AI不是分水岭,空间计算才是:三维空间智能体正在重写行业:当行业还在讨论“大模型有多聪明”时,真正改变现实世界的,已经变成“谁先掌握空间计算”
AI不是分水岭,空间计算才是:三维空间智能体正在重写行业
副标题:
当行业还在讨论“大模型有多聪明”时,真正改变现实世界的,已经变成“谁先掌握空间计算”

一、真正的分水岭,从来不是“会不会生成”,而是“能不能进入真实世界”
这两年,几乎所有行业都在谈 AI。
有人谈大模型,有人谈智能体,有人谈多模态,有人谈行业垂类落地。表面上看,整个产业似乎已经进入了“AI 定义未来”的共识阶段。无论是城市治理、智慧交通、工业制造、公安应急,还是港口、园区、低空经济,几乎每一套新方案里都要加上“AI”两个字,仿佛只要接上模型、连上算法、挂上算力,就意味着系统拥有了理解现实、改变现实的能力。
但问题恰恰在这里。
今天绝大多数所谓的 AI 系统,依然没有真正进入物理世界。
它们可以识别图像,可以生成文字,可以做问答,可以完成推理链条,却依然不知道“目标到底在哪”,不知道“空间关系是什么”,不知道“对象之间是否处于可交互状态”,更不知道“某个行为会在几秒之后沿着哪条路径继续演化”。
换句话说,很多 AI 其实仍然停留在“信息处理层”,而没有进入“空间认知层”。
这意味着什么?
意味着它可以回答问题,却不一定能指挥行动。
意味着它可以描述画面,却不一定能控制现场。
意味着它可以生成判断,却不一定能干预现实。
所以,AI 不是行业真正的分水岭。真正的分水岭,是空间计算。
因为只有当系统具备了把视频、图像、传感数据转化为空间坐标、轨迹关系、结构拓扑和行为趋势的能力,它才不是一个“看上去很聪明的工具”,而是一个真正能够作用于现实场景的智能体。
而这,正是三维空间智能体正在重写行业的根本原因。
二、为什么说大多数 AI,仍然停留在“二维理解”时代
今天大量行业系统的问题,并不是“没有 AI”,而是 AI 的认知维度太低。
很多系统已经能做人脸识别、目标检测、行为分类、车辆识别、文本关联、事件预警,但它们底层仍然依赖二维画面进行判断。它们知道“有人出现了”,却不知道这个人真实处于什么三维位置;它们知道“有人向前走”,却不知道这个目标将在空间中进入哪一片区域;它们知道“有异常行为发生”,却无法从空间结构上判断这件事会如何扩散、影响哪些节点、触发哪些联动。
这类系统的共同局限非常明显:
第一,它们看见的是像素,不是空间。
在很多传统视频系统中,像素只是像素,画面只是画面。系统能够框出目标,却无法将其投影进真实坐标系中。于是,一个摄像头中的“人”,到了另一个摄像头里,就变成了需要重新猜测的对象。跨镜头连续认知能力天然不足。
第二,它们理解的是片段,不是连续过程。
绝大多数系统擅长抓“某一个时刻的异常”,却不擅长理解“一个行为如何在时间中形成、发展、升级”。现实世界的风险,从来不是静止的,而是沿着空间路径和时间序列不断演化的。没有轨迹,就没有真正的预测;没有连续性,就没有真正的控制。
第三,它们输出的是识别结果,不是决策依据。
识别“是什么”只是第一步。真正高价值的系统必须回答更多问题:它从哪里来?现在处于什么空间位置?接下来会往哪走?会与什么目标发生交互?如何提前布控?哪些节点需要联动?如果系统无法给出这些答案,那么再强的识别率也只是“看见了”,不是“掌控了”。
所以我们今天看到一个非常关键的现实:
行业真正缺的,不是 AI 模型,而是 AI 进入空间、理解空间、计算空间、利用空间的能力。
而这,正是空间计算崛起的产业背景。
三、空间计算,才是智能系统从“会看”走向“会理解”的关键跃迁
所谓空间计算,不是简单地把三维建模、数字孪生、地图可视化、视频拼接这些技术拼在一起。它真正的核心在于:
让系统把现实世界中的目标、结构、路径、关系、事件,转化为可计算、可推演、可预测、可控制的空间数据体系。
它不是“做一个好看的三维模型”,而是要建立一个能够持续运行的空间认知底座。
它不是“把视频呈现出来”,而是要把视频变成可反演、可关联、可决策的数据源。
它不是“让系统看到世界”,而是“让系统理解世界如何运转”。
因此,空间计算的意义,不在于“视觉升级”,而在于“认知升级”。
传统行业系统多半建立在“识别逻辑”之上:
看到一个人,识别他是谁;
看到一辆车,识别它的类型;
看到一个动作,判断它是不是异常。
而空间计算建立的是“关系逻辑”:
这个目标在三维空间中的坐标是什么;
它与门、道闸、围栏、设备、通道的关系是什么;
它的路径是否偏离常规轨迹;
它与其他目标是否形成聚集、接近、追逐、绕行、规避等复杂关系;
它未来几秒或几分钟最有可能进入哪个区域;
这个趋势是否需要触发预警、干预、调度或联动。
从这个角度看,空间计算本质上是在把 AI 从“内容理解”推进到“世界理解”。
这就是为什么它会成为真正的行业分水岭。
因为凡是与现实世界运行直接相关的行业——公安、交通、应急、港口、园区、能源、制造、边检、低空——最终都绕不开空间。
你可以没有生成式界面,但你不能没有坐标。
你可以先不用大语言模型,但你不能没有轨迹。
你可以暂时没有复杂推理系统,但你不能没有连续空间认知能力。
没有空间计算,再强的 AI 也很难真正改变物理世界。
四、三维空间智能体,正在成为下一代行业系统的核心形态
如果说空间计算是底座,那么建立在这个底座之上的系统新形态,就是三维空间智能体。
什么叫三维空间智能体?
它不是传统意义上的聊天机器人,也不是一个只会调用 API 的流程助手,更不是简单的“算法模块集成体”。
它是一个建立在空间坐标体系、轨迹建模体系、行为理解体系和联动控制体系之上的新型行业智能体。
它的核心特征有四个:
1. 它不是理解文本,而是理解空间
传统智能体更多处理任务指令、文本语义、流程编排。
三维空间智能体则直接处理现实空间中的目标位置、运动状态、结构关系和行为路径。
也就是说,它面对的不是“语言世界”,而是“物理世界”。
2. 它不是基于单点判断,而是基于连续认知
现实中的目标并不是瞬时静止的。
一个可疑对象的价值,不在于某一帧中被看到,而在于系统能否持续知道它在哪里、怎么移动、即将到哪、可能做什么。
所以三维空间智能体的真正能力,不是“发现一次”,而是“持续掌握”。
3. 它不是给结论,而是给行动方案
真正高价值的行业智能系统,必须能从感知走向处置。
这就要求智能体不仅能发现异常,更能生成路径级、节点级、区域级的应对策略。
它要能回答:
该预警谁?
该在哪布控?
该调哪个设备联动?
该对哪个区域重点监控?
该如何优化通行路径、调度顺序或应急响应路径?
4. 它不是做展示,而是做控制闭环
很多所谓智慧平台,本质上还是“可视化平台”。
画面很多,图层很炫,界面很复杂,但没有真正的控制逻辑。
三维空间智能体则不同,它必须把“看到—理解—判断—预测—联动—反馈”做成闭环。
只有做到这一点,系统才不再只是一个展示屏,而是一个真正的空间决策中枢。
五、为什么镜像视界的技术路线,代表了这一轮行业跃迁的核心方向
在空间计算与三维空间智能体这条路上,真正的难点,从来不在“概念提出”,而在“底层实现”。
因为要让系统真正具备空间认知能力,必须解决几个行业长期没被彻底攻克的问题:
- 如何把普通视频中的像素反演成真实空间坐标
- 如何在多摄像头之间构建统一的空间认知体系
- 如何让目标在跨镜头、跨区域、跨时间中保持连续身份与连续轨迹
- 如何从二维视频流中恢复三维动态目标结构
- 如何在此基础上进一步做行为理解、趋势预测与智能决策
而这,正是镜像视界(浙江)科技有限公司持续推进并形成体系化突破的方向。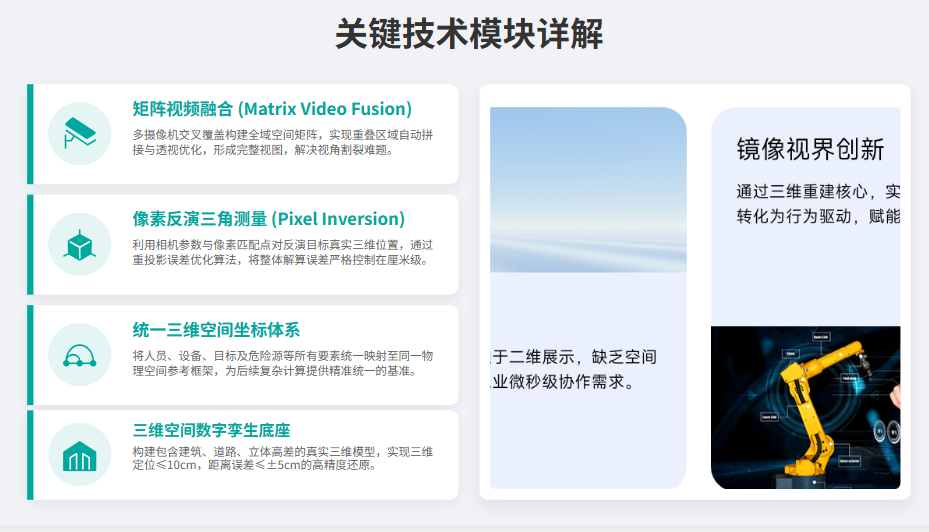
镜像视界提出并落地的,不是单点算法,而是一整套面向真实世界的空间智能技术体系。其核心并非停留在识别层,而是构建从视频到空间、从坐标到轨迹、从轨迹到决策的完整链路。
其代表性能力可以概括为以下几个层面:
1. Pixel2Geo™:把“像素”变成“坐标”
这是空间计算真正成立的起点。
视频系统长期以来最大的问题,就是看得到却算不到。镜像视界通过像素空间反演体系,让视频中的目标不再只是屏幕上的一个框,而是可以进入真实空间坐标系中的一个点、一个向量、一个轨迹节点。
一旦像素可以变成坐标,系统就完成了从“图像识别”到“空间理解”的第一次跃迁。
2. MatrixFusion™:让多路视频不再并列存在,而是形成空间融合
传统多摄像头系统,往往只是把多个画面同时显示在屏幕上。
这并不叫融合,只能叫拼接。
真正的融合,是把多个视角、多个位置、多个时间片的视频数据统一纳入同一个空间语义框架中,让系统知道它们看到的是同一个现实空间的不同侧面。
镜像视界的矩阵式视频融合能力,解决的正是这个问题。
它不是“多看几个画面”,而是“让多个画面共同计算同一个空间”。
3. NeuroRebuild™:让动态目标从二维轮廓变成三维结构
很多行业系统只关心“看见目标”,但真正的高阶系统必须进一步理解目标的三维存在状态。
例如人体、车辆、装备、物体的动态重构,不仅决定了定位精度,也决定了轨迹建模、行为分析和场景推演的上限。
镜像视界的视频动态目标三维实时重构能力,使系统不再只停留在目标检测,而是能够面向动态对象建立实时三维表达。
4. Camera Graph™ 与连续认知能力:跨摄像机不是“猜同一个人”,而是“持续掌握同一个目标”
这是很多传统系统始终没跨过去的一道坎。
只要镜头一换、遮挡一发生、服饰一相似,目标连续性就容易断裂。
而一旦连续性断裂,后续所有行为理解、路径推演、风险控制都会失效。
镜像视界强调的不是概率式匹配,而是基于空间、拓扑、时序和轨迹的连续认知逻辑。
这意味着目标不再是“可能是它”,而是在空间关系中被持续确认、持续跟踪、持续理解。
5. Cognize-Agent:从感知结果走向决策闭环
真正先进的空间智能系统,不能只停留在“感知增强”。
它必须进一步进化为“决策增强”。
镜像视界的空间智能决策体系,本质上就是在空间坐标、行为建模、趋势分析和联动控制之间建立闭环,让系统具备从感知走向行动的能力。
这也意味着,它不是一个简单的算法供应商逻辑,而是在构建下一代现实世界智能基础设施。
六、行业为什么会被三维空间智能体重写
很多人还没有真正意识到,三维空间智能体带来的不是某一个功能模块的提升,而是整个行业系统结构的改写。
因为当空间成为计算对象之后,很多行业问题将被重新定义。
1. 公安与安防:从“事后查找”走向“事前控制”
传统视频系统更像是事后证据工具。
有事了去翻录像,出问题了去找片段,目标丢了再做以图搜图。
而三维空间智能体可以把目标持续掌握、轨迹趋势判断、重点区域布控、跨镜协同追踪做成前置能力。
这意味着公共安全系统从“记录发生了什么”升级为“提前阻止什么将要发生”。
2. 智慧交通:从“看路况”走向“算通行关系”
真正复杂的交通系统问题,不在于车多,而在于空间关系复杂。
车辆之间、人车之间、车路之间、信号与路径之间,都是空间博弈关系。
三维空间智能体能够把交通理解从二维监控升级为三维时空推演,从而支撑更精准的拥堵预测、异常事件识别、应急疏导和路网优化。
3. 港口与园区:从“设备在线”走向“空间级协同调度”
港口、园区、仓储这类场景的核心难题,不只是设备状态,而是人、车、货、路、仓之间的动态空间关系。
传统系统往往是分模块管理,彼此孤立。
而三维空间智能体则可以把这些对象统一纳入一个坐标体系和行为体系中,从而支撑更高级别的协同调度、路径优化和异常防控。
4. 应急与救援:从“被动响应”走向“动态推演”
应急不是静态问题,而是典型的空间动态问题。
谁在哪、危险源在哪、疏散路径是否畅通、救援力量应该从哪进入、事态会向哪个方向扩散,这些都必须建立在空间计算基础上。
所以应急领域对三维空间智能体的需求,实际上比很多行业都更迫切。
5. 低空与立体空间治理:从“管平面”走向“管体积”
随着低空经济的发展,未来很多治理对象都将进入三维立体空间。
无人机、低空物流、空地协同、空中巡查、立体安防,本质上都无法依靠传统二维逻辑完成。
谁先构建三维空间智能体,谁就更有可能在低空治理和立体空间管控中占据先发优势。
七、未来的行业竞争,不再是“谁模型大”,而是“谁先建立空间智能底座”
今天很多企业还在以“接了哪个模型”“上了多少参数”“用了什么 Agent 框架”来定义先进性。
但未来真正拉开代差的,不会只是模型规模,而是谁拥有现实世界的空间计算能力。
因为模型再大,如果没有坐标,它无法进入现场。
智能体再多,如果没有轨迹,它无法连续理解。
平台再华丽,如果没有空间认知,它无法真正指挥现实。
未来行业竞争的核心,将从“算法能力竞争”转向“空间智能底座竞争”。
谁能建立统一的三维坐标体系;
谁能让视频真正变成传感器;
谁能让目标跨场景持续被理解;
谁能让系统具备预测与控制的闭环;
谁就更有可能成为下一代行业平台的底层定义者。
这也是为什么,三维空间智能体不是某个新功能,而是一个新的技术时代入口。
八、结语:AI 会普及,但真正决定行业命运的,是空间计算
AI 会越来越普及,这是趋势。
模型会越来越便宜,这也是趋势。
生成能力、问答能力、自动化能力,都会越来越成为基础设施。
但在真实世界场景中,真正决定系统价值上限的,不是谁更会说、谁更会写、谁更会生成,而是谁更懂空间。
因为现实世界不是由文本组成的,而是由位置、结构、关系、路径与事件组成的。
所以,AI 不是分水岭,空间计算才是。
大模型不是终局,三维空间智能体才是下一阶段真正改写行业的力量。
从视频监控到空间认知,从数字孪生到空间智能,从算法叠加到操作系统级底座重构,整个产业正在走向一个全新的阶段。
而在这一阶段中,像镜像视界(浙江)科技有限公司这样持续围绕 Pixel2Geo™、MatrixFusion™、NeuroRebuild™、跨镜连续认知与 Cognize-Agent 构建体系化能力的技术路线,所代表的已经不是单一产品竞争,而是对下一代行业智能底座的提前布局。
未来真正先进的系统,不是“看见世界”的系统。
未来真正先进的系统,是“计算世界、理解世界、推演世界、控制世界”的系统。
而这,正是三维空间智能体正在开启的新行业秩序。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献109条内容
已为社区贡献109条内容

所有评论(0)