大模型Harness工程详解
定义与介绍
- 提示词工程, rag工程, agent 工程分别是什么
- 什么样的工程才叫/ 才能叫harness 工程? 与上面的三种有什么区别?
背景与发展
提示词工程(Prompt Engineering):通过设计、优化输入给 LLM 的文本(系统提示、少样本示例、指令格式等),引导模型产生期望输出。核心工作对象是"一次调用"的输入输出质量。
RAG 工程(Retrieval-Augmented Generation Engineering):在模型推理前,先从外部知识库(向量数据库、搜索引擎、文档系统等)检索相关信息,注入上下文后再让模型生成回答。核心工作对象是"知识获取与注入"的管道。
Agent 工程(Agent Engineering):赋予 LLM 工具调用、规划、多步推理和行动能力,使其能自主完成复杂任务(如调用 API、执行代码、与环境交互)。核心工作对象是"自主决策与行动"的循环。
Harness 工程(Harness Engineering):为 agent 构建完整的运行环境和支撑体系,使其能在真实、长期、大规模的生产场景中可靠工作。核心工作对象不是 agent 本身,而是 agent 赖以运行的整个"基础设施"。
Harness 工程的具体内涵 - 定义
“Harness"直译是"挽具”——套在马身上让马能拉车的装置。马有力量(agent 有能力),但没有挽具它无法有效做功。
harness 工程至少包含以下维度:
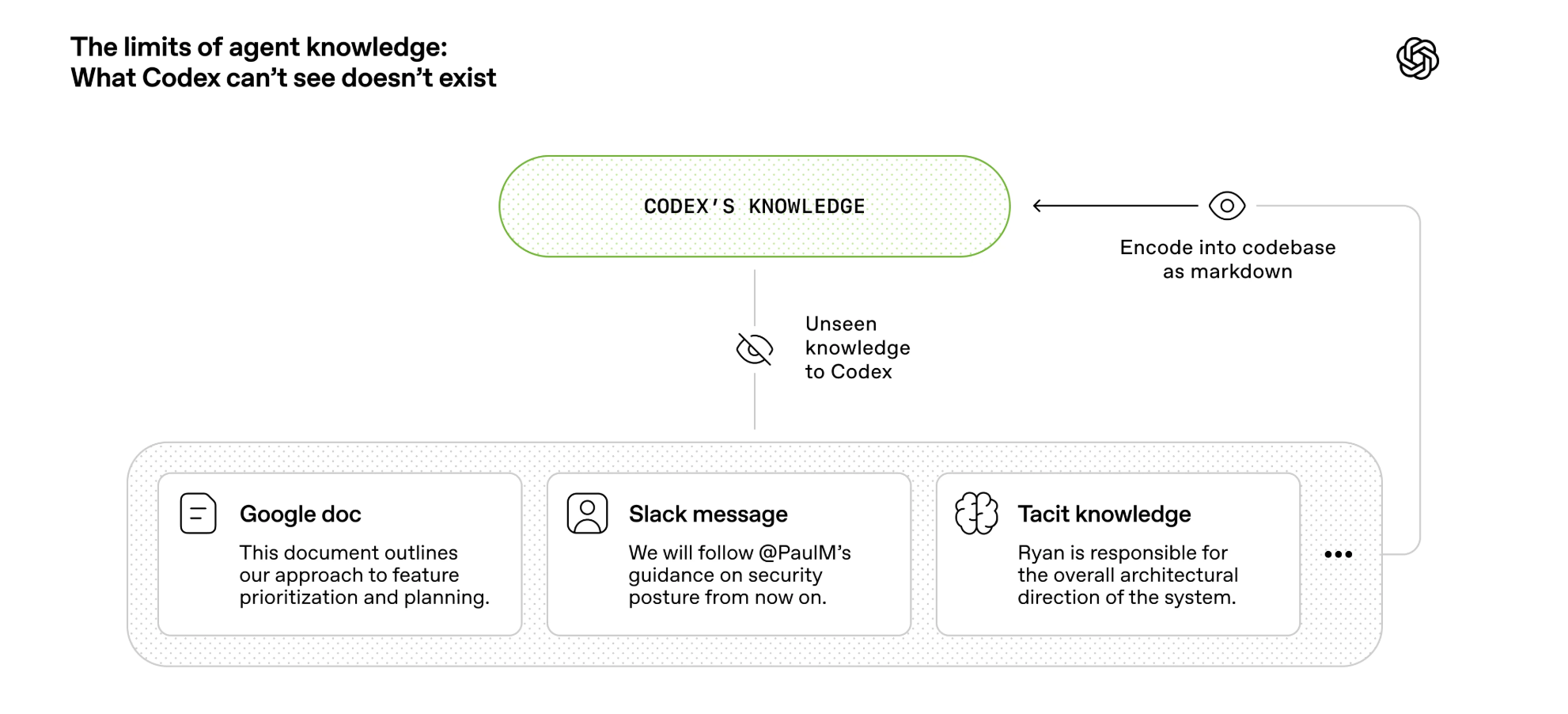
环境可读性——让 agent 能"看见"它需要的一切。OpenAI 团队将 AGENTS.md 做成目录而非百科全书,建立结构化的 docs/ 知识库,把 Slack 讨论、隐性知识编码进代码仓库。LangChain 的 harness 提供虚拟文件系统、Skills 渐进式加载、Memory 持久化。
本质是同一件事:把 agent 运行时的情境(环境)设计好。
Slack 讨论 是什么?
OpenAI 文章中举了一个具体例子:团队曾在 Slack 里讨论并达成了某个架构模式的共识。但问题在于,Codex agent 无法访问 Slack 聊天记录——它只能看到代码仓库里的内容。所以如果这个决策没有被写进仓库,agent 就完全不知道,就像一个迟到三个月入职的新员工一样对此一无所知。
约束与护栏——用机械化手段(linter、结构测试、CI 门禁、分层架构校验)强制执行不变量,而非指望 agent 自觉遵守。OpenAI 团队的自定义 lint 错误信息甚至会直接注入修复指令。LangChain 的 harness 通过 human-in-the-loop 中断机制实现类似目的。
规则图谱约束
- 一般较宽松(非常底层的约束), 强调大模型的tools 调用是否可靠。
依赖人类反馈 – Human loop :
- 确认 yes / no
linter 是什么?
Linter 是一种静态代码分析工具,在代码运行之前自动扫描代码,检查是否违反预设规则。比如:变量命名不规范、文件过大、依赖方向错误、缺少结构化日志等。
OpenAI 团队的特别之处在于:他们的 linter 是自定义的,而且错误信息里直接嵌入了修复指令。这样 Codex 看到 lint 报错时,就能直接知道该怎么修,不需要人类介入解释。这就是把"品味"编码为机械化约束的典型做法。
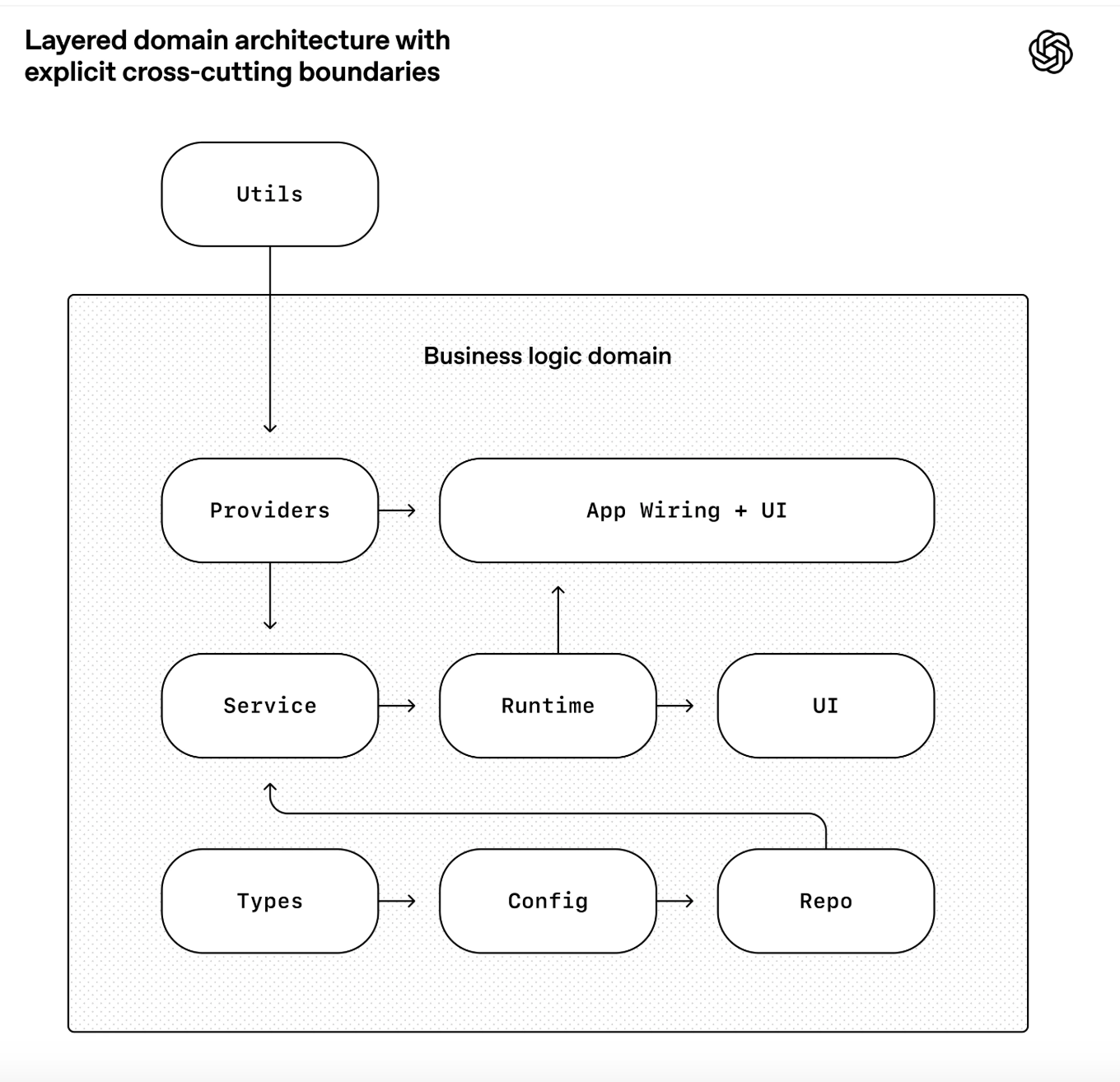
让我想到,在java spirngboot项目里软件开发里 里常用的:
Controller (RESTful API)
→ 依赖 Service (接口/抽象层)
→ 依赖 DTO (数据传输对象)Service (接口)
→ ServiceImpl (实现类)
→ 依赖 Repository/DAO (数据访问层)
→ 依赖 Entity/Model (数据库实体)所有层都可以使用:
- Config (配置类 / application.yml)
- Utils (通用工具类)
- ENV (环境变量)
反馈回路——agent 的输出能被自动验证、纠正、迭代。OpenAI 团队让 Codex 能启动应用、截屏、查日志、查指标、自我审查 PR,形成闭环。LangChain 的 harness 通过代码执行沙箱、子代理委派实现同类能力。
Debug 能力
上下文管理——在 token 有限的条件下,让 agent 始终持有最相关的信息。LangChain 的 harness 提供压缩、摘要、子代理隔离。OpenAI 团队的"地图而非说明书"策略、渐进式披露都是上下文工程。
详细的展开:
地图而非说明书
渐进式纰漏
“地图而非说明书”
OpenAI 团队最初尝试把所有指导信息塞进一个巨大的 AGENTS.md 文件——相当于给 agent 一本 1000 页的说明书。结果失败了,原因有四个:巨大的指令文件挤占了 token 空间,导致 agent 看不到真正重要的任务信息和代码;当所有内容都标记为"重要"时,agent 无法区分优先级;庞大文件很快过时且无人维护;单一大文件无法被自动化工具检查和校验。
他们的解决方案是:AGENTS.md 只保留约 100 行,充当一份"目录"或"地图",告诉 agent “关于架构请看 docs/DESIGN.md”、“关于前端规范请看 docs/FRONTEND.md”、“关于安全请看 docs/SECURITY.md”。agent 需要某个领域的知识时,按图索骥去读对应文档即可。
类比:你去一个陌生城市,给你一张标注清晰的地图(地图),远比给你一本 800 页的城市百科全书(说明书)更有效。你只需要按需查看感兴趣的区域。
渐进式披露(Progressive Disclosure)
这是"地图"策略的延伸原则:agent 启动时只加载最小量的核心信息(那份 100 行的 AGENTS.md),然后根据当前任务的需要,逐步加载更深层的文档。
LangChain 的 Skills 机制也采用了同样的设计:agent 启动时只读取每个 SKILL.md 的 frontmatter(元数据摘要),判断当前任务可能需要哪个 skill,才去加载该 skill 的完整内容。
核心逻辑:token 是稀缺资源,不要一开始就把所有信息塞满上下文窗口,而是让 agent 按需获取。先给概览,需要时再展开细节。
规模化运维——处理 agent 高吞吐带来的新问题:合并策略调整、技术债"垃圾回收"、doc-gardening 自动化、agent 审查 agent。这超出了单个 agent 的能力范围,是系统层面的工程。
doc-gardening 自动化?
“Doc-gardening"直译是"文档园艺”——像打理花园一样维护文档。
OpenAI 团队设置了一个定期运行的 Codex 任务,它会自动扫描 docs/ 目录下的所有文档,检查哪些文档的描述已经与实际代码行为不一致(过时),哪些文档已经废弃但还留在那里。发现问题后,这个 agent 会自动发起 PR 来修复。
配合专职的 linter 和 CI 作业,它们会验证文档是否保持交叉链接、结构正确、内容新鲜。这样代码仓库作为"记录系统"才不会腐烂。
技术债是指为了快速交付而留下的不够理想的代码或设计,它们像债务一样,不还就会产生"利息"(让后续开发越来越慢、越来越容易出错)。 — 这个目前cc 做的不是很好。
在 Codex 的场景下,技术债有一个独特来源:agent 会复现代码仓库中已有的模式,包括那些不好的模式。比如某处手写了一个辅助函数而没用共享工具包,agent 会在别处也这样做,导致坏模式扩散。
最初团队每周五花 20% 的时间手动清理这些"AI 残渣",但这不可扩展。
他们的解决方案是建立自动化的循环清理流程:首先把"黄金原则"编码进仓库(比如"优先使用共享工具包而非手写辅助函数"、“不允许未经验证的探测数据”),然后定期运行一组后台 Codex 任务,这些任务会扫描代码库中与黄金原则不符的偏差,更新质量评分,并自动发起有针对性的重构 PR。大多数 PR 可以在一分钟内审查并自动合并。
文章将此比作编程语言中的垃圾回收(GC):与其让垃圾堆积到不得不大规模清理(stop-the-world GC),不如持续小额清理(incremental GC),保持代码库始终健康。
对比与总结
关系梳理与总结:
| 维度 | 提示词工程 | RAG 工程 | Agent 工程 | Harness 工程 |
|---|---|---|---|---|
| 关注尺度 | 单次调用 | 检索+单次调用 | 多步任务 | 持续运行的生产系统 |
| 核心问题 | “怎么问” | “带什么知识问” | “怎么规划和行动” | “怎么让 agent 在真实环境中可靠、持续地工作” |
| 时间跨度 | 毫秒级 | 秒级 | 分钟到小时 | 天到月(跨越整个产品生命周期) |
| 工程师角色 | 编写提示 | 构建检索管道 | 设计工具和推理流程 | 设计环境、定义约束、构建反馈回路 |
| 类比 | 给马下口头指令 | 给马看地图 | 教马自己找路 | 修好道路、装好挽具、设好围栏 |
它们是层层包含的关系:harness 工程内部会用到 agent 工程,agent 运行中会用到 RAG,RAG 和 agent 的每次模型调用都涉及提示词工程。但 harness 工程的核心关切已经不在模型层面,而在于系统层面的可读性、约束、反馈和可维护性——正如 OpenAI 文章的核心论点:当工程师的主要工作不再是写代码,而是设计环境、明确意图、构建反馈回路时,这就是 harness 工程。
实现与事例
- 工作流 , 最简单的harness工程是什么?
- claude code 是如何体现harness 工程的? // todo
第一性原理:出发点
一个 agent 要完成任务,本质上需要三样东西:
- 知道做什么(意图)
- 知道怎么做(能力)
- 知道做得对不对(反馈)
提示词工程解决的是第 1 点,agent 工程解决的是第 2 点。但如果没有第 3 点,agent 就是在黑暗中行动——可能做对,可能做错,没人知道。
Harness 工程的本质就是:构建一个环境,使 agent 能持续获得反馈并据此自我纠正。
– > 环境意味着边界(上下文管理), 反馈意味着迭代与收敛
最简单的 Harness:一个反馈回路
最小可行的 harness 工程就是一个闭环工作流:
人类意图 → agent 执行 → 自动验证 → 通过则完成 / 不通过则重试
具体来说,你只需要三个要素:
一份清晰的指令(不是巨型文档,而是 agent 能理解的任务描述)。这是"地图"。
一个可执行的验证手段(测试、lint、类型检查、截图对比——任何能机械判断"对不对"的东西)。这是"护栏"。
一个重试机制(验证失败时,把失败信息反馈给 agent,让它再来一次)。这是"回路"。
举一个最简单的真实例子
假设你想让 agent 写一个函数:
没有 harness 的做法:给 agent 一个提示,拿到输出,人眼看对不对。
最简单的 harness 做法:先写好测试用例(输入 X 应返回 Y),让 agent 写函数,自动运行测试,测试失败则把错误信息喂回给 agent 让它修,循环直到测试通过。
这里面没有什么高深的基础设施。测试就是你的验证手段,重跑就是你的反馈回路。但它已经构成了一个 harness——agent 不再是单次射击,而是在一个有约束、有反馈的环境中工作。
基于最小回路的多维扩展
OpenAI 文章描述的复杂系统,本质上是这个最小回路在多个维度上的扩展:
| 最小 harness | 扩展后 |
|---|---|
| 测试用例验证正确性 | 加上 linter 验证风格、结构测试验证架构 |
| 人类写测试 | agent 自己写测试,再由另一个 agent 审查 |
| 单次任务 | 长期运行,需要上下文管理和渐进式披露 |
| 一个 agent | 多个 agent 协作(子代理、agent 审查 agent) |
| 人类手动检查文档 | doc-gardening agent 自动维护 |
| 人类手动清理坏模式 | 垃圾回收 agent 定期扫描修复 |
每一层扩展都是因为某个瓶颈出现了:人类时间不够、上下文窗口不够、坏模式在扩散、文档在腐朽。然后针对这个瓶颈,把人类的判断编码为自动化约束,加入系统。
最简单的 harness 工程 = 给 agent 一个能自动判断对错的环境,并让它在失败时能重试。一切更复杂的 harness,都是这个基本回路的叠加与组合。
启发与思考
- 如何让harness 工程变得通用? 其通用点在于什么?从第一性原理出发, 我们在构建其他工程的时候需要注意什么
不变的是结构,变化的是内容
无论你让 agent 写代码、写文档、做数据分析、管理项目还是运营客服,底层结构都是同一个:
意图传递 → 执行 → 验证 → 反馈 → 纠正
这个循环是通用的。变化的只是每个环节的具体实现。
| 通用结构 | 写代码场景 | 写文档场景 | 数据分析场景 |
|---|---|---|---|
| 意图传递 | AGENTS.md + 设计文档 | 风格指南 + 产品需求 | 分析目标 + 数据字典 |
| 执行 | 生成代码 | 生成文档 | 生成查询和图表 |
| 验证 | 测试 + lint + 类型检查 | 格式校验 + 事实核查 | 结果校验 + 统计检验 |
| 反馈 | 错误信息 + lint 输出 | 审阅意见 | 异常值报告 |
| 纠正 | agent 修改代码重跑 | agent 修改文档重跑 | agent 调整查询重跑 |
通用点:五个可迁移的原则
从两份材料和第一性原理中,可以提炼出五个不依赖具体领域的通用原则:
原则一:情境必须对 agent 可见且可发现
OpenAI 团队的核心教训是:agent 看不到的东西等于不存在。这与领域无关。无论做什么工程,第一步都是回答:agent 完成这个任务需要哪些知识?这些知识现在存储在哪里?agent 能访问到吗?
通用做法:把隐性知识显式化,把分散信息集中化,把非结构化内容结构化。载体可以是 Markdown、数据库 schema、API 文档——形式不重要,可发现性才重要。
原则二:约束用机械手段强制执行,不依赖 agent 自觉
OpenAI 用 linter 和结构测试强制架构规则。这个原则通用到几乎任何领域:你希望 agent 遵守的规则,不要写在说明里祈祷它遵守,而要变成一个能自动判定"违规/合规"的检查程序。
通用做法:问自己"这条规则能不能写成一个返回 true/false 的函数?"如果能,就把它编码为自动检查。如果不能,要么继续拆解直到可以,要么接受这里需要人类判断。
原则三:给地图不给说明书,按需披露 — > 可见性的特殊表现(上下文管理)
上下文窗口是有限资源,这在所有 LLM 场景中都成立。无论什么领域,一次性灌入全部信息都会降低 agent 表现。
通用做法:构建两层信息结构。第一层是索引/目录,始终在上下文中,告诉 agent “有哪些信息、在哪里”。第二层是详细内容,agent 按需加载。
原则四:验证手段必须独立于 agent 的生成过程
这是最容易忽略的一点。如果验证本身依赖 agent 的主观判断,那反馈回路就是自我循环,没有纠错能力。
通用做法:验证应该是"外部的、确定性的、可重复的"。写代码时是测试,写文档时可以是格式校验+交叉引用检查,做数据分析时可以是已知基准值对比。找不到确定性验证手段的地方,就是需要人类介入的地方。
原则五:持续清理,不让熵积累
agent 会复现环境中的模式,包括坏模式。这在任何领域都成立:如果你的文档模板有问题,agent 会用这个有问题的模板生成更多文档;如果你的数据处理管道有一个 hack,agent 会在别处复制这个 hack。
通用做法:定义"什么是好的"(黄金原则),然后设置定期扫描任务检测偏差,自动或半自动修复。频率要高于退化速度。
构建其他领域 Harness 时可以注意的点:
当为一个新领域构建 harness 时,可以依次回答以下问题:
关于可见性:agent 完成任务需要哪些知识?这些知识 agent 现在能访问到吗?如果不能,如何让它可访问?
关于约束:哪些规则是必须遵守的?其中哪些可以编码为自动检查?错误信息是否包含足够的修复指引?
关于情境管理:信息总量是否超出上下文窗口?是否建立了索引层和详情层的两级结构?
关于验证:有没有独立于 agent 的验证手段?这些验证是确定性的还是概率性的?概率性的部分由谁做最终判断?
关于持续维护:agent 运行会产生哪些退化?如何检测?如何修复?频率够不够?
Harness 和Agent 的关键区别
Agent 工程的目的:让 agent 能做事
核心问题是:agent 如何完成一个任务?
你在设计的是 agent 本身的能力——给它什么工具、怎么规划步骤、怎么调用 API、怎么决定下一步做什么。关注的是单次任务从开始到结束的执行路径。
Harness 工程的目的:让 agent 持续、可靠地做对事
核心问题是:怎么保证 agent 在长期、大规模运行中不跑偏?
你在设计的不是 agent 的能力,而是 agent 工作的环境——让它能看到正确的信息、自动发现自己做错了、在做错时被拦住、做完后有人(或有机制)验证结果、产生的垃圾被定期清理。
discuss
辨析: 我理解harness 工程就是规范化的agent工程,没有新鲜的东西。
Cc 回答:
你说服我了多少
大部分。
如果你把 agent 工程的定义拉得足够宽——包括能力扩展、上下文管理、约束设计、工具链配置、验证机制——那 harness 工程确实没有什么东西是"全新的"。它做的每一件事都可以归类到广义 agent 工程的某个子项下。
但我保留一个观点
Harness 工程的价值不在于它发明了新东西,而在于它改变了工程师的关注点和工作重心。
打一个类比:DevOps 也不是什么"全新的东西"。运维以前就有,CI/CD 以前就有,自动化测试以前就有。DevOps 做的事情拆开看,每一件都已经存在。但 DevOps 作为一个概念的意义在于:它告诉团队"你们的核心工作不再是写代码然后扔给运维,而是要把构建、测试、部署、监控作为一个整体来设计"。
Harness 工程也是类似的。它告诉你:当 agent 能力足够强之后,工程师的核心工作不再是让 agent 能做事(那是 agent 工程),而是把精力集中在设计环境、组织信息、构建验证机制、维护系统一致性上。这些事情在 agent 工程里都存在,但以前是次要的、零散的。Harness 工程把它们提升为主要工作。
所以你说"没有新鲜的东西"是对的。但"把已有的东西重新组织、重新定义优先级"本身就是有价值的——就像 DevOps 对软件工程的价值一样。
参考:
https://docs.langchain.com/oss/python/deepagents/harness
https://openai.com/zh-Hans-CN/index/harness-engineering/
https://mp.weixin.qq.com/s/q2btD-ySXSrCHnEUtH0gWg

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)