▲基于PPO强化学习的3自由度机械臂控制系统matlab仿真
目录
1.引言
近端策略优化(Proximal Policy Optimization, PPO)是一种策略梯度类强化学习算法,由OpenAI的John Schulman于2017年提出。PPO通过限制策略更新的幅度,在保证训练稳定性的同时实现高效的策略优化。将PPO应用于3自由度(3-DOF)机械臂控制系统,智能体通过与环境的反复交互,自主学习各关节的最优控制策略,最终实现精确的末端执行器定位与物体抓取。
3自由度机械臂由三个旋转关节组成,分别记为𝜃1 、θ2、𝜃3。通过控制这三个关节角度的变化,驱动末端执行器到达三维空间中的目标位置。传统控制方法(如PID、逆运动学求解)需要精确的数学模型,而基于PPO的强化学习方法则通过"试错—奖励"机制自动学习控制策略,具有更强的鲁棒性和泛化能力。
2.机械臂运动学模型
采用Denavit-Hartenberg(D-H)参数法建立机械臂的正运动学模型。设三段连杆长度分别为𝐿1、𝐿2、𝐿3 ,三个关节角分别为𝜃1 、𝜃2 、𝜃3 。其中𝜃1控制绕竖直轴(𝑧轴)的水平旋转,𝜃2和𝜃3控制在竖直平面内的俯仰运动。末端执行器在三维空间中的位置(x,y,z)由以下正运动学公式计算:

3.PPO强化学习建模
采用广义优势估计(GAE)来计算优势函数,降低方差的同时控制偏差:
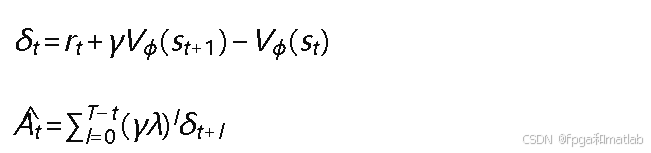
其中𝛾为折扣因子,𝜆为GAE参数,𝛿𝑡为时序差分误差。
PPO的核心思想是通过截断(Clipping)限制策略更新幅度。定义概率比:

价值网络通过最小化以下均方误差来更新:

PPO的总损失函数结合策略损失、价值损失和熵正则项:

4.MATLAB仿真程序
% Actor网络参数初始化
actor.W1 = randn(hiddenSize, stateDim) * 0.01;
actor.b1 = zeros(hiddenSize, 1);
actor.W2 = randn(hiddenSize, hiddenSize) * 0.01;
actor.b2 = zeros(hiddenSize, 1);
actor.W3 = randn(actionDim, hiddenSize) * 0.01;
actor.b3 = zeros(actionDim, 1);
actor.logStd = zeros(actionDim, 1) - 0.5;% Critic网络参数初始化
critic.W1 = randn(hiddenSize, stateDim) * 0.01;
critic.b1 = zeros(hiddenSize, 1);
critic.W2 = randn(hiddenSize, hiddenSize) * 0.01;
critic.b2 = zeros(hiddenSize, 1);
critic.W3 = randn(1, hiddenSize) * 0.01;
critic.b3 = zeros(1, 1);%% ==================== 3. PPO超参数 ====================
numEpisodes = 1000;
maxSteps = 2000;
gamma_disc = 0.99;
lambda_gae = 0.95;
epsilon_clip = 0.2;
lr_actor = 3e-4;
lr_critic = 1e-3;
ppo_epochs = 4;
miniBatchSize = 64;
entropy_coeff = 0.01;
其中,正运动学模块根据D-H参数计算末端执行器三维坐标;神经网络实现两层全连接网络(tanh激活),包含前向传播和反向传播;PPO训练循环,采集轨迹→GAE优势估计→多轮小批量梯度更新。
5.仿真结果分析
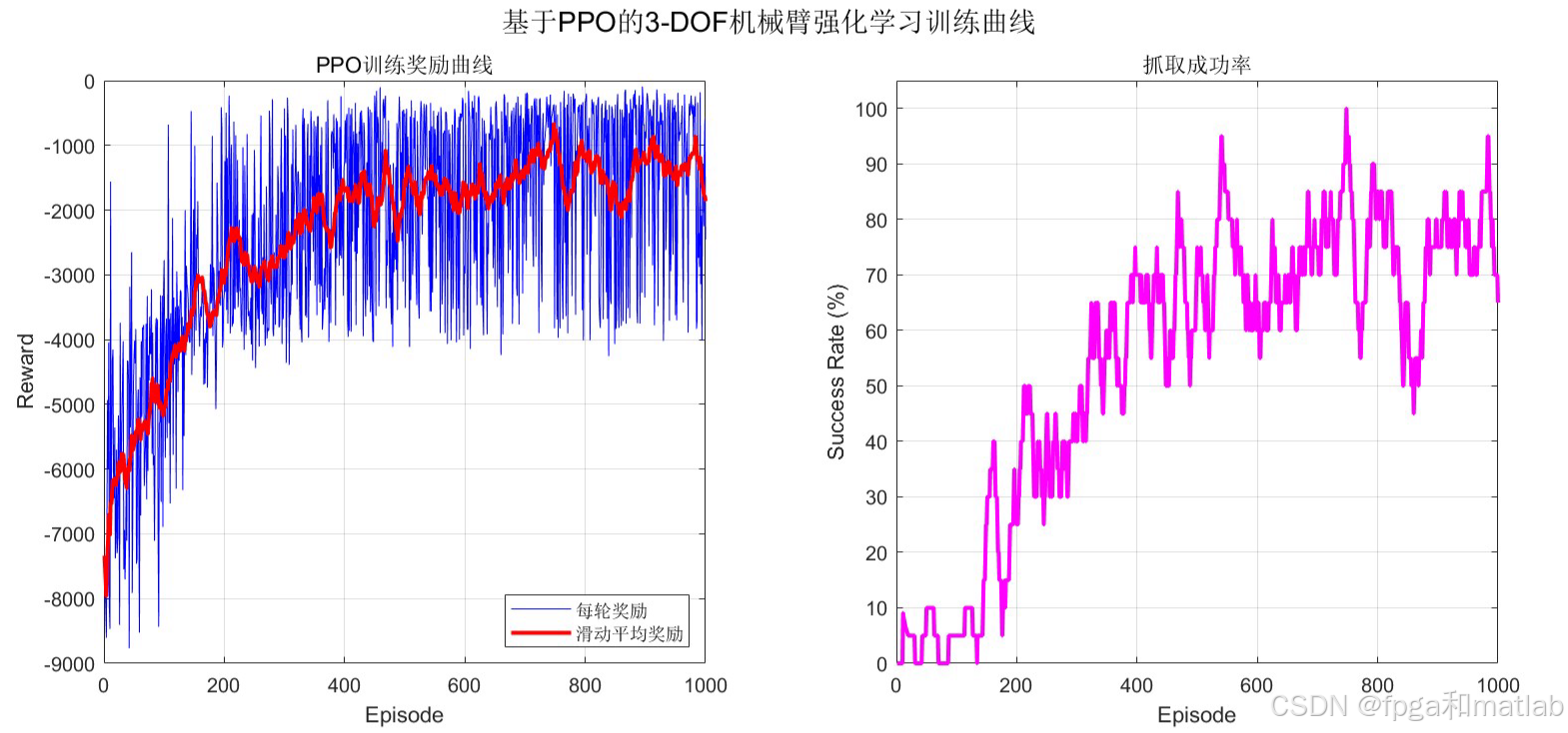
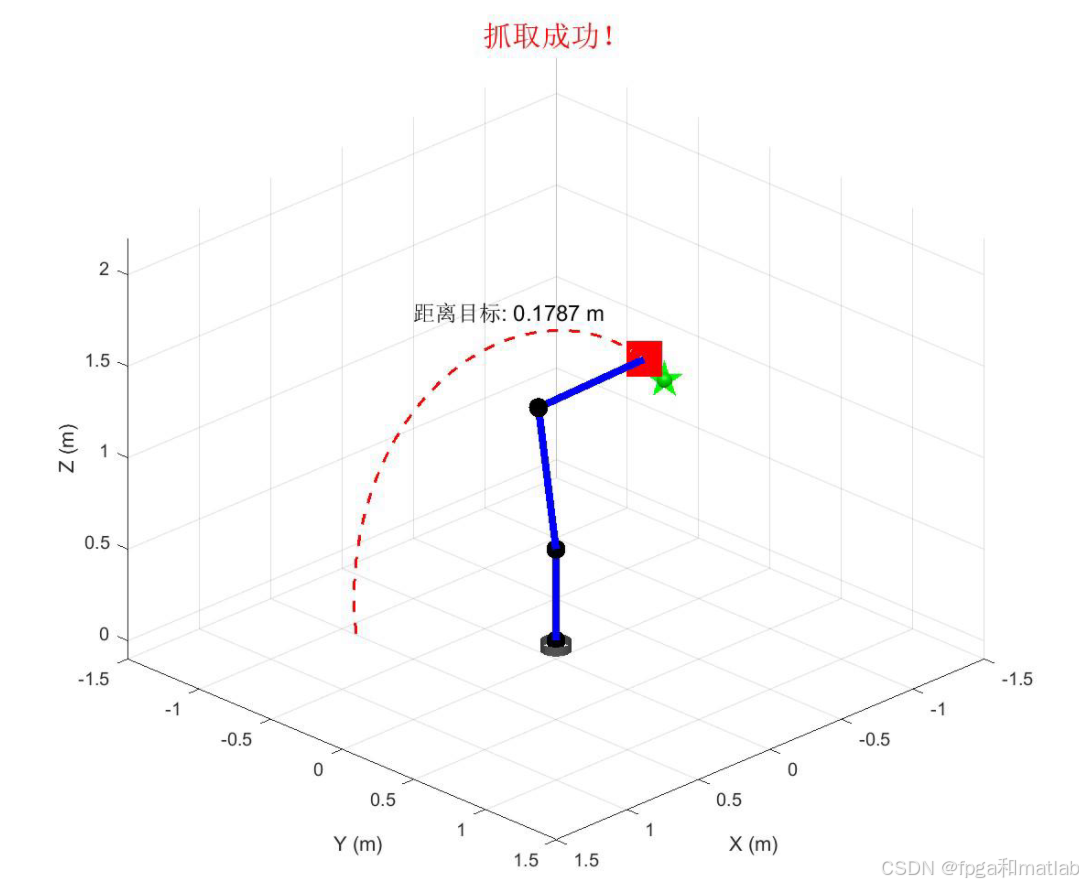
6.完整程序下载
完整可运行代码,博主已上传至CSDN,使用版本为MATLAB2024b:
(本程序包含程序操作步骤视频)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 5
5 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)