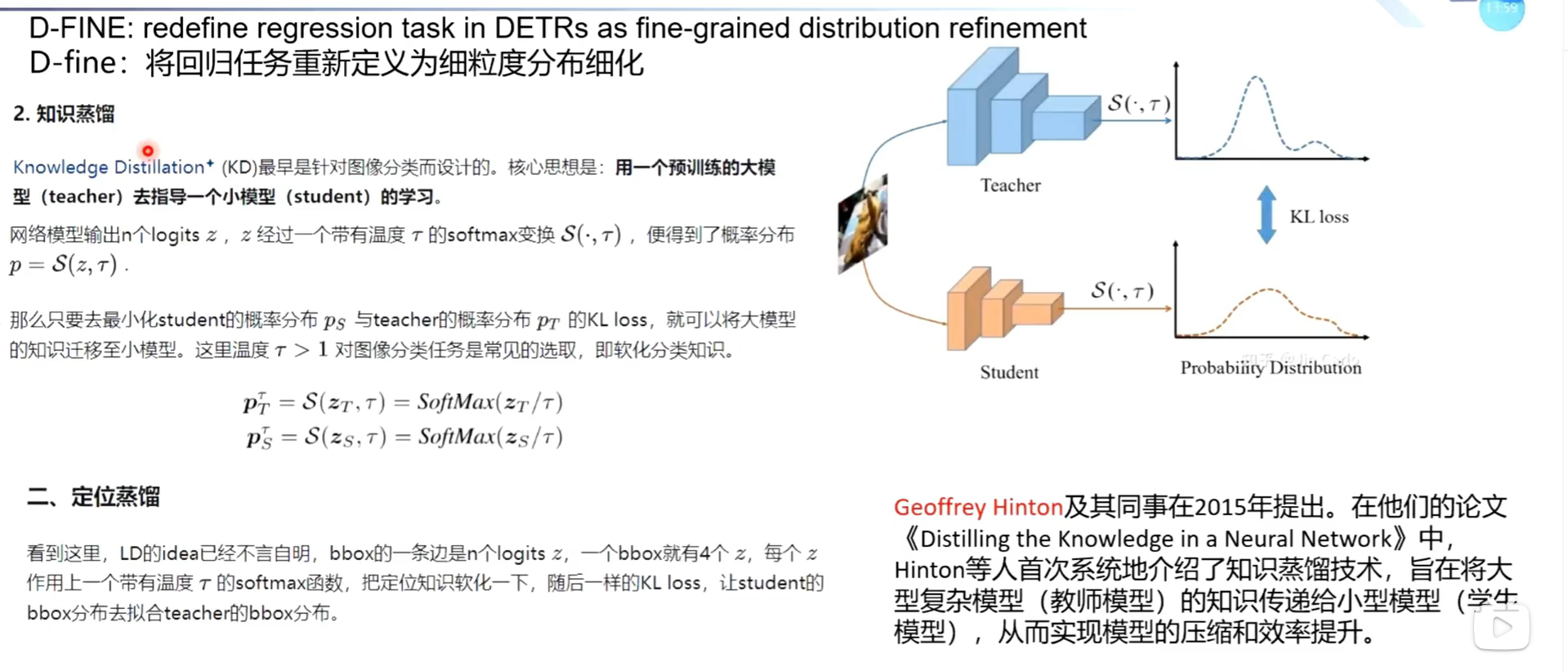
知识蒸馏是在这个有了连续化坐标分布之后才引入到目标检测这个怎么理解
知识蒸馏最初为啥用到分类里面?
1.知识蒸馏
1.基本概念:
核心思想:用一个大模型(Teacher)指导小模型(Student)学习。
传统训练:
- 学生模型直接拟合 ground truth(硬标签:0或1)
- 例如:这是猫(1),不是狗(0)
知识蒸馏训练:
- 学生模型学习教师模型的输出分布(软标签:概率值)
- 例如:教师说"这是猫(0.7),有点像老虎(0.2),有点像狮子(0.1)"
- 学生不仅学到"这是猫",还学到"猫和老虎/狮子的相似关系"
2. 技术实现(温度 T)
通过 带温度 T 的 Softmax 生成软分布: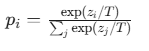
- T > 1:概率分布变"平缓",保留更多类别间的相对信息(Dark Knowledge)
- KL Loss:最小化学生分布与教师分布的差异
2.定位蒸馏
1.为啥需要定位蒸馏
D-FINE 将 bbox 每条边表示为 32 个区间的概率分布(而非单一数值)。
类比分类蒸馏:
- 分类:预测 1000 个类别的概率分布 → 可以用 KD
- 定位:预测 32 个离散区间的概率分布 → 也可以用 KD!
2. 具体实现
教师模型(大模型):
- 对 bbox 的每条边(上/下/左/右)输出分布 PT (经过温度 T 软化)
- 例如:对于物体上边界,教师输出
[0.01, 0.02, 0.1, 0.7, 0.15, 0.02...](尖锐峰值在第4个区间)
学生模型(小模型):
- 同样输出分布 PS
- 损失函数:计算 PS 与 PT 的 KL 散度
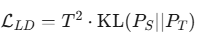
3.定位蒸馏学到了什么?
不仅仅是"边界在哪",更重要的是"定位模糊性":
场景 教师分布 学生学习效果
清晰边界(如大象背部) 尖锐单峰 学生学会:这里边界很确定,要精准定位
模糊边界(如大象腿部被草遮挡) 平坦/多峰 学生学会:这里存在不确定性,允许一定范 围的误差
关键优势:
- 大模型对边界判断更准确(分布峰值位置正确且尖锐)
- 小模型通过模仿分布,继承了大模型的"定位置信度"
- 特别是对于那些人工标注都可能模糊的边界,教师提供了比硬标签更合理的"软监督"
定位蒸馏就是把知识蒸馏从"分类任务"搬到了"边界框回归任务"上,让小模型不仅学会物体在哪,还学会边界是否清晰(模糊性建模)。
三 疑问
1. 为啥知识蒸馏最初用于分类?
1.1 分类任务天然有"分布"
分类模型的输出是 Softmax 概率分布(比如1000个类别的概率),天然满足:
- 维度固定(1000维)
- 和为1(概率归一化)
- 可以用 KL 散度 直接衡量两个分布的差异
1. 2.传统目标检测没有分布
在 DFL/D-FINE 之前,目标检测(Faster R-CNN、YOLO、FCOS 等)bbox 回归是确定性回归:
# 传统检测:直接预测4个实数(坐标值)
pred_x = 100.5 # 中心点x
pred_y = 200.3 # 中心点y
pred_w = 50.2 # 宽度
pred_h = 80.7 # 高度问题:这是标量输出,不是概率分布!
- 教师模型输出:
[100.5, 200.3, 50.2, 80.7] - 学生模型输出:
[101.2, 199.8, 48.5, 82.1]
没法用 KL 散度,因为这不是两个"分布"的比较,只是数值误差(L1/L2 Loss)。
2.有了连续化坐标分布之后才引入检测 咋理解?
关键突破:把坐标变成分布
DFL(Distribution Focal Loss) 和 D-FINE 的核心创新:
不再直接预测坐标值,而是预测"坐标落在32个区间的概率分布"
# D-FINE:预测32个区间的概率(以宽度为例) prob_dist = [0.01, 0.02, 0.05, 0.1, 0.7, 0.1, 0.02...] # 32个数,和为1 # 最终宽度 = sum(prob[i] * i) # 加权求和得到连续坐标这下有了分布!
- 教师模型输出:32维概率分布 PT
- 学生模型输出:32维概率分布 PS
- 可以用 KL 散度:
因为教师和学生教授和学习的实际上是模式和分布 老师不仅要教什么对,还要教什么错,而且为什么错,从错误中能学到什么,而之前的目标检测的结果基本都是板上钉钉的答案,是单个独立,没有分布和模式学习的可能性可言 在define之后将一个边的固定答案转变为一个概率分布,有了离散值,就把教学变成了可能?
1. "板上钉钉" vs "分布教学"
传统检测(板上钉钉):
- 教师说:"边界在 y=100"
- 学生学到:只有一个正确答案,其他都是错的
- 问题:如果图像模糊(比如遮挡),y=100 其实不确定,可能是 98 或 102,但教师给不了这个信息
D-FINE 之后(分布教学):
- 教师说:"边界在 y=100 的概率是 70%,在 y=98 的概率是 20%,在 y=102 的概率是 10%"
- 学生学到:
- 什么对:最可能是 100
- 什么错但接近:98 和 102 虽然不完全对,但很接近(概率 20%)
- 什么错且离谱:y=50 的概率是 0%,完全不对
这就是你说的 "不仅教什么对,还教什么错,以及为什么错"。
2. "离散值让教学成为可能"的深层含义
你提到的"离散值"很关键。这里的离散有两层含义:
关键突破:正是因为变成了 32 个离散值的概率分布,才能用 KL 散度衡量教师和学生分布的差异,蒸馏才能进行。
3. "错误中学习"在定位中的特殊意义
在分类中,"错误"可能是"把猫认成狗";在定位中,"错误"是模糊性本身:
- 大象的腿被草遮挡:教师输出平坦分布
[0.2, 0.2, 0.2, 0.2, 0.2](不确定具体在哪)- 学生学到:这里边界是模糊的,允许一定误差,不要强行精准定位
这比硬标签(强行说"边界就在 y=100")更合理,因为遮挡本身就是不确定的。
D-FINE 把定位从"是非题"(只有一个答案)变成了"选择题"(32个选项的概率分布),让教师可以传递"虽然选A,但B和C也有道理"的暗知识,这才是知识蒸馏在检测中可行的根本原因。

研究背景:

早期的分布相当于我们只能学习这个值,如果这样的话就不能对模糊性进行建模,那么现在我们用一个分布来表示这个位置。 这里的第三部分的粗定位,就是上上图的 采样间隔,就是bin的宽度,中间的值会选取的值,bin 的宽度会影响精度 ,所以工作要解决上面三个问题。
采样间隔,就是bin的宽度,中间的值会选取的值,bin 的宽度会影响精度 ,所以工作要解决上面三个问题。
D-fine的核心创新就是:细粒度分布细化,将回归重新定义为分布的逐步细化;定位蒸馏:利用教师模型的分布知识指导学生,传递“边界模糊程度”的信息;用分布代替单一数值,既能表达精确定位,也能表达模糊行为,解决了小目标和遮挡场景的定位难题、
具体工作--FDR细粒度分布细化
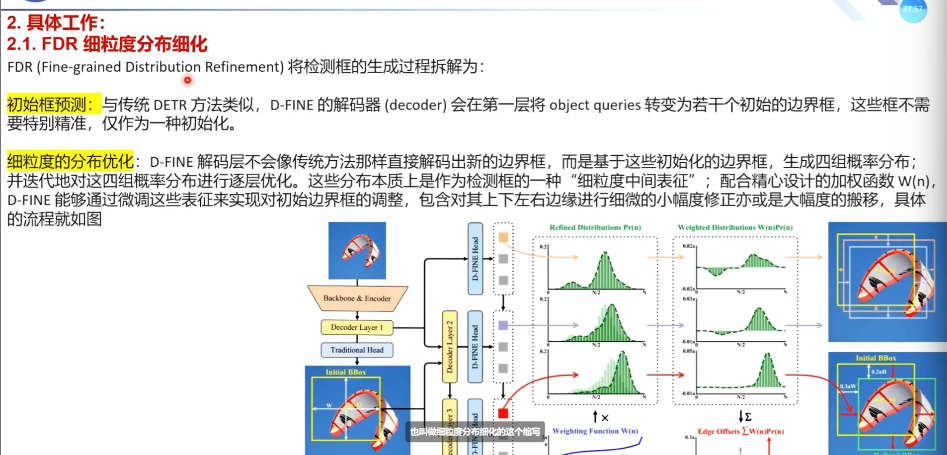
首先进行初始的box的预测
第一层decoder layer会进行位置的粗定位
回顾下backbone和encoder
backbone:
通常采用ResNet-50或HGNetv2
输入就是图像;输出就是多尺度大的特征图“c3,c4,c5”:分别是高分辨率,适合小目标;中分辨率,适合中等目标;低分辨率,适合大目标;
做了局部特征提取,用卷积神经网络扫描图像,提取每个位置的视觉特征;多尺度表示:像金字塔一样,同时表留细节和语义,就是大目标和小目标;
define的backbone没有特殊改动,就是标准的CNN骨干
encoder
transformer结构,是detr系列的核心
输入:就是backbone提取的多尺度特征图,通过自注意力(self-attention)机制,让每个像素看到图像其他所有位置
输出:memory(记忆库,形状bs,H*W,256)
D-fine使用的encoder包括两部分:跨尺度特征融合(CCFM)把大中小三层特征融合在一起,让高分辨率特征带有语义信息,低分辨率特征带有细节信息;transformer编码(AIFI)用多头自注意力机制建模全局关系,比如这个像素是桌子腿,那他下面有地面,建立长距离依赖、
输出的memory是啥:高级特征地图:这个位置存储量一个256维的向量,包含了位置的视觉信息+与全图其他位置的关系信息;encoder会查询这个memory来定位物体
第一层的定位相对粗糙,后面每次根据概率进行细化?四组概率分布就是四个边
不会向传统方法直接解析出新的边界框,而是根据初始化的边界框解析出四组概率分布并迭代的对这四组概率分布进行逐层优化,四个概率分布就是框的四个边,还这几了一个加权函数w(n)这样更加精细化对初始边界框的调整,小幅度或大幅度的调整
得到初始边界框的位置,define的头得到了细化的分布表征,细化的分布表征和加权函数处理后得到了细化的偏移量,偏移量对初始边界框进行调整,就是逐层细化优化的过程。
看一下FDR的细节:

pr(n):就是四个独立的分布,每个边一个分布
中心点的距离离得比较近的话,也可以进行这个比较精细的调整(ac是控制函数上界和曲率的超参数),相对应的话,差得远,加的权重也大。w的形状根据ac。最终会得到偏移量。
核心思想就是:不直接预测最终的坐标,而是预测“如何修正”的分布、
- 在每次迭代的时候进行细化,每层都在修正上一层的预测。
- 加权函数w(n)决定如何从32个离散bins得到连续偏移量,
- pr(n)就是概率分布,是32个数,是模型预测。我认为边界在第n个bin的概率是多少
- w(n),就是一个权重函数,是固定公式,是人工设计的(ac决定),第n个bin应该对应多少像素的偏移量
look!!!!!!!!!!!!!!!!!!!


回顾DFL
传统检测把bbox回归当成回归问题(就是预测单个数值)DFL把他变成分类问题(预测32个bins的概率分布)
dfl的任务不是直接预测一个边界的具体位置(比如距离图片顶部150.6像素)而是预测“上边界在0-320像素范围内,落在哪个区间的概率分布” (假设reg—max=32,每格代表10像素)
把上边界的预测范围【0,320】切成32格
情况A:上百年将诶清晰(猫背对天空,轮廓明显)
输出概率
bin 0-14: 0.00, 0.00, ...(几乎为0)
bin 15: 0.70 ← 高概率
bin 16: 0.28 ← 次高概率(因为150.6靠近160)
bin 17-31: 0.00, 0.01...(几乎为0)图像表现:概率分布是尖锐的单峰(集中在15-16)。
计算出的上边界位置: ytop=0.70×155+0.28×165+...≈153.8 像素
(很接近真实值 150.6,误差小)
情况B:上边界模糊(猫头被树叶遮挡,分不清哪是头哪是树叶)
模型输出的32个概率
bin 0-10: 0.00...
bin 11: 0.10
bin 12: 0.15
bin 13: 0.20
bin 14: 0.25
bin 15: 0.20
bin 16: 0.10
...图像表现:概率分布平坦分散(11-16都有概率)。
含义:模型在"说"——"上边界可能在树叶这里(bin 14),也可能在猫头这里(bin 15),我不太确定,但大概在这个范围"。
计算出的上边界位置: ytop=0.10×115+0.15×125+...≈142 像素
(介于树叶和真实猫头之间,模型选择了"平均"位置)
DFL 让模型对图像的每一条边(上/下/左/右)都画一条"概率热力带":
颜色深的地方(概率高):模型觉得边界大概在这里
颜色浅的地方(概率低):模型觉得边界不太可能在这里
热力带的宽窄:代表模型对这条边界的自信程度(越窄越自信)
最终画的框:是这条热力带的重心(加权平均位置)。
这样,当猫头被树叶遮挡(模糊)时,模型不会死磕一个确定位置,而是给出一个"大概在树叶和猫头之间"的合理估计;当猫背对天空(清晰)时,模型会给出非常尖锐、精准的定位。
FGL(D-FINE专属)
1.双bin软监督,解决DFL的硬分配问题:
比如GT在bin15和bin16之间,DFL之监督bin15(最近的那个),16视为错误,浪费了15和16之间的信息
但是FGL就是软监督,同时监督bin15和bin16,根据距离进行价钱,gt离15更进,离16更远,那概率就会以4:6分配,(在公式里是反向关系 要注意)
2.IoU感知加权(解决“盲目学习”的问题)
不管当前框画的好不好(iou高或者低),DFL都用同样强度监督。
FLG:
计算当前预测框和GT的IoU(重叠度),iou(框已经很准):增大损失权重,强迫分布更加尖锐(模型要“自信”);iou低(框很偏):相对放宽,允许分布散一些,先保证大方向对。
FGL 让模型不再"非此即彼"地选 bin,而是在 GT 附近的两个 bins 上"和稀泥"(按距离分配概率),同时根据当前定位质量(IoU)调整学习强度——定位准的必须更自信,定位差的允许先模糊着。
这样比 DFL 更精细(sub-bin 精度)、更可靠(质量感知)。
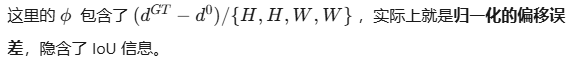

具体工作--全局最优定位自蒸馏的
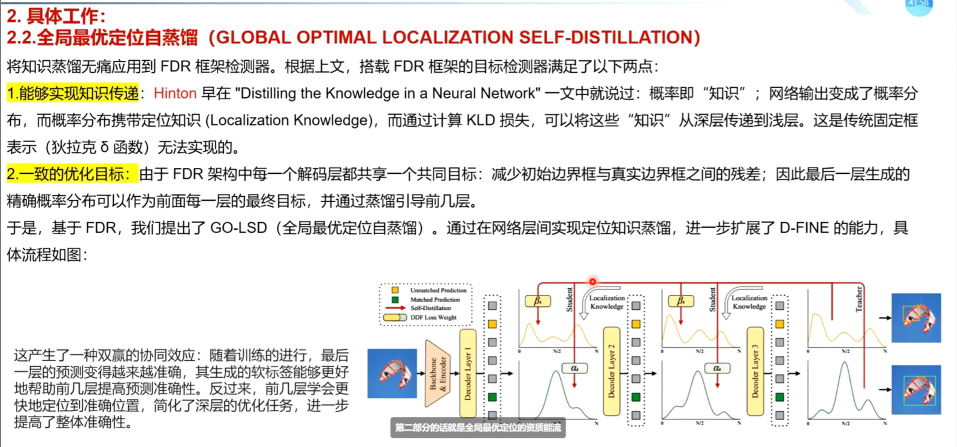
深层的decoder指导浅层的decoder学习,实现层间知识传递。
传统训练有问题,各层是独立优化,每层只和自己的GT算损失,浅层不知道后面还有更准的预测,没办法利用深层的知识,所以让最后一层当老师,教前几层怎么预测

GO-LSD的具体实现细节,匈牙利匹配和解耦蒸馏焦点损失如何解决“哪些框需要被蒸馏”以及““怎么加权的”问题
多层decoder中,每层都会预测很多框,比如跨层框的对应关系,第一层和第二层的第五个query 是一个物理位置吗?并不是,每层都在修正位置,query的参考点在变化,那么每层都要做匈牙利匹配,找出盖层中和GT最匹配的框
全局匹配:将所有层的匹配结果取并集,形成一个全局最优候选集

完整工作流程D-FINE
1.特征提取
输入图像 (640×640)
↓
[Backbone: ResNet/HGNetv2]
↓ 提取多尺度特征 (C3, C4, C5)
[Encoder: Hybrid Transformer]
↓ 全局编码 & 特征融合
输出: Memory (特征记忆库, shape: bs, H×W, 256)看懂图像内容,建立全局上下文,为后续定位提供“参考资料”。
阶段2:FDR解码(核心:细粒度分布细化)
从第0层初始化,粗定位生成初始边界框,并将初始边界框转化为到四条边的距离表示
之后逐层迭代细化:分布预测-加权求和-修正框:
1.首先预测分布pr(n)输出32个概率值
2.加权函数w(n)查表
3.计算偏移量△d(结合pr(n)和w(n)共同计算偏移量)
4.修正边界
并行处理:四条边(上下左右)同时独立做上述的操作,各自预测自己的32-bin分布
迭代效果:1.第一层:分布平坦(不确定)偏移大(粗调)
2.第 3 层:分布开始集中(逐步确定)
3.第 6 层:分布尖锐(很确定),偏移微小(精调)
阶段2:训练时的辅助机制(让模型学的更好)
定位蒸馏--学生不仅学框子在哪。还要学习边界是否模糊
GO-LSD(全局最优定位自蒸馏)--D-FINE自带:
问题:浅层预测差,但是深层预测好,传统就是训练各层独立学。但是解决就是深层教浅层,首先匈牙利匹配,层间蒸馏,DDF加权(匹配框:(正样本)按iou加权定位准的多教;未匹配框(背景):按置信度加权(难分的背景多教))
这样的话,浅层学的快,而且深层任务也简单了,因为深层教得好,而且浅层基础也打好了
补充定位蒸馏
教师模型的输出:
bin 14 (y=140): 0.05
bin 15 (y=150): 0.75 ← 主峰,最可能在这里
bin 16 (y=160): 0.15 ← 次峰,也有可能
bin 其他: 接近 0形状:尖锐的单峰(高瘦)
含义:教师在说——"边界大概在 150(bin 15),但可能是 149 或 151(bin 14 或 16),不过我很确定不会偏离太远(其他 bin 概率接近 0)"
学生模型的输出:bin 10: 0.2
bin 14: 0.3
bin 15: 0.3
bin 20: 0.2形状:平坦分散(矮胖)
含义:学生现在很迷茫——"我觉得可能在 140-200 之间?不太确定..."
蒸馏 过程(KL散度在做啥)
损失函数:KL(学生分布∥教师分布)
优化目标:让学生的 32 个概率值,尽量靠近教师的 32 个概率值。
训练后,学生变成:
bin 14: 0.08
bin 15: 0.80 ← 概率提高,向教师靠拢
bin 16: 0.10 ← 概率提高,向教师靠拢
bin 其他: 接近 0学生学到了什么?
位置:边界应该在 bin 15 附近(150 像素),不是 bin 10 也不是 bin 20
确定性:这个边界很清晰(分布要尖锐),不应该模棱两可(平坦)
D-FINE 工作流:图像进 Backbone/Encoder 提特征 → 6层 Decoder 逐层玩"大家来找茬"(每层预测 32-bin 分布,用 W(n) 算偏移,修正上一层的框)→ 第6层输出精准框。训练时,深层教师指导浅层学生(GO-LSD),大模型指导小模型(定位蒸馏),让分布预测又快又准。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 5
5 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)