大数据组件-Spark
1.Spark介绍
Apache Spark是一个开源的分布式计算引擎,专为大规模数据处理设计。它提供了高效的内存计算能力,支持批处理、实时流处理、机器学习和图计算等多种任务。
- 核心特点
- 模型采用RDD:弹性分布式数据集
- 基于内存模型计算:
- 提供了多语言的支持,完善的生态,超强的通用封装,可以离线可以实时
2.spark架构
- 主从架构(几个主从架构的对比看一下)
3.spark运行模式
面试重点:原理,区别,不同模式下的任务提交流程
(1)local模式(一般用到本地的调试,本地模式)
(2)集群模式
①单集群模式(standalone模式,利用的spark自带的管理模式)
client模式(driver在客户端,常用于测试环境)
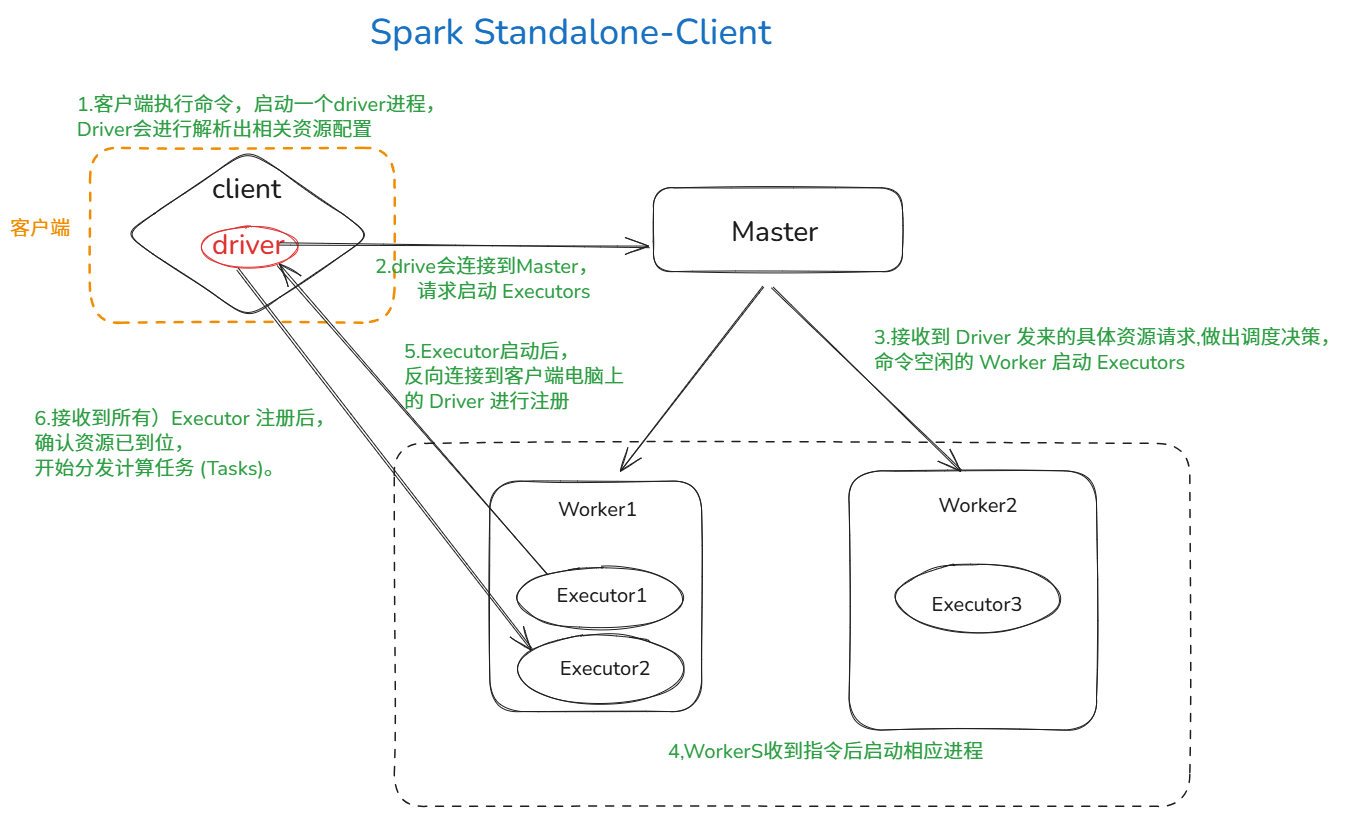
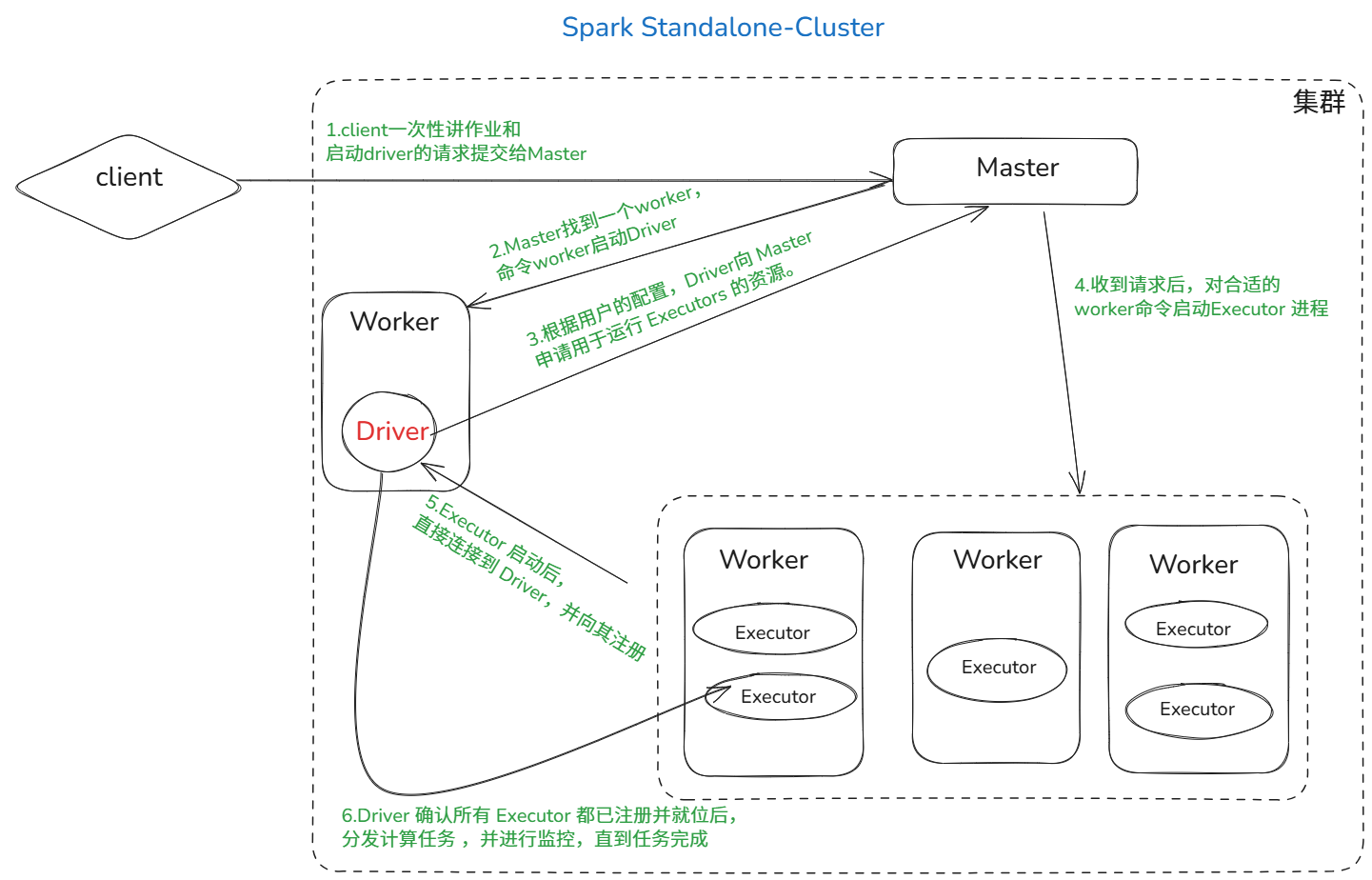
clustor模式(driver在集群中,常用于生产环境)
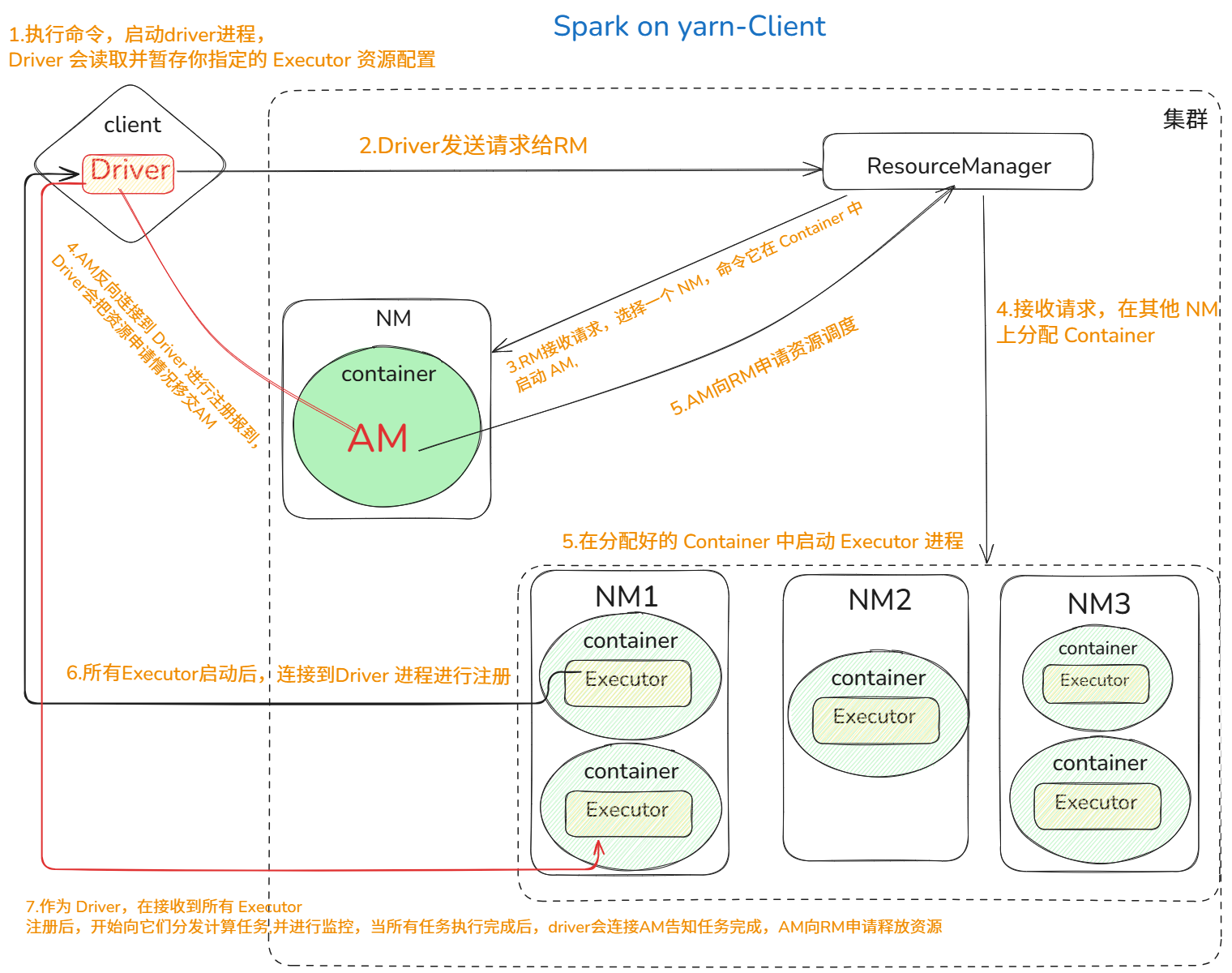
②集群模式( Spark on YARN)
client
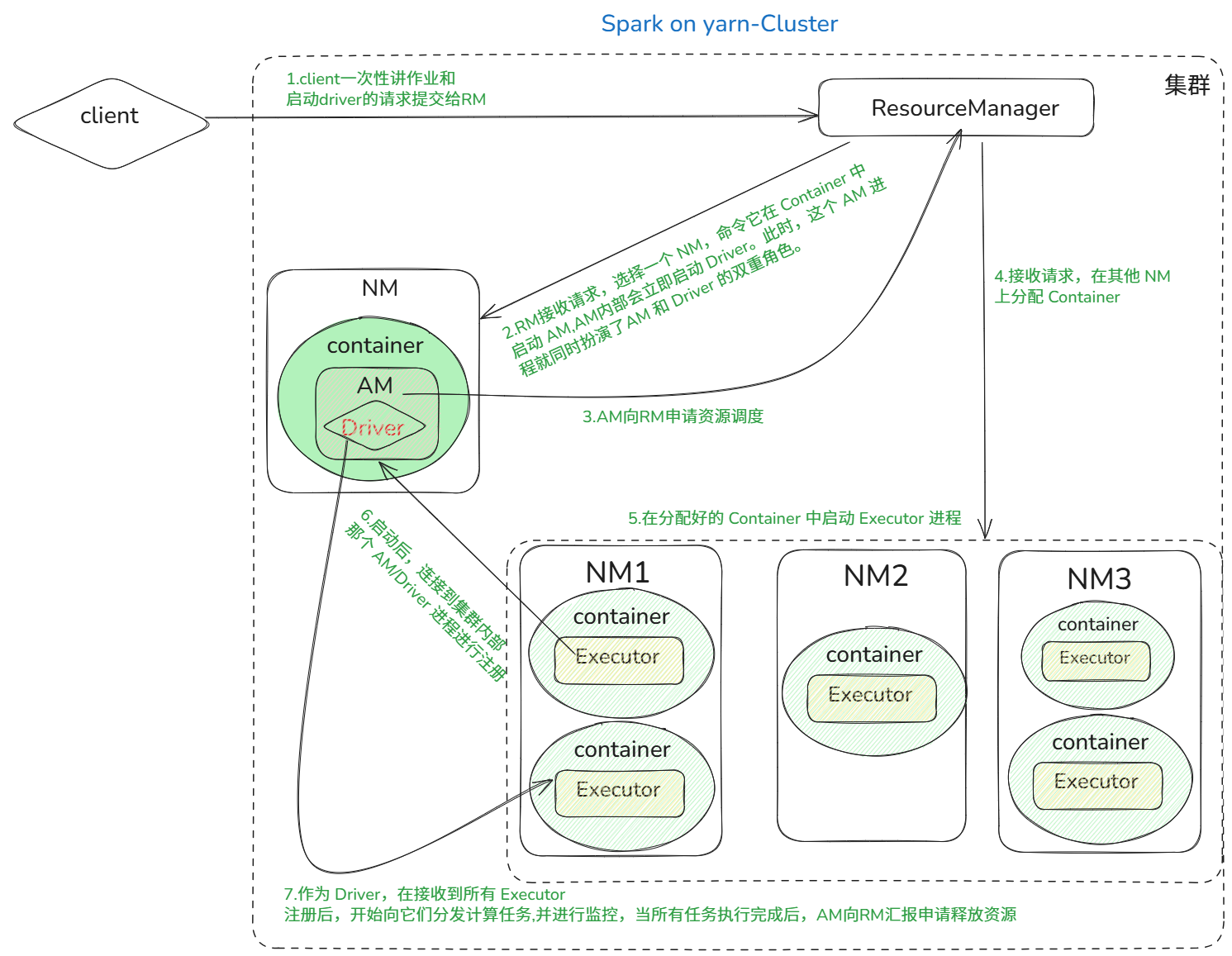
cluster
4.RDD
(1)核心概念
外在特性看,RDD 是一个弹性的、不可变的、可分区的分布式数据集,它支持惰性计算。
内在设计上的五个核心组成部分:
①第一,是一个分区列表:这是 RDD 在物理上的基本单元。一个 RDD 在逻辑上是一个完整的数据集,但在物理上是由一个或多个分区组成的,这直接决定了 RDD 的并行度。Spark 会为 RDD 的每一个分区启动一个 Task 进行计算。因此,分区列表是 Spark 进行并行计算的基础
②第二:是一个作用于每个分区的计算函数:这是一个函数,定义了如何计算出该 RDD 每个分区中的数据,作用:它封装了具体的计算逻辑。当一个 Task 启动后,它要执行的具体操作,就是由这个计算函数来定义的。例如,在一个由 map 操作产生的 RDD 中,这个函数就包含了 map 所需的转换逻辑。
③第三,是一个对父 RDD 的依赖关系列表:这个列表记录了当前 RDD 是如何从其一个或多个父 RDD 转换而来的。这个依赖关系分为窄依赖和宽依赖
作用:实现容错:这个依赖列表构成了 RDD 的**血缘关系 (Lineage)。当某个分区的数据丢失时,Spark 可以通过血缘关系回溯,找到其父 RDD 的相关分区,并使用计算函数重新计算出丢失的数据。
划分 Stage:DAGScheduler 正是根据这个依赖关系是宽依赖还是窄依赖,来决定是否需要在这里切分出一个新的 Stag
④第四,是一个可选的分区器:这是一个仅作用于 Key-Value 型 RDD 的对象
作用:它定义了数据在 Shuffle 过程中的路由规则。当执行 reduceByKey 等宽依赖操作时,Partitioner 会根据数据的 Key,计算出这条数据应该被发送到下游 Stage 的哪一个分区中,从而保证了相同 Key 的数据会被同一个 Task 处理。
⑤第五,是一个可选的首选位置列表:他是这个列表存储了计算每个分区的最佳节点位置
它的作用:这是实现数据本地性 (Data Locality) 优化的关键。TaskScheduler 在分配任务时,会优先查询这个列表,并尽可能地将 Task 调度到存有其所需数据的节点上执行,以最大限度地减少网络数据传输的开销。
总而言之,这五个组成部分共同构成了一个 RDD 的完整定义。它们使得 RDD 不仅仅是一个静态的数据集,更是一个包含了如何计算、如何容错、如何优化的、自洽的计算描述,为 Spark 的高效分布式计算提供了坚实的基础。
(2)RDD操作
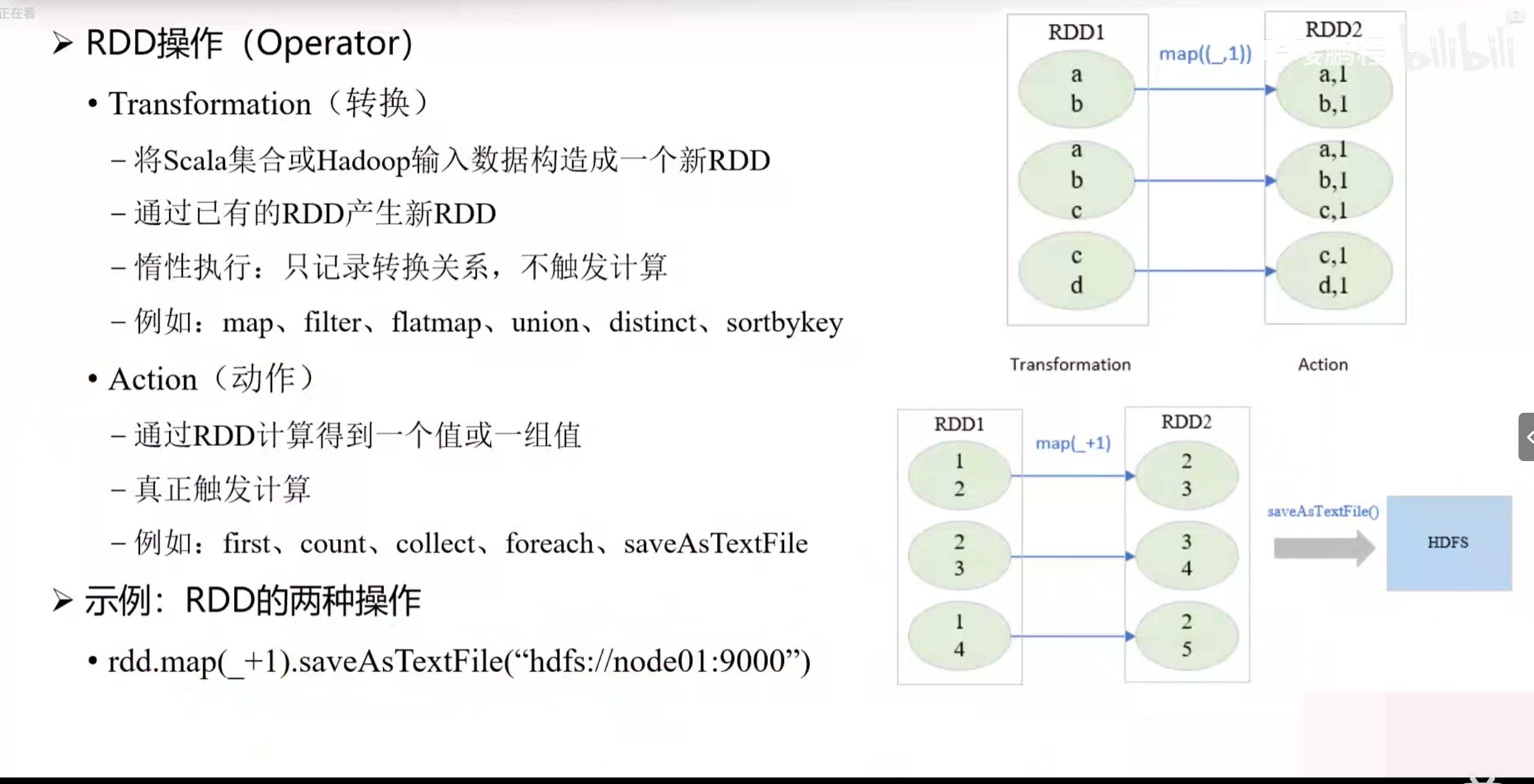
5.Spark shuffle 机制
什么是Shuffle?
Shuffle是指将上游Stage的Map Task输出数据,按照分区规则重新分发到下游Stage的Reduce Task的过程。触发Shuffle的操作:groupBy、join、reduceByKey、distinct等宽依赖操作。
无论 MR 计算模型,还是 spark 计算模型,甚至任何分布式的计算框架,可能都无法避免类似的网路传输操作。Spark 与 HADOOP 在计算模型思想上没有本质区别,还是 Map-Reduce 原型。从 Map 阶段到 Reduce 阶段,则通过 shuffle 方式进行链接。在 Spark 引擎中,shuffle 产生主要是出现了数据跨 RDD 的传输,一般多存在排序、重分区、分组。
需要注意:
- shuffle 是 stage 划分的关键依据,action 算子是 job 划分的关键依据,一个 job 可以有多个 stage
- 宽依赖一般都会产生 shuffle 操作,对应上节课宽依赖的算子
- shuffle 过程是任务计算最复杂最耗时的阶段,期间会涉及到数据跨网络传输,对磁盘的读写也最为频繁
(1)Spark 引擎中 shuffle 的演进:
第一个阶段:V1 - 1.0 基于 hash 的 shuffle:
- 纯基于 hash 方式处理 shuffle 过程
- 引入文件合并机制优化 hash 小文件问题(File Consolidation 机制)
第二个阶段:引入 sorted shuffle 策略,但是中间有几个版本依然默认为 hash shuffle
第三个阶段:默认的 hash shuffle 被抛弃,改用 sort shuffle
- 引入 Tungsten - Sort Based Shuffle 合并入 sort shuffle 策略中
- Hashshuffle 在 2.0 版本中彻底移除源码,退出历史舞台
(2)Hash Shuffle(旧版,已废弃)
原理:
每个Map Task为每个Reducer单独写一个文件,按key的hash值决定写哪个文件。
流程:
Map Task1 → 文件0(Reducer0的数据)
文件1(Reducer1的数据)
文件2(Reducer2的数据)
Map Task2 → 文件0
文件1
文件2
总文件数 = M(Map数)× R(Reducer数)(3)Sort Shuffle(现默认)
核心思路:
每个Map Task只写1个数据文件(还有一个索引文件),内部按partition排好序,配套1个索引文件记录每个partition的起止位置。
流程:
① Map Task处理数据,写入内存缓冲区
↓ 缓冲区满
② 按partition号排序,spill落盘(可能多次)
↓ 所有spill文件
③ merge合并成1个数据文件 + 1个索引文件
↓
④ 下游Reducer读索引,定位自己的数据范围,精准读取
文件数2M(4)两种方式对比
| Hash Shuffle | Sort Shuffle | |
|---|---|---|
| 每个Map文件数 | R个 | 2个(数据+索引) |
| 总文件数 | M × R | 2M |
| 是否排序 | 否 | 按partition排序 |
| 适用场景 | 已废弃 | 现默认 |
Spark Shuffle经历了从Hash Shuffle到Sort Shuffle的演进。Hash Shuffle每个Map Task给每个Reducer写一个文件,M×R个文件在大规模场景下造成严重的小文件问题。Sort Shuffle改为每个Map Task只写一个数据文件,内部按partition排好序,配合索引文件让Reducer精准定位数据,文件数从M×R降到2M。本质流程是:内存缓冲→排序→spill落盘→merge合并→生成数据文件和索引文件。
6.sparkui
作用:
监控作业执行
- 作业进度跟踪:实时查看每个 Spark Job 的运行状态(已完成 / 运行中 / 失败)、耗时等。
- 阶段划分与依赖分析:DAG 图展示 Stage 划分、宽窄依赖关系,清晰呈现任务执行链路。
性能分析与优化
- 任务执行时间监测:定位耗时较长的 Stage/Task,识别性能瓶颈。
- 资源利用评估:查看 Executor 的 CPU、内存、磁盘 I/O 使用情况,判断资源是否过载或闲置。
故障诊断与调试
- 任务失败原因查找:查看失败 Task 的日志、异常栈信息,定位代码或数据问题。
- 数据倾斜分析:通过 Task 的数据量、执行时间分布,快速定位数据倾斜的 Key 与 Stage。
查看sparkUI
1.运行sql后,点击日志中的application,任务id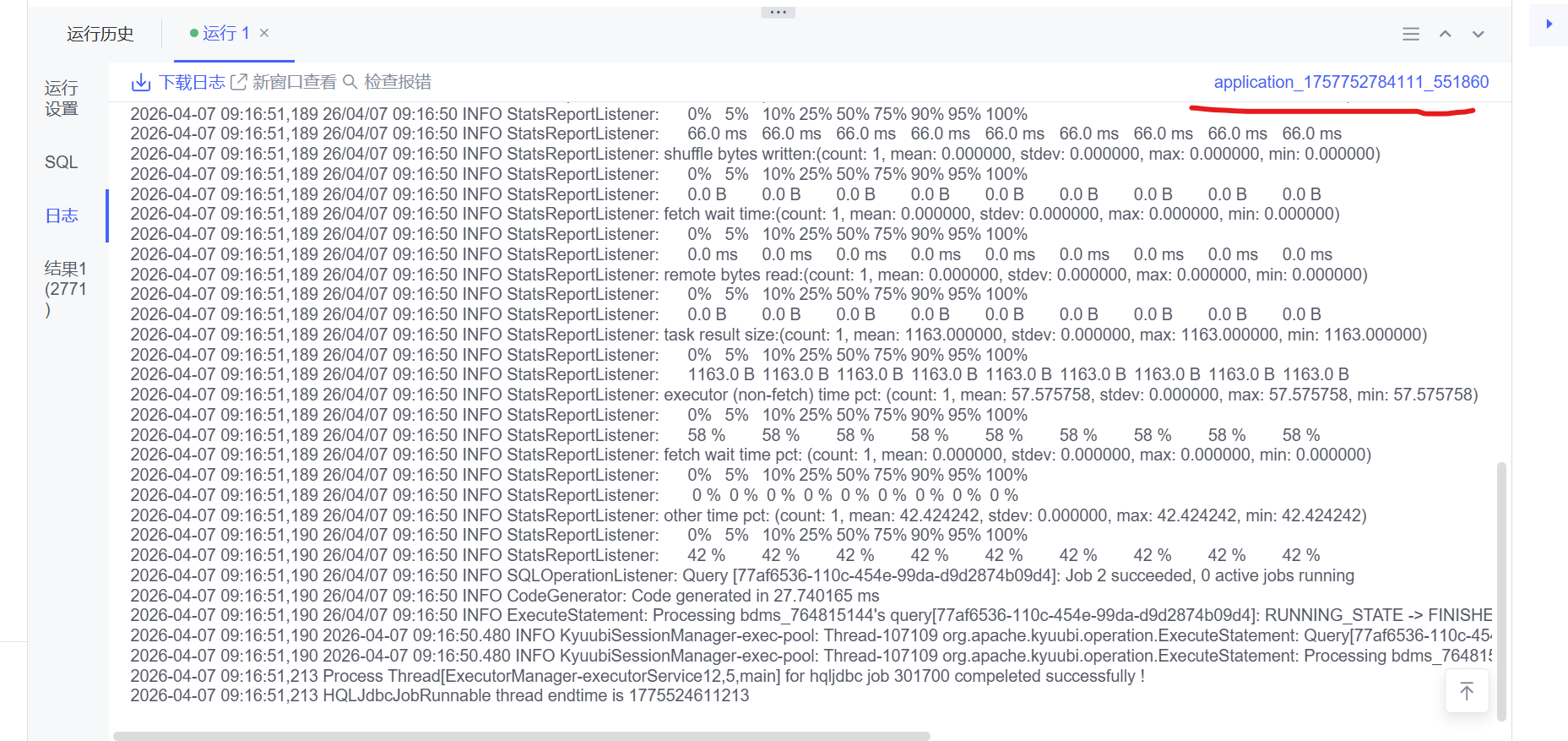
2.进去后点击tracking URL,进入SparkUI 界面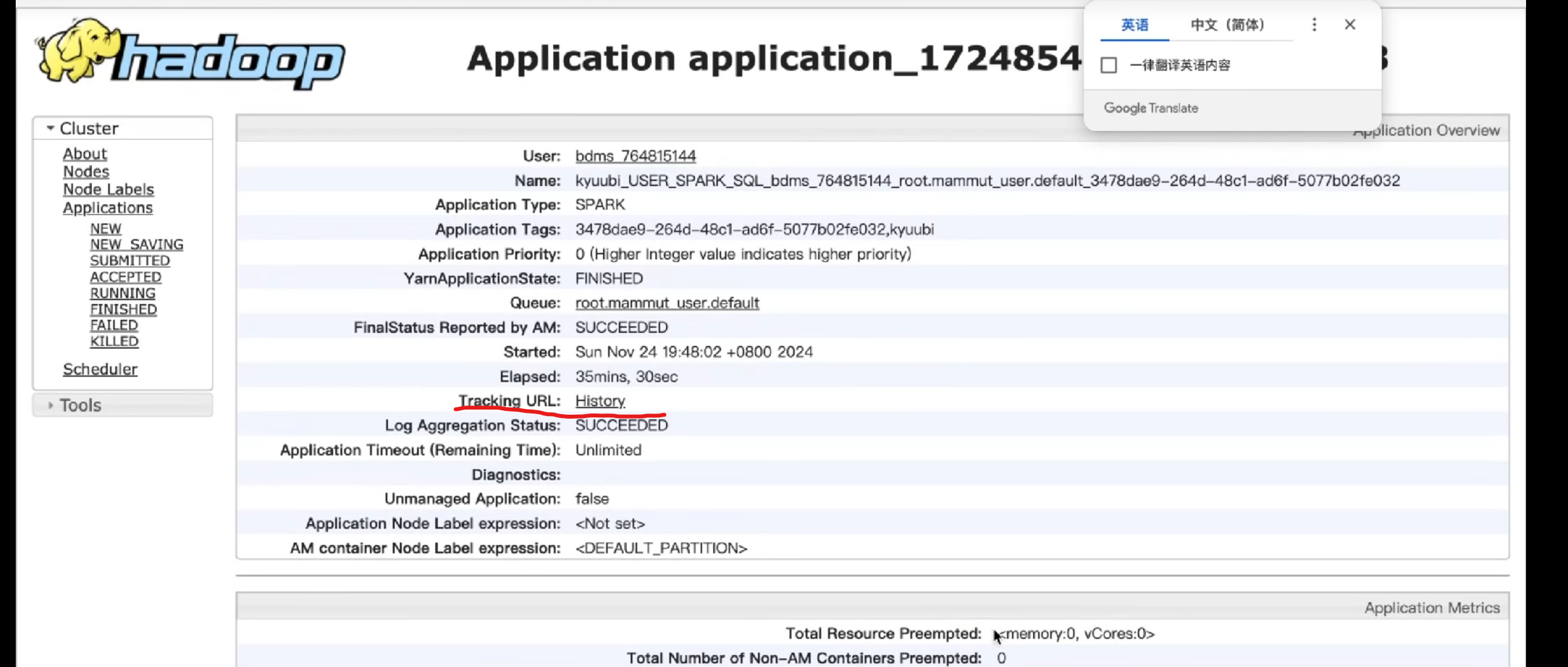
3.进入jobs界面
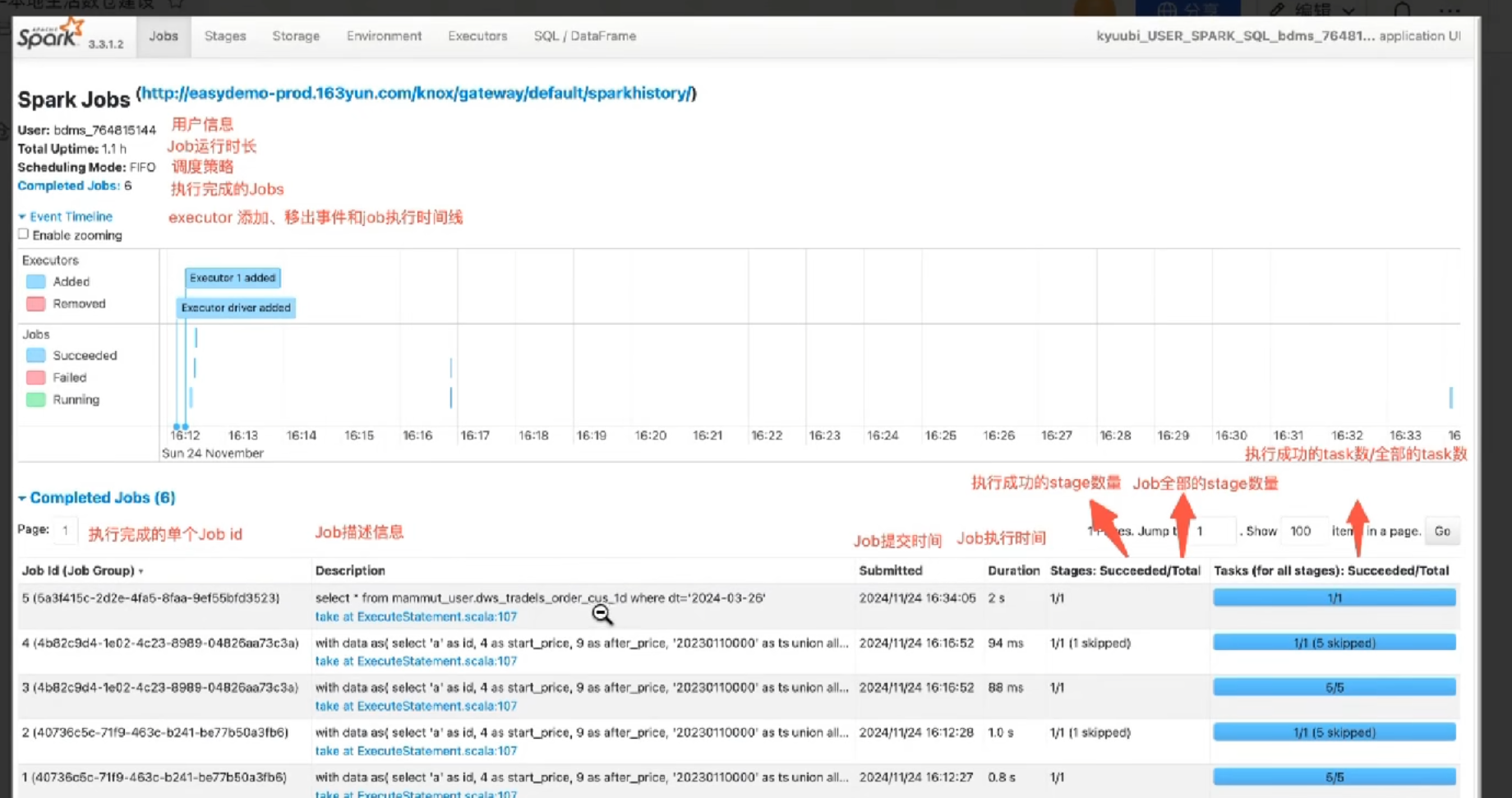
4.对于需要 排查的job,可以点进job 的详细信息
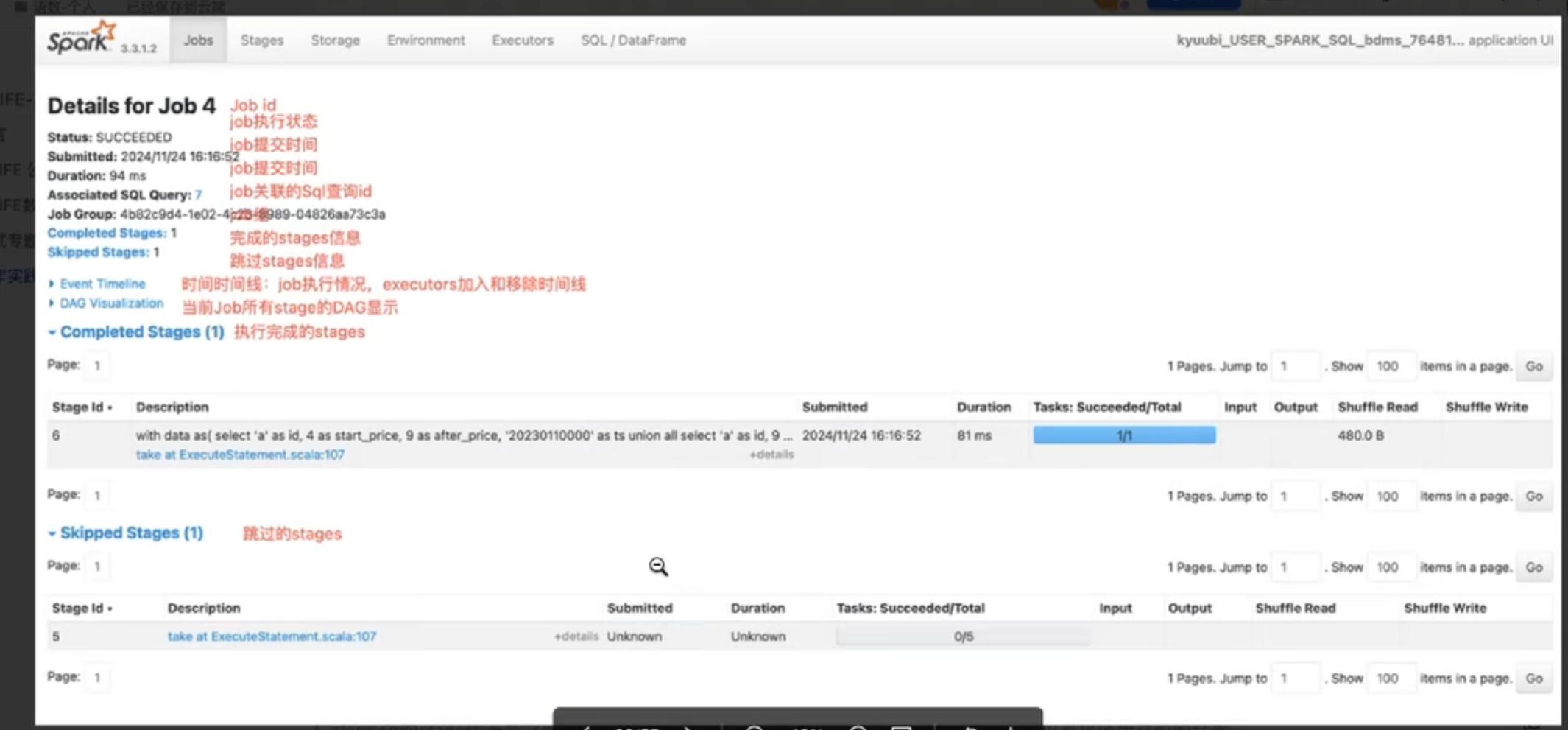
5.stage界面(日常最常用)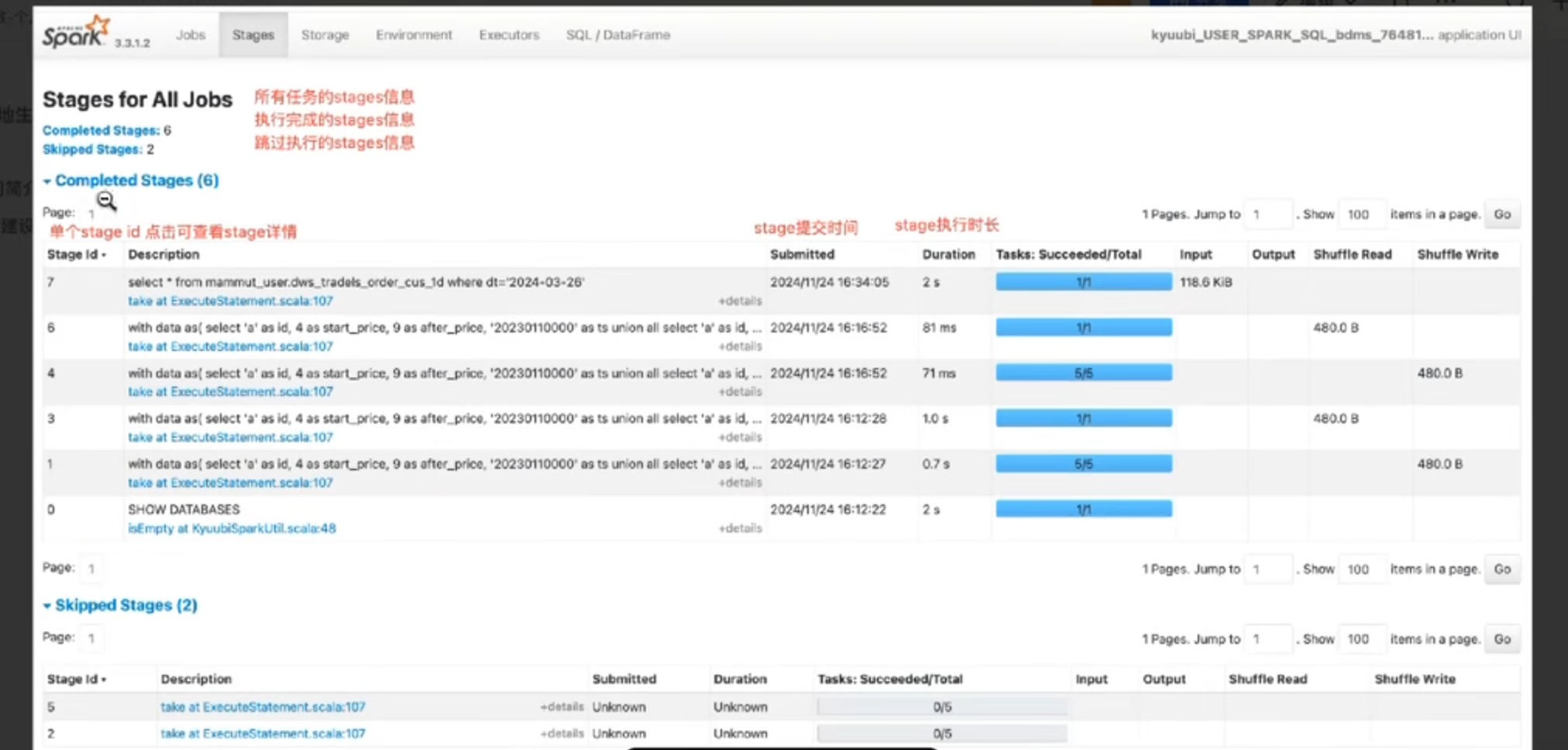
6.stage detail(一个stage在具体的执行操作)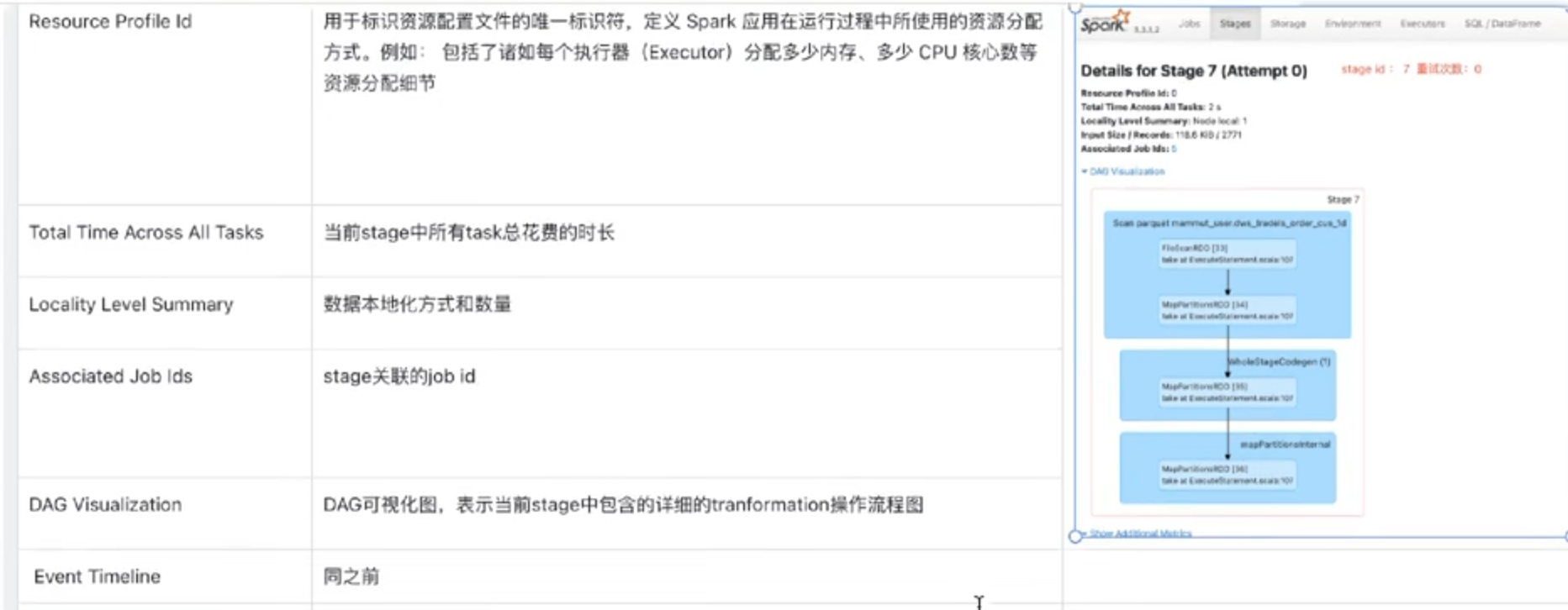
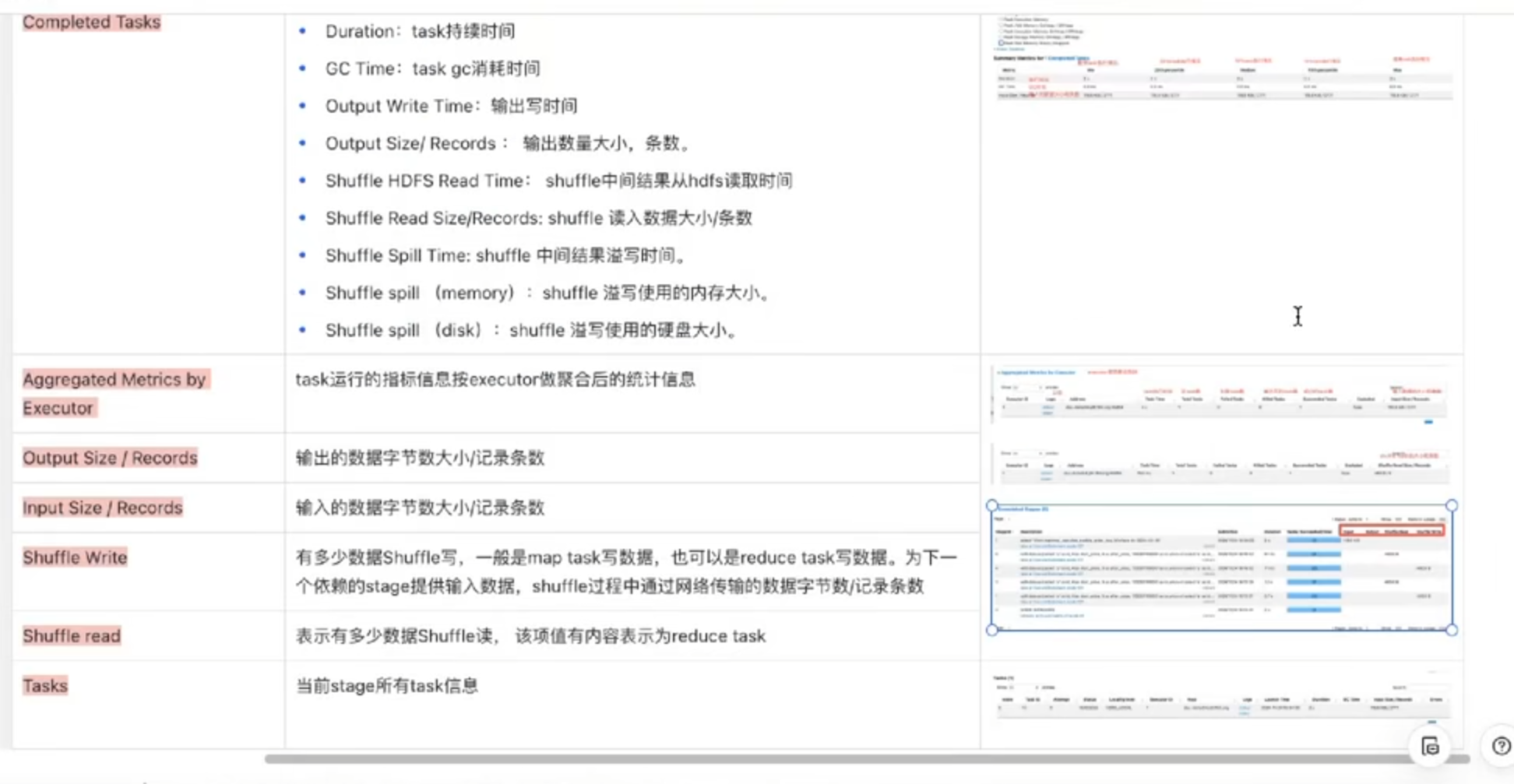
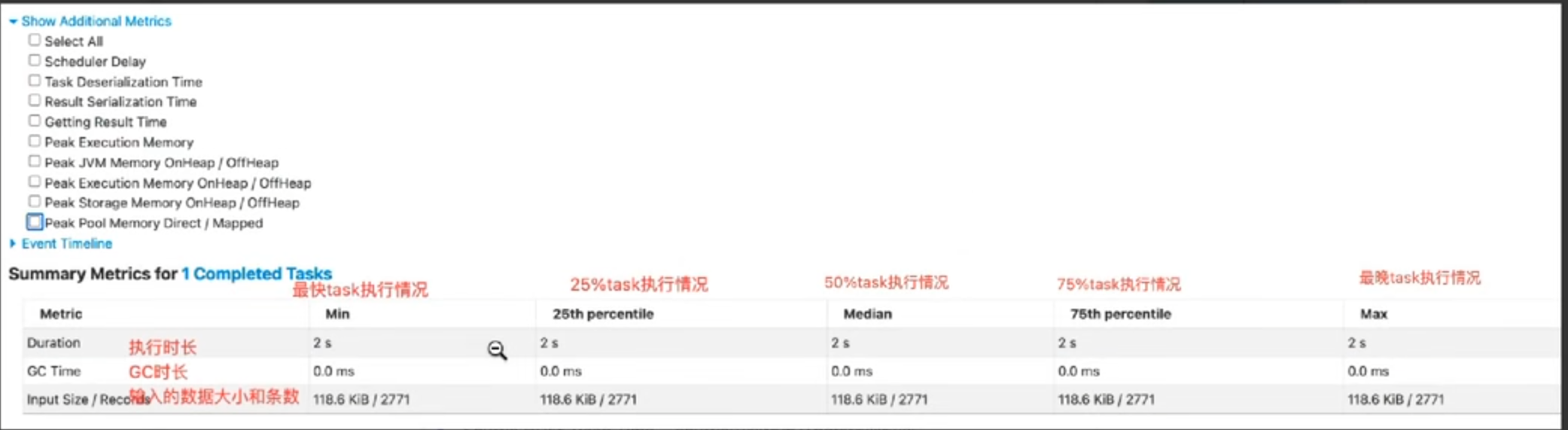

7.enviroment(主要是一些环境的配置)
spark properties比较重要:包含设置的参数有没有生效
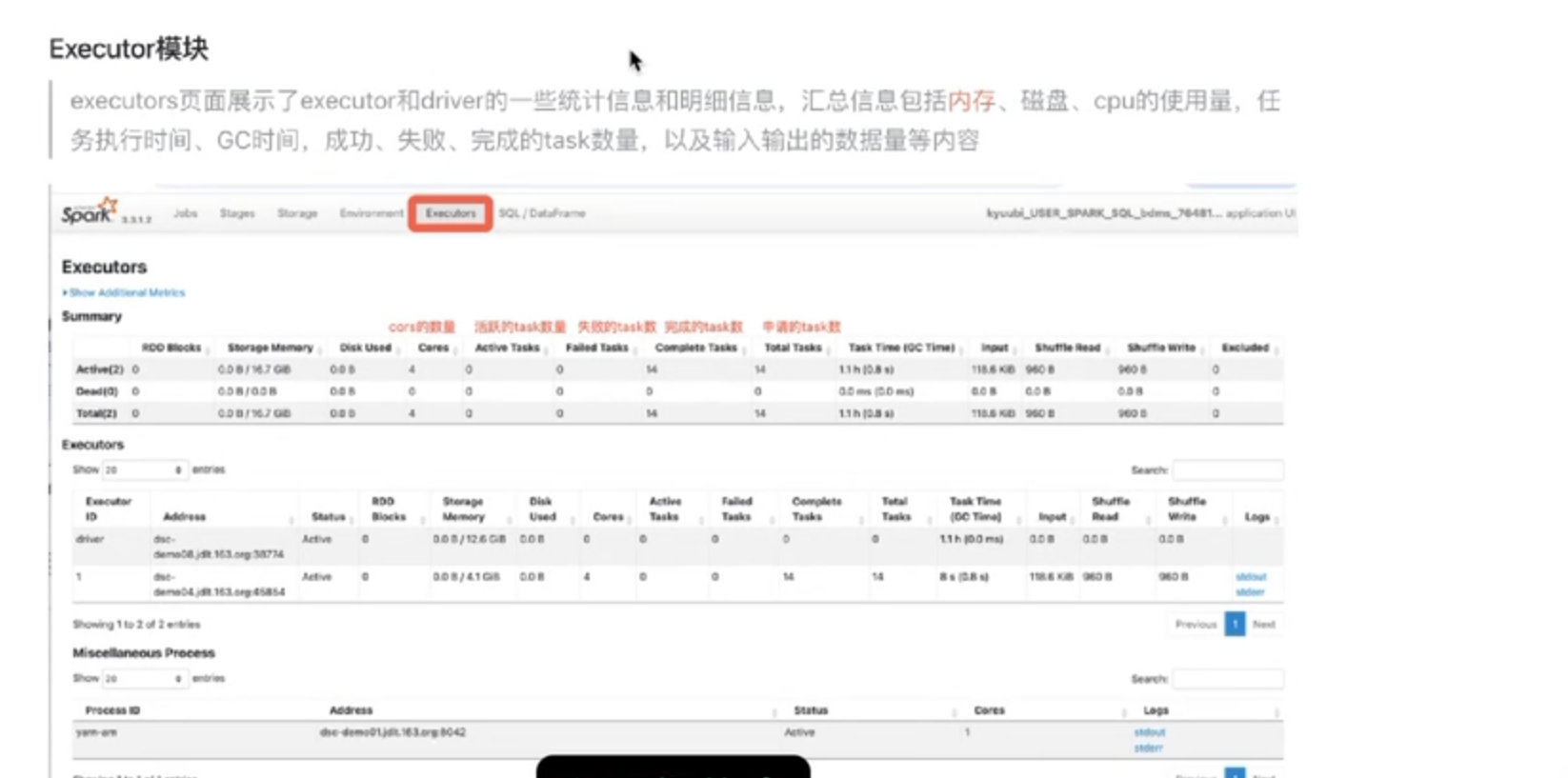
8.executor模块
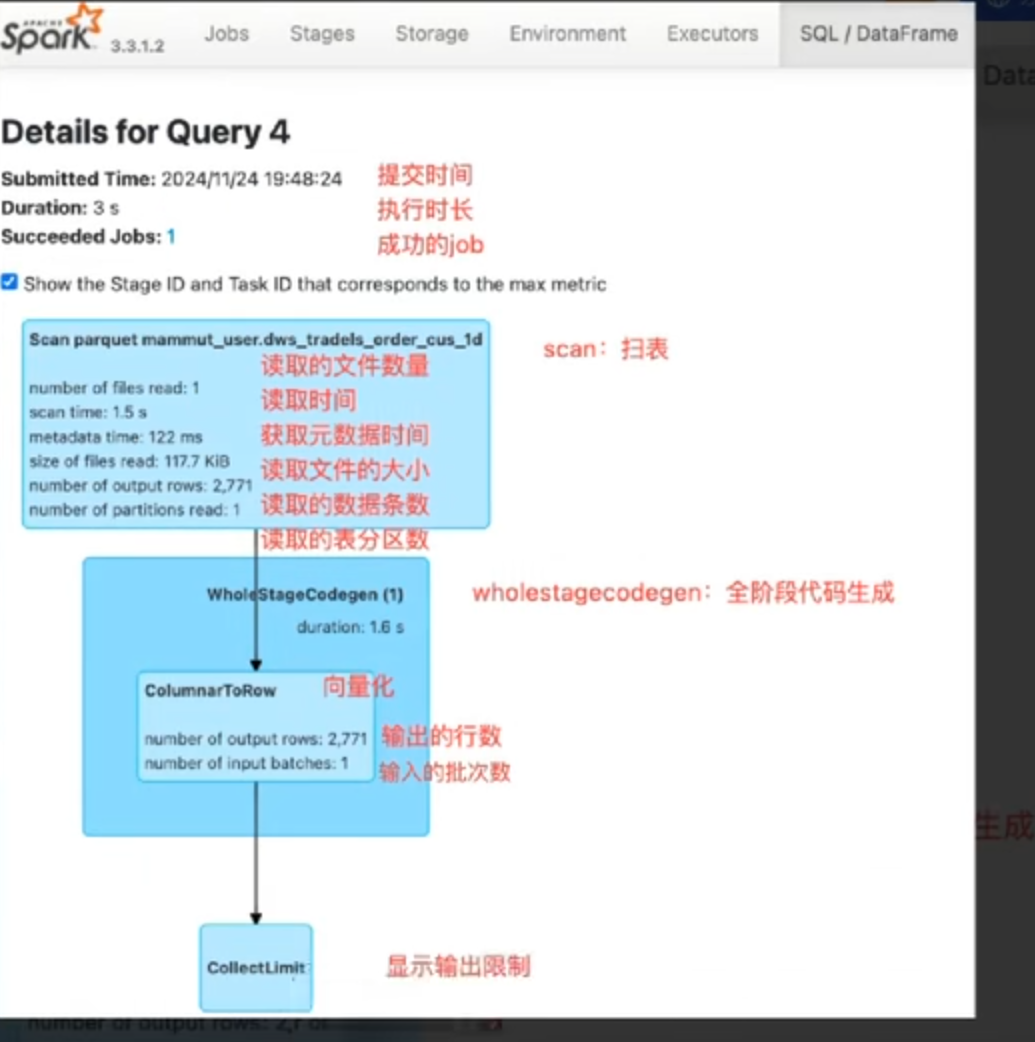
9.sql模块

通过SparkUi排查问题
数仓开发常见问题定位
↓
点击日志链接(进入Spark Web UI)
↓
├─ 分支1:执行失败
│ └─ 点击Stages标签页 → 找到Failed Stages → 查看Failure Reason → 点击+details → 查看报错信息 → 针对性优化
│
└─ 分支2:执行时间长
├─ 路径A(推荐,Stage维度)
│ └─ 点击Stages标签页 → 查看Completed Stages → 按duration倒序 → 点击最长时间Stage → 查看Summary Metrics → 查看Task明细 → 定位问题 → 针对性优化
│
└─ 路径B(Job维度)
└─ 点击Jobs标签页 → 按duration倒序 → 点击最长时间Job → 进入Job后按Stage维度继续排查
AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)