LLM强化学习从入门到精通:HeRL底层逻辑全解析,收藏这篇就够了!
当LLM推理陷入“试错泥潭”:如何用“经验指导”突破性能瓶颈?
在医疗问诊、开放域指令跟随等复杂场景中,大语言模型(LLM)常需通过强化学习(RL)优化推理能力。传统方法如RLVR(基于可验证奖励的强化学习)虽能提升性能,但依赖“盲目试错”——模型在庞大的输出空间中随机探索,难以高效定位高质量样本,甚至因负向梯度扩散陷入局部最优。例如,在医疗问答任务中,模型可能反复生成遗漏关键诊断依据的回答,却无法从失败中学习改进方向。
来自大连理工大学、浙江大学和中国科学院的研究团队指出:有效探索的核心是让模型“知道该往哪里探索”。受此启发,他们提出HeRL框架,通过“事后经验指导”将失败轨迹与未满足的评分标准(rubrics)转化为学习素材,引导模型定向探索高价值样本,无需从零开始试错。这一方法在医疗、指令跟随等开放场景中实现性能显著提升,且代码已开源。
论文技术速览
▌核心贡献:提出HeRL框架,通过事后经验(失败轨迹+未满足评分标准)指导LLM定向探索高价值样本
▌性能指标:IFEval提升9.8% | HealthBench-500提升9.9% | 指令跟随任务最高提升13.5%
▌代码状态:已开源
▌技术谱系:传统RLVR→结构化搜索/内在奖励探索→HeRL(事后经验指导探索)
从“盲目试错”到“经验学习”:LLM强化学习的探索困境与突破
LLM的强化学习优化本质是将策略推向“最大化奖励的理想分布”。早期方法如RLVR依赖标量奖励信号,但在开放场景中,奖励模型易过拟合表面模式,且探索缺乏目标导向。例如,熵基搜索虽能增加输出多样性,却因词汇空间庞大导致效率低下(图2显示其通过率甚至低于随机采样)。
2025年,研究人员开始尝试利用评分标准(rubrics)——将复杂任务拆解为可量化的维度(如“医疗回答需包含病因分析、治疗建议”),通过LLM-as-a-Judge对每个维度评分并聚合为奖励。但现有方法仅将评分标准作为奖励信号,未充分利用其语言描述指导探索。
HeRL的突破在于:将评分标准从“奖励工具”升级为“探索指南”。通过失败轨迹的“事后经验”(如“未满足‘治疗建议’评分项”),模型能在上下文学习中明确改进方向,直接生成符合目标的高价值样本,而非依赖随机试错。
HeRL框架拆解:用“失败经验”引导探索,像老师批改作业一样优化模型
HeRL的核心思路可类比为“老师指导学生改进作业”:学生先尝试答题(生成轨迹),老师用评分标准指出错误(未满足的rubrics),学生根据反馈修改(生成改进轨迹),最终通过“尝试-反馈-改进”循环提升能力。其技术细节如下:
1. 事后经验指导探索(Hindsight Experience guided Exploration)
步骤1:采样候选轨迹:对输入指令,从当前策略中采样N条轨迹(如医疗问答的回答),用评分标准评估每条轨迹的奖励(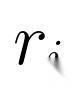
步骤2:筛选高潜力失败样本:选择奖励最高的失败轨迹(接近正确答案但存在不足),符合“最近发展区”理论——这类样本最易通过指导改进。
步骤3:生成改进轨迹:将失败轨迹与未满足评分项作为“事后经验”(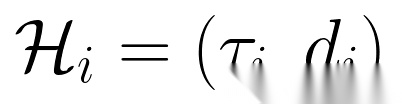 ),引导模型生成改进轨迹(
),引导模型生成改进轨迹(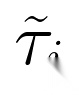 ),并计算新奖励(
),并计算新奖励(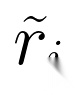 )。
)。
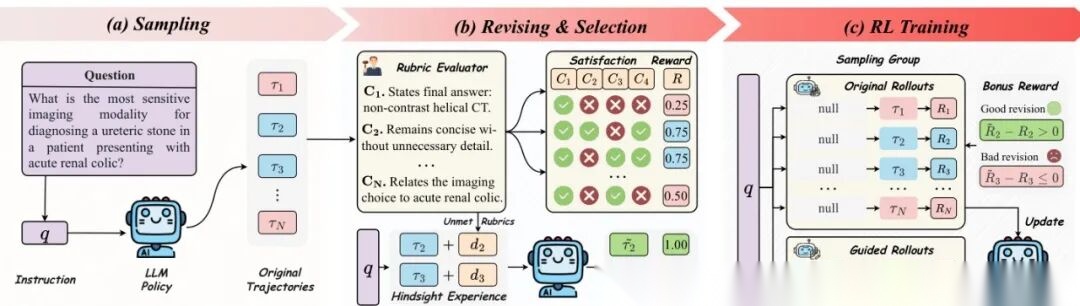
图3:HeRL框架流程图。先采样候选轨迹并评估评分标准,再用高潜力失败轨迹的事后经验生成改进轨迹,最后通过强化学习优化原始轨迹与改进轨迹。
2. 奖励机制:鼓励“可改进性”的Bonus Reward
为激励模型探索“有改进潜力”的轨迹,HeRL引入bonus reward:对高潜力失败轨迹,将其改进后的奖励提升量(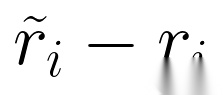 )按比例(
)按比例(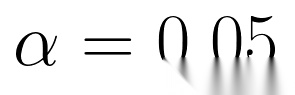 )叠加到原始奖励中:
)叠加到原始奖励中: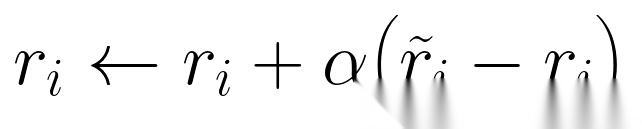
这使得模型不仅关注当前奖励,还重视“未来可提升空间”,避免陷入局部最优。
3. 策略优化:混合轨迹训练与策略塑造
HeRL的训练目标融合两类样本:原始采样轨迹和改进轨迹,通过PPO风格的目标函数优化: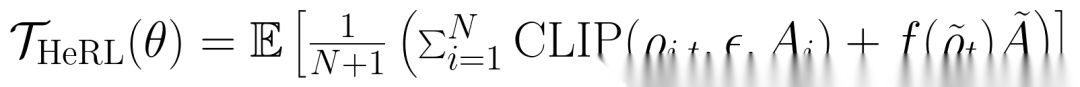
其中,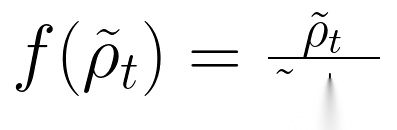 (
( )为策略塑造函数,增强对低概率改进轨迹的学习。
)为策略塑造函数,增强对低概率改进轨迹的学习。
实验验证:HeRL在多场景碾压基线,测试时还能“自我改进”
研究团队在指令跟随、写作、医疗QA等6个基准测试中验证HeRL的效果,核心结论如下:
1. 性能全面超越SFT、DPO、RLVR
在Qwen2.5-7B、Llama-3.2-3B等模型上,HeRL在所有任务中均表现最佳。以Qwen2.5-7B为例:
- IFEval(指令跟随):HeRL达82.4%,较RLVR提升5.1%,较SFT提升6.8%;
- HealthBench-500(医疗QA):HeRL达34.3%,较RLVR提升3.8%,较DPO提升6.3%;
- WritingBench(写作):HeRL达59.1%,而SFT/DPO均出现性能下降(表1)。
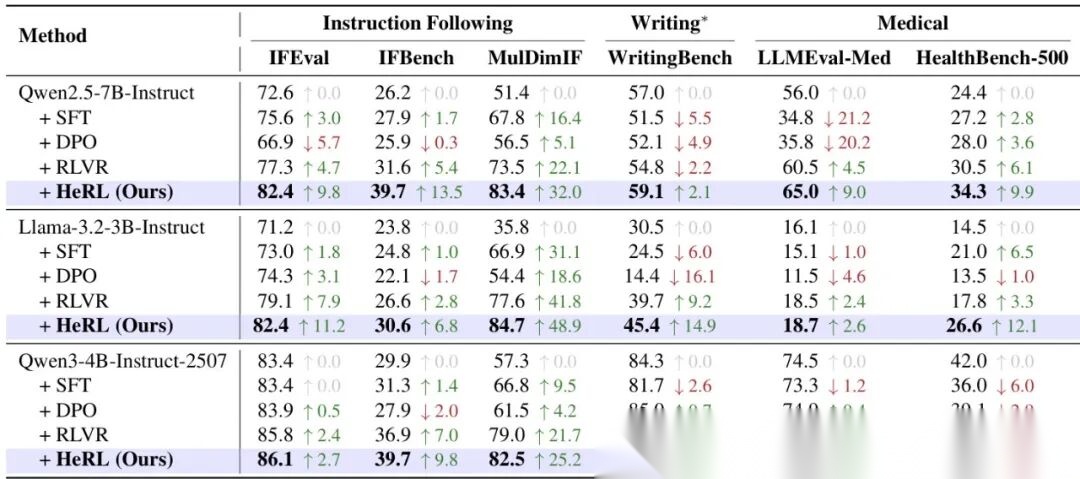
表1:HeRL与各基线在多任务上的性能对比(%)。HeRL在所有模型和任务中均为最优,且写作任务(未参与训练)仍实现提升。
2. 保持跨域泛化能力,避免过拟合
在MATH-500、GPQA等分布外(OOD)任务中,HeRL性能与原始模型相当,甚至略有提升(如Qwen3-4B在MATH-500提升3.8%),证明其未牺牲泛化能力(表2)。
3. 采样效率与推理边界双提升
采样效率:在IFBench上,HeRL的Pass@k(k=1,5,10)均优于RLVR,尤其在小k时优势显著(图4a);
测试时自改进:在HealthBench上,HeRL通过迭代“事后经验指导”,性能持续提升,远超单纯Pass@k采样(图4b)。
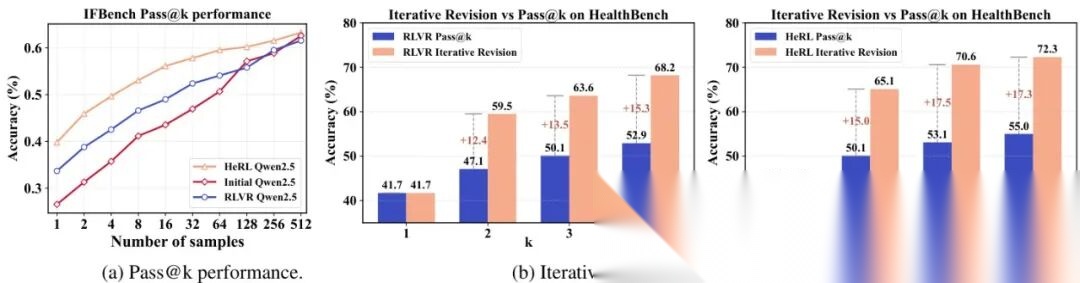
图4:(a)HeRL在不同采样预算下的Pass@k性能;(b)测试时迭代改进进一步提升性能。
4. 消融实验:事后经验(HE)与Bonus Reward(BR)缺一不可
去除HE或BR会导致性能下降。例如,仅用改进轨迹(NaiveHE)甚至会降低WritingBench性能(原文中表3),证明保留事后经验和奖励机制的重要性。
资源汇总
论文来源:https://arxiv.org/abs/2603.20046
GitHub:https://github.com/sikelifei/HeRL
总结
HeRL通过“事后经验指导”突破了LLM强化学习的探索效率瓶颈,将失败轨迹转化为定向探索的“导航图”,在医疗、指令跟随等开放场景中实现显著性能提升。其核心价值在于:
- 样本效率:无需海量试错,通过评分标准语言描述直接引导模型生成高价值样本;
- 泛化能力:在分布外任务中保持稳定性能,避免过拟合;
- 实用扩展性:支持测试时迭代自改进,进一步释放模型潜力。
未来,结合动态调整的评分标准(随模型能力进化),HeRL有望在更复杂的推理任务中发挥更大价值。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献157条内容
已为社区贡献157条内容

所有评论(0)